 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Processes
Oct 29, 2021
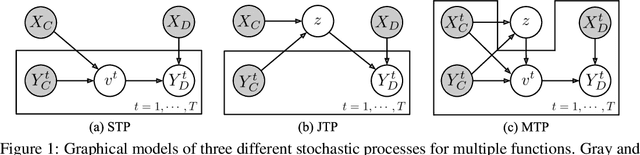
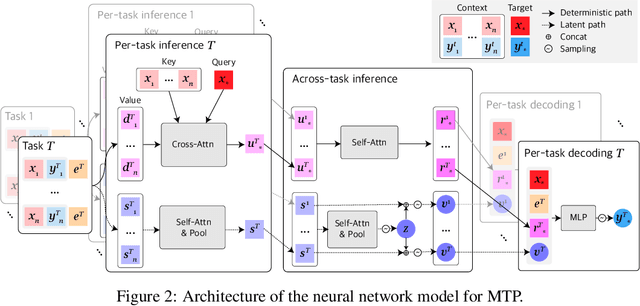
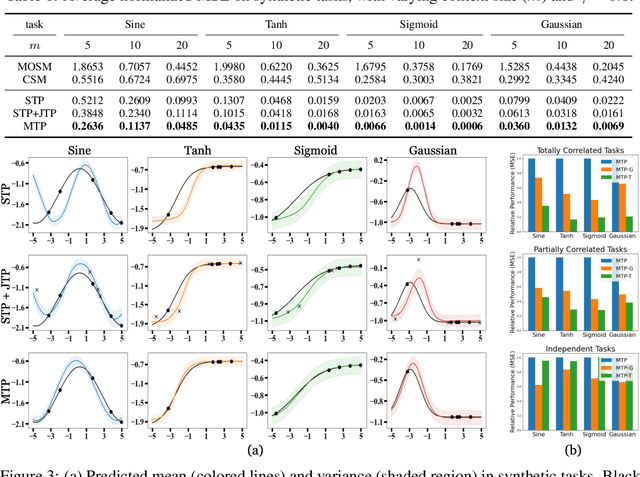
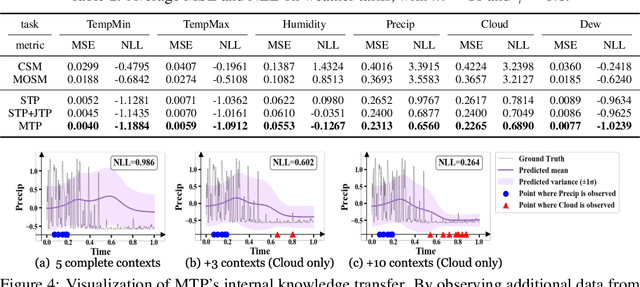
Neural Processes (NPs) consider a task as a function realized from a stochastic process and flexibly adapt to unseen tasks through inference on functions. However, naive NPs can model data from only a single stochastic process and are designed to infer each task independently. Since many real-world data represent a set of correlated tasks from multiple sources (e.g., multiple attributes and multi-sensor data), it is beneficial to infer them jointly and exploit the underlying correlation to improve the predictive performance. To this end, we propose Multi-Task Processes (MTPs), an extension of NPs designed to jointly infer tasks realized from multiple stochastic processes. We build our MTPs in a hierarchical manner such that inter-task correlation is considered by conditioning all per-task latent variables on a single global latent variable. In addition, we further design our MTPs so that they can address multi-task settings with incomplete data (i.e., not all tasks share the same set of input points), which has high practical demands in various applications. Experiments demonstrate that MTPs can successfully model multiple tasks jointly by discovering and exploiting their correlations in various real-world data such as time series of weather attributes and pixel-aligned visual modalities.
