 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feedforward Neural Network for Time Series Anomaly Detection
Dec 21, 2018
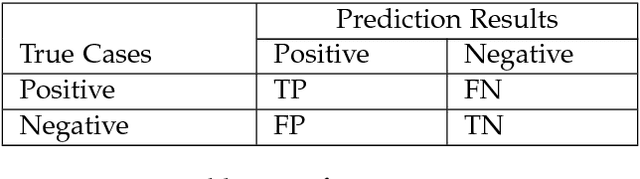
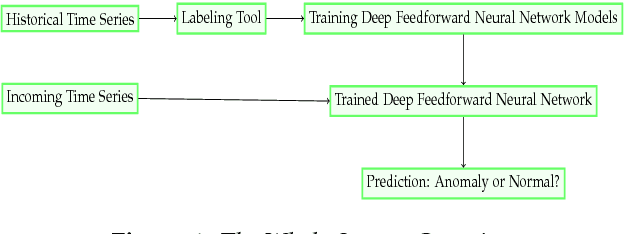
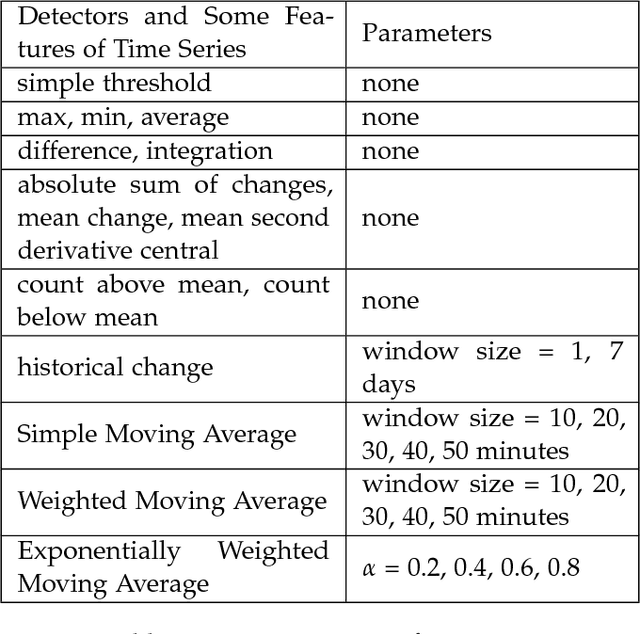
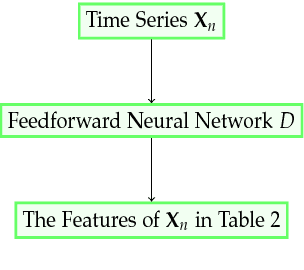
Time series anomaly detection is usually formulated as finding outlier data points relative to some usual data, which is also an important problem in industry and academia. To ensure systems working stably, internet companies, banks and other companies need to monitor time series, which is called KPI (Key Performance Indicators), such as CPU used, number of orders, number of online users and so on. However, millions of time series have several shapes (e.g. seasonal KPIs, KPIs of timed tasks and KPIs of CPU used), so that it is very difficult to use a simple statistical model to detect anomaly for all kinds of time series. Although some anomaly detectors have developed many years and some supervised models are also available in this field, we find many methods have their own disadvantages. In this paper, we present our system, which is based on deep feedforward neural network and detect anomaly points of time series. The main difference between our system and other systems based on supervised models is that we do not need feature engineering of time series to train deep feedforward neural network in our system, which is essentially an end-to-end system.
