 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Algorithms and Policies Using Adaptive and Machine Learning Approaches
May 13, 2021
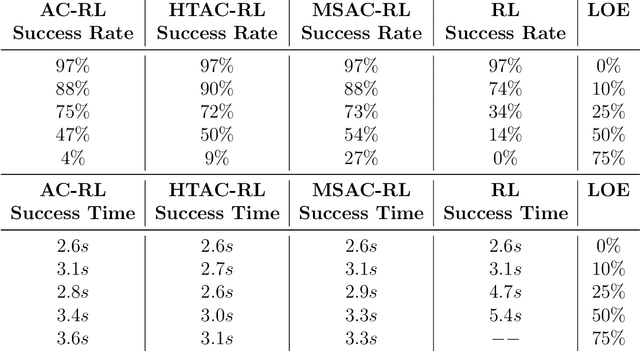
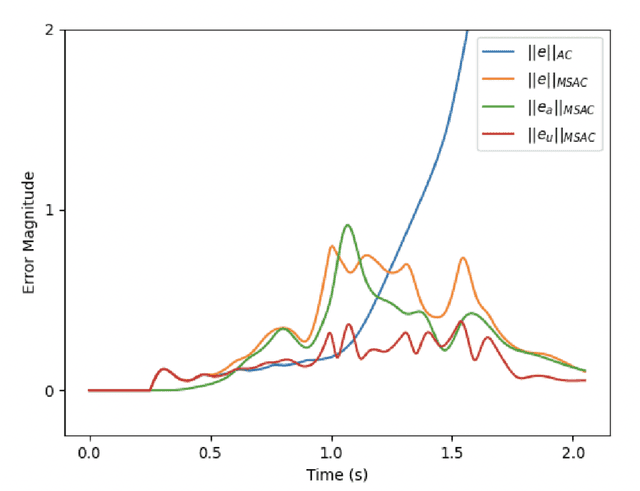
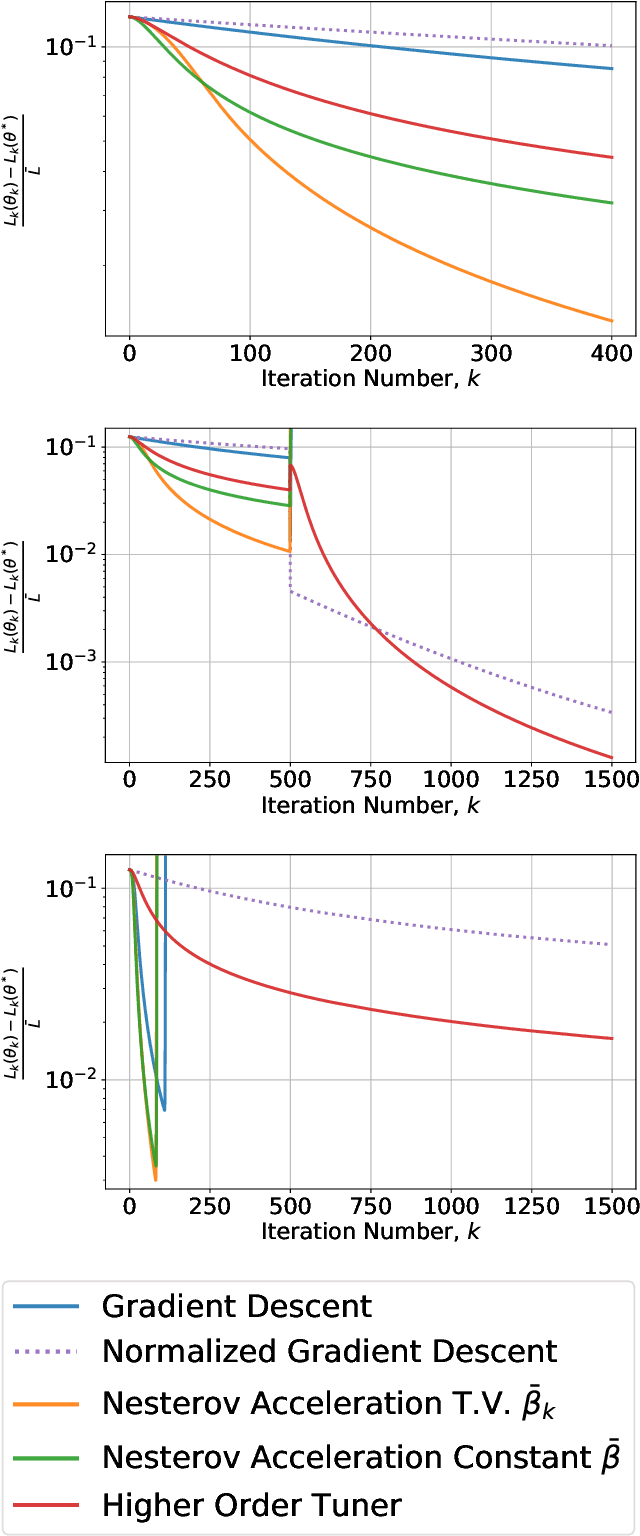
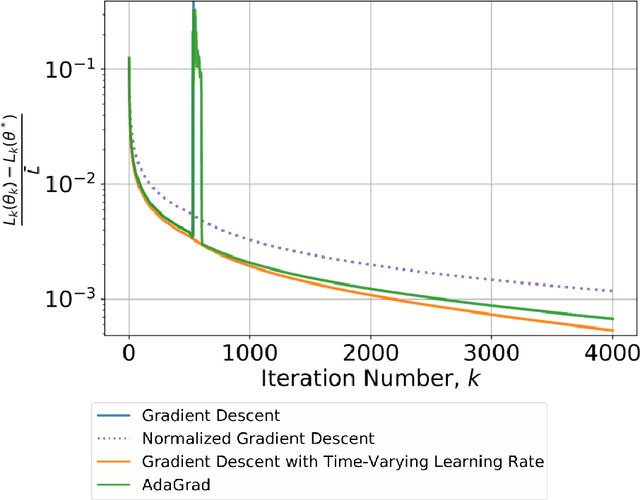
This paper considers the problem of real-time control and learning in dynamic systems subjected to uncertainties. Adaptive approaches are proposed to address the problem, which are combined to with methods and tools in Reinforcement Learning (RL) and Machine Learning (ML). Algorithms are proposed in continuous-time that combine adaptive approaches with RL leading to online control policies that guarantee stable behavior in the presence of parametric uncertainties that occur in real-time. Algorithms are proposed in discrete-time that combine adaptive approaches proposed for parameter and output estimation and ML approaches proposed for accelerated performance that guarantee stable estimation even in the presence of time-varying regressors, and for accelerated learning of the parameters with persistent excitation. Numerical validations of all