Bayesian Recurrent Framework for Missing Data Imputation and Prediction with Clinical Time Series
Nov 18, 2019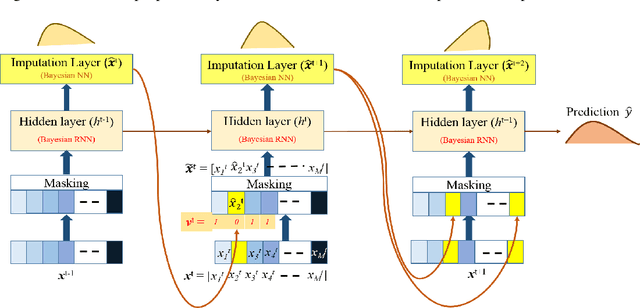
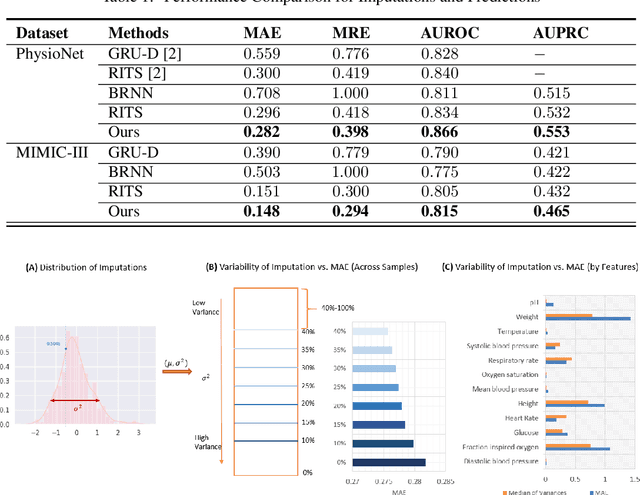
Real-world clinical time series data sets exhibit a high prevalence of missing values. Hence, there is an increasing interest in missing data imputation. Traditional statistical approaches impose constraints on the data-generating process and decouple imputation from prediction. Recent works propose recurrent neural network based approaches for missing data imputation and prediction with time series data. However, they generate deterministic outputs and neglect the inherent uncertainty. In this work, we introduce a unified Bayesian recurrent framework for simultaneous imputation and prediction on time series data sets. We evaluate our approach on two real-world mortality prediction tasks using the MIMIC-III and PhysioNet benchmark datasets. We demonstrate significant performance gains over state-of-the-art methods, and provide strategies to use the resulting probability distributions to better assess reliability of the imputations and predictions.
Improved FRQI on superconducting processors and its restrictions in the NISQ era
Oct 29, 2021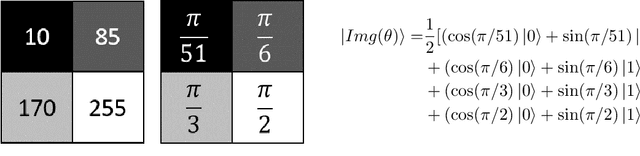
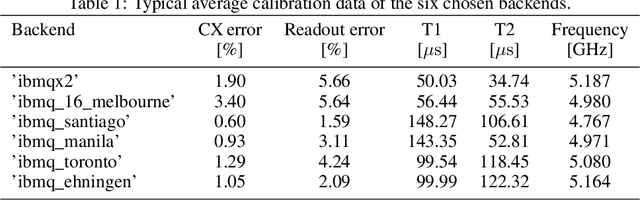

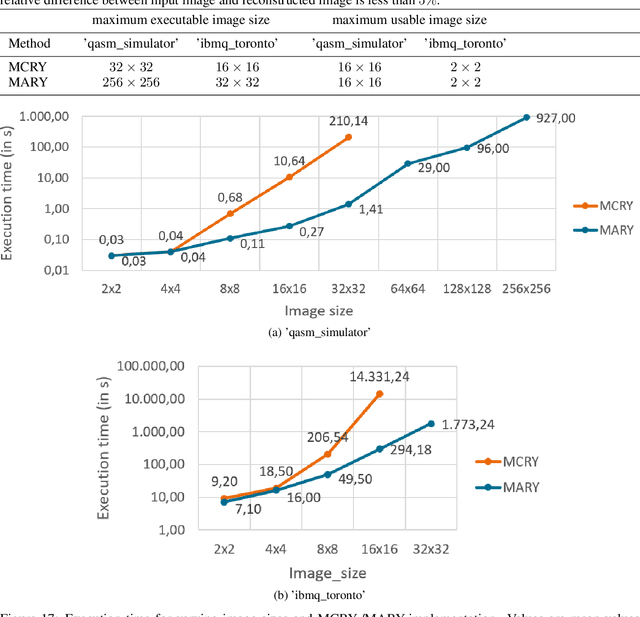
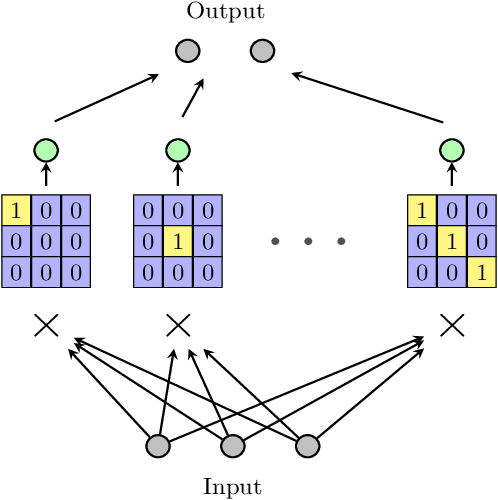
In image processing, the amount of data to be processed grows rapidly, in particular when imaging methods yield images of more than two dimensions or time series of images. Thus, efficient processing is a challenge, as data sizes may push even supercomputers to their limits. Quantum image processing promises to encode images with logarithmically less qubits than classical pixels in the image. In theory, this is a huge progress, but so far not many experiments have been conducted in practice, in particular on real backends. Often, the precise conversion of classical data to quantum states, the