 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TOD: Tensor-based Outlier Detection
Oct 26, 2021
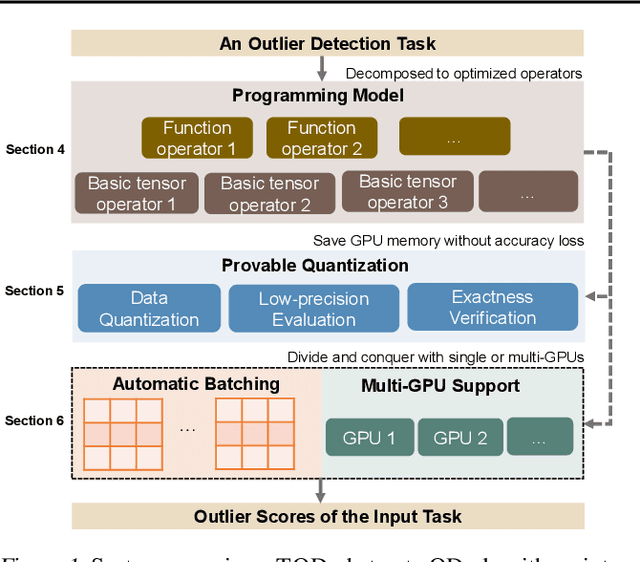
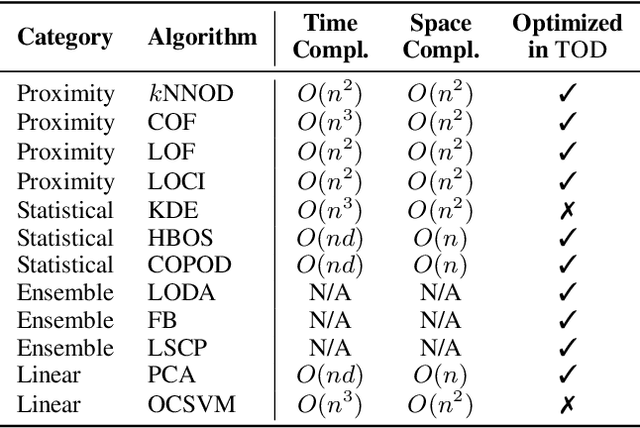
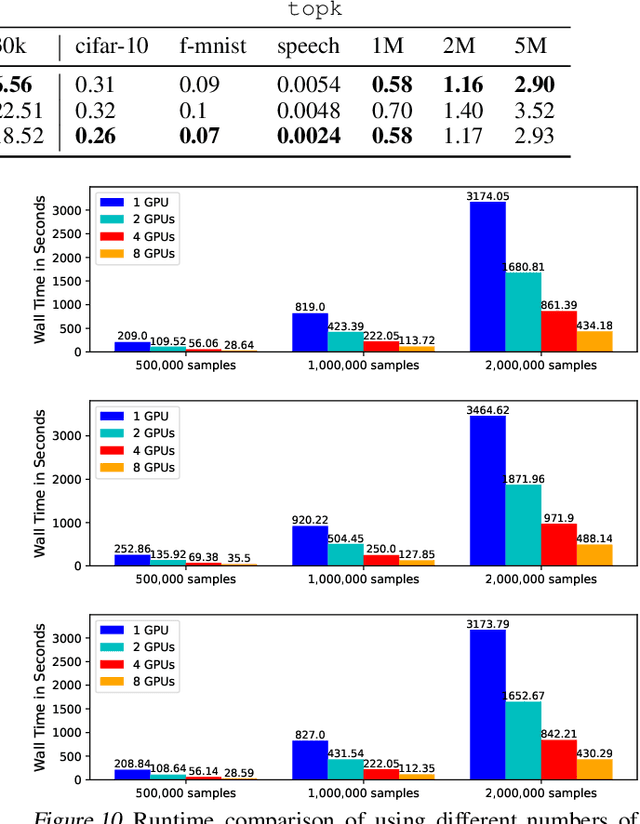
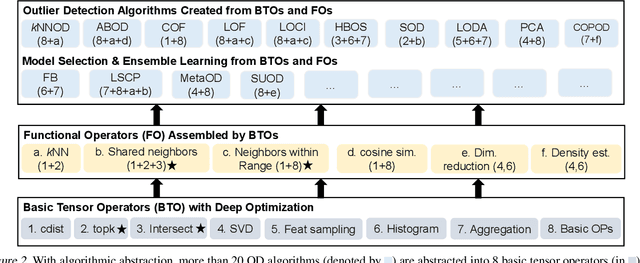
To scale outlier detection (OD) to large-scale, high-dimensional datasets, we propose TOD, a novel system that abstracts OD algorithms into basic tensor operations for efficient GPU acceleration. To make TOD highly efficient in both time and space, we leverage recent advances in deep learning infrastructure in both hardware and software. To deploy large OD applications on GPUs with limited memory, we introduce two key techniques. First, provable quantization accelerates OD computation and reduces the memory requirement by performing specific OD computations in lower precision while provably guaranteeing no accuracy loss. Second, to exploit the aggregated compute resources and memory capacity of multiple GPUs, we introduce automatic batching, which decomposes OD computations into small batches that can be executed on multiple GPUs in parallel. TOD supports a comprehensive set of OD algorithms and utility functions. Extensive evaluation on both real and synthetic OD datasets shows that TOD is on average 11.9X faster than the state-of-the-art comprehensive OD system PyOD, and takes less than an hour to detect outliers within a million samples. TOD enables straightforward integration for additional OD algorithms and provides a unified framework for combining classical OD algorithms with deep learning methods. These combinations result in an infinite number of OD methods, many of which are novel and can be easily prototyped in TOD.
