 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimization of the Model Predictive Control Meta-Parameters Through Reinforcement Learning
Nov 07, 2021
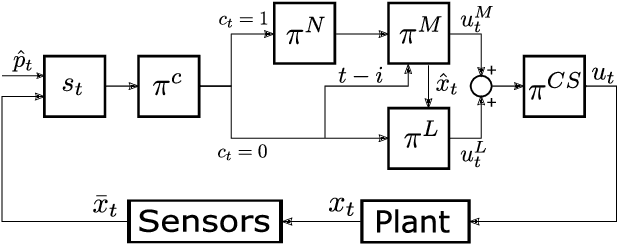
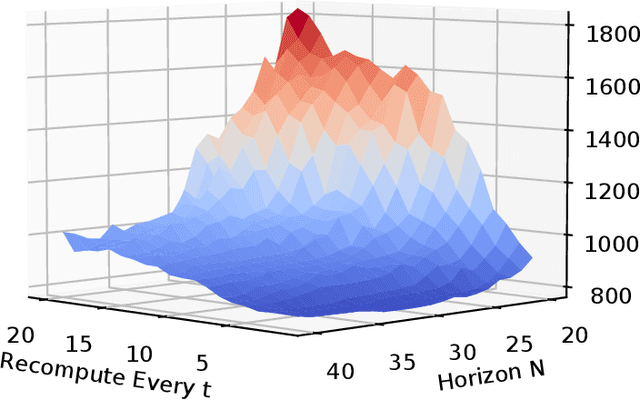
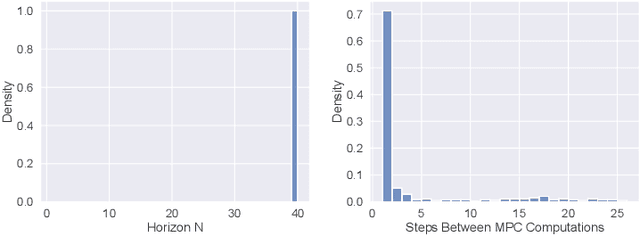
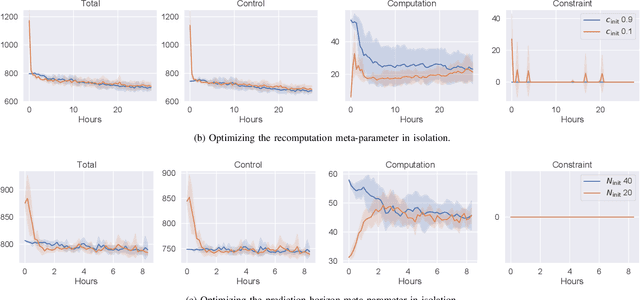
Model predictive control (MPC) is increasingly being considered for control of fast systems and embedded applications. However, the MPC has some significant challenges for such systems. Its high computational complexity results in high power consumption from the control algorithm, which could account for a significant share of the energy resources in battery-powered embedded systems. The MPC parameters must be tuned, which is largely a trial-and-error process that affects the control performance, the robustness and the computational complexity of the controller to a high degree. In this paper, we propose a novel framework in which any parameter of the control algorithm can be jointly tuned using reinforcement learning(RL), with the goal of simultaneously optimizing the control performance and the power usage of the control algorithm. We propose the novel idea of optimizing the meta-parameters of MPCwith RL, i.e. parameters affecting the structure of the MPCproblem as opposed to the solution to a given problem. Our control algorithm is based on an event-triggered MPC where we learn when the MPC should be re-computed, and a dual mode MPC and linear state feedback control law applied in between MPC computations. We formulate a novel mixture-distribution policy and show that with joint optimization we achieve improvements that do not present themselves when optimizing the same parameters in isolation. We demonstrate our framework on the inverted pendulum control task, reducing the total computation time of the control system by 36% while also improving the control performance by 18.4% over the best-performing MPC baseline.
