 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Static UWB Radar-based Passive Human Tracking Using COTS Devices
Sep 27, 2021

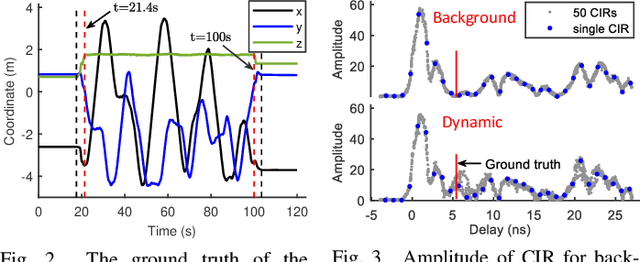
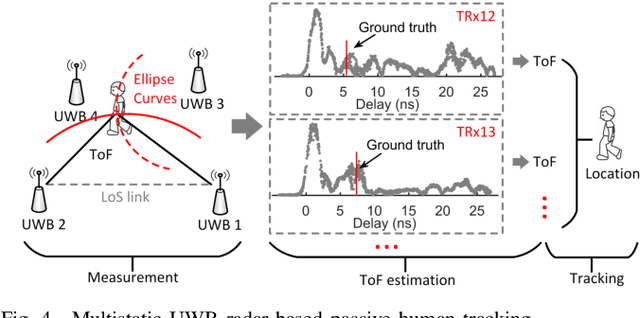
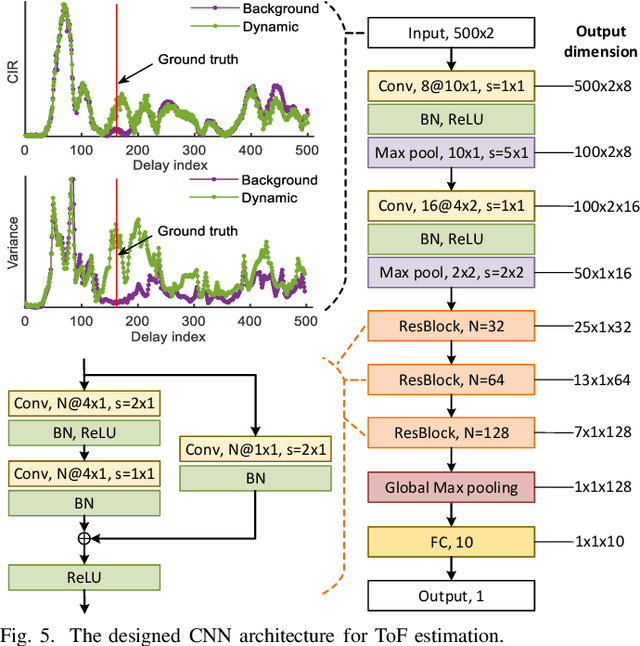
Due to its high delay resolution, the ultra-wideband (UWB) technique has been widely adopted for fine-grained indoor localization. Instead of active positioning, multi-static UWB radar-based passive human tracking is explored using commercial off-the-shelf (COTS) devices. To extract the time-of-flight (ToF) reflected by the moving person, channel impulse responses (CIR) and the corresponding variances are used to train the convolutional neural networks (CNN) model. Particle filter algorithm is adopted to track the moving person based on the extracted ToFs of all pairs of links. Experimental results show that the proposed CIR- and variance-based CNN models achieve 30.12-cm and 29.04-cm root-mean-square errors (RMSEs), respectively. Especially, the variance-based CNN model is robust to the scenario changing and promising for practical applications.
