 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Large-Scale News Classification using BERT Language Model: Spark NLP Approach
Jul 15, 2021
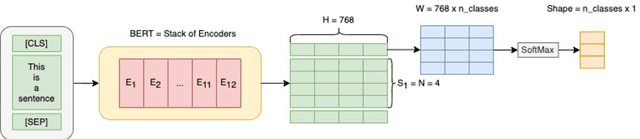

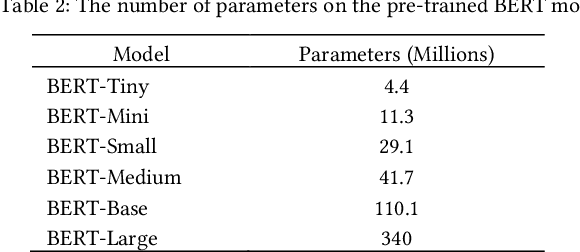

The rise of big data analytics on top of NLP increases the computational burden for text processing at scale. The problems faced in NLP are very high dimensional text, so it takes a high computation resource. The MapReduce allows parallelization of large computations and can improve the efficiency of text processing. This research aims to study the effect of big data processing on NLP tasks based on a deep learning approach. We classify a big text of news topics with fine-tuning BERT used pre-trained models. Five pre-trained models with a different number of parameters were used in this study. To measure the efficiency of this method, we compared the performance of the BERT with the pipelines from Spark NLP. The result shows that BERT without Spark NLP gives higher accuracy compared to BERT with Spark NLP. The accuracy average and training time of all models using BERT is 0.9187 and 35 minutes while using BERT with Spark NLP pipeline is 0.8444 and 9 minutes. The bigger model will take more computation resources and need a longer time to complete the tasks. However, the accuracy of BERT with Spark NLP only decreased by an average of 5.7%, while the training time was reduced significantly by 62.9% compared to BERT without Spark NLP.
Estimation of Stationary Optimal Transport Plans
Jul 25, 2021We study optimal transport problems in which finite-valued quantities of interest evolve dynamically over time in a stationary fashion. Mathematically, this is a special case of the general optimal transport problem in which the distributions under study represent stationary processes and the cost depends on a finite number of time points. In this setting, we argue that one should restrict attention to stationary couplings, also known as joinings, which have close connections with long run average cost. We introduce estimators of both optimal joinings and the optimal joining cost, and we establish their consistency under mild conditions. Under stronger mixing assumptions we establish finite-sample error rates for the same estimators that extend the best known results in the iid case. Finally, we extend the consistency and rate analysis to an entropy-penalized version of the optimal joining problem.
Equivariant Discrete Normalizing Flows
Oct 16, 2021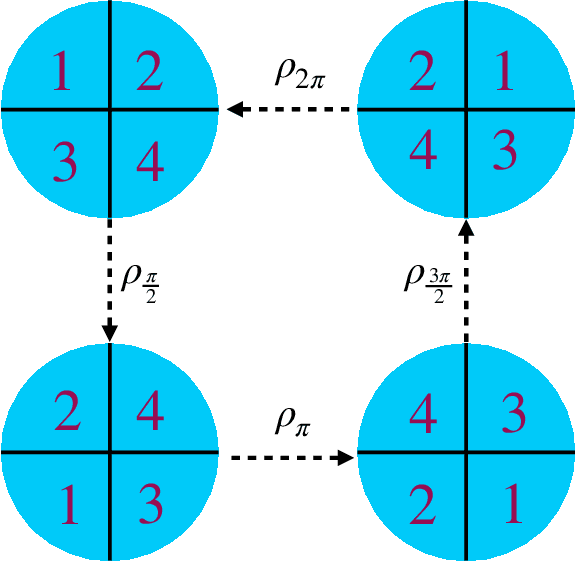
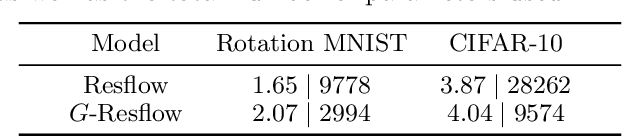
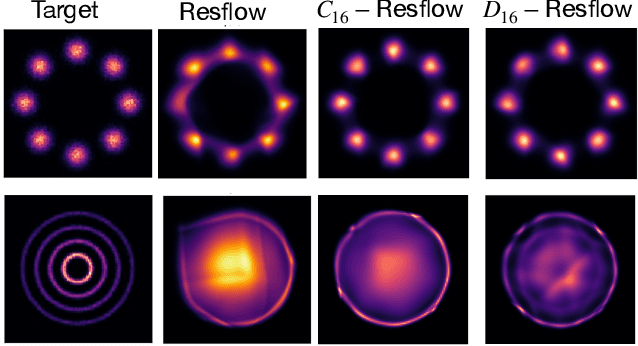
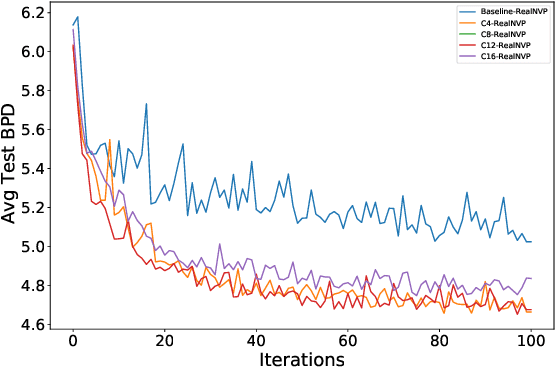
