 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse Progressive Distillation: Resolving Overfitting under Pretrain-and-Finetune Paradigm
Oct 18, 2021
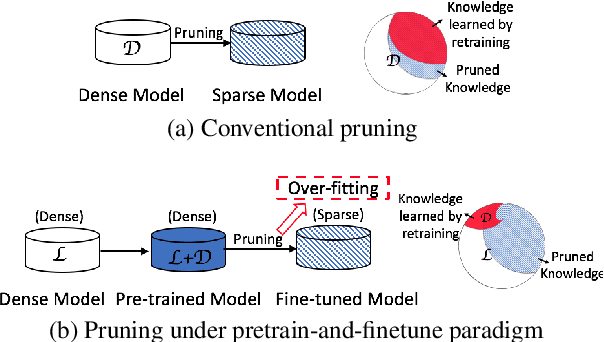
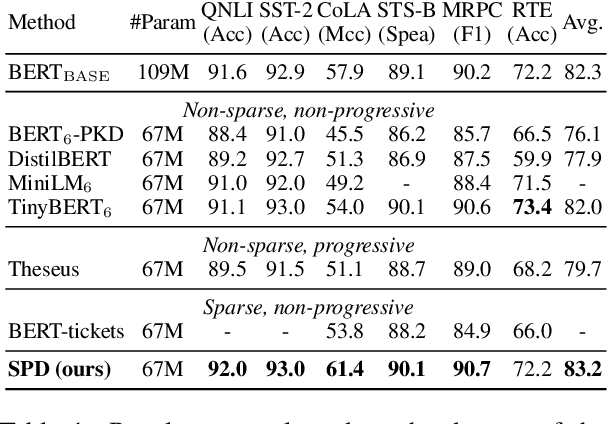
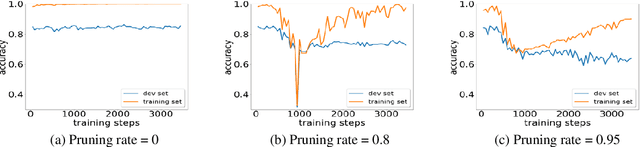
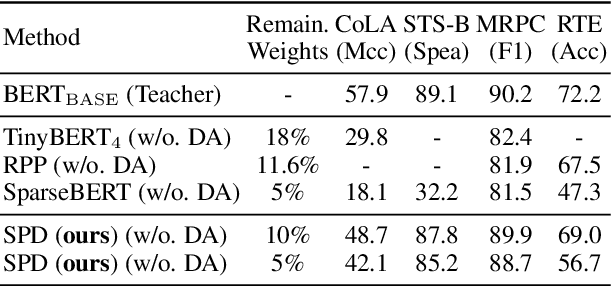
Various pruning approaches have been proposed to reduce the footprint requirements of Transformer-based language models. Conventional wisdom is that pruning reduces the model expressiveness and thus is more likely to underfit than overfit compared to the original model. However, under the trending pretrain-and-finetune paradigm, we argue that pruning increases the risk of overfitting if pruning was performed at the fine-tuning phase, as it increases the amount of information a model needs to learn from the downstream task, resulting in relative data deficiency. In this paper, we aim to address the overfitting issue under the pretrain-and-finetune paradigm to improve pruning performance via progressive knowledge distillation (KD) and sparse pruning. Furthermore, to mitigate the interference between different strategies of learning rate, pruning and distillation, we propose a three-stage learning framework. We show for the first time that reducing the risk of overfitting can help the effectiveness of pruning under the pretrain-and-finetune paradigm. Experiments on multiple datasets of GLUE benchmark show that our method achieves highly competitive pruning performance over the state-of-the-art competitors across different pruning ratio constraints.