algorithms are carried out using a quadrotor landing task on a moving platform and benchmark problems in ML. All results clearly point out the advantage of adaptive approaches for real-time control and learning.
MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
May 01, 2020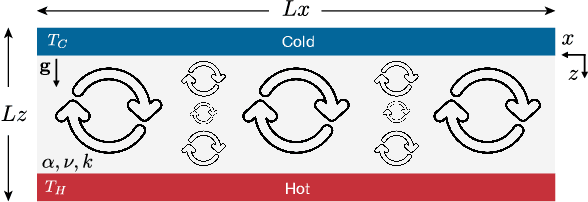
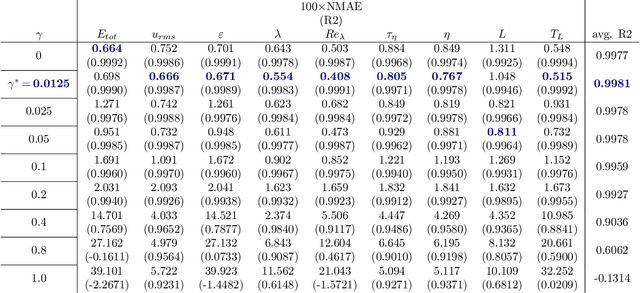
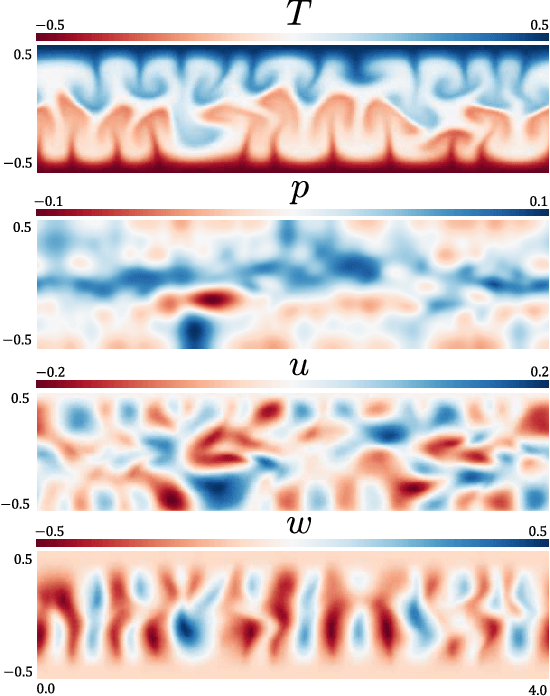

We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder. We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh-Benard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
Attention-Guided Lightweight Network for Real-Time Segmentation of Robotic Surgical Instruments
Oct 24, 2019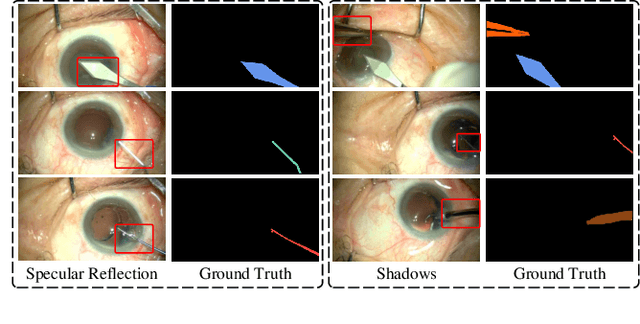
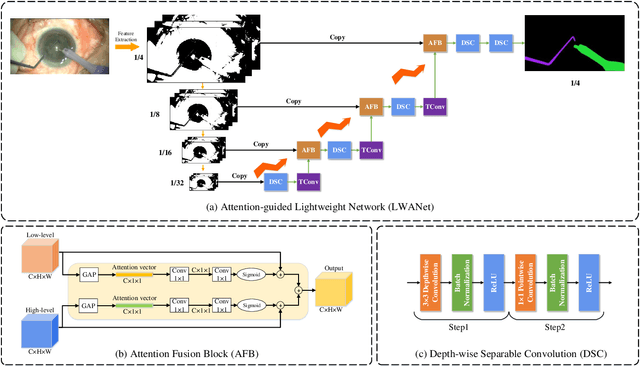
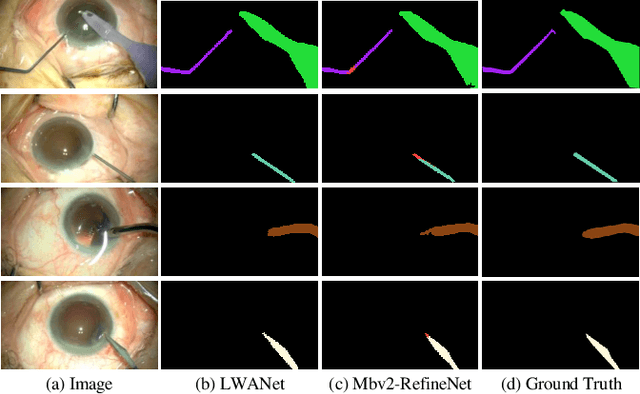
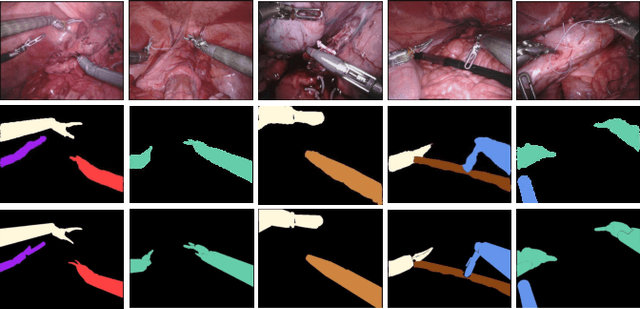
Real-time segmentation of surgical instruments plays a crucial role in robot-assisted surgery. However, real-time segmentation of surgical instruments using current deep learning models is still a challenging task due to the high computational costs and slow inference speed. In this paper, an attention-guided lightweight network (LWANet), is proposed to segment surgical instruments in real-time. LWANet adopts the encoder-decoder architecture, where the encoder is the lightweight network MobileNetV2 and the decoder consists of depth-wise separable convolution, attention fusion block, and transposed convolution. Depth-wise separable convolution is used as the basic unit to construct the decoder, which can reduce the model size and computational costs. Attention fusion block captures global context and encodes semantic dependencies between channels to emphasize target regions, contributing to locating the surgical instrument. Transposed convolution is performed to upsample the feature map for acquiring refined edges. LWANet can segment surgical instruments in real-time, taking few computational costs. Based on 960*544 inputs, its inference speed can reach 39 fps with only 3.39 GFLOPs. Also, it has a small model size and the number of parameters is only 2.06 M. The proposed network is evaluated on two datasets. It achieves state-of-the-art performance 94.10% mean IOU on Cata7 and obtains a new record on EndoVis 2017 with 4.10% increase on mean mIOU.
