 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SDnDTI: Self-supervised deep learning-based denoising for diffusion tensor MRI
Nov 14, 2021
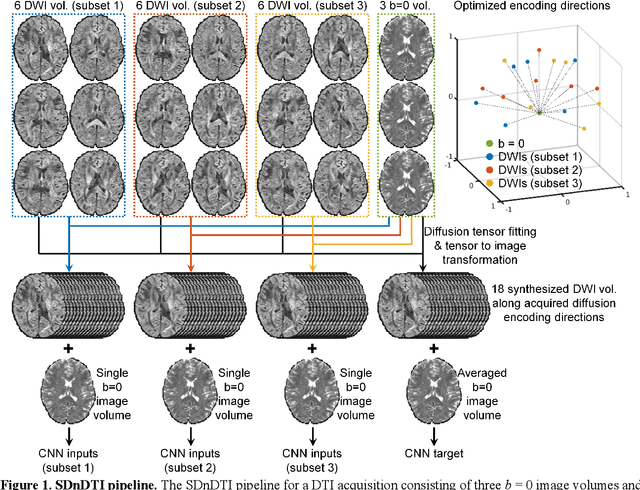
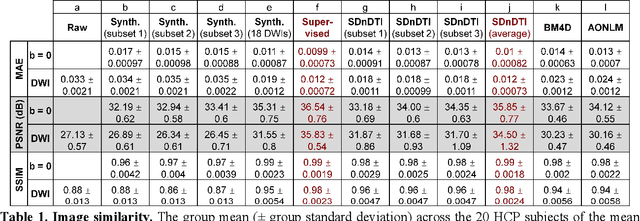
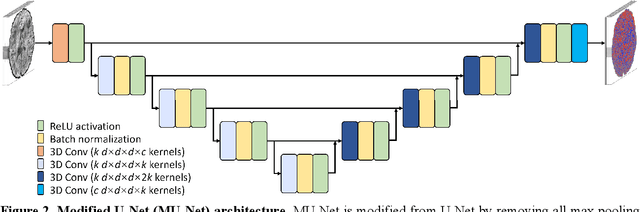
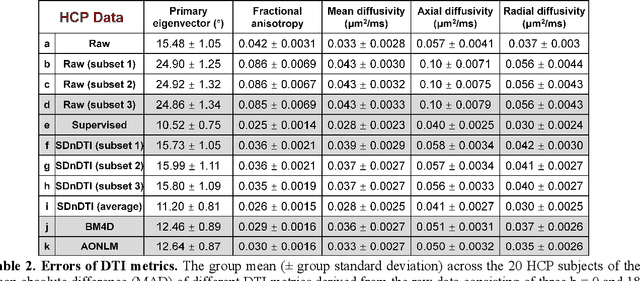
The noise in diffusion-weighted images (DWIs) decreases the accuracy and precision of diffusion tensor magnetic resonance imaging (DTI) derived microstructural parameters and leads to prolonged acquisition time for achieving improved signal-to-noise ratio (SNR). Deep learning-based image denoising using convolutional neural networks (CNNs) has superior performance but often requires additional high-SNR data for supervising the training of CNNs, which reduces the practical feasibility. We develop a self-supervised deep learning-based method entitled "SDnDTI" for denoising DTI data, which does not require additional high-SNR data for training. Specifically, SDnDTI divides multi-directional DTI data into many subsets, each consisting of six DWI volumes along optimally chosen diffusion-encoding directions that are robust to noise for the tensor fitting, and then synthesizes DWI volumes along all acquired directions from the diffusion tensors fitted using each subset of the data as the input data of CNNs. On the other hand, SDnDTI synthesizes DWI volumes along acquired diffusion-encoding directions with higher SNR from the diffusion tensors fitted using all acquired data as the training target. SDnDTI removes noise from each subset of synthesized DWI volumes using a deep 3-dimensional CNN to match the quality of the cleaner target DWI volumes and achieves even higher SNR by averaging all subsets of denoised data. The denoising efficacy of SDnDTI is demonstrated on two datasets provided by the Human Connectome Project (HCP) and the Lifespan HCP in Aging. The SDnDTI results preserve image sharpness and textural details and substantially improve upon those from the raw data. The results of SDnDTI are comparable to those from supervised learning-based denoising and outperform those from state-of-the-art conventional denoising algorithms including BM4D, AONLM and MPPCA.
