 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling Rare Interactions in Time Series Data Through Qualitative Change: Application to Outcome Prediction in Intensive Care Units
Apr 03, 2020
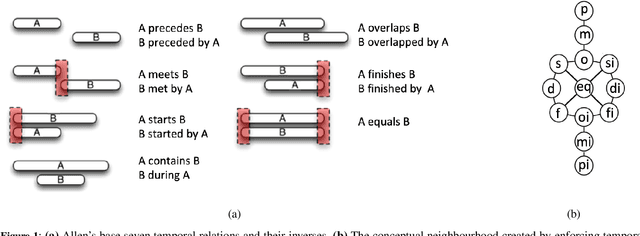
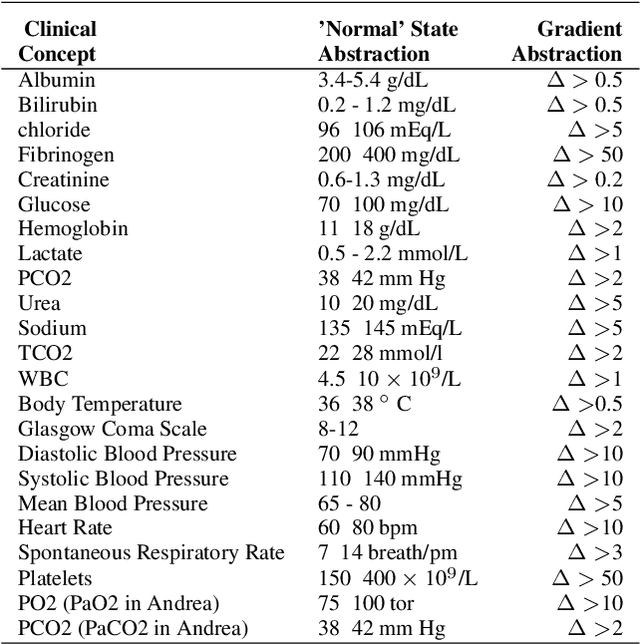
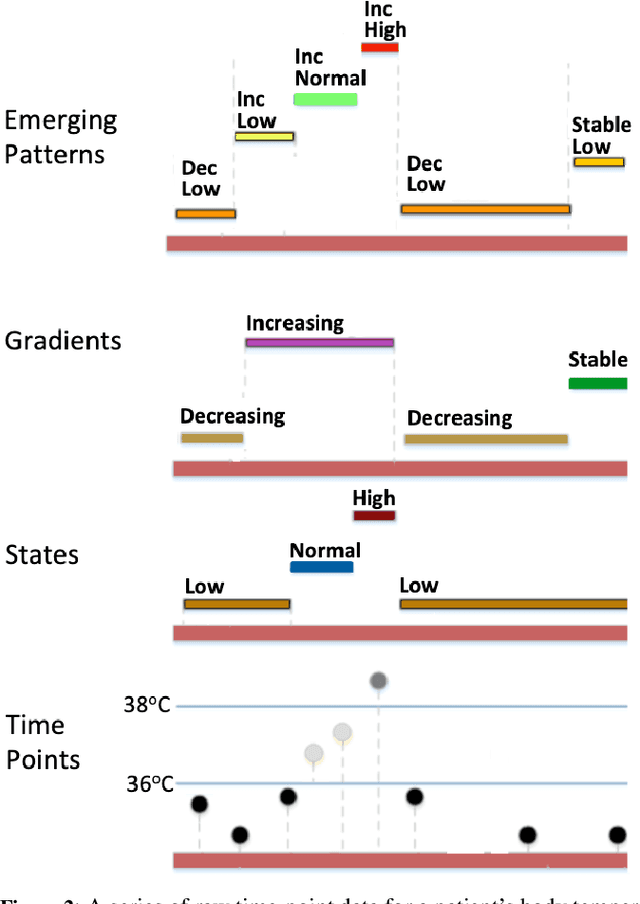
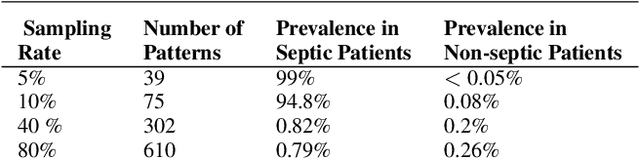
Many areas of research are characterised by the deluge of large-scale highly-dimensional time-series data. However, using the data available for prediction and decision making is hampered by the current lag in our ability to uncover and quantify true interactions that explain the outcomes.We are interested in areas such as intensive care medicine, which are characterised by i) continuous monitoring of multivariate variables and non-uniform sampling of data streams, ii) the outcomes are generally governed by interactions between a small set of rare events, iii) these interactions are not necessarily definable by specific values (or value ranges) of a given group of variables, but rather, by the deviations of these values from the normal state recorded over time, iv) the need to explain the predictions made by the model. Here, while numerous data mining models have been formulated for outcome prediction, they are unable to explain their predictions. We present a model for uncovering interactions with the highest likelihood of generating the outcomes seen from highly-dimensional time series data. Interactions among variables are represented by a relational graph structure, which relies on qualitative abstractions to overcome non-uniform sampling and to capture the semantics of the interactions corresponding to the changes and deviations from normality of variables of interest over time. Using the assumption that similar templates of small interactions are responsible for the outcomes (as prevalent in the medical domains), we reformulate the discovery task to retrieve the most-likely templates from the data.
