 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
May 01, 2020
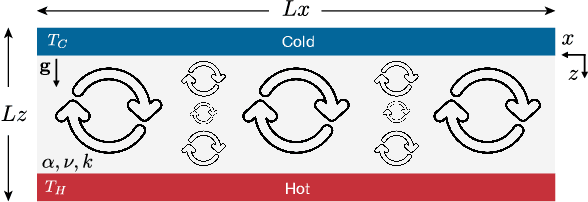
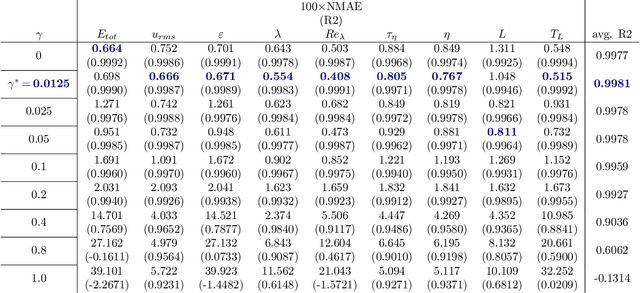
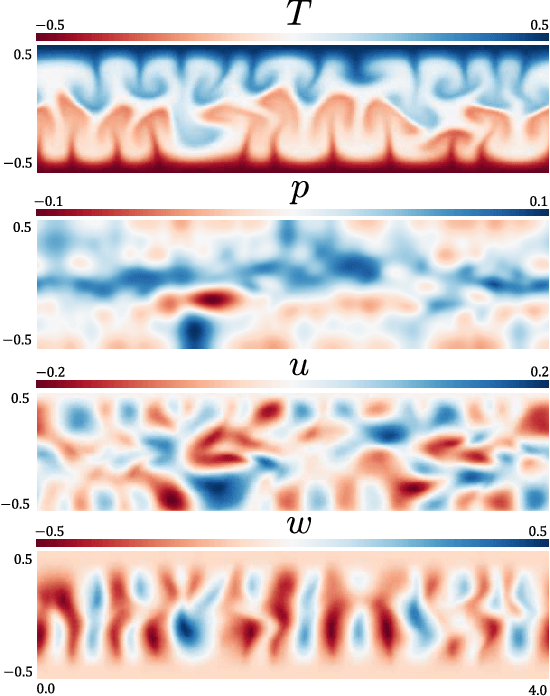

We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder. We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh-Benard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
Parameter Estimation in Adaptive Control of Time-Varying Systems Under a Range of Excitation Conditions
Nov 10, 2019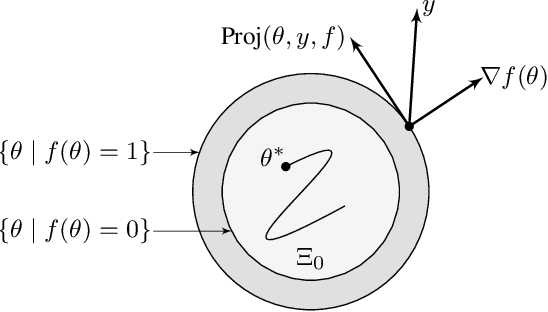
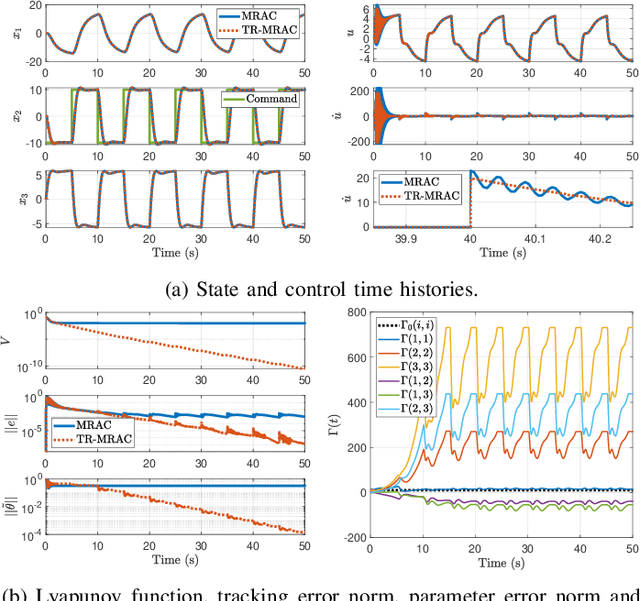


This paper presents a new parameter estimation algorithm for the adaptive control of a class of time-varying plants. The main feature of this algorithm is a matrix of time-varying learning rates, which enables parameter estimation error trajectories to tend exponentially fast towards a compact set whenever excitation conditions are satisfied. This algorithm is employed in a large class of problems where unknown parameters are present and are time-varying. It is shown that this algorithm guarantees global boundedness of the state and parameter errors of the system, and avoids an often used filtering approach for constructing key regressor signals. In addition, intervals of time over which these errors tend exponentially fast toward a compact set are provided, both in the presence of finite and persistent excitation. A projection operator is used to ensure the boundedness of the learning rate matrix, as compared to a time-varying forgetting factor. Numerical simulations are provided to complement the theoretical analysis.