Evaluating the Single-Shot MultiBox Detector and YOLO Deep Learning Models for the Detection of Tomatoes in a Greenhouse
Sep 02, 2021
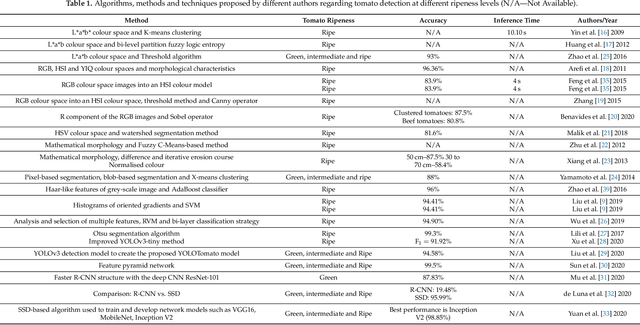
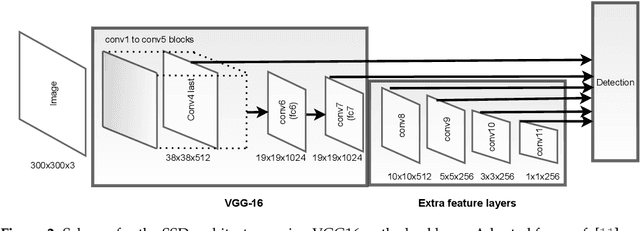
The development of robotic solutions for agriculture requires advanced perception capabilities that can work reliably in any crop stage. For example, to automatise the tomato harvesting process in greenhouses, the visual perception system needs to detect the tomato in any life cycle stage (flower to the ripe tomato). The state-of-the-art for visual tomato detection focuses mainly on ripe tomato, which has a distinctive colour from the background. This paper contributes with an annotated visual dataset of green and reddish tomatoes. This kind of dataset is uncommon and not available for research purposes. This will enable further developments in edge artificial intelligence for in situ and in real-time visual tomato detection required for the development of harvesting robots. Considering this dataset, five deep learning models were selected, trained and benchmarked to detect green and reddish tomatoes grown in greenhouses. Considering our robotic platform specifications, only the Single-Shot MultiBox Detector (SSD) and YOLO architectures were considered. The results proved that the system can detect green and reddish tomatoes, even those occluded by leaves. SSD MobileNet v2 had the best performance when compared against SSD Inception v2, SSD ResNet 50, SSD ResNet 101 and YOLOv4 Tiny, reaching an F1-score of 66.15%, an mAP of 51.46% and an inference time of 16.44 ms with the NVIDIA Turing Architecture platform, an NVIDIA Tesla T4, with 12 GB. YOLOv4 Tiny also had impressive results, mainly concerning inferring times of about 5 ms.