Inter Extreme Points Geodesics for Weakly Supervised Segmentation
Jul 01, 2021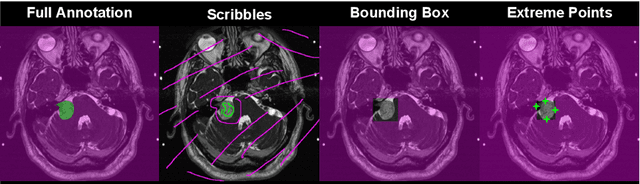
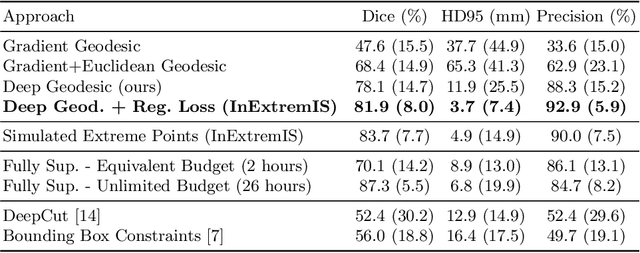
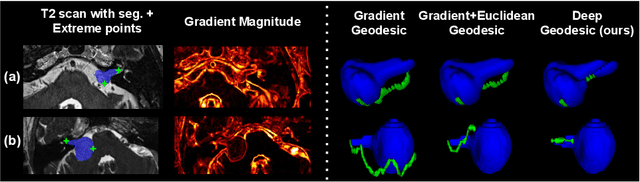
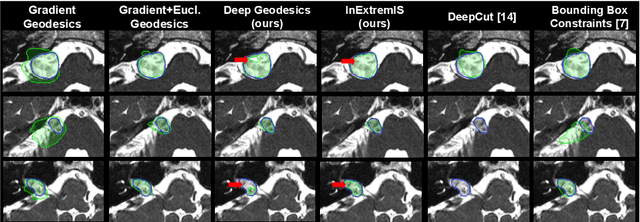
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.
Advancement of Deep Learning in Pneumonia and Covid-19 Classification and Localization: A Qualitative and Quantitative Analysis
Nov 16, 2021
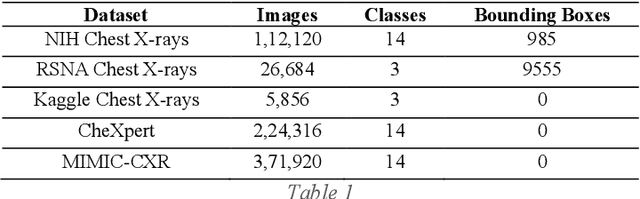
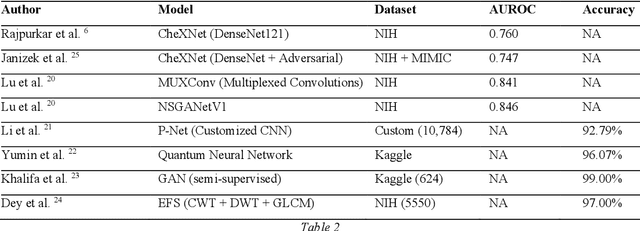
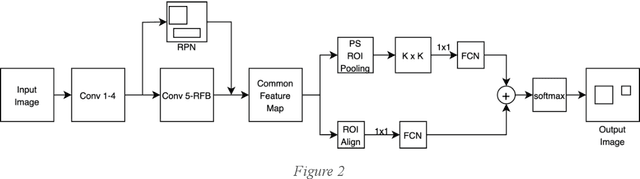
Around 450 million people are affected by pneumonia every year which results in 2.5 million deaths. Covid-19 has also affected 181 million people which has lead to 3.92 million casualties. The chances of death in both of these diseases can be significantly reduced if they are diagnosed early. However, the current methods of diagnosing pneumonia (complaints + chest X-ray) and covid-19 (RT-PCR) require the presence of expert radiologists and time, respectively. With the help of Deep Learning models, pneumonia and covid-19 can be detected instantly from Chest X-rays or CT scans. This way, the process of diagnosing Pneumonia/Covid-19 can be made more efficient and widespread. In this paper, we aim to elicit, explain, and evaluate, qualitatively and quantitatively, major advancements in deep learning methods aimed at detecting or localizing community-acquired pneumonia (CAP), viral pneumonia, and covid-19 from images of chest X-rays and CT scans. Being a systematic review, the focus of this paper lies in explaining deep learning model architectures which have either been modified or created from scratch for the task at hand wiwth focus on generalizability. For each model, this paper answers the question of why the model is designed the way it is, the challenges that a particular model overcomes, and the tradeoffs that come with modifying a model to the required specifications. A quantitative analysis of all models described in the paper is also provided to quantify the effectiveness of different models with a similar goal. Some tradeoffs cannot be quantified, and hence they are mentioned explicitly in the qualitative analysis, which is done throughout the paper. By compiling and analyzing a large quantum of research details in one place with all the datasets, model architectures, and results, we aim to provide a one-stop solution to beginners and current researchers interested in this field.