exact implementation, and the interpretation of the measurements in the classical context are challenging. We investigate these practical questions in this paper. In particular, we study the feasibility of the Flexible Representation of Quantum Images (FRQI). Furthermore, we check experimentally what is the limit in the current noisy intermediate-scale quantum era, i.e. up to which image size an image can be encoded, both on simulators and on real backends. Finally, we propose a method for simplifying the circuits needed for the FRQI. With our alteration, the number of gates needed, especially of the error-prone controlled-NOT gates, can be reduced. As a consequence, the size of manageable images increases.
Global Optimality Beyond Two Layers: Training Deep ReLU Networks via Convex Programs
Oct 11, 2021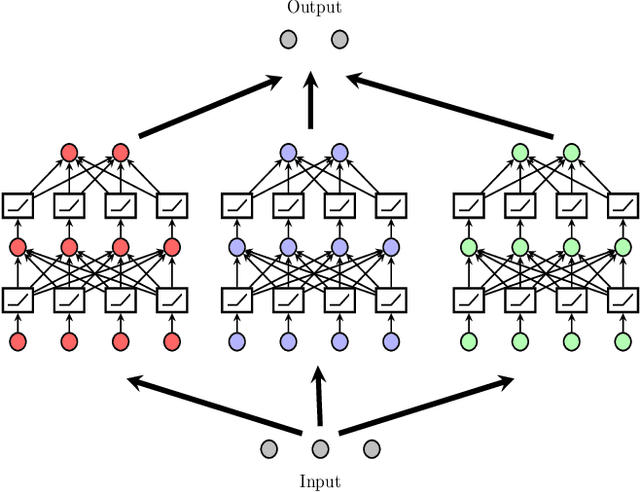
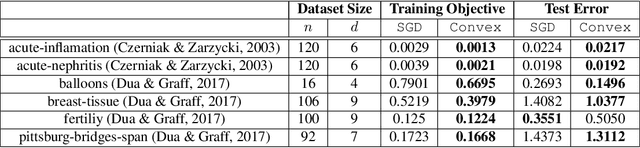

Understanding the fundamental mechanism behind the success of deep neural networks is one of the key challenges in the modern machine learning literature. Despite numerous attempts, a solid theoretical analysis is yet to be developed. In this paper, we develop a novel unified framework to reveal a hidden regularization mechanism through the lens of convex optimization. We first show that the training of multiple three-layer ReLU sub-networks with weight decay regularization can be equivalently cast as a convex optimization problem in a higher dimensional space, where sparsity is enforced via a group $\ell_1$-norm regularization. Consequently, ReLU networks can be interpreted as high dimensional feature selection methods. More importantly, we then prove that the equivalent convex problem can be globally optimized by a standard convex optimization solver with a polynomial-time complexity with respect to the number of samples and data dimension when the width of the network is fixed. Finally, we numerically validate our theoretical results via experiments involving both synthetic and real datasets.