Semantic-Guided Zero-Shot Learning for Low-Light Image/Video Enhancement
Oct 03, 2021
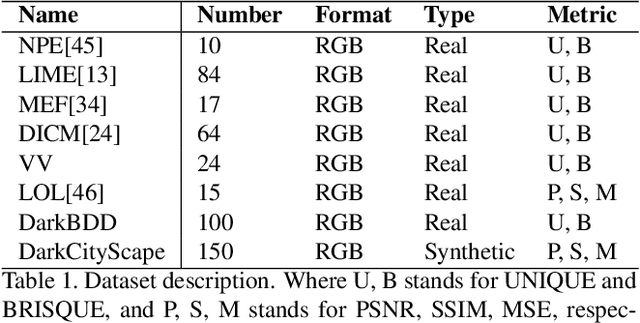
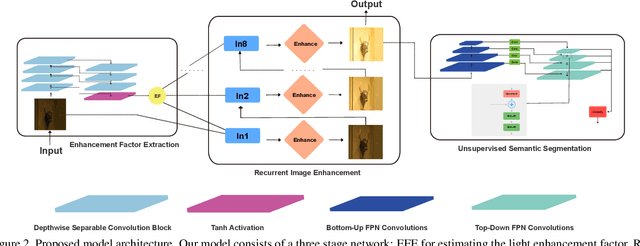
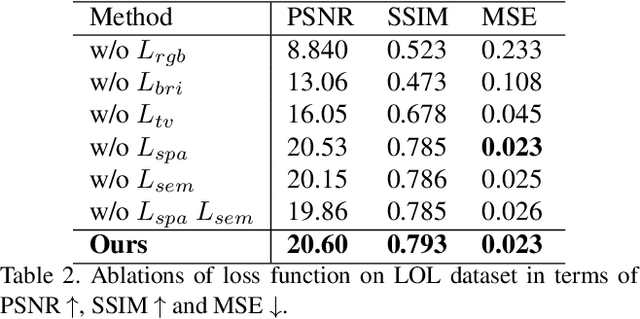
Low-light images challenge both human perceptions and computer vision algorithms. It is crucial to make algorithms robust to enlighten low-light images for computational photography and computer vision applications such as real-time detection and segmentation tasks. This paper proposes a semantic-guided zero-shot low-light enhancement network which is trained in the absence of paired images, unpaired datasets, and segmentation annotation. Firstly, we design an efficient enhancement factor extraction network using depthwise separable convolution. Secondly, we propose a recurrent image enhancement network for progressively enhancing the low-light image. Finally, we introduce an unsupervised semantic segmentation network for preserving the semantic information. Extensive experiments on various benchmark datasets and a low-light video demonstrate that our model outperforms the previous state-of-the-art qualitatively and quantitatively. We further discuss the benefits of the proposed method for low-light detection and segmentation.
SOFT: Softmax-free Transformer with Linear Complexity
Oct 29, 2021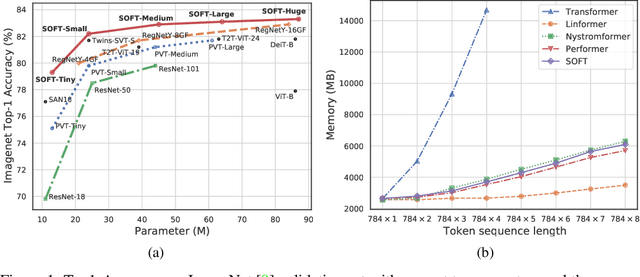
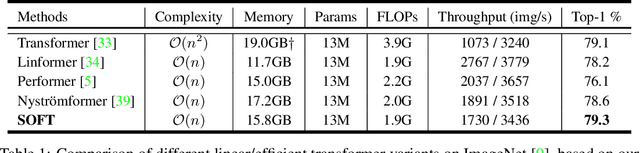
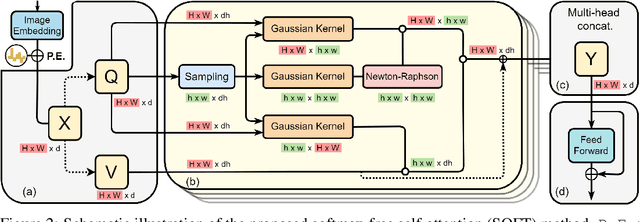
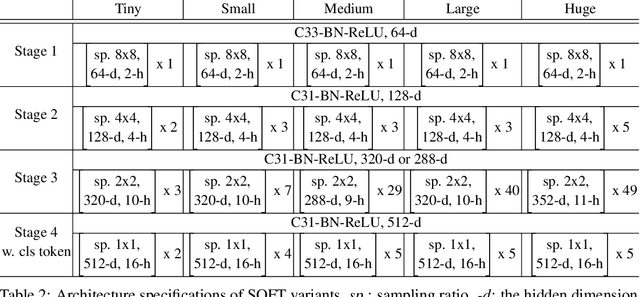
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by self-attention. However, the employment of self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have been made in Natural Language Processing. However, an in-depth analysis in this work shows that they are either theoretically flawed or empirically ineffective for visual recognition. We further identify that their limitations are rooted in keeping the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Keeping this softmax operation challenges any subsequent linearization efforts. Based on this insight, for the first time, a softmax-free transformer or SOFT is proposed. To remove softmax in self-attention, Gaussian kernel function is used to replace the dot-product similarity without further normalization. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of the approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Extensive experiments on ImageNet show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.
