 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
Nov 01, 2021
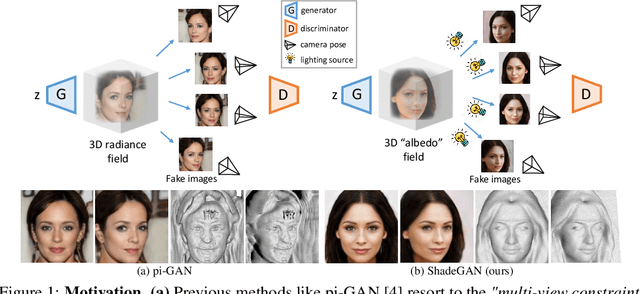
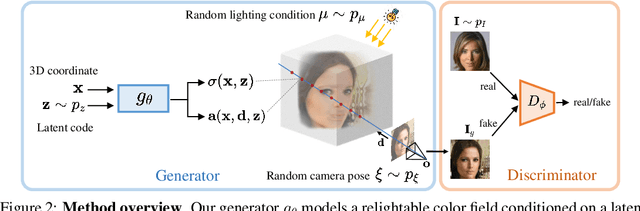
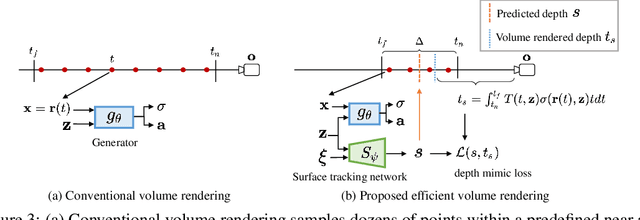

The advancement of generative radiance fields has pushed the boundary of 3D-aware image synthesis. Motivated by the observation that a 3D object should look realistic from multiple viewpoints, these methods introduce a multi-view constraint as regularization to learn valid 3D radiance fields from 2D images. Despite the progress, they often fall short of capturing accurate 3D shapes due to the shape-color ambiguity, limiting their applicability in downstream tasks. In this work, we address this ambiguity by proposing a novel shading-guided generative implicit model that is able to learn a starkly improved shape representation. Our key insight is that an accurate 3D shape should also yield a realistic rendering under different lighting conditions. This multi-lighting constraint is realized by modeling illumination explicitly and performing shading with various lighting conditions. Gradients are derived by feeding the synthesized images to a discriminator. To compensate for the additional computational burden of calculating surface normals, we further devise an efficient volume rendering strategy via surface tracking, reducing the training and inference time by 24% and 48%, respectively. Our experiments on multiple datasets show that the proposed approach achieves photorealistic 3D-aware image synthesis while capturing accurate underlying 3D shapes. We demonstrate improved performance of our approach on 3D shape reconstruction against existing methods, and show its applicability on image relighting. Our code will be released at https://github.com/XingangPan/ShadeGAN.
