 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepMCAT: Large-Scale Deep Clustering for Medical Image Categorization
Sep 30, 2021
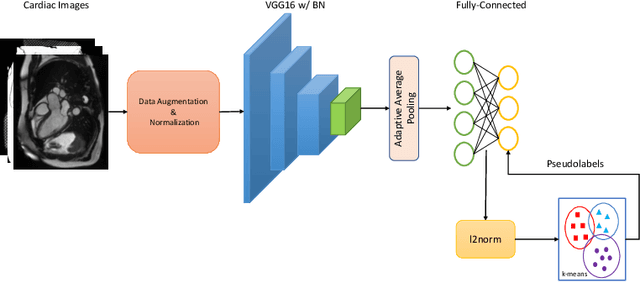

In recent years, the research landscape of machine learning in medical imaging has changed drastically from supervised to semi-, weakly- or unsupervised methods. This is mainly due to the fact that ground-truth labels are time-consuming and expensive to obtain manually. Generating labels from patient metadata might be feasible but it suffers from user-originated errors which introduce biases. In this work, we propose an unsupervised approach for automatically clustering and categorizing large-scale medical image datasets, with a focus on cardiac MR images, and without using any labels. We investigated the end-to-end training using both class-balanced and imbalanced large-scale datasets. Our method was able to create clusters with high purity and achieved over 0.99 cluster purity on these datasets. The results demonstrate the potential of the proposed method for categorizing unstructured large medical databases, such as organizing clinical PACS systems in hospitals.
Interpretable Classification of Time-Series Data using Efficient Enumerative Techniques
Jul 24, 2019
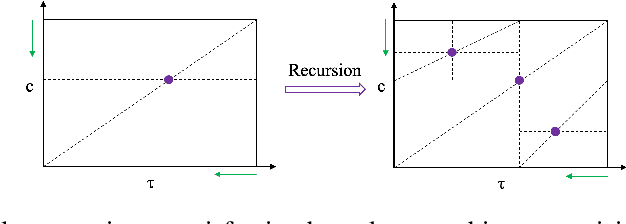
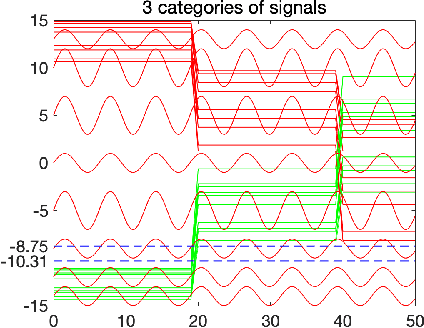
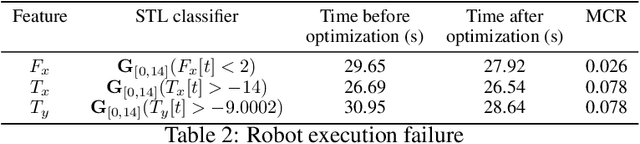
Cyber-physical system applications such as autonomous vehicles, wearable devices, and avionic systems generate a large volume of time-series data. Designers often look for tools to help classify and categorize the data. Traditional machine learning techniques for time-series data offer several solutions to solve these problems; however, the artifacts trained by these algorithms often lack interpretability. On the other hand, temporal logics, such as Signal Temporal Logic (STL) have been successfully used in the formal methods community as specifications of time-series behaviors. In this work, we propose a new technique to automatically learn temporal logic formulae that are able to cluster and classify real-valued time-series data. Previous work on learning STL formulas from data either assumes a formula-template to be given by the user, or assumes some special fragment of STL that enables exploring the formula structure in a systematic fashion. In our technique, we relax these assumptions, and provide a way to systematically explore the space of all STL formulas. As the space of all STL formulas is very large, and contains many semantically equivalent formulas, we suggest a technique to heuristically prune the space of formulas considered. Finally, we illustrate our technique on various case studies from the automotive, transportation and healthcare domain.