FacTeR-Check: Semi-automated fact-checking through Semantic Similarity and Natural Language Inference
Oct 27, 2021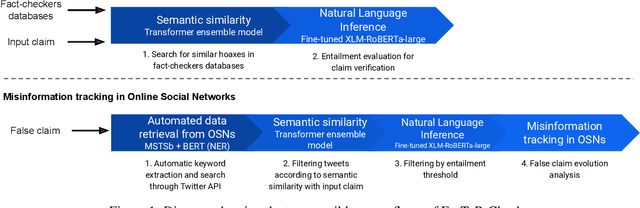
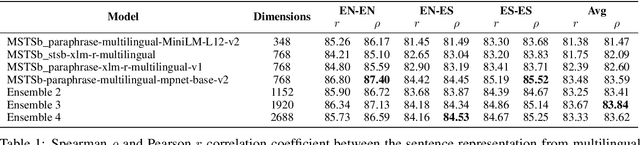

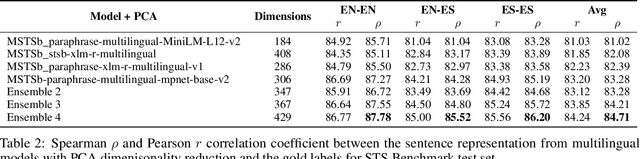
Our society produces and shares overwhelming amounts of information through the Online Social Networks (OSNs). Within this environment, misinformation and disinformation have proliferated, becoming a public safety concern on every country. Allowing the public and professionals to efficiently find reliable evidence about the factual veracity of a claim is crucial to mitigate this harmful spread. To this end, we propose FacTeR-Check, a multilingual architecture for semi-automated fact-checking that can be used for either the general public but also useful for fact-checking organisations. FacTeR-Check enables retrieving fact-checked information, unchecked claims verification and tracking dangerous information over social media. This architectures involves several modules developed to evaluate semantic similarity, to calculate natural language inference and to retrieve information from Online Social Networks. The union of all these modules builds a semi-automated fact-checking tool able of verifying new claims, to extract related evidence, and to track the evolution of a hoax on a OSN. While individual modules are validated on related benchmarks (mainly MSTS and SICK), the complete architecture is validated using a new dataset called NLI19-SP that is publicly released with COVID-19 related hoaxes and tweets from Spanish social media. Our results show state-of-the-art performance on the individual benchmarks, as well as producing useful analysis of the evolution over time of 61 different hoaxes.
Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation
Oct 27, 2021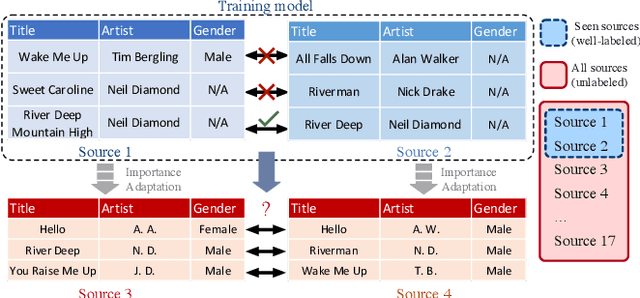

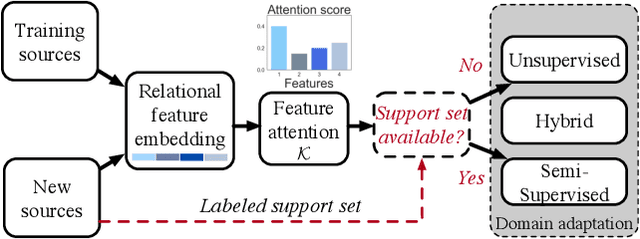
Multi-source entity linkage focuses on integrating knowledge from multiple sources by linking the records that represent the same real world entity. This is critical in high-impact applications such as data cleaning and user stitching. The state-of-the-art entity linkage pipelines mainly depend on supervised learning that requires abundant amounts of training data. However, collecting well-labeled training data becomes expensive when the data from many sources arrives incrementally over time. Moreover, the trained models can easily overfit to specific data sources, and thus fail to generalize to new sources due to significant differences in data and label distributions. To address these challenges, we present AdaMEL, a deep transfer learning framework that learns generic high-level knowledge to perform multi-source entity linkage. AdaMEL models the attribute importance that is used to match entities through an attribute-level self-attention mechanism, and leverages the massive unlabeled data from new data sources through domain adaptation to make it generic and data-source agnostic. In addition, AdaMEL is capable of incorporating an additional set of labeled data to more accurately integrate data sources with different attribute importance. Extensive experiments show that our framework achieves state-of-the-art results with 8.21% improvement on average over methods based on supervised learning. Besides, it is more stable in handling different sets of data sources in less runtime.
Automated Cardiac Resting Phase Detection Targeted on the Right Coronary Artery
Sep 06, 2021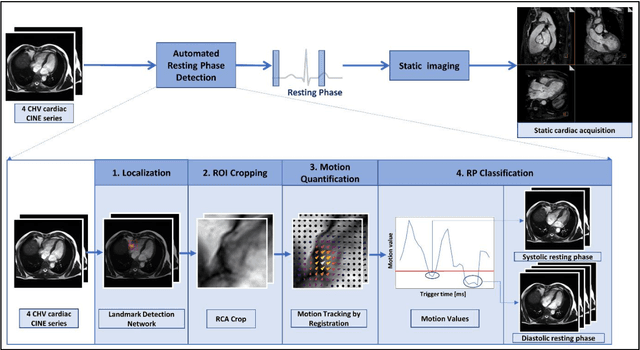
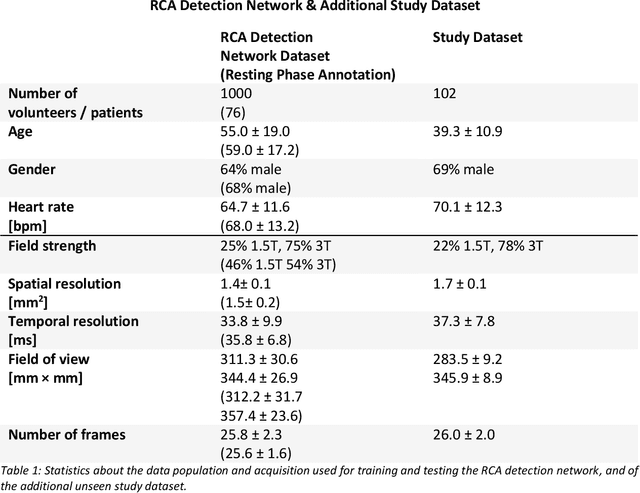
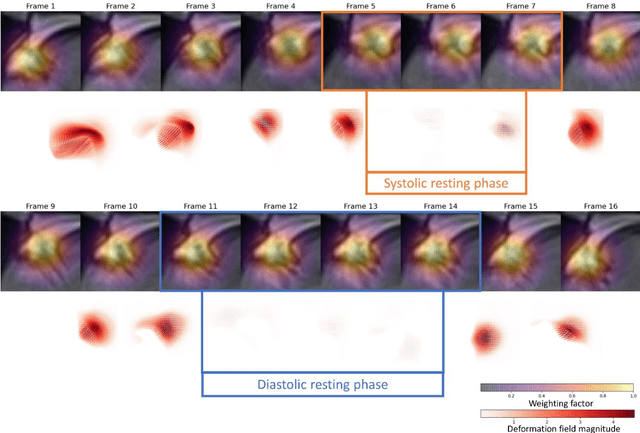
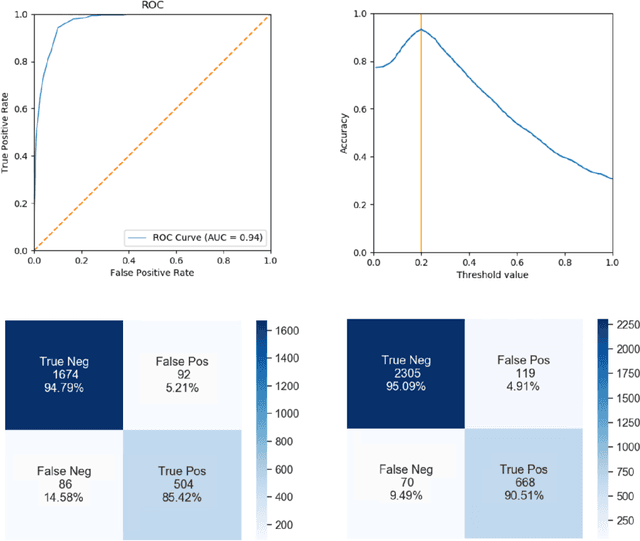
