 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fully Homomorphically Encrypted Deep Learning as a Service
Jul 26, 2021
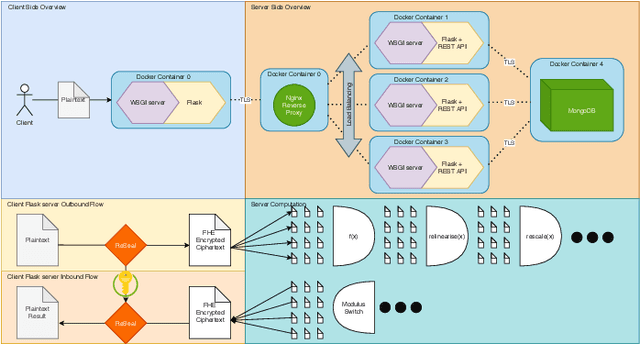
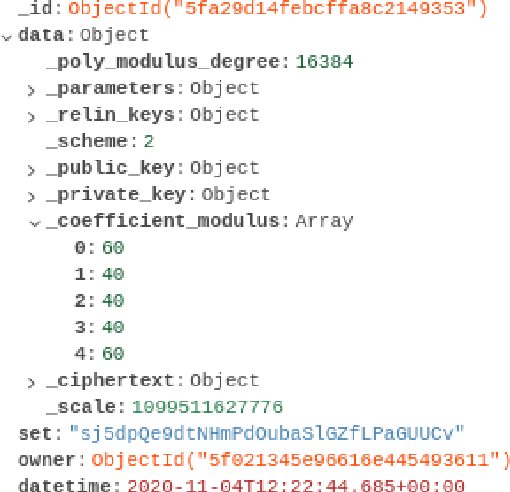
Fully Homomorphic Encryption (FHE) is a relatively recent advancement in the field of privacy-preserving technologies. FHE allows for the arbitrary depth computation of both addition and multiplication, and thus the application of abelian/polynomial equations, like those found in deep learning algorithms. This project investigates, derives, and proves how FHE with deep learning can be used at scale, with relatively low time complexity, the problems that such a system incurs, and mitigations/solutions for such problems. In addition, we discuss how this could have an impact on the future of data privacy and how it can enable data sharing across various actors in the agri-food supply chain, hence allowing the development of machine learning-based systems. Finally, we find that although FHE incurs a high spatial complexity cost, the time complexity is within expected reasonable bounds, while allowing for absolutely private predictions to be made, in our case for milk yield prediction.
Deployment Optimization for Shared e-Mobility Systems with Multi-agent Deep Neural Search
Nov 03, 2021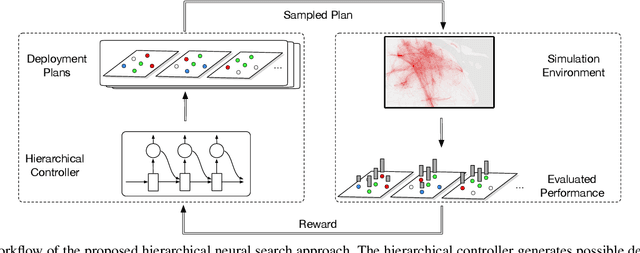
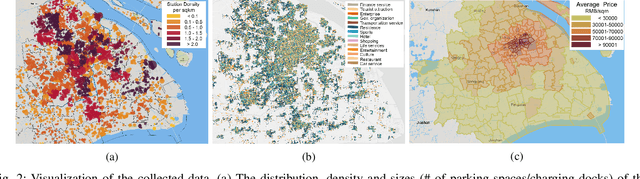
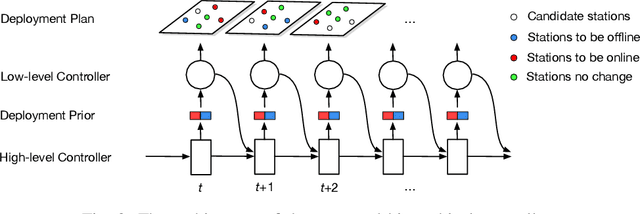
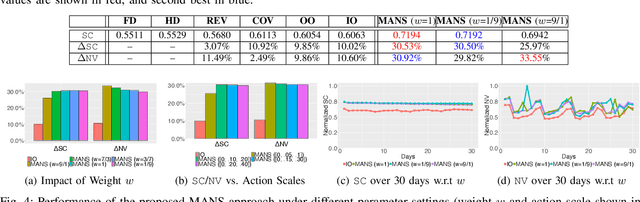
Shared e-mobility services have been widely tested and piloted in cities across the globe, and already woven into the fabric of modern urban planning. This paper studies a practical yet important problem in those systems: how to deploy and manage their infrastructure across space and time, so that the services are ubiquitous to the users while sustainable in profitability. However, in real-world systems evaluating the performance of different deployment strategies and then finding the optimal plan is prohibitively expensive, as it is often infeasible to conduct many iterations of trial-and-error. We tackle this by designing a high-fidelity simulation environment, which abstracts the key operation details of the shared e-mobility systems at fine-granularity, and is calibrated using data collected from the real-world. This allows us to try out arbitrary deployment plans to learn the optimal given specific context, before actually implementing any in the real-world systems. In particular, we propose a novel multi-agent neural search approach, in which we design a hierarchical controller to produce tentative deployment plans. The generated deployment plans are then tested using a multi-simulation paradigm, i.e., evaluated in parallel, where the results are used to train the controller with deep reinforcement learning. With this closed loop, the controller can be steered to have higher probability of generating better deployment plans in future iterations. The proposed approach has been evaluated extensively in our simulation environment, and experimental results show that it outperforms baselines e.g., human knowledge, and state-of-the-art heuristic-based optimization approaches in both service coverage and net revenue.
Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations
Oct 26, 2021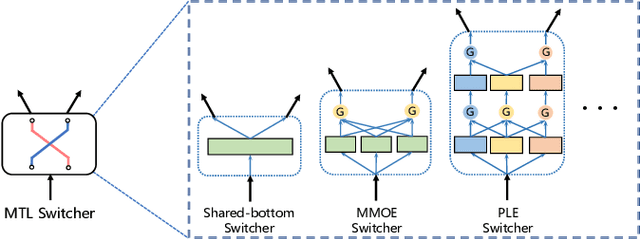
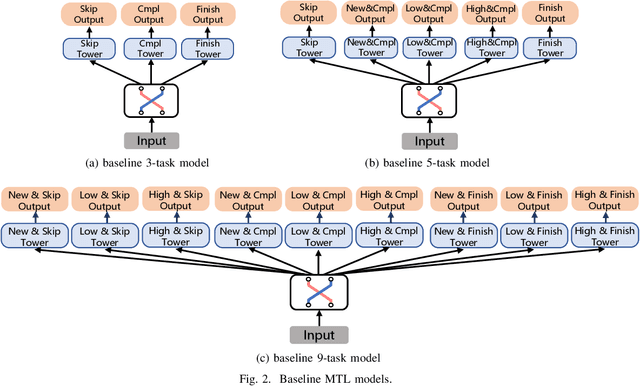
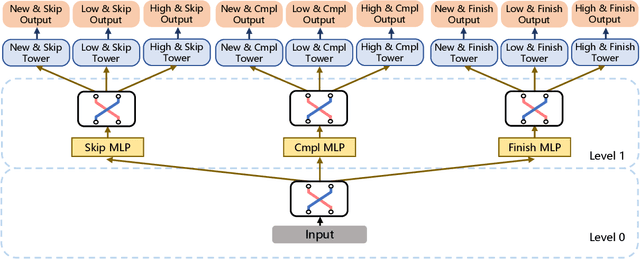
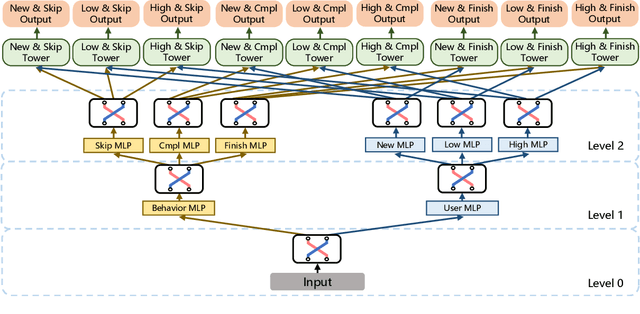
There has been many studies on improving the efficiency of shared learning in Multi-Task Learning(MTL). Previous work focused on the "micro" sharing perspective for a small number of tasks, while in Recommender Systems(RS) and other AI applications, there are often demands to model a large number of tasks with multi-dimensional task relations. For example, when using MTL to model various user behaviors in RS, if we differentiate new users and new items from old ones, there will be a cartesian product style increase of tasks with multi-dimensional relations. This work studies the "macro" perspective of shared learning network design and proposes a Multi-Faceted Hierarchical MTL model(MFH). MFH exploits the multi-dimension task relations with a nested hierarchical tree structure which maximizes the shared learning. We evaluate MFH and SOTA models in a large industry video platform of 10 billion samples and results show that MFH outperforms SOTA MTL models significantly in both offline and online evaluations across all user groups, especially remarkable for new users with an online increase of 9.1\% in app time per user and 1.85\% in next-day retention rate. MFH now has been deployed in a large scale online video recommender system. MFH is especially beneficial to the cold-start problems in RS where new users and new items often suffer from a "local overfitting" phenomenon. However, the idea is actually generic and widely applicable to other MTL scenarios.
