 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Existence, uniqueness, and convergence rates for gradient flows in the training of artificial neural networks with ReLU activation
Aug 18, 2021
The training of artificial neural networks (ANNs) with rectified linear unit (ReLU) activation via gradient descent (GD) type optimization schemes is nowadays a common industrially relevant procedure. Till this day in the scientific literature there is in general no mathematical convergence analysis which explains the numerical success of GD type optimization schemes in the training of ANNs with ReLU activation. GD type optimization schemes can be regarded as temporal discretization methods for the gradient flow (GF) differential equations associated to the considered optimization problem and, in view of this, it seems to be a natural direction of research to first aim to develop a mathematical convergence theory for time-continuous GF differential equations and, thereafter, to aim to extend such a time-continuous convergence theory to implementable time-discrete GD type optimization methods. In this article we establish two basic results for GF differential equations in the training of fully-connected feedforward ANNs with one hidden layer and ReLU activation. In the first main result of this article we establish in the training of such ANNs under the assumption that the probability distribution of the input data of the considered supervised learning problem is absolutely continuous with a bounded density function that every GF differential equation admits for every initial value a solution which is also unique among a suitable class of solutions. In the second main result of this article we prove in the training of such ANNs under the assumption that the target function and the density function of the probability distribution of the input data are piecewise polynomial that every non-divergent GF trajectory converges with an appropriate rate of convergence to a critical point and that the risk of the non-divergent GF trajectory converges with rate 1 to the risk of the critical point.
Gradient-free optimization of chaotic acoustics with reservoir computing
Jun 17, 2021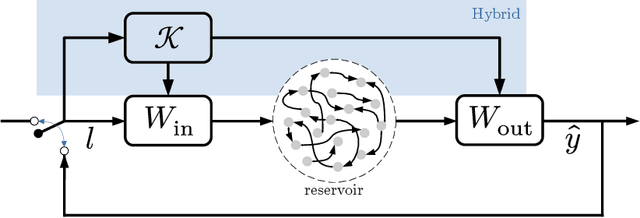
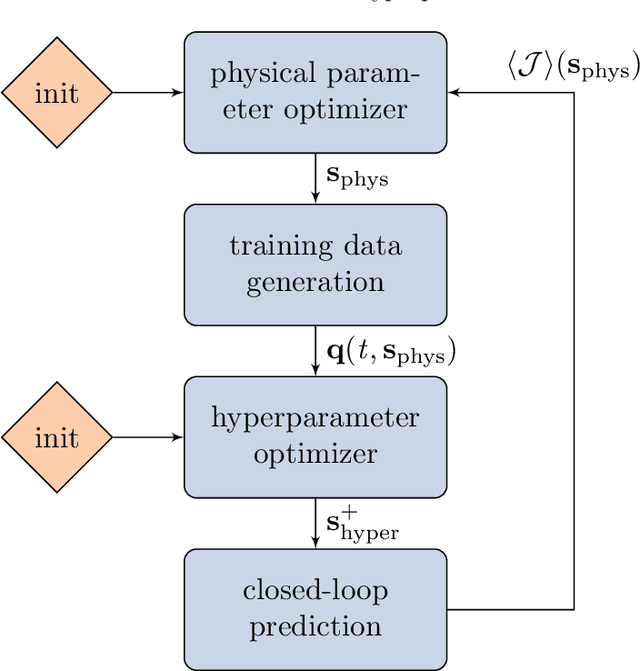
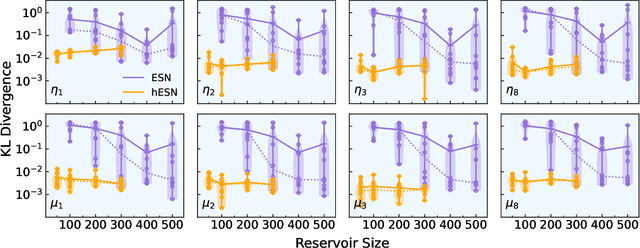
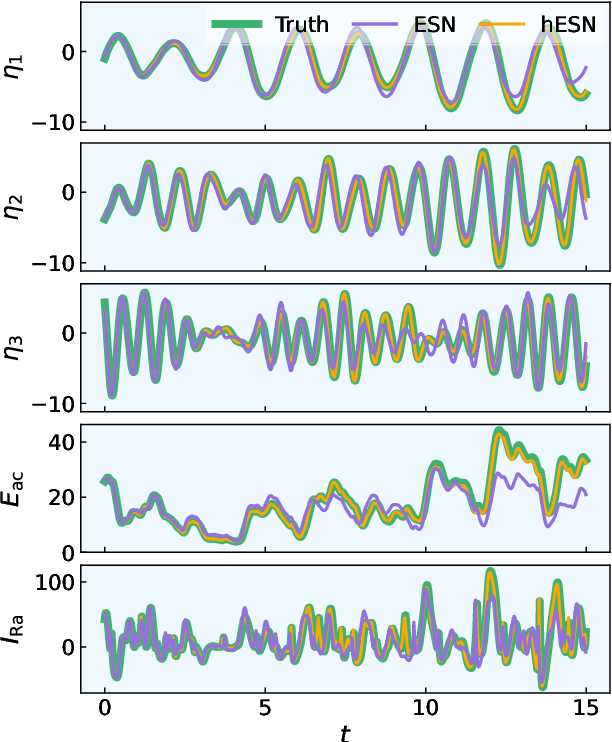