Joint Spatio-Temporal Discretisation of Nonlinear Active Cochlear Models
Aug 12, 2021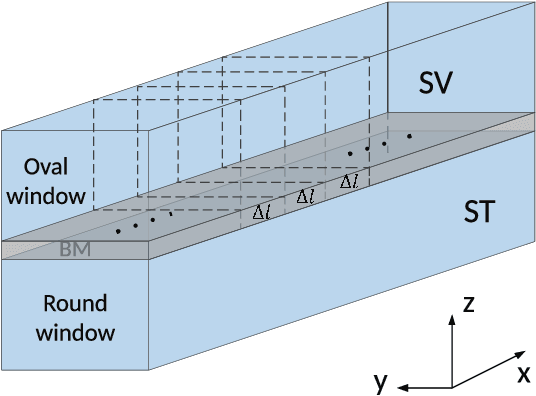
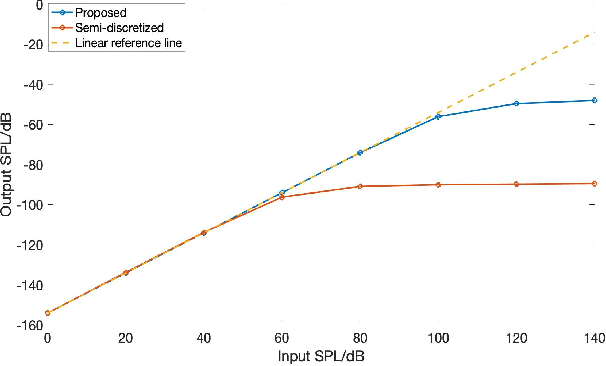
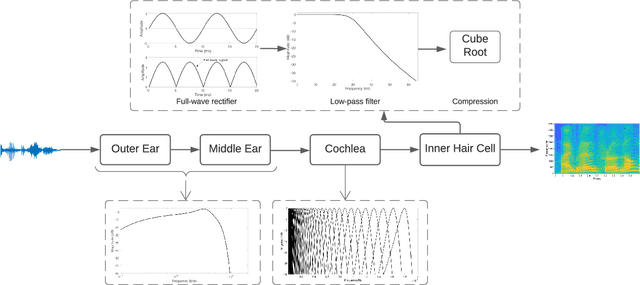
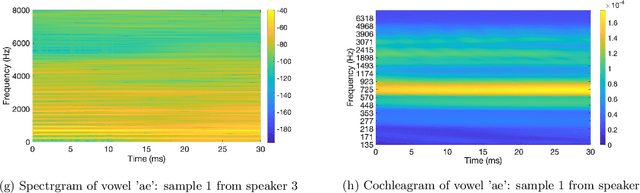
Biologically inspired auditory models play an important role in developing effective audio representations that can be tightly integrated into speech and audio processing systems. Current computational models of the cochlea are typically expressed in terms of systems of differential equations and do not directly lend themselves for use in computational speech processing systems. Specifically, these models are spatially discrete and temporally continuous. This paper presents a jointly discretised (spatially and temporally discrete) model of the cochlea which allows for processing at fixed time intervals suited to discrete time speech and audio processing systems. The proposed model takes into account the active feedback mechanism in the cochlea, a core characteristic lacking in traditional speech processing front-ends, which endows it with significant dynamic range compression capability. This model is derived by jointly discretising an established semi-discretised (spatially discrete and temporally continuous) cochlear model in a state space form. We then demonstrate that the proposed jointly discretised implementation matches the semi-discrete model in terms of its characteristics and finally present stability analyses of the proposed model.
