 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SDnDTI: Self-supervised deep learning-based denoising for diffusion tensor MRI
Nov 14, 2021
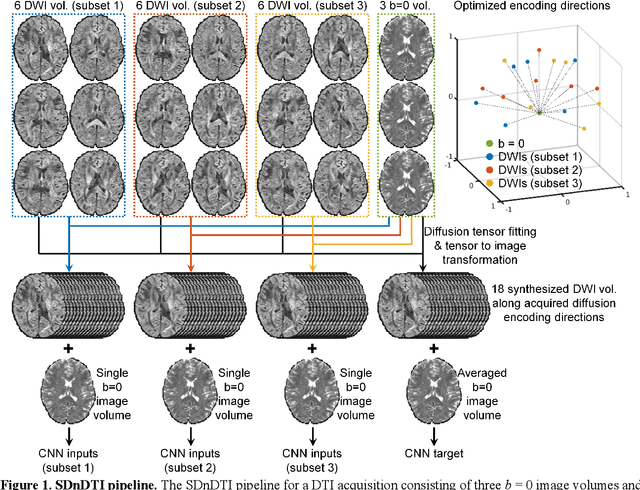
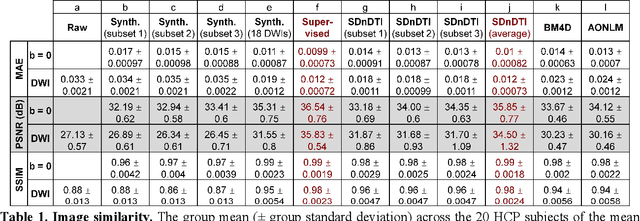
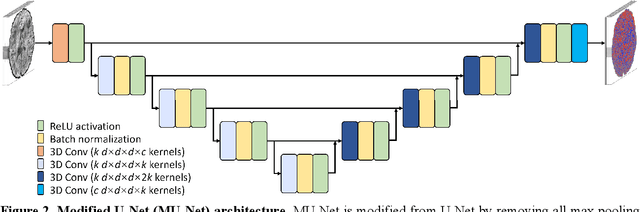
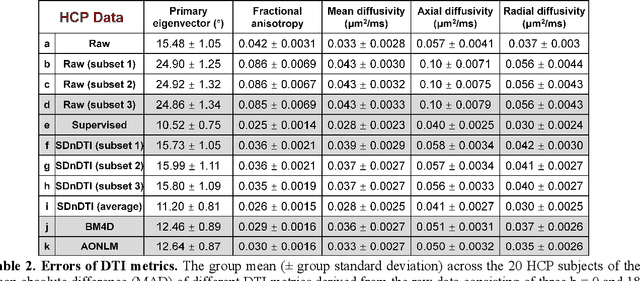
The noise in diffusion-weighted images (DWIs) decreases the accuracy and precision of diffusion tensor magnetic resonance imaging (DTI) derived microstructural parameters and leads to prolonged acquisition time for achieving improved signal-to-noise ratio (SNR). Deep learning-based image denoising using convolutional neural networks (CNNs) has superior performance but often requires additional high-SNR data for supervising the training of CNNs, which reduces the practical feasibility. We develop a self-supervised deep learning-based method entitled "SDnDTI" for denoising DTI data, which does not require additional high-SNR data for training. Specifically, SDnDTI divides multi-directional DTI data into many subsets, each consisting of six DWI volumes along optimally chosen diffusion-encoding directions that are robust to noise for the tensor fitting, and then synthesizes DWI volumes along all acquired directions from the diffusion tensors fitted using each subset of the data as the input data of CNNs. On the other hand, SDnDTI synthesizes DWI volumes along acquired diffusion-encoding directions with higher SNR from the diffusion tensors fitted using all acquired data as the training target. SDnDTI removes noise from each subset of synthesized DWI volumes using a deep 3-dimensional CNN to match the quality of the cleaner target DWI volumes and achieves even higher SNR by averaging all subsets of denoised data. The denoising efficacy of SDnDTI is demonstrated on two datasets provided by the Human Connectome Project (HCP) and the Lifespan HCP in Aging. The SDnDTI results preserve image sharpness and textural details and substantially improve upon those from the raw data. The results of SDnDTI are comparable to those from supervised learning-based denoising and outperform those from state-of-the-art conventional denoising algorithms including BM4D, AONLM and MPPCA.