Learning Co-segmentation by Segment Swapping for Retrieval and Discovery
Oct 29, 2021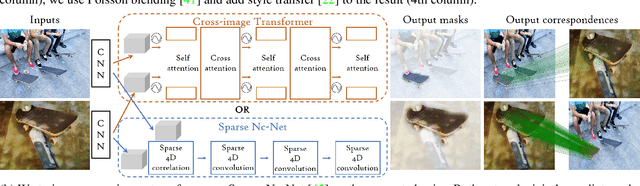
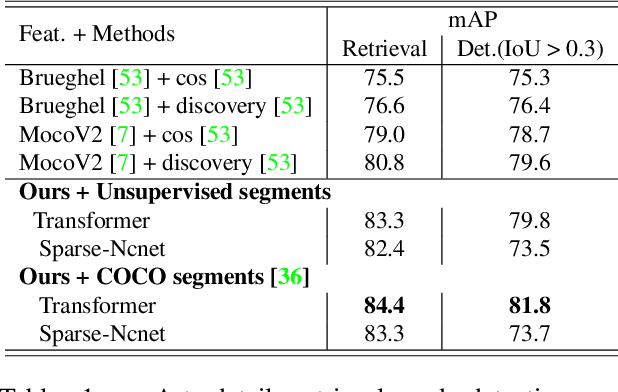
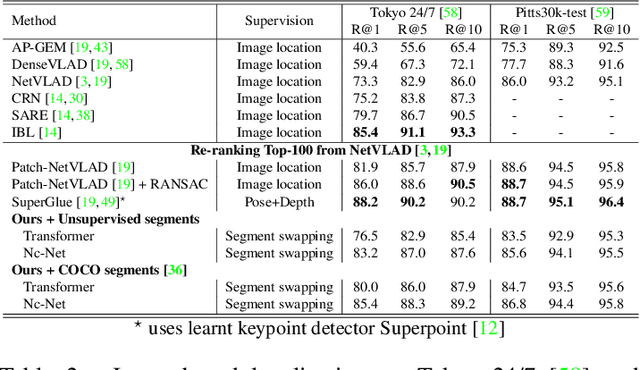

The goal of this work is to efficiently identify visually similar patterns from a pair of images, e.g. identifying an artwork detail copied between an engraving and an oil painting, or matching a night-time photograph with its daytime counterpart. Lack of training data is a key challenge for this co-segmentation task. We present a simple yet surprisingly effective approach to overcome this difficulty: we generate synthetic training pairs by selecting object segments in an image and copy-pasting them into another image. We then learn to predict the repeated object masks. We find that it is crucial to predict the correspondences as an auxiliary task and to use Poisson blending and style transfer on the training pairs to generalize on real data. We analyse results with two deep architectures relevant to our joint image analysis task: a transformer-based architecture and Sparse Nc-Net, a recent network designed to predict coarse correspondences using 4D convolutions. We show our approach provides clear improvements for artwork details retrieval on the Brueghel dataset and achieves competitive performance on two place recognition benchmarks, Tokyo247 and Pitts30K. We then demonstrate the potential of our approach by performing object discovery on the Internet object discovery dataset and the Brueghel dataset. Our code and data are available at http://imagine.enpc.fr/~shenx/SegSwap/.