Designing Machine Learning Pipeline Toolkit for AutoML Surrogate Modeling Optimization
Jul 14, 2021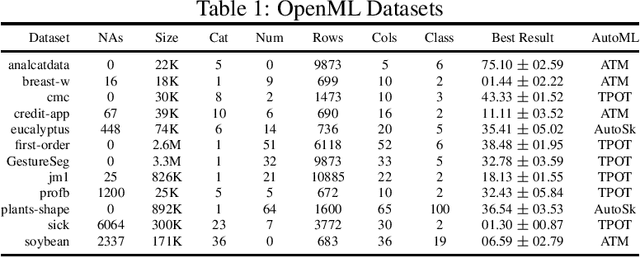
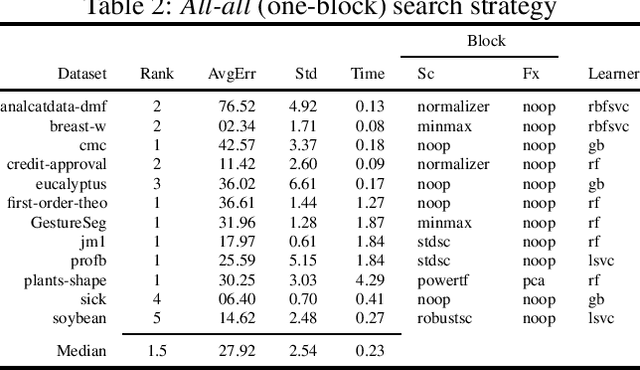
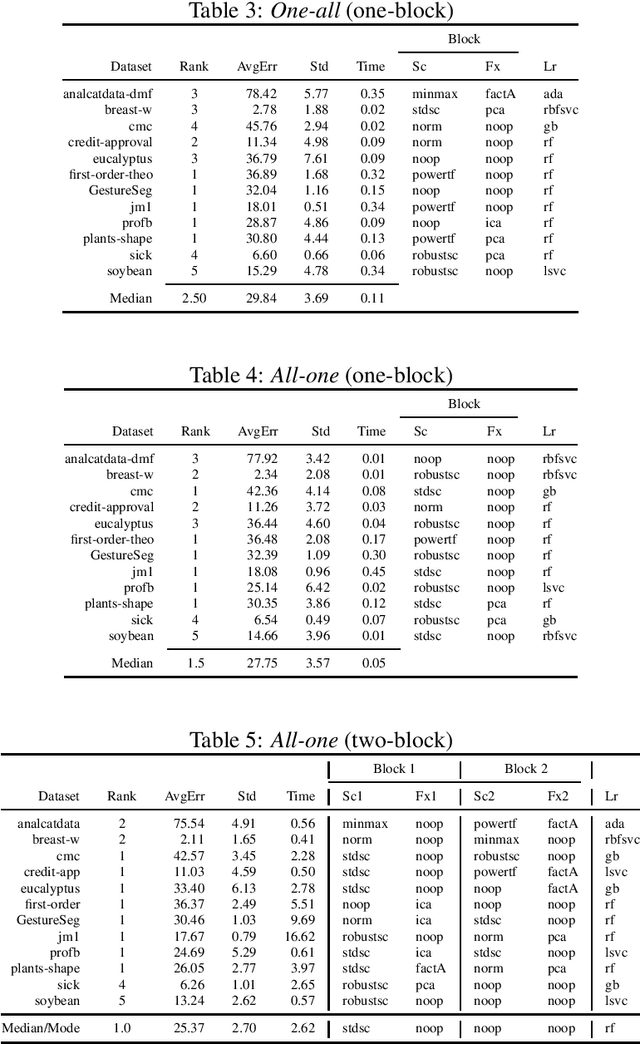
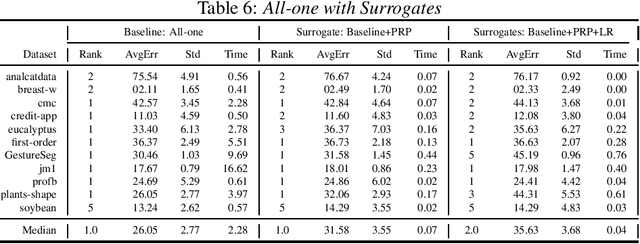
The pipeline optimization problem in machine learning requires simultaneous optimization of pipeline structures and parameter adaptation of their elements. Having an elegant way to express these structures can help lessen the complexity in the management and analysis of their performances together with the different choices of optimization strategies. With these issues in mind, we created the AutoMLPipeline (AMLP) toolkit which facilitates the creation and evaluation of complex machine learning pipeline structures using simple expressions. We use AMLP to find optimal pipeline signatures, datamine them, and use these datamined features to speed-up learning and prediction. We formulated a two-stage pipeline optimization with surrogate modeling in AMLP which outperforms other AutoML approaches with a 4-hour time budget in less than 5 minutes of AMLP computation time.