AnchorGAE: General Data Clustering via $O(n)$ Bipartite Graph Convolution
Nov 12, 2021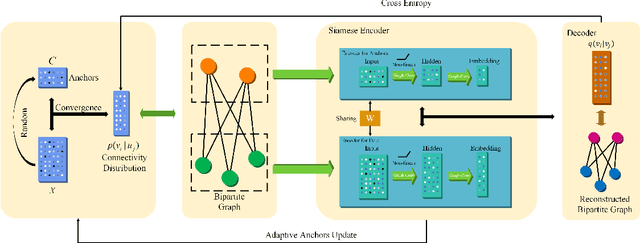
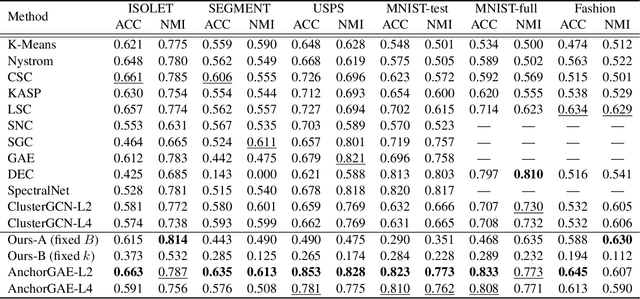

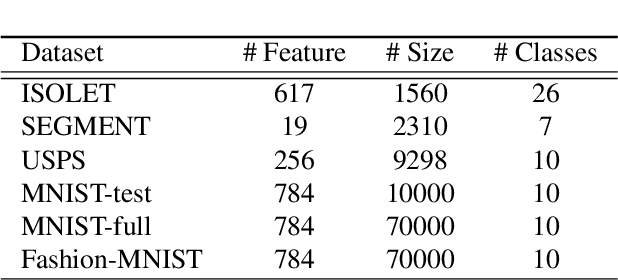
Graph-based clustering plays an important role in clustering tasks. As graph convolution network (GCN), a variant of neural networks on graph-type data, has achieved impressive performance, it is attractive to find whether GCNs can be used to augment the graph-based clustering methods on non-graph data, i.e., general data. However, given $n$ samples, the graph-based clustering methods usually need at least $O(n^2)$ time to build graphs and the graph convolution requires nearly $O(n^2)$ for a dense graph and $O(|\mathcal{E}|)$ for a sparse one with $|\mathcal{E}|$ edges. In other words, both graph-based clustering and GCNs suffer from severe inefficiency problems. To tackle this problem and further employ GCN to promote the capacity of graph-based clustering, we propose a novel clustering method, AnchorGAE. As the graph structure is not provided in general clustering scenarios, we first show how to convert a non-graph dataset into a graph by introducing the generative graph model, which is used to build GCNs. Anchors are generated from the original data to construct a bipartite graph such that the computational complexity of graph convolution is reduced from $O(n^2)$ and $O(|\mathcal{E}|)$ to $O(n)$. The succeeding steps for clustering can be easily designed as $O(n)$ operations. Interestingly, the anchors naturally lead to a siamese GCN architecture. The bipartite graph constructed by anchors is updated dynamically to exploit the high-level information behind data. Eventually, we theoretically prove that the simple update will lead to degeneration and a specific strategy is accordingly designed.