Learning Not to Reconstruct Anomalies
Oct 19, 2021
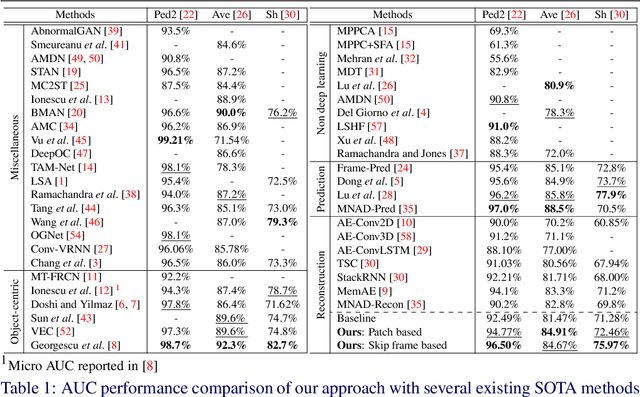
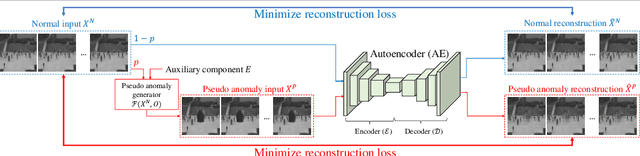

Video anomaly detection is often seen as one-class classification (OCC) problem due to the limited availability of anomaly examples. Typically, to tackle this problem, an autoencoder (AE) is trained to reconstruct the input with training set consisting only of normal data. At test time, the AE is then expected to well reconstruct the normal data while poorly reconstructing the anomalous data. However, several studies have shown that, even with only normal data training, AEs can often start reconstructing anomalies as well which depletes the anomaly detection performance. To mitigate this problem, we propose a novel methodology to train AEs with the objective of reconstructing only normal data, regardless of the input (i.e., normal or abnormal). Since no real anomalies are available in the OCC settings, the training is assisted by pseudo anomalies that are generated by manipulating normal data to simulate the out-of-normal-data distribution. We additionally propose two ways to generate pseudo anomalies: patch and skip frame based. Extensive experiments on three challenging video anomaly datasets demonstrate the effectiveness of our method in improving conventional AEs, achieving state-of-the-art performance.
DQRE-SCnet: A novel hybrid approach for selecting users in Federated Learning with Deep-Q-Reinforcement Learning based on Spectral Clustering
Nov 07, 2021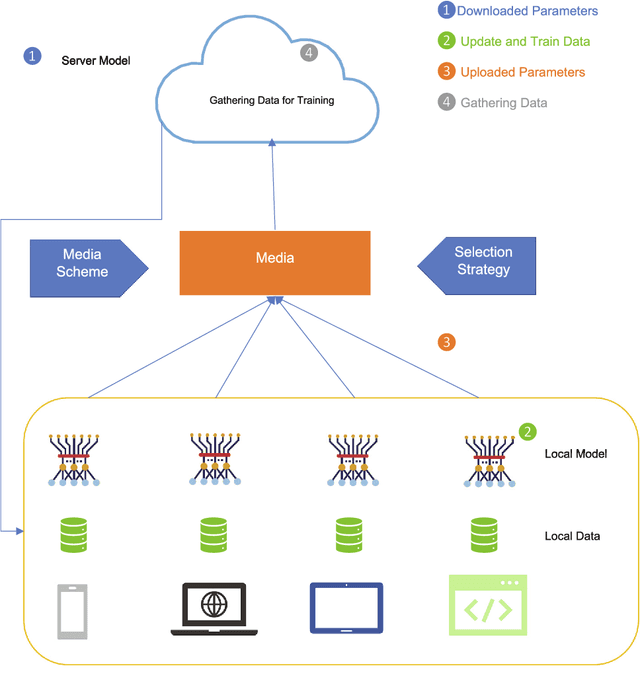
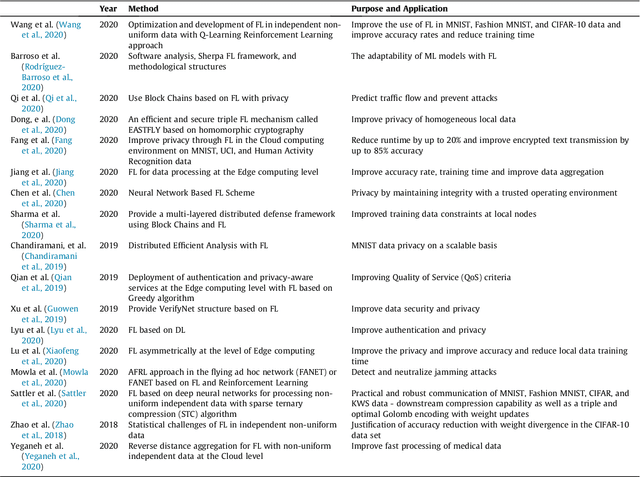
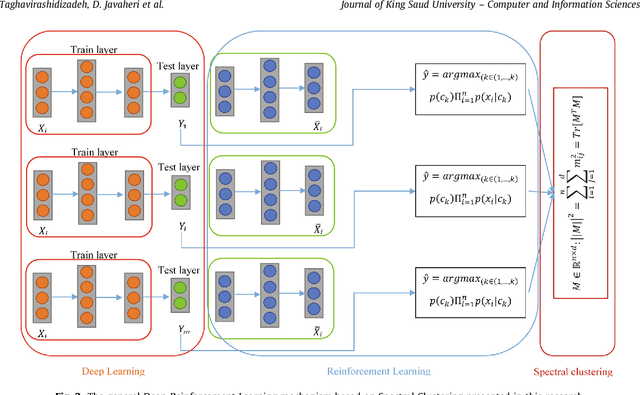
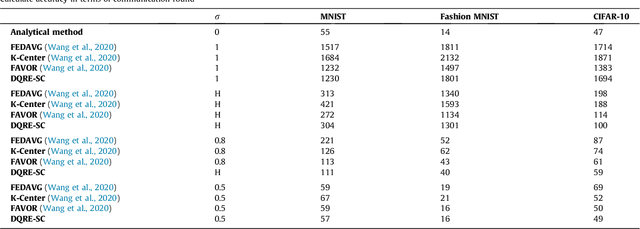
Machine learning models based on sensitive data in the real-world promise advances in areas ranging from medical screening to disease outbreaks, agriculture, industry, defense science, and more. In many applications, learning participant communication rounds benefit from collecting their own private data sets, teaching detailed machine learning models on the real data, and sharing the benefits of using these models. Due to existing privacy and security concerns, most people avoid sensitive data sharing for training. Without each user demonstrating their local data to a central server, Federated Learning allows various parties to train a machine learning algorithm on their shared data jointly. This method of