* Dataset at DOI:10.25747/pc1e-nk92
Evolutionary Algorithms for Solving Unconstrained, Constrained and Multi-objective Noisy Combinatorial Optimisation Problems
Oct 05, 2021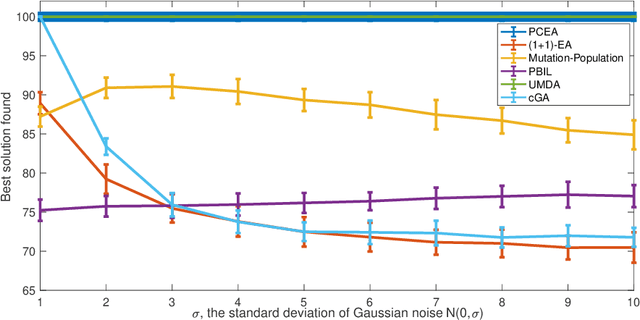

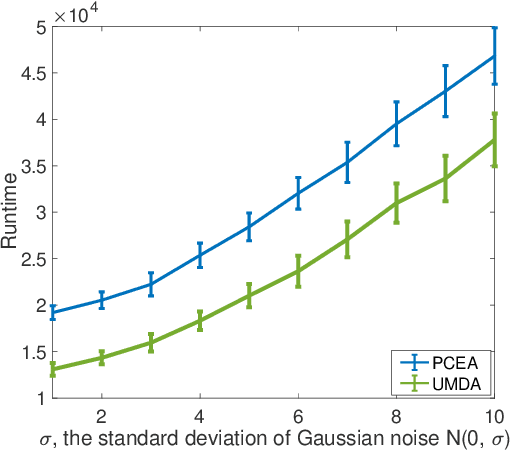

We present an empirical study of a range of evolutionary algorithms applied to various noisy combinatorial optimisation problems. There are three sets of experiments. The first looks at several toy problems, such as OneMax and other linear problems. We find that UMDA and the Paired-Crossover Evolutionary Algorithm (PCEA) are the only ones able to cope robustly with noise, within a reasonable fixed time budget. In the second stage, UMDA and PCEA are then tested on more complex noisy problems: SubsetSum, Knapsack and SetCover. Both perform well under increasing levels of noise, with UMDA being the better of the two. In the third stage, we consider two noisy multi-objective problems (CountingOnesCountingZeros and a multi-objective formulation of SetCover). We compare several adaptations of UMDA for multi-objective problems with the Simple Evolutionary Multi-objective Optimiser (SEMO) and NSGA-II. We conclude that UMDA, and its variants, can be highly effective on a variety of noisy combinatorial optimisation, outperforming many other evolutionary algorithms.
An Adaptable Approach to Learn Realistic Legged Locomotion without Examples
Oct 28, 2021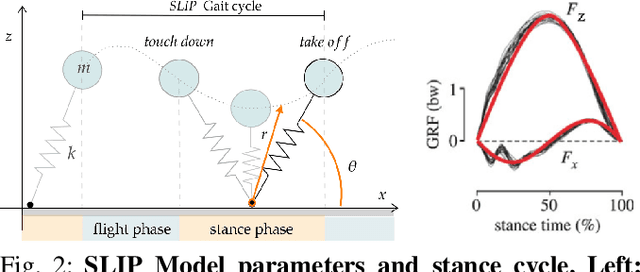
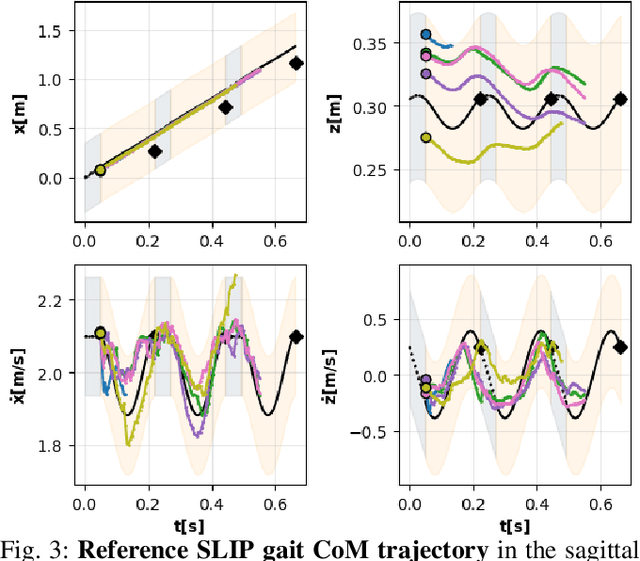
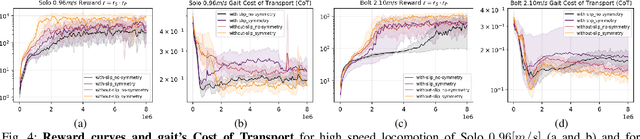
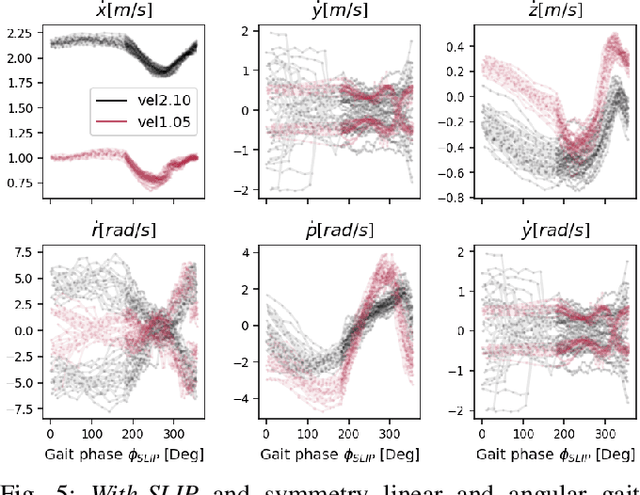