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021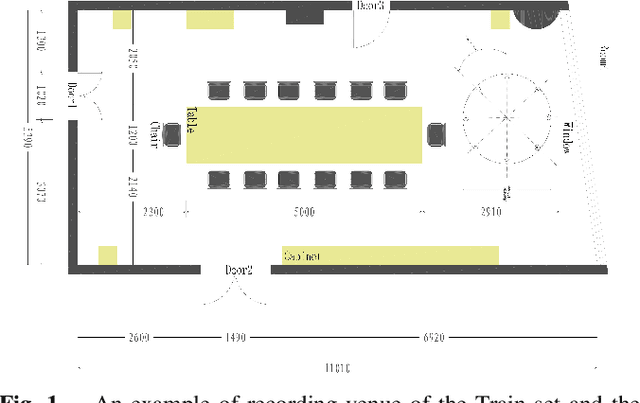
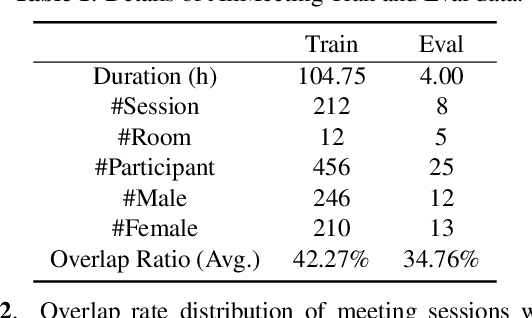
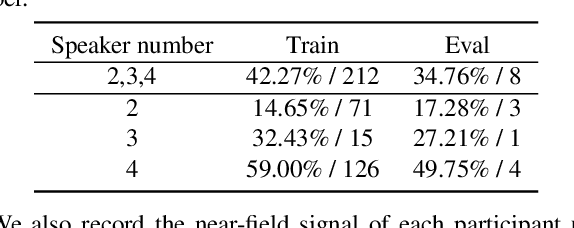
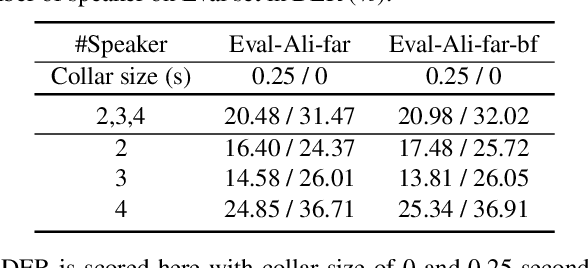
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
Toward a Unified Framework for Debugging Gray-box Models
Sep 23, 2021
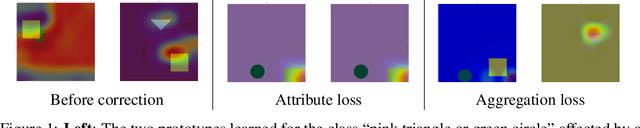
We are concerned with debugging concept-based gray-box models (GBMs). These models acquire task-relevant concepts appearing in the inputs and then compute a prediction by aggregating the concept activations. This work stems from the observation that in GBMs both the concepts and the aggregation function can be affected by different bugs, and that correcting these bugs requires different kinds of corrective supervision. To this end, we introduce a simple schema for identifying and prioritizing bugs in both components, discuss possible implementations and open problems. At the same time, we introduce a new loss function for debugging the aggregation step that extends existing approaches to align the model's explanations to GBMs by making them robust to how the concepts change during training.