Automatic Generation of Word Problems for Academic Education via Natural Language Processing (NLP)
Sep 30, 2021
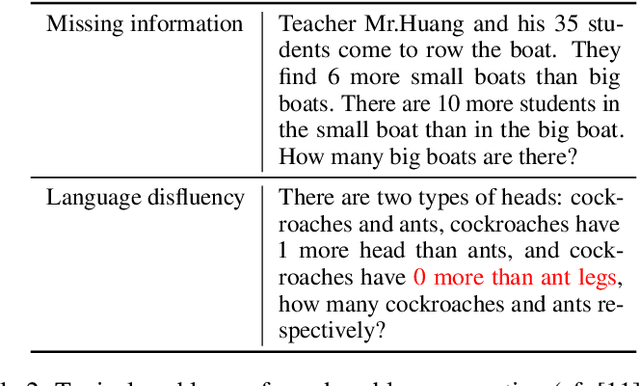


Digital learning platforms enable students to learn on a flexible and individual schedule as well as providing instant feedback mechanisms. The field of STEM education requires students to solve numerous training exercises to grasp underlying concepts. It is apparent that there are restrictions in current online education in terms of exercise diversity and individuality. Many exercises show little variance in structure and content, hindering the adoption of abstraction capabilities by students. This thesis proposes an approach to generate diverse, context rich word problems. In addition to requiring the generated language to be grammatically correct, the nature of word problems implies additional constraints on the validity of contents. The proposed approach is proven to be effective in generating valid word problems for mathematical statistics. The experimental results present a tradeoff between generation time and exercise validity. The system can easily be parametrized to handle this tradeoff according to the requirements of specific use cases.
Computation Rate Maximization for Multiuser Mobile Edge Computing Systems With Dynamic Energy Arrivals
Jun 23, 2021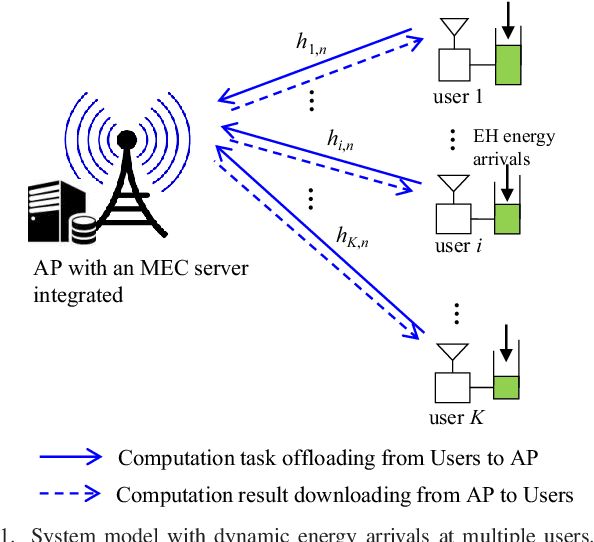
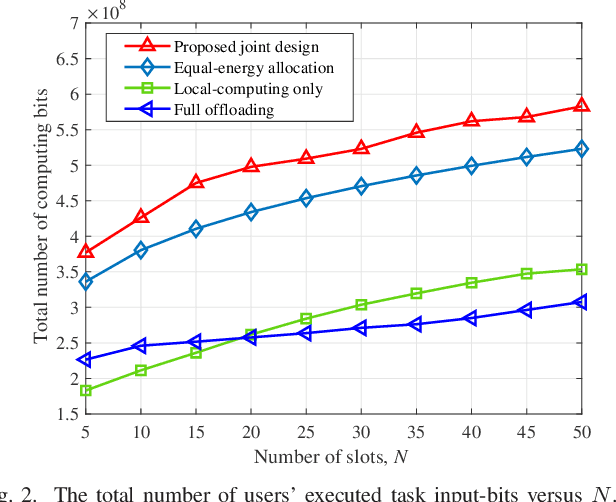
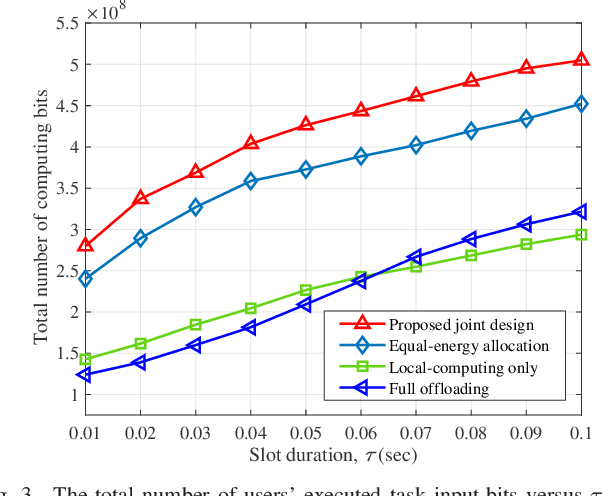
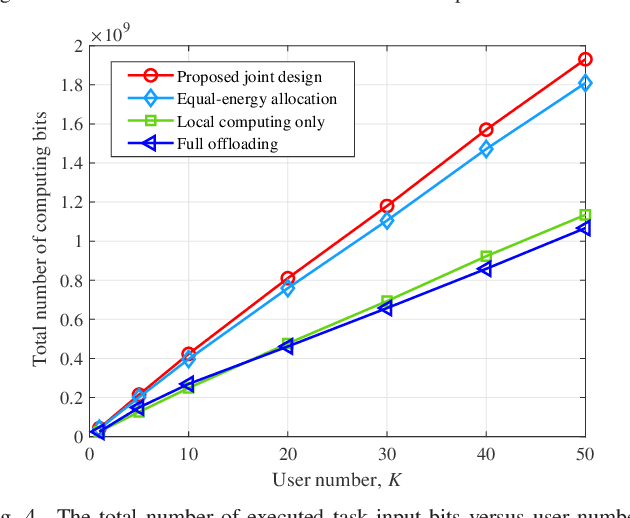
This paper considers an energy harvesting (EH) based multiuser mobile edge computing (MEC) system, where each user utilizes the harvested energy from renewable energy sources to execute its computation tasks via computation offloading and local computing. Towards maximizing the system's weighted computation rate (i.e., the number of weighted users' computing bits within a finite time horizon) subject to the users' energy causality constraints due to dynamic energy arrivals, the decision for joint computation offloading and local computing over time is optimized {\em over time}. Assuming that the profile of channel state information and dynamic task arrivals at the users is known in advance, the weighted computation rate maximization problem becomes a convex optimization problem. Building