Modality-Guided Subnetwork for Salient Object Detection
Oct 10, 2021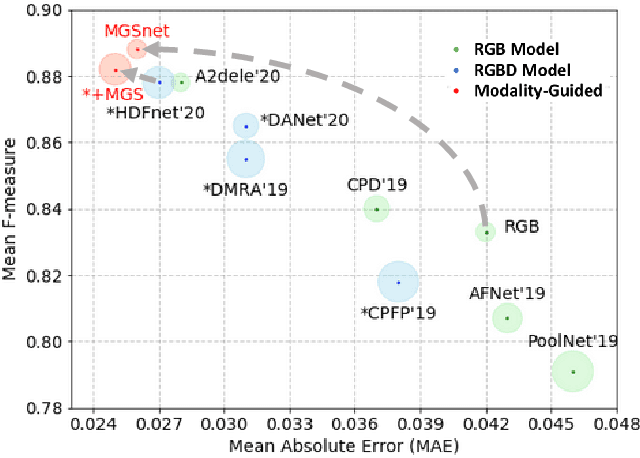
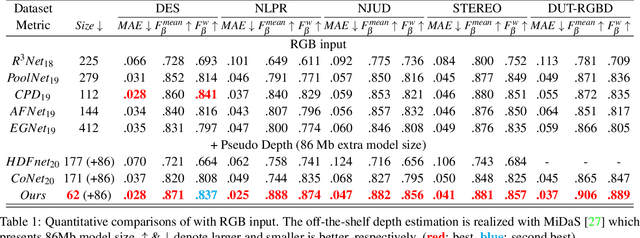
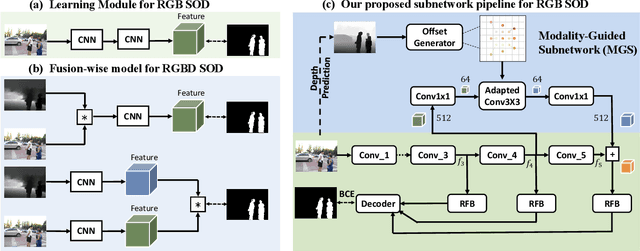
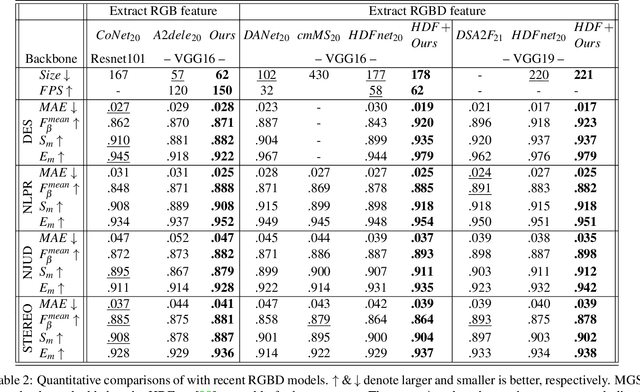
Recent RGBD-based models for saliency detection have attracted research attention. The depth clues such as boundary clues, surface normal, shape attribute, etc., contribute to the identification of salient objects with complicated scenarios. However, most RGBD networks require multi-modalities from the input side and feed them separately through a two-stream design, which inevitably results in extra costs on depth sensors and computation. To tackle these inconveniences, we present in this paper a novel fusion design named modality-guided subnetwork (MGSnet). It has the following superior designs: 1) Our model works for both RGB and RGBD data, and dynamically estimating depth if not available. Taking the inner workings of depth-prediction networks into account, we propose to estimate the pseudo-geometry maps from RGB input - essentially mimicking the multi-modality input. 2) Our MGSnet for RGB SOD results in real-time inference but achieves state-of-the-art performance compared to other RGB models. 3) The flexible and lightweight design of MGS facilitates the integration into RGBD two-streaming models. The introduced fusion design enables a cross-modality interaction to enable further progress but with a minimal cost.