Purpose: Static cardiac imaging such as late gadolinium enhancement, mapping, or 3-D coronary angiography require prior information, e.g., the phase during a cardiac cycle with least motion, called resting phase (RP). The purpose of this work is to propose a fully automated framework that allows the detection of the right coronary artery (RCA) RP within CINE series. Methods: The proposed prototype system consists of three main steps. First, the localization of the regions of interest (ROI) is performed. Second, as CINE series are time-resolved, the cropped ROI series over all time points are taken for tracking motions quantitatively. Third, the output motion values are used to classify RPs. In this work, we focused on the detection of the area with the outer edge of the cross-section of the RCA as our target. The proposed framework was evaluated on 102 clinically acquired dataset at 1.5T and 3T. The automatically classified RPs were compared with the ground truth RPs annotated manually by a medical expert for testing the robustness and feasibility of the framework. Results: The predicted RCA RPs showed high agreement with the experts annotated RPs with 92.7% accuracy, 90.5% sensitivity and 95.0% specificity for the unseen study dataset. The mean absolute difference of the start and end RP was 13.6 ${\pm}$ 18.6 ms for the validation study dataset (n=102). Conclusion: In this work, automated RP detection has been introduced by the proposed framework and demonstrated feasibility, robustness, and applicability for diverse static imaging acquisitions.
Compressive Sensing Based Adaptive Defence Against Adversarial Images
Oct 11, 2021
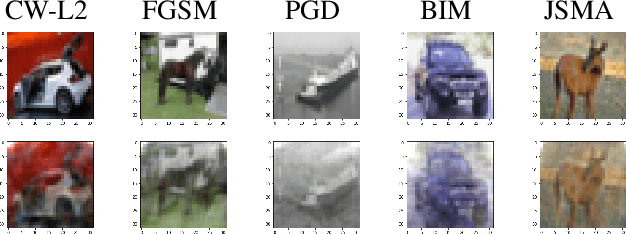
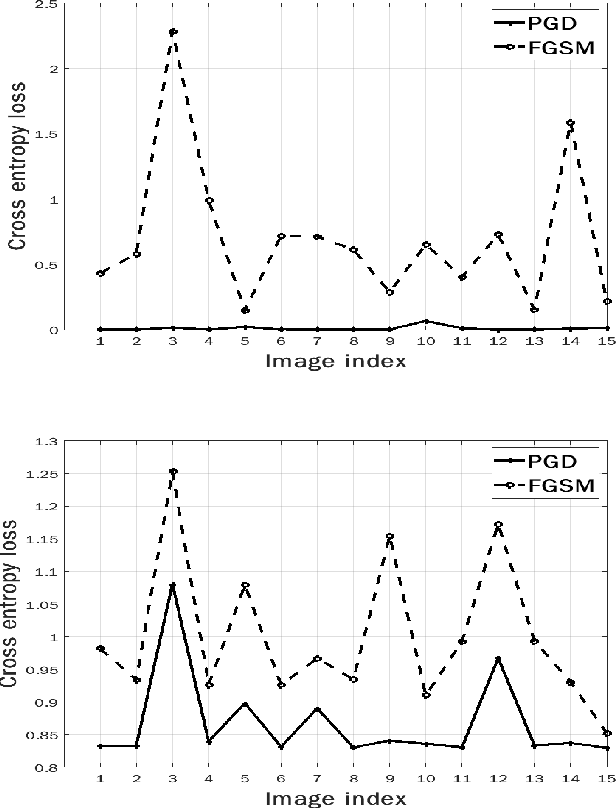
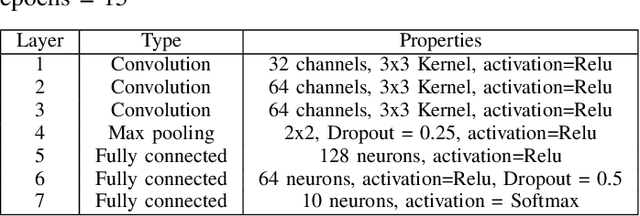
Herein, security of deep neural network against adversarial attack is considered. Existing compressive sensing based defence schemes assume that adversarial perturbations are usually on high frequency components, whereas recently it has been shown that low frequency perturbations are more effective. This paper proposes a novel Compressive sensing