on the Lagrange duality method, the well-structured optimal solution is analytically obtained. Both the users' local computing and offloading rates are shown to have a monotonically increasing structure. Numerical results show that the proposed design scheme can achieve a significant performance gain over the alternative benchmark schemes.
Tiny Machine Learning for Concept Drift
Jul 30, 2021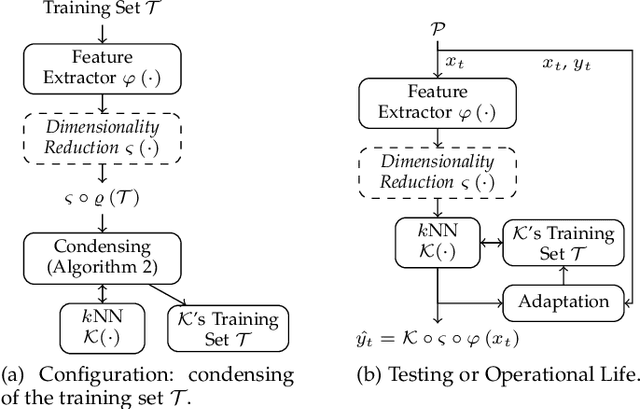

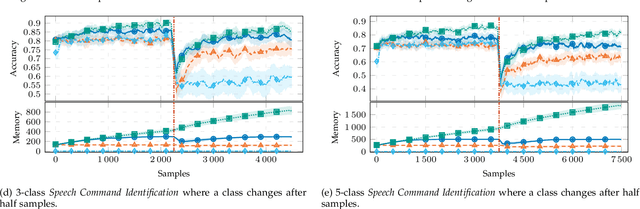
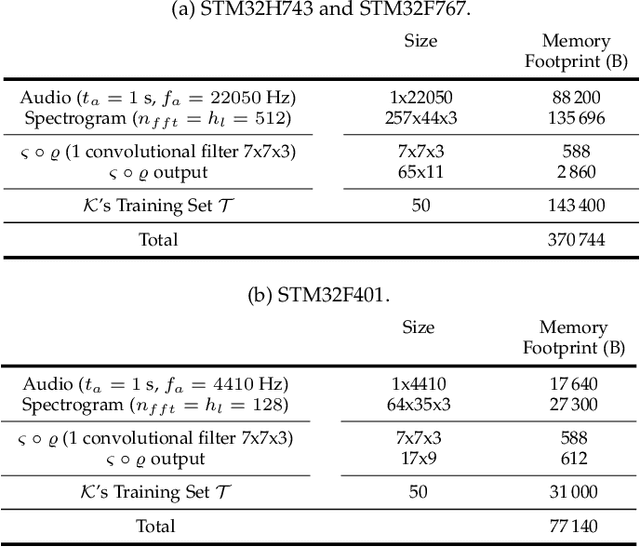
Tiny Machine Learning (TML) is a new research area whose goal is to design machine and deep learning techniques able to operate in Embedded Systems and IoT units, hence satisfying the severe technological constraints on memory, computation, and energy characterizing these pervasive devices. Interestingly, the related literature mainly focused on reducing the computational and memory demand of the inference phase of machine and deep learning models. At the same time, the training is typically assumed to be carried out in Cloud or edge computing systems (due to the larger memory and computational requirements). This assumption results in TML solutions that might become obsolete when the process generating the data is affected by concept drift (e.g., due to periodicity or seasonality effect, faults or malfunctioning affecting sensors or actuators, or changes in the users' behavior), a common situation in real-world application scenarios. For the first time in the literature, this paper introduces a Tiny Machine Learning for Concept Drift (TML-CD) solution based on deep learning feature extractors and a k-nearest neighbors classifier integrating a hybrid adaptation module able to deal with concept drift affecting the data-generating process. This adaptation module continuously updates (in a passive way) the knowledge base of TML-CD and, at the same time, employs a Change Detection Test to inspect for changes (in an active way) to quickly adapt to concept drift by removing the obsolete knowledge. Experimental results on both image and audio benchmarks show the effectiveness of the proposed solution, whilst the porting of TML-CD on three off-the-shelf micro-controller units shows the feasibility of what is proposed in real-world pervasive systems.
