 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid ICP
Sep 15, 2021
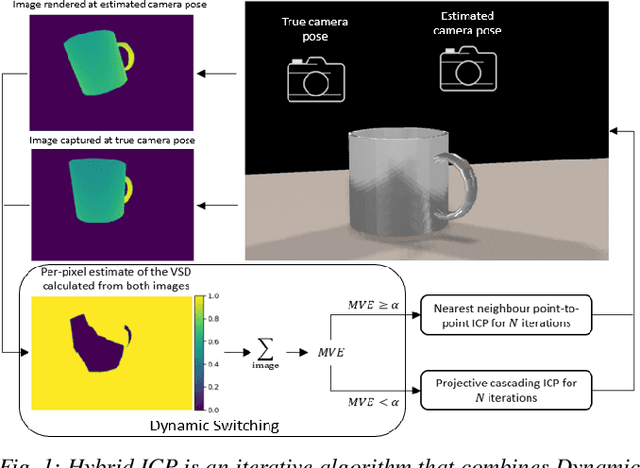

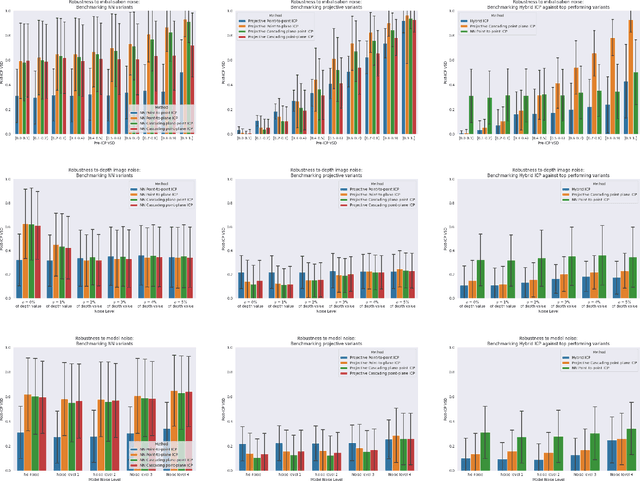

ICP algorithms typically involve a fixed choice of data association method and a fixed choice of error metric. In this paper, we propose Hybrid ICP, a novel and flexible ICP variant which dynamically optimises both the data association method and error metric based on the live image of an object and the current ICP estimate. We show that when used for object pose estimation, Hybrid ICP is more accurate and more robust to noise than other commonly used ICP variants. We also consider the setting where ICP is applied sequentially with a moving camera, and we study the trade-off between the accuracy of each ICP estimate and the number of ICP estimates available within a fixed amount of time.
MultiTask-CenterNet (MCN): Efficient and Diverse Multitask Learning using an Anchor Free Approach
Aug 11, 2021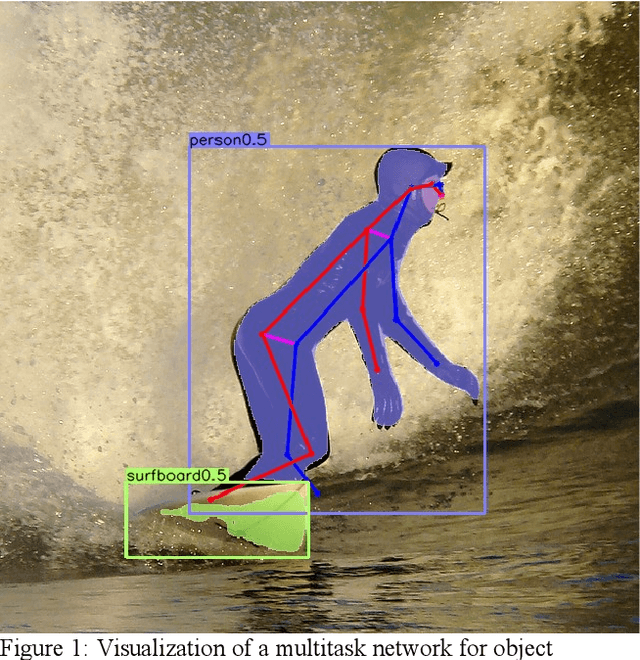

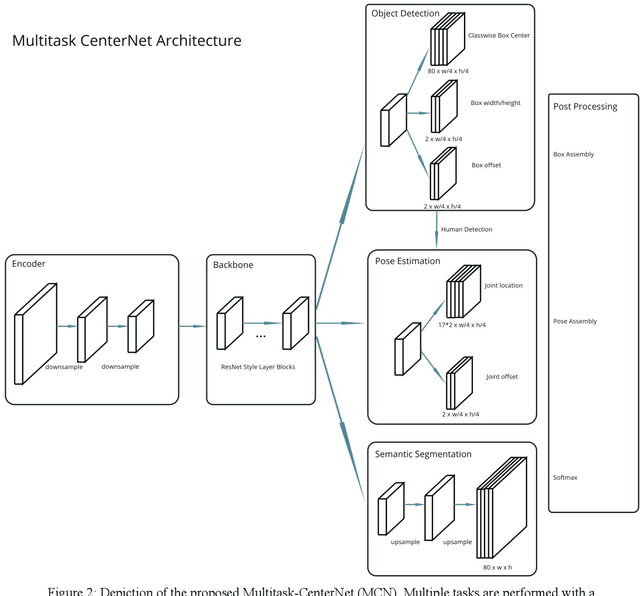
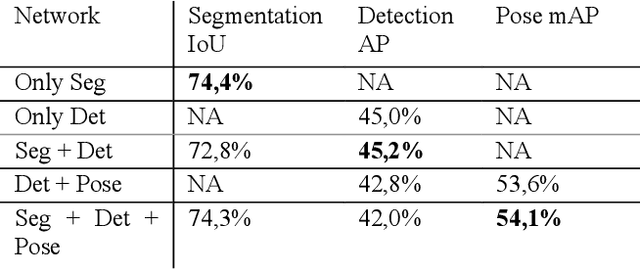
Multitask learning is a common approach in machine learning, which allows to train multiple objectives with a shared architecture. It has been shown that by training multiple tasks together inference