Fast PDE-constrained optimization via self-supervised operator learning
Oct 25, 2021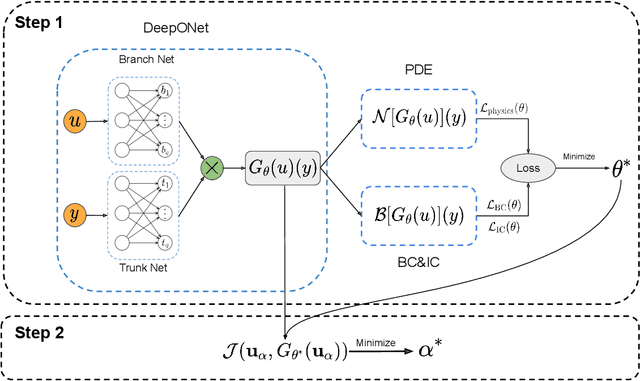

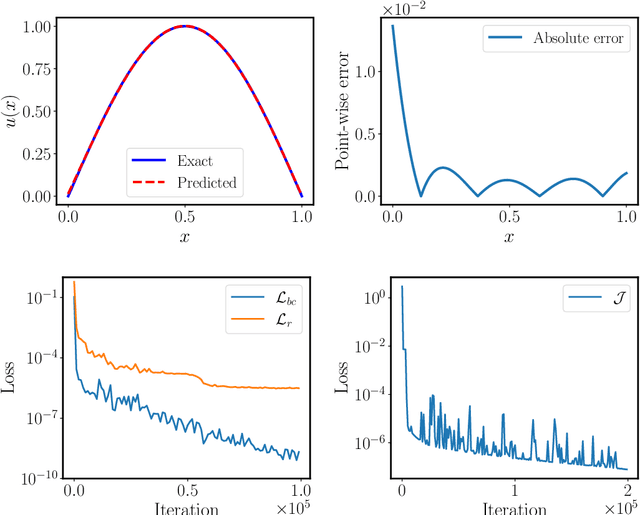
Design and optimal control problems are among the fundamental, ubiquitous tasks we face in science and engineering. In both cases, we aim to represent and optimize an unknown (black-box) function that associates a performance/outcome to a set of controllable variables through an experiment. In cases where the experimental dynamics can be described by partial differential equations (PDEs), such problems can be mathematically translated into PDE-constrained optimization tasks, which quickly become intractable as the number of control variables and the cost of experiments increases. In this work we leverage physics-informed deep operator networks (DeepONets) -- a self-supervised framework for learning the solution operator of parametric PDEs -- to build fast and differentiable surrogates for rapidly solving PDE-constrained optimization problems, even in the absence of any paired input-output training data. The effectiveness of the proposed framework will be demonstrated across different applications involving continuous functions as control or design variables, including time-dependent optimal control of heat transfer, and drag minimization of obstacles in Stokes flow. In all cases, we observe that DeepONets can minimize high-dimensional cost functionals in a matter of seconds, yielding a significant speed up compared to traditional adjoint PDE solvers that are typically costly and limited to relatively low-dimensional control/design parametrizations.
Interpretable Classification of Time-Series Data using Efficient Enumerative Techniques
Jul 24, 2019
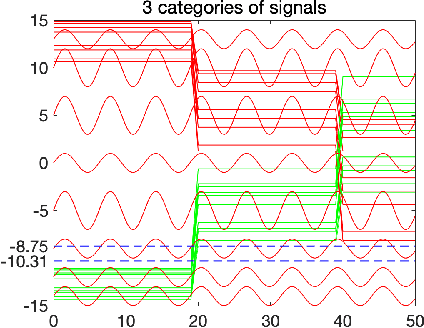
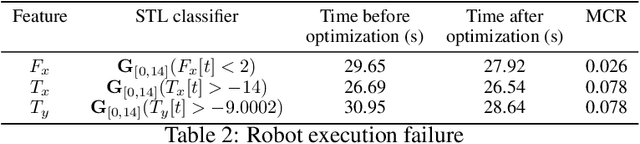
Cyber-physical system applications such as autonomous vehicles, wearable devices, and avionic systems generate a large volume of time-series data. Designers often look for tools to help classify and categorize the data. Traditional machine learning techniques for time-series data offer several solutions to solve these problems; however, the artifacts trained by these algorithms often lack interpretability. On the other hand, temporal logics, such as Signal Temporal Logic (STL) have been successfully used in the formal methods community as specifications of time-series behaviors. In this work, we propose a new technique to automatically learn temporal logic formulae that are able to cluster and classify real-valued time-series data. Previous work on learning STL formulas from data either assumes a formula-template to be given by the user, or assumes some special fragment of STL that enables exploring the formula structure in a systematic fashion. In our technique, we relax these assumptions, and provide a way to systematically explore the space of all STL formulas. As the space of all STL formulas is very large, and contains many semantically equivalent formulas, we suggest a technique to heuristically prune the space of formulas considered. Finally, we illustrate our technique on various case studies from the automotive, transportation and healthcare domain.