We develop a versatile optimization method, which finds the design parameters that minimize time-averaged acoustic cost functionals. The method is gradient-free, model-informed, and data-driven with reservoir computing based on echo state networks. First, we analyse the predictive capabilities of echo state networks both in the short- and long-time prediction of the dynamics. We find that both fully data-driven and model-informed architectures learn the chaotic acoustic dynamics, both time-accurately and statistically. Informing the training with a physical reduced-order model with one acoustic mode markedly improves the accuracy and robustness of the echo state networks, whilst keeping the computational cost low. Echo state networks offer accurate predictions of the long-time dynamics, which would be otherwise expensive by integrating the governing equations to evaluate the time-averaged quantity to optimize. Second, we couple echo state networks with a Bayesian technique to explore the design thermoacoustic parameter space. The computational method is minimally intrusive. Third, we find the set of flame parameters that minimize the time-averaged acoustic energy of chaotic oscillations, which are caused by the positive feedback with a heat source, such as a flame in gas turbines or rocket motors. These oscillations are known as thermoacoustic oscillations. The optimal set of flame parameters is found with the same accuracy as brute-force grid search, but with a convergence rate that is more than one order of magnitude faster. This work opens up new possibilities for non-intrusive (``hands-off'') optimization of chaotic systems, in which the cost of generating data, for example from high-fidelity simulations and experiments, is high.
Teaching Models new APIs: Domain-Agnostic Simulators for Task Oriented Dialogue
Oct 13, 2021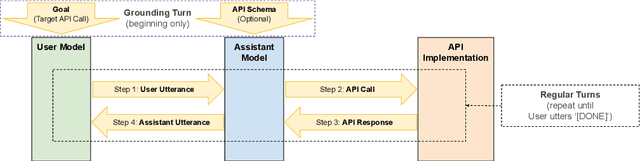
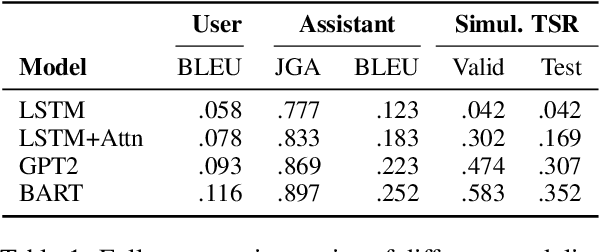
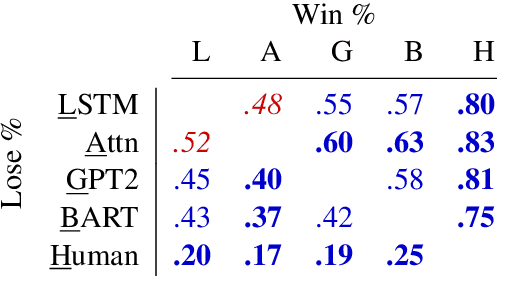
We demonstrate that large language models are able to simulate Task Oriented Dialogues in novel domains, provided only with an API implementation and a list of goals. We show these simulations can formulate online, automatic metrics that correlate well with human evaluations. Furthermore, by checking for whether the User's goals are met, we can use simulation to repeatedly generate training data and improve the quality of simulations themselves. With no human intervention or domain-specific training data, our simulations bootstrap end-to-end models which achieve a 37\% error reduction in previously unseen domains. By including as few as 32 domain-specific conversations, bootstrapped models can match the performance of a fully-supervised model with $10\times$ more data. To our knowledge, this is the first time simulations have been shown to be effective at bootstrapping models without explicitly requiring any domain-specific training data, rule-engineering, or humans-in-the-loop.