time and compute resources can be saved, while the objectives performance remains on a similar or even higher level. However, in perception related multitask networks only closely related tasks can be found, such as object detection, instance and semantic segmentation or depth estimation. Multitask networks with diverse tasks and their effects with respect to efficiency on one another are not well studied. In this paper we augment the CenterNet anchor-free approach for training multiple diverse perception related tasks together, including the task of object detection and semantic segmentation as well as human pose estimation. We refer to this DNN as Multitask-CenterNet (MCN). Additionally, we study different MCN settings for efficiency. The MCN can perform several tasks at once while maintaining, and in some cases even exceeding, the performance values of its corresponding single task networks. More importantly, the MCN architecture decreases inference time and reduces network size when compared to a composition of single task networks.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021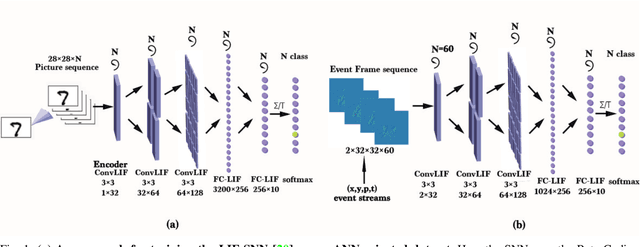
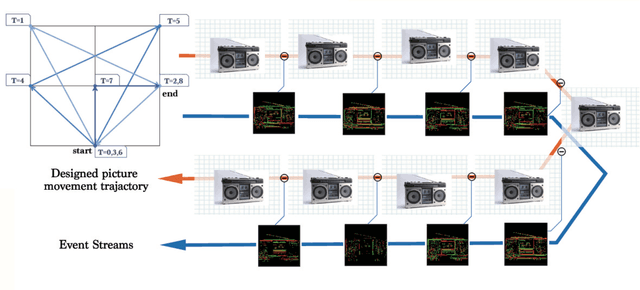
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Jul 11, 2021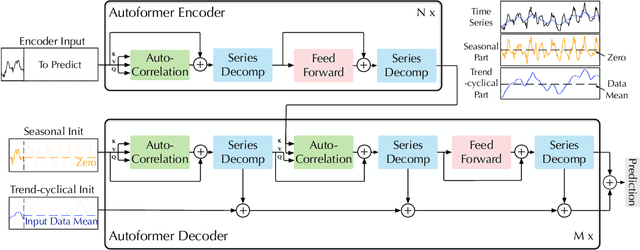
