 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Back to Basics: Efficient Network Compression via IMP
Nov 01, 2021
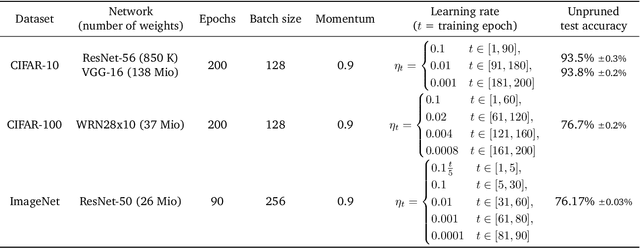
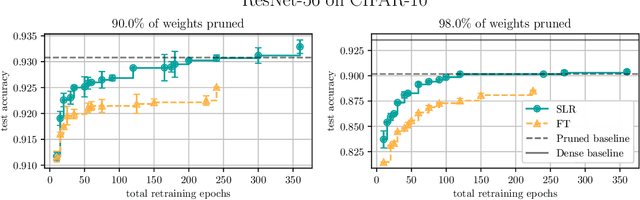
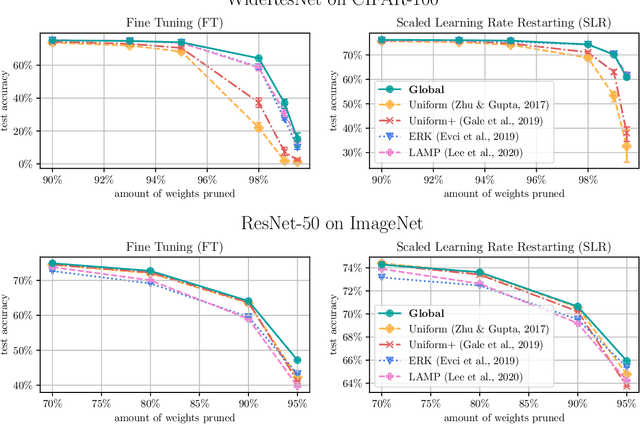
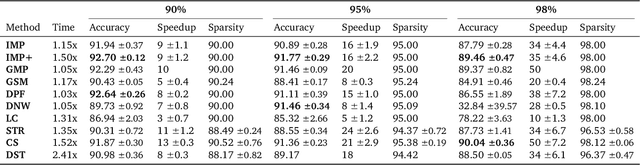
Network pruning is a widely used technique for effectively compressing Deep Neural Networks with little to no degradation in performance during inference. Iterative Magnitude Pruning (IMP) is one of the most established approaches for network pruning, consisting of several iterative training and pruning steps, where a significant amount of the network's performance is lost after pruning and then recovered in the subsequent retraining phase. While commonly used as a benchmark reference, it is often argued that a) it reaches suboptimal states by not incorporating sparsification into the training phase, b) its global selection criterion fails to properly determine optimal layer-wise pruning rates and c) its iterative nature makes it slow and non-competitive. In light of recently proposed retraining techniques, we investigate these claims through rigorous and consistent experiments where we compare IMP to pruning-during-training algorithms, evaluate proposed modifications of its selection criterion and study the number of iterations and total training time actually required. We find that IMP with SLR for retraining can outperform state-of-the-art pruning-during-training approaches without or with only little computational overhead, that the global magnitude selection criterion is largely competitive with more complex approaches and that only few retraining epochs are needed in practice to achieve most of the sparsity-vs.-performance tradeoff of IMP. Our goals are both to demonstrate that basic IMP can already provide state-of-the-art pruning results on par with or even outperforming more complex or heavily parameterized approaches and also to establish a more realistic yet easily realisable baseline for future research.