Using Google Trends as a proxy for occupant behavior to predict building energy consumption
Oct 31, 2021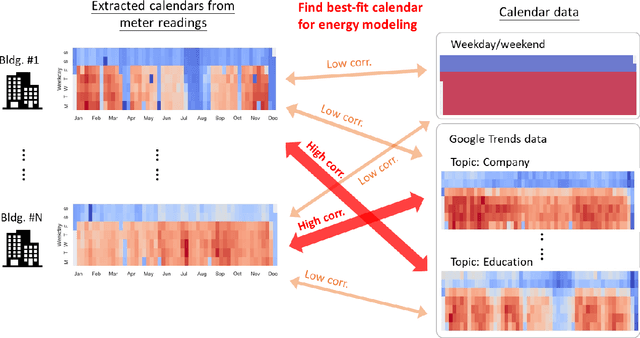
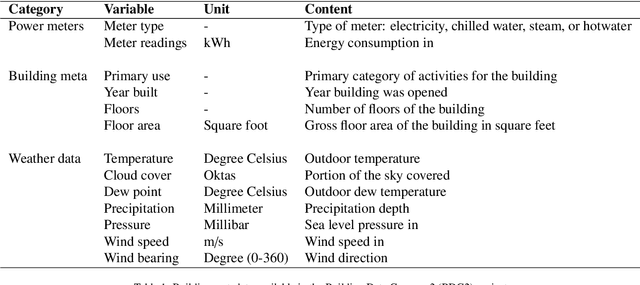
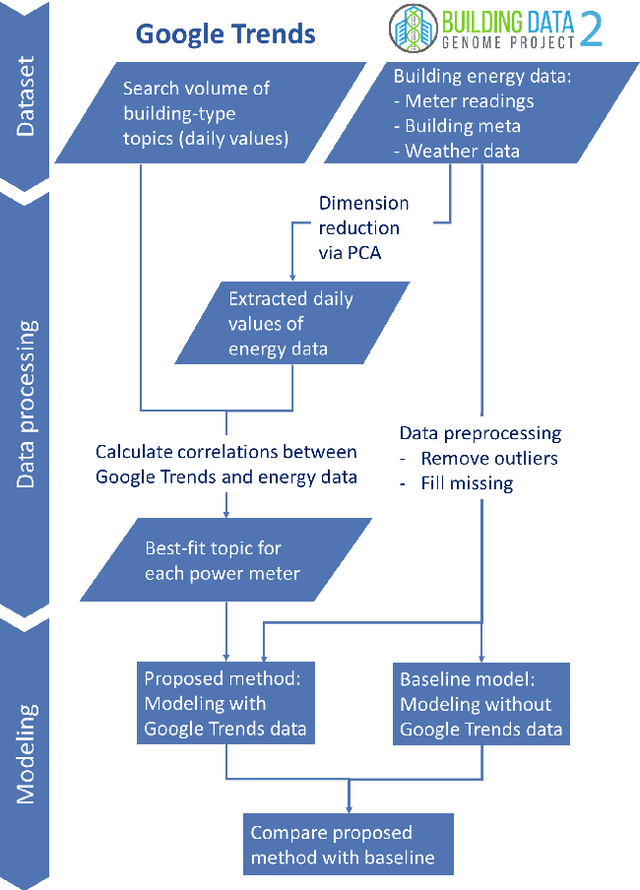

In recent years, the availability of larger amounts of energy data and advanced machine learning algorithms has created a surge in building energy prediction research. However, one of the variables in energy prediction models, occupant behavior, is crucial for prediction performance but hard-to-measure or time-consuming to collect from each building. This study proposes an approach that utilizes the search volume of topics (e.g., education} or Microsoft Excel) on the Google Trends platform as a proxy of occupant behavior and use of buildings. Linear correlations were first examined to explore the relationship between energy meter data and Google Trends search terms to infer building occupancy. Prediction errors before and after the inclusion of the trends of these terms were compared and analyzed based on the ASHRAE Great Energy Predictor III (GEPIII) competition dataset. The results show that highly correlated Google Trends data can effectively reduce the overall RMSLE error for a subset of the buildings to the level of the GEPIII competition's top five winning teams' performance. In particular, the RMSLE error reduction during public holidays and days with site-specific schedules are respectively reduced by 20-30% and 2-5%. These results show the potential of using Google Trends to improve energy prediction for a portion of the building stock by automatically identifying site-specific and holiday schedules.