based Adaptive Defence (CAD) algorithm which combats distortion in frequency domain instead of time domain. Unlike existing literature, the proposed CAD algorithm does not use information about the type of attack such as l0, l2, l-infinity etc. CAD algorithm uses exponential weight algorithm for exploration and exploitation to identify the type of attack, compressive sampling matching pursuit (CoSaMP) to recover the coefficients in spectral domain, and modified basis pursuit using a novel constraint for l0, l-infinity norm attack. Tight performance bounds for various recovery schemes meant for various attack types are also provided. Experimental results against five state-of-the-art white box attacks on MNIST and CIFAR-10 show that the proposed CAD algorithm achieves excellent classification accuracy and generates good quality reconstructed image with much lower computation
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Oct 22, 2021


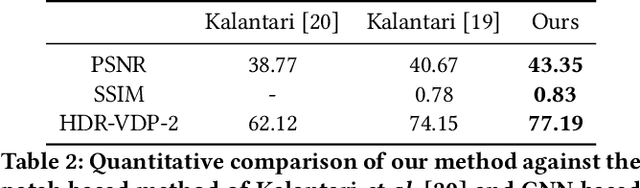
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Bid Optimization using Maximum Entropy Reinforcement Learning
Oct 11, 2021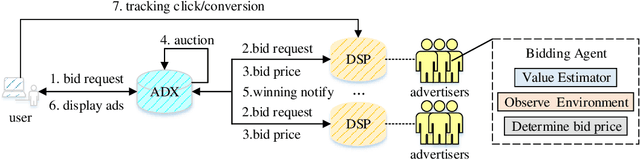

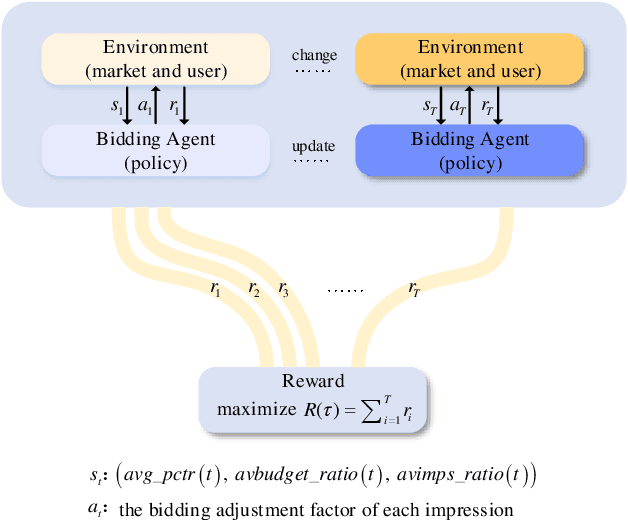
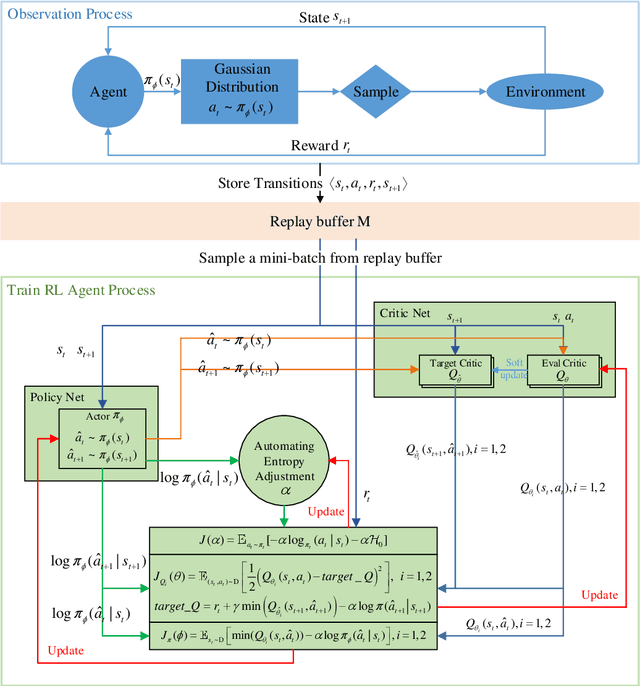
Real-time bidding (RTB) has become a critical way of online advertising. In RTB, an advertiser can participate in bidding ad impressions to display its advertisements. The advertiser determines every impression's bidding price according to its bidding strategy. Therefore, a good bidding strategy can help advertisers improve cost efficiency. This paper focuses on optimizing a single advertiser's bidding strategy using reinforcement learning (RL) in RTB. Unfortunately, it is challenging to optimize the bidding strategy through RL at the granularity of impression due to the highly dynamic nature of the RTB environment. In this paper, we first utilize a widely accepted linear bidding function to compute every impression's base price and optimize it by a mutable adjustment