Inference for Network Structure and Dynamics from Time Series Data via Graph Neural Network
Jan 18, 2020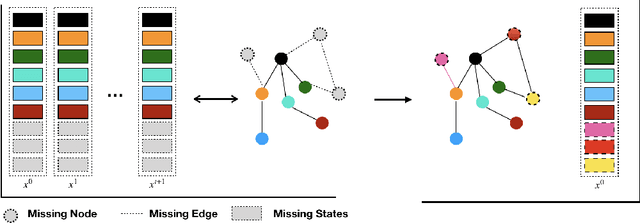
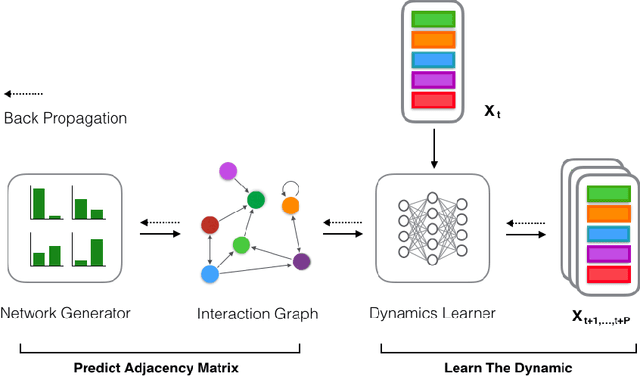
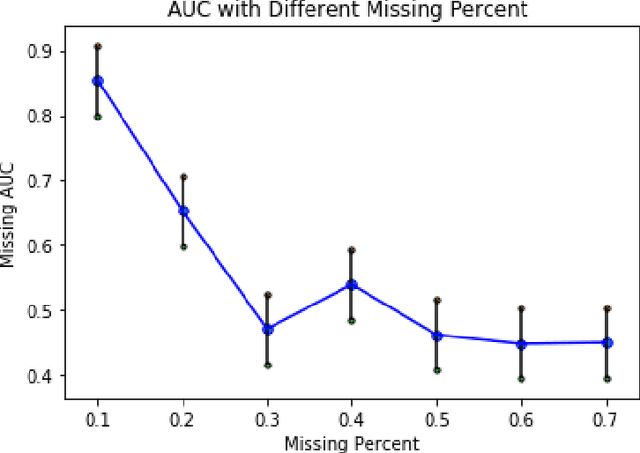
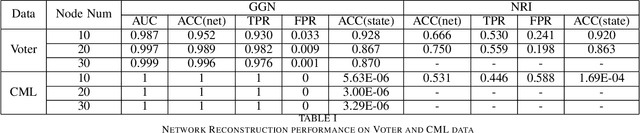
Network structures in various backgrounds play important roles in social, technological, and biological systems. However, the observable network structures in real cases are often incomplete or unavailable due to measurement errors or private protection issues. Therefore, inferring the complete network structure is useful for understanding complex systems. The existing studies have not fully solved the problem of inferring network structure with partial or no information about connections or nodes. In this paper, we tackle the problem by utilizing time series data generated by network dynamics. We regard the network inference problem based on dynamical time series data as a problem of minimizing errors for predicting future states and proposed a novel data-driven deep learning model called Gumbel Graph Network (GGN) to solve the two kinds of network inference problems: Network Reconstruction and Network Completion. For the network reconstruction problem, the GGN framework includes two modules: the dynamics learner and the network generator. For the network completion problem, GGN adds a new module called the States Learner to infer missing parts of the network. We carried out experiments on discrete and continuous time series data. The experiments show that our method can reconstruct up to 100% network structure on the network reconstruction task. While the model can also infer the unknown parts of the structure with up to 90% accuracy when some nodes are missing. And the accuracy decays with the increase of the fractions of missing nodes. Our framework may have wide application areas where the network structure is hard to obtained and the time series data is rich.