Which One is Better: Assessing Objective Metrics for Point Cloud Compression
Sep 15, 2021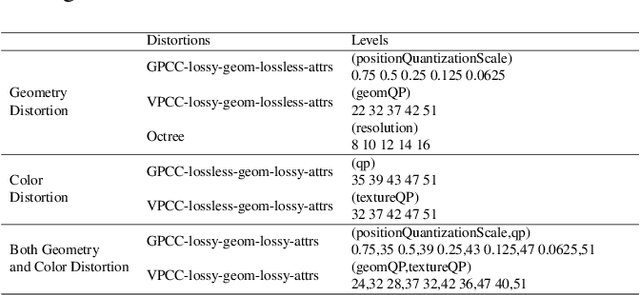

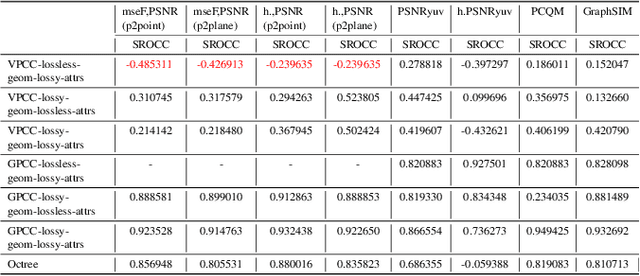
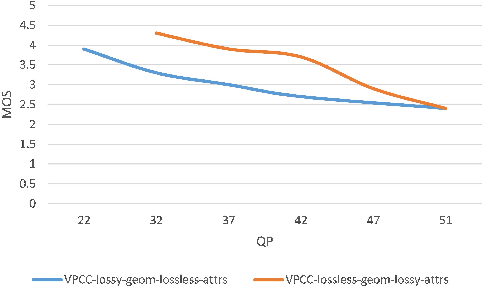
Point cloud compression (PCC) has made remarkable achievement in recent years. In the mean time, point cloud quality assessment (PCQA) also realize gratifying development. Some recently emerged metrics present robust performance on public point cloud assessment databases. However, these metrics have not been evaluated specifically for PCC to verify whether they exhibit consistent performance with the subjective perception. In this paper, we establish a new dataset for compression evaluation first, which contains 175 compressed point clouds in total, deriving from 7 compression algorithms with 5 compression levels. Then leveraging the proposed dataset, we evaluate the performance of the existing PCQA metrics in terms of different compression types. The results demonstrate some deficiencies of existing metrics in compression evaluation.
Deep Active Learning by Leveraging Training Dynamics
Oct 16, 2021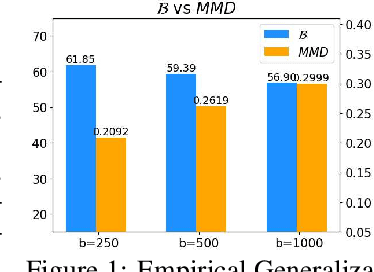


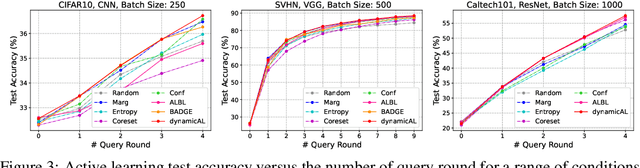
Active learning theories and methods have been extensively studied in classical statistical learning settings. However, deep active learning, i.e., active learning with deep learning models, is usually based on empirical criteria without solid theoretical justification, thus suffering from heavy doubts when some of those fail to provide benefits in applications. In this paper, by exploring the connection between the generalization performance and the training dynamics, we propose a theory-driven deep active learning method (dynamicAL) which selects samples to maximize training dynamics. In particular, we prove that convergence speed of training and the generalization performance is positively correlated under the ultra-wide condition and show that maximizing the training dynamics leads to a better generalization performance. Further on, to scale up to large deep neural networks and data sets, we introduce two relaxations for the subset selection problem and reduce the time complexity from polynomial to constant. Empirical results show that dynamicAL not only outperforms the other baselines consistently but also scales well on large deep learning models. We hope our work inspires more attempts in bridging the theoretical findings of deep networks and practical impacts in deep active learning applications.
