 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reliable Real Time Ball Tracking for Robot Table Tennis
Aug 20, 2019

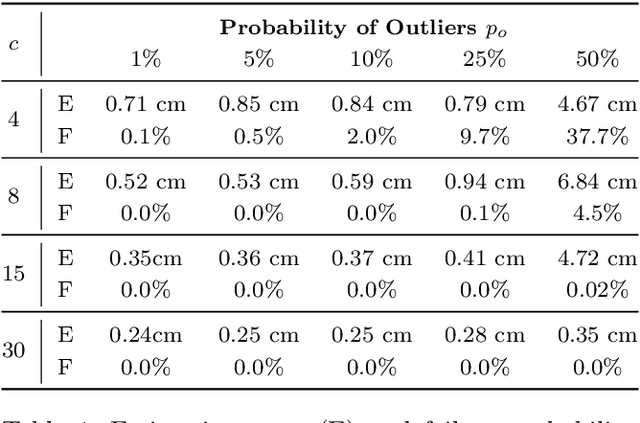


Robot table tennis systems require a vision system that can track the ball position with low latency and high sampling rate. Altering the ball to simplify the tracking using for instance infrared coating changes the physics of the ball trajectory. As a result, table tennis systems use custom tracking systems to track the ball based on heuristic algorithms respecting the real time constrains applied to RGB images captured with a set of cameras. However, these heuristic algorithms often report erroneous ball positions, and the table tennis policies typically need to incorporate additional heuristics to detect and possibly correct outliers. In this paper, we propose a vision system for object detection and tracking that focus on reliability while providing real time performance. Our assumption is that by using multiple cameras, we can find and discard the errors obtained in the object detection phase by checking for consistency with the positions reported by other cameras. We provide an open source implementation of the proposed tracking system to simplify future research in robot table tennis or related tracking applications with strong real time requirements. We evaluate the proposed system thoroughly in simulation and in the real system, outperforming previous work. Furthermore, we show that the accuracy and robustness of the proposed system increases as more cameras are added. Finally, we evaluate the table tennis playing performance of an existing method in the real robot using the proposed vision system. We measure a slight increase in performance compared to a previous vision system even after removing all the heuristics previously present to filter out erroneous ball observations.
Deployment Optimization for Shared e-Mobility Systems with Multi-agent Deep Neural Search
Nov 03, 2021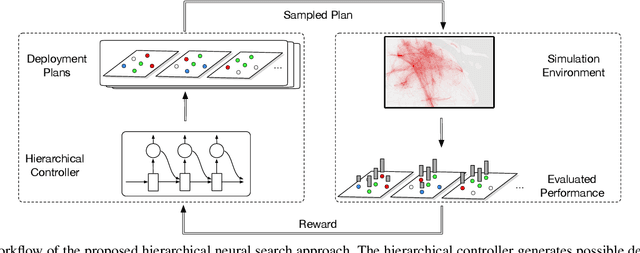
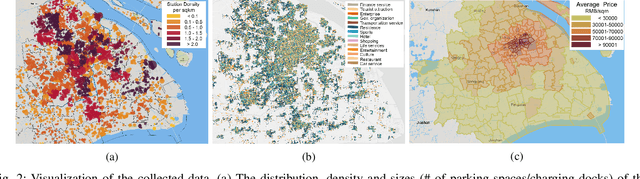
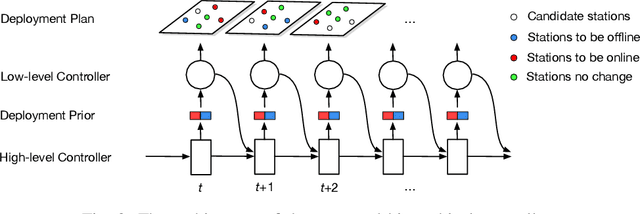
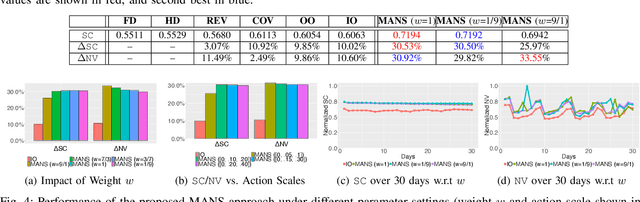
Shared e-mobility services have been widely tested and piloted in cities across the globe, and already woven into the fabric of modern urban planning. This paper studies a practical yet important problem in those systems: how to deploy and manage their infrastructure across space and time, so that the services are ubiquitous to the users while sustainable in profitability. However, in real-world systems evaluating the performance of different deployment strategies and then finding the optimal plan is prohibitively expensive, as it is often infeasible to conduct many iterations of trial-and-error. We tackle this by designing a high-fidelity simulation environment, which abstracts the key operation details of the shared e-mobility systems at fine-granularity, and is calibrated using data collected from the real-world. This allows us to try out arbitrary deployment plans to learn the optimal given specific context, before actually implementing any in the real-world systems. In particular, we propose a novel multi-agent neural search approach, in which we design a hierarchical controller to produce tentative deployment plans. The generated deployment plans are then tested using a multi-simulation paradigm, i.e., evaluated in parallel, where the results are used to train the controller with deep reinforcement learning. With this closed loop, the controller can be steered to have higher probability of generating better deployment plans in future iterations. The proposed approach has been evaluated extensively in our simulation environment, and experimental results show that it outperforms baselines e.g., human knowledge, and state-of-the-art heuristic-based optimization approaches in both service coverage and net revenue.