collective privacy learning results in the expense of important communication during training. Most large-scale machine-learning applications require decentralized learning based on data sets generated on various devices and places. Such datasets represent an essential obstacle to decentralized learning, as their diverse contexts contribute to significant differences in the delivery of data across devices and locations. Researchers have proposed several ways to achieve data privacy in Federated Learning systems. However, there are still challenges with homogeneous local data. This research approach is to select nodes (users) to share their data in Federated Learning for independent data-based equilibrium to improve accuracy, reduce training time, and increase convergence. Therefore, this research presents a combined Deep-QReinforcement Learning Ensemble based on Spectral Clustering called DQRE-SCnet to choose a subset of devices in each communication round. Based on the results, it has been displayed that it is possible to decrease the number of communication rounds needed in Federated Learning.
An Operator-Splitting Method for the Gaussian Curvature Regularization Model with Applications in Surface Smoothing and Imaging
Aug 04, 2021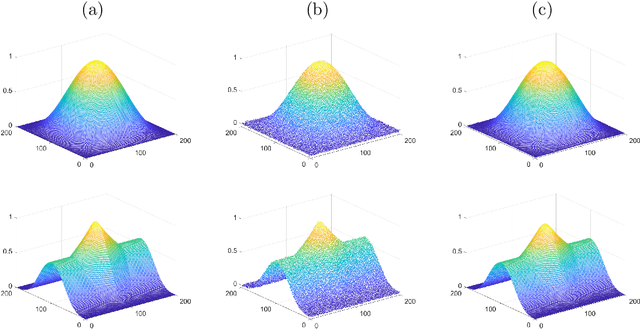

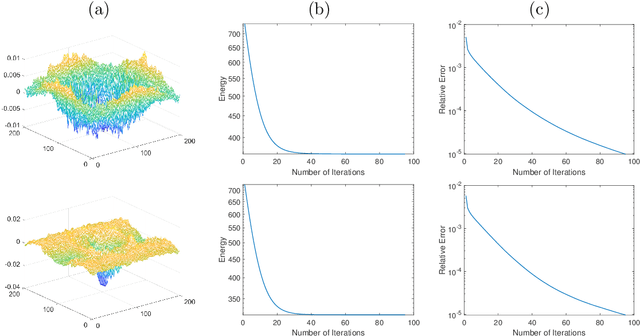
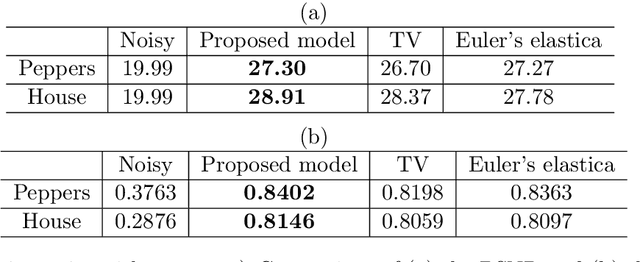
Gaussian curvature is an important geometric property of surfaces, which has been used broadly in mathematical modeling. Due to the full nonlinearity of the Gaussian curvature, efficient numerical methods for models based on it are uncommon in literature. In this article, we propose an operator-splitting method for a general Gaussian curvature model. In our method, we decouple the full nonlinearity of Gaussian curvature from differential operators by introducing two matrix- and vector-valued functions. The optimization problem is then converted into the search for the steady state solution of a time dependent PDE system. The above PDE system is well-suited to time discretization by operator splitting, the sub-problems encountered at each fractional step having either a closed form solution or being solvable by efficient algorithms. The proposed method is not sensitive to the choice of parameters, its efficiency and performances being demonstrated via systematic experiments on surface smoothing and image denoising.