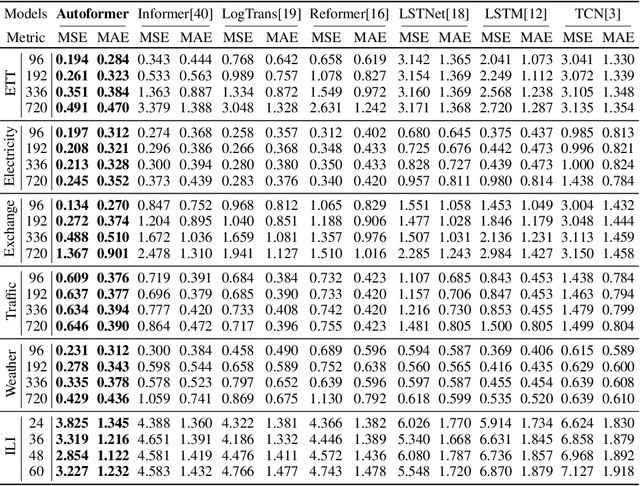
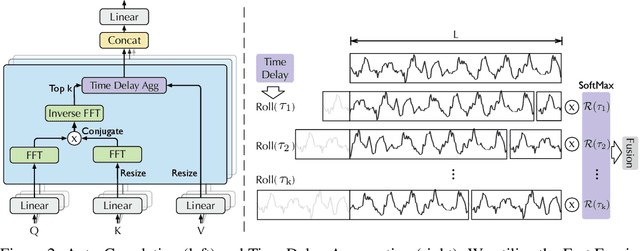
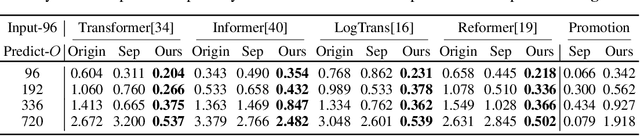
Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the \textit{long-term forecasting} problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Towards these challenges, we propose Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We go beyond the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.
Fractional order magnetic resonance fingerprinting in the human cerebral cortex
Jun 09, 2021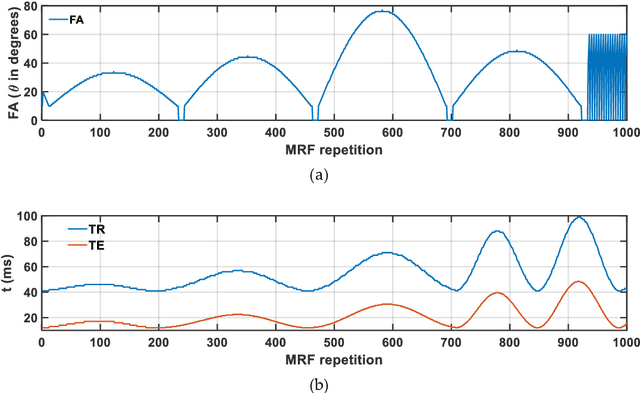
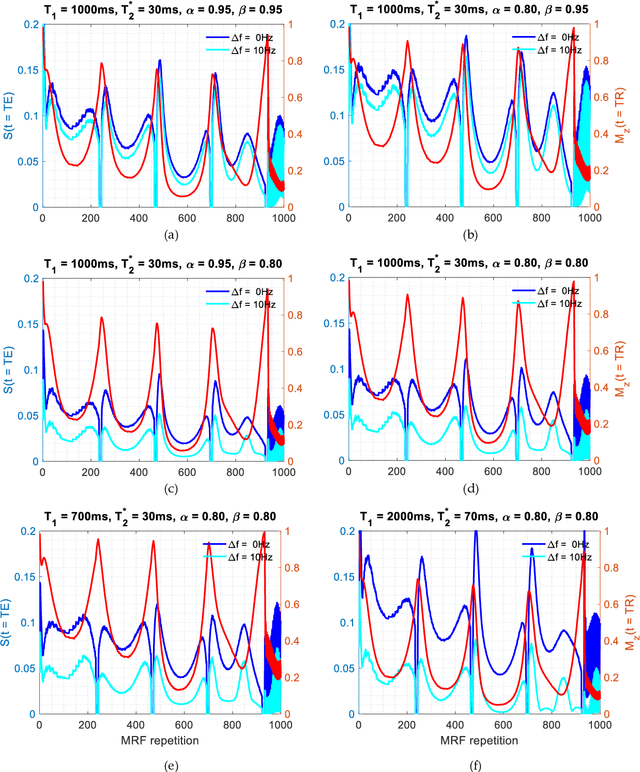
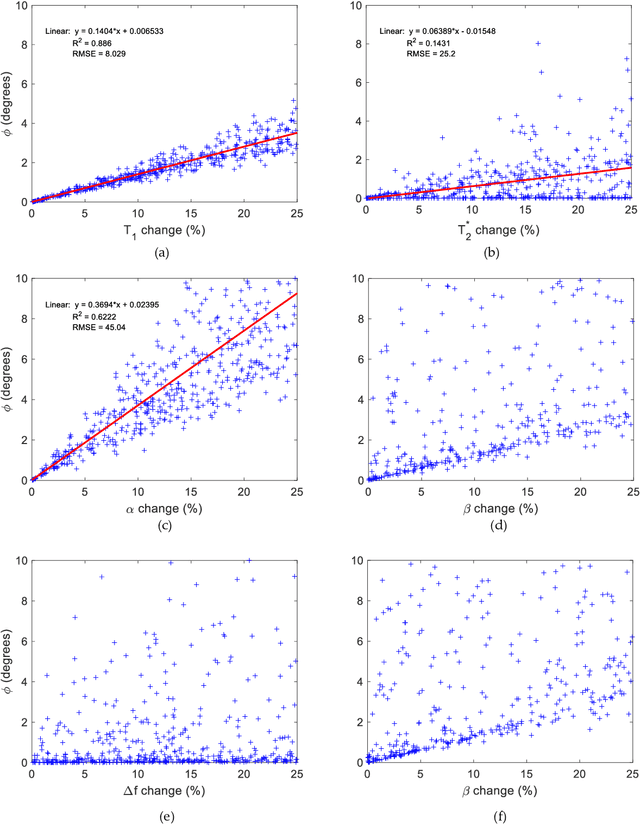
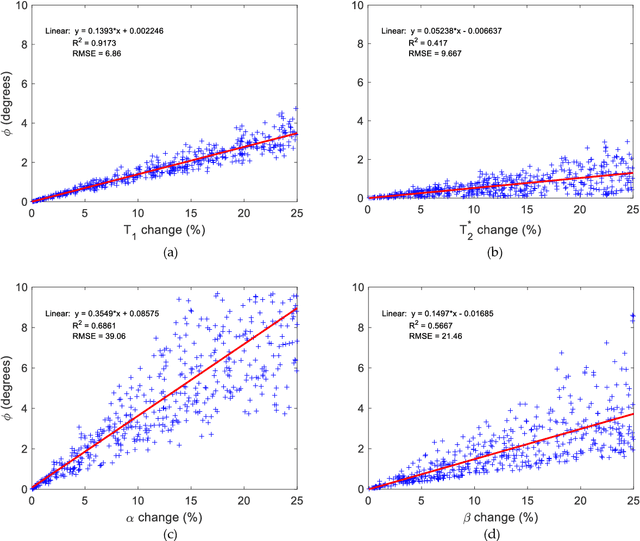
Mathematical models are becoming increasingly important in magnetic resonance imaging (MRI), as they provide a mechanistic approach for making a link between tissue microstructure and signals acquired using the medical imaging instrument. The Bloch equations, which describes spin and relaxation in a magnetic field, is a set of integer order differential equations with a solution exhibiting mono-exponential behaviour in time. Parameters of the model may be estimated using a non-linear solver, or by creating a dictionary of model parameters from which MRI signals are simulated and then