Deep Identification of Nonlinear Systems in Koopman Form
Oct 06, 2021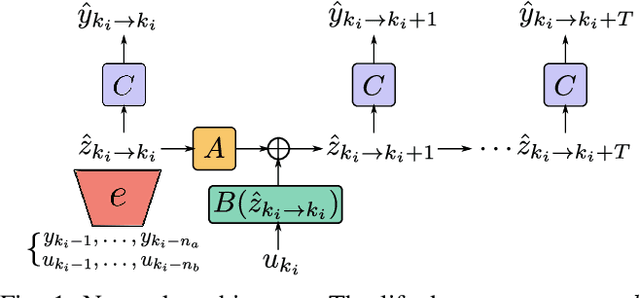
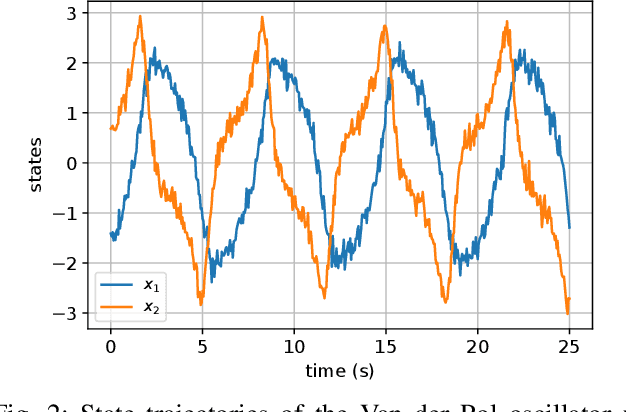
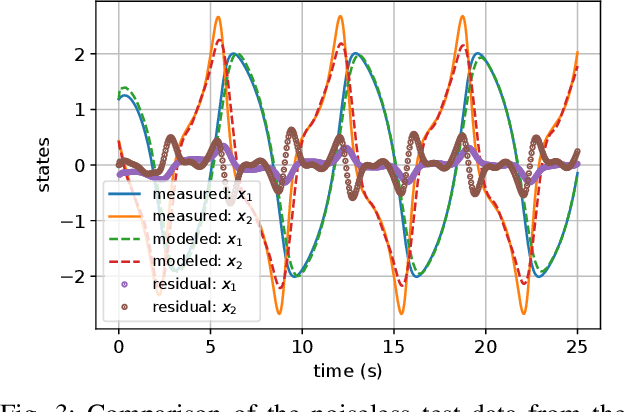
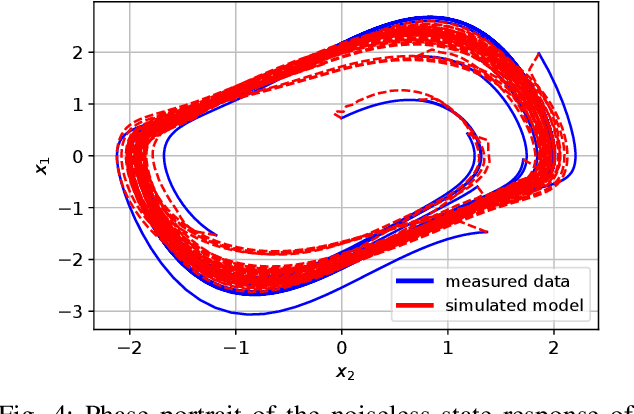
The present paper treats the identification of nonlinear dynamical systems using Koopman-based deep state-space encoders. Through this method, the usual drawback of needing to choose a dictionary of lifting functions a priori is circumvented. The encoder represents the lifting function to the space where the dynamics are linearly propagated using the Koopman operator. An input-affine formulation is considered for the lifted model structure and we address both full and partial state availability. The approach is implemented using the the deepSI toolbox in Python. To lower the computational need of the simulation error-based training, the data is split into subsections where multi-step prediction errors are calculated independently. This formulation allows for efficient batch optimization of the network parameters and, at the same time, excellent long term prediction capabilities of the obtained models. The performance of the approach is illustrated by nonlinear benchmark examples.