factor derived from the RTB auction environment, to avoid optimizing every impression's bidding price directly. Specifically, we use the maximum entropy RL algorithm (Soft Actor-Critic) to optimize the adjustment factor generation policy at the impression-grained level. Finally, the empirical study on a public dataset demonstrates that the proposed bidding strategy has superior performance compared with the baselines.
Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation
Oct 14, 2019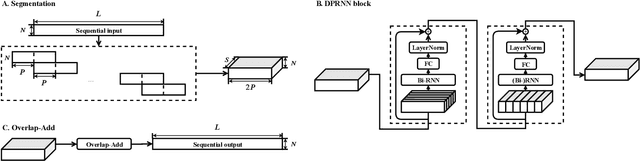
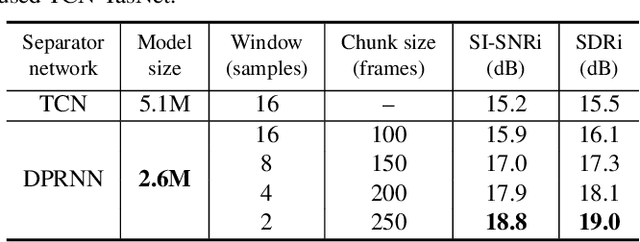
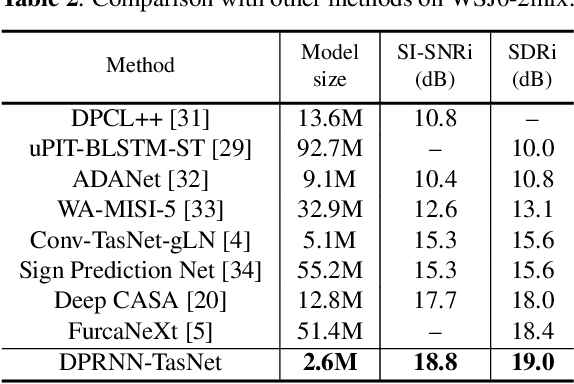
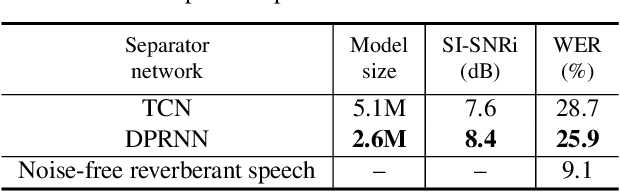
Recent studies in deep learning-based speech separation have proven the superiority of time-domain approaches to conventional time-frequency-based methods. Unlike the time-frequency domain approaches, the time-domain separation systems often receive input sequences consisting of a huge number of time steps, which introduces challenges for modeling extremely long sequences. Conventional recurrent neural networks (RNNs) are not effective for modeling such long sequences due to optimization difficulties, while one-dimensional convolutional neural networks (1-D CNNs) cannot perform utterance-level sequence modeling when its receptive field is smaller than the sequence length. In this paper, we propose dual-path recurrent neural network (DPRNN), a simple yet effective method for organizing RNN layers in a deep structure to model extremely long sequences. DPRNN splits the long sequential input into smaller chunks and applies intra- and inter-chunk operations iteratively, where the input length can be made proportional to the square root of the original sequence length in each operation. Experiments show that by replacing 1-D CNN with DPRNN and apply sample-level modeling in the time-domain audio separation network (TasNet), a new state-of-the-art performance on WSJ0-2mix is achieved with a 20 times smaller model than the previous best system.