Large-Scale News Classification using BERT Language Model: Spark NLP Approach
Jul 14, 2021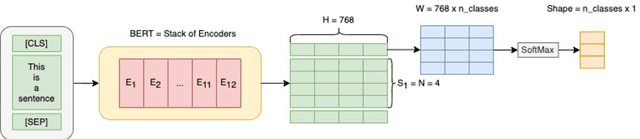

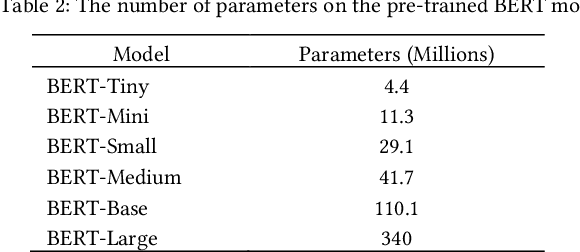

The rise of big data analytics on top of NLP increases the computational burden for text processing at scale. The problems faced in NLP are very high dimensional text, so it takes a high computation resource. The MapReduce allows parallelization of large computations and can improve the efficiency of text processing. This research aims to study the effect of big data processing on NLP tasks based on a deep learning approach. We classify a big text of news topics with fine-tuning BERT used pre-trained models. Five pre-trained models with a different number of parameters were used in this study. To measure the efficiency of this method, we compared the performance of the BERT with the pipelines from Spark NLP. The result shows that BERT without Spark NLP gives higher accuracy compared to BERT with Spark NLP. The accuracy average and training time of all models using BERT is 0.9187 and 35 minutes while using BERT with Spark NLP pipeline is 0.8444 and 9 minutes. The bigger model will take more computation resources and need a longer time to complete the tasks. However, the accuracy of BERT with Spark NLP only decreased by an average of 5.7%, while the training time was reduced significantly by 62.9% compared to BERT without Spark NLP.