Deployment Optimization for Shared e-Mobility Systems with Multi-agent Deep Neural Search
Nov 03, 2021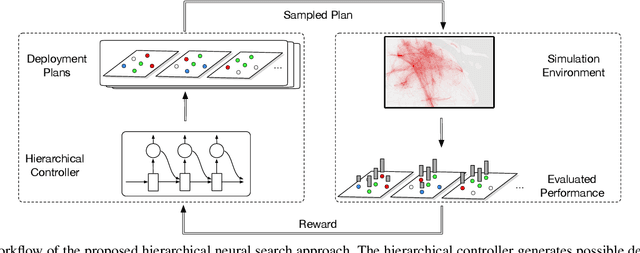
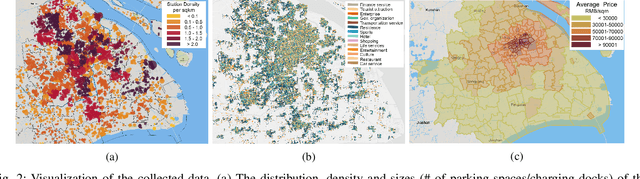
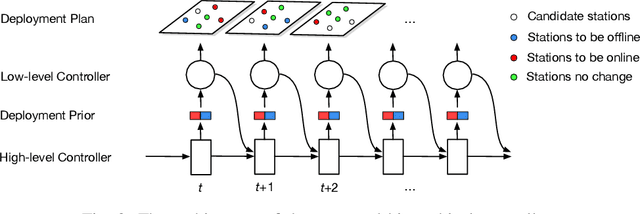
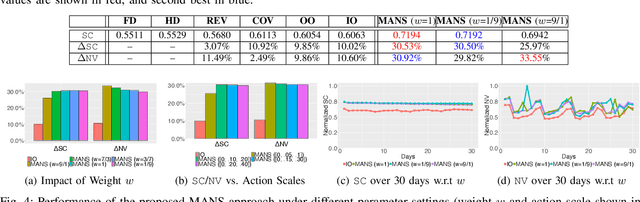
Shared e-mobility services have been widely tested and piloted in cities across the globe, and already woven into the fabric of modern urban planning. This paper studies a practical yet important problem in those systems: how to deploy and manage their infrastructure across space and time, so that the services are ubiquitous to the users while sustainable in profitability. However, in real-world systems evaluating the performance of different deployment strategies and then finding the optimal plan is prohibitively expensive, as it is often infeasible to conduct many iterations of trial-and-error. We tackle this by designing a high-fidelity simulation environment, which abstracts the key operation details of the shared e-mobility systems at fine-granularity, and is calibrated using data collected from the real-world. This allows us to try out arbitrary deployment plans to learn the optimal given specific context, before actually implementing any in the real-world systems. In particular, we propose a novel multi-agent neural search approach, in which we design a hierarchical controller to produce tentative deployment plans. The generated deployment plans are then tested using a multi-simulation paradigm, i.e., evaluated in parallel, where the results are used to train the controller with deep reinforcement learning. With this closed loop, the controller can be steered to have higher probability of generating better deployment plans in future iterations. The proposed approach has been evaluated extensively in our simulation environment, and experimental results show that it outperforms baselines e.g., human knowledge, and state-of-the-art heuristic-based optimization approaches in both service coverage and net revenue.
Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations
Oct 26, 2021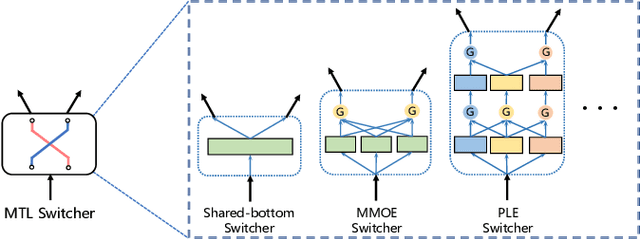
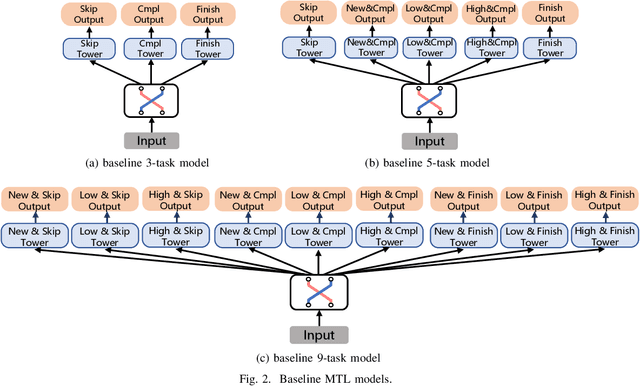
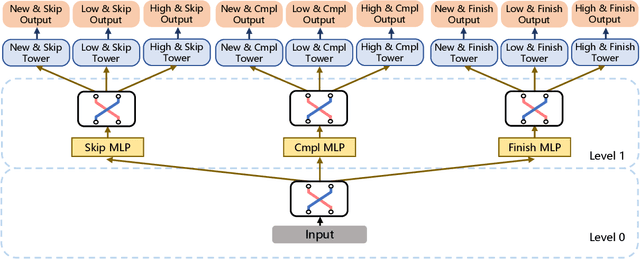
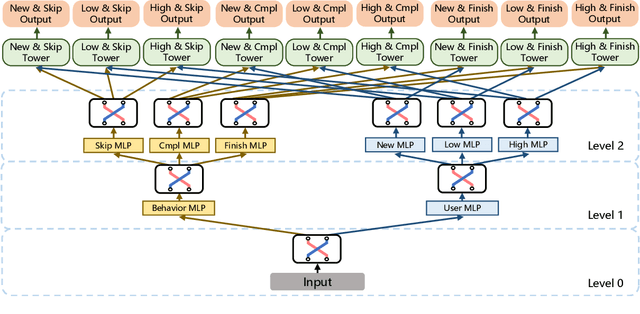
There has been many studies on improving the efficiency of shared learning in Multi-Task Learning(MTL). Previous work focused on the "micro" sharing perspective for a small number of tasks, while in Recommender Systems(RS) and other AI applications, there are often demands to model a large number of tasks with multi-dimensional task relations. For example, when using MTL to model various user behaviors in RS, if we differentiate new users and new items from old ones, there will be a cartesian product style increase of tasks with multi-dimensional relations. This work studies the "macro" perspective of shared learning network design and proposes a Multi-Faceted Hierarchical MTL model(MFH). MFH exploits the multi-dimension task relations with a nested hierarchical tree structure which maximizes the shared learning. We evaluate MFH and SOTA models in a large industry video platform of 10 billion samples and results show that MFH outperforms SOTA MTL models significantly in both offline and online evaluations across all user groups, especially remarkable for new users with an online increase of 9.1\% in app time per user and 1.85\% in next-day retention rate. MFH now has been deployed in a large scale online video recommender system. MFH is especially beneficial to the cold-start problems in RS where new users and new items often suffer from a "local overfitting" phenomenon. However, the idea is actually generic and widely applicable to other MTL scenarios.
Multistep traffic speed prediction: A deep learning based approach using latent space mapping considering spatio-temporal dependencies
Nov 03, 2021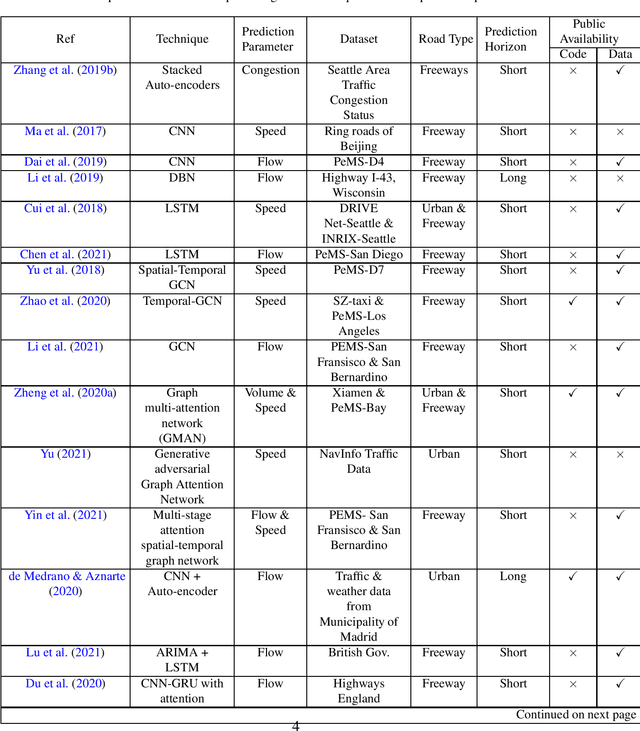
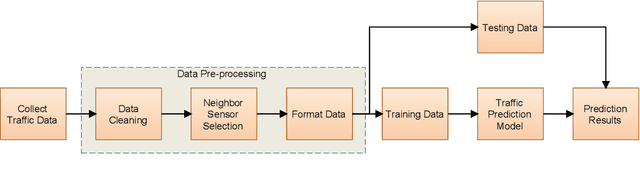
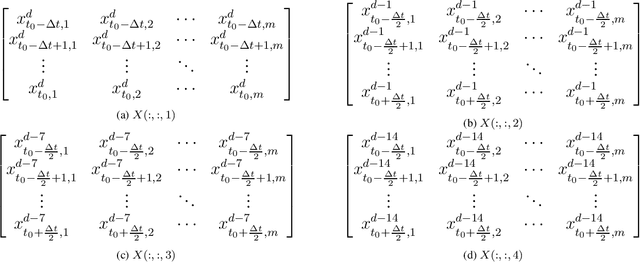
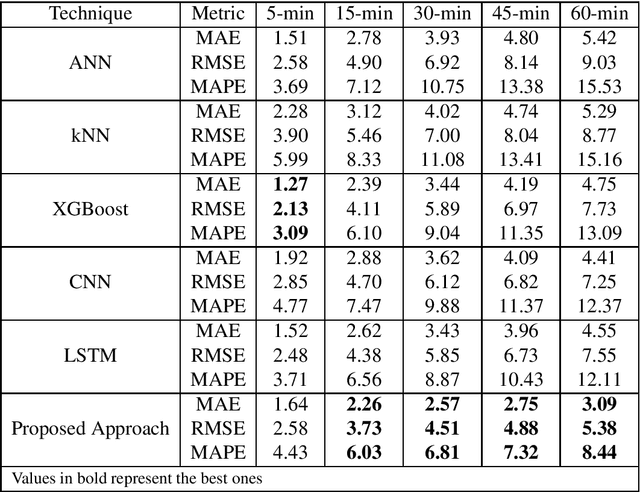