Background Subtraction with Real-time Semantic Segmentation
Dec 12, 2018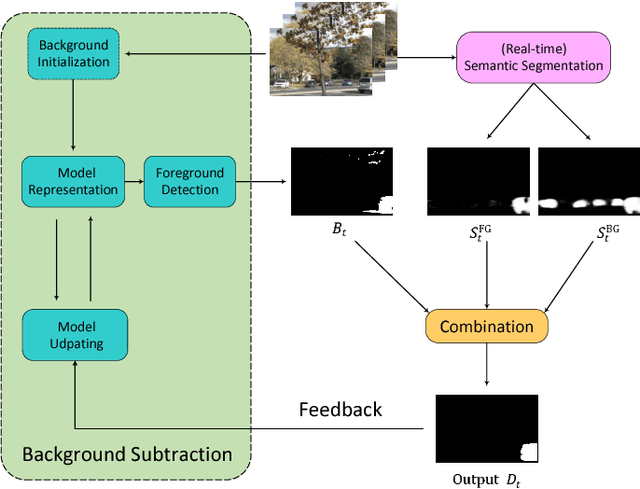
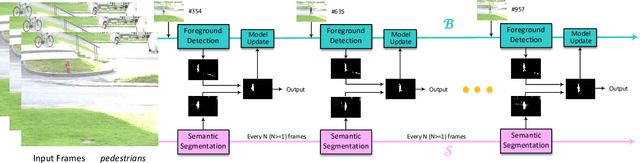
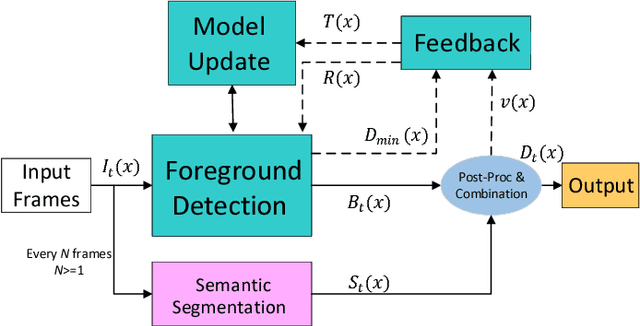

Accurate and fast foreground object extraction is very important for object tracking and recognition in video surveillance. Although many background subtraction (BGS) methods have been proposed in the recent past, it is still regarded as a tough problem due to the variety of challenging situations that occur in real-world scenarios. In this paper, we explore this problem from a new perspective and propose a novel background subtraction framework with real-time semantic segmentation (RTSS). Our proposed framework consists of two components, a traditional BGS segmenter $\mathcal{B}$ and a real-time semantic segmenter $\mathcal{S}$. The BGS segmenter $\mathcal{B}$ aims to construct background models and segments foreground objects. The real-time semantic segmenter $\mathcal{S}$ is used to refine the foreground segmentation outputs as feedbacks for improving the model updating accuracy. $\mathcal{B}$ and $\mathcal{S}$ work in parallel on two threads. For each input frame $I_t$, the BGS segmenter $\mathcal{B}$ computes a preliminary foreground/background (FG/BG) mask $B_t$. At the same time, the real-time semantic segmenter $\mathcal{S}$ extracts the object-level semantics ${S}_t$. Then, some specific rules are applied on ${B}_t$ and ${S}_t$ to generate the final detection ${D}_t$. Finally, the refined FG/BG mask ${D}_t$ is fed back to update the background model. Comprehensive experiments evaluated on the CDnet 2014 dataset demonstrate that our proposed method achieves state-of-the-art performance among all unsupervised background subtraction methods while operating at real-time, and even performs better than some deep learning based supervised algorithms. In addition, our proposed framework is very flexible and has the potential for generalization.