Masks Fusion with Multi-Target Learning For Speech Enhancement
Sep 28, 2021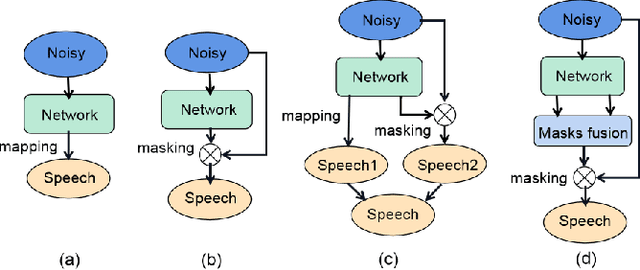
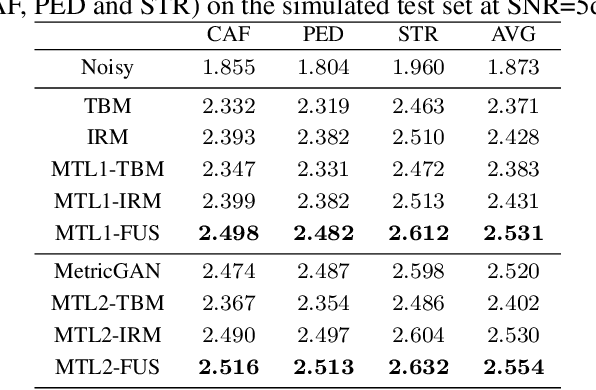
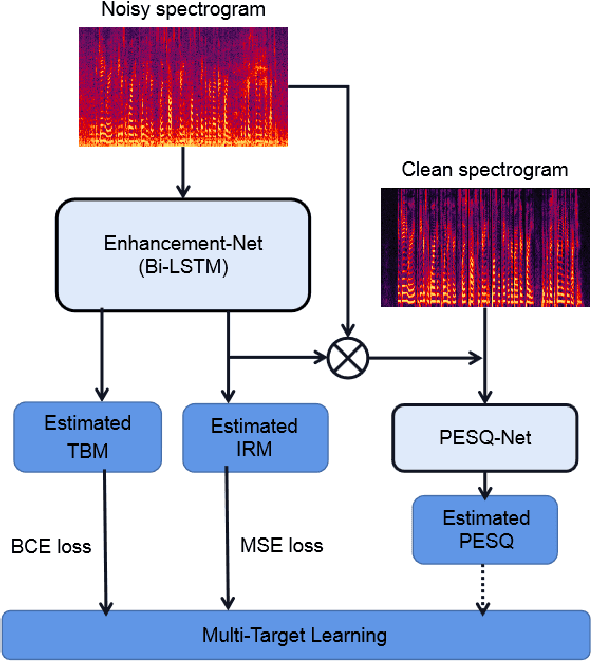
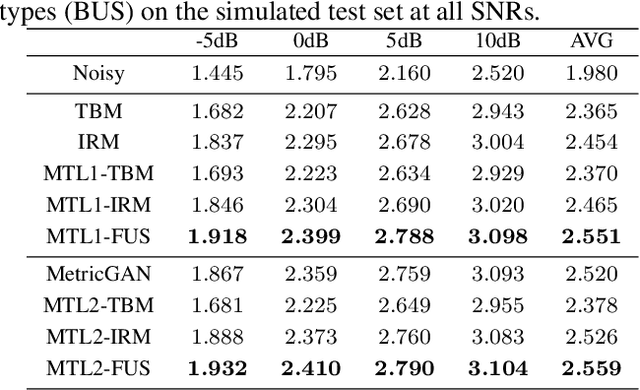
Recently, deep neural network (DNN) based time-frequency (T-F) mask estimation has shown remarkable effectiveness for speech enhancement. Typically, a single T-F mask is first estimated based on DNN and then used to mask the spectrogram of noisy speech in an order to suppress the noise. This work proposes a multi-mask fusion method for speech enhancement. It simultaneously estimates two complementary masks, e.g., ideal ratio mask (IRM) and target binary mask (TBM), and then fuse them to obtain a refined mask for speech enhancement. The advantage of the new method is twofold. First, simultaneously estimating multiple complementary masks brings benefit endowed by multi-target learning. Second, multi-mask fusion can exploit the complementarity of multiple masks to boost the performance of speech enhancement. Experimental results show that the proposed method can achieve significant PESQ improvement and reduce the recognition error rate of back-end over traditional masking-based methods. Code is available at https://github.com/lc-zhou/mask-fusion.
Large-scale, real-time visual-inertial localization revisited
Jun 30, 2019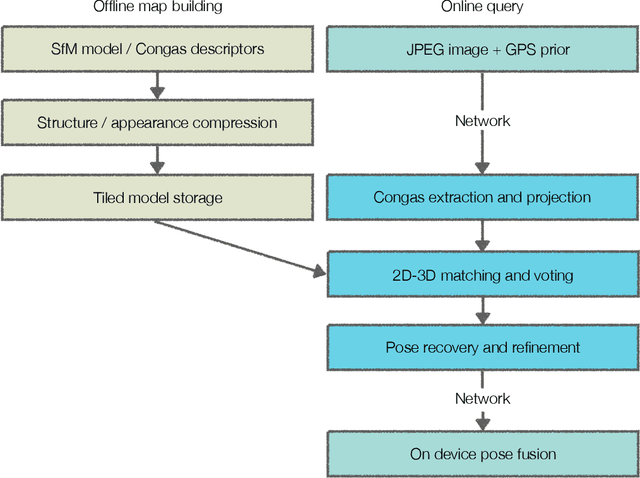

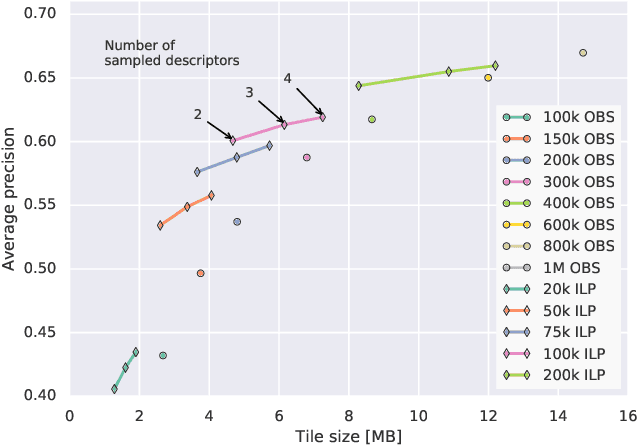
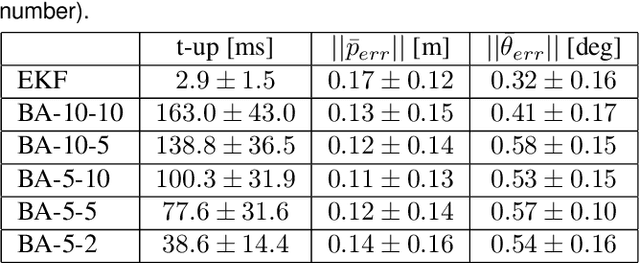
The overarching goals in image-based localization are scale, robustness and speed. In recent years, approaches based on local features and sparse 3D point-cloud models have both dominated the benchmarks and seen successful realworld deployment. They enable applications ranging from robot navigation, autonomous driving, virtual and augmented reality to device geo-localization. Recently end-to-end learned localization approaches have been proposed which show promising results on small scale datasets. However the positioning accuracy, scalability, latency and compute & storage requirements of these approaches remain open challenges. We aim to deploy localization at global-scale where one thus relies on methods using local features and sparse 3D models. Our approach spans from offline model building to real-time client-side pose fusion. The system compresses appearance and geometry of the scene for efficient model storage and lookup leading to scalability beyond what what has been previously demonstrated. It allows for low-latency localization queries and efficient fusion run in real-time on mobile platforms by combining server-side localization with real-time visual-inertial-based camera pose tracking. In order to further improve efficiency we leverage a combination of priors, nearest neighbor search, geometric match culling and a cascaded pose candidate refinement step. This combination outperforms previous approaches when working with large scale models and allows deployment at unprecedented scale. We demonstrate the effectiveness of our approach on a proof-of-concept system localizing 2.5 million images against models from four cities in different regions on the world achieving query latencies in the 200ms range.