Directional MCLP Analysis and Reconstruction for Spatial Speech Communication
Sep 09, 2021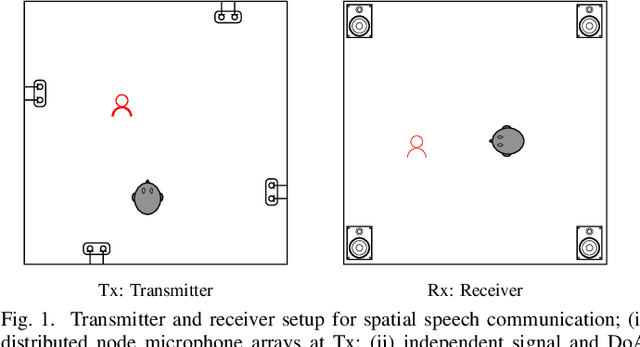
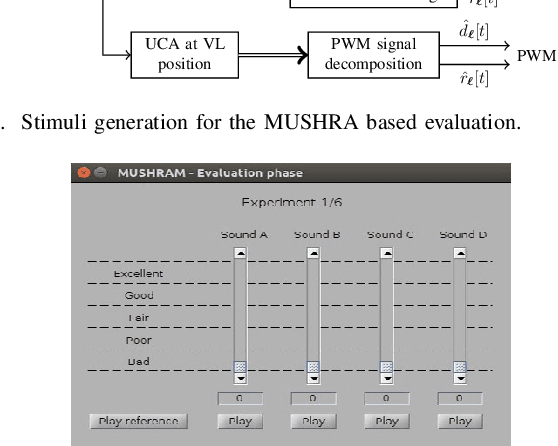
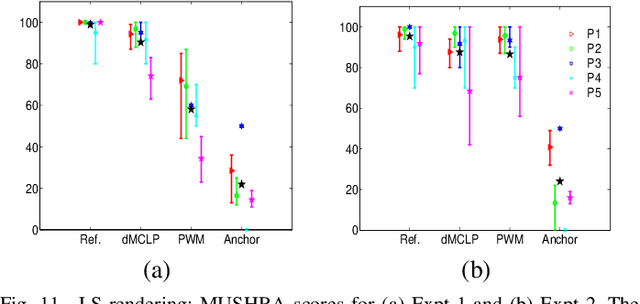
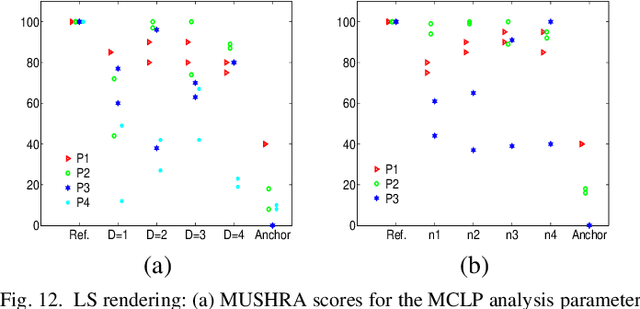
Spatial speech communication, i.e., the reconstruction of spoken signal along with the relative speaker position in the enclosure (reverberation information) is considered in this paper. Directional, diffuse components and the source position information are estimated at the transmitter, and perceptually effective reproduction is considered at the receiver. We consider spatially distributed microphone arrays for signal acquisition, and node specific signal estimation, along with its direction of arrival (DoA) estimation. Short-time Fourier transform (STFT) domain multi-channel linear prediction (MCLP) approach is used to model the diffuse component and relative acoustic transfer function is used to model the direct signal component. Distortion-less array response constraint and the time-varying complex Gaussian source model are used in the joint estimation of source DoA and the constituent signal components, separately at each node. The intersection between DoA directions at each node is used to compute the source position. Signal components computed at the node nearest to the estimated source position are taken as the signals for transmission. At the receiver, a four channel loud speaker (LS) setup is used for spatial reproduction, in which the source spatial image is reproduced relative to a chosen virtual listener position in the transmitter enclosure. Vector base amplitude panning (VBAP) method is used for direct component reproduction using the LS setup and the diffuse component is reproduced equally from all the loud speakers after decorrelation. This scheme of spatial speech communication is shown to be effective and more natural for hands-free telecommunication, through either loudspeaker listening or binaural headphone listening with head related transfer function (HRTF) based presentation.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021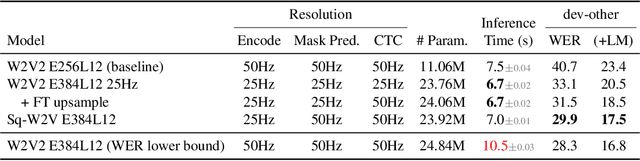