Pseudo-label refinement using superpixels for semi-supervised brain tumour segmentation
Oct 16, 2021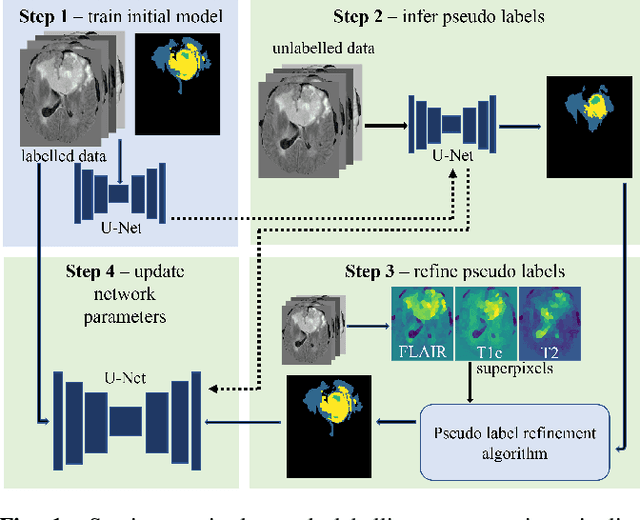
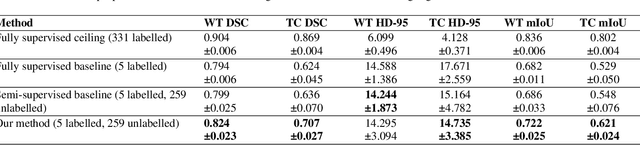
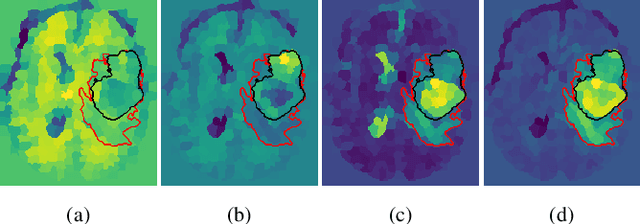
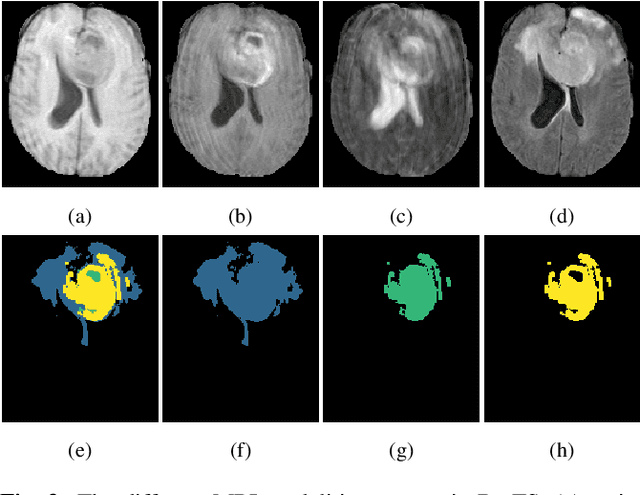
Training neural networks using limited annotations is an important problem in the medical domain. Deep Neural Networks (DNNs) typically require large, annotated datasets to achieve acceptable performance which, in the medical domain, are especially difficult to obtain as they require significant time from expert radiologists. Semi-supervised learning aims to overcome this problem by learning segmentations with very little annotated data, whilst exploiting large amounts of unlabelled data. However, the best-known technique, which utilises inferred pseudo-labels, is vulnerable to inaccurate pseudo-labels degrading the performance. We propose a framework based on superpixels - meaningful clusters of adjacent pixels - to improve the accuracy of the pseudo labels and address this issue. Our framework combines superpixels with semi-supervised learning, refining the pseudo-labels during training using the features and edges of the superpixel maps. This method is evaluated on a multimodal magnetic resonance imaging (MRI) dataset for the task of brain tumour region segmentation. Our method demonstrates improved performance over the standard semi-supervised pseudo-labelling baseline when there is a reduced annotator burden and only 5 annotated patients are available. We report DSC=0.824 and DSC=0.707 for the test set whole tumour and tumour core regions respectively.