Exploring Non-Autoregressive End-To-End Neural Modeling For English Mispronunciation Detection And Diagnosis
Nov 01, 2021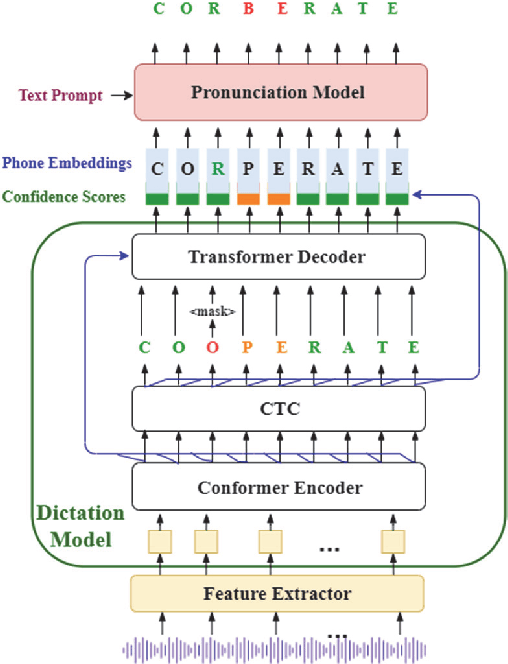
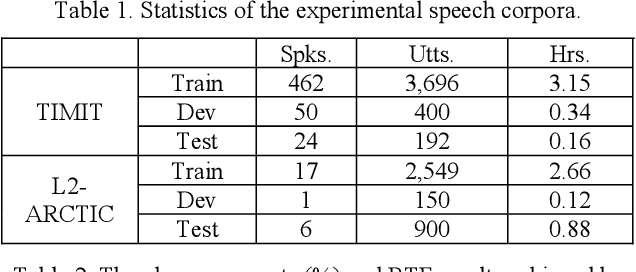
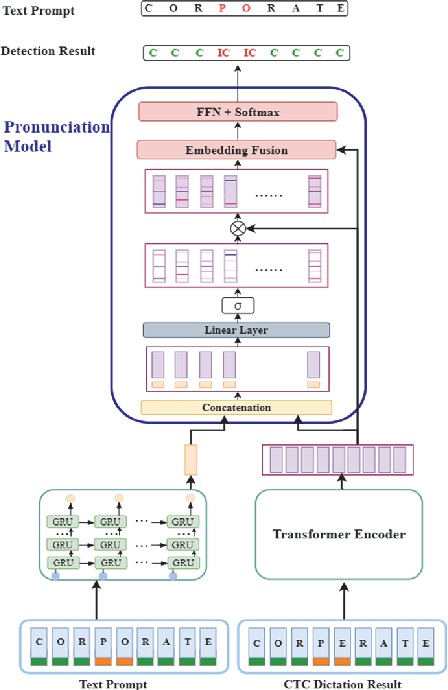
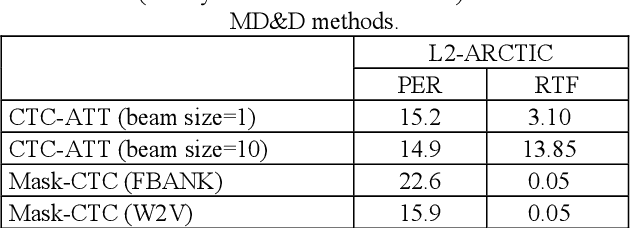
End-to-end (E2E) neural modeling has emerged as one predominant school of thought to develop computer-assisted language training (CAPT) systems, showing competitive performance to conventional pronunciation-scoring based methods. However, current E2E neural methods for CAPT are faced with at least two pivotal challenges. On one hand, most of the E2E methods operate in an autoregressive manner with left-to-right beam search to dictate the pronunciations of an L2 learners. This however leads to very slow inference speed, which inevitably hinders their practical use. On the other hand, E2E neural methods are normally data greedy and meanwhile an insufficient amount of nonnative training data would often reduce their efficacy on mispronunciation detection and diagnosis (MD&D). In response, we put forward a novel MD&D method that leverages non-autoregressive (NAR) E2E neural modeling to dramatically speed up the inference time while maintaining performance in line with the conventional E2E neural methods. In addition, we design and develop a pronunciation modeling network stacked on top of the NAR E2E models of our method to further boost the effectiveness of MD&D. Empirical experiments conducted on the L2-ARCTIC English dataset seems to validate the feasibility of our method, in comparison to some top-of-the-line E2E models and an iconic pronunciation-scoring based method built on a DNN-HMM acoustic model.
