 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Convergence of Tsetlin Machines for the AND and the OR Operators
Sep 17, 2021

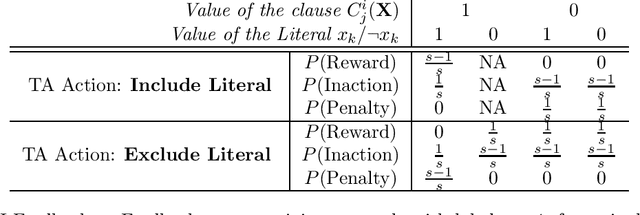
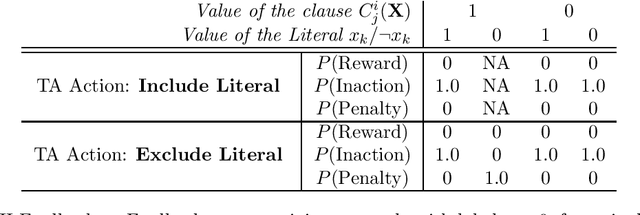
The Tsetlin Machine (TM) is a novel machine-learning algorithm based on propositional logic, which has obtained state-of-the-art performance on several pattern recognition problems. In previous studies, the convergence properties of TM for 1-bit operation and XOR operation have been analyzed. To make the analyses for the basic digital operations complete, in this article, we analyze the convergence when input training samples follow AND and OR operators respectively. Our analyses reveal that the TM can converge almost surely to reproduce AND and OR operators, which are learnt from training data over an infinite time horizon. The analyses on AND and OR operators, together with the previously analysed 1-bit and XOR operations, complete the convergence analyses on basic operators in Boolean algebra.
Learning to Describe Solutions for Bug Reports Based on Developer Discussions
Oct 08, 2021
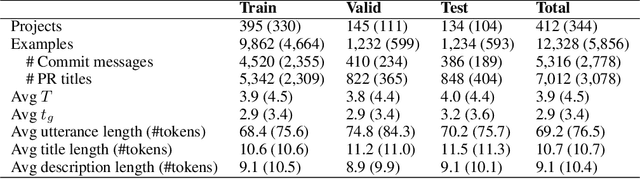

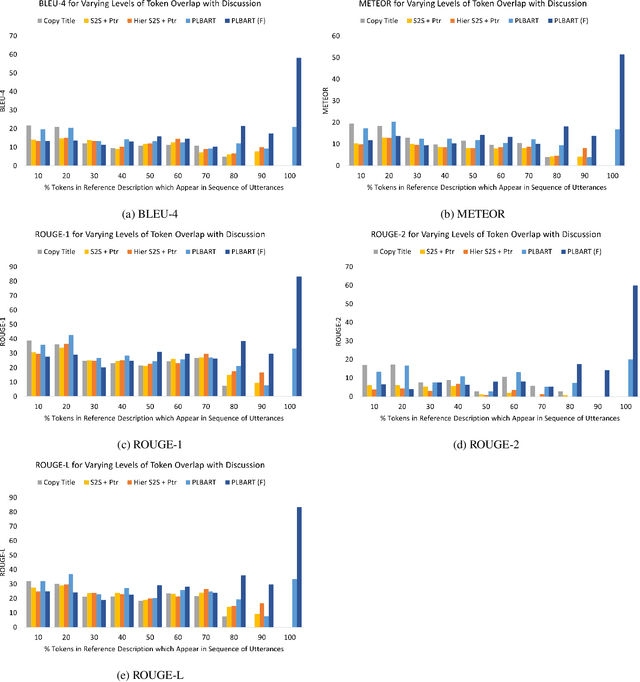
When a software bug is reported, developers engage in a discussion to collaboratively resolve it. While the solution is likely formulated within the discussion, it is often buried in a large amount of text, making it difficult to comprehend, which delays its implementation. To expedite bug resolution, we propose generating a concise natural language description of the solution by synthesizing relevant content within the discussion, which encompasses both natural language and source code. Furthermore, to support generating an informative description during an ongoing discussion, we propose a secondary task of determining when sufficient context about the solution emerges in real-time. We construct a dataset for these tasks with a novel technique for obtaining noisy supervision from repository changes linked to bug reports. We establish baselines for generating solution descriptions, and develop a classifier which makes a prediction following each new utterance on whether or not the necessary context for performing generation is available. Through automated and human evaluation, we find these tasks to form an ideal testbed for complex reasoning in long, bimodal dialogue context.
