 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PhyloTransformer: A Discriminative Model for Mutation Prediction Based on a Multi-head Self-attention Mechanism
Nov 03, 2021
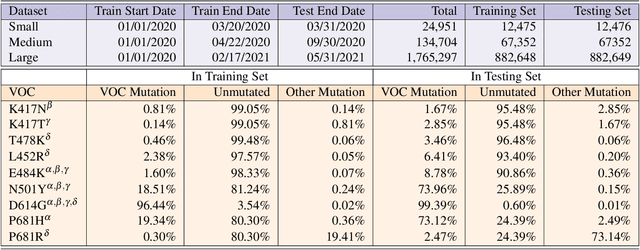
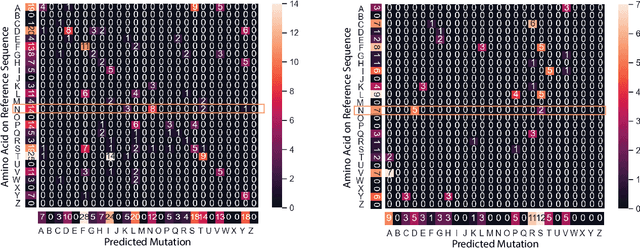
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has caused an ongoing pandemic infecting 219 million people as of 10/19/21, with a 3.6% mortality rate. Natural selection can generate favorable mutations with improved fitness advantages; however, the identified coronaviruses may be the tip of the iceberg, and potentially more fatal variants of concern (VOCs) may emerge over time. Understanding the patterns of emerging VOCs and forecasting mutations that may lead to gain of function or immune escape is urgently required. Here we developed PhyloTransformer, a Transformer-based discriminative model that engages a multi-head self-attention mechanism to model genetic mutations that may lead to viral reproductive advantage. In order to identify complex dependencies between the elements of each input sequence, PhyloTransformer utilizes advanced modeling techniques, including a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+) from Performer, and the Masked Language Model (MLM) from Bidirectional Encoder Representations from Transformers (BERT). PhyloTransformer was trained with 1,765,297 genetic sequences retrieved from the Global Initiative for Sharing All Influenza Data (GISAID) database. Firstly, we compared the prediction accuracy of novel mutations and novel combinations using extensive baseline models; we found that PhyloTransformer outperformed every baseline method with statistical significance. Secondly, we examined predictions of mutations in each nucleotide of the receptor binding motif (RBM), and we found our predictions were precise and accurate. Thirdly, we predicted modifications of N-glycosylation sites to identify mutations associated with altered glycosylation that may be favored during viral evolution. We anticipate that PhyloTransformer may guide proactive vaccine design for effective targeting of future SARS-CoV-2 variants.
Extreme Multi-label Learning for Semantic Matching in Product Search
Jun 23, 2021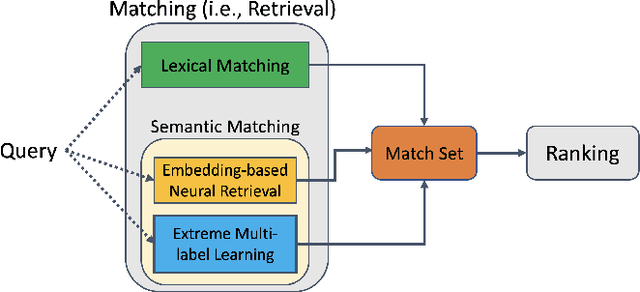

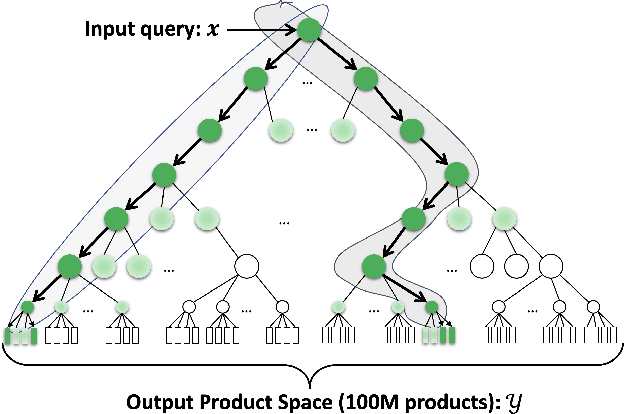
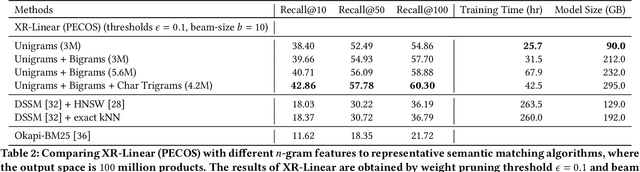