Incorporating Reachability Knowledge into a Multi-Spatial Graph Convolution Based Seq2Seq Model for Traffic Forecasting
Jul 04, 2021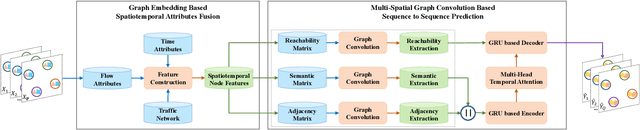
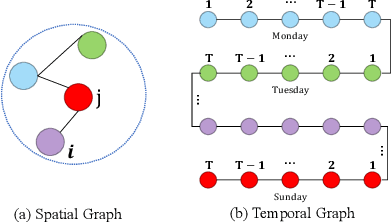
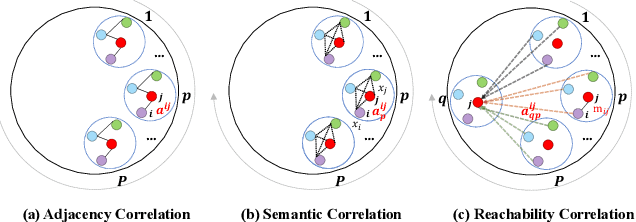
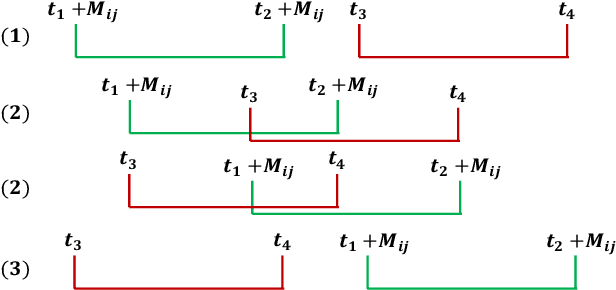
Accurate traffic state prediction is the foundation of transportation control and guidance. It is very challenging due to the complex spatiotemporal dependencies in traffic data. Existing works cannot perform well for multi-step traffic prediction that involves long future time period. The spatiotemporal information dilution becomes serve when the time gap between input step and predicted step is large, especially when traffic data is not sufficient or noisy. To address this issue, we propose a multi-spatial graph convolution based Seq2Seq model. Our main novelties are three aspects: (1) We enrich the spatiotemporal information of model inputs by fusing multi-view features (time, location and traffic states) (2) We build multiple kinds of spatial correlations based on both prior knowledge and data-driven knowledge to improve model performance especially in insufficient or noisy data cases. (3) A spatiotemporal attention mechanism based on reachability knowledge is novelly designed to produce high-level features fed into decoder of Seq2Seq directly to ease information dilution. Our model is evaluated on two real world traffic datasets and achieves better performance than other competitors.
Astrocytes mediate analogous memory in a multi-layer neuron-astrocytic network
Aug 31, 2021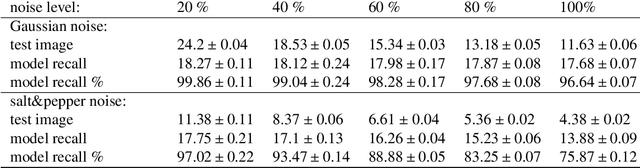
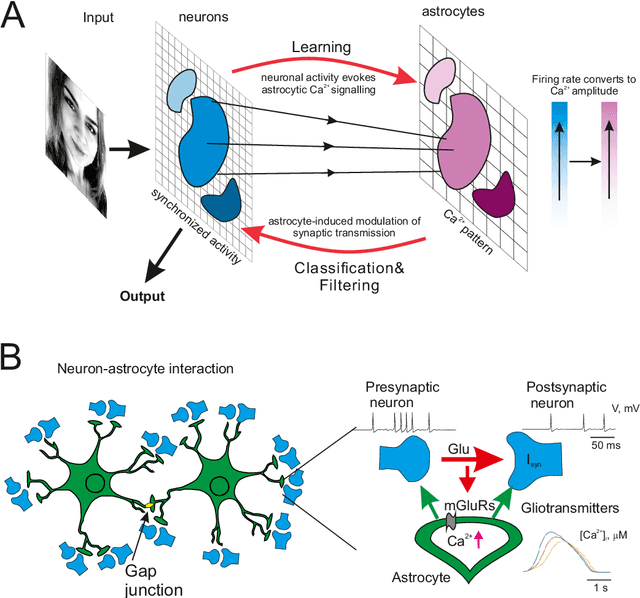


Modeling the neuronal processes underlying short-term working memory remains the focus of many theoretical studies in neuroscience. Here we propose a mathematical model of spiking neuron network (SNN) demonstrating how a piece of information can be maintained as a robust activity pattern for several seconds then completely disappear if no other stimuli come. Such short-term memory traces are preserved due to the activation of astrocytes accompanying the SNN. The astrocytes exhibit calcium transients at a time scale of seconds. These transients further modulate the efficiency of synaptic transmission and, hence, the firing rate of neighboring neurons at diverse timescales through gliotransmitter release. We show how such transients continuously encode frequencies of neuronal discharges and provide robust short-term storage of analogous information. This kind of short-term memory can keep operative information for seconds, then completely forget it to avoid overlapping with forthcoming patterns. The SNN is inter-connected with the astrocytic layer by local inter-cellular diffusive connections. The astrocytes are activated only when the neighboring neurons fire quite synchronously, e.g. when an information pattern is loaded. For illustration, we took greyscale photos of people's faces where the grey level encoded the level of applied current stimulating the neurons. The astrocyte feedback modulates (facilitates) synaptic transmission by varying the frequency of neuronal firing. We show how arbitrary patterns can be loaded, then stored for a certain interval of time, and retrieved if the appropriate clue pattern is applied to the input.