Traffic management in a city has become a major problem due to the increasing number of vehicles on roads. Intelligent Transportation System (ITS) can help the city traffic managers to tackle the problem by providing accurate traffic forecasts. For this, ITS requires a reliable traffic prediction algorithm that can provide accurate traffic prediction at multiple time steps based on past and current traffic data. In recent years, a number of different methods for traffic prediction have been proposed which have proved their effectiveness in terms of accuracy. However, most of these methods have either considered spatial information or temporal information only and overlooked the effect of other. In this paper, to address the above problem a deep learning based approach has been developed using both the spatial and temporal dependencies. To consider spatio-temporal dependencies, nearby road sensors at a particular instant are selected based on the attributes like traffic similarity and distance. Two pre-trained deep auto-encoders were cross-connected using the concept of latent space mapping and the resultant model was trained using the traffic data from the selected nearby sensors as input. The proposed deep learning based approach was trained using the real-world traffic data collected from loop detector sensors installed on different highways of Los Angeles and Bay Area. The traffic data is freely available from the web portal of the California Department of Transportation Performance Measurement System (PeMS). The effectiveness of the proposed approach was verified by comparing it with a number of machine/deep learning approaches. It has been found that the proposed approach provides accurate traffic prediction results even for 60-min ahead prediction with least error than other techniques.
DL-Traff: Survey and Benchmark of Deep Learning Models for Urban Traffic Prediction
Aug 20, 2021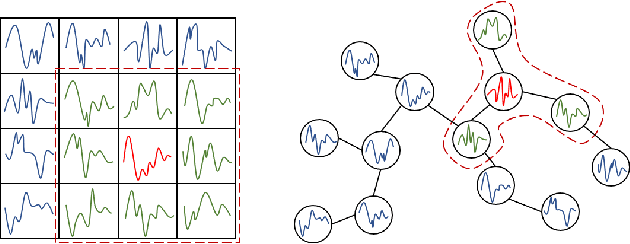
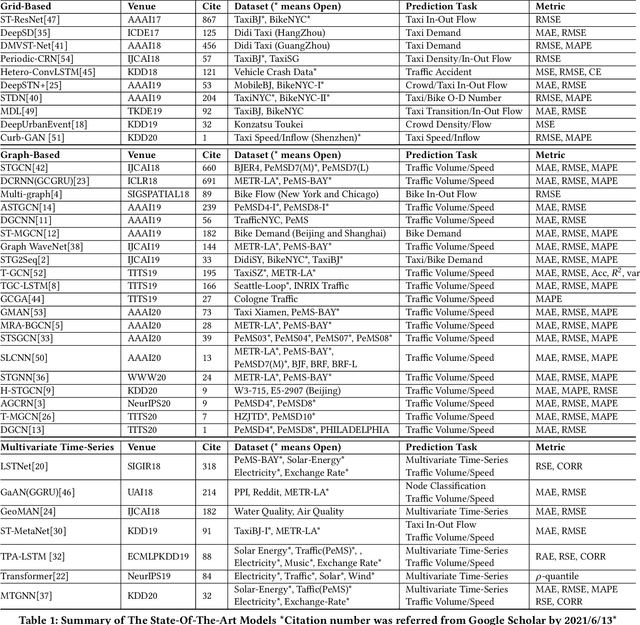
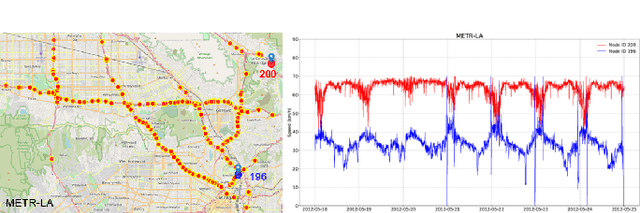
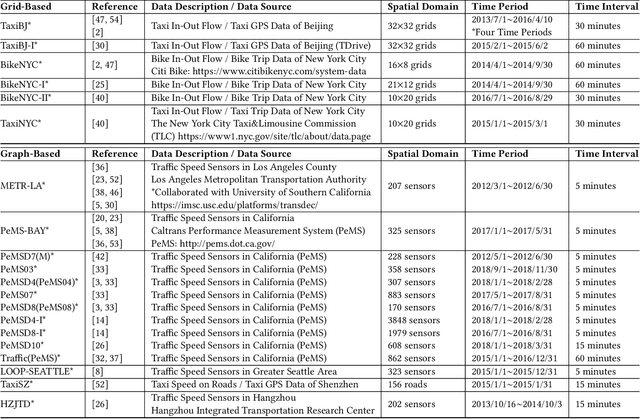