At its core, generative modeling seeks to uncover the underlying factors that give rise to observed data that can often be modelled as the natural symmetries that manifest themselves through invariances and equivariances to certain transformations laws. However, current approaches are couched in the formalism of continuous normalizing flows that require the construction of equivariant vector fields -- inhibiting their simple application to conventional higher dimensional generative modelling domains like natural images. In this paper we focus on building equivariant normalizing flows using discrete layers. We first theoretically prove the existence of an equivariant map for compact groups whose actions are on compact spaces. We further introduce two new equivariant flows: $G$-coupling Flows and $G$-Residual Flows that elevate classical Coupling and Residual Flows with equivariant maps to a prescribed group $G$. Our construction of $G$-Residual Flows are also universal, in the sense that we prove an $G$-equivariant diffeomorphism can be exactly mapped by a $G$-residual flow. Finally, we complement our theoretical insights with experiments -- for the first time -- on image datasets like CIFAR-10 and show $G$-Equivariant Discrete Normalizing flows lead to increased data efficiency, faster convergence, and improved likelihood estimates.
A Survey on Channel Estimation and Practical Passive Beamforming Design for Intelligent Reflecting Surface Aided Wireless Communications
Oct 04, 2021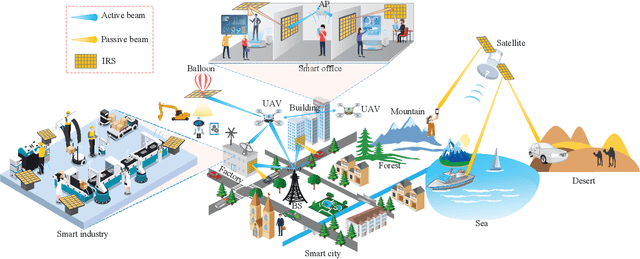
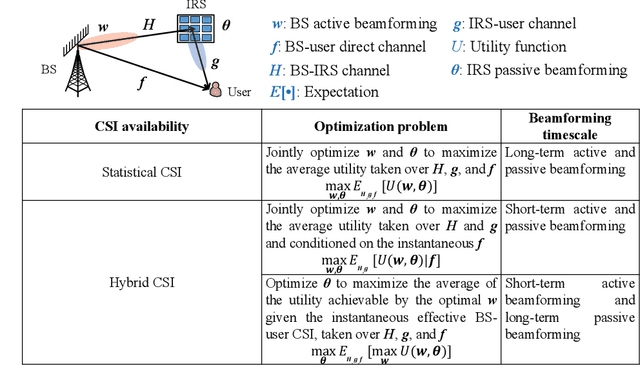
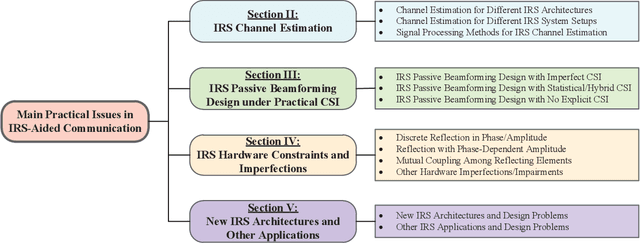
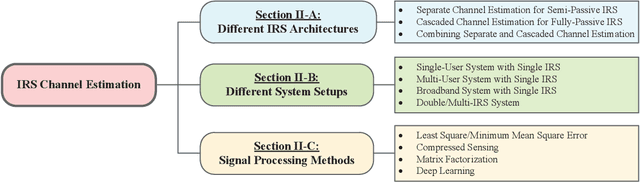
Intelligent reflecting surface (IRS) has emerged as a key enabling technology to realize smart and reconfigurable radio environment for wireless communications, by digitally controlling the signal reflection via a large number of passive reflecting elements in real time. Different from conventional wireless communication techniques that only adapt to but have no or limited control over dynamic wireless channels, IRS provides a new and cost-effective means to combat the wireless channel impair-ments in a proactive manner. However, despite its great potential, IRS faces new and unique challenges in its efficient integration into wireless communication systems, especially its channel estimation and passive beamforming design under various practical hardware constraints. In this paper, we provide a comprehensive survey on the up-to-date research in IRS-aided wireless communications, with an emphasis on the promising solutions to tackle practical design issues. Furthermore, we discuss new and emerging IRS architectures and applications as well as their practical design problems to motivate future research.