Weak Novel Categories without Tears: A Survey on Weak-Shot Learning
Oct 16, 2021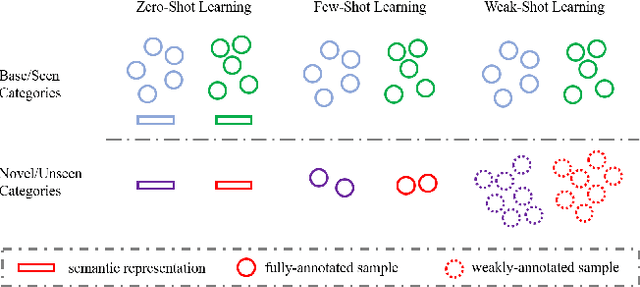
Deep learning is a data-hungry approach, which requires massive training data. However, it is time-consuming and labor-intensive to collect abundant fully-annotated training data for all categories. Assuming the existence of base categories with adequate fully-annotated training samples, different paradigms requiring fewer training samples or weaker annotations for novel categories have attracted growing research interest. Among them, zero-shot (resp., few-shot) learning explores using zero (resp., a few) training samples for novel categories, which lowers the quantity requirement for novel categories. Instead, weak-shot learning lowers the quality requirement for novel categories. Specifically, sufficient training samples are collected for novel categories but they only have weak annotations. In different tasks, weak annotations are presented in different forms (e.g., noisy labels for image classification, image labels for object detection, bounding boxes for segmentation), similar to the definitions in weakly supervised learning. Therefore, weak-shot learning can also be treated as weakly supervised learning with auxiliary fully supervised categories. In this paper, we discuss the existing weak-shot learning methodologies in different tasks and summarize the codes at https://github.com/bcmi/Awesome-Weak-Shot-Learning.
Deep Integrated Pipeline of Segmentation Leading to Classification for Automated Detection of Breast Cancer from Breast Ultrasound Images
Oct 26, 2021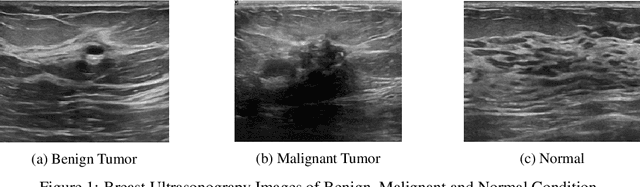
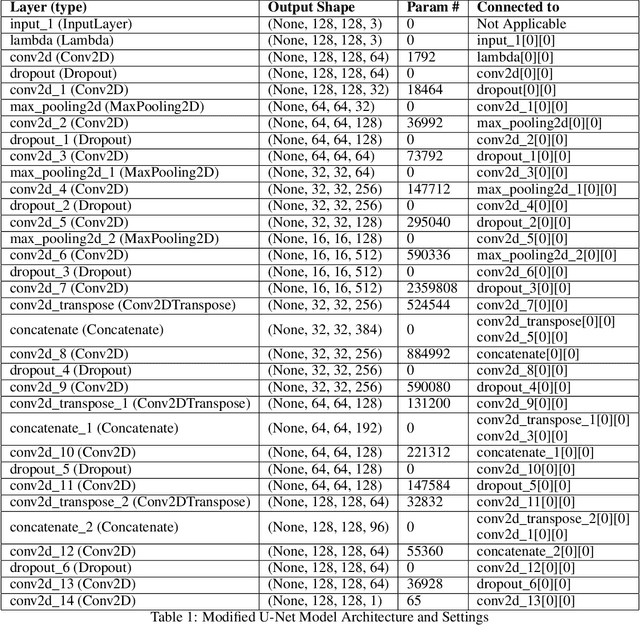
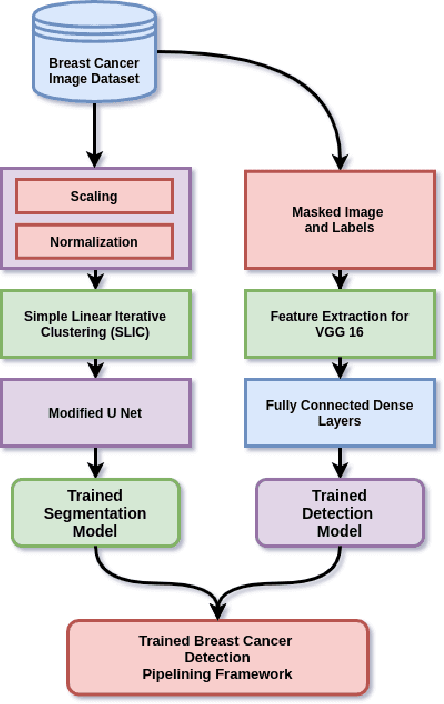

Breast cancer has become a symbol of tremendous concern in the modern world, as it is one of the major causes of cancer mortality worldwide. In this concern, many people are frequently screening for breast cancer in order to be identified early and avert mortality from the disease by receiving treatment. Breast Ultrasonography Images are frequently utilized by doctors to diagnose breast cancer at an early stage. However, the