White blood cell subtype detection and classification
Aug 10, 2021
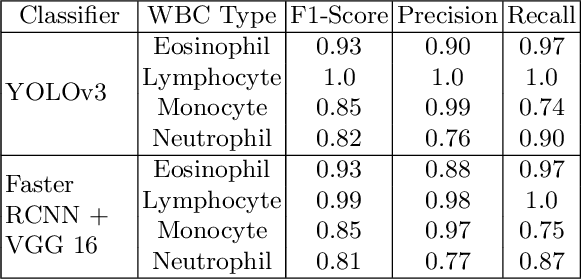
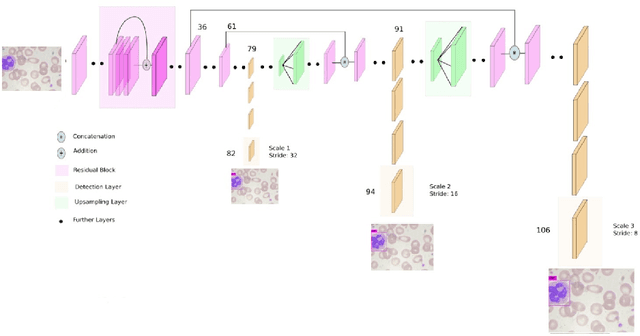
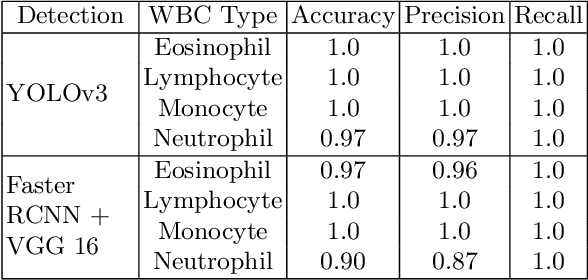
Machine learning has endless applications in the health care industry. White blood cell classification is one of the interesting and promising area of research. The classification of the white blood cells plays an important part in the medical diagnosis. In practise white blood cell classification is performed by the haematologist by taking a small smear of blood and careful examination under the microscope. The current procedures to identify the white blood cell subtype is more time taking and error-prone. The computer aided detection and diagnosis of the white blood cells tend to avoid the human error and reduce the time taken to classify the white blood cells. In the recent years several deep learning approaches have been developed in the context of classification of the white blood cells that are able to identify but are unable to localize the positions of white blood cells in the blood cell image. Following this, the present research proposes to utilize YOLOv3 object detection technique to localize and classify the white blood cells with bounding boxes. With exhaustive experimental analysis, the proposed work is found to detect the white blood cell with 99.2% accuracy and classify with 90% accuracy.
A Deep Learning Generative Model Approach for Image Synthesis of Plant Leaves
Nov 05, 2021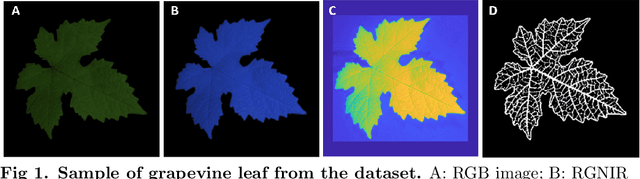
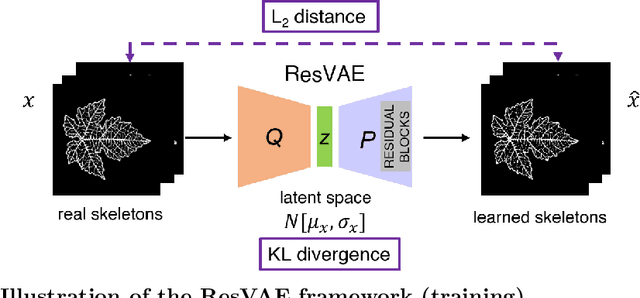
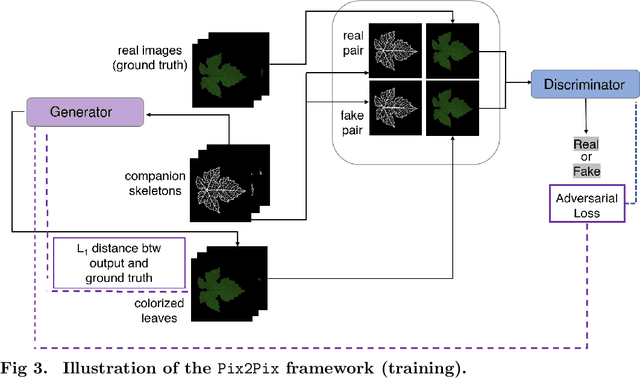
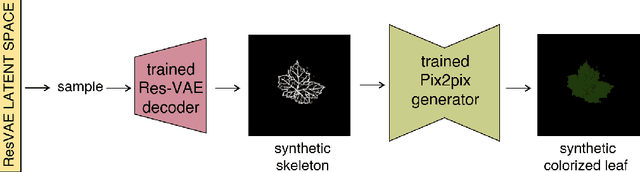
Objectives. We generate via advanced Deep Learning (DL) techniques artificial leaf images in an automatized way. We aim to dispose of a source of training samples for AI applications for modern crop management. Such applications require large amounts of data and, while leaf images are not truly scarce, image collection and annotation remains a very time--consuming process. Data scarcity can be addressed by augmentation techniques consisting in simple transformations of samples belonging to a small dataset, but the richness of the augmented data is limited: this motivates the search for alternative approaches. Methods. Pursuing an approach