Fast Wireless Sensor Anomaly Detection based on Data Stream in Edge Computing Enabled Smart Greenhouse
Jul 28, 2021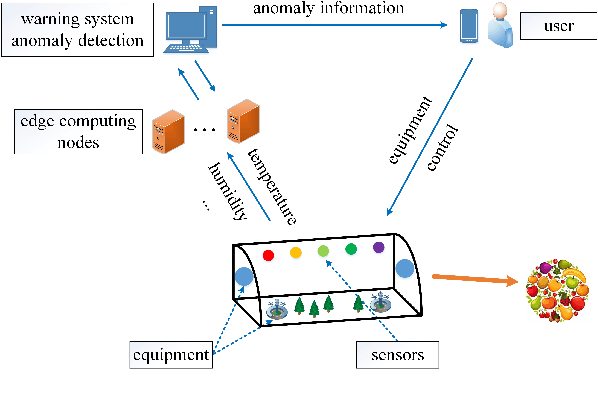
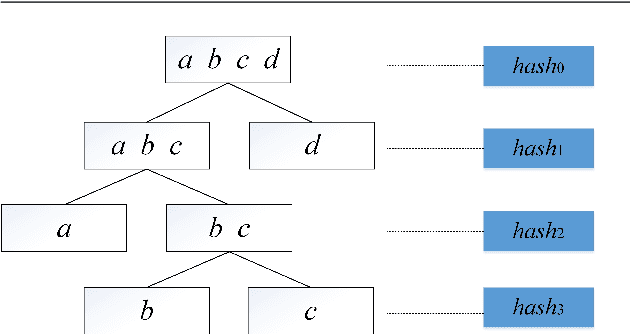

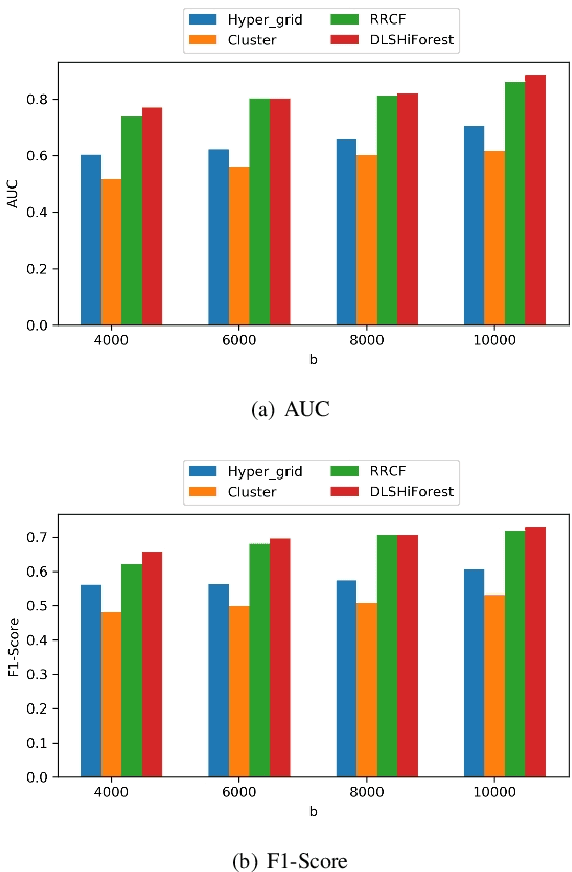
Edge computing enabled smart greenhouse is a representative application of Internet of Things technology, which can monitor the environmental information in real time and employ the information to contribute to intelligent decision-making. In the process, anomaly detection for wireless sensor data plays an important role. However, traditional anomaly detection algorithms originally designed for anomaly detection in static data have not properly considered the inherent characteristics of data stream produced by wireless sensor such as infiniteness, correlations and concept drift, which may pose a considerable challenge on anomaly detection based on data stream, and lead to low detection accuracy and efficiency. First, data stream usually generates quickly which means that it is infinite and enormous, so any traditional off-line anomaly detection algorithm that attempts to store the whole dataset or to scan the dataset multiple times for anomaly detection will run out of memory space. Second, there exist correlations among different data streams, which traditional algorithms hardly consider. Third, the underlying data generation process or data distribution may change over time. Thus, traditional anomaly detection algorithms with no model update will lose their effects. Considering these