Learning controllers that reproduce legged locomotion in nature have been a long-time goal in robotics and computer graphics. While yielding promising results, recent approaches are not yet flexible enough to be applicable to legged systems of different morphologies. This is partly because they often rely on precise motion capture references or elaborate learning environments that ensure the naturality of the emergent locomotion gaits but prevent generalization. This work proposes a generic approach for ensuring realism in locomotion by guiding the learning process with the spring-loaded inverted pendulum model as a reference. Leveraging on the exploration capacities of Reinforcement Learning (RL), we learn a control policy that fills in the information gap between the template model and full-body dynamics required to maintain stable and periodic locomotion. The proposed approach can be applied to robots of different sizes and morphologies and adapted to any RL technique and control architecture. We present experimental results showing that even in a model-free setup and with a simple reactive control architecture, the learned policies can generate realistic and energy-efficient locomotion gaits for a bipedal and a quadrupedal robot. And most importantly, this is achieved without using motion capture, strong constraints in the dynamics or kinematics of the robot, nor prescribing limb coordination. We provide supplemental videos for qualitative analysis of the naturality of the learned gaits.
Waypoint Models for Instruction-guided Navigation in Continuous Environments
Oct 05, 2021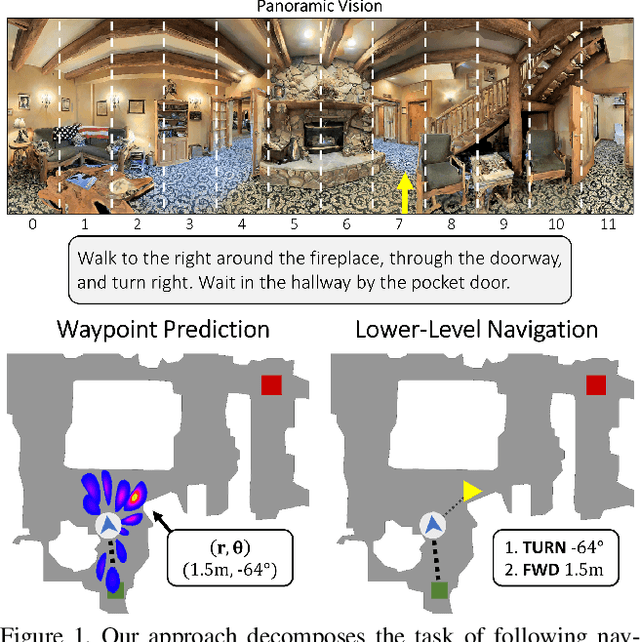
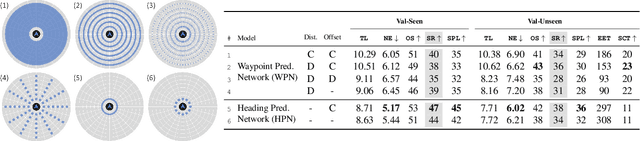
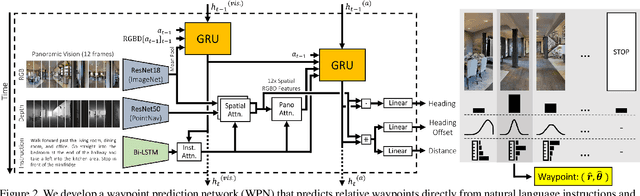

Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation -- either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard -- increasing success rate by 4% with our best model on this challenging task.