based on DL generative models, we propose a Leaf-to-Leaf Translation (L2L) procedure structured in two steps: first, a residual variational autoencoder architecture generates synthetic leaf skeletons (leaf profile and veins) starting from companions binarized skeletons of real images. In a second step, we perform translation via a Pix2pix framework, which uses conditional generator adversarial networks to reproduce the colorization of leaf blades, preserving the shape and the venation pattern. Results. The L2L procedure generates synthetic images of leaves with a realistic appearance. We address the performance measurement both in a qualitative and a quantitative way; for this latter evaluation, we employ a DL anomaly detection strategy which quantifies the degree of anomaly of synthetic leaves with respect to real samples. Conclusions. Generative DL approaches have the potential to be a new paradigm to provide low-cost meaningful synthetic samples for computer-aided applications. The present L2L approach represents a step towards this goal, being able to generate synthetic samples with a relevant qualitative and quantitative resemblance to real leaves.
ST-DETR: Spatio-Temporal Object Traces Attention Detection Transformer
Jul 24, 2021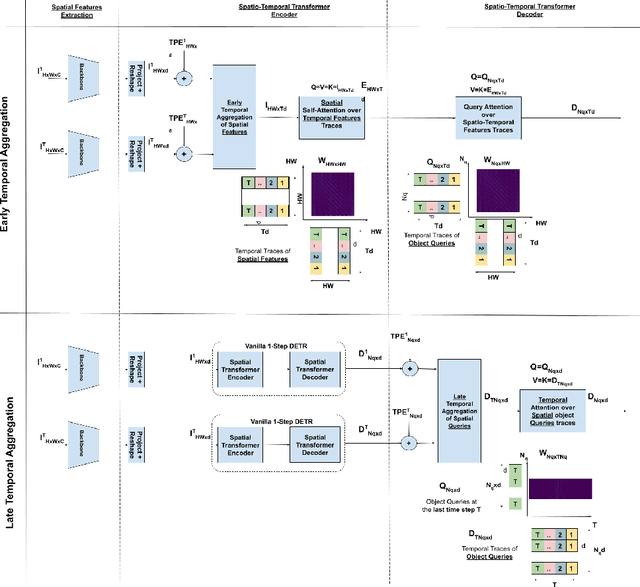

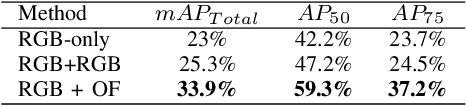

We propose ST-DETR, a Spatio-Temporal Transformer-based architecture for object detection from a sequence of temporal frames. We treat the temporal frames as sequences in both space and time and employ the full attention mechanisms to take advantage of the features correlations over both dimensions. This treatment enables us to deal with frames sequence as temporal object features traces over every location in the space. We explore two possible approaches; the early spatial features aggregation over the temporal dimension, and the late temporal aggregation of object query spatial features. Moreover, we propose a novel Temporal Positional Embedding technique to encode the time sequence information. To evaluate our approach, we choose the Moving Object Detection (MOD)task, since it is a perfect candidate to showcase the importance of the temporal dimension. Results show a significant 5% mAP improvement on the KITTI MOD dataset over the 1-step spatial baseline.