Amortized Tree Generation for Bottom-up Synthesis Planning and Synthesizable Molecular Design
Oct 12, 2021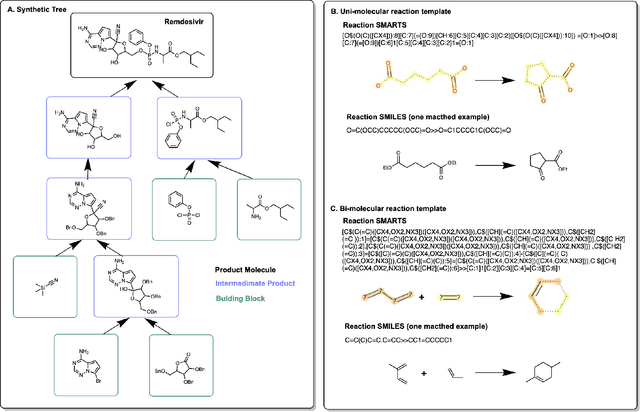

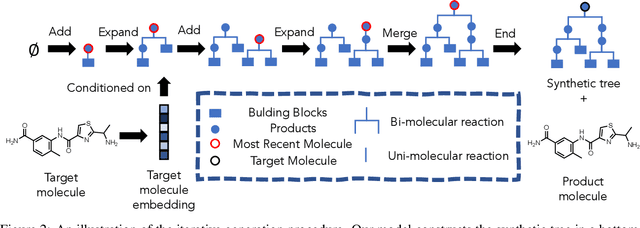

Molecular design and synthesis planning are two critical steps in the process of molecular discovery that we propose to formulate as a single shared task of conditional synthetic pathway generation. We report an amortized approach to generate synthetic pathways as a Markov decision process conditioned on a target molecular embedding. This approach allows us to conduct synthesis planning in a bottom-up manner and design synthesizable molecules by decoding from optimized conditional codes, demonstrating the potential to solve both problems of design and synthesis simultaneously. The approach leverages neural networks to probabilistically model the synthetic trees, one reaction step at a time, according to reactivity rules encoded in a discrete action space of reaction templates. We train these networks on hundreds of thousands of artificial pathways generated from a pool of purchasable compounds and a list of expert-curated templates. We validate our method with (a) the recovery of molecules using conditional generation, (b) the identification of synthesizable structural analogs, and (c) the optimization of molecular structures given oracle functions relevant to drug discovery.
Time Series Source Separation using Dynamic Mode Decomposition
Mar 04, 2019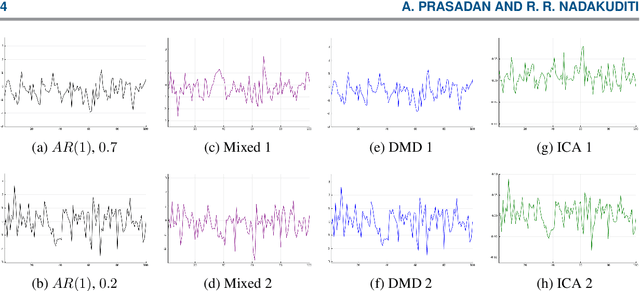

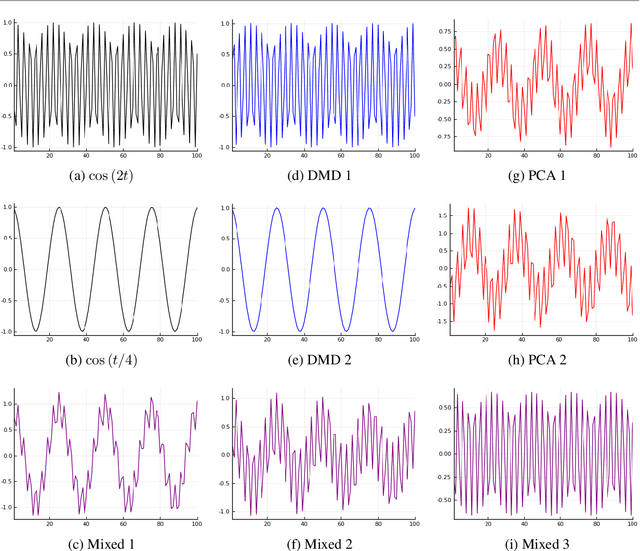
The dynamic mode decomposition (DMD) extracted dynamic modes are the non-orthogonal eigenvectors of the matrix that best approximates the one-step temporal evolution of the multivariate samples. In the context of dynamic system analysis, the extracted dynamic modes are a generalization of global stability modes. We apply DMD to a data matrix whose rows are linearly independent, additive mixtures of latent time series. We show that when the latent time series are uncorrelated at a lag of one time-step then, in the large sample limit, the recovered dynamic modes will approximate, up to a column-wise normalization, the columns of the mixing matrix. Thus, DMD is a time series blind source separation algorithm in disguise, but is different from closely related second order algorithms such as SOBI and AMUSE. All can unmix mixed ergodic Gaussian time series in a way that ICA fundamentally cannot. We use our insights on single lag DMD to develop a higher-lag extension, analyze the finite sample performance with and without randomly missing data, and identify settings where the higher lag variant can outperform the conventional single lag variant. We validate our results with numerical simulations, and highlight how DMD can be used in change point detection.