Multistep traffic speed prediction: A deep learning based approach using latent space mapping considering spatio-temporal dependencies
Nov 03, 2021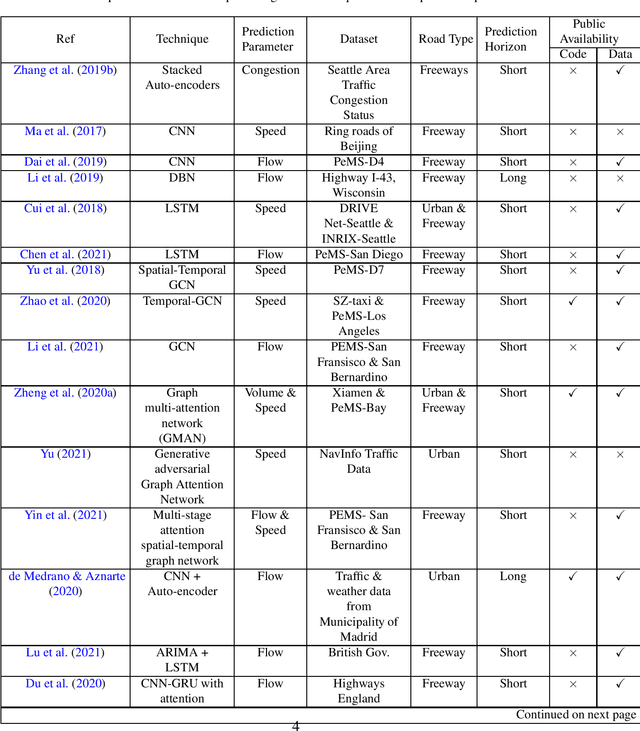
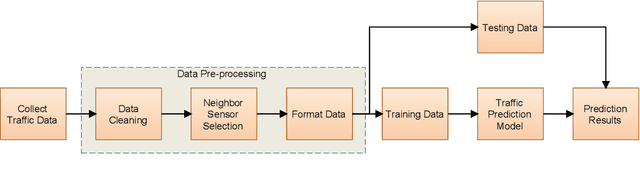
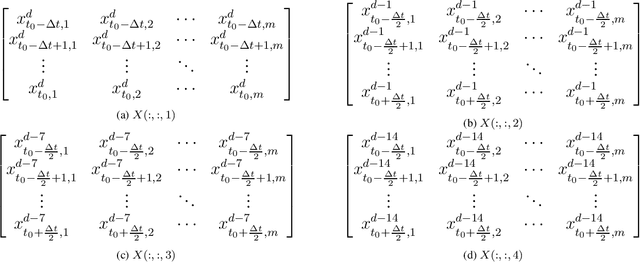
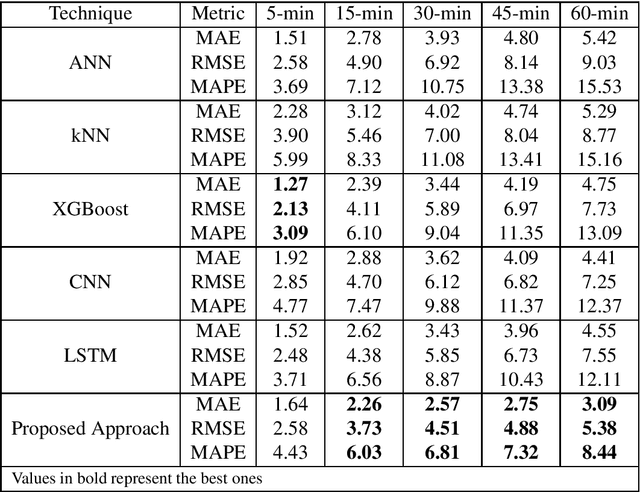
Traffic management in a city has become a major problem due to the increasing number of vehicles on roads. Intelligent Transportation System (ITS) can help the city traffic managers to tackle the problem by providing accurate traffic forecasts. For this, ITS requires a reliable traffic prediction algorithm that can provide accurate traffic prediction at multiple time steps based on past and current traffic data. In recent years, a number of different methods for traffic prediction have been proposed which have proved their effectiveness in terms of accuracy. However, most of these methods have either considered spatial information or temporal information only and overlooked the effect of other. In this paper, to address the above problem a deep learning based approach has been developed using both the spatial and temporal dependencies. To consider spatio-temporal dependencies, nearby road sensors at a particular instant are selected based on the attributes like traffic similarity and distance. Two pre-trained deep auto-encoders were cross-connected using the concept of latent space mapping and the resultant model was trained using the traffic data from the selected nearby sensors as input. The proposed deep learning based approach was trained using the real-world traffic data collected from loop detector sensors installed on different highways of Los Angeles and Bay Area. The traffic data is freely available from the web portal of the California Department of Transportation Performance Measurement System (PeMS). The effectiveness of the proposed approach was verified by comparing it with a number of machine/deep learning approaches. It has been found that the proposed approach provides accurate traffic prediction results even for 60-min ahead prediction with least error than other techniques.