Fingerprint Presentation Attack Detection by Channel-wise Feature Denoising
Nov 15, 2021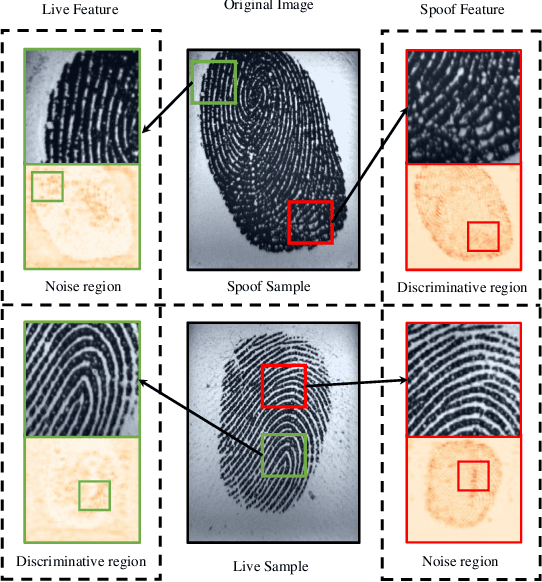
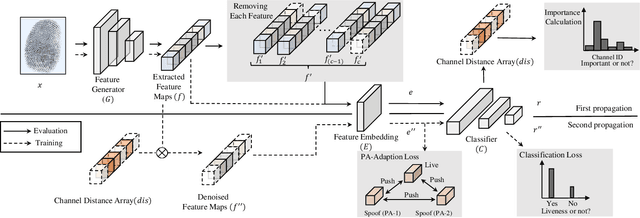
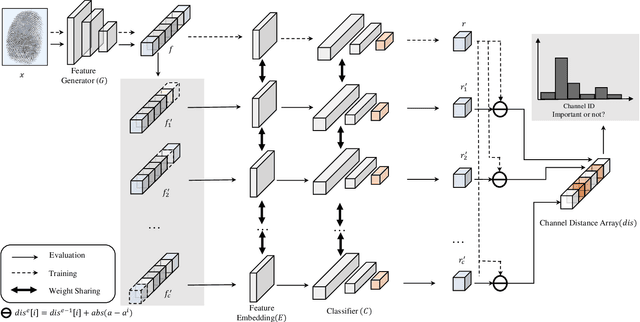
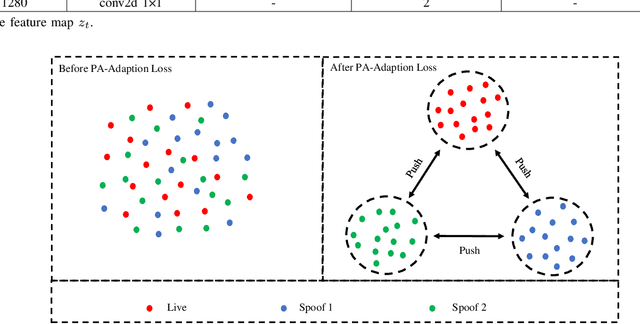
Due to the diversity of attack materials, fingerprint recognition systems (AFRSs) are vulnerable to malicious attacks. It is of great importance to propose effective Fingerprint Presentation Attack Detection (PAD) methods for the safety and reliability of AFRSs. However, current PAD methods often have poor robustness under new attack materials or sensor settings. This paper thus proposes a novel Channel-wise Feature Denoising fingerprint PAD (CFD-PAD) method by considering handling the redundant "noise" information which ignored in previous works. The proposed method learned important features of fingerprint images by weighting the importance of each channel and finding those discriminative channels and "noise" channels. Then, the propagation of "noise" channels is suppressed in the feature map to reduce interference. Specifically, a PA-Adaption loss is designed to constrain the feature distribution so as to make the feature distribution of live fingerprints more aggregate and spoof fingerprints more disperse. Our experimental results evaluated on LivDet 2017 showed that our proposed CFD-PAD can achieve 2.53% ACE and 93.83% True Detection Rate when the False Detection Rate equals to 1.0% (TDR@FDR=1%) and it outperforms the best single model based methods in terms of ACE (2.53% vs. 4.56%) and TDR@FDR=1%(93.83% vs. 73.32\%) significantly, which proves the effectiveness of the proposed method. Although we have achieved a comparable result compared with the state-of-the-art multiple model based method, there still achieves