Multistep traffic speed prediction: A deep learning based approach using latent space mapping considering spatio-temporal dependencies
Nov 03, 2021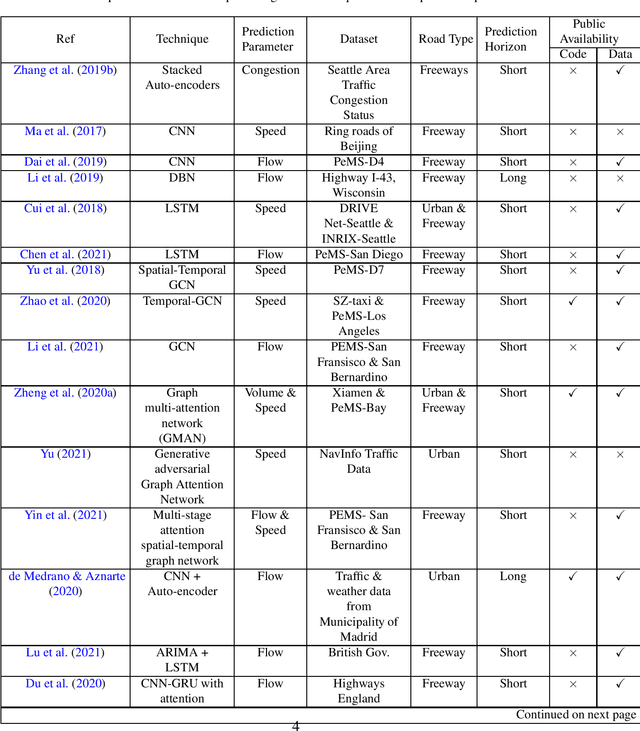
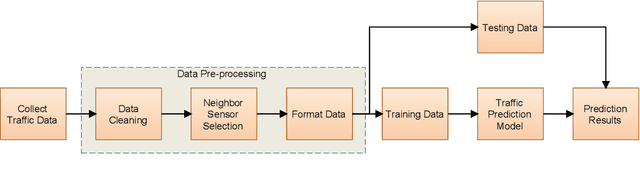
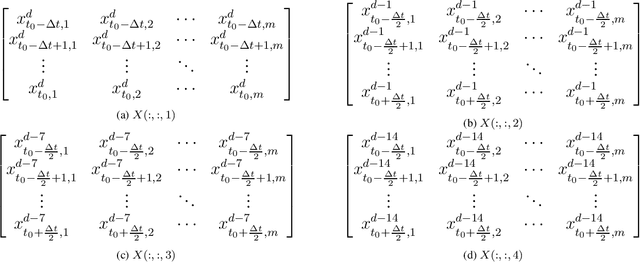
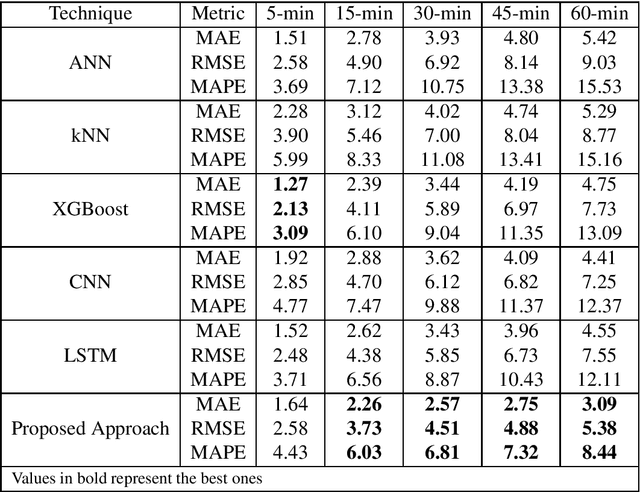
Traffic management in a city has become a major problem due to the increasing number of vehicles on roads. Intelligent Transportation System (ITS) can help the city traffic managers to tackle the problem by providing accurate traffic forecasts. For this, ITS requires a reliable traffic prediction algorithm that can provide accurate traffic prediction at multiple time steps based on past and current traffic data. In recent years, a number of different methods for traffic prediction have been proposed which have proved their effectiveness in terms of accuracy. However, most of these methods have either considered spatial information or temporal information only and overlooked the effect of other. In this paper, to address the above problem a deep learning based approach has been developed using both the spatial and temporal dependencies. To consider spatio-temporal dependencies, nearby road sensors at a particular instant are selected based on the attributes like traffic similarity and distance. Two pre-trained deep auto-encoders were cross-connected using the concept of latent space