issues, a novel method (called DLSHiForest) on basis of Locality-Sensitive Hashing and time window technique in this paper is proposed to solve these problems while achieving accurate and efficient detection. Comprehensive experiments are executed using real-world agricultural greenhouse dataset to demonstrate the feasibility of our approach. Experimental results show that our proposal is practicable in addressing challenges of traditional anomaly detection while ensuring accuracy and efficiency.
Survey on Semantic Stereo Matching / Semantic Depth Estimation
Sep 21, 2021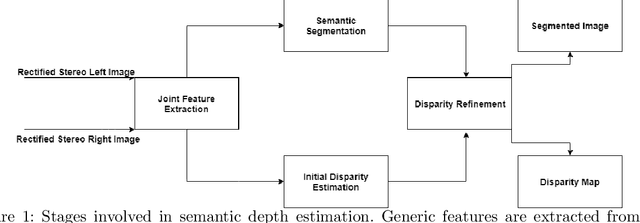
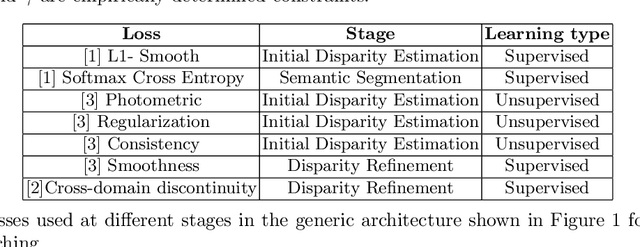
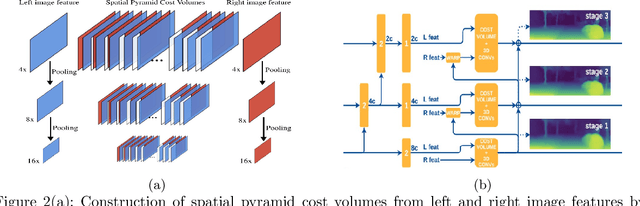

Stereo matching is one of the widely used techniques for inferring depth from stereo images owing to its robustness and speed. It has become one of the major topics of research since it finds its applications in autonomous driving, robotic navigation, 3D reconstruction, and many other fields. Finding pixel correspondences in non-textured, occluded and reflective areas is the major challenge in stereo matching. Recent developments have shown that semantic cues from image segmentation can be used to improve the results of stereo matching. Many deep neural network architectures have been proposed to leverage the advantages of semantic segmentation in stereo matching. This paper aims to give a comparison among the state of art networks both in terms of accuracy and in terms of speed which are of higher importance in real-time applications.