DocScanner: Robust Document Image Rectification with Progressive Learning
Oct 28, 2021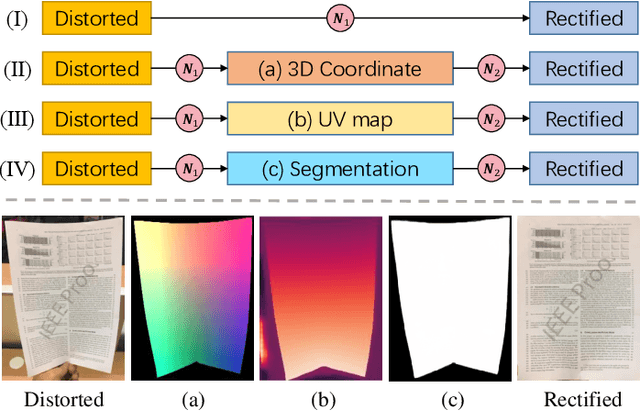

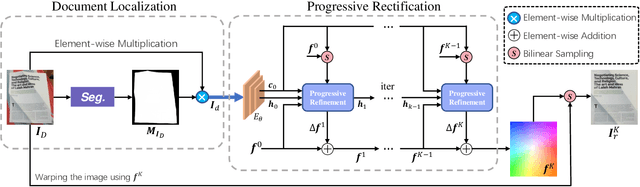
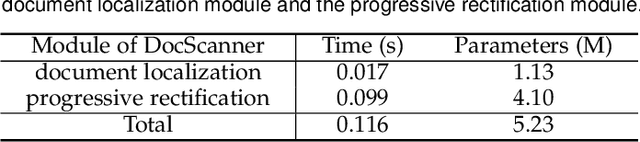
Compared to flatbed scanners, portable smartphones are much more convenient for physical documents digitizing. However, such digitized documents are often distorted due to uncontrolled physical deformations, camera positions, and illumination variations. To this end, this work presents DocScanner, a new deep network architecture for document image rectification. Different from existing methods, DocScanner addresses this issue by introducing a progressive learning mechanism. Specifically, DocScanner maintains a single estimate of the rectified image, which is progressively corrected with a recurrent architecture. The iterative refinements make DocScanner converge to a robust and superior performance, and the lightweight recurrent architecture ensures the running efficiency. In addition, before the above rectification process, observing the corrupted rectified boundaries existing in prior works, DocScanner exploits a document localization module to explicitly segment the foreground document from the cluttered background environments. To further improve the rectification quality, based on the geometric priori between the distorted and the rectified images, a geometric regularization is introduced during training to further facilitate the performance. Extensive experiments are conducted on the Doc3D dataset and the DocUNet benchmark dataset, and the quantitative and qualitative evaluation results verify the effectiveness of DocScanner, which outperforms previous methods on OCR accuracy, image similarity, and our proposed distortion metric by a considerable margin. Furthermore, our DocScanner shows the highest efficiency in inference time and parameter count.
Semi-Siamese Bi-encoder Neural Ranking Model Using Lightweight Fine-Tuning
Oct 28, 2021
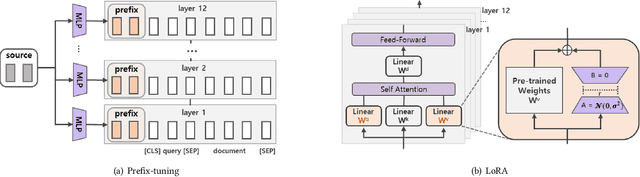

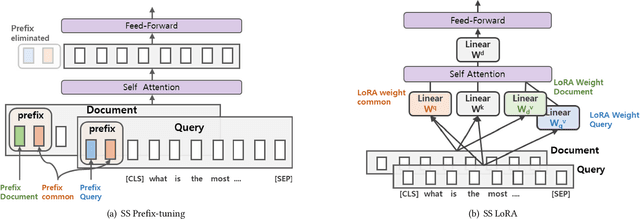
A BERT-based Neural Ranking Model (NRM) can be either a cross-encoder or a bi-encoder. Between the two, bi-encoder is highly efficient because all the documents can be pre-processed before the actual query time. Although query and document are independently encoded, the existing bi-encoder NRMs are Siamese models where a single language model is used for consistently encoding both of query and document. In this work, we show two approaches for improving the performance of BERT-based bi-encoders. The first approach is to replace the full fine-tuning step with a lightweight fine-tuning. We examine lightweight fine-tuning methods that are adapter-based, prompt-based, and hybrid of the two. The second approach is to develop semi-Siamese models where queries and documents are handled with a limited amount of difference. The limited difference is realized by learning two lightweight fine-tuning modules, where the main language model of BERT is kept common for both query and document. We provide extensive experiment results for monoBERT, TwinBERT, and ColBERT where three performance metrics are evaluated over Robust04, ClueWeb09b, and MS-MARCO datasets. The results confirm that both lightweight fine-tuning and semi-Siamese are considerably helpful for improving BERT-based bi-encoders. In fact, lightweight fine-tuning is helpful for cross-encoder, too.