mapping and the resultant model was trained using the traffic data from the selected nearby sensors as input. The proposed deep learning based approach was trained using the real-world traffic data collected from loop detector sensors installed on different highways of Los Angeles and Bay Area. The traffic data is freely available from the web portal of the California Department of Transportation Performance Measurement System (PeMS). The effectiveness of the proposed approach was verified by comparing it with a number of machine/deep learning approaches. It has been found that the proposed approach provides accurate traffic prediction results even for 60-min ahead prediction with least error than other techniques.
Deep Learning-based Frozen Section to FFPE Translation
Jul 27, 2021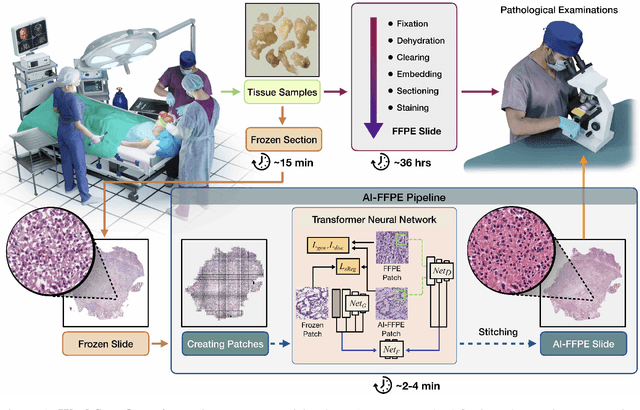
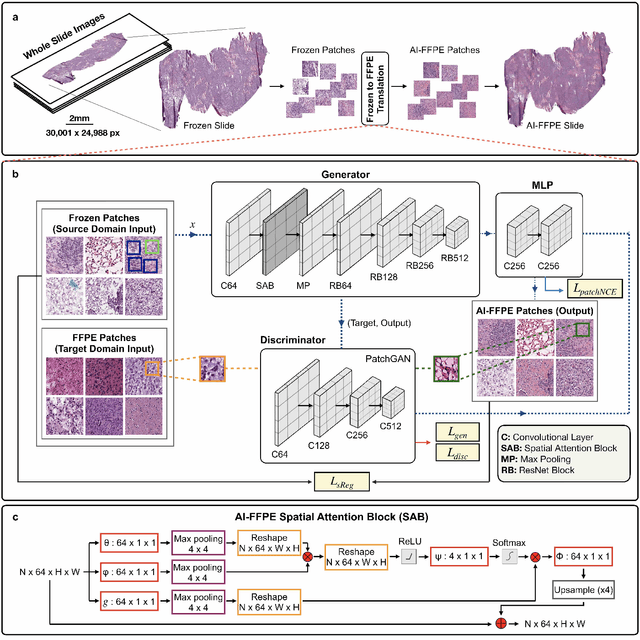
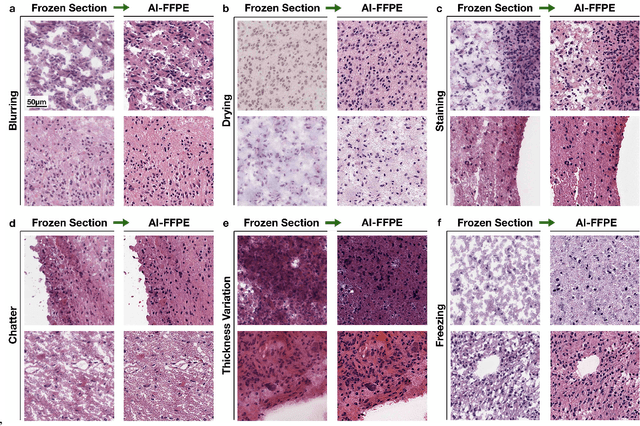
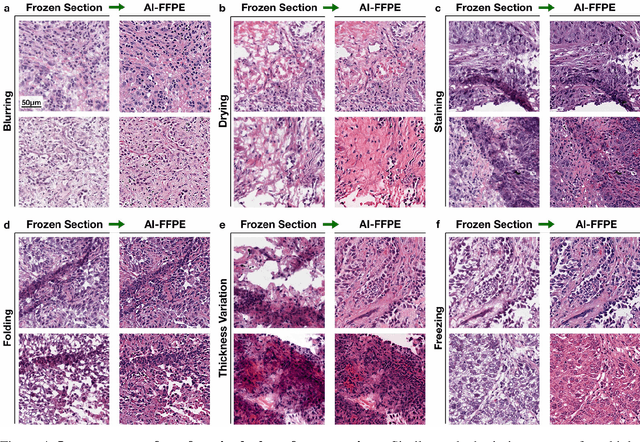
Frozen sectioning (FS) is the preparation method of choice for microscopic evaluation of tissues during surgical operations. The high speed of the procedure allows pathologists to rapidly assess the key microscopic features, such as tumour margins and malignant status to guide surgical decision-making and minimise disruptions to the course of the operation. However, FS is prone to introducing many misleading artificial structures (histological artefacts), such as nuclear ice crystals, compression, and cutting artefacts, hindering timely and accurate diagnostic judgement of the pathologist. Additional training and prolonged experience is often required to make highly effective and time-critical diagnosis on frozen sections. On the other hand, the gold standard tissue preparation technique of formalin-fixation and paraffin-embedding (FFPE) provides significantly superior image quality, but is a very time-consuming process (12-48 hours), making it unsuitable for intra-operative use. In this paper, we propose an artificial intelligence (AI) method that improves FS image quality by computationally transforming frozen-sectioned whole-slide images (FS-WSIs) into whole-slide FFPE-style images in minutes. AI-FFPE rectifies FS artefacts with the guidance of an attention mechanism that puts a particular emphasis on artefacts while utilising a self-regularization mechanism established between FS input image and synthesized FFPE-style image that preserves clinically relevant features. As a result, AI-FFPE method successfully generates FFPE-style images without significantly extending tissue processing time and consequently improves diagnostic accuracy. We demonstrate the efficacy of AI-FFPE on lung and brain frozen sections using a variety of different qualitative and quantitative metrics including visual Turing tests from 20 board certified pathologists.