Geometry-informed irreversible perturbations for accelerated convergence of Langevin dynamics
Aug 18, 2021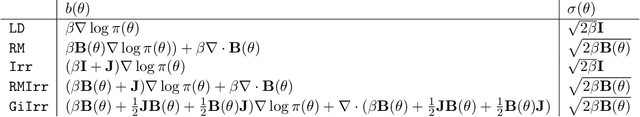
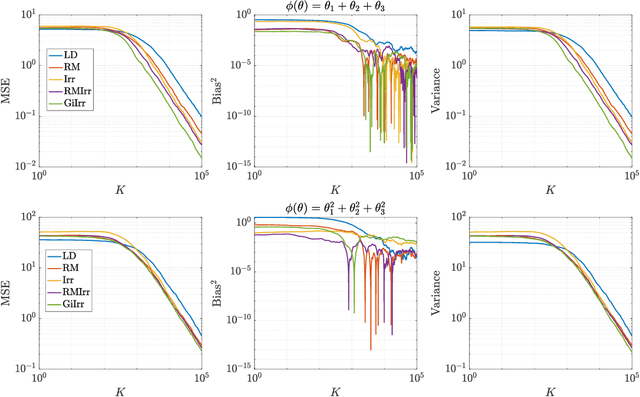
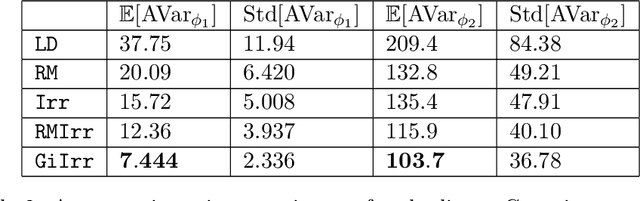
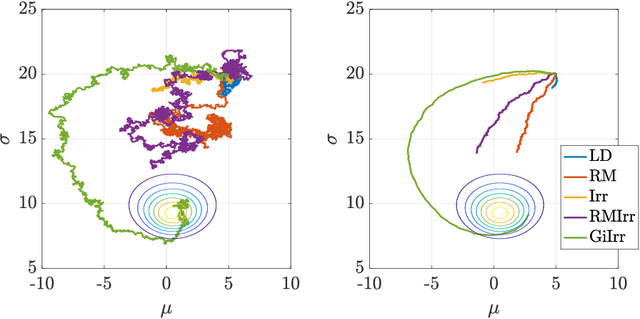
We introduce a novel geometry-informed irreversible perturbation that accelerates convergence of the Langevin algorithm for Bayesian computation. It is well documented that there exist perturbations to the Langevin dynamics that preserve its invariant measure while accelerating its convergence. Irreversible perturbations and reversible perturbations (such as Riemannian manifold Langevin dynamics (RMLD)) have separately been shown to improve the performance of Langevin samplers. We consider these two perturbations simultaneously by presenting a novel form of irreversible perturbation for RMLD that is informed by the underlying geometry. Through numerical examples, we show that this new irreversible perturbation can improve performance of the estimator over reversible perturbations that do not take the geometry into account. Moreover we demonstrate that irreversible perturbations generally can be implemented in conjunction with the stochastic gradient version of the Langevin algorithm. Lastly, while continuous-time irreversible perturbations cannot impair the performance of a Langevin estimator, the situation can sometimes be more complicated when discretization is considered. To this end, we describe a discrete-time example in which irreversibility increases both the bias and variance of the resulting estimator.
