 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communicating Inferred Goals with Passive Augmented Reality and Active Haptic Feedback
Sep 03, 2021
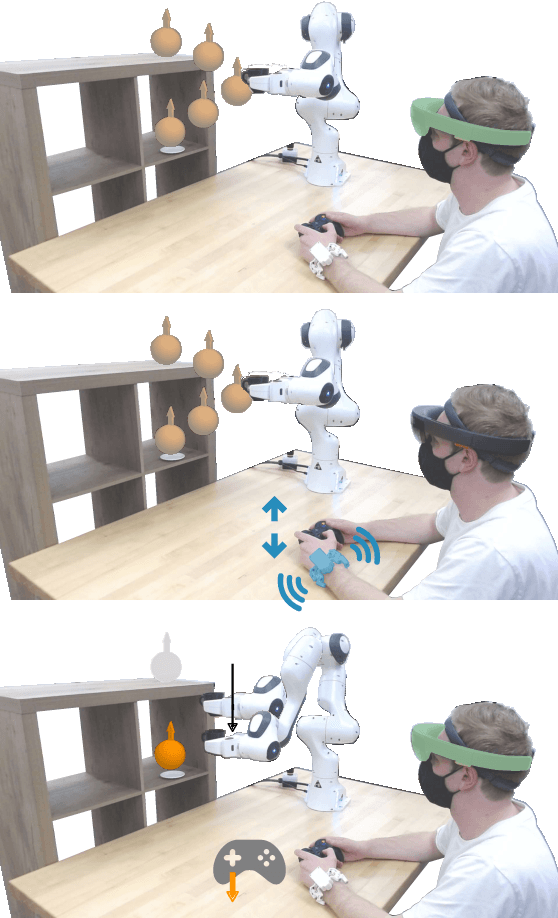
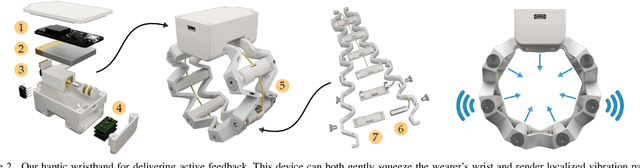

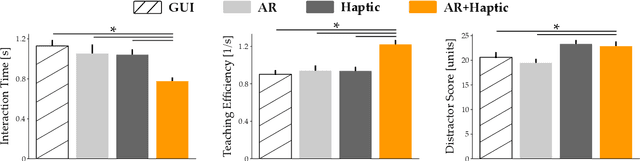
Robots learn as they interact with humans. Consider a human teleoperating an assistive robot arm: as the human guides and corrects the arm's motion, the robot gathers information about the human's desired task. But how does the human know what their robot has inferred? Today's approaches often focus on conveying intent: for instance, upon legible motions or gestures to indicate what the robot is planning. However, closing the loop on robot inference requires more than just revealing the robot's current policy: the robot should also display the alternatives it thinks are likely, and prompt the human teacher when additional guidance is necessary. In this paper we propose a multimodal approach for communicating robot inference that combines both passive and active feedback. Specifically, we leverage information-rich augmented reality to passively visualize what the robot has inferred, and attention-grabbing haptic wristbands to actively prompt and direct the human's teaching. We apply our system to shared autonomy tasks where the robot must infer the human's goal in real-time. Within this context, we integrate passive and active modalities into a single algorithmic framework that determines when and which type of feedback to provide. Combining both passive and active feedback experimentally outperforms single modality baselines; during an in-person user study, we demonstrate that our integrated approach increases how efficiently humans teach the robot while simultaneously decreasing the amount of time humans spend interacting with the robot. Videos here: https://youtu.be/swq_u4iIP-g
Powerline Tracking with Event Cameras
Aug 01, 2021

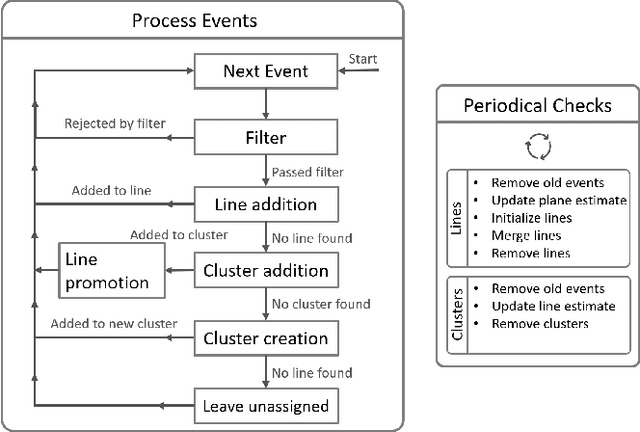
Autonomous inspection of powerlines with quadrotors is challenging. Flights require persistent perception to keep a close look at the lines. We propose a method that uses event cameras to robustly track powerlines. Event cameras are inherently robust to motion blur, have low latency, and high dynamic range. Such properties are advantageous for autonomous inspection of powerlines with drones, where fast motions and challenging illumination conditions are ordinary. Our method identifies lines in the stream of events by detecting planes in the spatio-temporal signal, and tracks them through time. The implementation runs onboard and is capable of detecting multiple distinct lines in real time with rates of up to $320$ thousand events per second. The performance is evaluated in real-world flights along a powerline. The tracker is able to persistently track the powerlines, with a mean lifetime of the line $10\times$ longer than existing approaches.