Automated Cardiac Resting Phase Detection Targeted on the Right Coronary Artery
Sep 06, 2021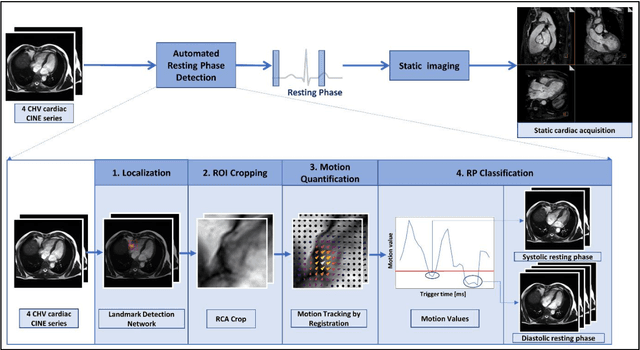
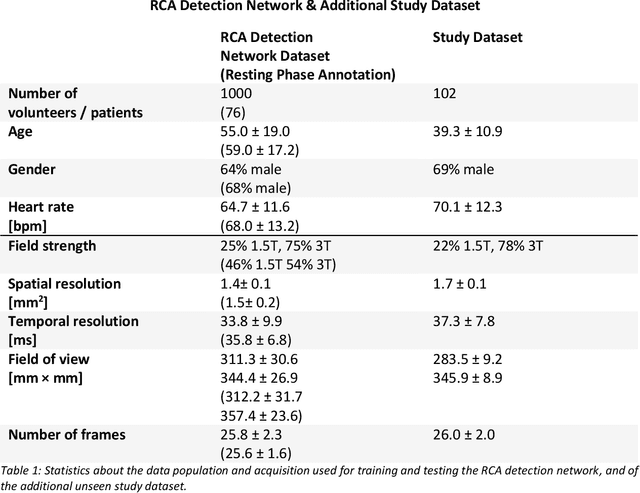
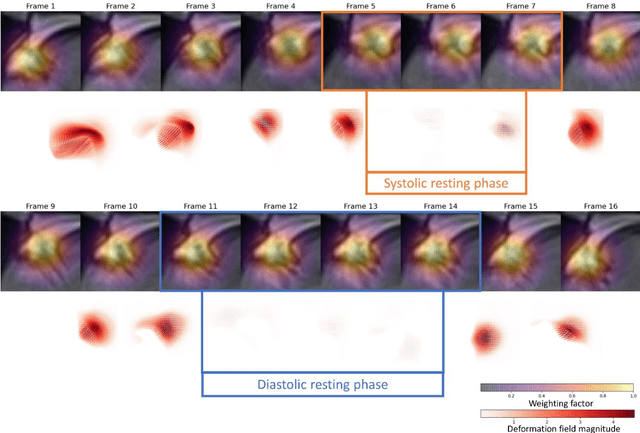
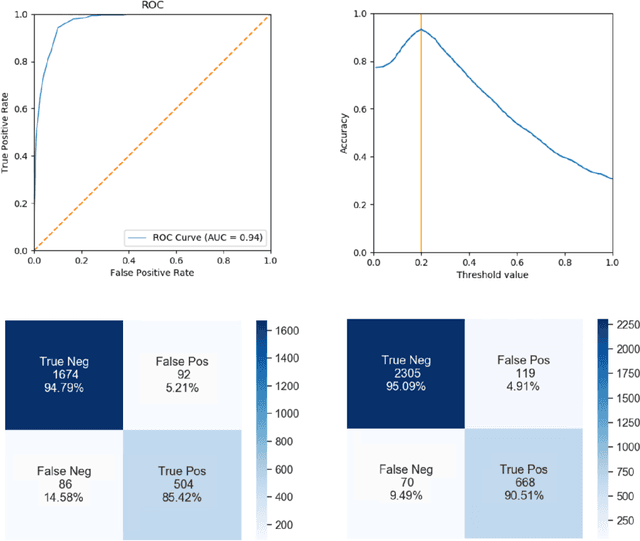
Purpose: Static cardiac imaging such as late gadolinium enhancement, mapping, or 3-D coronary angiography require prior information, e.g., the phase during a cardiac cycle with least motion, called resting phase (RP). The purpose of this work is to propose a fully automated framework that allows the detection of the right coronary artery (RCA) RP within CINE series. Methods: The proposed prototype system consists of three main steps. First, the localization of the regions of interest (ROI) is performed. Second, as CINE series are time-resolved, the cropped ROI series over all time points are taken for tracking motions quantitatively. Third, the output motion values are used to classify RPs. In this work, we focused on the detection of the area with the outer edge of the cross-section of the RCA as our target. The proposed framework was evaluated on 102 clinically acquired dataset at 1.5T and 3T. The automatically classified RPs were compared with the ground truth RPs annotated manually by a medical expert for testing the robustness and feasibility of the framework. Results: The predicted RCA RPs showed high agreement with the experts annotated RPs with 92.7% accuracy, 90.5% sensitivity and 95.0% specificity for the unseen study dataset. The mean absolute difference of the start and end RP was 13.6 ${\pm}$ 18.6 ms for the validation study dataset (n=102). Conclusion: In this work, automated RP detection has been introduced by the proposed framework and demonstrated feasibility, robustness, and applicability for diverse static imaging acquisitions.