an increase of TDR@FDR=1% from 91.19% to 93.83% by our method. Besides, our model is simpler, lighter and, more efficient and has achieved a 74.76% reduction in time-consuming compared with the state-of-the-art multiple model based method. Code will be publicly available.
Spatial Data Augmentation with Simulated Room Impulse Responses for Sound Event Localization and Detection
Oct 13, 2021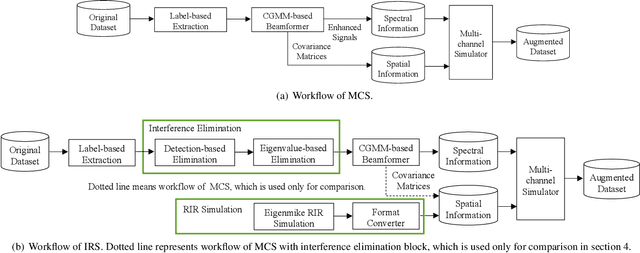
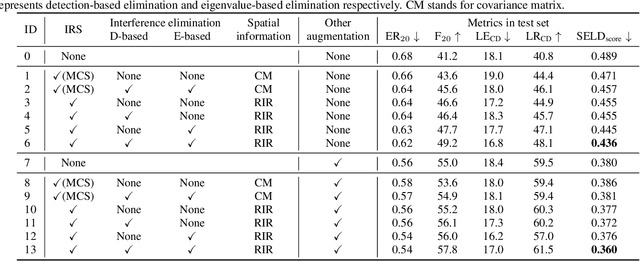
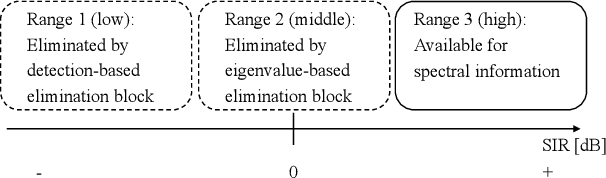
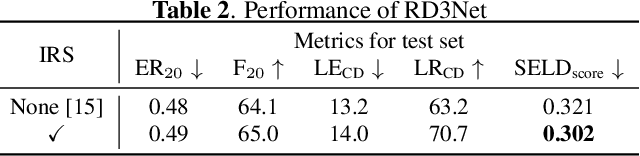
Recording and annotating real sound events for a sound event localization and detection (SELD) task is time consuming, and data augmentation techniques are often favored when the amount of data is limited. However, how to augment the spatial information in a dataset, including unlabeled directional interference events, remains an open research question. Furthermore, directional interference events make it difficult to accurately extract spatial characteristics from target sound events. To address this problem, we propose an impulse response simulation framework (IRS) that augments spatial characteristics using simulated room impulse responses (RIR). RIRs corresponding to a microphone array assumed to be placed in various rooms are accurately simulated, and the source signals of the target sound events are extracted from a mixture. The simulated RIRs are then convolved with the extracted source signals to obtain an augmented multi-channel training dataset. Evaluation results obtained using the TAU-NIGENS Spatial Sound Events 2021 dataset show that the IRS contributes to improving the overall SELD performance. Additionally, we conducted an ablation study to discuss the contribution and need for each component within the IRS.