Neighborhood-Enhanced and Time-Aware Model for Session-based Recommendation
Oct 01, 2019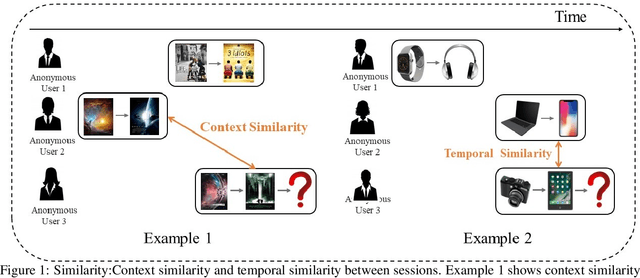
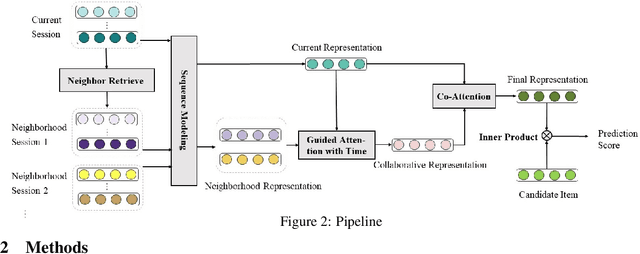
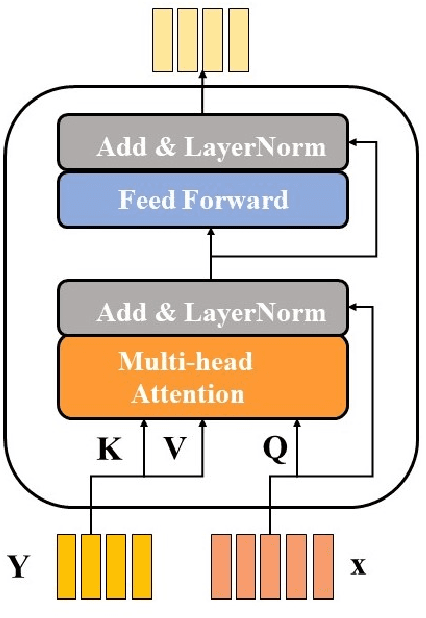
Session based recommendation has become one of the research hotpots in the field of recommendation systems due to its highly practical value.Previous deep learning methods mostly focus on the sequential characteristics within the current session,and neglect the context similarity and temporal similarity between sessions which contain abundant collaborative information.In this paper,we propose a novel neural networks framework,namely Neighborhood Enhanced and Time Aware Recommendation Machine(NETA) for session based recommendation. Firstly,we introduce an efficient neighborhood retrieve mechanism to find out similar sessions which includes collaborative information.Then we design a guided attention with time-aware mechanism to extract collaborative representation from neighborhood sessions.Especially,temporal recency between sessions is considered separately.Finally, we design a simple co-attention mechanism to determine the importance of complementary collaborative representation when predicting the next item.Extensive experiments conducted on two real-world datasets demonstrate the effectiveness of our proposed model.
Neural Circuit Synthesis from Specification Patterns
Jul 25, 2021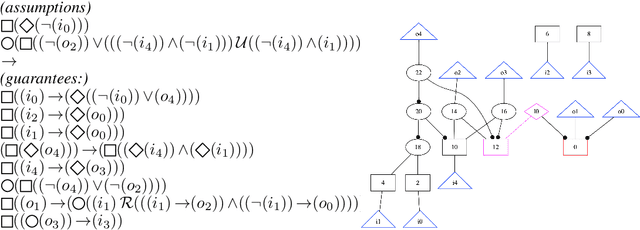

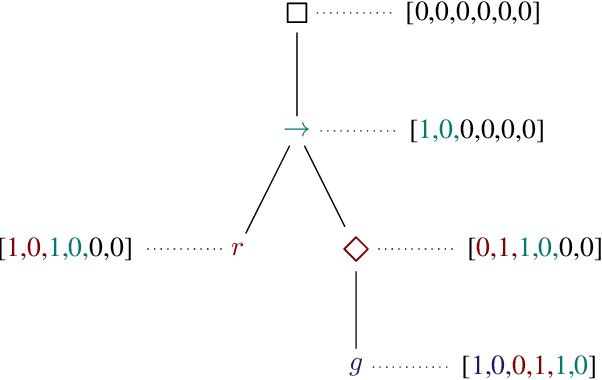

We train hierarchical Transformers on the task of synthesizing hardware circuits directly out of high-level logical specifications in linear-time temporal logic (LTL). The LTL synthesis problem is a well-known algorithmic challenge with a long history and an annual competition is organized to track the improvement of algorithms and tooling over time. New approaches using machine learning might open a lot of possibilities in this area, but suffer from the lack of sufficient amounts of training data. In this paper, we consider a method to generate large amounts of additional training data, i.e., pairs of specifications and circuits implementing them. We ensure that this synthetic data is sufficiently close to human-written specifications by mining common patterns from the specifications used in the synthesis competitions. We show that hierarchical Transformers trained on this synthetic data solve a significant portion of problems from the synthesis competitions, and even out-of-distribution examples from a recent case study.