DeepMCAT: Large-Scale Deep Clustering for Medical Image Categorization
Sep 30, 2021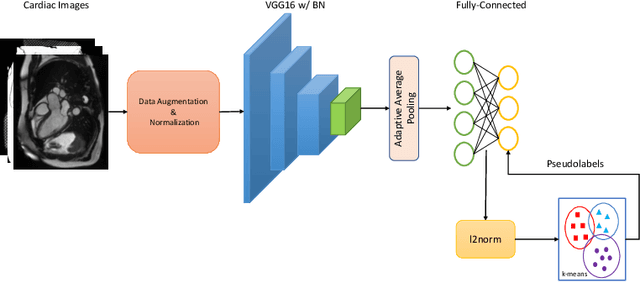

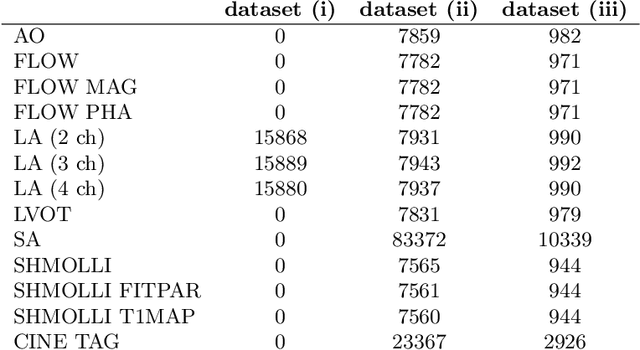
In recent years, the research landscape of machine learning in medical imaging has changed drastically from supervised to semi-, weakly- or unsupervised methods. This is mainly due to the fact that ground-truth labels are time-consuming and expensive to obtain manually. Generating labels from patient metadata might be feasible but it suffers from user-originated errors which introduce biases. In this work, we propose an unsupervised approach for automatically clustering and categorizing large-scale medical image datasets, with a focus on cardiac MR images, and without using any labels. We investigated the end-to-end training using both class-balanced and imbalanced large-scale datasets. Our method was able to create clusters with high purity and achieved over 0.99 cluster purity on these datasets. The results demonstrate the potential of the proposed method for categorizing unstructured large medical databases, such as organizing clinical PACS systems in hospitals.