Novel Secret-Key-Assisted Schemes for Secure MISOME-OFDM Systems
Oct 17, 2021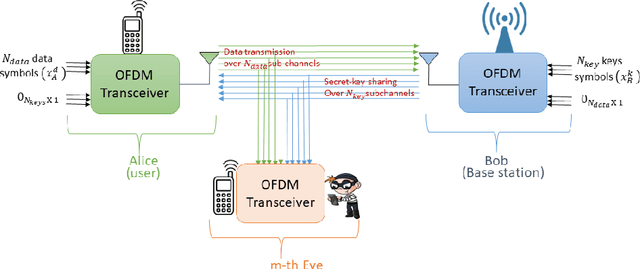
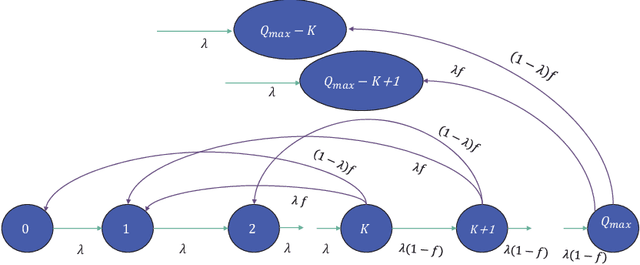
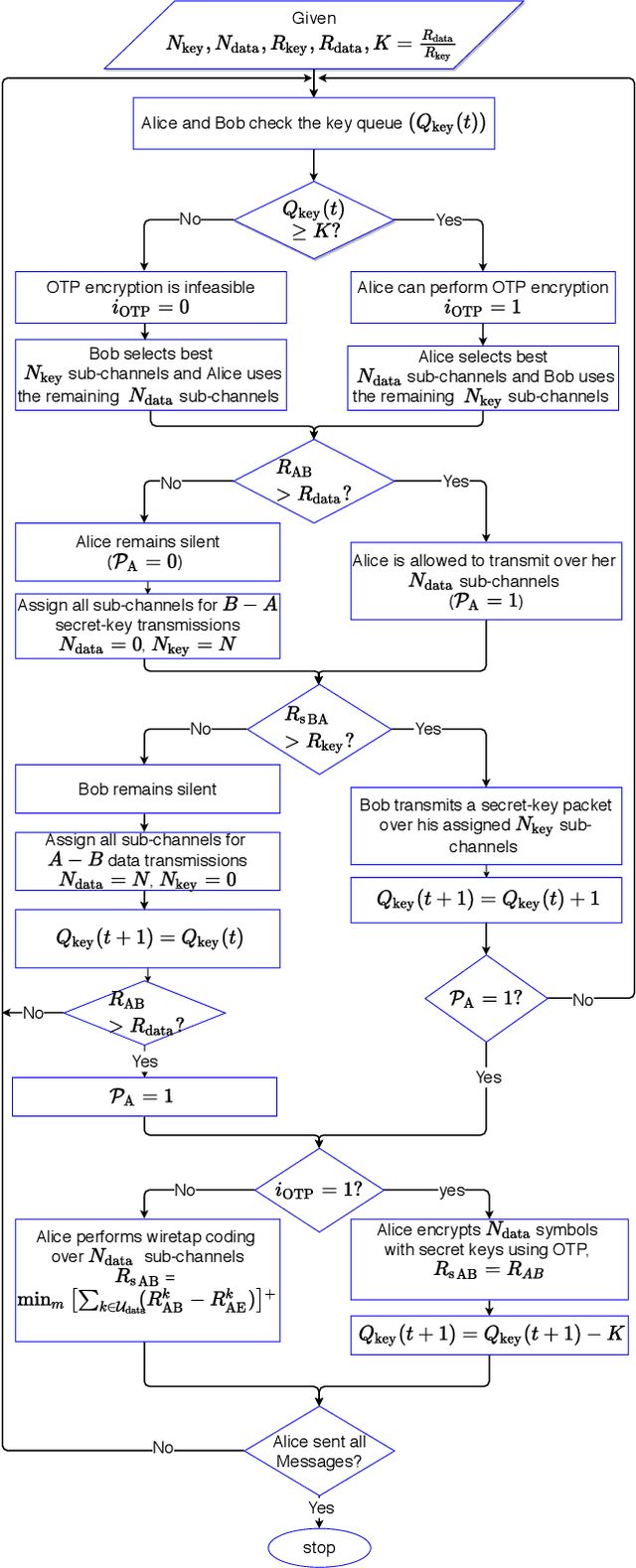
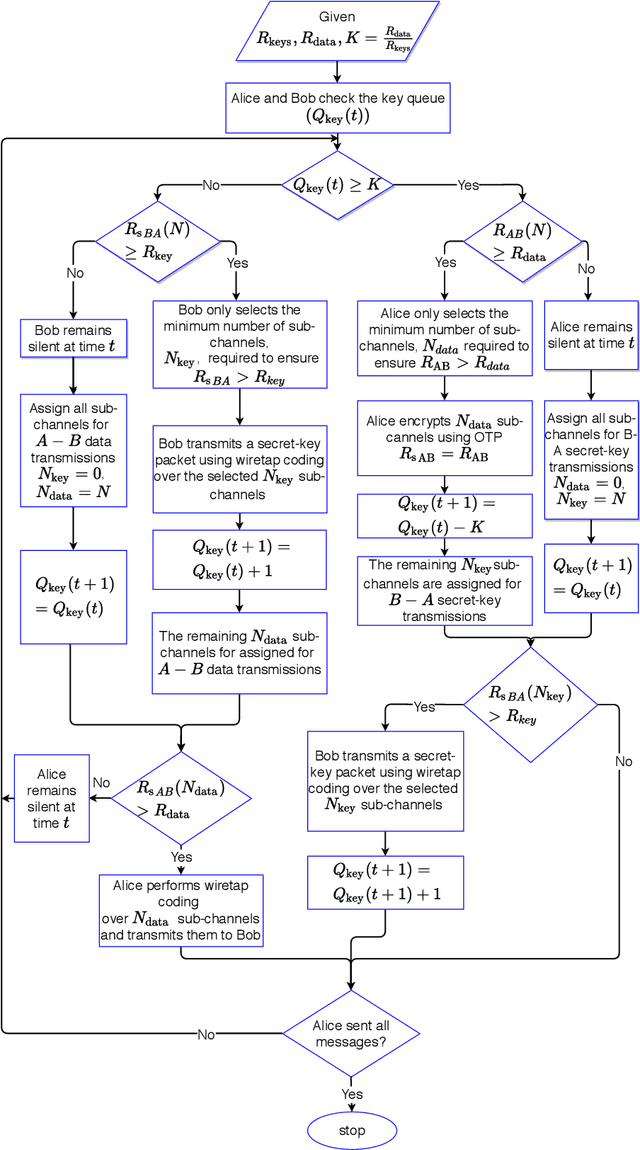
We propose a new secure transmission scheme for uplink multiple-input single-output (MISO) orthogonal-frequency multiplexing (OFDM) systems in the presence of multiple eavesdroppers. Our proposed scheme utilizes the sub-channels orthogonality of OFDM systems to simultaneously transmit data and secret key symbols. The base station, Bob, shares secret key symbols with the legitimate user, Alice, using wiretap coding over a portion of the sub-channels. Concurrently, Alice uses the accumulated secret keys in her secret-key queue to encrypt data symbols using a one time pad (OTP) cipher and transmits them to Bob over the remaining sub-channels. if Alice did not accumulate sufficient keys in her secret-key queue, she employs wiretap coding to secure her data transmissions. We propose fixed and dynamic sub-channel allocation schemes to divide the sub-channels between data and secret keys. We derive the secrecy outage probability (SOP) and the secure throughput for the proposed scheme. We quantify the system's security under practical non-Gaussian transmissions where discrete signal constellation points are transmitted by the legitimate source nodes. Numerical results validate our theoretical findings and quantify the impact of different system design parameters.