Visual Evaluation of Generative Adversarial Networks for Time Series Data
Dec 23, 2019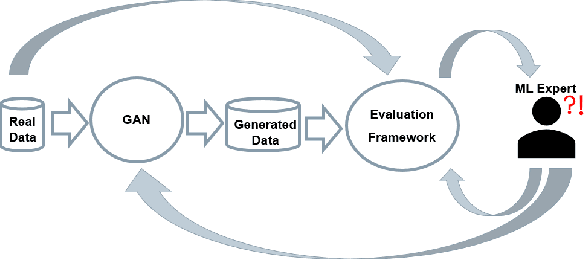
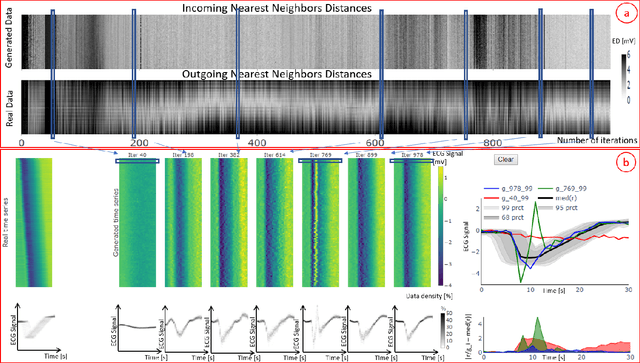
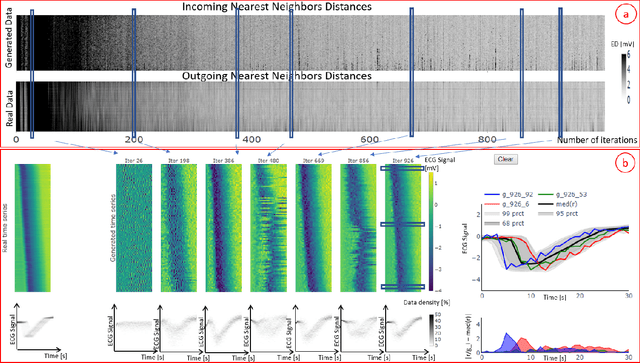
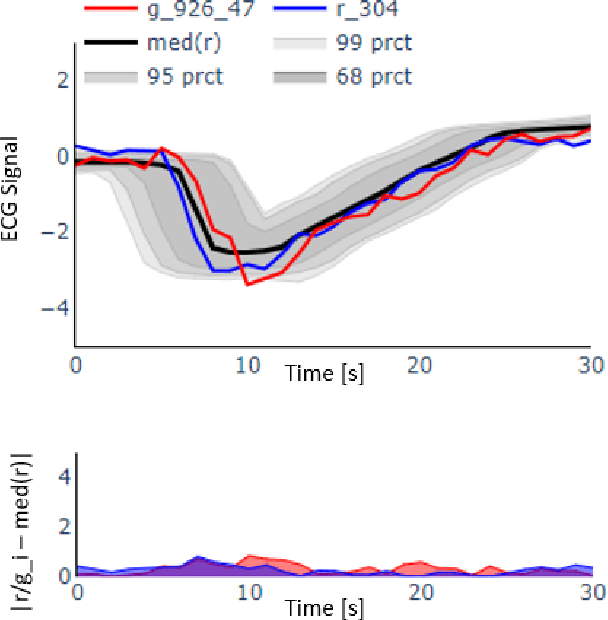
A crucial factor to trust Machine Learning (ML) algorithm decisions is a good representation of its application field by the training dataset. This is particularly true when parts of the training data have been artificially generated to overcome common training problems such as lack of data or imbalanced dataset. Over the last few years, Generative Adversarial Networks (GANs) have shown remarkable results in generating realistic data. However, this ML approach lacks an objective function to evaluate the quality of the generated data. Numerous GAN applications focus on generating image data mostly because they can be easily evaluated by a human eye. Less efforts have been made to generate time series data. Assessing their quality is more complicated, particularly for technical data. In this paper, we propose a human-centered approach supporting a ML or domain expert to accomplish this task using Visual Analytics (VA) techniques. The presented approach consists of two views, namely a GAN Iteration View showing similarity metrics between real and generated data over the iterations of the generation process and a Detailed Comparative View equipped with different time series visualizations such as TimeHistograms, to compare the generated data at different iteration steps. Starting from the GAN Iteration View, the user can choose suitable iteration steps for detailed inspection. We evaluate our approach with a usage scenario that enabled an efficient comparison of two different GAN models.