Dynamic texture recognition using time-causal and time-recursive spatio-temporal receptive fields
Jun 21, 2018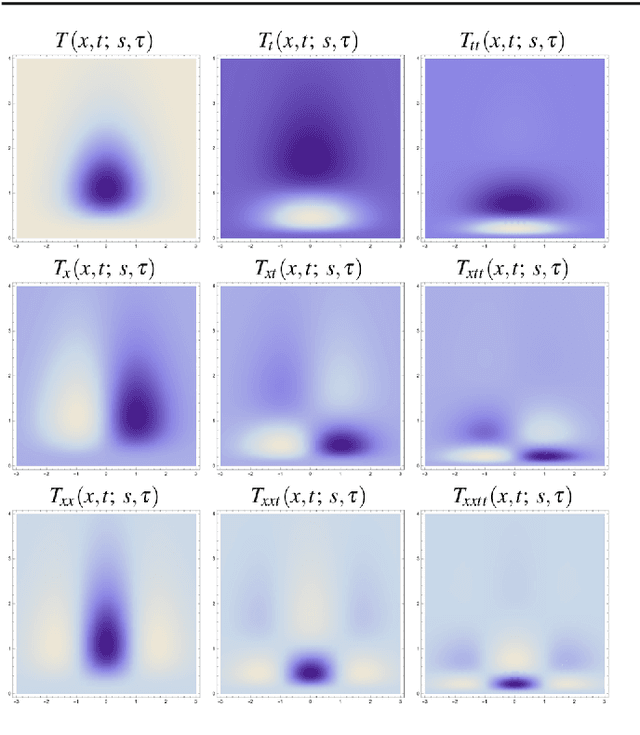

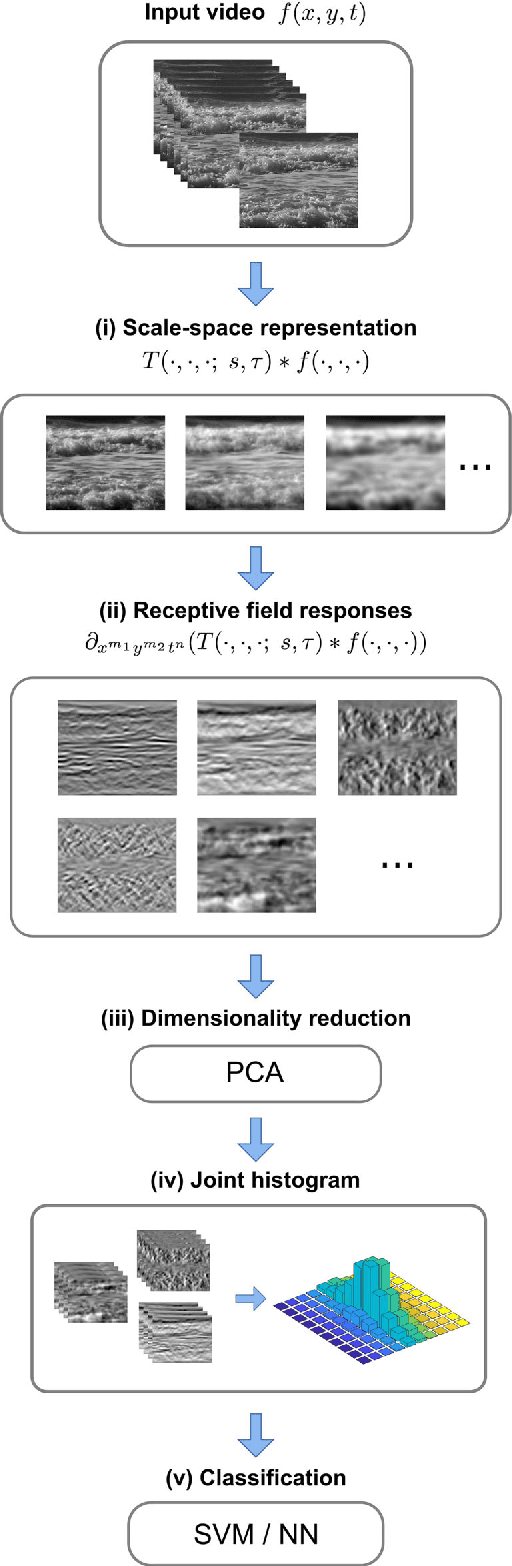
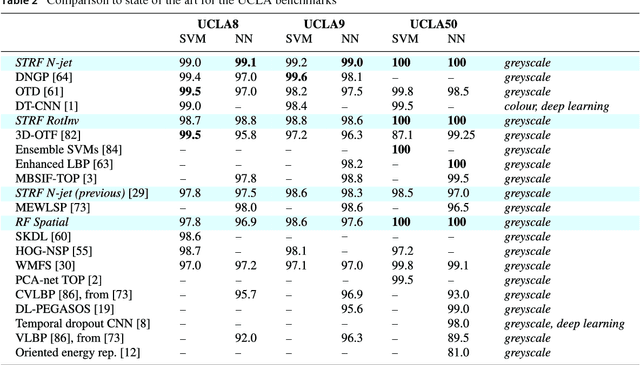
This work presents a first evaluation of using spatio-temporal receptive fields from a recently proposed time-causal spatio-temporal scale-space framework as primitives for video analysis. We propose a new family of video descriptors based on regional statistics of spatio-temporal receptive field responses and evaluate this approach on the problem of dynamic texture recognition. Our approach generalises a previously used method, based on joint histograms of receptive field responses, from the spatial to the spatio-temporal domain and from object recognition to dynamic texture recognition. The time-recursive formulation enables computationally efficient time-causal recognition. The experimental evaluation demonstrates competitive performance compared to state-of-the-art. Especially, it is shown that binary versions of our dynamic texture descriptors achieve improved performance compared to a large range of similar methods using different primitives either handcrafted or learned from data. Further, our qualitative and quantitative investigation into parameter choices and the use of different sets of receptive fields highlights the robustness and flexibility of our approach. Together, these results support the descriptive power of this family of time-causal spatio-temporal receptive fields, validate our approach for dynamic texture recognition and point towards the possibility of designing a range of video analysis methods based on these new time-causal spatio-temporal primitives.