We consider the problem of semantic matching in product search: given a customer query, retrieve all semantically related products from a huge catalog of size 100 million, or more. Because of large catalog spaces and real-time latency constraints, semantic matching algorithms not only desire high recall but also need to have low latency. Conventional lexical matching approaches (e.g., Okapi-BM25) exploit inverted indices to achieve fast inference time, but fail to capture behavioral signals between queries and products. In contrast, embedding-based models learn semantic representations from customer behavior data, but the performance is often limited by shallow neural encoders due to latency constraints. Semantic product search can be viewed as an eXtreme Multi-label Classification (XMC) problem, where customer queries are input instances and products are output labels. In this paper, we aim to improve semantic product search by using tree-based XMC models where inference time complexity is logarithmic in the number of products. We consider hierarchical linear models with n-gram features for fast real-time inference. Quantitatively, our method maintains a low latency of 1.25 milliseconds per query and achieves a 65% improvement of Recall@100 (60.9% v.s. 36.8%) over a competing embedding-based DSSM model. Our model is robust to weight pruning with varying thresholds, which can flexibly meet different system requirements for online deployments. Qualitatively, our method can retrieve products that are complementary to existing product search system and add diversity to the match set.
Differentiable Multiple Shooting Layers
Jun 07, 2021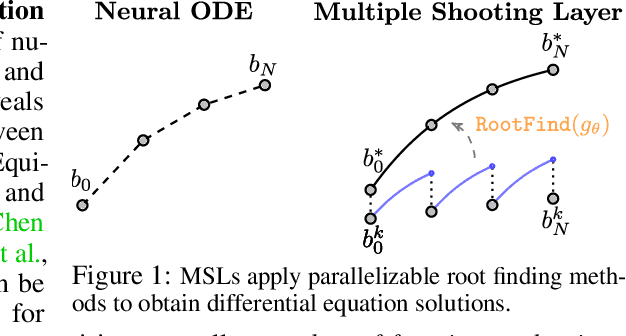
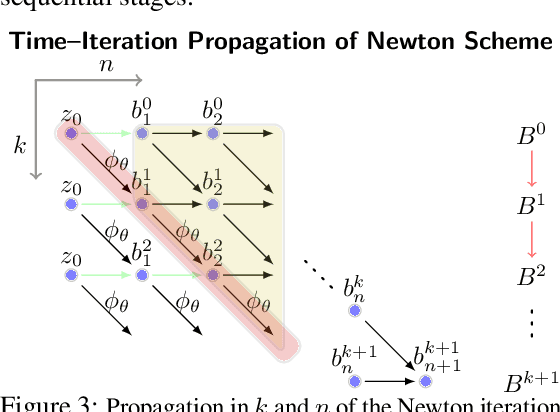
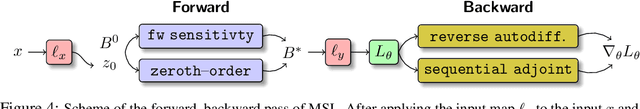

We detail a novel class of implicit neural models. Leveraging time-parallel methods for differential equations, Multiple Shooting Layers (MSLs) seek solutions of initial value problems via parallelizable root-finding algorithms. MSLs broadly serve as drop-in replacements for neural ordinary differential equations (Neural ODEs) with improved efficiency in number of function evaluations (NFEs) and wall-clock inference time. We develop the algorithmic framework of MSLs, analyzing the different choices of solution methods from a theoretical and computational perspective. MSLs are showcased in long horizon optimal control of ODEs and PDEs and as latent models for sequence generation. Finally, we investigate the speedups obtained through application of MSL inference in neural controlled differential equations (Neural CDEs) for time series classification of medical data.