Nowadays, with the rapid development of IoT (Internet of Things) and CPS (Cyber-Physical Systems) technologies, big spatiotemporal data are being generated from mobile phones, car navigation systems, and traffic sensors. By leveraging state-of-the-art deep learning technologies on such data, urban traffic prediction has drawn a lot of attention in AI and Intelligent Transportation System community. The problem can be uniformly modeled with a 3D tensor (T, N, C), where T denotes the total time steps, N denotes the size of the spatial domain (i.e., mesh-grids or graph-nodes), and C denotes the channels of information. According to the specific modeling strategy, the state-of-the-art deep learning models can be divided into three categories: grid-based, graph-based, and multivariate time-series models. In this study, we first synthetically review the deep traffic models as well as the widely used datasets, then build a standard benchmark to comprehensively evaluate their performances with the same settings and metrics. Our study named DL-Traff is implemented with two most popular deep learning frameworks, i.e., TensorFlow and PyTorch, which is already publicly available as two GitHub repositories https://github.com/deepkashiwa20/DL-Traff-Grid and https://github.com/deepkashiwa20/DL-Traff-Graph. With DL-Traff, we hope to deliver a useful resource to researchers who are interested in spatiotemporal data analysis.
Marine vessel tracking using a monocular camera
Aug 23, 2021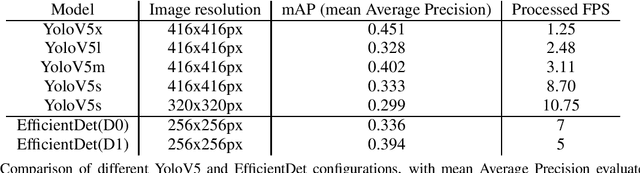

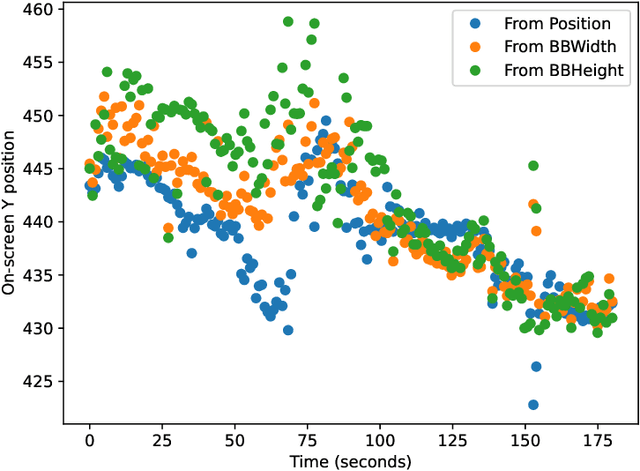

In this paper, a new technique for camera calibration using only GPS data is presented. A new way of tracking objects that move on a plane in a video is achieved by using the location and size of the bounding box to estimate the distance, achieving an average prediction error of 5.55m per 100m distance from the camera. This solution can be run in real-time at the edge, achieving efficient inference in a low-powered IoT environment while also being able to track multiple different vessels.