Bayesian optimization of distributed neurodynamical controller models for spatial navigation
Oct 31, 2021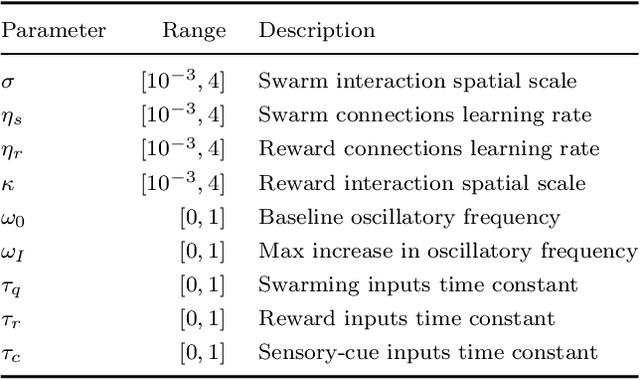
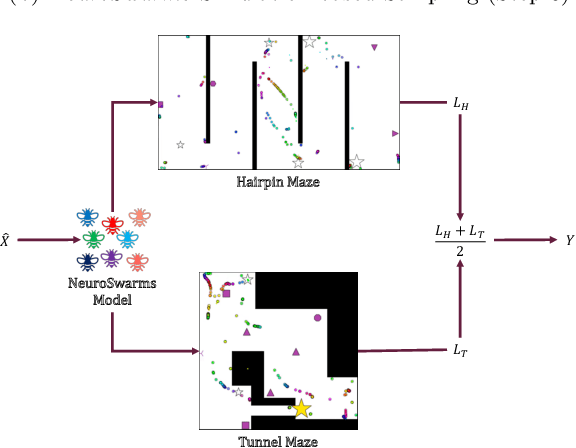
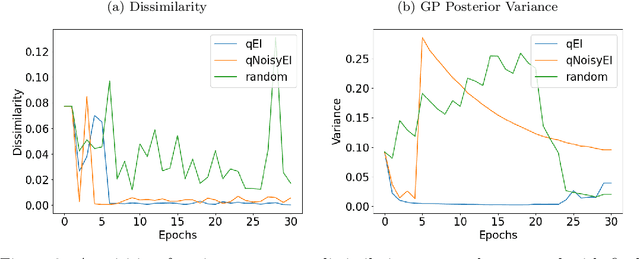
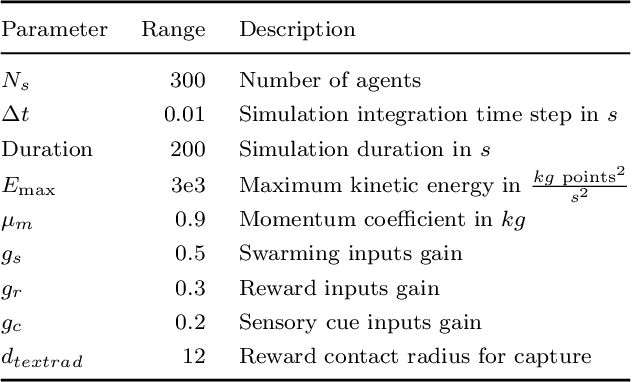
Dynamical systems models for controlling multi-agent swarms have demonstrated advances toward resilient, decentralized navigation algorithms. We previously introduced the NeuroSwarms controller, in which agent-based interactions were modeled by analogy to neuronal network interactions, including attractor dynamics and phase synchrony, that have been theorized to operate within hippocampal place-cell circuits in navigating rodents. This complexity precludes linear analyses of stability, controllability, and performance typically used to study conventional swarm models. Further, tuning dynamical controllers by hand or grid search is often inadequate due to the complexity of objectives, dimensionality of model parameters, and computational costs of simulation-based sampling. Here, we present a framework for tuning dynamical controller models of autonomous multi-agent systems based on Bayesian Optimization (BayesOpt). Our approach utilizes a task-dependent objective function to train Gaussian Processes (GPs) as surrogate models to achieve adaptive and efficient exploration of a dynamical controller model's parameter space. We demonstrate this approach by studying an objective function selecting for NeuroSwarms behaviors that cooperatively localize and capture spatially distributed rewards under time pressure. We generalized task performance across environments by combining scores for simulations in distinct geometries. To validate search performance, we compared high-dimensional clustering for high- vs. low-likelihood parameter points by visualizing sample trajectories in Uniform Manifold Approximation and Projection (UMAP) embeddings. Our findings show that adaptive, sample-efficient evaluation of the self-organizing behavioral capacities of complex systems, including dynamical swarm controllers, can accelerate the translation of neuroscientific theory to applied domains.