Context-Aware Unsupervised Clustering for Person Search
Oct 04, 2021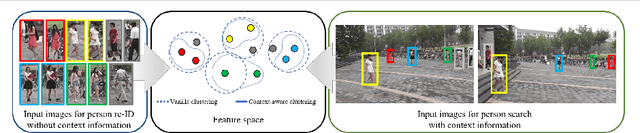
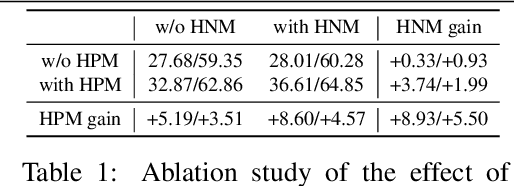
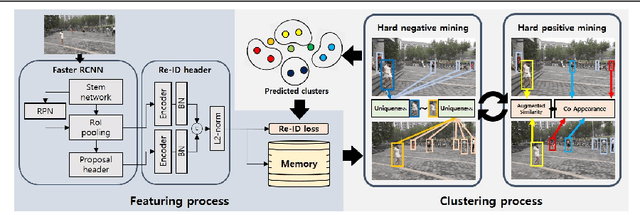
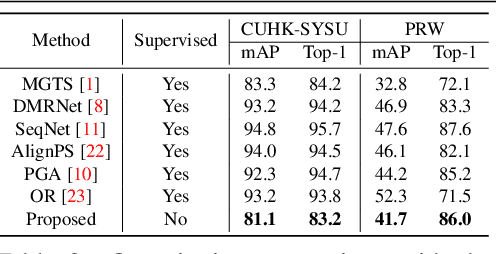
The existing person search methods use the annotated labels of person identities to train deep networks in a supervised manner that requires a huge amount of time and effort for human labeling. In this paper, we first introduce a novel framework of person search that is able to train the network in the absence of the person identity labels, and propose efficient unsupervised clustering methods to substitute the supervision process using annotated person identity labels. Specifically, we propose a hard negative mining scheme based on the uniqueness property that only a single person has the same identity to a given query person in each image. We also propose a hard positive mining scheme by using the contextual information of co-appearance that neighboring persons in one image tend to appear simultaneously in other images. The experimental results show that the proposed method achieves comparable performance to that of the state-of-the-art supervised person search methods, and furthermore outperforms the extended unsupervised person re-identification methods on the benchmark person search datasets.