Physics Informed Machine Learning of SPH: Machine Learning Lagrangian Turbulence
Oct 25, 2021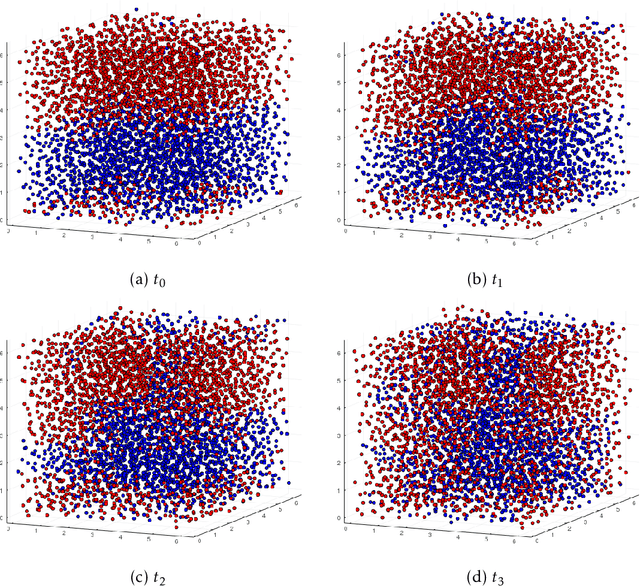
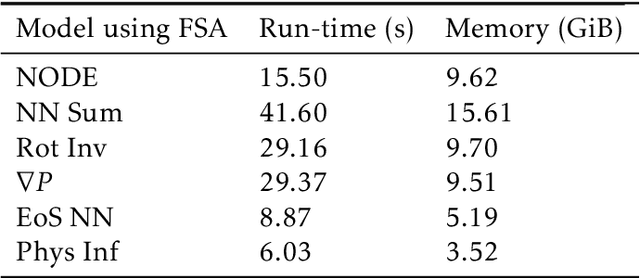
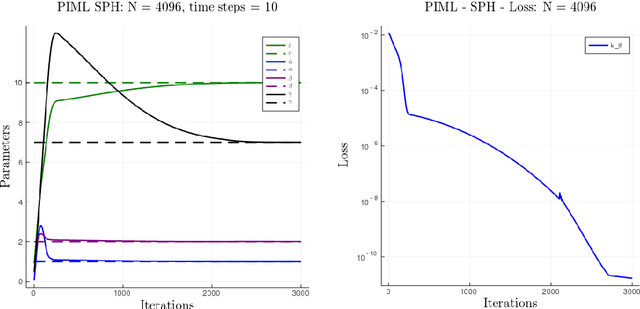
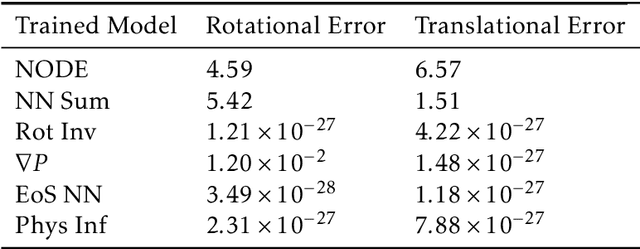
Smoothed particle hydrodynamics (SPH) is a mesh-free Lagrangian method for obtaining approximate numerical solutions of the equations of fluid dynamics; which has been widely applied to weakly- and strongly compressible turbulence in astrophysics and engineering applications. We present a learn-able hierarchy of parameterized and "physics-explainable" SPH informed fluid simulators using both physics based parameters and Neural Networks (NNs) as universal function approximators. Our learning algorithm develops a mixed mode approach, mixing forward and reverse mode automatic differentiation with forward and adjoint based sensitivity analyses to efficiently perform gradient based optimization. We show that our physics informed learning method is capable of: (a) solving inverse problems over the physically interpretable parameter space, as well as over the space of NN parameters; (b) learning Lagrangian statistics of turbulence (interpolation); (c) combining Lagrangian trajectory based, probabilistic, and Eulerian field based loss functions; and (d) extrapolating beyond training sets into more complex regimes of interest. Furthermore, this hierarchy of models gradually introduces more physical structure, which we show improves interpretability, generalizability (over larger ranges of time scales and Reynolds numbers), preservation of physical symmetries, and requires less training data.