Snippet Policy Network for Multi-class Varied-length ECG Early Classification
Jul 28, 2021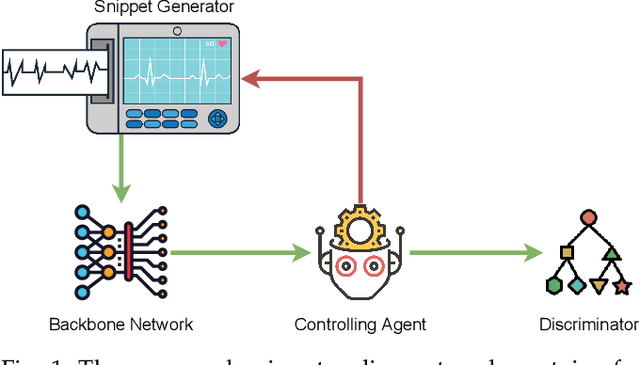
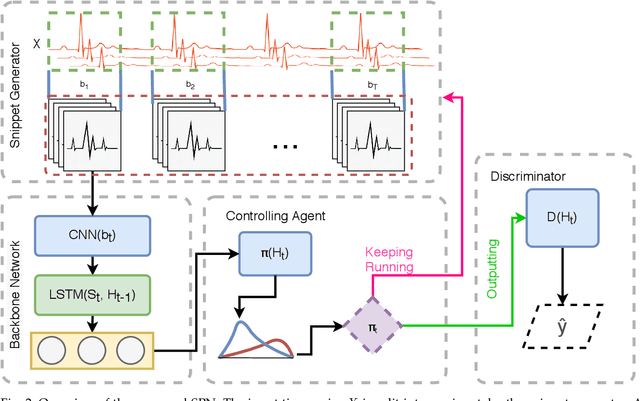
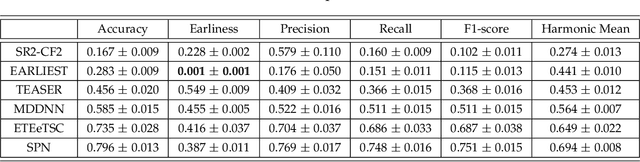
Arrhythmia detection from ECG is an important research subject in the prevention and diagnosis of cardiovascular diseases. The prevailing studies formulate arrhythmia detection from ECG as a time series classification problem. Meanwhile, early detection of arrhythmia presents a real-world demand for early prevention and diagnosis. In this paper, we address a problem of cardiovascular disease early classification, which is a varied-length and long-length time series early classification problem as well. For solving this problem, we propose a deep reinforcement learning-based framework, namely Snippet Policy Network (SPN), consisting of four modules, snippet generator, backbone network, controlling agent, and discriminator. Comparing to the existing approaches, the proposed framework features flexible input length, solves the dual-optimization solution of the earliness and accuracy goals. Experimental results demonstrate that SPN achieves an excellent performance of over 80\% in terms of accuracy. Compared to the state-of-the-art methods, at least 7% improvement on different metrics, including the precision, recall, F1-score, and harmonic mean, is delivered by the proposed SPN. To the best of our knowledge, this is the first work focusing on solving the cardiovascular early classification problem based on varied-length ECG data. Based on these excellent features from SPN, it offers a good exemplification for addressing all kinds of varied-length time series early classification problems.
Using Single-Trial Representational Similarity Analysis with EEG to track semantic similarity in emotional word processing
Oct 04, 2021Electroencephalography (EEG) is a powerful non-invasive brain imaging technique with a high temporal resolution that has seen extensive use across multiple areas of cognitive science research. This thesis adapts representational similarity analysis (RSA) to single-trial EEG datasets and introduces its principles to EEG researchers unfamiliar with multivariate analyses. We have two separate aims: 1. we want to explore the effectiveness of single-trial RSA on EEG datasets; 2. we want to utilize single-trial RSA and computational semantic models to investigate the role of semantic meaning in emotional word processing. We report two primary findings: 1. single-trial RSA on EEG datasets can produce meaningful and interpretable results given a high number of trials and subjects; 2. single-trial RSA reveals that emotional processing in the 500-800ms time window is associated with additional semantic analysis.