matched with experiment. We have previously shown the potential efficacy of a magnetic resonance fingerprinting (MRF) approach, i.e. dictionary matching based on the classical Bloch equations, for parcellating the human cerebral cortex. However, this classical model is unable to describe in full the mm-scale MRI signal generated based on an heterogenous and complex tissue micro-environment. The time-fractional order Bloch equations has been shown to provide, as a function of time, a good fit of brain MRI signals. We replaced the integer order Bloch equations with the previously reported time-fractional counterpart within the MRF framework and performed experiments to parcellate human gray matter, which is cortical brain tissue with different cyto-architecture at different spatial locations. Our findings suggest that the time-fractional order parameters, {\alpha} and {\beta}, potentially associate with the effect of interareal architectonic variability, hypothetically leading to more accurate cortical parcellation.
All-neural beamformer for continuous speech separation
Oct 13, 2021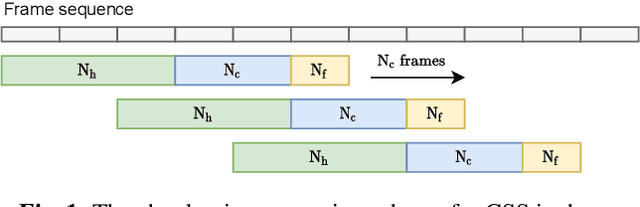
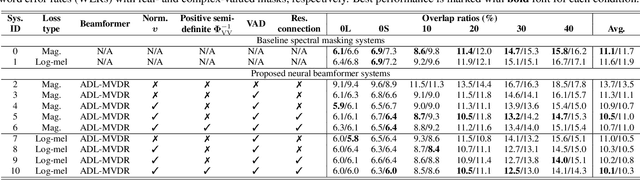

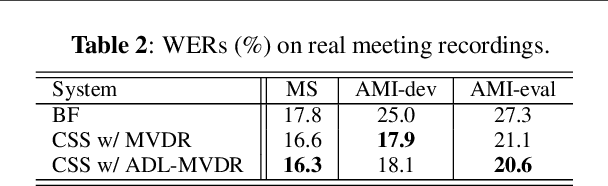
Continuous speech separation (CSS) aims to separate overlapping voices from a continuous influx of conversational audio containing an unknown number of utterances spoken by an unknown number of speakers. A common application scenario is transcribing a meeting conversation recorded by a microphone array. Prior studies explored various deep learning models for time-frequency mask estimation, followed by a minimum variance distortionless response (MVDR) filter to improve the automatic speech recognition (ASR) accuracy. The performance of these methods is fundamentally upper-bounded by MVDR's spatial selectivity. Recently, the all deep learning MVDR (ADL-MVDR) model was proposed for neural beamforming and demonstrated superior performance in a target speech extraction task using pre-segmented input. In this paper, we further adapt ADL-MVDR to the CSS task with several enhancements to enable end-to-end neural beamforming. The proposed system achieves significant word error rate reduction over a baseline spectral masking system on the LibriCSS dataset. Moreover, the proposed neural beamformer is shown to be comparable to a state-of-the-art MVDR-based system in real meeting transcription tasks, including AMI, while showing potentials to further simplify the runtime implementation and reduce the system latency with frame-wise processing.