RF-Net: a Unified Meta-learning Framework for RF-enabled One-shot Human Activity Recognition
Oct 29, 2021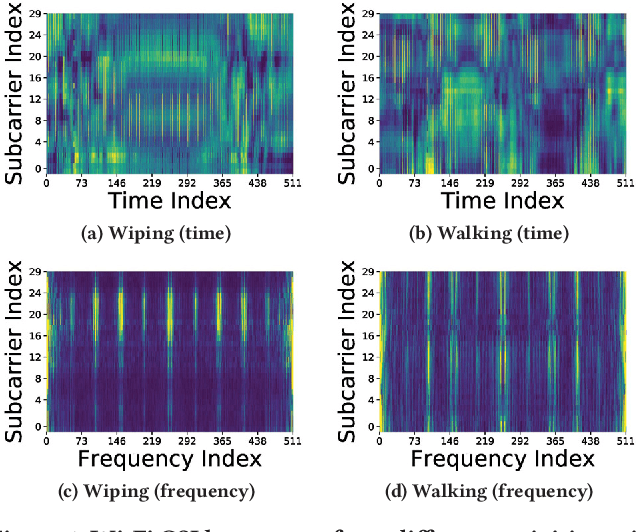
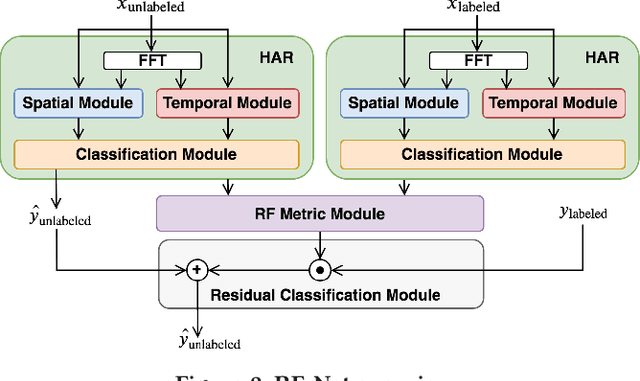

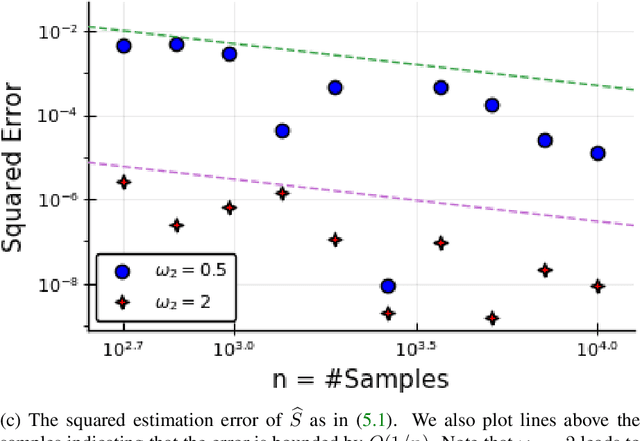
Radio-Frequency (RF) based device-free Human Activity Recognition (HAR) rises as a promising solution for many applications. However, device-free (or contactless) sensing is often more sensitive to environment changes than device-based (or wearable) sensing. Also, RF datasets strictly require on-line labeling during collection, starkly different from image and text data collections where human interpretations can be leveraged to perform off-line labeling. Therefore, existing solutions to RF-HAR entail a laborious data collection process for adapting to new environments. To this end, we propose RF-Net as a meta-learning based approach to one-shot RF-HAR; it reduces the labeling efforts for environment adaptation to the minimum level. In particular, we first examine three representative RF sensing techniques and two major meta-learning approaches. The results motivate us to innovate in two designs: i) a dual-path base HAR network, where both time and frequency domains are dedicated to learning powerful RF features including spatial and attention-based temporal ones, and ii) a metric-based meta-learning framework to enhance the fast adaption capability of the base network, including an RF-specific metric module along with a residual classification module. We conduct extensive experiments based on all three RF sensing techniques in multiple real-world indoor environments; all results strongly demonstrate the efficacy of RF-Net compared with state-of-the-art baselines.