Online and Offline Robot Programming via Augmented Reality Workspaces
Jul 05, 2021
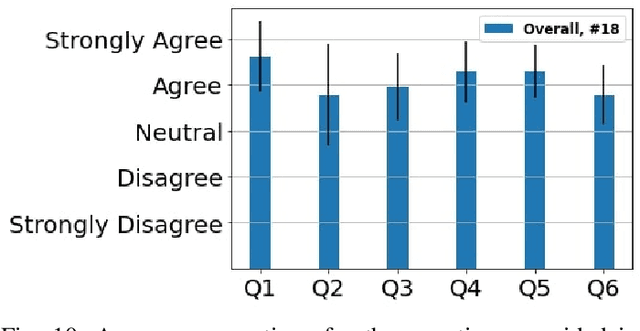

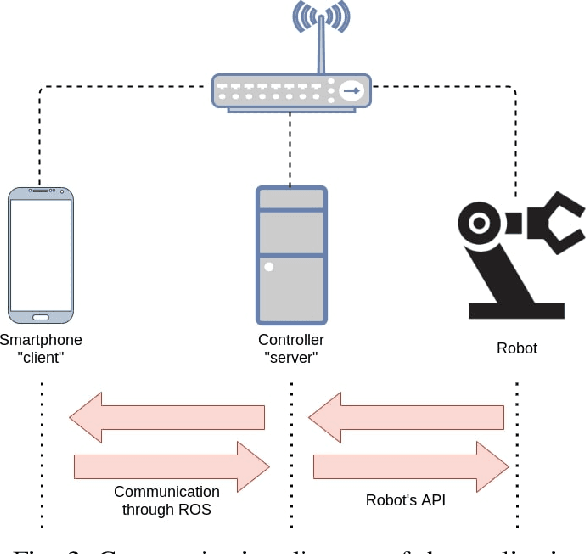
Robot programming methods for industrial robots are time consuming and often require operators to have knowledge in robotics and programming. To reduce costs associated with reprogramming, various interfaces using augmented reality have recently been proposed to provide users with more intuitive means of controlling robots in real-time and programming them without having to code. However, most solutions require the operator to be close to the real robot's workspace which implies either removing it from the production line or shutting down the whole production line due to safety hazards. We propose a novel augmented reality interface providing the users with the ability to model a virtual representation of a workspace which can be saved and reused to program new tasks or adapt old ones without having to be co-located with the real robot. Similar to previous interfaces, the operators then have the ability to program robot tasks or control the robot in real-time by manipulating a virtual robot. We evaluate the intuitiveness and usability of the proposed interface with a user study where 18 participants programmed a robot manipulator for a disassembly task.
Learning discriminative and robust time-frequency representations for environmental sound classification
Dec 14, 2019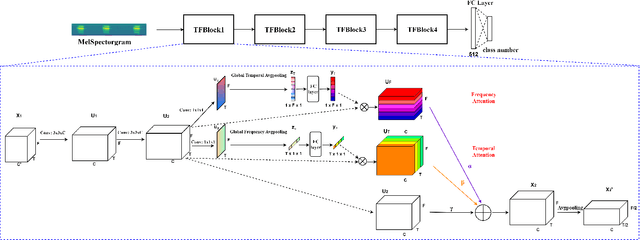
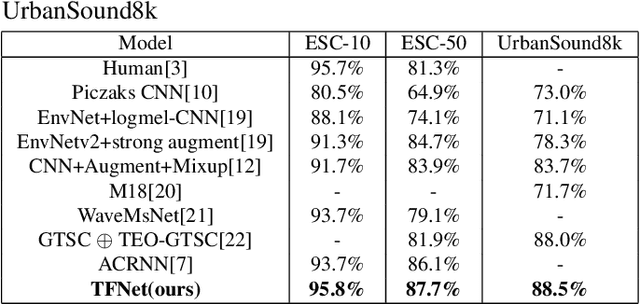
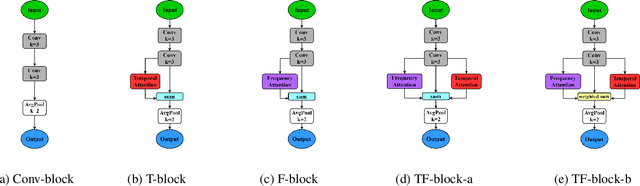
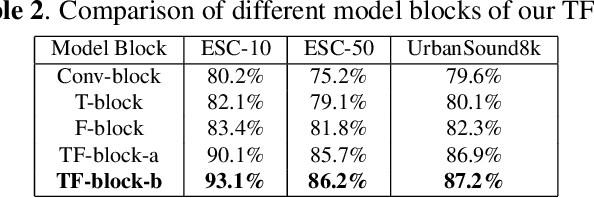
Convolutional neural networks (CNN) are one of the best-performing neural network architectures for environmental sound classification (ESC). Recently, attention mechanisms have been used in CNN to capture the useful information from the audio signal for sound classification, especially for weakly labelled data where the timing information about the acoustic events is not available in the training data, apart from the availability of sound class labels. In these methods, however, the inherent time-frequency characteristics and variations are not explicitly exploited when obtaining the deep features. In this paper, we propose a new method, called time-frequency enhancement block (TFBlock), which temporal attention and frequency attention are employed to enhance the features from relevant frames and frequency bands. Compared with other attention mechanisms, in our method, parallel branches are constructed which allow the temporal and frequency features to be attended respectively in order to mitigate interference from the sections where no sound events happened in the acoustic environments. The experiments on three benchmark ESC datasets show that our method improves the classification performance and also exhibits robustness to noise.