Efficient Multiple Constraint Acquisition
Sep 13, 2021

Constraint acquisition systems such as QuAcq and MultiAcq can assist non-expert users to model their problems as constraint networks by classifying (partial) examples as positive or negative. For each negative example, the former focuses on one constraint of the target network, while the latter can learn a maximum number of constraints. Two bottlenecks of the acquisition process where both these algorithms encounter problems are the large number of queries required to reach convergence, and the high cpu times needed to generate queries, especially near convergence. In this paper we propose algorithmic and heuristic methods to deal with both these issues. We first describe an algorithm, called MQuAcq, that blends the main idea of MultiAcq into QuAcq resulting in a method that learns as many constraints as MultiAcq does after a negative example, but with a lower complexity. A detailed theoretical analysis of the proposed algorithm is also presented. %We also present a technique that boosts the performance of constraint acquisition by reducing the number of queries significantly. Then we turn our attention to query generation which is a significant but rather overlooked part of the acquisition process. We describe %in detail how query generation in a typical constraint acquisition system operates, and we propose heuristics for improving its efficiency. Experiments from various domains demonstrate that our resulting algorithm that integrates all the new techniques does not only generate considerably fewer queries than QuAcq and MultiAcq, but it is also by far faster than both of them, in average query generation time as well as in total run time, and also largely alleviates the premature convergence problem.
Ensemble Neural Representation Networks
Oct 07, 2021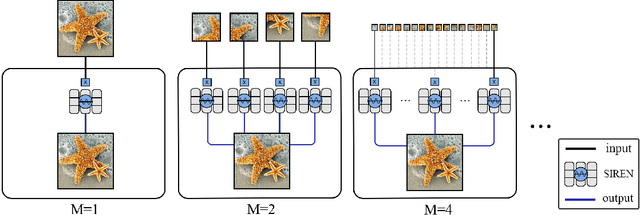
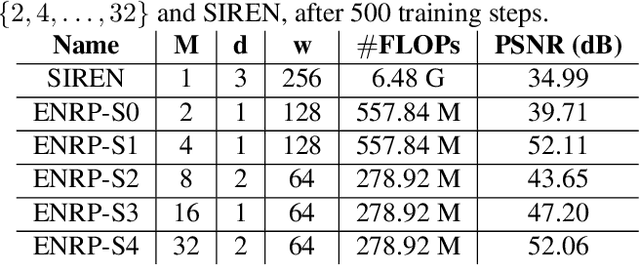
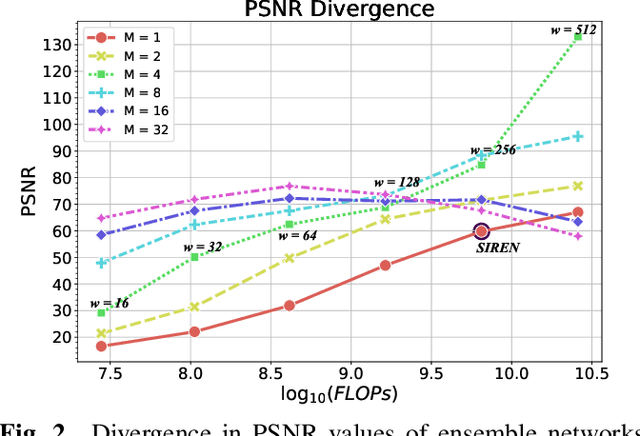

Implicit Neural Representation (INR) has recently attracted considerable attention for storing various types of signals in continuous forms. The existing INR networks require lengthy training processes and high-performance computational resources. In this paper, we propose a novel sub-optimal ensemble architecture for INR that resolves the aforementioned problems. In this architecture, the representation task is divided into several sub-tasks done by independent sub-networks. We show that the performance of the proposed ensemble INR architecture may decrease if the dimensions of sub-networks increase. Hence, it is vital to suggest an optimization algorithm to find the sub-optimal structure of the ensemble network, which is done in this paper. According to the simulation results, the proposed architecture not only has significantly fewer floating-point operations (FLOPs) and less training time, but it also has better performance in terms of Peak Signal to Noise Ratio (PSNR) compared to those of its counterparts.