Idle Time Optimization for Target Assignment and Path Finding in Sortation Centers
Nov 30, 2019
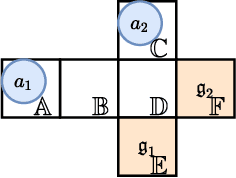
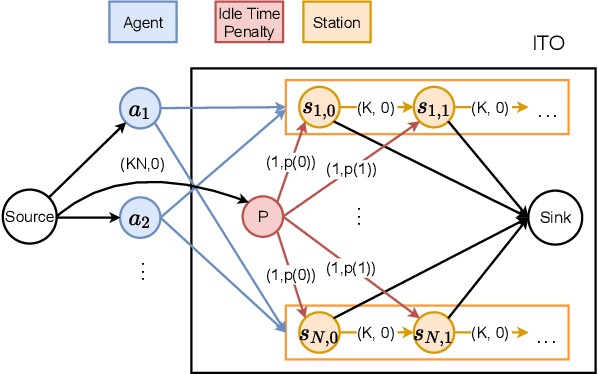
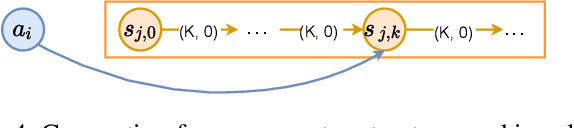
In this paper, we study the one-shot and lifelong versions of the Target Assignment and Path Finding problem in automated sortation centers, where each agent needs to constantly assign itself a sorting station, move to its assigned station without colliding with obstacles or other agents, wait in the queue of that station to obtain a parcel for delivery, and then deliver the parcel to a sorting bin. The throughput of such centers is largely determined by the total idle time of all stations since their queues can frequently become empty. To address this problem, we first formalize and study the one-shot version that assigns stations to a set of agents and finds collision-free paths for the agents to their assigned stations. We present efficient algorithms for this task based on a novel min-cost max-flow formulation that minimizes the total idle time of all stations in a fixed time window. We then demonstrate how our algorithms for solving the one-shot problem can be applied to solving the lifelong problem as well. Experimentally, we believe to be the first