Improving Span Representation for Domain-adapted Coreference Resolution
Sep 20, 2021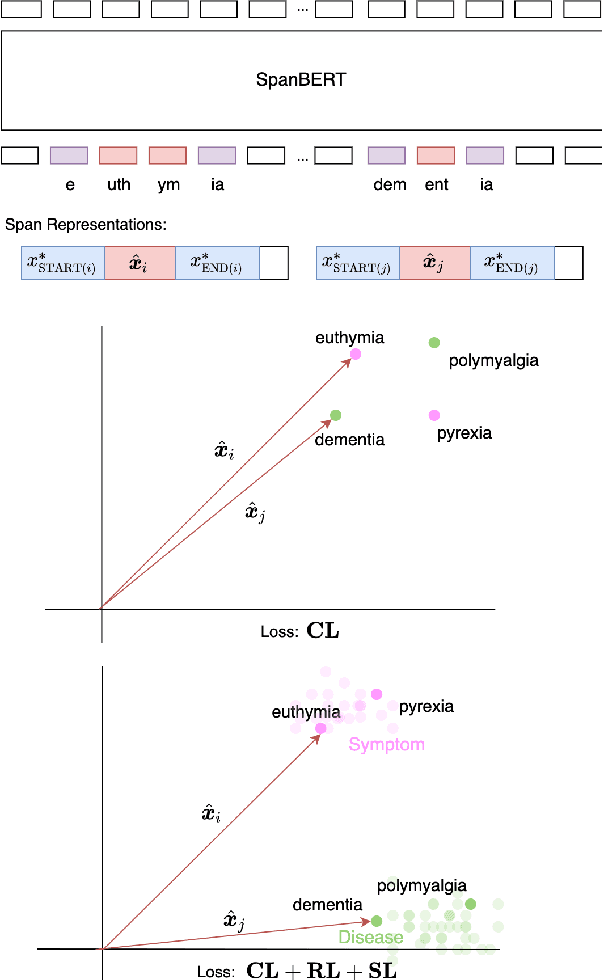
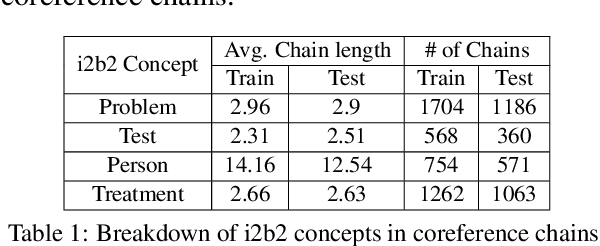

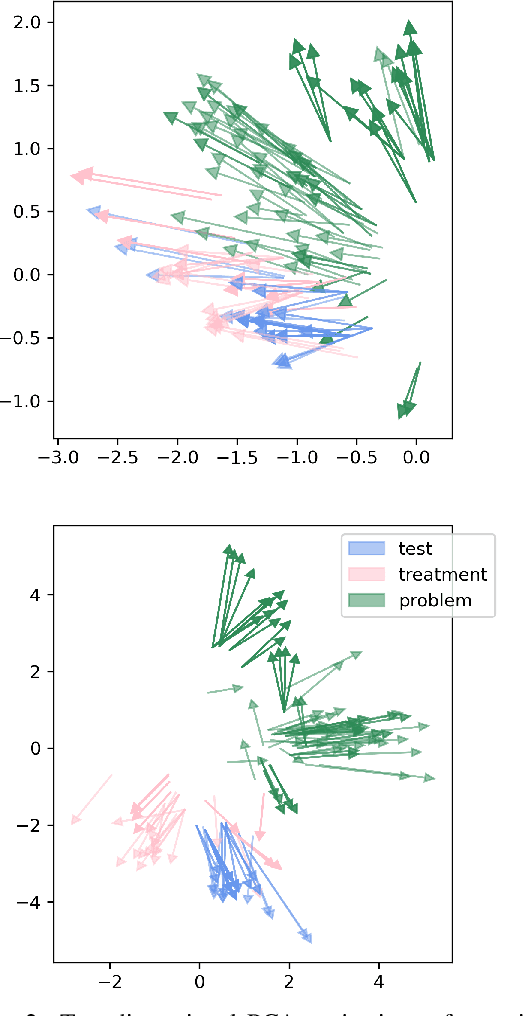
Recent work has shown fine-tuning neural coreference models can produce strong performance when adapting to different domains. However, at the same time, this can require a large amount of annotated target examples. In this work, we focus on supervised domain adaptation for clinical notes, proposing the use of concept knowledge to more efficiently adapt coreference models to a new domain. We develop methods to improve the span representations via (1) a retrofitting loss to incentivize span representations to satisfy a knowledge-based distance function and (2) a scaffolding loss to guide the recovery of knowledge from the span representation. By integrating these losses, our model is able to improve our baseline precision and F-1 score. In particular, we show that incorporating knowledge with end-to-end coreference models results in better performance on the most challenging, domain-specific spans.
Localization based on enhanced low frequency interaural level difference