Constrained Shortest Path Search with Graph Convolutional Neural Networks
Aug 02, 2021
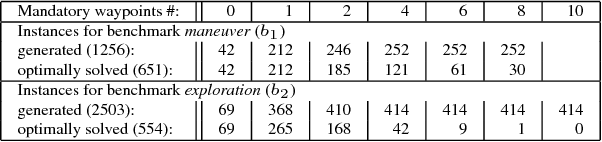
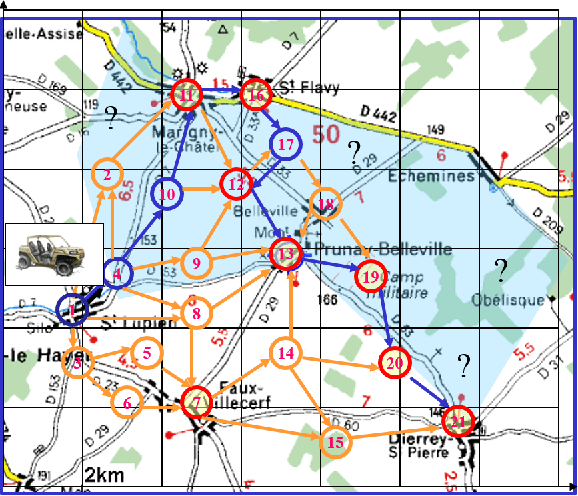
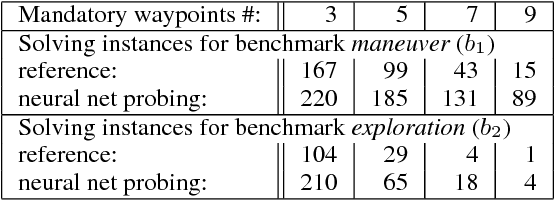
Planning for Autonomous Unmanned Ground Vehicles (AUGV) is still a challenge, especially in difficult, off-road, critical situations. Automatic planning can be used to reach mission objectives, to perform navigation or maneuvers. Most of the time, the problem consists in finding a path from a source to a destination, while satisfying some operational constraints. In a graph without negative cycles, the computation of the single-pair shortest path from a start node to an end node is solved in polynomial time. Additional constraints on the solution path can however make the problem harder to solve. This becomes the case when we need the path to pass through a few mandatory nodes without requiring a specific order of visit. The complexity grows exponentially with the number of mandatory nodes to visit. In this paper, we focus on shortest path search with mandatory nodes on a given connected graph. We propose a hybrid model that combines a constraint-based solver and a graph convolutional neural network to improve search performance. Promising results are obtained on realistic scenarios.