A Short Study on Compressing Decoder-Based Language Models
Oct 16, 2021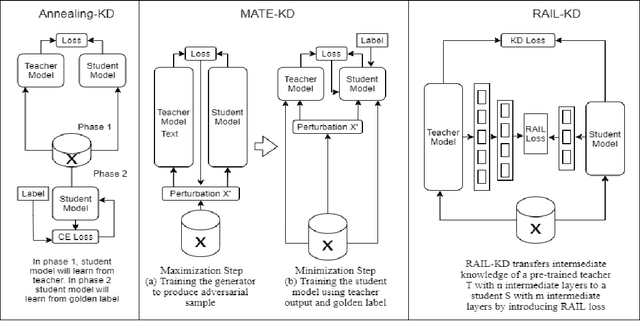
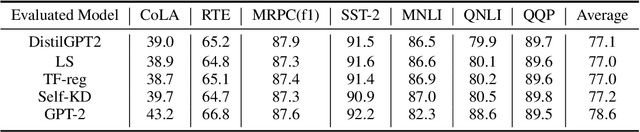

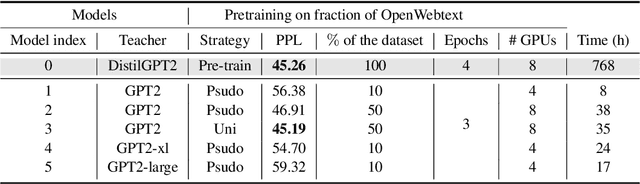
Pre-trained Language Models (PLMs) have been successful for a wide range of natural language processing (NLP) tasks. The state-of-the-art of PLMs, however, are extremely large to be used on edge devices. As a result, the topic of model compression has attracted increasing attention in the NLP community. Most of the existing works focus on compressing encoder-based models (tiny-BERT, distilBERT, distilRoBERTa, etc), however, to the best of our knowledge, the compression of decoder-based models (such as GPT-2) has not been investigated much. Our paper aims to fill this gap. Specifically, we explore two directions: 1) we employ current state-of-the-art knowledge distillation techniques to improve fine-tuning of DistilGPT-2. 2) we pre-train a compressed GPT-2 model using layer truncation and compare it against the distillation-based method (DistilGPT2). The training time of our compressed model is significantly less than DistilGPT-2, but it can achieve better performance when fine-tuned on downstream tasks. We also demonstrate the impact of data cleaning on model performance.
Augmentation Pathways Network for Visual Recognition
Jul 26, 2021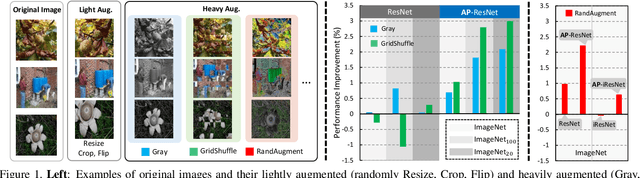

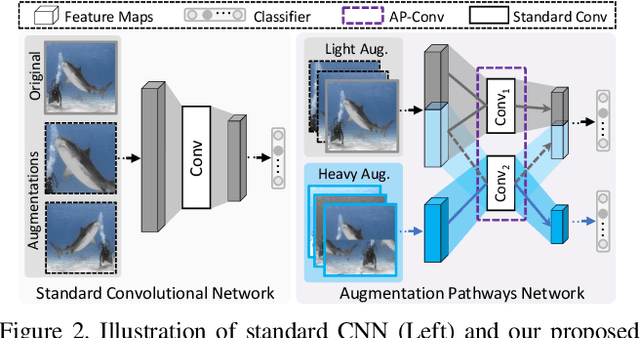
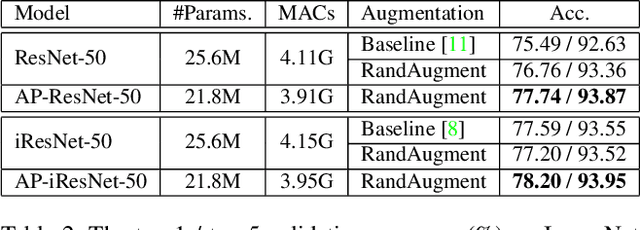
Data augmentation is practically helpful for visual recognition, especially at the time of data scarcity. However, such success is only limited to quite a few light augmentations (e.g., random crop, flip). Heavy augmentations (e.g., gray, grid shuffle) are either unstable or show adverse effects during training, owing to the big gap between the original and augmented images. This paper introduces a novel network design, noted as Augmentation Pathways (AP), to systematically stabilize training on a much wider range of augmentation policies. Notably, AP tames heavy data augmentations and stably boosts performance without a careful selection among augmentation policies. Unlike traditional single pathway, augmented images are processed in different neural paths. The main pathway handles light augmentations, while other pathways focus on heavy augmentations. By interacting with multiple paths in a dependent manner, the backbone network robustly learns from shared visual patterns among augmentations, and suppresses noisy patterns at the same time. Furthermore, we extend AP to a homogeneous version and a heterogeneous version for high-order scenarios, demonstrating its robustness and flexibility in practical usage. Experimental results on ImageNet benchmarks demonstrate the compatibility and effectiveness on a much wider range of augmentations (e.g., Crop, Gray, Grid Shuffle, RandAugment), while consuming fewer parameters and lower computational costs at inference time. Source code:https://github.com/ap-conv/ap-net.