* 14 pages
LATTE: LSTM Self-Attention based Anomaly Detection in Embedded Automotive Platforms
Jul 12, 2021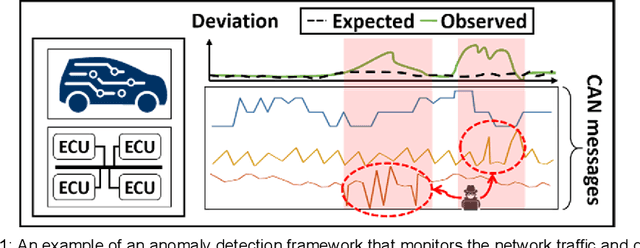

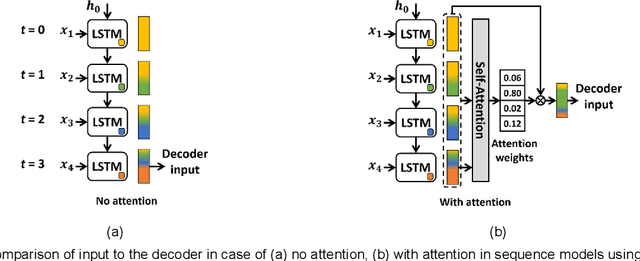

Modern vehicles can be thought of as complex distributed embedded systems that run a variety of automotive applications with real-time constraints. Recent advances in the automotive industry towards greater autonomy are driving vehicles to be increasingly connected with various external systems (e.g., roadside beacons, other vehicles), which makes emerging vehicles highly vulnerable to cyber-attacks. Additionally, the increased complexity of automotive applications and the in-vehicle networks results in poor attack visibility, which makes detecting such attacks particularly challenging in automotive systems. In this work, we present a novel anomaly detection framework called LATTE to detect cyber-attacks in Controller Area Network (CAN) based networks within automotive platforms. Our proposed LATTE framework uses a stacked Long Short Term Memory (LSTM) predictor network with novel attention mechanisms to learn the normal operating behavior at design time. Subsequently, a novel detection scheme (also trained at design time) is used to detect various cyber-attacks (as anomalies) at runtime. We evaluate our proposed LATTE framework under different automotive attack scenarios and present a detailed comparison with the best-known prior works in this area, to demonstrate the potential of our approach.
LSAR: Efficient Leverage Score Sampling Algorithm for the Analysis of Big Time Series Data
Nov 27, 2019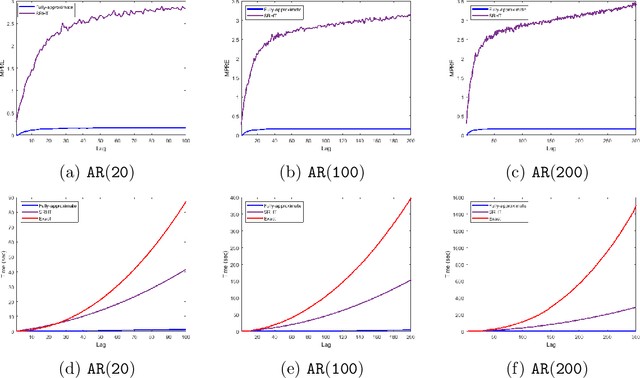
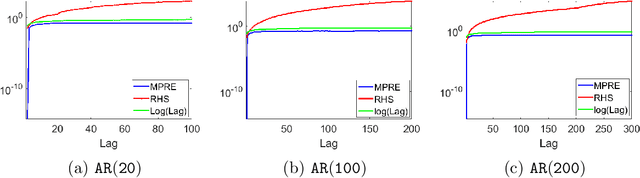
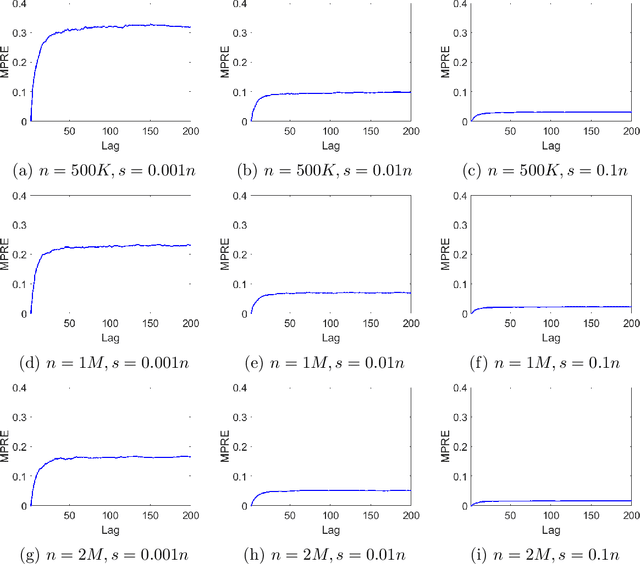
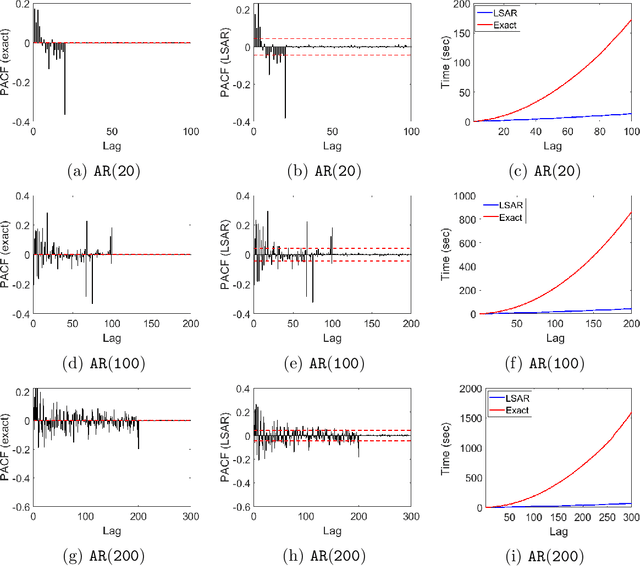