Multi Scale Graph Wavenet for Spatio-temporal Wind Speed Forecasting
Sep 30, 2021
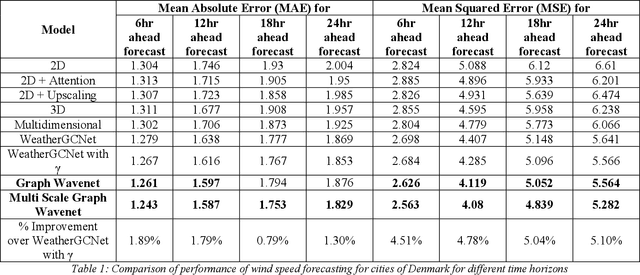
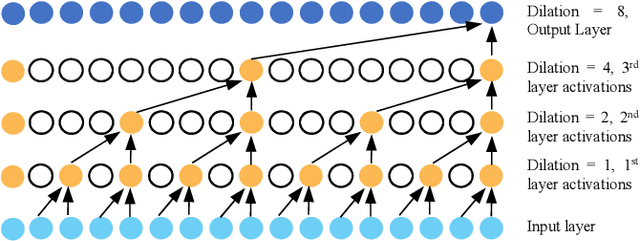
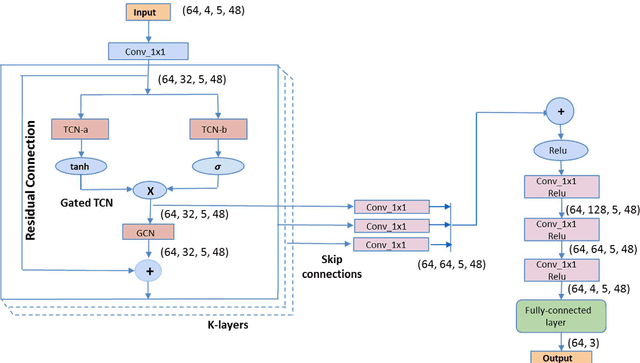
Geometric deep learning has gained tremendous attention in both academia and industry due to its inherent capability of representing arbitrary structures. Due to exponential increase in interest towards renewable sources of energy, especially wind energy, accurate wind speed forecasting has become very important. . In this paper, we propose a novel deep learning architecture, Multi Scale Graph Wavenet for wind speed forecasting. It is based on a graph convolutional neural network and captures both spatial and temporal relationships in multivariate time series weather data for wind speed forecasting. We especially took inspiration from dilated convolutions, skip connections and the inception network to capture temporal relationships and graph convolutional networks for capturing spatial relationships in the data. We conducted experiments on real wind speed data measured at different cities in Denmark and compared our results with the state-of-the-art baseline models. Our novel architecture outperformed the state-of-the-art methods on wind speed forecasting for multiple forecast horizons by 4-5%.
Back to Basics: Efficient Network Compression via IMP
Nov 01, 2021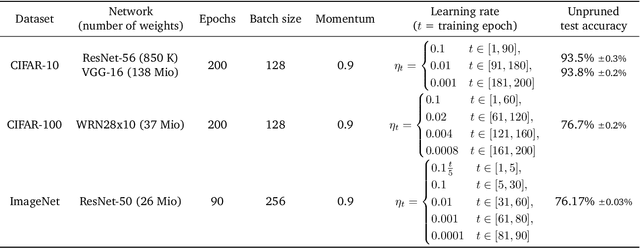
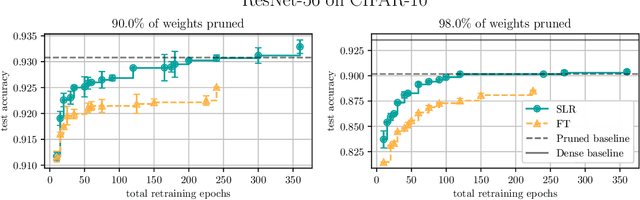
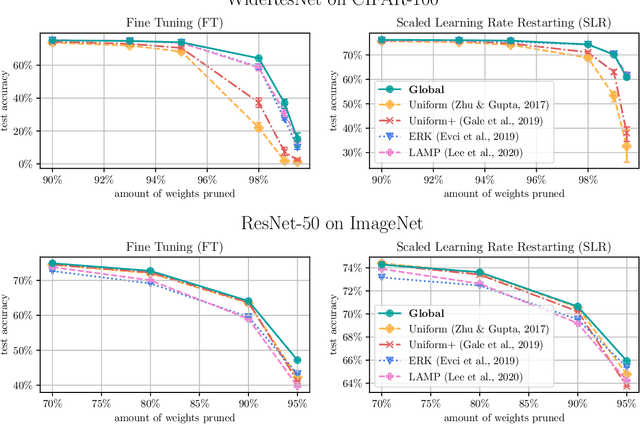
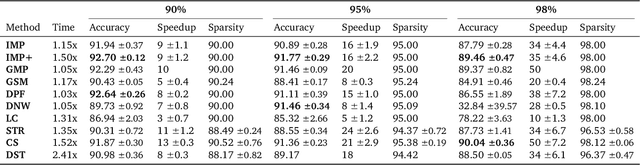
Network pruning is a widely used technique for effectively compressing Deep Neural Networks with little to no degradation in performance during inference. Iterative Magnitude Pruning (IMP) is one of the most established approaches for network pruning, consisting of several iterative training and pruning steps, where a significant amount of the network's performance is lost after pruning and then recovered in the subsequent retraining phase. While commonly used as a benchmark reference, it is often argued that a) it reaches suboptimal states by not incorporating sparsification into the training phase, b) its global selection criterion fails to properly determine optimal layer-wise pruning rates and c) its iterative nature makes it slow and non-competitive. In light of recently proposed retraining techniques, we investigate these claims through rigorous and consistent experiments