Improving Robustness of time series classifier with Neural ODE guided gradient based data augmentation
Oct 15, 2019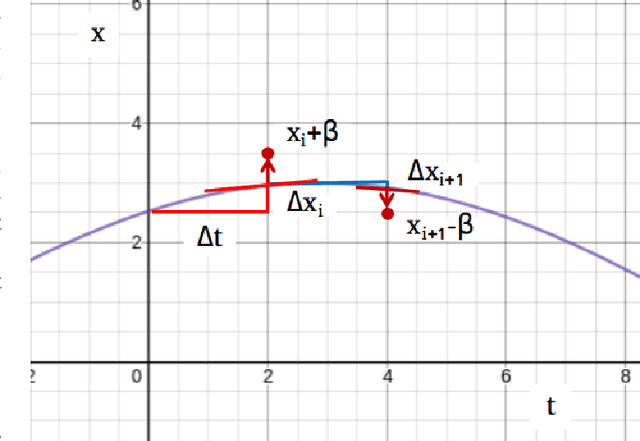
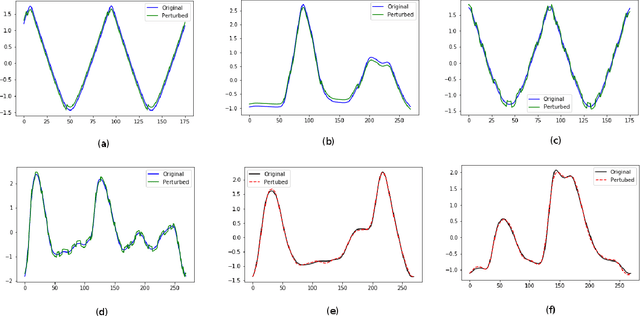
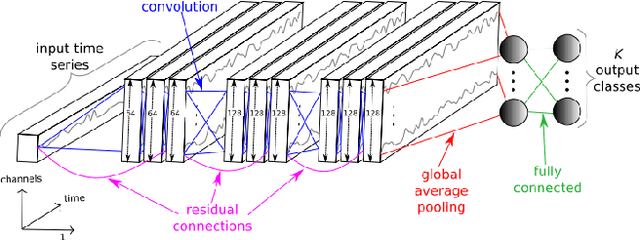
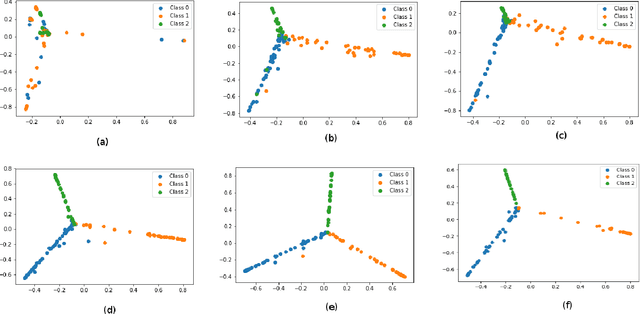
Exploring adversarial attack vectors and studying their effects on machine learning algorithms has been of interest to researchers. Deep neural networks working with time series data have received lesser interest compared to their image counterparts in this context. In a recent finding, it has been revealed that current state-of-the-art deep learning time series classifiers are vulnerable to adversarial attacks. In this paper, we introduce two local gradient based and one spectral density based time series data augmentation techniques. We show that a model trained with data obtained using our techniques obtains state-of-the-art classification accuracy on various time series benchmarks. In addition, it improves the robustness of the model against some of the most common corruption techniques,such as Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM).
RADAMS: Resilient and Adaptive Alert and Attention Management Strategy against Informational Denial-of-Service (IDoS) Attacks
Nov 01, 2021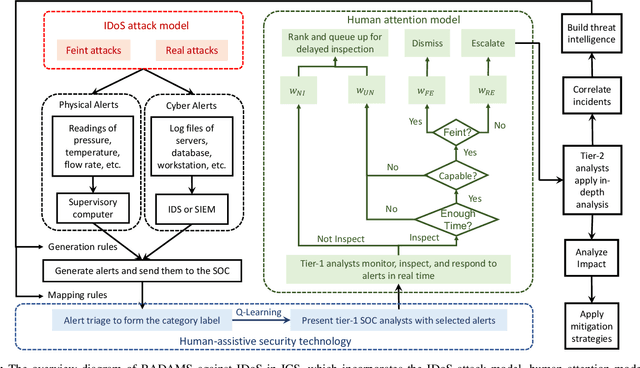
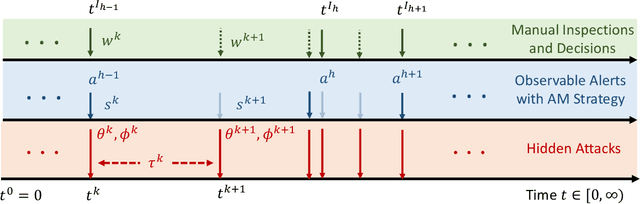
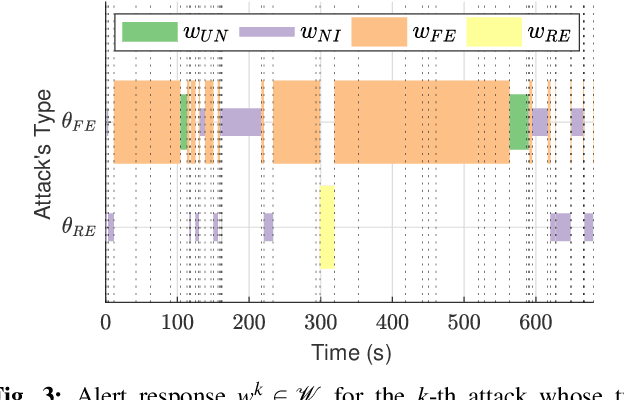
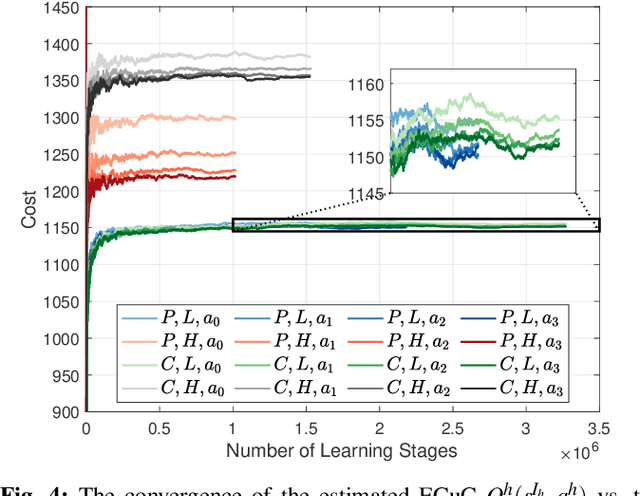
Attacks exploiting human attentional vulnerability have posed severe threats to cybersecurity. In this work, we identify and formally define a new type of proactive attentional attacks called Informational Denial-of-Service (IDoS) attacks that generate a large volume of feint attacks to overload human operators and hide real attacks among feints. We incorporate human factors (e.g., levels of expertise, stress, and efficiency) and empirical results (e.g., the Yerkes-Dodson law and the sunk cost fallacy) to model the operators' attention dynamics and their decision-making processes along with the real-time alert monitoring and inspection. To assist human operators in timely and accurately dismissing the feints and escalating the real attacks, we develop a Resilient and Adaptive Data-driven alert and Attention Management Strategy (RADAMS) that de-emphasizes alerts selectively based on the alerts' observable features. RADAMS uses