Global Convergence of the ODE Limit for Online Actor-Critic Algorithms in Reinforcement Learning
Aug 19, 2021Actor-critic algorithms are widely used in reinforcement learning, but are challenging to mathematically analyze due to the online arrival of non-i.i.d. data samples. The distribution of the data samples dynamically changes as the model is updated, introducing a complex feedback loop between the data distribution and the reinforcement learning algorithm. We prove that, under a time rescaling, the online actor-critic algorithm with tabular parametrization converges to an ordinary differential equations (ODEs) as the number of updates becomes large. The proof first establishes the geometric ergodicity of the data samples under a fixed actor policy. Then, using a Poisson equation, we prove that the fluctuations of the data samples around a dynamic probability measure, which is a function of the evolving actor model, vanish as the number of updates become large. Once the ODE limit has been derived, we study its convergence properties using a two time-scale analysis which asymptotically de-couples the critic ODE from the actor ODE. The convergence of the critic to the solution of the Bellman equation and the actor to the optimal policy are proven. In addition, a convergence rate to this global minimum is also established. Our convergence analysis holds under specific choices for the learning rates and exploration rates in the actor-critic algorithm, which could provide guidance for the implementation of actor-critic algorithms in practice.
Improving Span Representation for Domain-adapted Coreference Resolution
Sep 20, 2021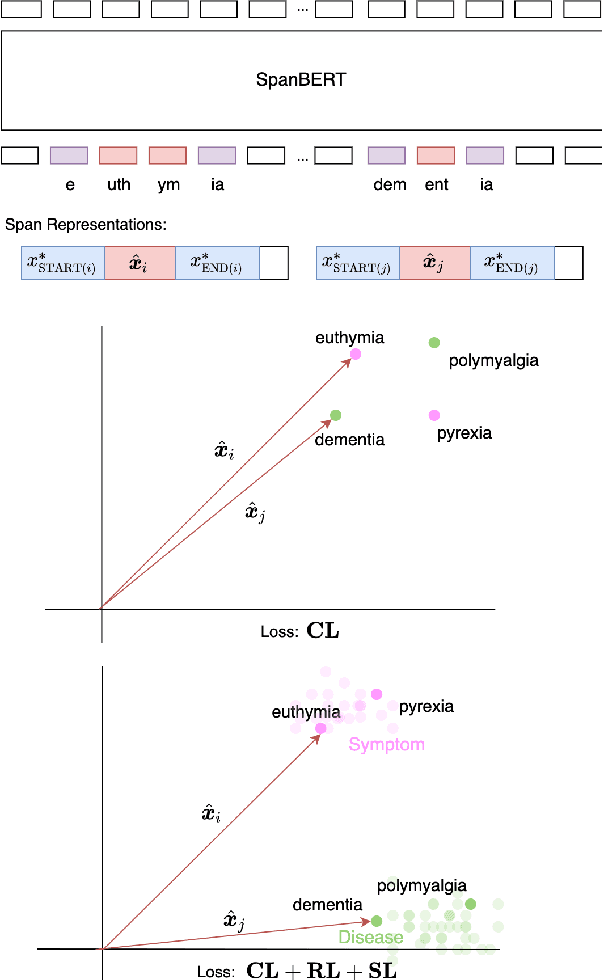
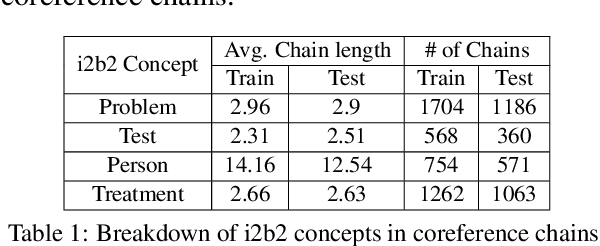

Recent work has shown fine-tuning neural coreference models can produce strong performance when adapting to different domains. However, at the same time, this can require a large amount of annotated target examples. In this work, we focus on supervised domain adaptation for clinical notes, proposing the use of concept knowledge to more efficiently adapt coreference models to a new domain. We develop methods to improve the span representations via (1) a retrofitting loss to incentivize span representations to satisfy a knowledge-based distance function and (2) a scaffolding loss to guide the recovery of knowledge from the span representation. By integrating these losses, our model is able to improve our baseline precision and F-1 score. In particular, we show that incorporating knowledge with end-to-end coreference models results in better performance on the most challenging, domain-specific spans.