Top-1 Solution of Multi-Moments in Time Challenge 2019
Mar 13, 2020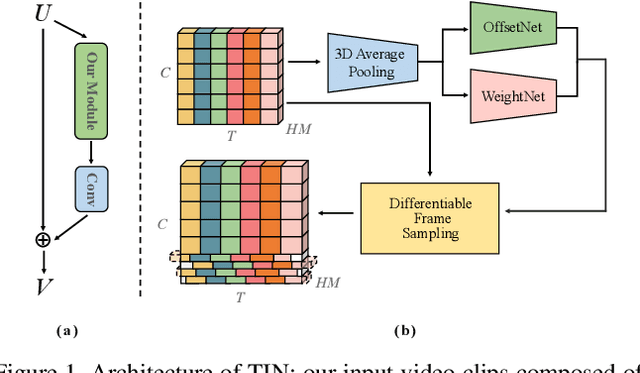
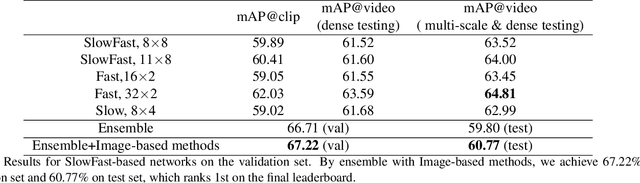
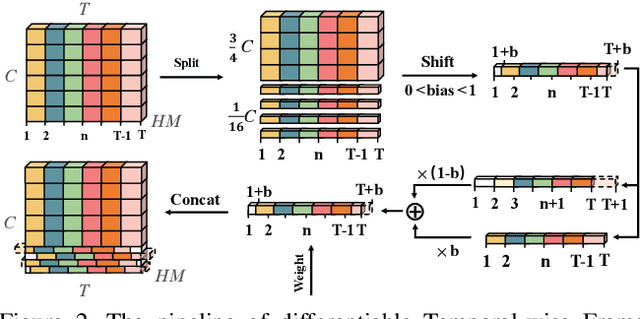
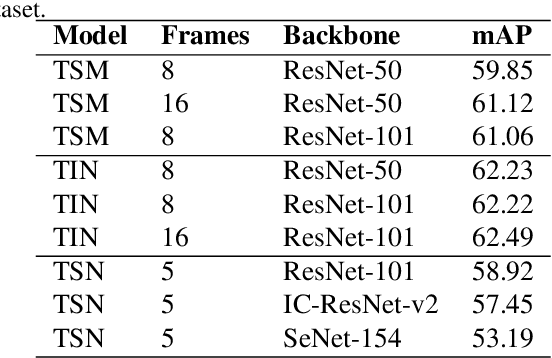
In this technical report, we briefly introduce the solutions of our team 'Efficient' for the Multi-Moments in Time challenge in ICCV 2019. We first conduct several experiments with popular Image-Based action recognition methods TRN, TSN, and TSM. Then a novel temporal interlacing network is proposed towards fast and accurate recognition. Besides, the SlowFast network and its variants are explored. Finally, we ensemble all the above models and achieve 67.22\% on the validation set and 60.77\% on the test set, which ranks 1st on the final leaderboard. In addition, we release a new code repository for video understanding which unifies state-of-the-art 2D and 3D methods based on PyTorch. The solution of the challenge is also included in the repository, which is available at https://github.com/Sense-X/X-Temporal.
Gabor filter incorporated CNN for compression
Oct 29, 2021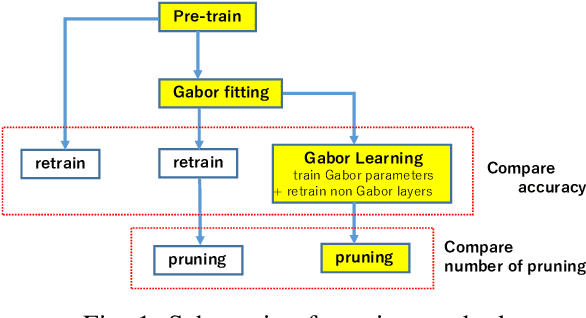
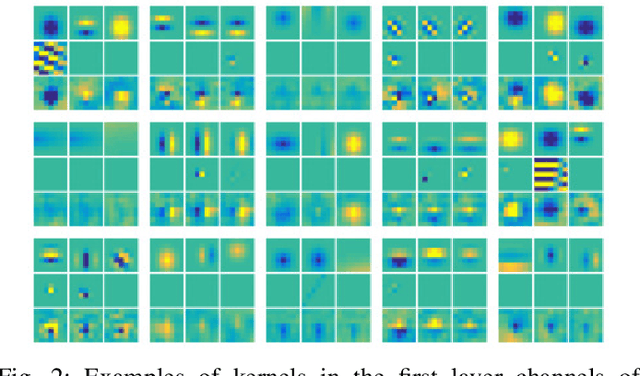
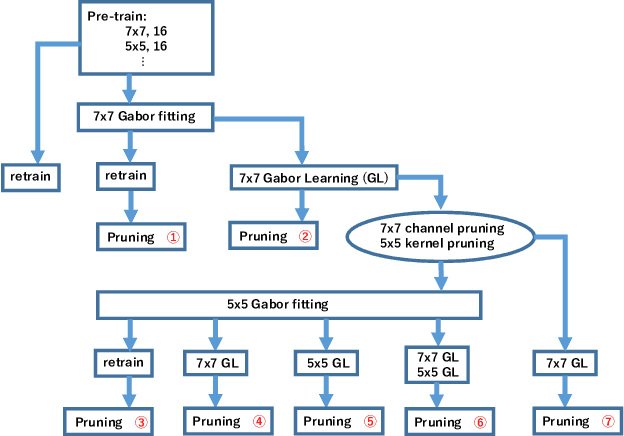
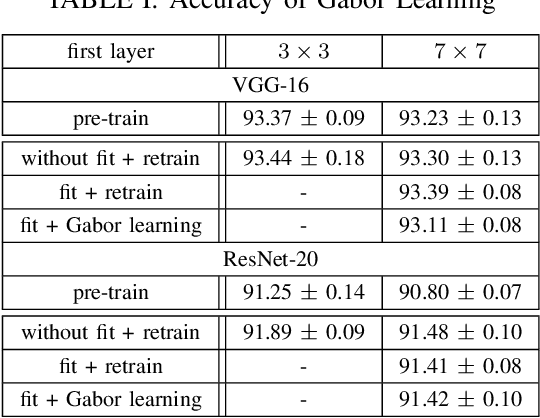
Convolutional neural networks (CNNs) are remarkably successful in many computer vision tasks. However, the high cost of inference is problematic for embedded and real-time systems, so there are many studies on compressing the networks. On the other hand, recent advances in self-attention