We apply methods from randomized numerical linear algebra (RandNLA) to develop improved algorithms for the analysis of large-scale time series data. We first develop a new fast algorithm to estimate the leverage scores of an autoregressive (AR) model in big data regimes. We show that the accuracy of approximations lies within $(1+\mathcal{O}(\varepsilon))$ of the true leverage scores with high probability. These theoretical results are subsequently exploited to develop an efficient algorithm, called LSAR, for fitting an appropriate AR model to big time series data. Our proposed algorithm is guaranteed, with high probability, to find the maximum likelihood estimates of the parameters of the underlying true AR model and has a worst case running time that significantly improves those of the state-of-the-art alternatives in big data regimes. Empirical results on large-scale synthetic as well as real data highly support the theoretical results and reveal the efficacy of this new approach. To the best of our knowledge, this paper is the first attempt to establish a nexus between RandNLA and big time series data analysis.
Short-term traffic prediction using physics-aware neural networks
Sep 21, 2021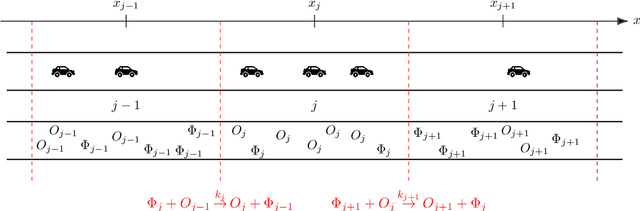
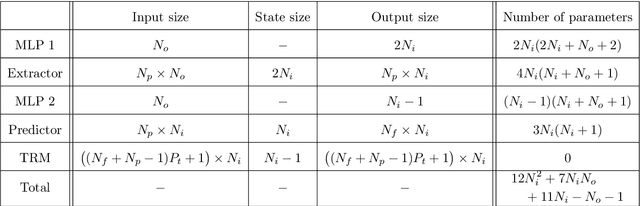
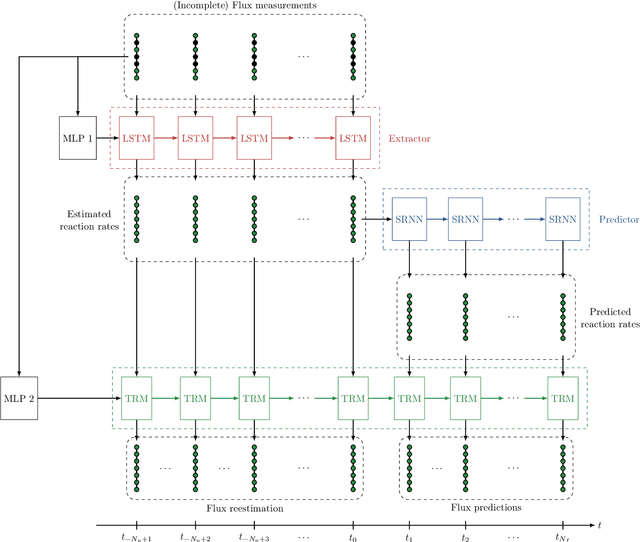
In this work, we propose an algorithm performing short-term predictions of the flux of vehicles on a stretch of road, using past measurements of the flux. This algorithm is based on a physics-aware recurrent neural network. A discretization of a macroscopic traffic flow model (using the so-called Traffic Reaction Model) is embedded in the architecture of the network and yields flux predictions based on estimated and predicted space-time dependent traffic parameters. These parameters are themselves obtained using a succession of LSTM ans simple recurrent neural networks. Besides, on top of the predictions, the algorithm yields a smoothing of its inputs which is also physically-constrained by the macroscopic traffic flow model. The algorithm is tested on raw flux measurements obtained from loop detectors.