Visual Evaluation of Generative Adversarial Networks for Time Series Data
Dec 23, 2019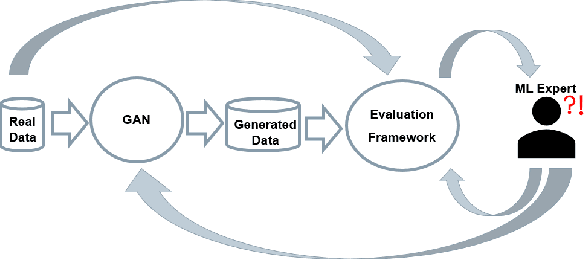
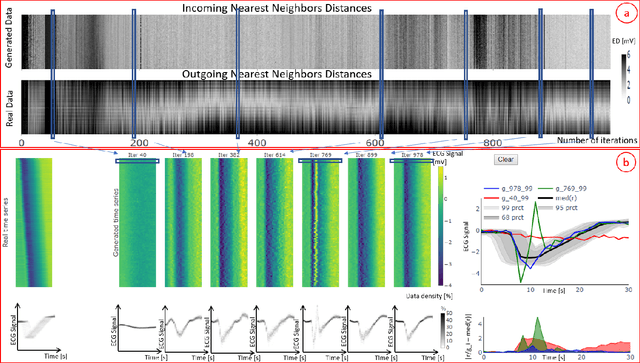
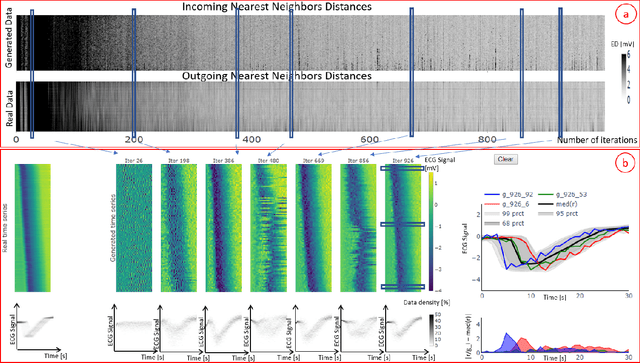
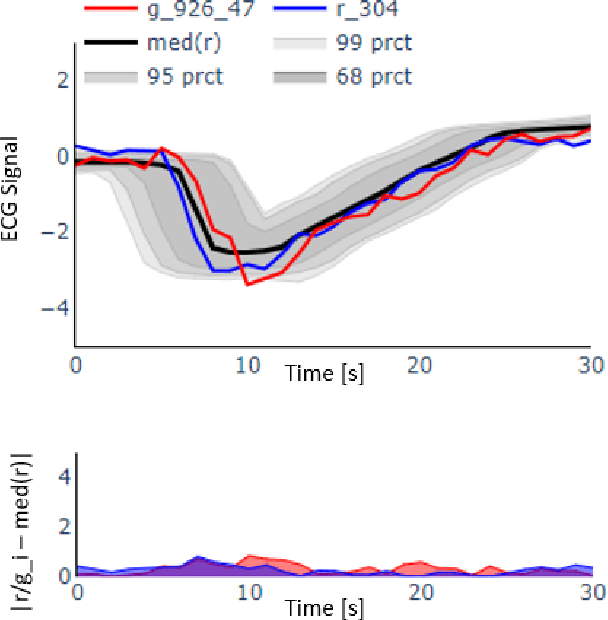
A crucial factor to trust Machine Learning (ML) algorithm decisions is a good representation of its application field by the training dataset. This is particularly true when parts of the training data have been artificially generated to overcome common training problems such as lack of data or imbalanced dataset. Over the last few years, Generative Adversarial Networks (GANs) have shown remarkable results in generating realistic data. However, this ML approach lacks an objective function to evaluate the quality of the generated data. Numerous GAN applications focus on generating image data mostly because they can be easily evaluated by a human eye. Less efforts have been made to generate time series data. Assessing their quality is more complicated, particularly for technical data. In this paper, we propose a human-centered approach supporting a ML or domain expert to accomplish this task using Visual Analytics (VA) techniques. The presented approach consists of two views, namely a GAN Iteration View showing similarity metrics between real and generated data over the iterations of the generation process and a Detailed Comparative View equipped with different time series visualizations such as TimeHistograms, to compare the generated data at different iteration steps. Starting from the GAN Iteration View, the user can choose suitable iteration steps for detailed inspection. We evaluate our approach with a usage scenario that enabled an efficient comparison of two different GAN models.