models showed that convolution filters are preferable to self-attention in the earlier layers, which indicates that stronger inductive biases are better in the earlier layers. As shown in convolutional filters, strong biases can train specific filters and construct unnecessarily filters to zero. This is analogous to classical image processing tasks, where choosing the suitable filters makes a compact dictionary to represent features. We follow this idea and incorporate Gabor filters in the earlier layers of CNNs for compression. The parameters of Gabor filters are learned through backpropagation, so the features are restricted to Gabor filters. We show that the first layer of VGG-16 for CIFAR-10 has 192 kernels/features, but learning Gabor filters requires an average of 29.4 kernels. Also, using Gabor filters, an average of 83% and 94% of kernels in the first and the second layer, respectively, can be removed on the altered ResNet-20, where the first five layers are exchanged with two layers of larger kernels for CIFAR-10.
Blockage Prediction Using Wireless Signatures: Deep Learning Enables Real-World Demonstration
Nov 16, 2021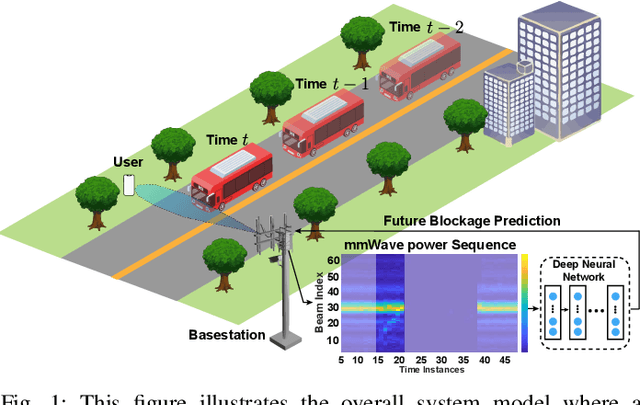
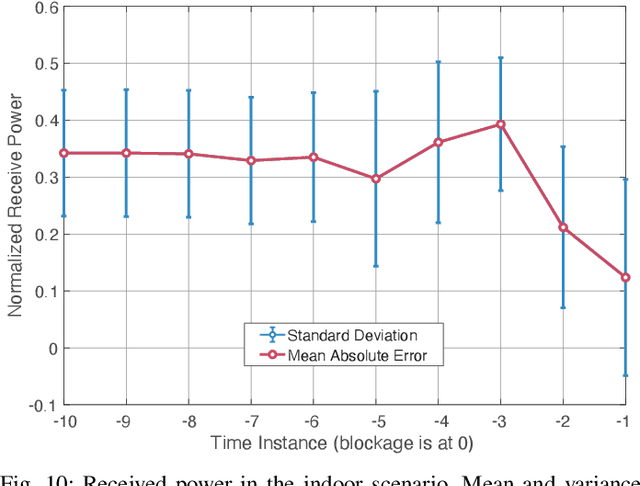
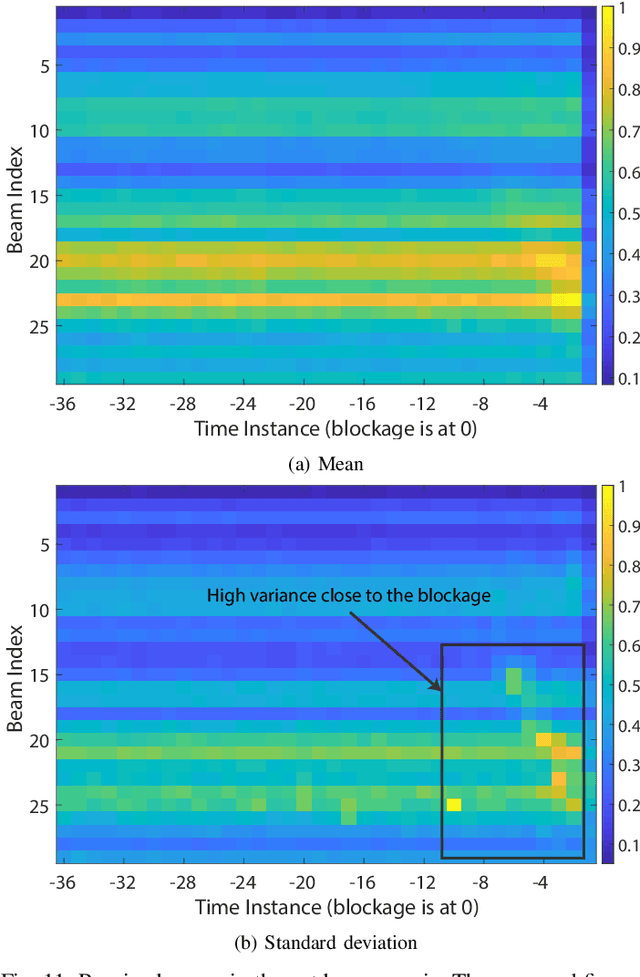
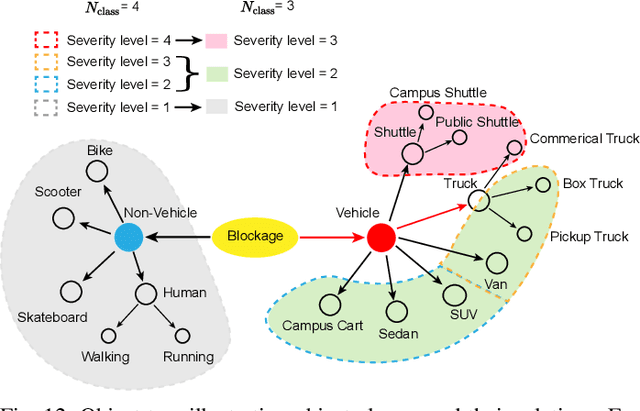
Overcoming the link blockage challenges is essential for enhancing the reliability and latency of millimeter wave (mmWave) and sub-terahertz (sub-THz) communication networks. Previous approaches relied mainly on either (i) multiple-connectivity, which under-utilizes the network resources, or on (ii) the use of out-of-band and non-RF sensors to predict link blockages, which is associated with increased cost and system complexity. In this paper, we propose a novel solution that relies only on in-band mmWave wireless measurements to proactively predict future dynamic line-of-sight (LOS) link blockages. The proposed solution utilizes deep neural networks and special patterns of received signal power, that we call pre-blockage wireless signatures to infer future blockages. Specifically, the developed machine learning models attempt to predict: (i) If a future blockage will occur? (ii) When will this blockage happen? (iii) What is the type of the blockage? And (iv) what is the direction of the moving blockage? To evaluate our proposed approach, we build a large-scale real-world dataset comprising nearly $0.5$ million data points (mmWave measurements) for both indoor and outdoor blockage scenarios. The results, using this dataset, show that the proposed approach can successfully predict the occurrence of future dynamic blockages with more than 85\% accuracy. Further, for the outdoor scenario with highly-mobile vehicular blockages, the proposed model can predict the exact time of the future blockage with less than $80$ms error for blockages happening within the future $500$ms. These results, among others, highlight the promising gains of the proposed proactive blockage prediction solution which could potentially enhance the reliability and latency of future wireless networks.