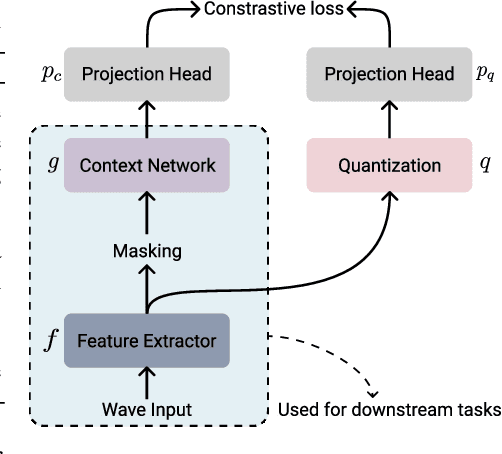
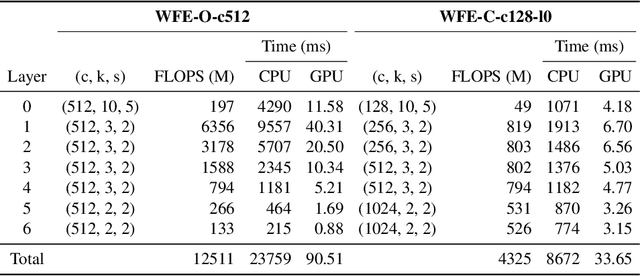
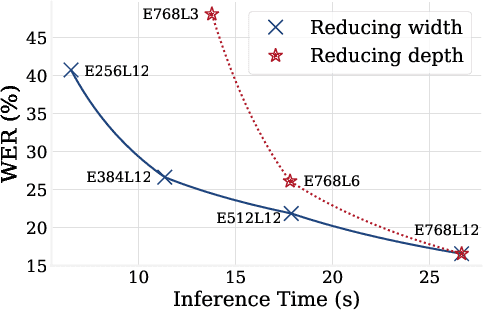
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Introduction to Coresets: Approximated Mean
Nov 04, 2021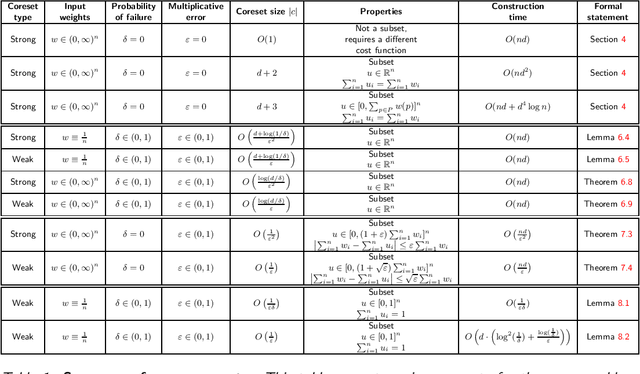
A \emph{strong coreset} for the mean queries of a set $P$ in ${\mathbb{R}}^d$ is a small weighted subset $C\subseteq P$, which provably approximates its sum of squared distances to any center (point) $x\in {\mathbb{R}}^d$. A \emph{weak coreset} is (also) a small weighted subset $C$ of $P$, whose mean approximates the mean of $P$. While computing the mean of $P$ can be easily computed in linear time, its coreset can be used to solve harder constrained version, and is in the heart of generalizations such as coresets for $k$-means clustering. In this paper, we survey most of the mean coreset construction techniques, and suggest a unified analysis methodology for providing and explaining classical and modern results including step-by-step proofs. In particular, we collected folklore and scattered related results, some of which are not formally stated elsewhere. Throughout this survey, we present, explain, and prove a set of techniques, reductions, and algorithms very widespread and crucial in this field. However, when put to use in the (relatively simple) mean problem, such techniques are much simpler to grasp. The survey may help guide new researchers unfamiliar with the field, and introduce them to the very basic foundations of coresets, through a simple, yet fundamental, problem. Experts in this area might appreciate the unified analysis flow, and the comparison table for existing results. Finally, to encourage and help practitioners and software engineers, we provide full open source code for all presented algorithms.