Proceedings Third Workshop on Formal Methods for Autonomous Systems
Oct 22, 2021Autonomous systems are highly complex and present unique challenges for the application of formal methods. Autonomous systems act without human intervention, and are often embedded in a robotic system, so that they can interact with the real world. As such, they exhibit the properties of safety-critical, cyber-physical, hybrid, and real-time systems. This EPTCS volume contains the proceedings for the third workshop on Formal Methods for Autonomous Systems (FMAS 2021), which was held virtually on the 21st and 22nd of October 2021. Like the previous workshop, FMAS 2021 was an online, stand-alone event, as an adaptation to the ongoing COVID-19 restrictions. Despite the challenges this brought, we were determined to build on the success of the previous two FMAS workshops. The goal of FMAS is to bring together leading researchers who are tackling the unique challenges of autonomous systems using formal methods, to present recent and ongoing work. We are interested in the use of formal methods to specify, model, or verify autonomous and/or robotic systems; in whole or in part. We are also interested in successful industrial applications and potential future directions for this emerging application of formal methods.
MoTiAC: Multi-Objective Actor-Critics for Real-Time Bidding
Feb 18, 2020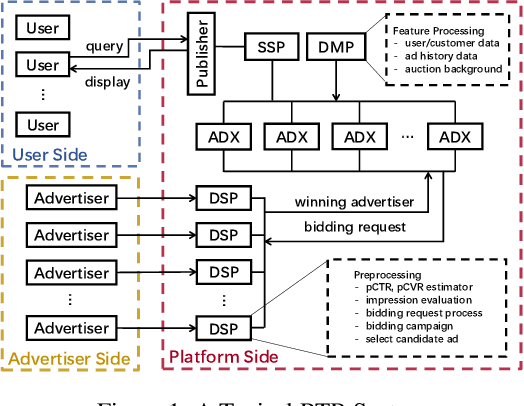
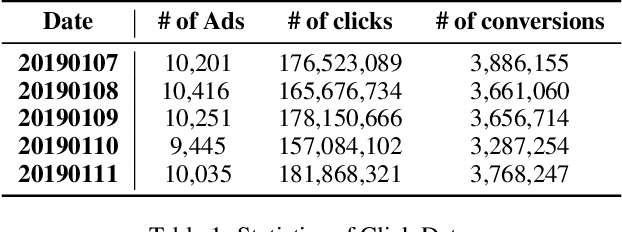
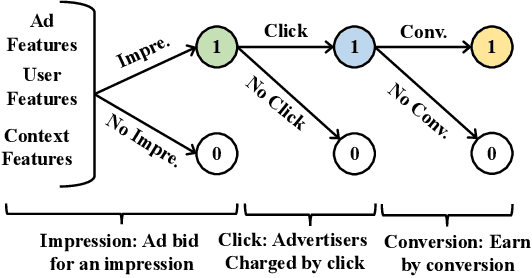
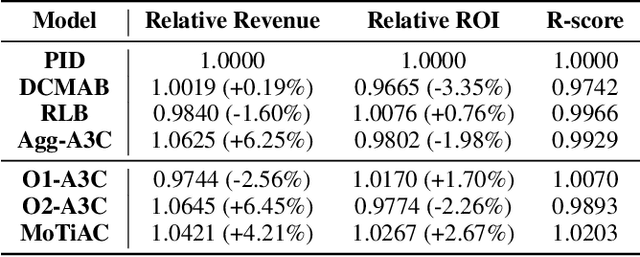
Online real-time bidding (RTB) is known as a complex auction game where ad platforms seek to consider various influential key performance indicators (KPIs), like revenue and return on investment (ROI). The trade-off among these competing goals needs to be balanced on a massive scale. To address the problem, we propose a multi-objective reinforcement learning algorithm, named MoTiAC, for the problem of bidding