complex artifacts and heavily noised Breast Ultrasonography Images make detecting Breast Cancer a tough challenge. Furthermore, the ever-increasing number of patients being screened for Breast Cancer necessitates the use of automated Computer Aided Technology for high accuracy diagnosis at a cheap cost and in a short period of time. The current progress of Artificial Intelligence (AI) in the fields of Medical Image Analysis and Health Care is a boon to humanity. In this study, we have proposed a compact integrated automated pipelining framework which integrates ultrasonography image preprocessing with Simple Linear Iterative Clustering (SLIC) to tackle the complex artifact of Breast Ultrasonography Images complementing semantic segmentation with Modified U-Net leading to Breast Tumor classification with robust feature extraction using a transfer learning approach with pretrained VGG 16 model and densely connected neural network architecture. The proposed automated pipeline can be effectively implemented to assist medical practitioners in making more accurate and timely diagnoses of breast cancer.
Probabilistic Iterative LQR for Short Time Horizon MPC
Dec 11, 2020
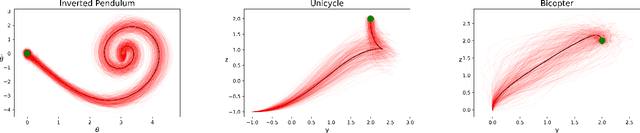
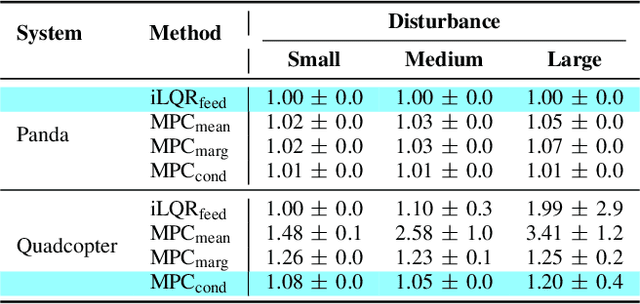
Optimal control is often used in robotics for planning a trajectory to achieve some desired behavior, as expressed by the cost function. Most works in optimal control focus on finding a single optimal trajectory, which is then typically tracked by another controller. In this work, we instead consider trajectory distribution as the solution of an optimal control problem, resulting in better tracking performance and a more stable controller. A Gaussian distribution is first obtained from an iterative Linear Quadratic Regulator (iLQR) solver. A short horizon Model Predictive Control (MPC) is then used to track this distribution. We show that tracking a distribution is more cost-efficient and robust as compared to tracking the mean or using iLQR feedback control. The proposed method is validated with kinematic control of 7-DoF Panda manipulator and dynamic control of 6-DoF quadcopter in simulation.