AW-Opt: Learning Robotic Skills with Imitation andReinforcement at Scale
Nov 09, 2021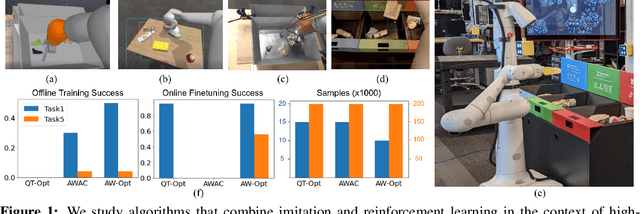
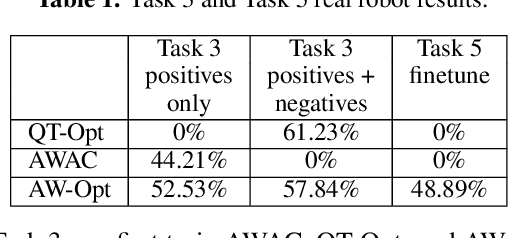
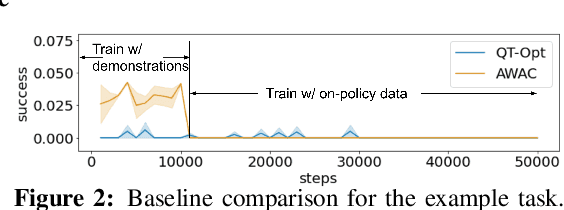
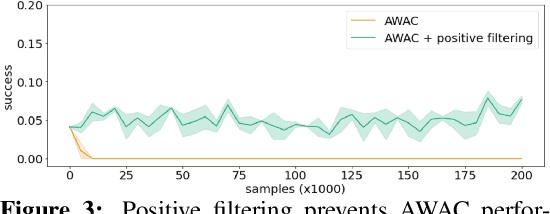
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021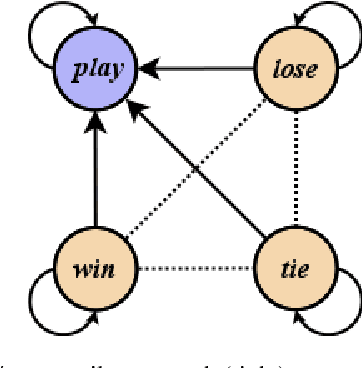
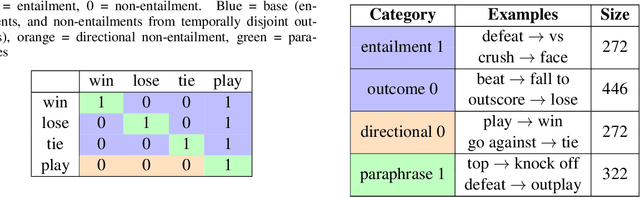
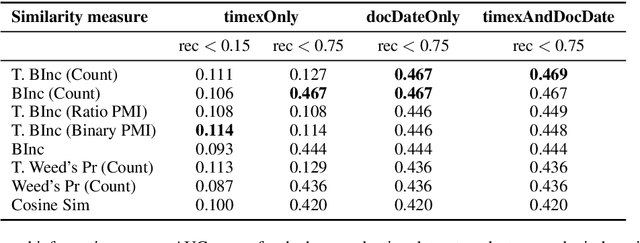
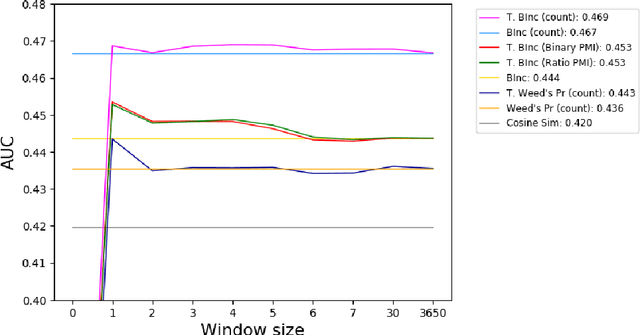
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021
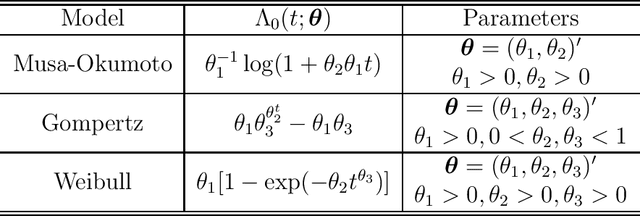
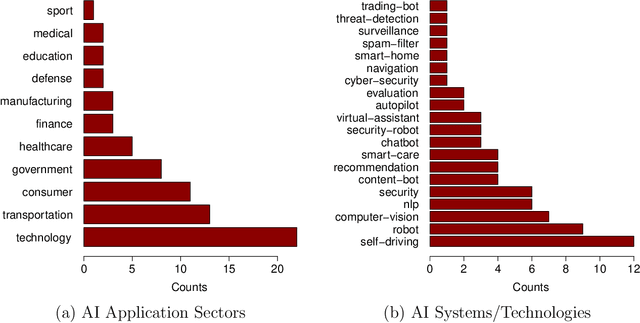
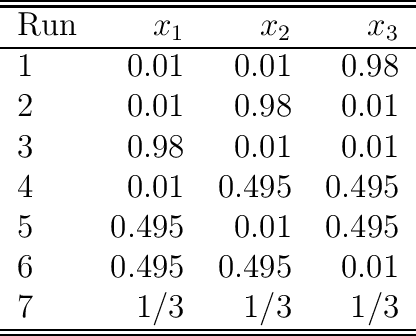
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
Financial Time Series Forecasting with Deep Learning : A Systematic Literature Review: 2005-2019
Nov 29, 2019
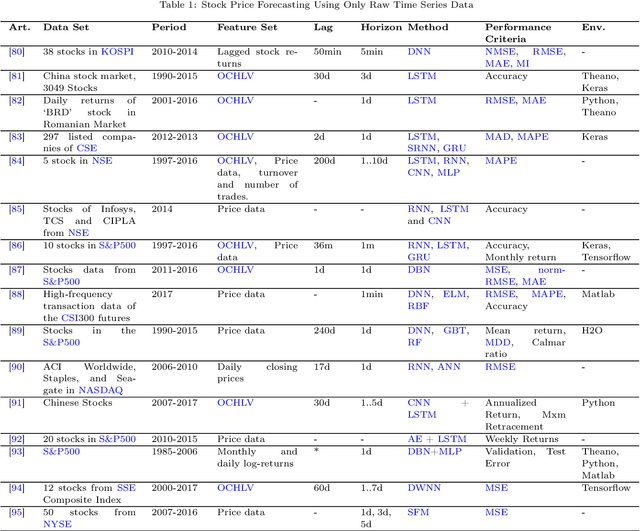

Financial time series forecasting is, without a doubt, the top choice of computational intelligence for finance researchers from both academia and financial industry due to its broad implementation areas and substantial impact. Machine Learning (ML) researchers came up with various models and a vast number of studies have been published accordingly. As such, a significant amount of surveys exist covering ML for financial time series forecasting studies. Lately, Deep Learning (DL) models started appearing within the field, with results that significantly outperform traditional ML counterparts. Even though there is a growing interest in developing models for financial time series forecasting research, there is a lack of review papers that were solely focused on DL for finance. Hence, our motivation in this paper is to provide a comprehensive literature review on DL studies for financial time series forecasting implementations. We