reinforcement learning to achieve a customized and transferable design for various human operators and evolving IDoS attacks. The integrated modeling and theoretical analysis lead to the Product Principle of Attention (PPoA), fundamental limits, and the tradeoff among crucial human and economic factors. Experimental results corroborate that the proposed strategy outperforms the default strategy and can reduce the IDoS risk by as much as 20%. Besides, the strategy is resilient to large variations of costs, attack frequencies, and human attention capacities. We have recognized interesting phenomena such as attentional risk equivalency, attacker's dilemma, and the half-truth optimal attack strategy.
V2iFi: in-Vehicle Vital Sign Monitoring via Compact RF Sensing
Oct 28, 2021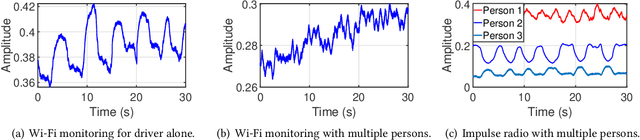

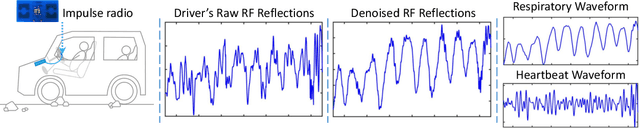
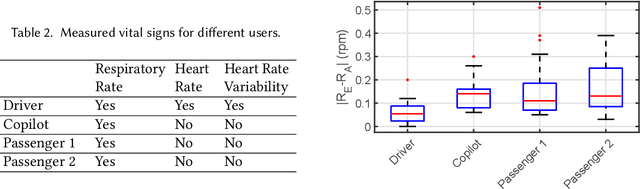
Given the significant amount of time people spend in vehicles, health issues under driving condition have become a major concern. Such issues may vary from fatigue, asthma, stroke, to even heart attack, yet they can be adequately indicated by vital signs and abnormal activities. Therefore, in-vehicle vital sign monitoring can help us predict and hence prevent these issues. Whereas existing sensor-based (including camera) methods could be used to detect these indicators, privacy concern and system complexity both call for a convenient yet effective and robust alternative. This paper aims to develop V2iFi, an intelligent system performing monitoring tasks using a COTS impulse radio mounted on the windshield. V2iFi is capable of reliably detecting driver's vital signs under driving condition and with the presence of passengers, thus allowing for potentially inferring corresponding health issues. Compared with prior work based on Wi-Fi CSI, V2iFi is able to distinguish reflected signals from multiple users, and hence provide finer-grained measurements under more realistic settings. We evaluate V2iFi both in lab environments and during real-life road tests; the results demonstrate that respiratory rate, heart rate, and heart rate variability can all be estimated accurately. Based on these estimation results, we further discuss how machine learning models can be applied on top of V2iFi so as to improve both physiological and psychological wellbeing in driving environments.