Multi-condition multi-objective optimization using deep reinforcement learning
Oct 10, 2021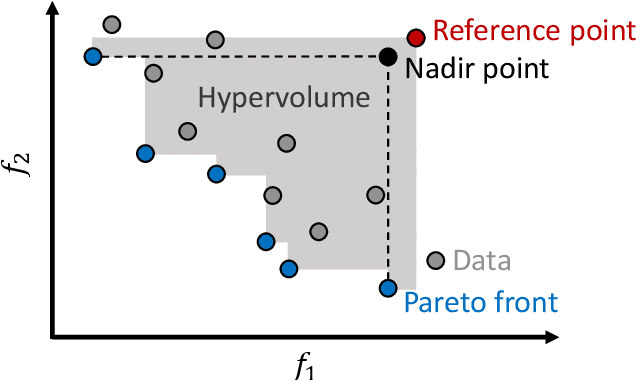
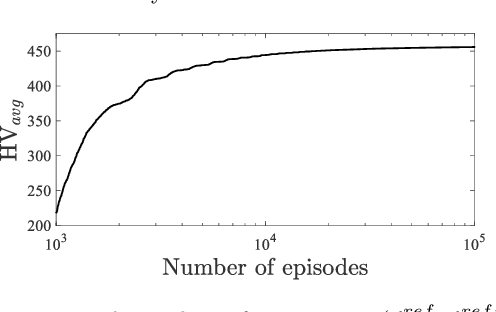
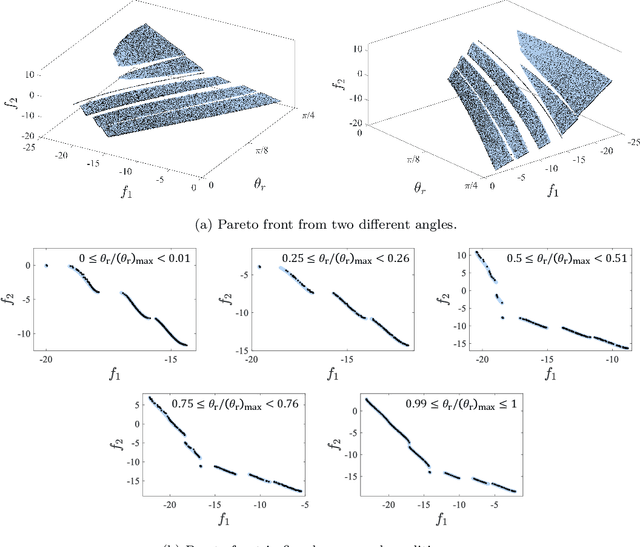
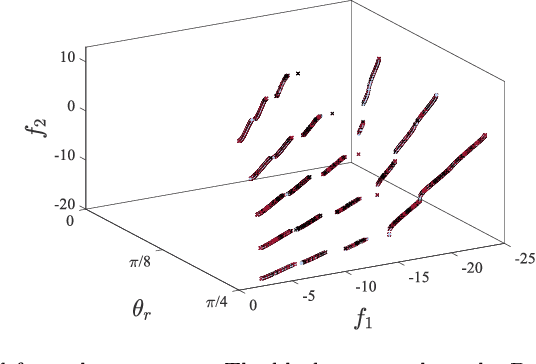
A multi-condition multi-objective optimization method that can find Pareto front over a defined condition space is developed for the first time using deep reinforcement learning. Unlike the conventional methods which perform optimization at a single condition, the present method learns the correlations between conditions and optimal solutions. The exclusive capability of the developed method is examined in the solutions of a novel modified Kursawe benchmark problem and an airfoil shape optimization problem which include nonlinear characteristics which are difficult to resolve using conventional optimization methods. Pareto front with high resolution over a defined condition space is successfully determined in each problem. Compared with multiple operations of a single-condition optimization method for multiple conditions, the present multi-condition optimization method based on deep reinforcement learning shows a greatly accelerated search of Pareto front by reducing the number of required function evaluations. An analysis of aerodynamics performance of airfoils with optimally designed shapes confirms that multi-condition optimization is indispensable to avoid significant degradation of target performance for varying flow conditions.