A deep learning model for classification of diabetic retinopathy in eye fundus images based on retinal lesion detection
Oct 14, 2021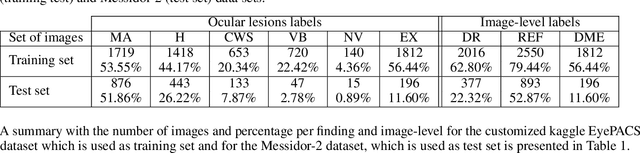
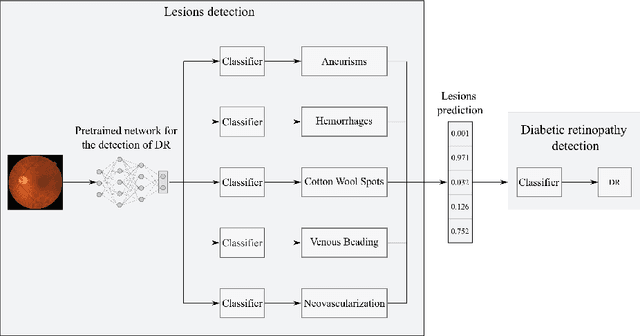
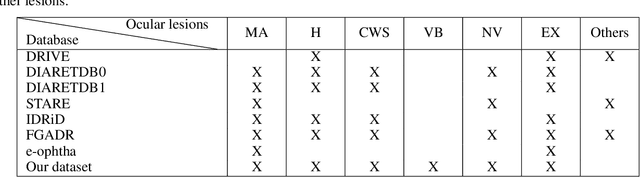
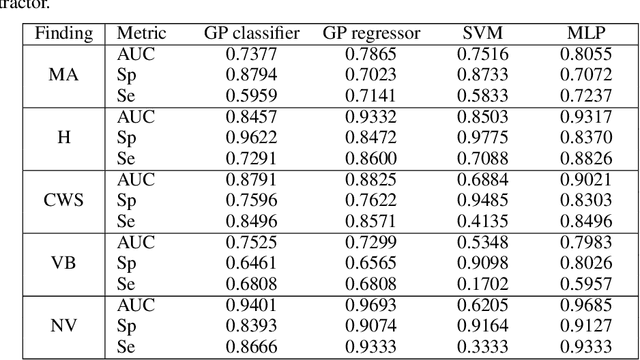
Diabetic retinopathy (DR) is the result of a complication of diabetes affecting the retina. It can cause blindness, if left undiagnosed and untreated. An ophthalmologist performs the diagnosis by screening each patient and analyzing the retinal lesions via ocular imaging. In practice, such analysis is time-consuming and cumbersome to perform. This paper presents a model for automatic DR classification on eye fundus images. The approach identifies the main ocular lesions related to DR and subsequently diagnoses the illness. The proposed method follows the same workflow as the clinicians, providing information that can be interpreted clinically to support the prediction. A subset of the kaggle EyePACS and the Messidor-2 datasets, labeled with ocular lesions, is made publicly available. The kaggle EyePACS subset is used as a training set and the Messidor-2 as a test set for lesions and DR classification models. For DR diagnosis, our model has an area-under-the-curve, sensitivity, and specificity of 0.948, 0.886, and 0.875, respectively, which competes with state-of-the-art approaches.
LFZip: Lossy compression of multivariate floating-point time series data via improved prediction
Nov 01, 2019

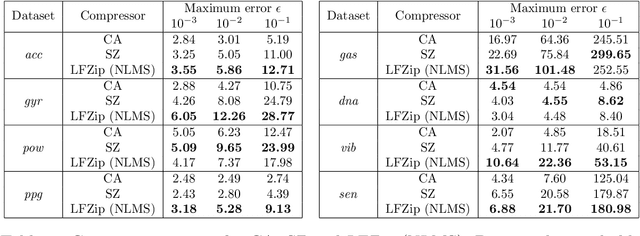
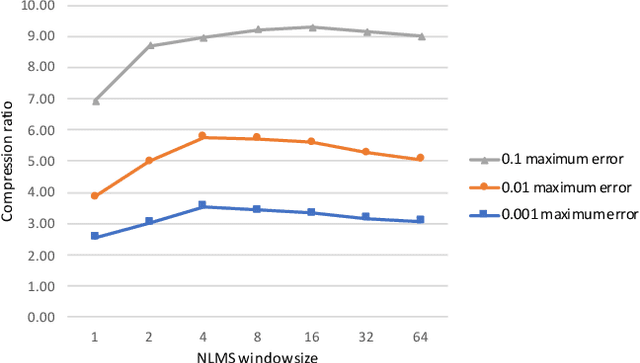
Time series data compression is emerging as an important problem with the growth in IoT devices and sensors. Due to the presence of noise in these datasets, lossy compression can often provide significant compression gains without impacting the performance of downstream applications. In this work, we propose an error-bounded lossy compressor, LFZip, for multivariate floating-point time series data that provides guaranteed reconstruction up to user-specified maximum absolute error. The compressor is based on the prediction-quantization-entropy coder framework and benefits from improved prediction using linear models and neural networks. We evaluate the compressor on several time series datasets where it outperforms the existing state-of-the-art error-bounded lossy compressors. The code and data are available at https://github.com/shubhamchandak94/LFZip