Jun 17, 2021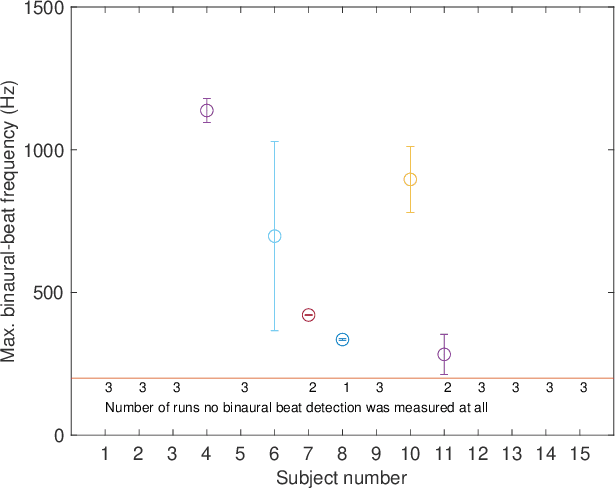
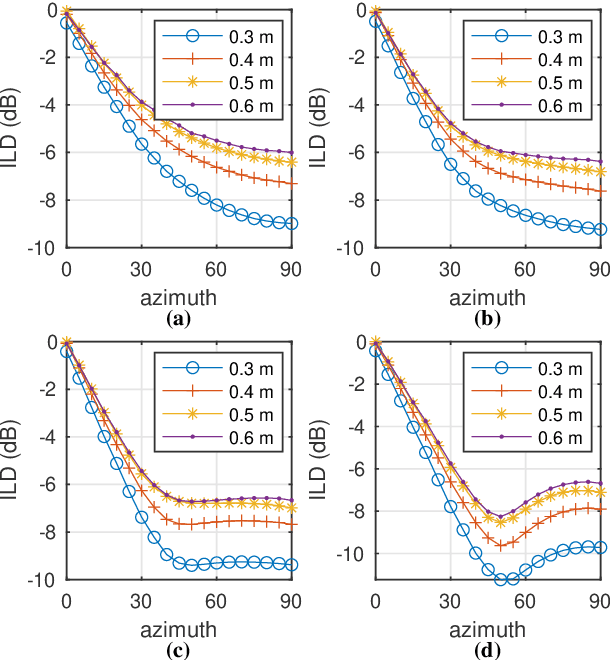
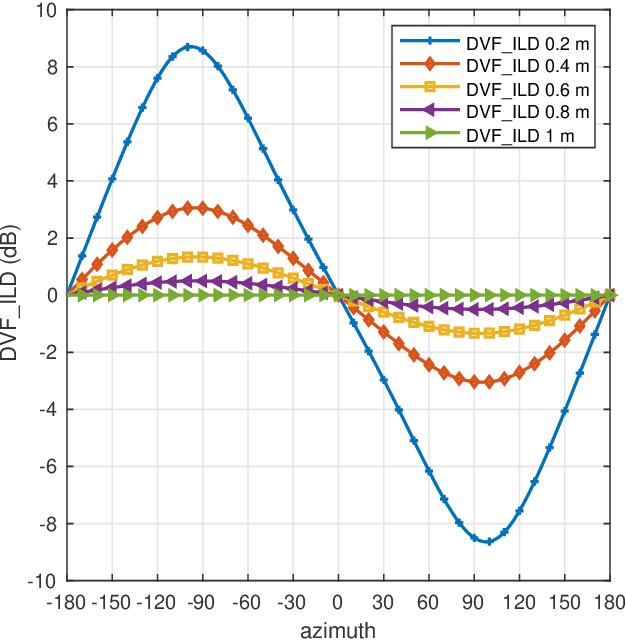
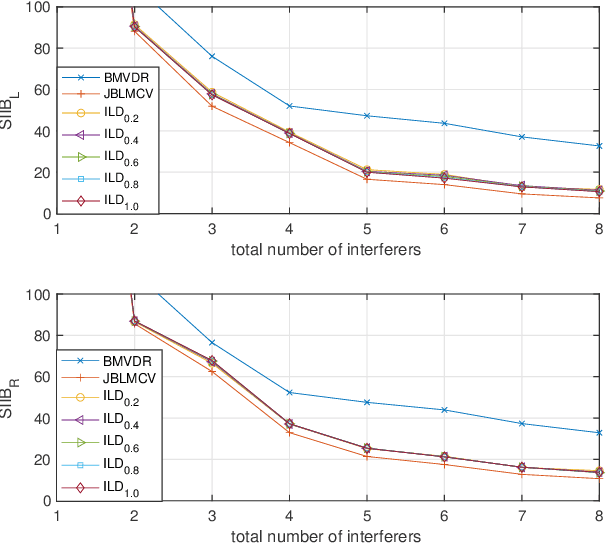
The processing of low-frequency interaural time differences is found to be problematic among hearing-impaired people. The current generation of beamformers does not consider this deficiency. In an attempt to tackle this issue, we propose to replace the inaudible interaural time differences in the low-frequency region with the interaural level differences. In addition, a beamformer is introduced and analyzed, which enhances the low-frequency interaural level differences of the sound sources using a near-field transformation. The proposed beamforming problem is relaxed to a convex problem using semi-definite relaxation. The instrumental analysis suggests that the low-frequency interaural level differences are enhanced without hindering the provided intelligibility. A psychoacoustic localization test is done using a listening experiment, which suggests that the replacement of time differences into level differences improves the localization performance of normal-hearing listeners for an anechoic scene but not for a reverberant scene.