Learning to Efficiently Sample from Diffusion Probabilistic Models
Jun 07, 2021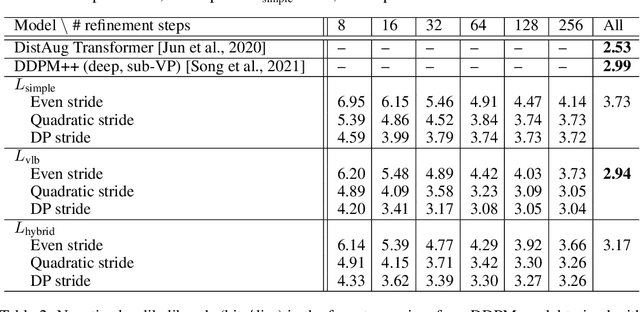
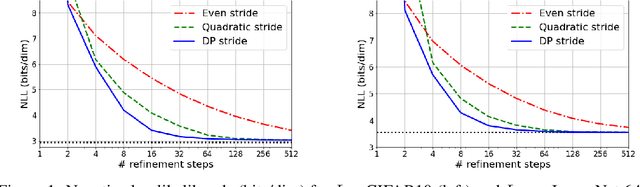
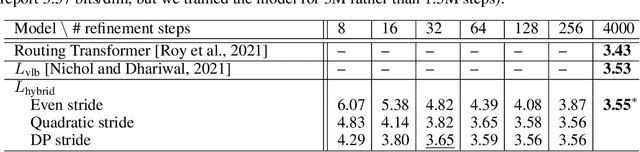
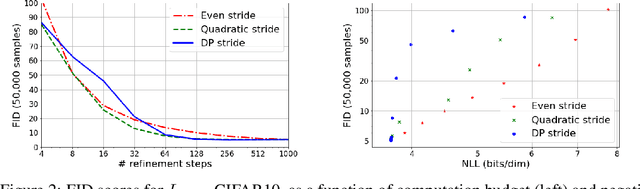
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
Automatic Generation of Word Problems for Academic Education via Natural Language Processing (NLP)
Sep 30, 2021
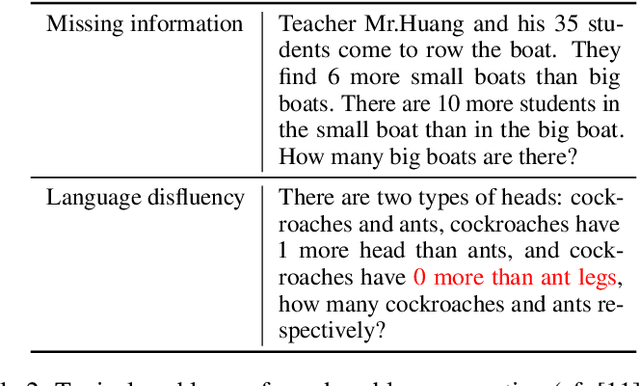


Digital learning platforms enable students to learn on a flexible and individual schedule as well as providing instant feedback mechanisms. The field of STEM education requires students to solve numerous training exercises to grasp underlying concepts. It is apparent that there are restrictions in current online education in terms of exercise diversity and individuality. Many exercises show little variance in structure and content, hindering the adoption of abstraction capabilities by students. This thesis proposes an approach to generate diverse, context rich word problems. In addition to requiring the generated language to be grammatically correct, the nature of word problems implies additional constraints on the validity of contents. The proposed approach is proven to be effective in generating valid word problems for mathematical statistics. The experimental results present a tradeoff between generation time and exercise validity. The system can easily be parametrized to handle this tradeoff according to the requirements of specific use cases.