researchers to consider real-world automated sortation centers using an industrial simulator with realistic data and a kinodynamic model of real robots. On this simulator, we showcase the benefits of our algorithms by demonstrating their efficiency and effectiveness for up to 350 agents.
Multi-objective Conflict-based Search Using Safe-interval Path Planning
Aug 02, 2021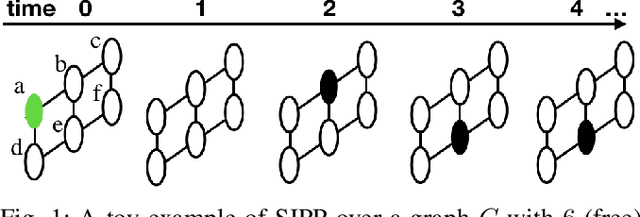
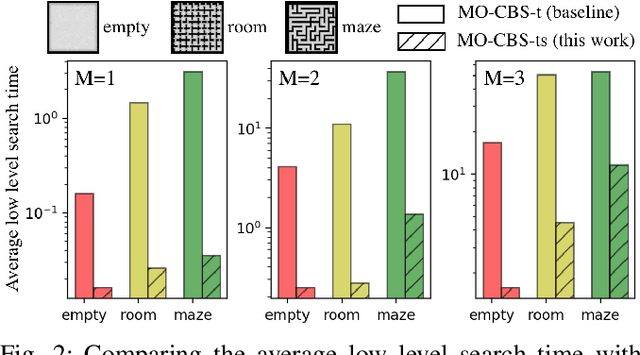
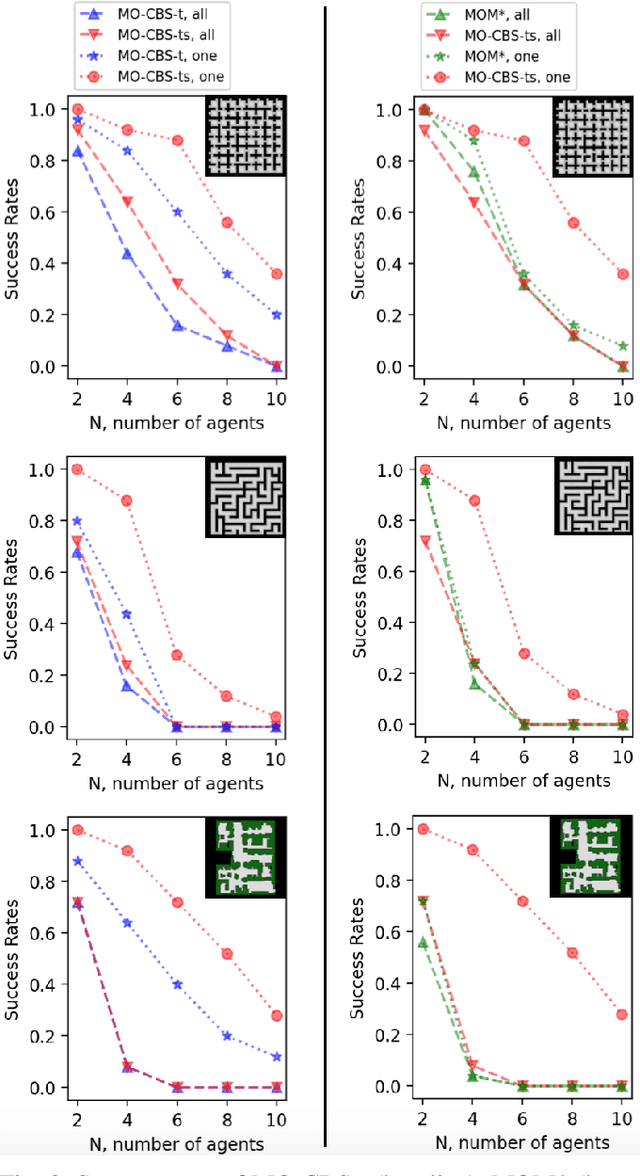
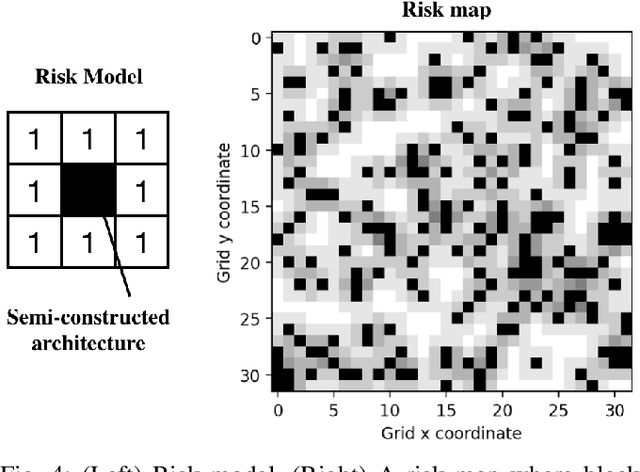
This paper addresses a generalization of the well known multi-agent path finding (MAPF) problem that optimizes multiple conflicting objectives simultaneously such as travel time and path risk. This generalization, referred to as multi-objective MAPF (MOMAPF), arises in several applications ranging from hazardous material transportation to construction site planning. In this paper, we present a new multi-objective conflict-based search (MO-CBS) approach that relies on a novel multi-objective safe interval path planning (MO-SIPP) algorithm for its low-level search. We first develop the MO-SIPP algorithm, show its properties and then embed it in MO-CBS. We present extensive numerical results to show that (1) there is an order of magnitude improvement