optimization with various goals. Specifically, in MoTiAC, instead of using a fixed and linear combination of multiple objectives, we compute adaptive weights overtime on the basis of how well the current state agrees with the agent's prior. In addition, we provide interesting properties of model updating and further prove that Pareto optimality could be guaranteed. We demonstrate the effectiveness of our method on a real-world commercial dataset. Experiments show that the model outperforms all state-of-the-art baselines.
Sequential Decision-Making for Active Object Detection from Hand
Oct 21, 2021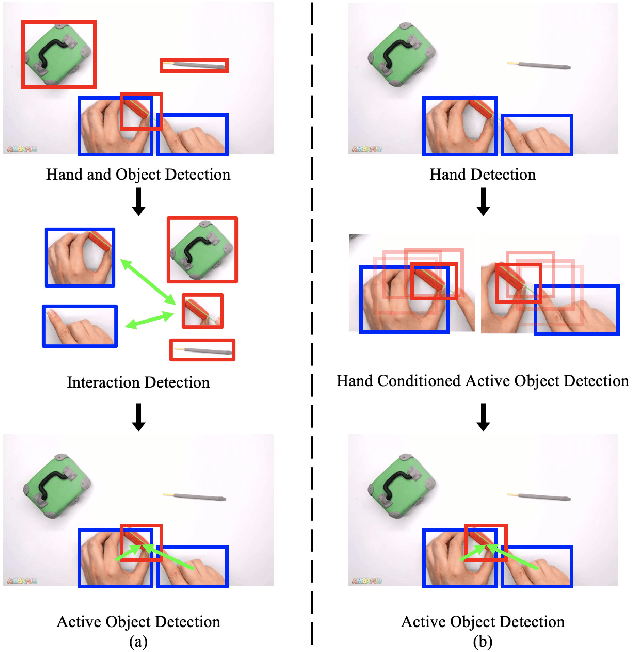

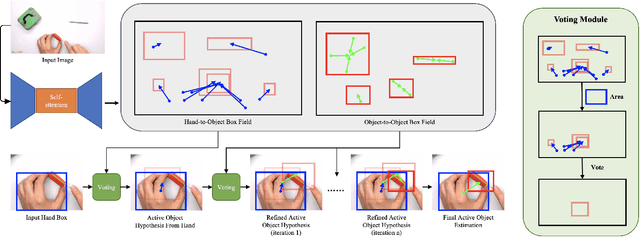

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand -- despite the occlusion induced by hand-object interactions. Based on the observation that hand appearance is a strong indicator of the location and size of the active object, we set up our active object detection method as a sequential decision-making process that is conditioned on the location and appearance of the hands. The key innovation of our approach is the design of the active object detection policy that uses an internal representation called the Relational Box Field, which allows for every pixel to regress an improved location of an active object bounding box, essentially giving every pixel the ability to vote for a better bounding box location. The policy is trained using a hybrid imitation learning and reinforcement learning approach, and at test time, the policy is used repeatedly to refine the bounding box location of the active object. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
Thrust Direction Control of an Underactuated Oscillating Swimming Robot
Jul 27, 2021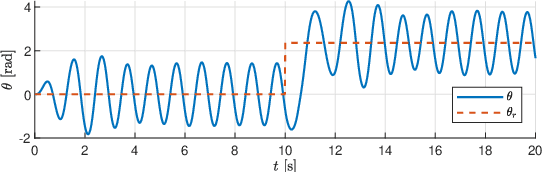
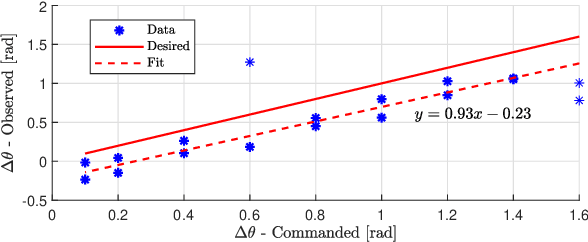
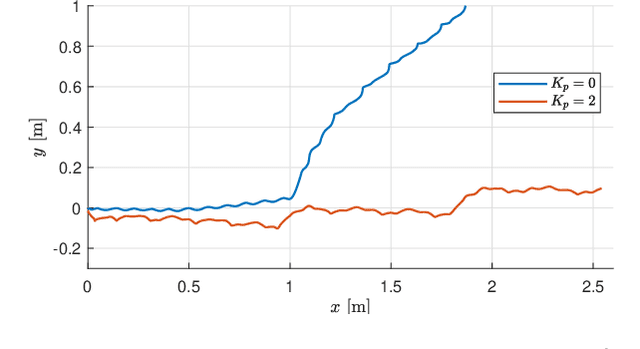
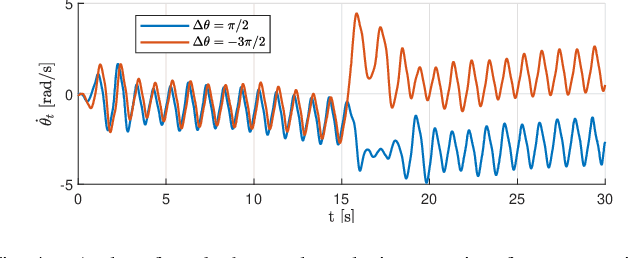