Improved SAT models for NFA learning
Jul 13, 2021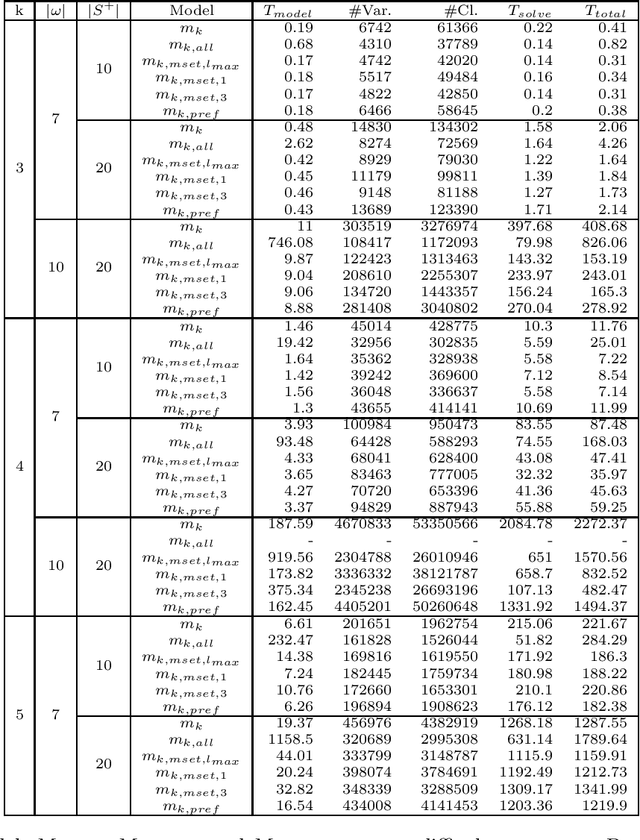
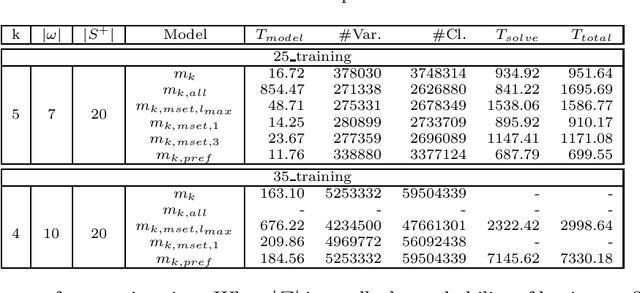
Grammatical inference is concerned with the study of algorithms for learning automata and grammars from words. We focus on learning Nondeterministic Finite Automaton of size k from samples of words. To this end, we formulate the problem as a SAT model. The generated SAT instances being enormous, we propose some model improvements, both in terms of the number of variables, the number of clauses, and clauses size. These improvements significantly reduce the instances, but at the cost of longer generation time. We thus try to balance instance size vs. generation and solving time. We also achieved some experimental comparisons and we analyzed our various model improvements.