Cell-average based neural network method for hyperbolic and parabolic partial differential equations
Jul 02, 2021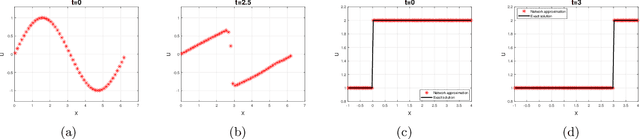
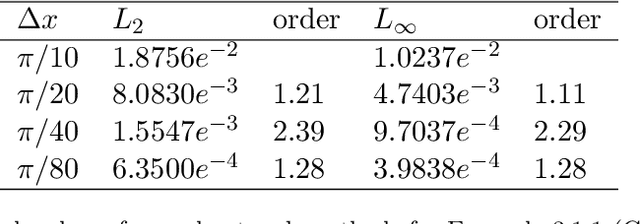
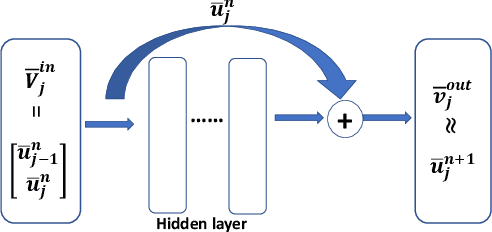

Motivated by finite volume scheme, a cell-average based neural network method is proposed. The method is based on the integral or weak formulation of partial differential equations. A simple feed forward network is forced to learn the solution average evolution between two neighboring time steps. Offline supervised training is carried out to obtain the optimal network parameter set, which uniquely identifies one finite volume like neural network method. Once well trained, the network method is implemented as a finite volume scheme, thus is mesh dependent. Different to traditional numerical methods, our method can be relieved from the explicit scheme CFL restriction and can adapt to any time step size for solution evolution. For Heat equation, first order of convergence is observed and the errors are related to the spatial mesh size but are observed independent of the mesh size in time. The cell-average based neural network method can sharply evolve contact discontinuity with almost zero numerical diffusion introduced. Shock and rarefaction waves are well captured for nonlinear hyperbolic conservation laws.
Auto-DSP: Learning to Optimize Acoustic Echo Cancellers
Oct 08, 2021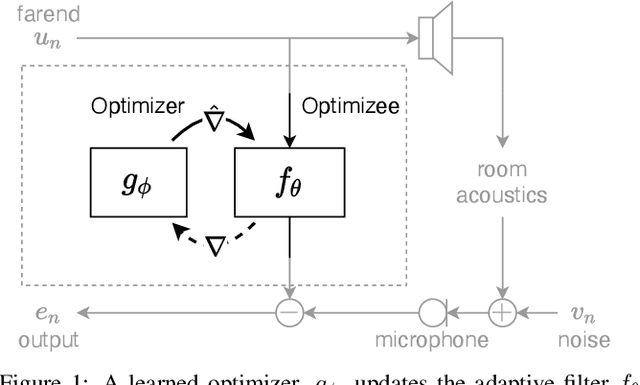
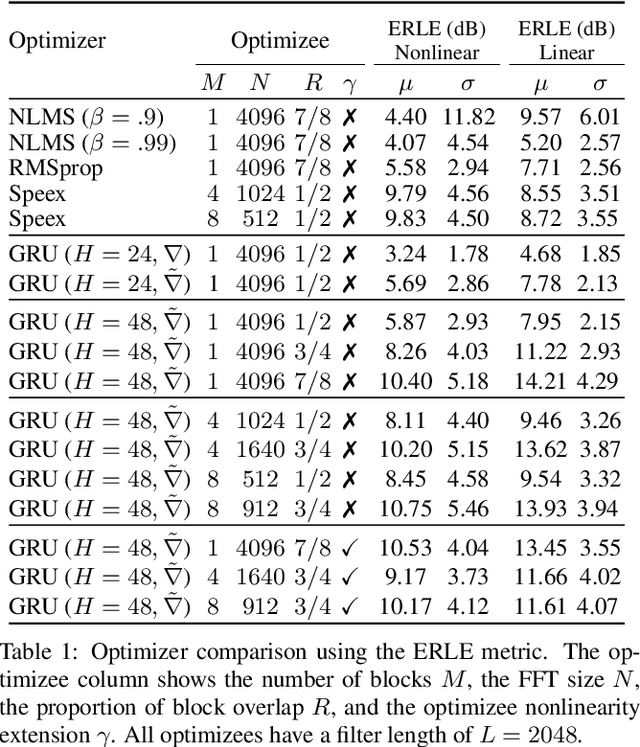
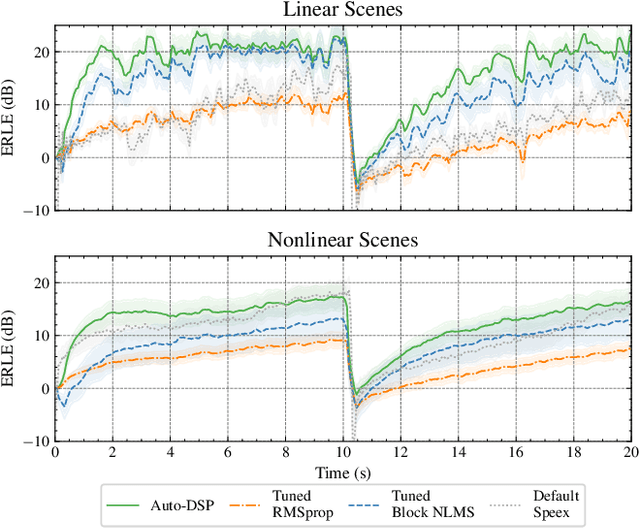