Variational Predictive Routing with Nested Subjective Timescales
Oct 21, 2021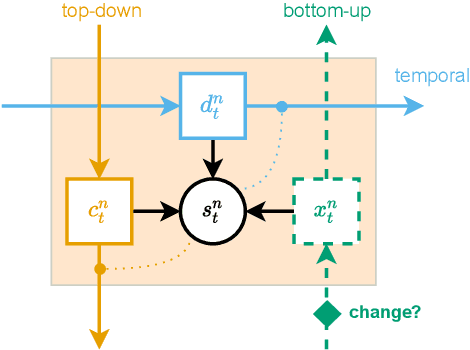
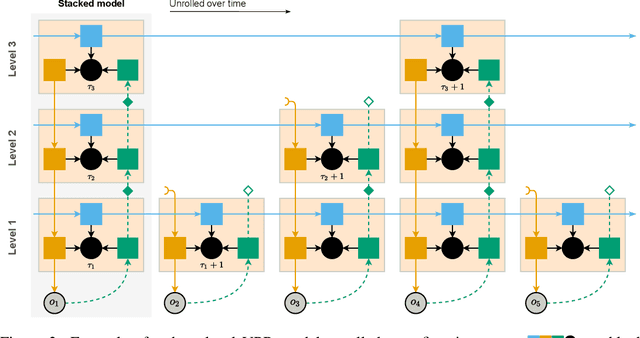
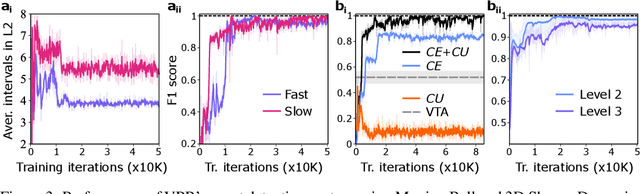
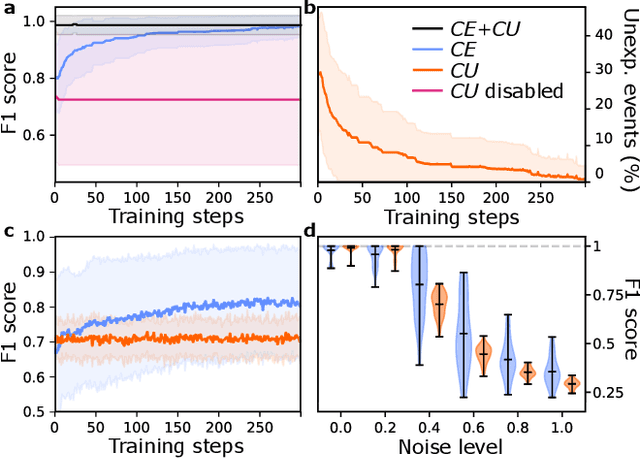
Discovery and learning of an underlying spatiotemporal hierarchy in sequential data is an important topic for machine learning. Despite this, little work has been done to explore hierarchical generative models that can flexibly adapt their layerwise representations in response to datasets with different temporal dynamics. Here, we present Variational Predictive Routing (VPR) - a neural probabilistic inference system that organizes latent representations of video features in a temporal hierarchy, based on their rates of change, thus modeling continuous data as a hierarchical renewal process. By employing an event detection mechanism that relies solely on the system's latent representations (without the need of a separate model), VPR is able to dynamically adjust its internal state following changes in the observed features, promoting an optimal organisation of representations across the levels of the model's latent hierarchy. Using several video datasets, we show that VPR is able to detect event boundaries, disentangle spatiotemporal features across its hierarchy, adapt to the dynamics of the data, and produce accurate time-agnostic rollouts of the future. Our approach integrates insights from neuroscience and introduces a framework with high potential for applications in model-based reinforcement learning, where flexible and informative state-space rollouts are of particular interest.