Differentially Private Stochastic Optimization: New Results in Convex and Non-Convex Settings
Jul 13, 2021
We study differentially private stochastic optimization in convex and non-convex settings. For the convex case, we focus on the family of non-smooth generalized linear losses (GLLs). Our algorithm for the $\ell_2$ setting achieves optimal excess population risk in near-linear time, while the best known differentially private algorithms for general convex losses run in super-linear time. Our algorithm for the $\ell_1$ setting has nearly-optimal excess population risk $\tilde{O}\big(\sqrt{\frac{\log{d}}{n}}\big)$, and circumvents the dimension dependent lower bound of [AFKT21] for general non-smooth convex losses. In the differentially private non-convex setting, we provide several new algorithms for approximating stationary points of the population risk. For the $\ell_1$-case with smooth losses and polyhedral constraint, we provide the first nearly dimension independent rate, $\tilde O\big(\frac{\log^{2/3}{d}}{{n^{1/3}}}\big)$ in linear time. For the constrained $\ell_2$-case, with smooth losses, we obtain a linear-time algorithm with rate $\tilde O\big(\frac{1}{n^{3/10}d^{1/10}}+\big(\frac{d}{n^2}\big)^{1/5}\big)$. Finally, for the $\ell_2$-case we provide the first method for {\em non-smooth weakly convex} stochastic optimization with rate $\tilde O\big(\frac{1}{n^{1/4}}+\big(\frac{d}{n^2}\big)^{1/6}\big)$ which matches the best existing non-private algorithm when $d= O(\sqrt{n})$. We also extend all our results above for the non-convex $\ell_2$ setting to the $\ell_p$ setting, where $1 < p \leq 2$, with only polylogarithmic (in the dimension) overhead in the rates.
Continual Learning on Noisy Data Streams via Self-Purified Replay
Oct 14, 2021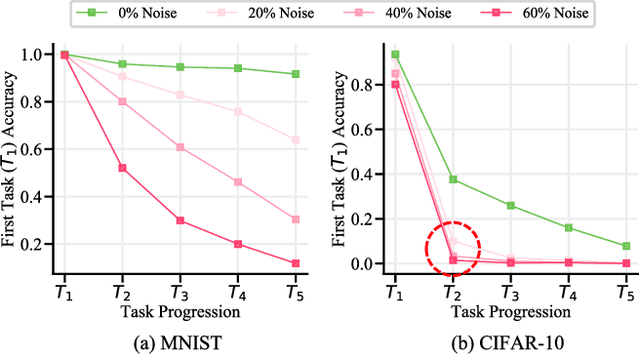
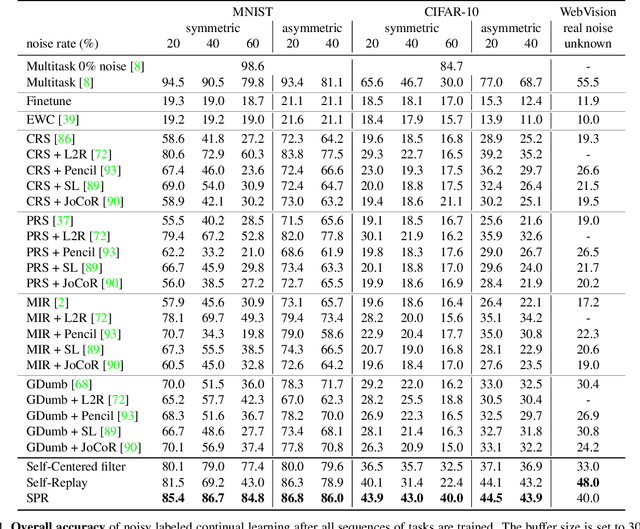
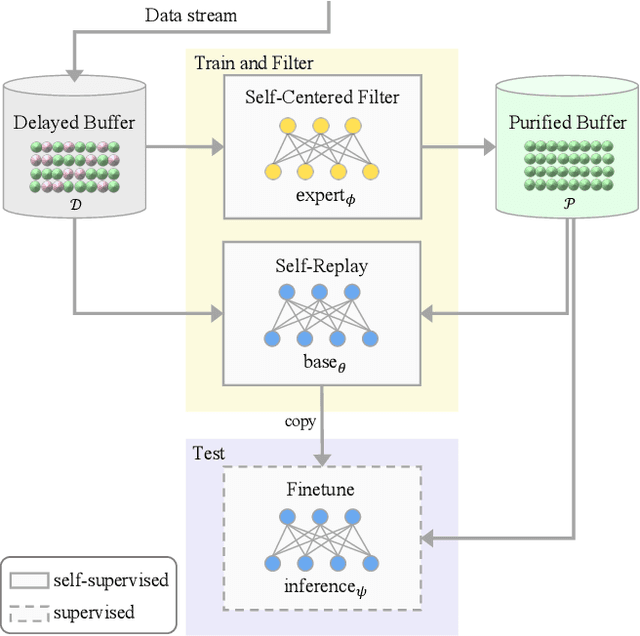
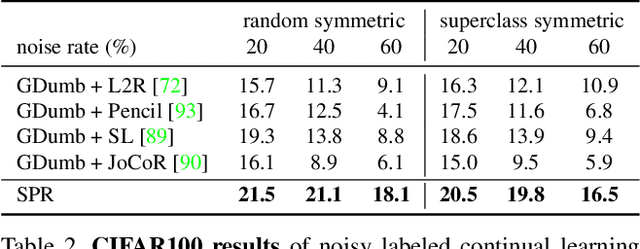
Continually learning in the real world must overcome many challenges, among which noisy labels are a common and inevitable issue. In this work, we present a repla-ybased continual learning framework that simultaneously addresses both catastrophic forgetting and noisy labels for the first time. Our solution is based on two observations; (i) forgetting can be mitigated even with noisy labels via self-supervised learning, and (ii) the purity of the replay