Auto White-Balance Correction for Mixed-Illuminant Scenes
Oct 08, 2021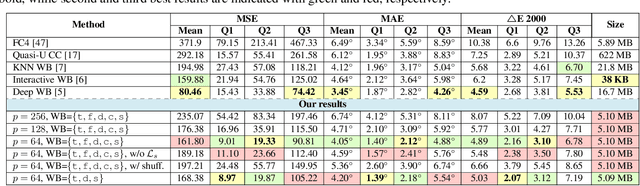

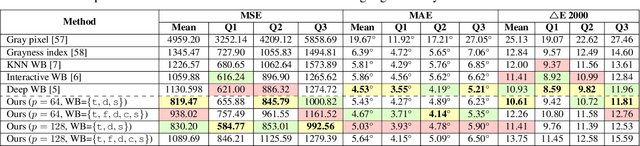

Auto white balance (AWB) is applied by camera hardware at capture time to remove the color cast caused by the scene illumination. The vast majority of white-balance algorithms assume a single light source illuminates the scene; however, real scenes often have mixed lighting conditions. This paper presents an effective AWB method to deal with such mixed-illuminant scenes. A unique departure from conventional AWB, our method does not require illuminant estimation, as is the case in traditional camera AWB modules. Instead, our method proposes to render the captured scene with a small set of predefined white-balance settings. Given this set of rendered images, our method learns to estimate weighting maps that are used to blend the rendered images to generate the final corrected image. Through extensive experiments, we show this proposed method produces promising results compared to other alternatives for single- and mixed-illuminant scene color correction. Our source code and trained models are available at https://github.com/mahmoudnafifi/mixedillWB.
A system for information extraction from scientific texts in Russian
Sep 14, 2021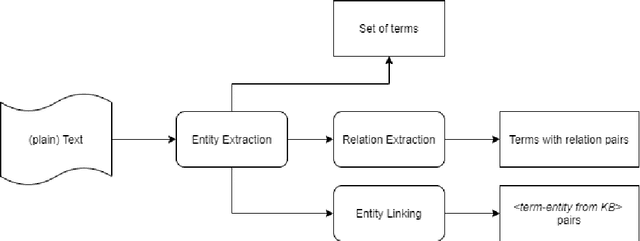
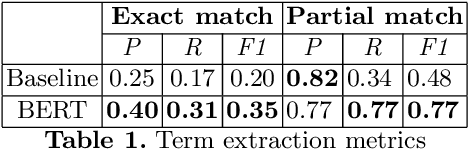
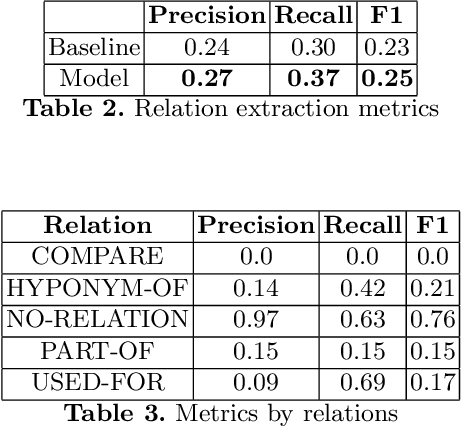
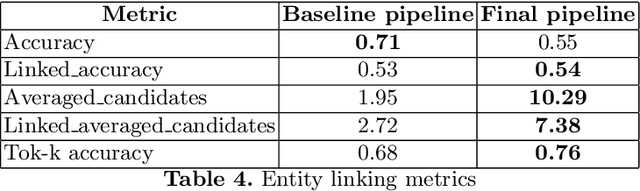
In this paper, we present a system for information extraction from scientific texts in the Russian language. The system performs several tasks in an end-to-end manner: term recognition, extraction of relations between terms, and term linking with entities from the knowledge base. These tasks are extremely important for information retrieval, recommendation systems, and classification. The advantage of the implemented methods is that the system does not require a large amount of labeled data, which saves time and effort for data labeling and therefore can be applied in low- and mid-resource settings. The source code is publicly available and can be used for different research purposes.