Modality-Guided Subnetwork for Salient Object Detection
Oct 10, 2021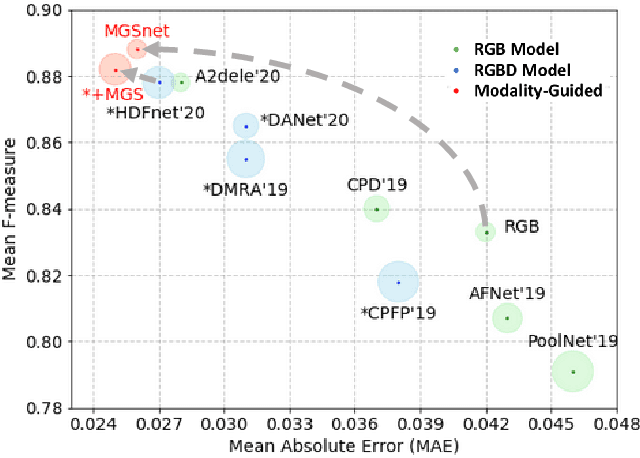
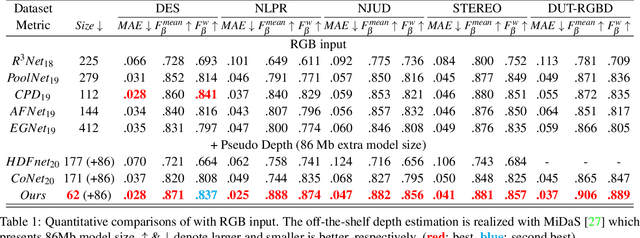
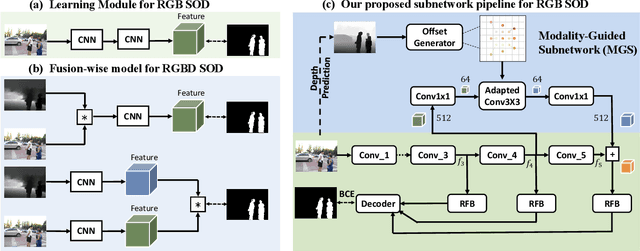
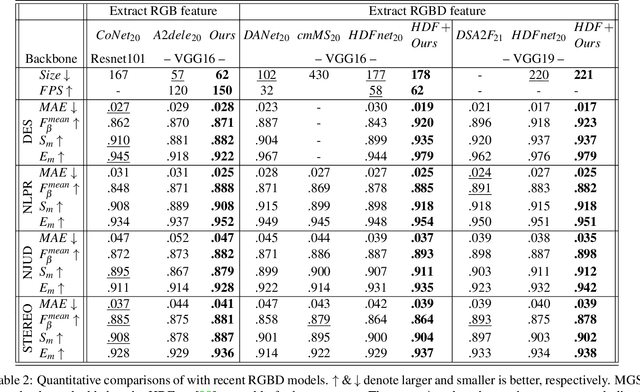
Recent RGBD-based models for saliency detection have attracted research attention. The depth clues such as boundary clues, surface normal, shape attribute, etc., contribute to the identification of salient objects with complicated scenarios. However, most RGBD networks require multi-modalities from the input side and feed them separately through a two-stream design, which inevitably results in extra costs on depth sensors and computation. To tackle these inconveniences, we present in this paper a novel fusion design named modality-guided subnetwork (MGSnet). It has the following superior designs: 1) Our model works for both RGB and RGBD data, and dynamically estimating depth if not available. Taking the inner workings of depth-prediction networks into account, we propose to estimate the pseudo-geometry maps from RGB input - essentially mimicking the multi-modality input. 2) Our MGSnet for RGB SOD results in real-time inference but achieves state-of-the-art performance compared to other RGB models. 3) The flexible and lightweight design of MGS facilitates the integration into RGBD two-streaming models. The introduced fusion design enables a cross-modality interaction to enable further progress but with a minimal cost.
On the Explanatory Power of Decision Trees
Sep 04, 2021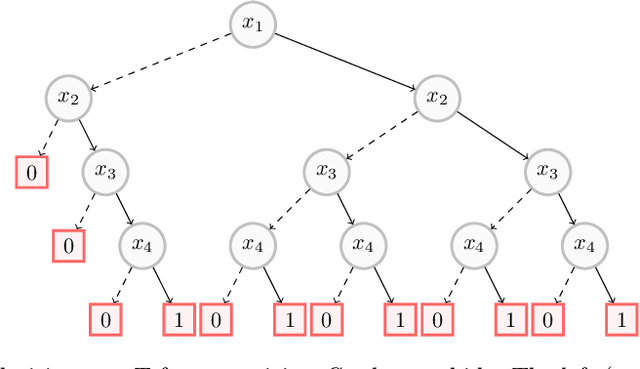
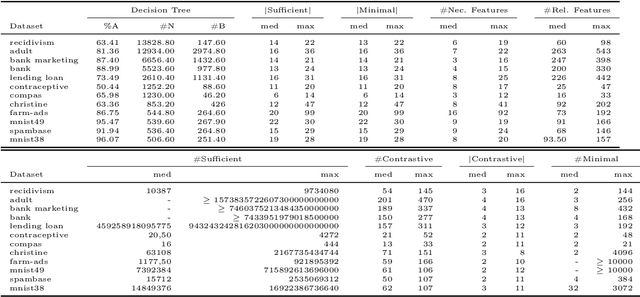
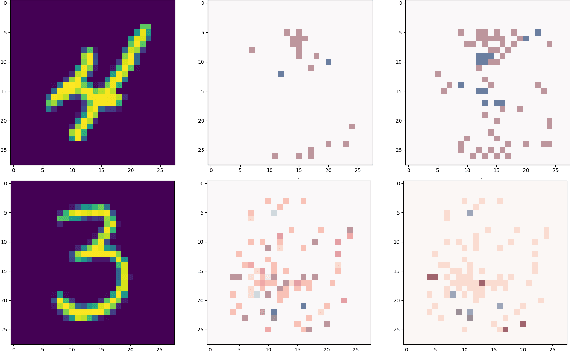
Decision trees have long been recognized as models of choice in sensitive applications where interpretability is of paramount importance. In this paper, we examine the computational ability of Boolean decision trees in deriving, minimizing, and counting sufficient reasons and contrastive explanations. We prove that the set of all sufficient reasons of minimal size for an instance given a decision tree can be exponentially larger than the size of the input (the instance and the decision tree). Therefore, generating the full set of sufficient reasons can be out of reach. In