Detecting Hardly Visible Roads in Low-Resolution Satellite Time Series Data
Dec 04, 2019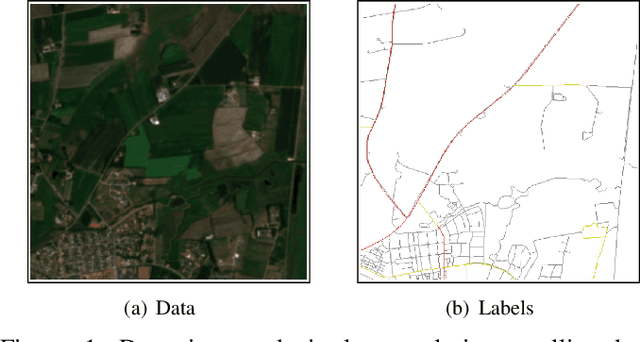

Massive amounts of satellite data have been gathered over time, holding the potential to unveil a spatiotemporal chronicle of the surface of Earth. These data allow scientists to investigate various important issues, such as land use changes, on a global scale. However, not all land-use phenomena are equally visible on satellite imagery. In particular, the creation of an inventory of the planet's road infrastructure remains a challenge, despite being crucial to analyze urbanization patterns and their impact. Towards this end, this work advances data-driven approaches for the automatic identification of roads based on open satellite data. Given the typical resolutions of these historical satellite data, we observe that there is inherent variation in the visibility of different road types. Based on this observation, we propose two deep learning frameworks that extend state-of-the-art deep learning methods by formalizing road detection as an ordinal classification task. In contrast to related schemes, one of the two models also resorts to satellite time series data that are potentially affected by missing data and cloud occlusion. Taking these time series data into account eliminates the need to manually curate datasets of high-quality image tiles, substantially simplifying the application of such models on a global scale. We evaluate our approaches on a dataset that is based on Sentinel~2 satellite imagery and OpenStreetMap vector data. Our results indicate that the proposed models can successfully identify large and medium-sized roads. We also discuss opportunities and challenges related to the detection of roads and other infrastructure on a global scale.
SRT3D: A Sparse Region-Based 3D Object Tracking Approach for the Real World
Oct 25, 2021
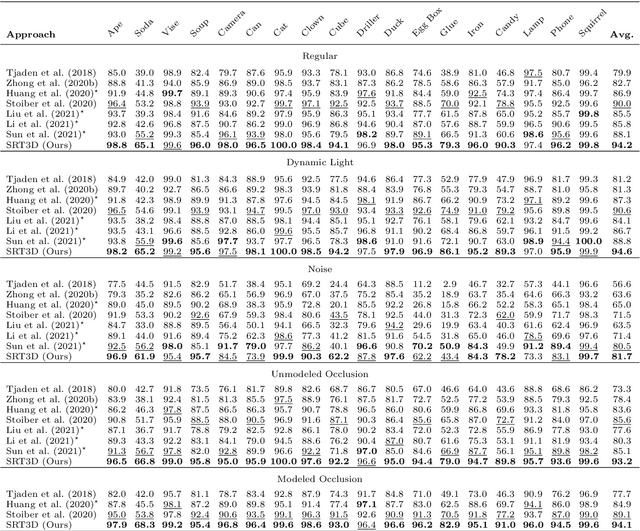
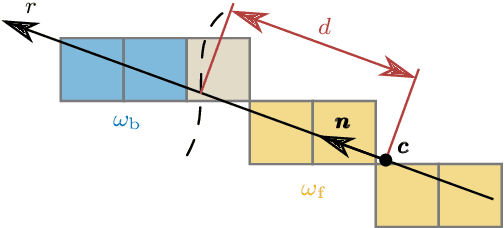
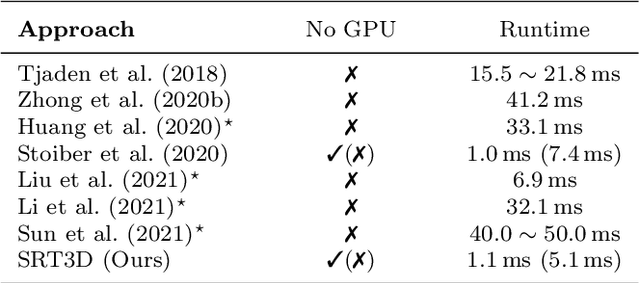
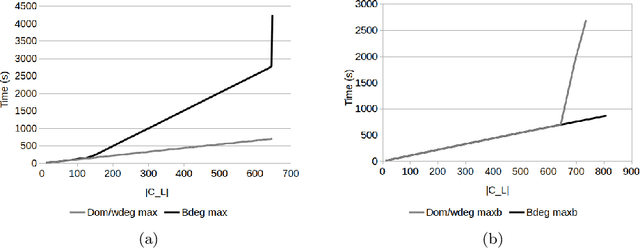
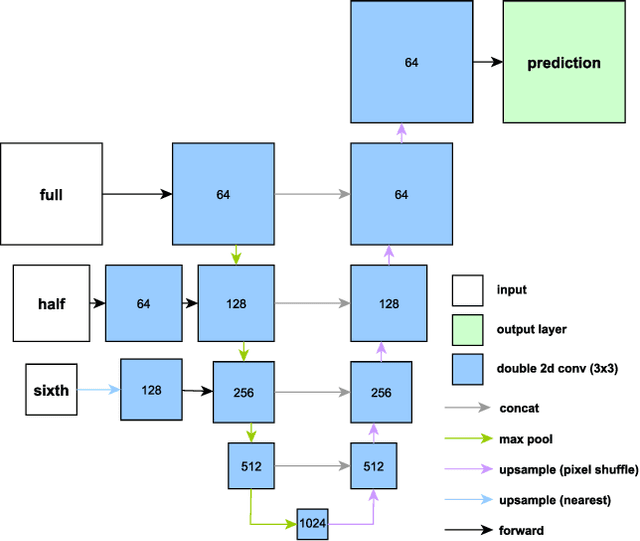