* 27 pages
The Portiloop: a deep learning-based open science tool for closed-loop brain stimulation
Jul 30, 2021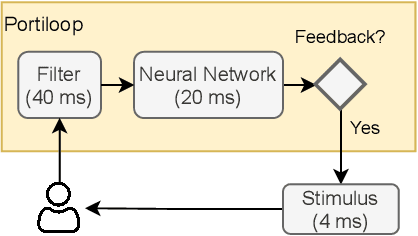
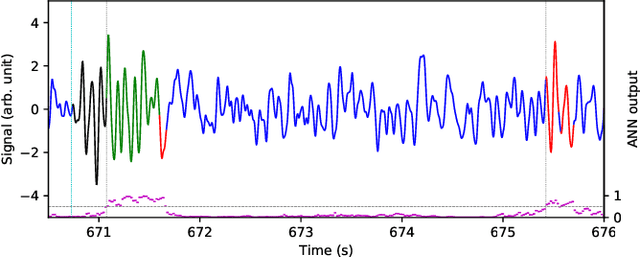
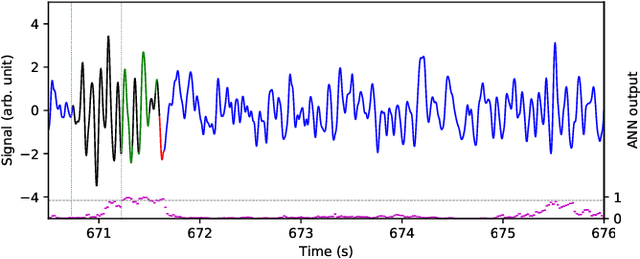
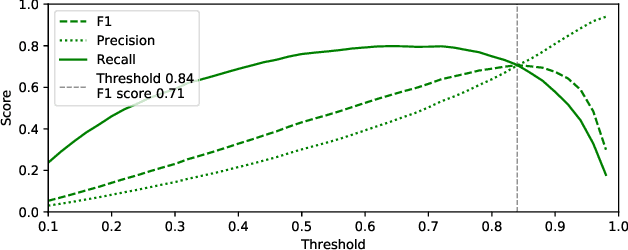
Electroencephalography (EEG) is a method of measuring the brain's electrical activity, using non-invasive scalp electrodes. In this article, we propose the Portiloop, a deep learning-based portable and low-cost device enabling the neuroscience community to capture EEG, process it in real time, detect patterns of interest, and respond with precisely-timed stimulation. The core of the Portiloop is a System on Chip composed of an Analog to Digital Converter (ADC) and a Field-Programmable Gate Array (FPGA). After being converted to digital by the ADC, the EEG signal is processed in the FPGA. The FPGA contains an ad-hoc Artificial Neural Network (ANN) with convolutional and recurrent units, directly implemented in hardware. The output of the ANN is then used to trigger the user-defined feedback. We use the Portiloop to develop a real-time sleep spindle stimulating application, as a case study. Sleep spindles are a specific type of transient oscillation ($\sim$2.5 s, 12-16 Hz) that are observed in EEG recordings, and are related to memory consolidation during sleep. We tested the Portiloop's capacity to detect and stimulate sleep spindles in real time using an existing database of EEG sleep recordings. With 71% for both precision and recall as compared with expert labels, the system is able to stimulate spindles within $\sim$300 ms of their onset, enabling experimental manipulation of early the entire spindle. The Portiloop can be extended to detect and stimulate other neural events in EEG. It is fully available to the research community as an open science project.
Ultrafast Focus Detection for Automated Microscopy
Aug 26, 2021
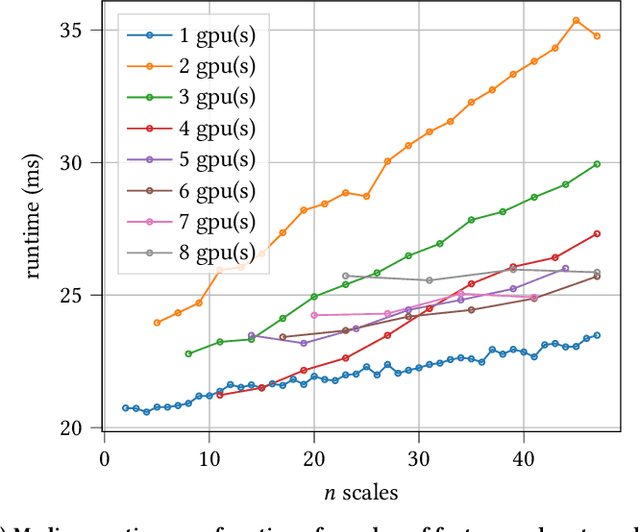
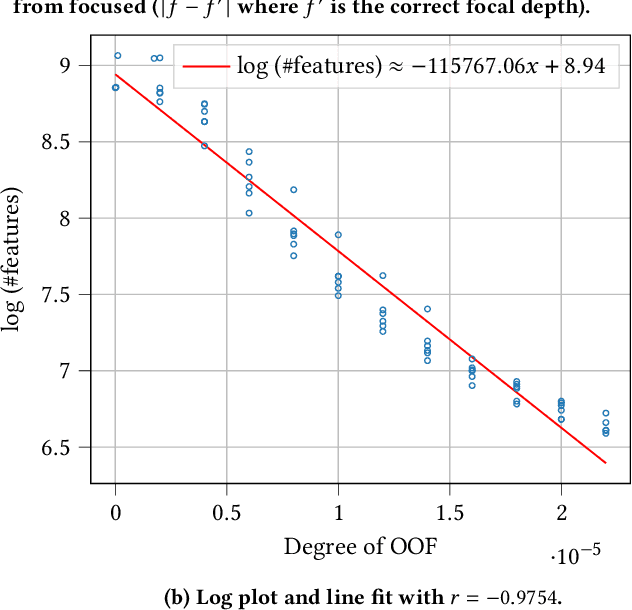
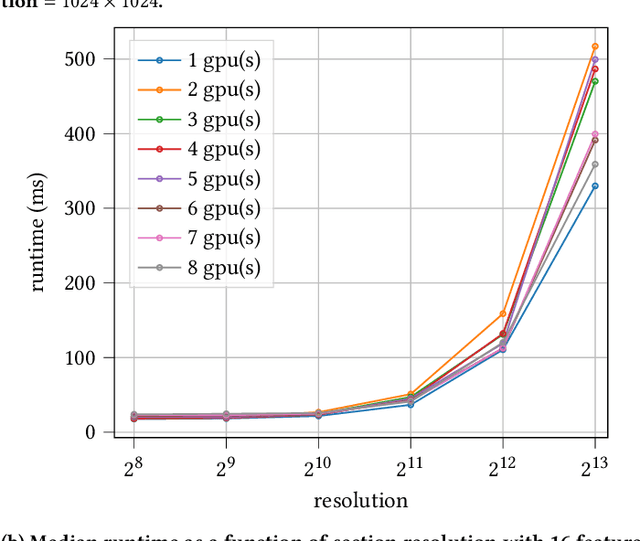
Recent advances in scientific instruments have resulted in dramatic increase in the volumes and velocities of data being generated in every-day laboratories. Scanning electron microscopy is one such example where technological advancements are now overwhelming scientists with critical data for montaging, alignment, and image segmentation -- key practices for many scientific domains, including, for example, neuroscience, where they are used to derive the