Adaptive filtering algorithms are commonplace in signal processing and have wide-ranging applications from single-channel denoising to multi-channel acoustic echo cancellation and adaptive beamforming. Such algorithms typically operate via specialized online, iterative optimization methods and have achieved tremendous success, but require expert knowledge, are slow to develop, and are difficult to customize. In our work, we present a new method to automatically learn adaptive filtering update rules directly from data. To do so, we frame adaptive filtering as a differentiable operator and train a learned optimizer to output a gradient descent-based update rule from data via backpropagation through time. We demonstrate our general approach on an acoustic echo cancellation task (single-talk with noise) and show that we can learn high-performing adaptive filters for a variety of common linear and non-linear multidelayed block frequency domain filter architectures. We also find that our learned update rules exhibit fast convergence, can optimize in the presence of nonlinearities, and are robust to acoustic scene changes despite never encountering any during training.
Robust Dynamic Bus Control: A Distributional Multi-agent Reinforcement Learning Approach
Nov 02, 2021
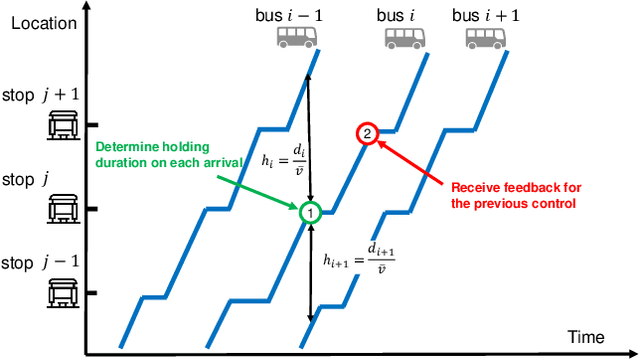
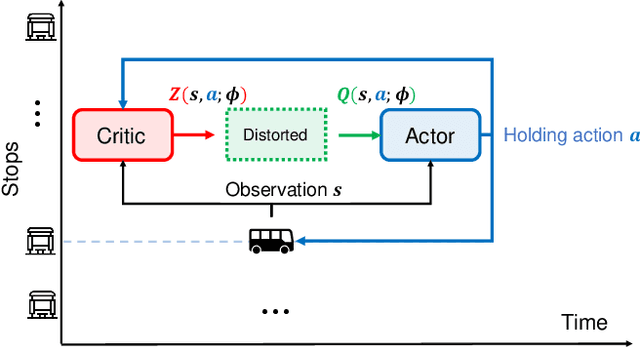
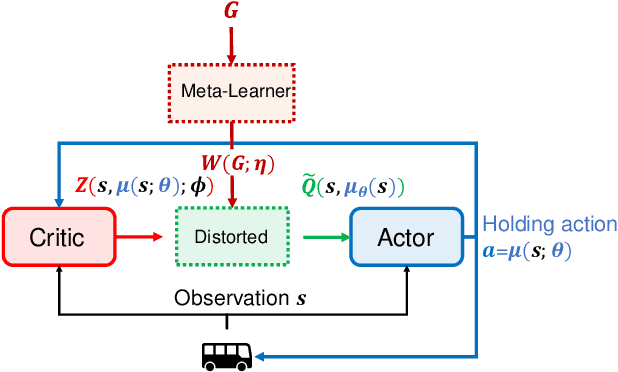
Bus system is a critical component of sustainable urban transportation. However, the operation of a bus fleet is unstable in nature, and bus bunching has become a common phenomenon that undermines the efficiency and reliability of bus systems. Recently research has demonstrated the promising application of multi-agent reinforcement learning (MARL) to achieve efficient vehicle holding control to avoid bus bunching. However, existing studies essentially overlook the robustness issue resulting from various events, perturbations and anomalies in a transit system, which is of utmost importance when transferring the models for real-world