Incremental learning of LSTM framework for sensor fusion in attitude estimation
Aug 04, 2021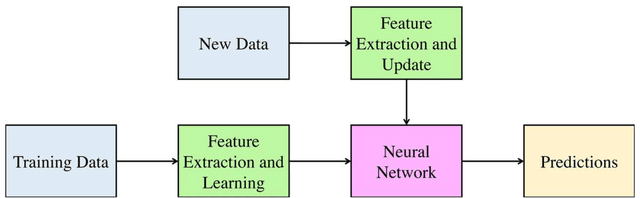
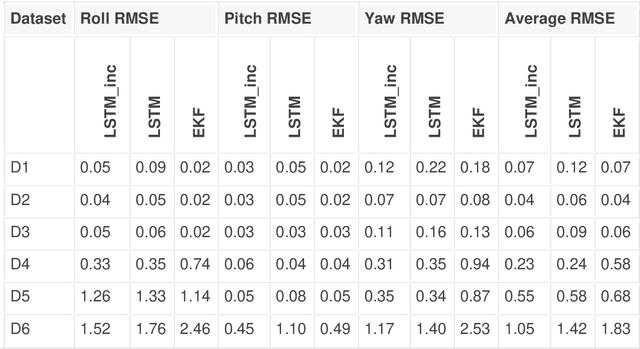
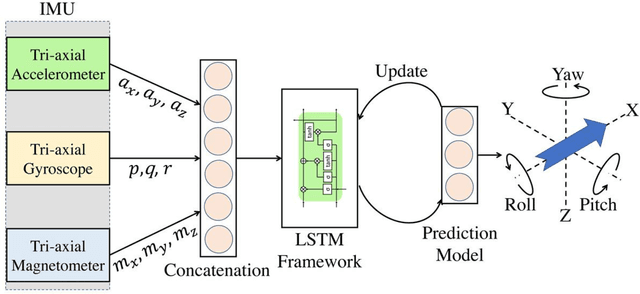
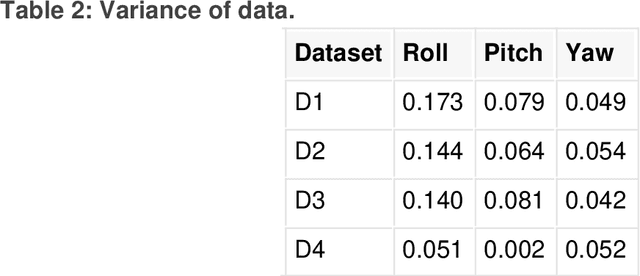
This paper presents a novel method for attitude estimation of an object in 3D space by incremental learning of the Long-Short Term Memory (LSTM) network. Gyroscope, accelerometer, and magnetometer are few widely used sensors in attitude estimation applications. Traditionally, multi-sensor fusion methods such as the Extended Kalman Filter and Complementary Filter are employed to fuse the measurements from these sensors. However, these methods exhibit limitations in accounting for the uncertainty, unpredictability, and dynamic nature of the motion in real-world situations. In this paper, the inertial sensors data are fed to the LSTM network which are then updated incrementally to incorporate the dynamic changes in motion occurring in the run time. The robustness and efficiency of the proposed framework is demonstrated on the dataset collected from a commercially available inertial measurement unit. The proposed framework offers a significant improvement in the results compared to the traditional method, even in the case of a highly dynamic environment. The LSTM framework-based attitude estimation approach can be deployed on a standard AI-supported processing module for real-time applications.
A Probabilistic Domain-knowledge Framework for Nosocomial Infection Risk Estimation of Communicable Viral Diseases in Healthcare Personnel: A Case Study for COVID-19
Nov 05, 2021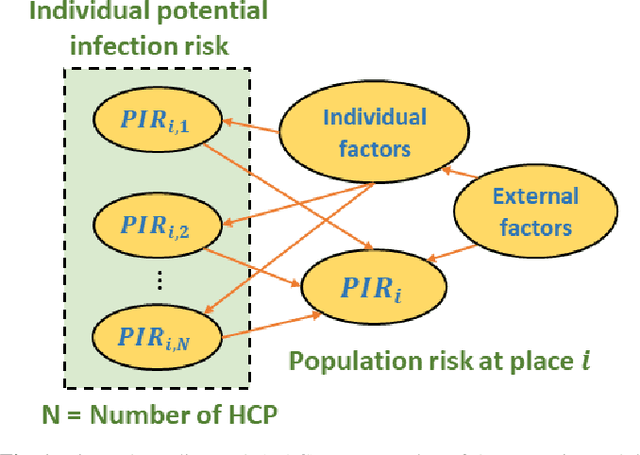
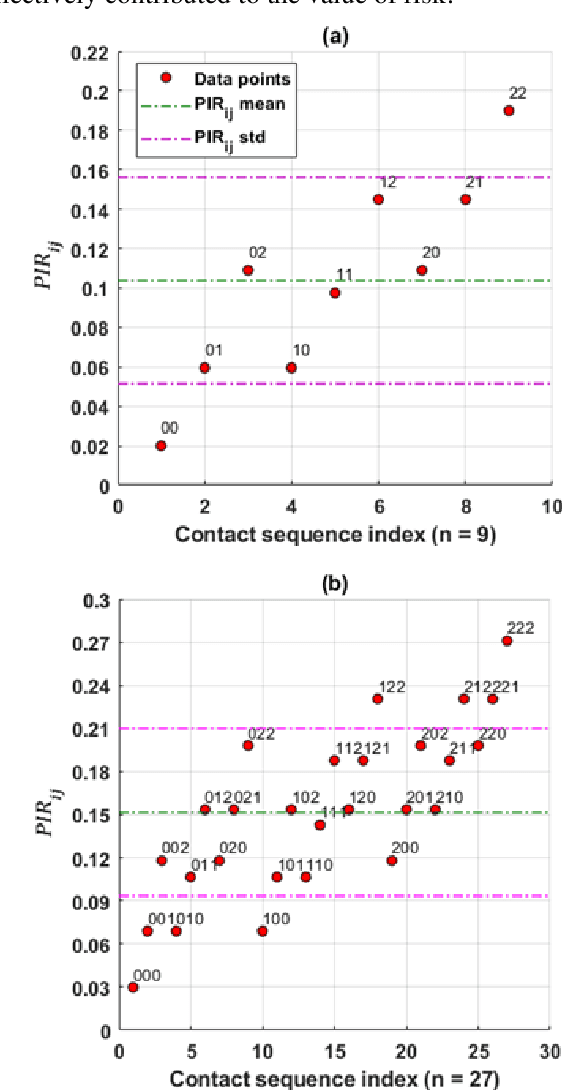
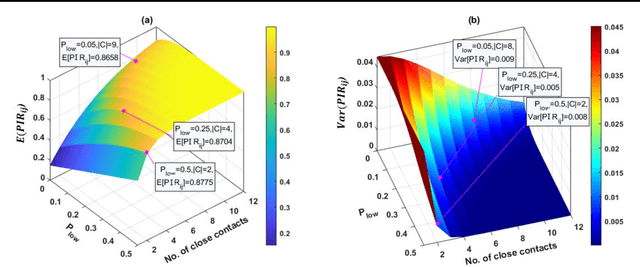
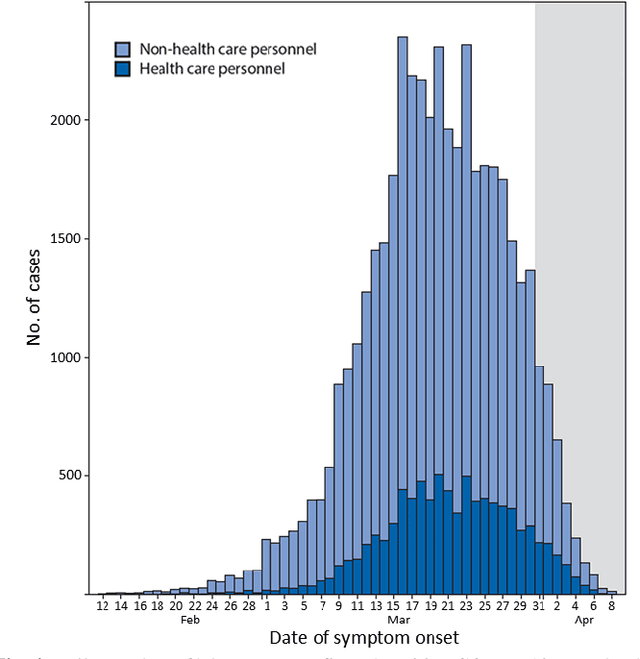