Detecting multiple change-points in the time-varying Ising model
Oct 18, 2019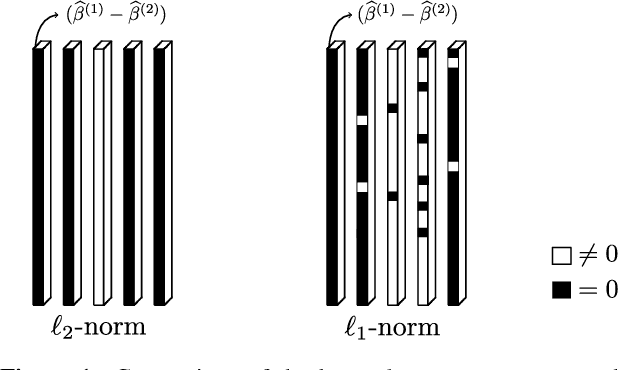
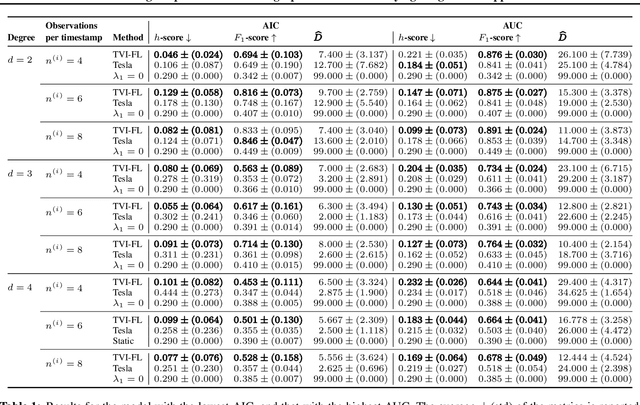
This work focuses on the estimation of change-points in a time-varying Ising graphical model (outputs $-1$ or $1$) evolving in a piecewise constant fashion. The occurring changes alter the graphical structure of the model, a structure which we also estimate in the present paper. For this purpose, we propose a new optimization program consisting in the minimization of a penalized negative conditional log-likelihood. The objective of the penalization is twofold: it imposes the learned graphs to be sparse and, thanks to a fused-type penalty, it enforces them to evolve piecewise constantly. Using few assumptions, we then give a change-point consistency theorem. Up to our knowledge, we are the first to present such theoretical result in the context of time-varying Ising model. Finally, experimental results on several synthetic examples and a real-world dataset demonstrate the empirical performance of our method.
DeepSteal: Advanced Model Extractions Leveraging Efficient Weight Stealing in Memories
Nov 08, 2021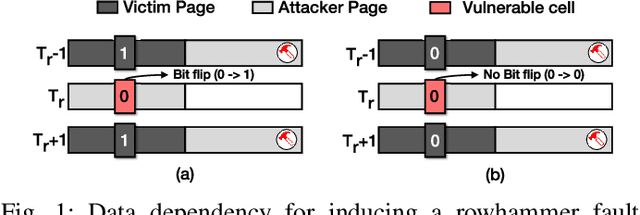
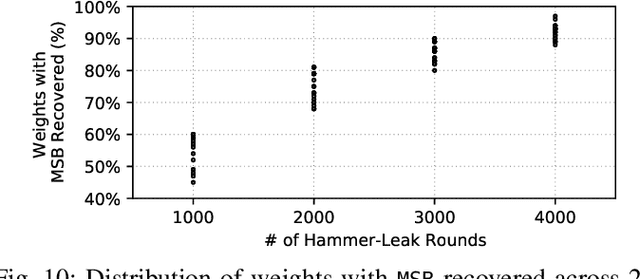
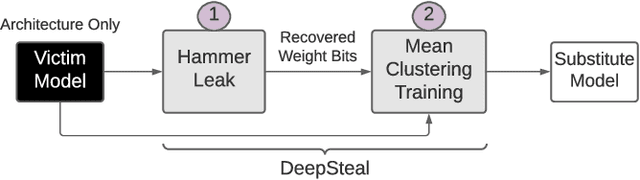
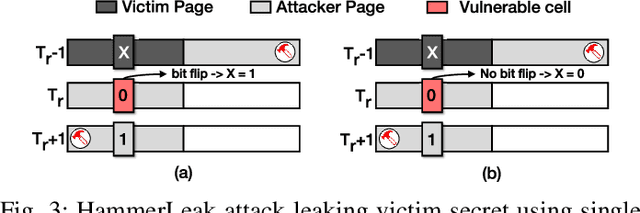
Recent advancements of Deep Neural Networks (DNNs) have seen widespread deployment in multiple security-sensitive domains. The need of resource-intensive training and use of valuable domain-specific training data have made these models a top intellectual property (IP) for model owners. One of the major threats to the DNN privacy is model extraction attacks where adversaries attempt to steal sensitive information in DNN models. Recent studies show hardware-based side channel attacks can reveal internal knowledge about DNN models (e.g., model architectures) However, to date, existing attacks cannot extract detailed model parameters (e.g., weights/biases). In this work, for the first time, we propose an advanced model extraction attack framework DeepSteal that effectively steals DNN weights with the aid of memory side-channel attack. Our proposed DeepSteal comprises two key stages. Firstly, we develop a new weight bit information extraction method, called HammerLeak, through adopting the rowhammer based hardware fault technique as the information leakage vector. HammerLeak leverages several novel system-level techniques tailed for DNN applications to enable fast and efficient weight stealing. Secondly, we propose a novel substitute model training algorithm with Mean Clustering weight penalty, which leverages the partial leaked bit information effectively and generates a substitute prototype of the target victim model. We evaluate this substitute model extraction method on three popular image datasets (e.g., CIFAR-10/100/GTSRB) and four DNN architectures (e.g., ResNet-18/34/Wide-ResNet/VGG-11). The extracted substitute model has successfully achieved more than 90 % test accuracy on deep residual networks for the CIFAR-10 dataset. Moreover, our extracted substitute model could also generate effective adversarial input samples to fool the victim model.