buffer is crucial. Building on this regard, we propose two key components of our method: (i) a self-supervised replay technique named Self-Replay which can circumvent erroneous training signals arising from noisy labeled data, and (ii) the Self-Centered filter that maintains a purified replay buffer via centrality-based stochastic graph ensembles. The empirical results on MNIST, CIFAR-10, CIFAR-100, and WebVision with real-world noise demonstrate that our framework can maintain a highly pure replay buffer amidst noisy streamed data while greatly outperforming the combinations of the state-of-the-art continual learning and noisy label learning methods. The source code is available at http://vision.snu.ac.kr/projects/SPR
TEAGS: Time-aware Text Embedding Approach to Generate Subgraphs
Aug 21, 2019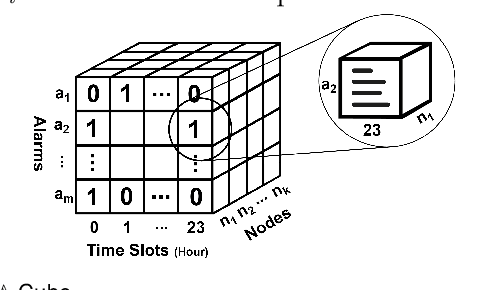
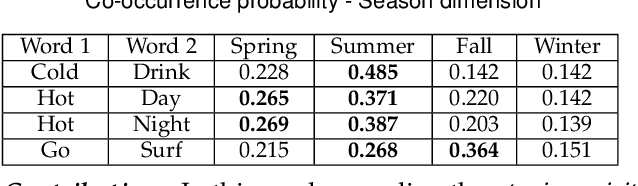
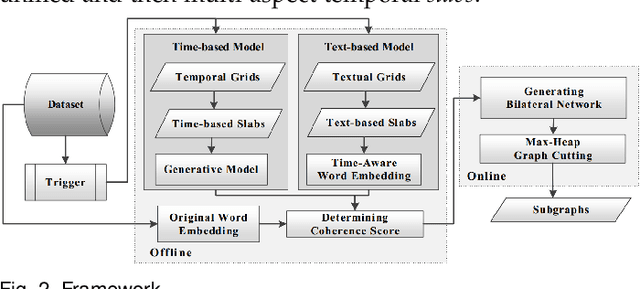
Contagions (e.g. virus, gossip) spread over the nodes in propagation graphs. We can use the temporal and textual data of the nodes to compute the edge weights and then generate subgraphs with highly relevant nodes. This is beneficial to many applications. Yet, challenges abound. First, the propagation pattern between each pair of nodes may change by time. Second, not always the same contagion propagates. Hence, the state-of-the-art text mining approaches including topic-modeling cannot effectively compute the edge weights. Third, since the propagation is affected by time, the word-word co-occurrence patterns may differ in various temporal dimensions, that can decrease the effectiveness of word embedding approaches. We argue that multi-aspect temporal dimensions (hour, day, etc) should be considered to better calculate the correlation weights between the nodes. In this work, we devise a novel framework that on the one hand, integrates a neural network based time-aware word embedding component to construct the word vectors through multiple temporal facets, and on the other hand, uses a temporal generative model to compute the weights. Subsequently, we propose a Max-Heap Graph cutting algorithm to generate subgraphs. We validate our model through comprehensive experiments on real-world datasets. The results show that our model can retrieve the subgraphs more effective than other rivals and the temporal dynamics should be noticed both in word embedding and propagation processes.