Audio-to-Image Cross-Modal Generation
Sep 27, 2021

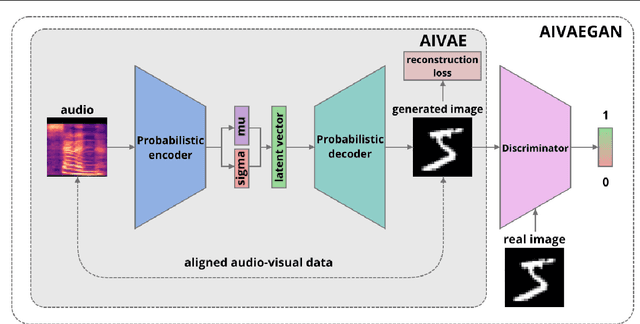

Cross-modal representation learning allows to integrate information from different modalities into one representation. At the same time, research on generative models tends to focus on the visual domain with less emphasis on other domains, such as audio or text, potentially missing the benefits of shared representations. Studies successfully linking more than one modality in the generative setting are rare. In this context, we verify the possibility to train variational autoencoders (VAEs) to reconstruct image archetypes from audio data. Specifically, we consider VAEs in an adversarial training framework in order to ensure more variability in the generated data and find that there is a trade-off between the consistency and diversity of the generated images - this trade-off can be governed by scaling the reconstruction loss up or down, respectively. Our results further suggest that even in the case when the generated images are relatively inconsistent (diverse), features that are critical for proper image classification are preserved.
Optimal Auction Design for the Gradual Procurement of Strategic Service Provider Agents
Oct 25, 2021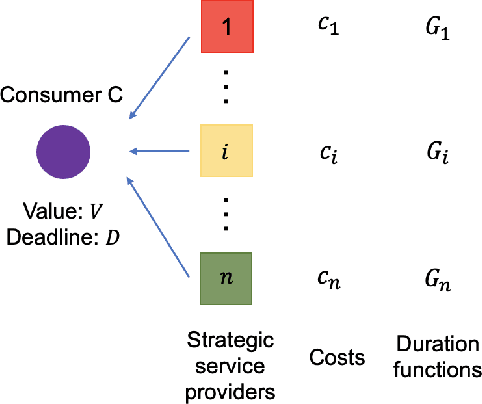
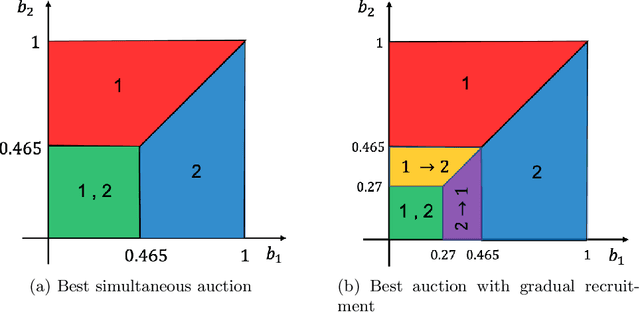
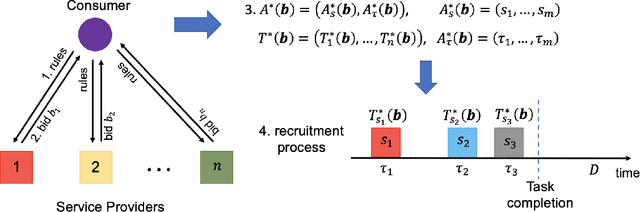
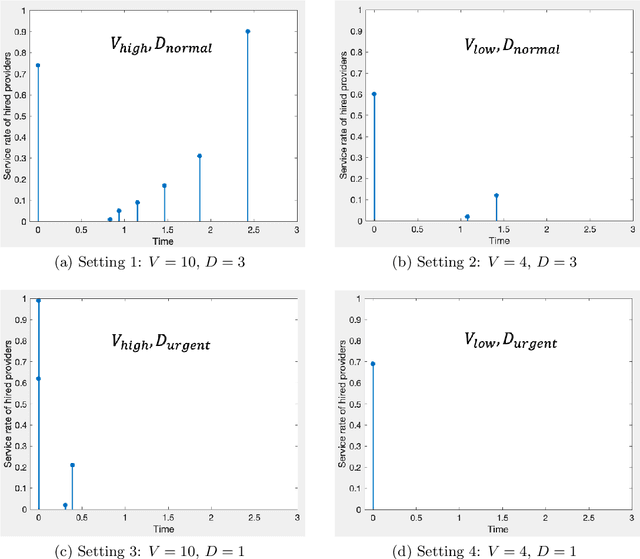
We consider an outsourcing problem where a software agent procures multiple services from providers with uncertain reliabilities to complete a computational task before a strict deadline. The service consumer requires a procurement strategy that achieves the optimal balance between success probability and invocation cost. However, the service providers are self-interested and may misrepresent their private cost information if it benefits them. For such settings, we design a novel procurement auction that provides the consumer with the highest possible revenue, while giving sufficient incentives to providers to tell the truth about their costs. This auction creates a contingent plan for gradual service procurement that suggests recruiting a new provider only when the success probability of the already hired providers drops below a time-dependent threshold. To make this auction incentive compatible, we propose a novel weighted threshold payment scheme which pays the minimum among all truthful mechanisms. Using the weighted payment scheme, we also design a low-complexity near-optimal auction that reduces the computational complexity of the optimal mechanism by 99% with only marginal performance loss (less than 1%). We demonstrate the effectiveness and strength of our proposed auctions through both game theoretical and numerical analysis. The experiment results confirm that the proposed auctions exhibit 59% improvement in performance over the current state-of-the-art, by increasing success probability up to 79% and reducing invocation cost by up to 11%.