* 29 pages, 16 figures
The UCR Time Series Archive
Oct 17, 2018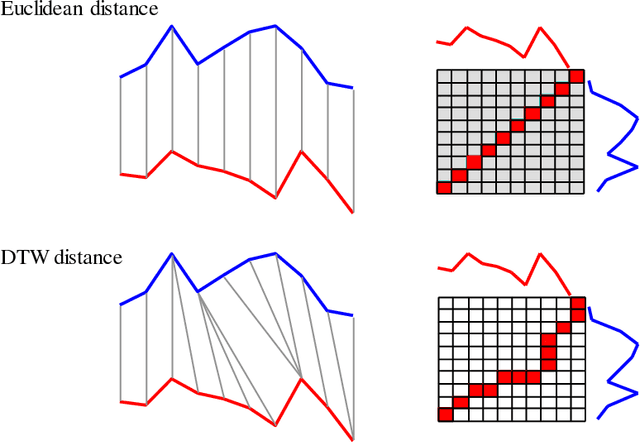
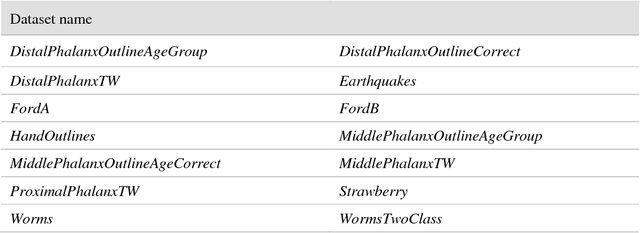
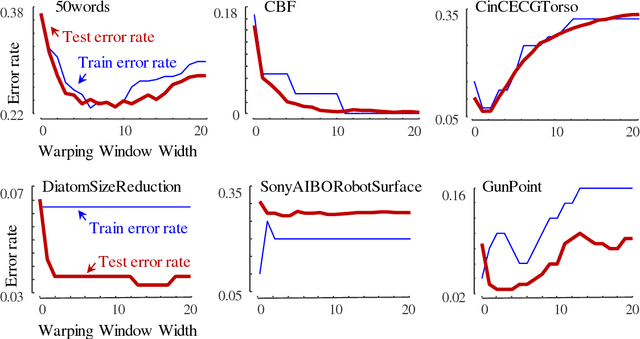
The UCR Time Series Archive - introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.
Anomaly Detection for High-Dimensional Data Using Large Deviations Principle
Sep 28, 2021
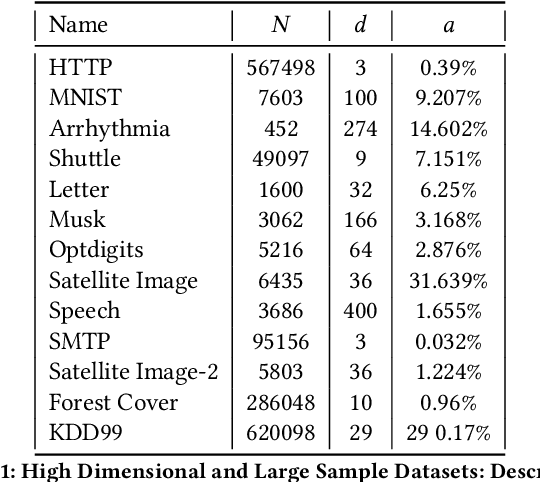
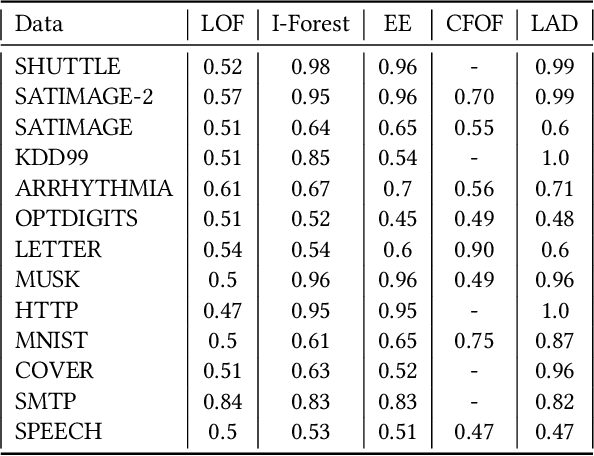

Most current anomaly detection methods suffer from the curse of dimensionality when dealing with high-dimensional data. We propose an anomaly detection algorithm that can scale to high-dimensional data using concepts from the theory of large deviations. The proposed Large Deviations Anomaly Detection (LAD) algorithm is shown to outperform state of art anomaly detection methods on a variety of large and high-dimensional benchmark data sets. Exploiting the ability of the algorithm to scale to high-dimensional data, we propose an online anomaly detection method to identify anomalies in a collection of multivariate time series. We demonstrate the applicability of the online algorithm in identifying counties in the United States with anomalous trends in terms of COVID-19 related cases and deaths. Several of the identified anomalous counties correlate with counties with documented poor response to the COVID pandemic.