where we compare IMP to pruning-during-training algorithms, evaluate proposed modifications of its selection criterion and study the number of iterations and total training time actually required. We find that IMP with SLR for retraining can outperform state-of-the-art pruning-during-training approaches without or with only little computational overhead, that the global magnitude selection criterion is largely competitive with more complex approaches and that only few retraining epochs are needed in practice to achieve most of the sparsity-vs.-performance tradeoff of IMP. Our goals are both to demonstrate that basic IMP can already provide state-of-the-art pruning results on par with or even outperforming more complex or heavily parameterized approaches and also to establish a more realistic yet easily realisable baseline for future research.
Learning Optimal Conformal Classifiers
Oct 18, 2021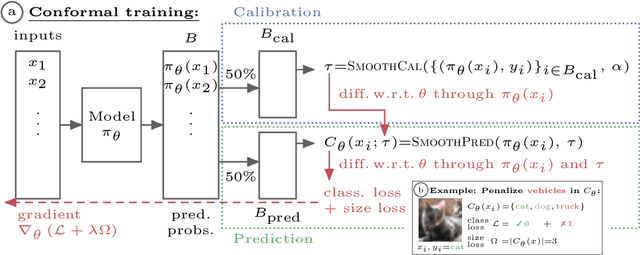
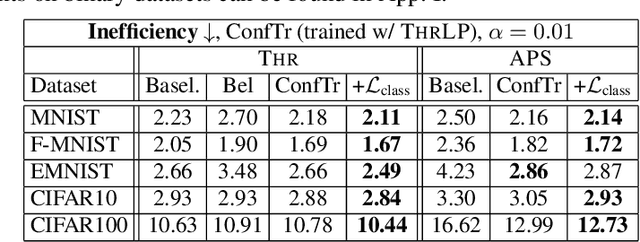

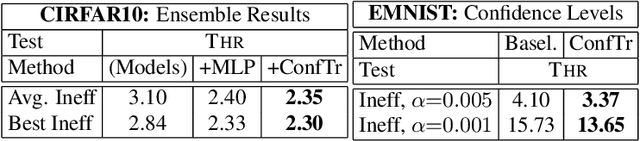
Modern deep learning based classifiers show very high accuracy on test data but this does not provide sufficient guarantees for safe deployment, especially in high-stake AI applications such as medical diagnosis. Usually, predictions are obtained without a reliable uncertainty estimate or a formal guarantee. Conformal prediction (CP) addresses these issues by using the classifier's probability estimates to predict confidence sets containing the true class with a user-specified probability. However, using CP as a separate processing step after training prevents the underlying model from adapting to the prediction of confidence sets. Thus, this paper explores strategies to differentiate through CP during training with the goal of training model with the conformal wrapper end-to-end. In our approach, conformal training (ConfTr), we specifically "simulate" conformalization on mini-batches during training. We show that CT outperforms state-of-the-art CP methods for classification by reducing the average confidence set size (inefficiency). Moreover, it allows to "shape" the confidence sets predicted at test time, which is difficult for standard CP. On experiments with several datasets, we show ConfTr can influence how inefficiency is distributed across classes, or guide the composition of confidence sets in terms of the included classes, while retaining the guarantees offered by CP.