Principle-driven Fiber Transmission Model based on PINN Neural Network
Aug 24, 2021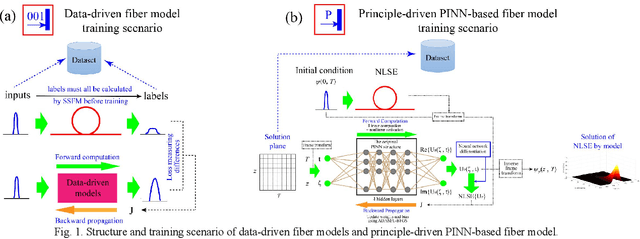
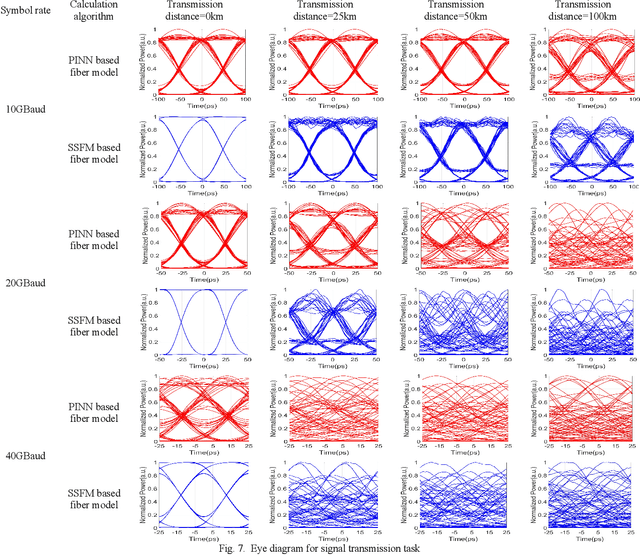
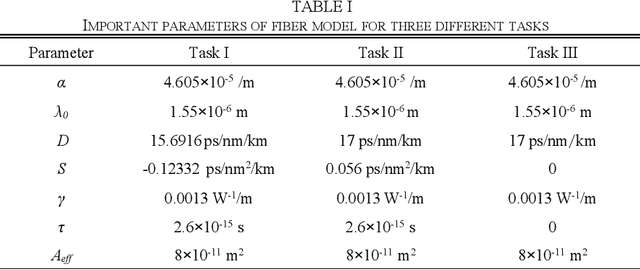
In this paper, a novel principle-driven fiber transmission model based on physical induced neural network (PINN) is proposed. Unlike data-driven models which regard fiber transmission problem as data regression tasks, this model views it as an equation solving problem. Instead of adopting input signals and output signals which are calculated by SSFM algorithm in advance before training, this principle-driven PINN based fiber model adopts frames of time and distance as its inputs and the corresponding real and imaginary parts of NLSE solutions as its outputs. By taking into account of pulses and signals before transmission as initial conditions and fiber physical principles as NLSE in the design of loss functions, this model will progressively learn the transmission rules. Therefore, it can be effectively trained without the data labels, referred as the pre-calculated signals after transmission in data-driven models. Due to this advantage, SSFM algorithm is no longer needed before the training of principle-driven fiber model which can save considerable time consumption. Through numerical demonstration, the results show that this principle-driven PINN based fiber model can handle the prediction tasks of pulse evolution, signal transmission and fiber birefringence for different transmission parameters of fiber telecommunications.