not only categorized the studies according to their intended forecasting implementation areas, such as index, forex, commodity forecasting, but also grouped them based on their DL model choices, such as Convolutional Neural Networks (CNNs), Deep Belief Networks (DBNs), Long-Short Term Memory (LSTM). We also tried to envision the future for the field by highlighting the possible setbacks and opportunities, so the interested researchers can benefit.
Memory visualization tool for training neural network
Oct 25, 2021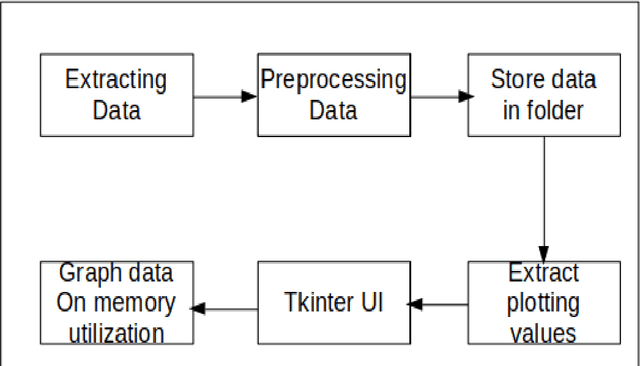
Software developed helps world a better place ranging from system software, open source, application software and so on. Software engineering does have neural network models applied to code suggestion, bug report summarizing and so on to demonstrate their effectiveness at a real SE task. Software and machine learning algorithms combine to make software give better solutions and understanding of environment. In software, there are both generalized applications which helps solve problems for entire world and also some specific applications which helps one particular community. To address the computational challenge in deep learning, many tools exploit hardware features such as multi-core CPUs and many-core GPUs to shorten the training time. Machine learning algorithms have a greater impact in the world but there is a considerable amount of memory utilization during the process. We propose a new tool for analysis of memory utilized for developing and training deep learning models. Our tool results in visual utilization of memory concurrently. Various parameters affecting the memory utilization are analysed while training. This tool helps in knowing better idea of processes or models which consumes more memory.