anatomical relationships of the brain. These instruments now necessitate equally advanced computing resources and techniques to realize their full potential. Here we present a fast out-of-focus detection algorithm for electron microscopy images collected serially and demonstrate that it can be used to provide near-real time quality control for neurology research. Our technique, Multi-scale Histologic Feature Detection, adapts classical computer vision techniques and is based on detecting various fine-grained histologic features. We further exploit the inherent parallelism in the technique by employing GPGPU primitives in order to accelerate characterization. Tests are performed that demonstrate near-real-time detection of out-of-focus conditions. We deploy these capabilities as a funcX function and show that it can be applied as data are collected using an automated pipeline . We discuss extensions that enable scaling out to support multi-beam microscopes and integration with existing focus systems for purposes of implementing auto-focus.
Incorporating Reachability Knowledge into a Multi-Spatial Graph Convolution Based Seq2Seq Model for Traffic Forecasting
Jul 04, 2021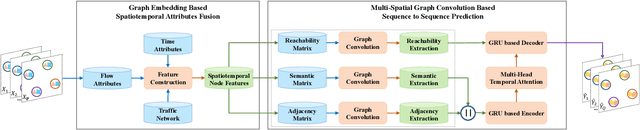
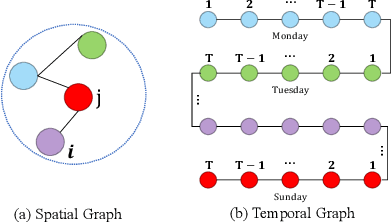
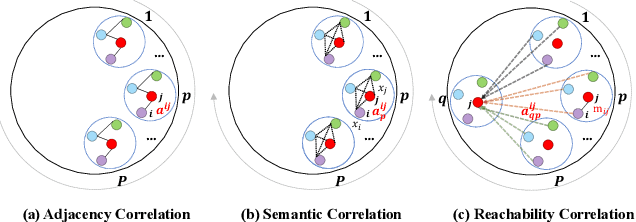
Accurate traffic state prediction is the foundation of transportation control and guidance. It is very challenging due to the complex spatiotemporal dependencies in traffic data. Existing works cannot perform well for multi-step traffic prediction that involves long future time period. The spatiotemporal information dilution becomes serve when the time gap between input step and predicted step is large, especially when traffic data is not sufficient or noisy. To address this issue, we propose a multi-spatial graph convolution based Seq2Seq model. Our main novelties are three aspects: (1) We enrich the spatiotemporal information of model inputs by fusing multi-view features (time, location and traffic states) (2) We build multiple kinds of spatial correlations based on both prior knowledge and data-driven knowledge to improve model performance especially in insufficient or noisy data cases. (3) A spatiotemporal attention mechanism based on reachability knowledge is novelly designed to produce high-level features fed into decoder of Seq2Seq directly to ease information dilution. Our model is evaluated on two real world traffic datasets and achieves better performance than other competitors.
CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms
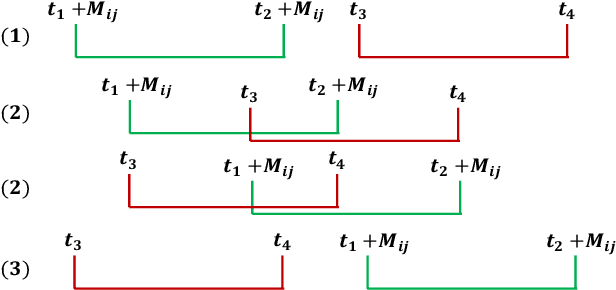
Nov 05, 2021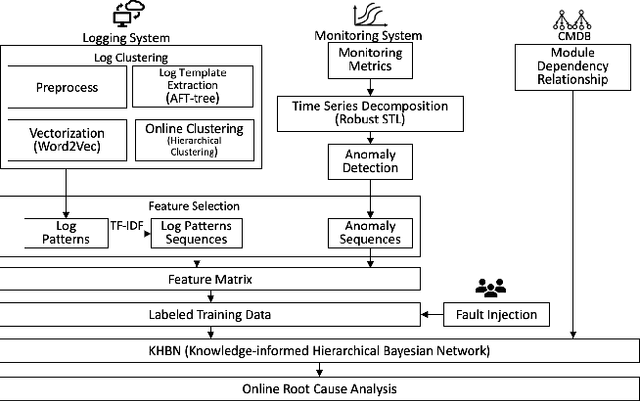
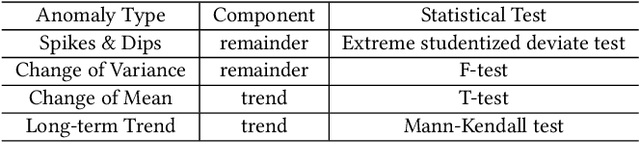
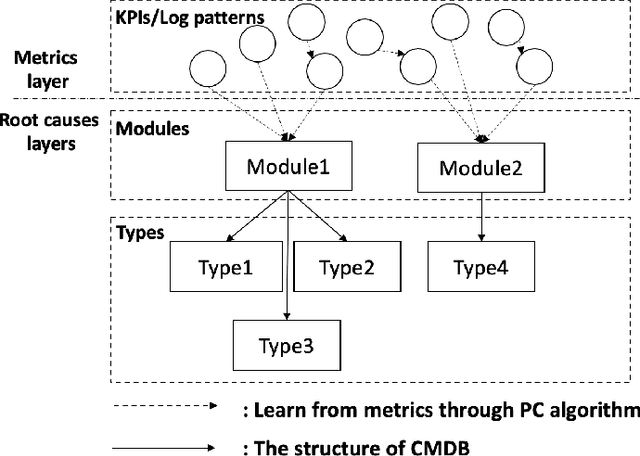
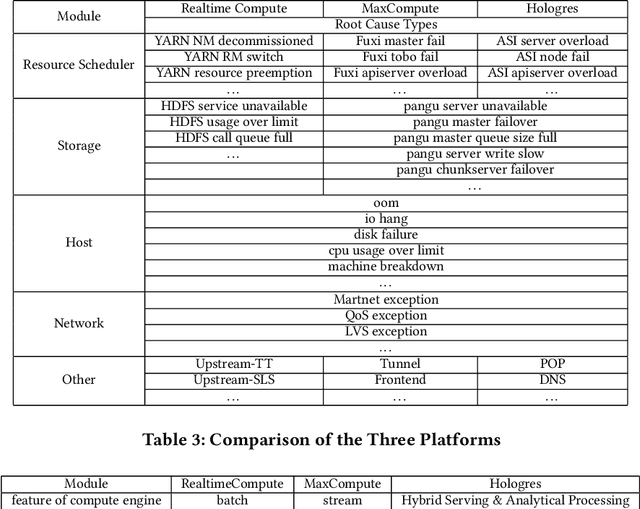
As business of Alibaba expands across the world among various industries, higher standards are imposed on the service quality and reliability of big data cloud computing platforms which constitute the infrastructure of Alibaba Cloud. However, root cause analysis in these platforms is non-trivial due to the complicated system architecture. In this paper, we propose a root cause analysis framework called CloudRCA which makes use of heterogeneous multi-source data including Key Performance Indicators (KPIs), logs, as well as topology, and extracts important features via state-of-the-art anomaly detection and log analysis techniques. The engineered features are then utilized in a Knowledge-informed Hierarchical Bayesian Network (KHBN) model to infer root causes with high accuracy and efficiency. Ablation study and comprehensive experimental comparisons demonstrate that, compared to existing frameworks, CloudRCA 1) consistently outperforms existing approaches in f1-score across different cloud systems; 2) can handle novel types of root causes thanks to the hierarchical structure of KHBN; 3) performs more robustly with respect to algorithmic configurations; and 4) scales more favorably in the data and feature sizes. Experiments also show that a cross-platform transfer learning mechanism can be adopted to further improve the accuracy by more than 10\%. CloudRCA has been integrated into the diagnosis system of Alibaba Cloud and employed in three typical cloud computing platforms including MaxCompute, Realtime Compute and Hologres. It saves Site Reliability Engineers (SREs) more than $20\%$ in the time spent on resolving failures in the past twelve months and improves service reliability significantly.
* Accepted by CIKM 2021; 10 pages, 3 figures, 12 tables