Fast Training of Neural Lumigraph Representations using Meta Learning
Jun 28, 2021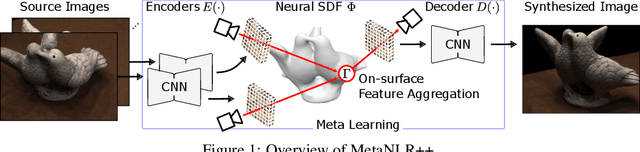


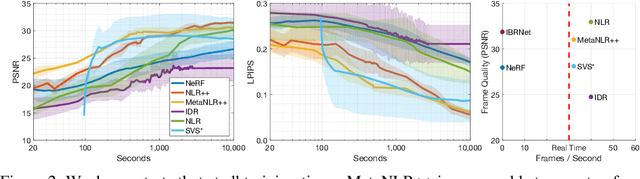
Novel view synthesis is a long-standing problem in machine learning and computer vision. Significant progress has recently been made in developing neural scene representations and rendering techniques that synthesize photorealistic images from arbitrary views. These representations, however, are extremely slow to train and often also slow to render. Inspired by neural variants of image-based rendering, we develop a new neural rendering approach with the goal of quickly learning a high-quality representation which can also be rendered in real-time. Our approach, MetaNLR++, accomplishes this by using a unique combination of a neural shape representation and 2D CNN-based image feature extraction, aggregation, and re-projection. To push representation convergence times down to minutes, we leverage meta learning to learn neural shape and image feature priors which accelerate training. The optimized shape and image features can then be extracted using traditional graphics techniques and rendered in real time. We show that MetaNLR++ achieves similar or better novel view synthesis results in a fraction of the time that competing methods require.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021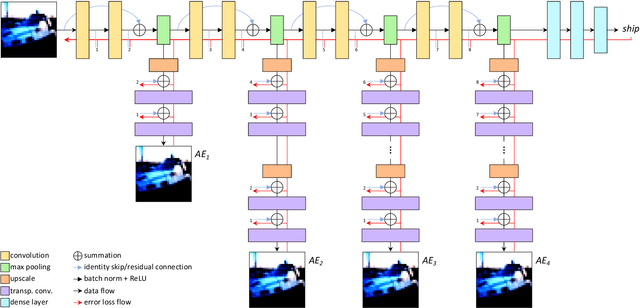
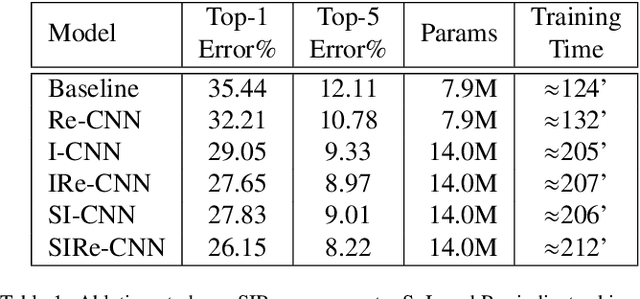

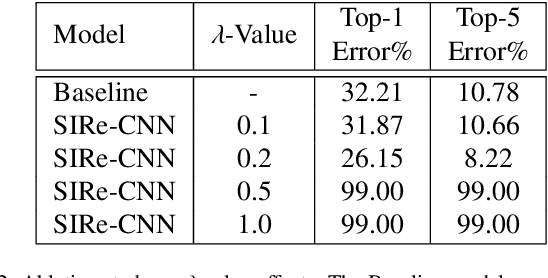