in the average low level search time, and (2) a significant improvement in the success rates of finding the Pareto-optimal front can be obtained using the proposed approach in comparison with the state of the art. Finally, we also provide a case study to demonstrate the potential application of the proposed algorithms for construction site planning.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019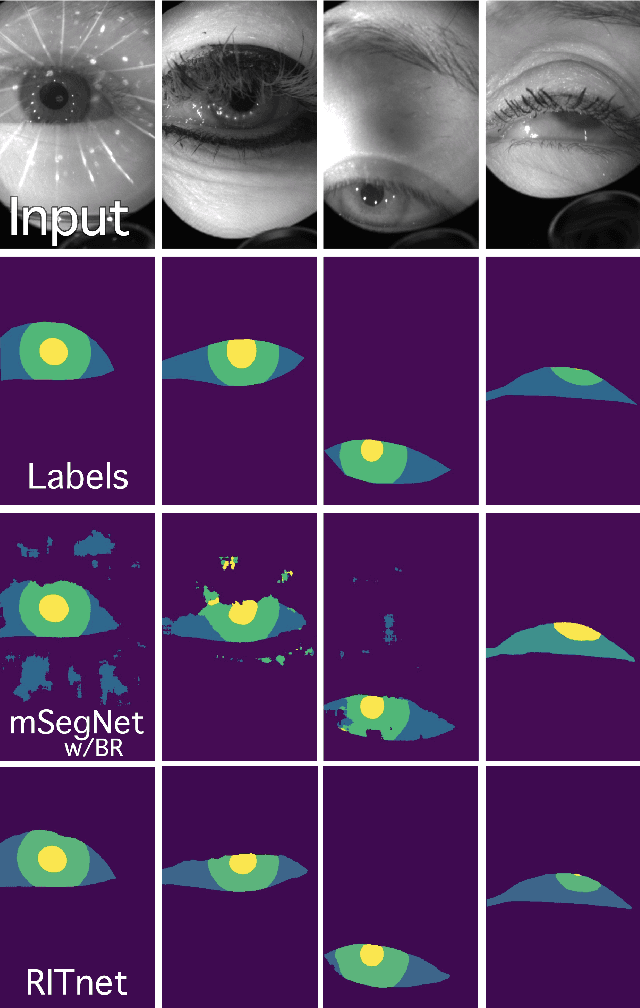
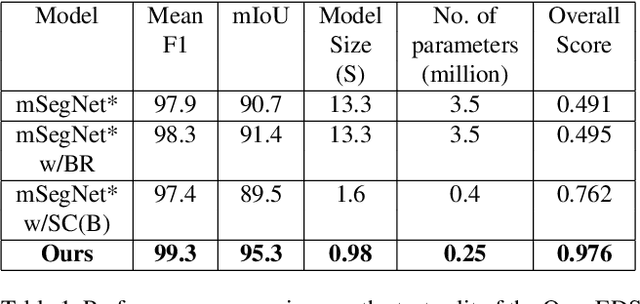
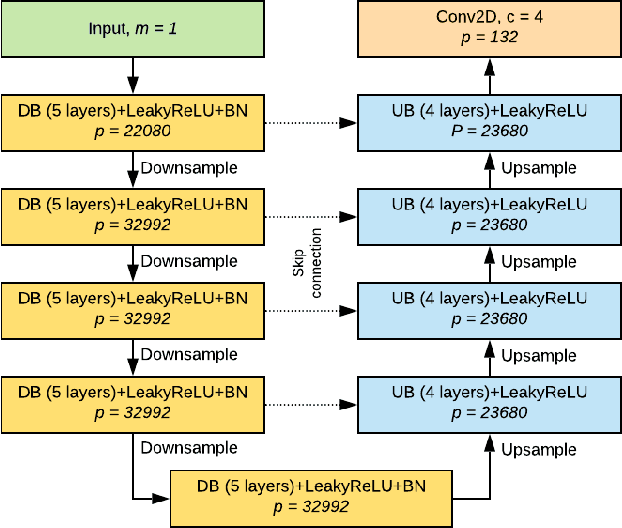
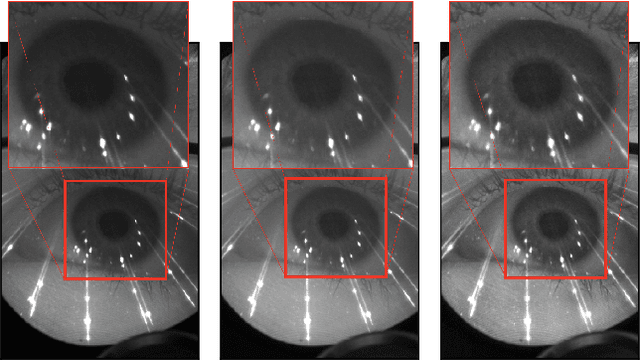
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
Multi-Objective Path-Based D* Lite
Aug 02, 2021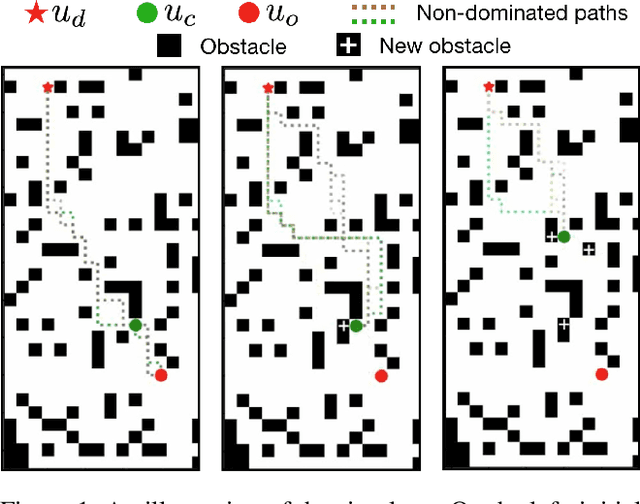
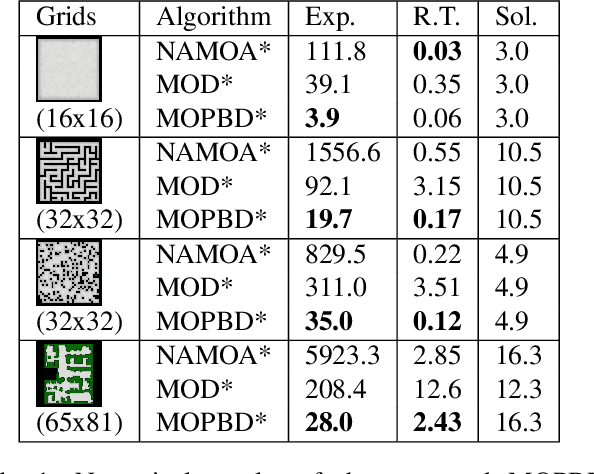
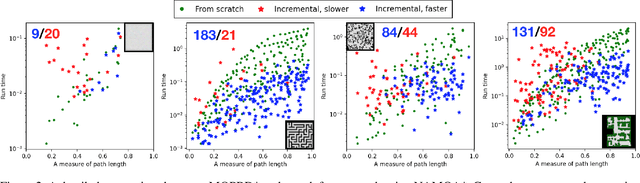
Incremental graph search algorithms, such as D* Lite, reuse previous search efforts to speed up subsequent similar path planning tasks. These algorithms have demonstrated their efficiency in comparison with search from scratch, and have been leveraged in many applications such as navigation in unknown terrain. On the other hand, path planning typically involves optimizing multiple conflicting objectives simultaneously, such as travel risk, arrival time, etc. Multi-objective path planning is