Hospital-acquired infections of communicable viral diseases (CVDs) are posing a tremendous challenge to healthcare workers globally. Healthcare personnel (HCP) is facing a consistent risk of hospital-acquired infections, and subsequently higher rates of morbidity and mortality. We proposed a domain knowledge-driven infection risk model to quantify the individual HCP and the population-level healthcare facility risks. For individual-level risk estimation, a time-variant infection risk model is proposed to capture the transmission dynamics of CVDs. At the population-level, the infection risk is estimated using a Bayesian network model constructed from three feature sets including individual-level factors, engineering control factors, and administrative control factors. The sensitivity analyses indicated that the uncertainty in the individual infection risk can be attributed to two variables: the number of close contacts and the viral transmission probability. The model validation was implemented in the transmission probability model, individual level risk model, and population-level risk model using a Coronavirus disease case study. Regarding the first, multivariate logistic regression was applied for a cross-sectional data in the UK with an AIC value of 7317.70 and a 10-fold cross validation accuracy of 78.23%. For the second model, we collected laboratory-confirmed COVID-19 cases of HCP in different occupations. The occupation-specific risk evaluation suggested the highest-risk occupations were registered nurses, medical assistants, and respiratory therapists, with estimated risks of 0.0189, 0.0188, and 0.0176, respectively. To validate the population-level risk model, the infection risk in Texas and California was estimated. The proposed model will significantly influence the PPE allocation and safety plans for HCP