Deep Active Learning by Leveraging Training Dynamics
Oct 16, 2021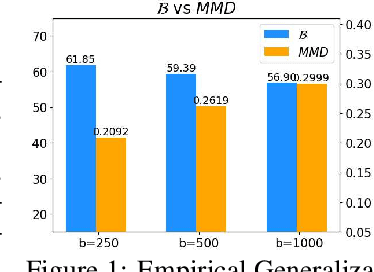


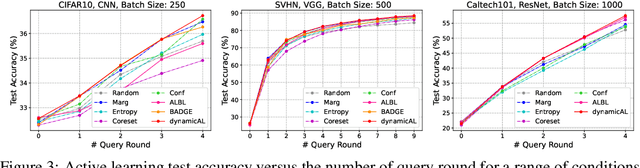
Active learning theories and methods have been extensively studied in classical statistical learning settings. However, deep active learning, i.e., active learning with deep learning models, is usually based on empirical criteria without solid theoretical justification, thus suffering from heavy doubts when some of those fail to provide benefits in applications. In this paper, by exploring the connection between the generalization performance and the training dynamics, we propose a theory-driven deep active learning method (dynamicAL) which selects samples to maximize training dynamics. In particular, we prove that convergence speed of training and the generalization performance is positively correlated under the ultra-wide condition and show that maximizing the training dynamics leads to a better generalization performance. Further on, to scale up to large deep neural networks and data sets, we introduce two relaxations for the subset selection problem and reduce the time complexity from polynomial to constant. Empirical results show that dynamicAL not only outperforms the other baselines consistently but also scales well on large deep learning models. We hope our work inspires more attempts in bridging the theoretical findings of deep networks and practical impacts in deep active learning applications.
Improving Robustness of time series classifier with Neural ODE guided gradient based data augmentation
Oct 15, 2019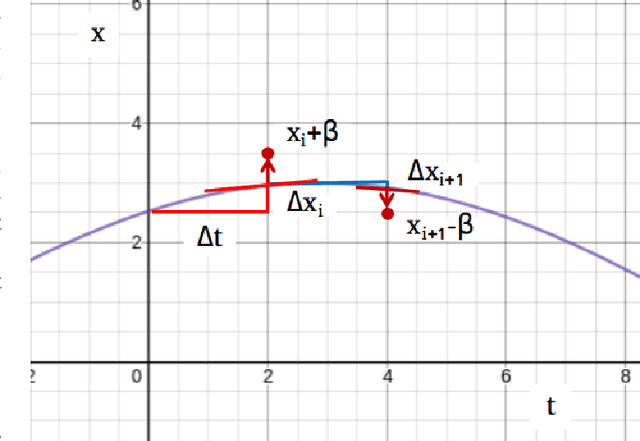
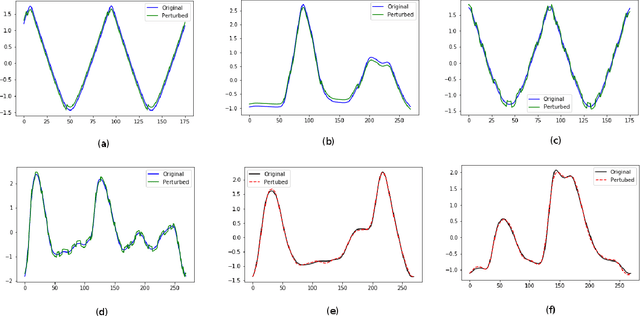
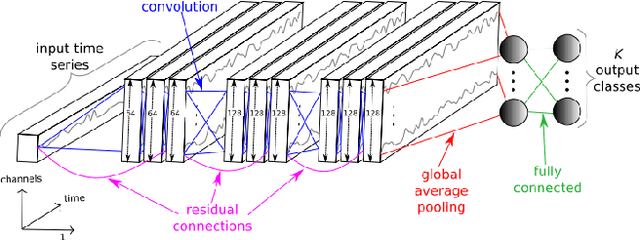
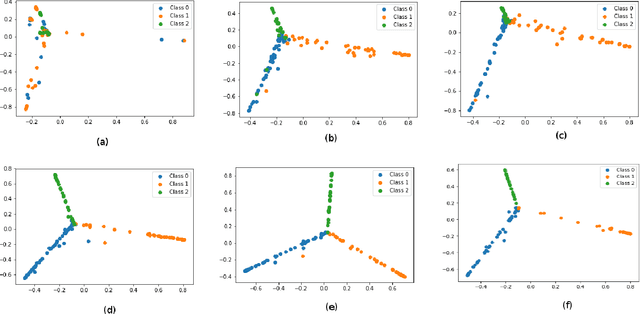
Exploring adversarial attack vectors and studying their effects on machine learning algorithms has been of interest to researchers. Deep neural networks working with time series data have received lesser interest compared to their image counterparts in this context. In a recent finding, it has been revealed that current state-of-the-art deep learning time series classifiers are vulnerable to adversarial attacks. In this paper, we introduce two local gradient based and one spectral density based time series data augmentation techniques. We show that a model trained with data obtained using our techniques obtains state-of-the-art classification accuracy on various time series benchmarks. In addition, it improves the robustness of the model against some of the most common corruption techniques,such as Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM).