challenging as the number of "Pareto-optimal" solutions can grow exponentially with respect to the size of the graph, which makes it computationally burdensome to plan from scratch each time when similar planning tasks needs to be solved. This article presents a new multi-objective incremental search algorithm called Multi-Objective Path-Based D* Lite (MOPBD*) which reuses previous search efforts to speed up subsequent planning tasks while optimizing multiple objectives. Numerical results show that MOPBD* is more efficient than search from scratch and runs an order of magnitude faster than existing incremental method for multi-objective path planning.
On the Empirical Evaluation of Information Gain Criteria for Active Action Selection
Sep 28, 2021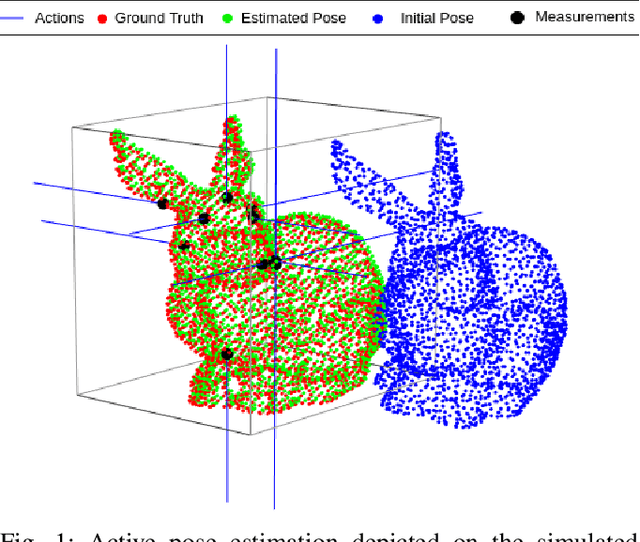
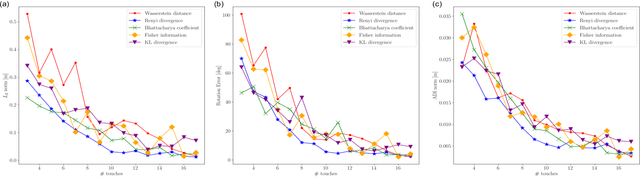


Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) is proposed for pose estimation using point cloud registration. Active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain as tactile data collection is time consuming. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements ($<15$ points) across all the selected criteria. Furthermore, we explore the use of uncommon information theoretic criteria in the robotics domain for action selection.