Habitual and Reflective Control in Hierarchical Predictive Coding
Sep 02, 2021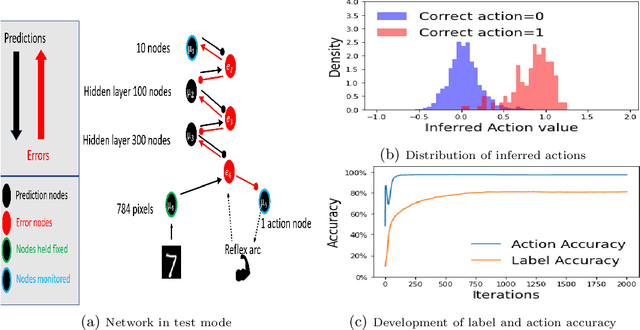
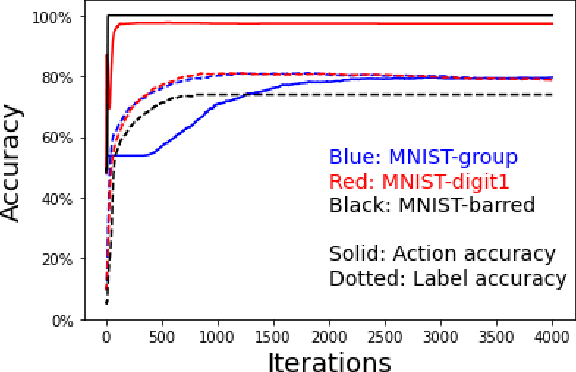
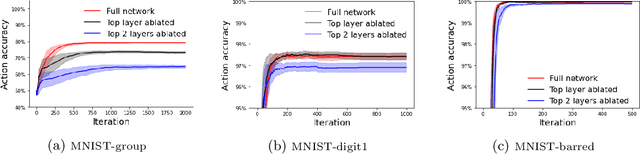
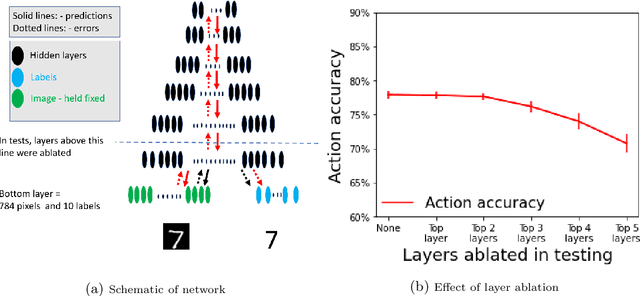
In cognitive science, behaviour is often separated into two types. Reflexive control is habitual and immediate, whereas reflective is deliberative and time consuming. We examine the argument that Hierarchical Predictive Coding (HPC) can explain both types of behaviour as a continuum operating across a multi-layered network, removing the need for separate circuits in the brain. On this view, "fast" actions may be triggered using only the lower layers of the HPC schema, whereas more deliberative actions need higher layers. We demonstrate that HPC can distribute learning throughout its hierarchy, with higher layers called into use only as required.