deployment/application. In this study, we integrate implicit quantile network and meta-learning to develop a distributional MARL framework -- IQNC-M -- to learn continuous control. The proposed IQNC-M framework achieves efficient and reliable control decisions through better handling various uncertainties/events in real-time transit operations. Specifically, we introduce an interpretable meta-learning module to incorporate global information into the distributional MARL framework, which is an effective solution to circumvent the credit assignment issue in the transit system. In addition, we design a specific learning procedure to train each agent within the framework to pursue a robust control policy. We develop simulation environments based on real-world bus services and passenger demand data and evaluate the proposed framework against both traditional holding control models and state-of-the-art MARL models. Our results show that the proposed IQNC-M framework can effectively handle the various extreme events, such as traffic state perturbations, service interruptions, and demand surges, thus improving both efficiency and reliability of the system.
Semantic Sensing and Planning for Human-Robot Collaboration in Uncertain Environments
Oct 20, 2021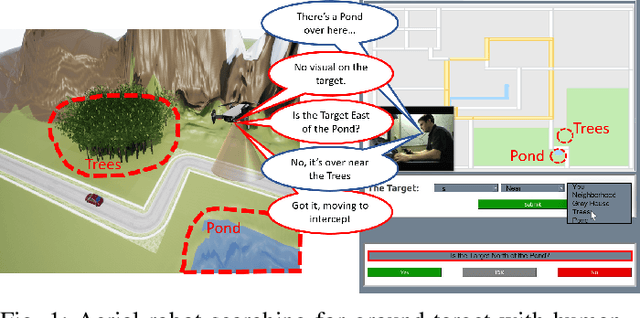
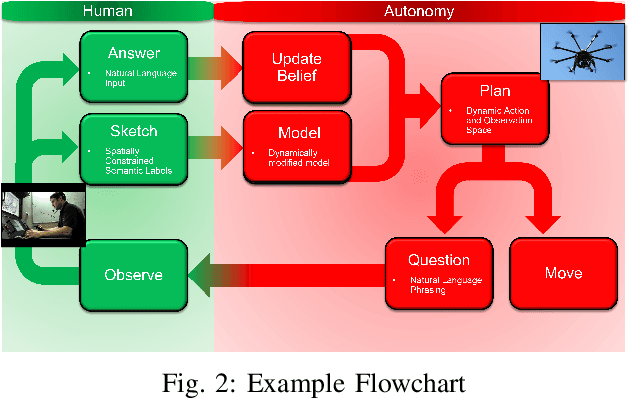
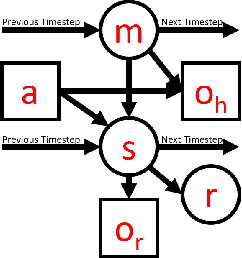
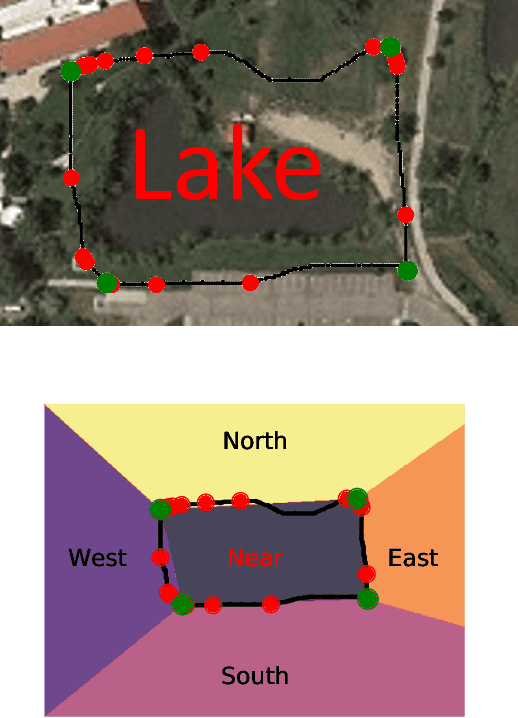
Autonomous robots can benefit greatly from human-provided semantic characterizations of uncertain task environments and states. However, the development of integrated strategies which let robots model, communicate, and act on such soft data remains challenging. Here, a framework is presented for active semantic sensing and planning in human-robot teams which addresses