Region-based methods have become increasingly popular for model-based, monocular 3D tracking of texture-less objects in cluttered scenes. However, while they achieve state-of-the-art results, most methods are computationally expensive, requiring significant resources to run in real-time. In the following, we build on our previous work and develop SRT3D, a sparse region-based approach to 3D object tracking that bridges this gap in efficiency. Our method considers image information sparsely along so-called correspondence lines that model the probability of the object's contour location. We thereby improve on the current state of the art and introduce smoothed step functions that consider a defined global and local uncertainty. For the resulting probabilistic formulation, a thorough analysis is provided. Finally, we use a pre-rendered sparse viewpoint model to create a joint posterior probability for the object pose. The function is maximized using second-order Newton optimization with Tikhonov regularization. During the pose estimation, we differentiate between global and local optimization, using a novel approximation for the first-order derivative employed in the Newton method. In multiple experiments, we demonstrate that the resulting algorithm improves the current state of the art both in terms of runtime and quality, performing particularly well for noisy and cluttered images encountered in the real world.
Architopes: An Architecture Modification for Composite Pattern Learning, Increased Expressiveness, and Reduced Training Time
Jun 24, 2020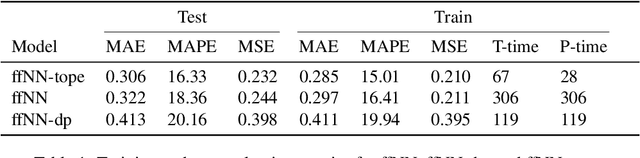
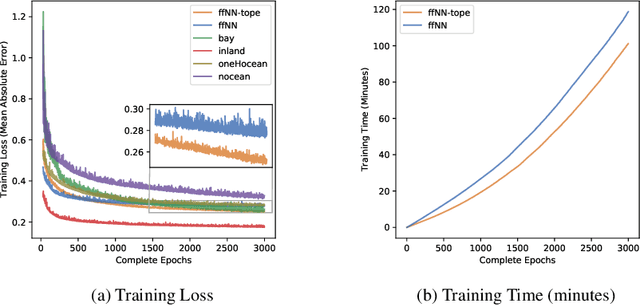


We introduce a simple neural network architecture modification that enables composite pattern learning, increases expressiveness, and reduces training time. This expressibility improvement is explained by the density of the modified architecture in a new refined local $L^p$-space describing composite patterns. In contrast, most feed-forward neural network architectures with sigmoid activation functions are shown not to be dense in this space. In practice, restrictions have to be placed on the dimension of any architecture's parameter space. $L^1$ approximation bounds are obtained in terms of the number of the trainable parameters. Likewise, convergence guarantees are obtained as the imposed restrictions are asymptotically removed. By exploiting the new architecture's structure, a parallelizable training meta-algorithm is provided, and numerical evaluations are made using the California housing dataset.