The Modboat is an autonomous surface robot that turns the oscillation of a single motor into a controlled paddling motion through passive flippers. Inertial control methods developed in prior work can successfully drive the Modboat along trajectories and enable docking to neighboring modules, but have a non-constant cycle time and cannot react to dynamic environments. In this work we present a thrust direction control method for the Modboat that significantly improves the time-response of the system and increases the accuracy with which it can be controlled. We experimentally demonstrate that this method can be used to perform more compact maneuvers than prior methods or comparable robots can. We also present an extension to the controller that solves the reaction wheel problem of unbounded actuator velocity, and show that it further improves performance.
A Proximal Algorithm for Sampling from Non-smooth Potentials
Oct 09, 2021
Markov chain Monte Carlo (MCMC) is an effective and dominant method to sample from high-dimensional complex distributions. Yet, most existing MCMC methods are only applicable to settings with smooth potentials (log-densities). In this work, we examine sampling problems with non-smooth potentials. We propose a novel MCMC algorithm for sampling from non-smooth potentials. We provide a non-asymptotical analysis of our algorithm and establish a polynomial-time complexity $\tilde {\cal O}(d\varepsilon^{-1})$ to obtain $\varepsilon$ total variation distance to the target density, better than all existing results under the same assumptions. Our method is based on the proximal bundle method and an alternating sampling framework. This framework requires the so-called restricted Gaussian oracle, which can be viewed as a sampling counterpart of the proximal mapping in convex optimization. One key contribution of this work is a fast algorithm that realizes the restricted Gaussian oracle for any convex non-smooth potential with bounded Lipschitz constant.