addition, computing a single sufficient reason does not prove enough in general; indeed, two sufficient reasons for the same instance may differ on many features. To deal with this issue and generate synthetic views of the set of all sufficient reasons, we introduce the notions of relevant features and of necessary features that characterize the (possibly negated) features appearing in at least one or in every sufficient reason, and we show that they can be computed in polynomial time. We also introduce the notion of explanatory importance, that indicates how frequent each (possibly negated) feature is in the set of all sufficient reasons. We show how the explanatory importance of a feature and the number of sufficient reasons can be obtained via a model counting operation, which turns out to be practical in many cases. We also explain how to enumerate sufficient reasons of minimal size. We finally show that, unlike sufficient reasons, the set of all contrastive explanations for an instance given a decision tree can be derived, minimized and counted in polynomial time.
Fully Homomorphically Encrypted Deep Learning as a Service
Jul 26, 2021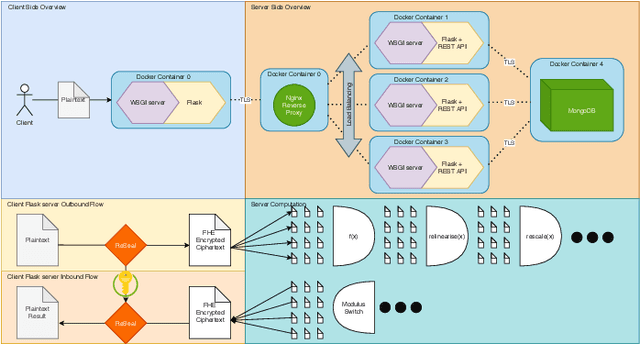
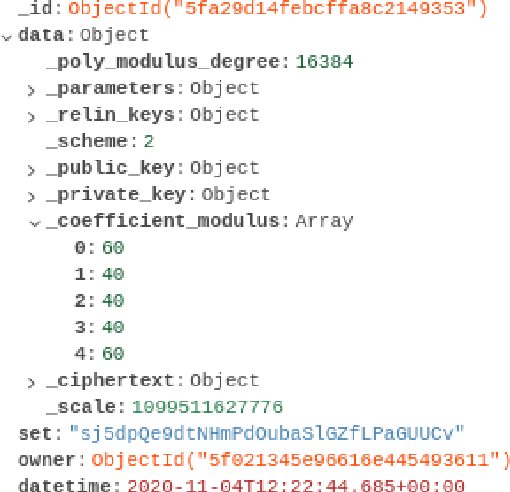
Fully Homomorphic Encryption (FHE) is a relatively recent advancement in the field of privacy-preserving technologies. FHE allows for the arbitrary depth computation of both addition and multiplication, and thus the application of abelian/polynomial equations, like those found in deep learning algorithms. This project investigates, derives, and proves how FHE with deep learning can be used at scale, with relatively low time complexity, the problems that such a system incurs, and mitigations/solutions for such problems. In addition, we discuss how this could have an impact on the future of data privacy and how it can enable data sharing across various actors in the agri-food supply chain, hence allowing the development of machine learning-based systems. Finally, we find that although FHE incurs a high spatial complexity cost, the time complexity is within expected reasonable bounds, while allowing for absolutely private predictions to be made, in our case for milk yield prediction.