these gaps by formally combining the benefits of online sampling-based POMDP policies, multi-modal semantic interaction, and Bayesian data fusion. This approach lets humans opportunistically impose model structure and extend the range of semantic soft data in uncertain environments by sketching and labeling arbitrary landmarks across the environment. Dynamic updating of the environment while searching for a mobile target allows robotic agents to actively query humans for novel and relevant semantic data, thereby improving beliefs of unknown environments and target states for improved online planning. Target search simulations show significant improvements in time and belief state estimates required for interception versus conventional planning based solely on robotic sensing. Human subject studies demonstrate a average doubling in dynamic target capture rate compared to the lone robot case, employing reasoning over a range of user characteristics and interaction modalities. Video of interaction can be found at https://youtu.be/Eh-82ZJ1o4I.
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Oct 14, 2021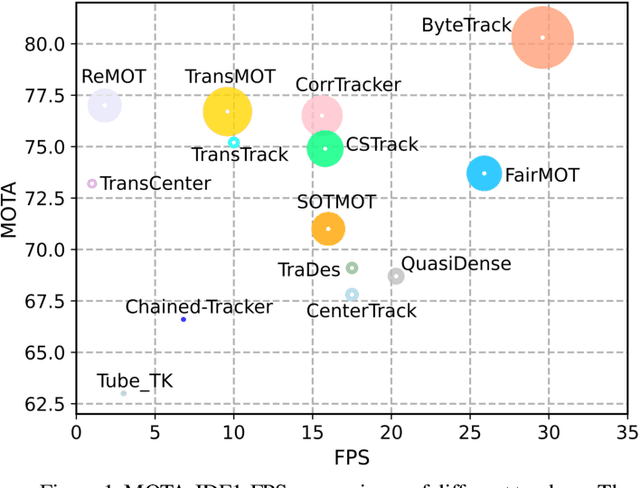


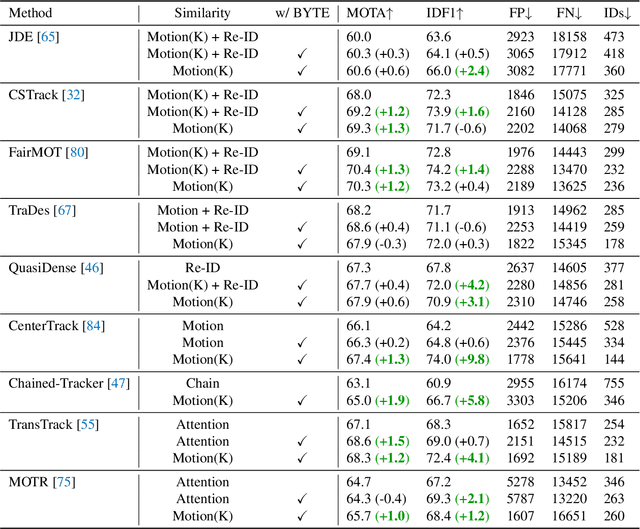
Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects in videos. Most methods obtain identities by associating detection boxes whose scores are higher than a threshold. The objects with low detection scores, e.g. occluded objects, are simply thrown away, which brings non-negligible true object missing and fragmented trajectories. To solve this problem, we present a simple, effective and generic association method, called BYTE, tracking BY associaTing Every detection box instead of only the high score ones. For the low score detection boxes, we utilize their similarities with