Pseudo-label refinement using superpixels for semi-supervised brain tumour segmentation
Oct 16, 2021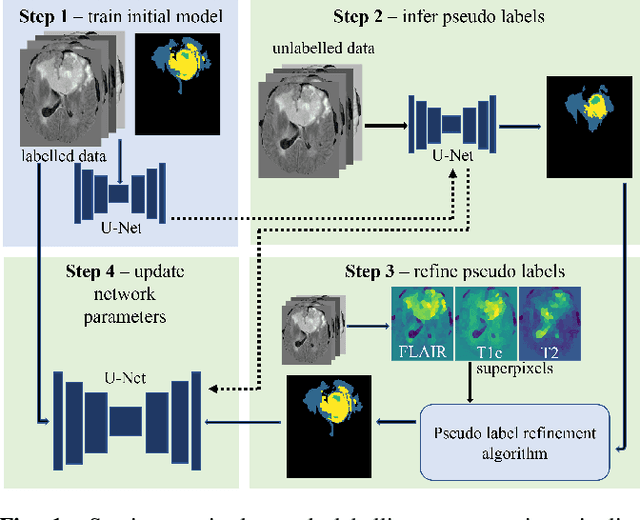
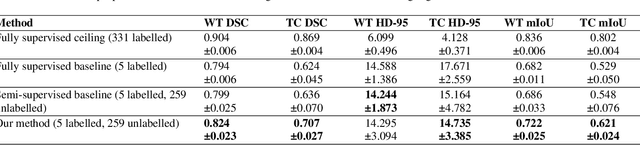
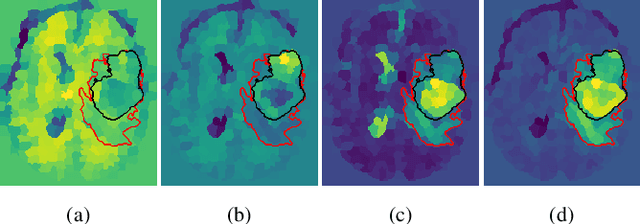
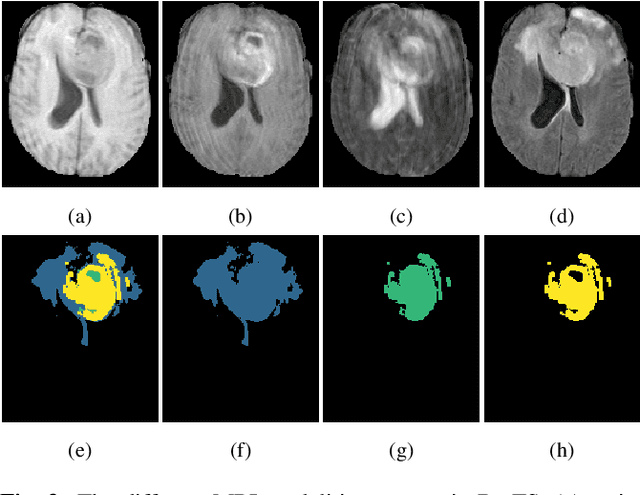
Training neural networks using limited annotations is an important problem in the medical domain. Deep Neural Networks (DNNs) typically require large, annotated datasets to achieve acceptable performance which, in the medical domain, are especially difficult to obtain as they require significant time from expert radiologists. Semi-supervised learning aims to overcome this problem by learning segmentations with very little annotated data, whilst exploiting large amounts of unlabelled data. However, the best-known technique, which utilises inferred pseudo-labels, is vulnerable to inaccurate pseudo-labels degrading the performance. We propose a framework based on superpixels - meaningful clusters of adjacent pixels - to improve the accuracy of the pseudo labels and address this issue. Our framework combines superpixels with semi-supervised learning, refining the pseudo-labels during training using the features and edges of the superpixel maps. This method is evaluated on a multimodal magnetic resonance imaging (MRI) dataset for the task of brain tumour region segmentation. Our method demonstrates improved performance over the standard semi-supervised pseudo-labelling baseline when there is a reduced annotator burden and only 5 annotated patients are available. We report DSC=0.824 and DSC=0.707 for the test set whole tumour and tumour core regions respectively.