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019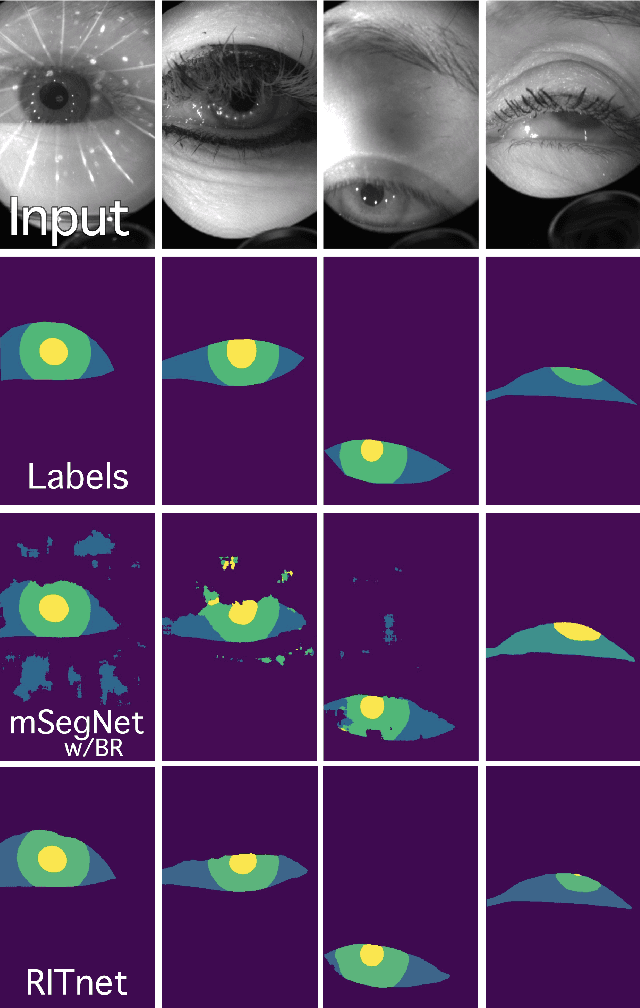
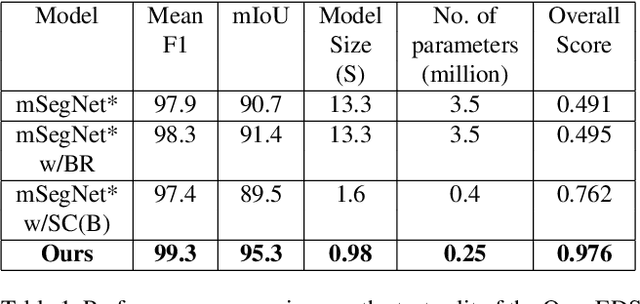
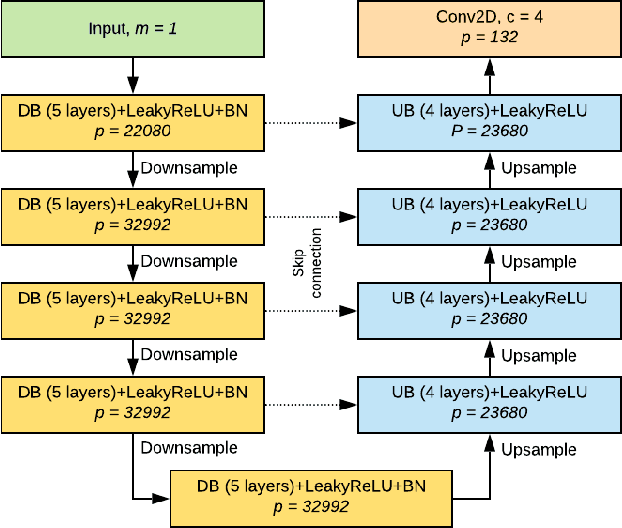
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
Real-time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-driving Images
Feb 24, 2020
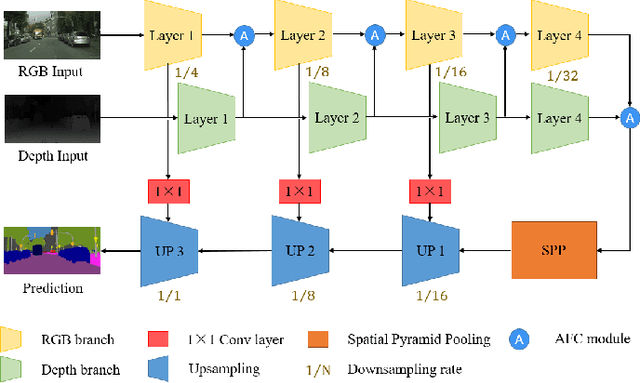
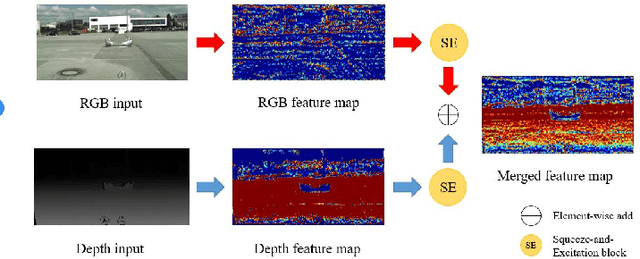

Semantic segmentation has made striking progress due to the success of deep convolutional neural networks. Considering the demand of autonomous driving, real-time semantic segmentation has become a research hotspot these years. However, few real-time RGB-D fusion semantic segmentation studies are carried out despite readily accessible depth information nowadays. In this paper, we propose a real-time fusion semantic segmentation network termed RFNet that efficiently exploits complementary features from depth information to enhance the performance in an attention-augmented way, while running swiftly that is a necessity for autonomous vehicles applications. Multi-dataset training is leveraged to incorporate unexpected small obstacle detection, enriching the recognizable classes required to face unforeseen hazards in the real world. A comprehensive set of experiments demonstrates the effectiveness of our framework. On \textit{Cityscapes}, Our method outperforms previous state-of-the-art semantic segmenters, with excellent accuracy and 22Hz inference speed at the full 2048$\times$1024 resolution, outperforming most existing RGB-D networks.