Learning to Simulate Self-Driven Particles System with Coordinated Policy Optimization
Oct 26, 2021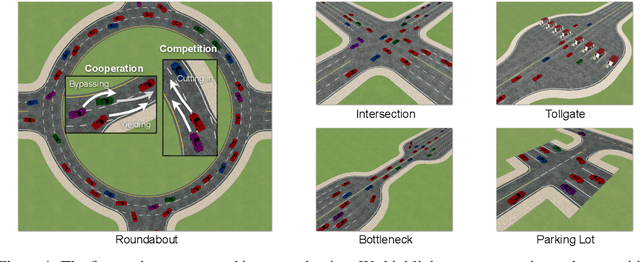
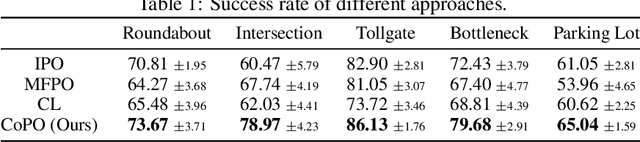
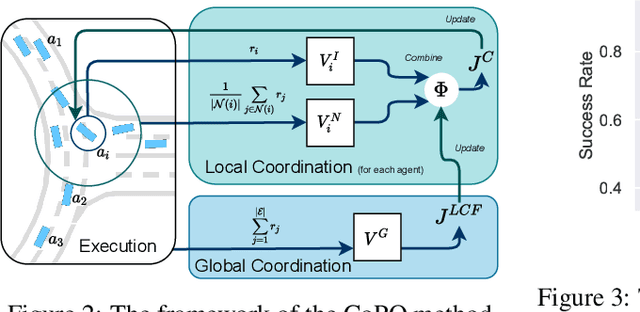

Self-Driven Particles (SDP) describe a category of multi-agent systems common in everyday life, such as flocking birds and traffic flows. In a SDP system, each agent pursues its own goal and constantly changes its cooperative or competitive behaviors with its nearby agents. Manually designing the controllers for such SDP system is time-consuming, while the resulting emergent behaviors are often not realistic nor generalizable. Thus the realistic simulation of SDP systems remains challenging. Reinforcement learning provides an appealing alternative for automating the development of the controller for SDP. However, previous multi-agent reinforcement learning (MARL) methods define the agents to be teammates or enemies before hand, which fail to capture the essence of SDP where the role of each agent varies to be cooperative or competitive even within one episode. To simulate SDP with MARL, a key challenge is to coordinate agents' behaviors while still maximizing individual objectives. Taking traffic simulation as the testing bed, in this work we develop a novel MARL method called Coordinated Policy Optimization (CoPO), which incorporates social psychology principle to learn neural controller for SDP. Experiments show that the proposed method can achieve superior performance compared to MARL baselines in various metrics. Noticeably the trained vehicles exhibit complex and diverse social behaviors that improve performance and safety of the population as a whole. Demo video and source code are available at: https://decisionforce.github.io/CoPO/