A Survey of Open Source User Activity Traces with Applications to User Mobility Characterization and Modeling
Oct 15, 2021
The current state-of-the-art in user mobility research has extensively relied on open-source mobility traces captured from pedestrian and vehicular activity through a variety of communication technologies as users engage in a wide-range of applications, including connected healthcare, localization, social media, e-commerce, etc. Most of these traces are feature-rich and diverse, not only in the information they provide, but also in how they can be used and leveraged. This diversity poses two main challenges for researchers and practitioners who wish to make use of available mobility datasets. First, it is quite difficult to get a bird's eye view of the available traces without spending considerable time looking them up. Second, once they have found the traces, they still need to figure out whether the traces are adequate to their needs. The purpose of this survey is three-fold. It proposes a taxonomy to classify open-source mobility traces including their mobility mode, data source and collection technology. It then uses the proposed taxonomy to classify existing open-source mobility traces and finally, highlights three case studies using popular publicly available datasets to showcase how our taxonomy can tease out feature sets in traces to help determine their applicability to specific use-cases.
Class Incremental Online Streaming Learning
Oct 20, 2021
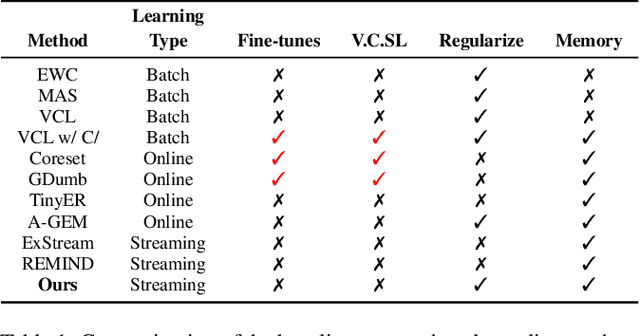

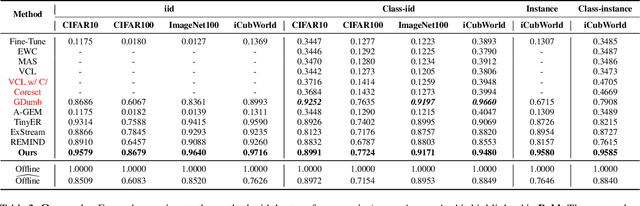
A wide variety of methods have been developed to enable lifelong learning in conventional deep neural networks. However, to succeed, these methods require a `batch' of samples to be available and visited multiple times during training. While this works well in a static setting, these methods continue to suffer in a more realistic situation where data arrives in \emph{online streaming manner}. We empirically demonstrate that the performance of current approaches degrades if the input is obtained as a stream of data with the following restrictions: $(i)$ each instance comes one at a time and can be seen only once, and $(ii)$ the input data violates the i.i.d assumption, i.e., there can be a class-based correlation. We propose a novel approach (CIOSL) for the class-incremental learning in an \emph{online streaming setting} to address these challenges. The proposed approach leverages implicit and explicit dual weight regularization and experience replay. The implicit regularization is leveraged via the knowledge distillation, while the explicit regularization incorporates a novel approach for parameter regularization by learning the joint distribution of the buffer replay and the current sample. Also, we propose an efficient online memory replay and replacement buffer strategy that significantly boosts the model's performance. Extensive experiments and ablation on challenging datasets show the efficacy of the proposed method.