Differentially Private Stochastic Optimization: New Results in Convex and Non-Convex Settings
Jul 12, 2021
We study differentially private stochastic optimization in convex and non-convex settings. For the convex case, we focus on the family of non-smooth generalized linear losses (GLLs). Our algorithm for the $\ell_2$ setting achieves optimal excess population risk in near-linear time, while the best known differentially private algorithms for general convex losses run in super-linear time. Our algorithm for the $\ell_1$ setting has nearly-optimal excess population risk $\tilde{O}\big(\sqrt{\frac{\log{d}}{n}}\big)$, and circumvents the dimension dependent lower bound of [AFKT21] for general non-smooth convex losses. In the differentially private non-convex setting, we provide several new algorithms for approximating stationary points of the population risk. For the $\ell_1$-case with smooth losses and polyhedral constraint, we provide the first nearly dimension independent rate, $\tilde O\big(\frac{\log^{2/3}{d}}{{n^{1/3}}}\big)$ in linear time. For the constrained $\ell_2$-case, with smooth losses, we obtain a linear-time algorithm with rate $\tilde O\big(\frac{1}{n^{3/10}d^{1/10}}+\big(\frac{d}{n^2}\big)^{1/5}\big)$. Finally, for the $\ell_2$-case we provide the first method for {\em non-smooth weakly convex} stochastic optimization with rate $\tilde O\big(\frac{1}{n^{1/4}}+\big(\frac{d}{n^2}\big)^{1/6}\big)$ which matches the best existing non-private algorithm when $d= O(\sqrt{n})$. We also extend all our results above for the non-convex $\ell_2$ setting to the $\ell_p$ setting, where $1 < p \leq 2$, with only polylogarithmic (in the dimension) overhead in the rates.
On the Latent Holes of VAEs for Text Generation
Oct 07, 2021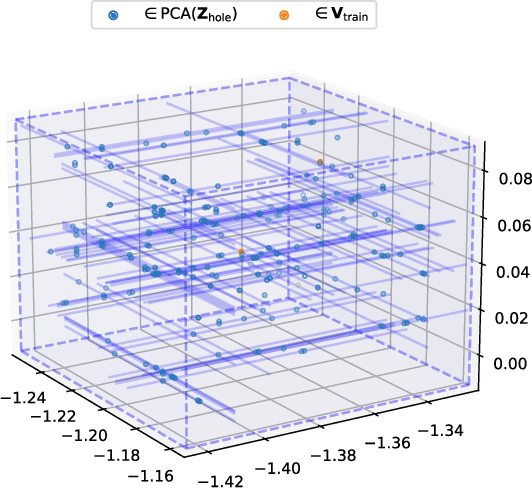

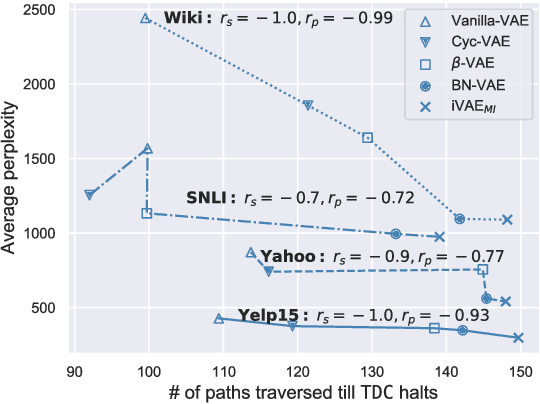
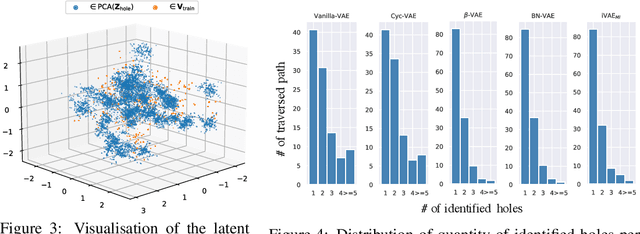
In this paper, we provide the first focused study on the discontinuities (aka. holes) in the latent space of Variational Auto-Encoders (VAEs), a phenomenon which has been shown to have a detrimental effect on model capacity. When investigating latent holes, existing works are exclusively centred around the encoder network and they merely explore the existence of holes. We tackle these limitations by proposing a highly efficient Tree-based Decoder-Centric (TDC) algorithm for latent hole identification, with a focal point on the text domain. In contrast to past studies, our approach pays attention to the decoder network, as a decoder has a direct impact on the model's output quality. Furthermore, we provide, for the first time, in-depth empirical analysis of the latent hole phenomenon, investigating several important aspects such as how the holes impact VAE algorithms' performance on text generation, and how the holes are distributed in the latent space.