tracklets to recover true objects and filter out the background detections. We apply BYTE to 9 different state-of-the-art trackers and achieve consistent improvement on IDF1 score ranging from 1 to 10 points. To put forwards the state-of-the-art performance of MOT, we design a simple and strong tracker, named ByteTrack. For the first time, we achieve 80.3 MOTA, 77.3 IDF1 and 63.1 HOTA on the test set of MOT17 with 30 FPS running speed on a single V100 GPU. The source code, pre-trained models with deploy versions and tutorials of applying to other trackers are released at https://github.com/ifzhang/ByteTrack.
Individual Survival Curves with Conditional Normalizing Flows
Jul 27, 2021
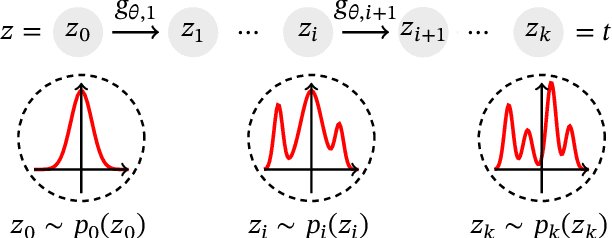
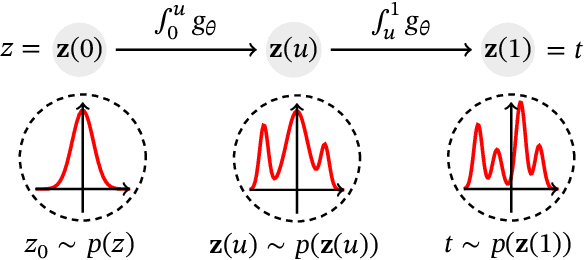
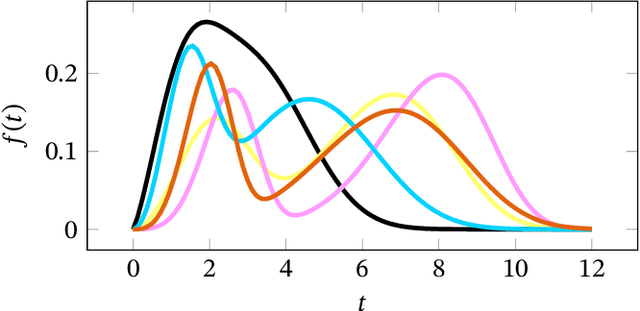
Survival analysis, or time-to-event modelling, is a classical statistical problem that has garnered a lot of interest for its practical use in epidemiology, demographics or actuarial sciences. Recent advances on the subject from the point of view of machine learning have been concerned with precise per-individual predictions instead of population studies, driven by the rise of individualized medicine. We introduce here a conditional normalizing flow based estimate of the time-to-event density as a way to model highly flexible and individualized conditional survival distributions. We use a novel hierarchical formulation of normalizing flows to enable efficient fitting of flexible conditional distributions without overfitting and show how the normalizing flow formulation can be efficiently adapted to the censored setting. We experimentally validate the proposed approach on a synthetic dataset as well as four open medical datasets and an example of a common financial problem.