Enhanced Fast Boolean Matching based on Sensitivity Signatures Pruning
Nov 11, 2021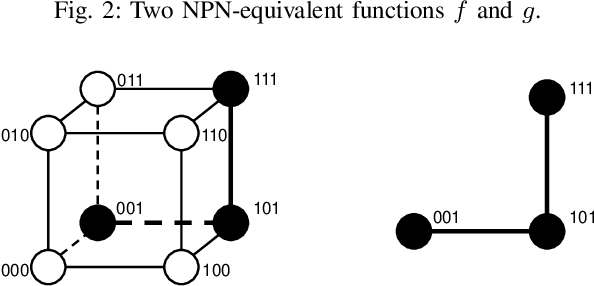
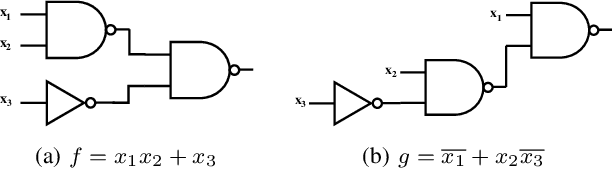
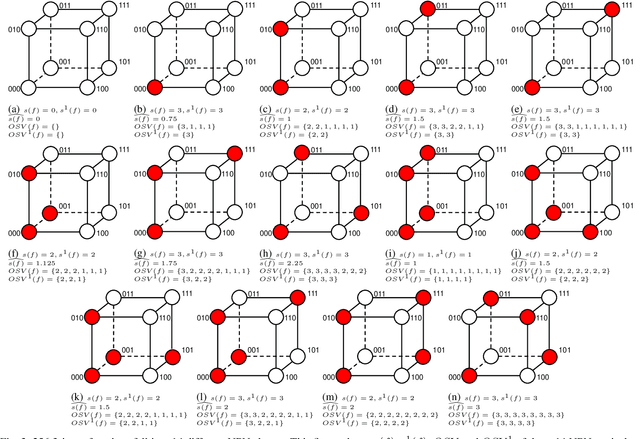
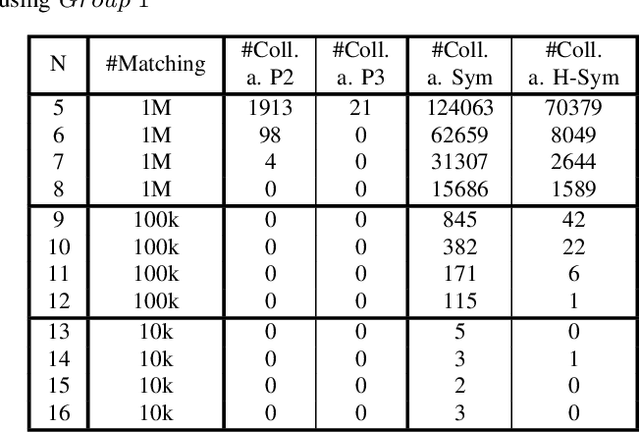
Boolean matching is significant to digital integrated circuits design. An exhaustive method for Boolean matching is computationally expensive even for functions with only a few variables, because the time complexity of such an algorithm for an n-variable Boolean function is $O(2^{n+1}n!)$. Sensitivity is an important characteristic and a measure of the complexity of Boolean functions. It has been used in analysis of the complexity of algorithms in different fields. This measure could be regarded as a signature of Boolean functions and has great potential to help reduce the search space of Boolean matching. In this paper, we introduce Boolean sensitivity into Boolean matching and design several sensitivity-related signatures to enhance fast Boolean matching. First, we propose some new signatures that relate sensitivity to Boolean equivalence. Then, we prove that these signatures are prerequisites for Boolean matching, which we can use to reduce the search space of the matching problem. Besides, we develop a fast sensitivity calculation method to compute and compare these signatures of two Boolean functions. Compared with the traditional cofactor and symmetric detection methods, sensitivity is a series of signatures of another dimension. We also show that sensitivity can be easily integrated into traditional methods and distinguish the mismatched Boolean functions faster. To the best of our knowledge, this is the first work that introduces sensitivity to Boolean matching. The experimental results show that sensitivity-related signatures we proposed in this paper can reduce the search space to a very large extent, and perform up to 3x speedup over the state-of-the-art Boolean matching methods.