Learning to Forecast Dynamical Systems from Streaming Data
Sep 21, 2021
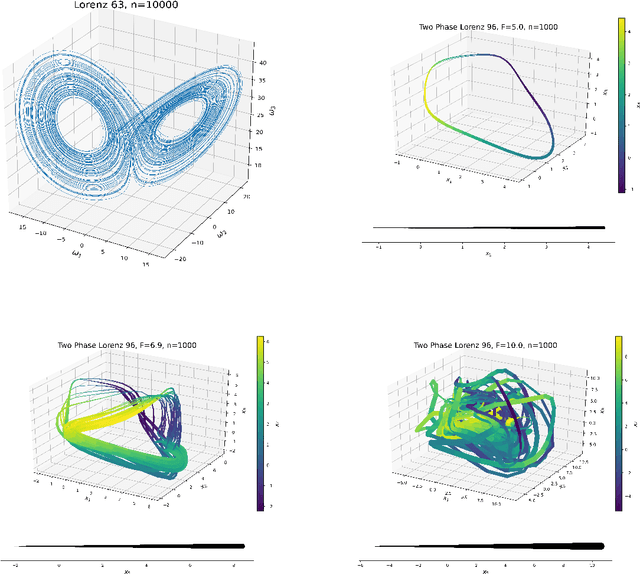
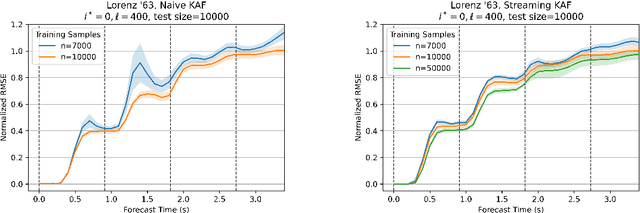

Kernel analog forecasting (KAF) is a powerful methodology for data-driven, non-parametric forecasting of dynamically generated time series data. This approach has a rigorous foundation in Koopman operator theory and it produces good forecasts in practice, but it suffers from the heavy computational costs common to kernel methods. This paper proposes a streaming algorithm for KAF that only requires a single pass over the training data. This algorithm dramatically reduces the costs of training and prediction without sacrificing forecasting skill. Computational experiments demonstrate that the streaming KAF method can successfully forecast several classes of dynamical systems (periodic, quasi-periodic, and chaotic) in both data-scarce and data-rich regimes. The overall methodology may have wider interest as a new template for streaming kernel regression.
An Accurate Smartphone Battery Parameter Calibration Using Unscented Kalman Filter
Oct 06, 2021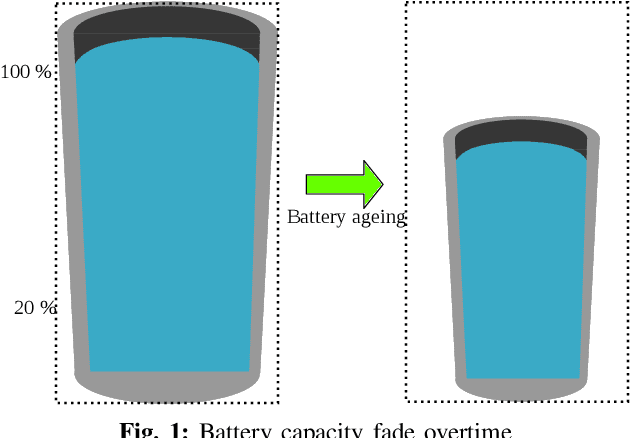
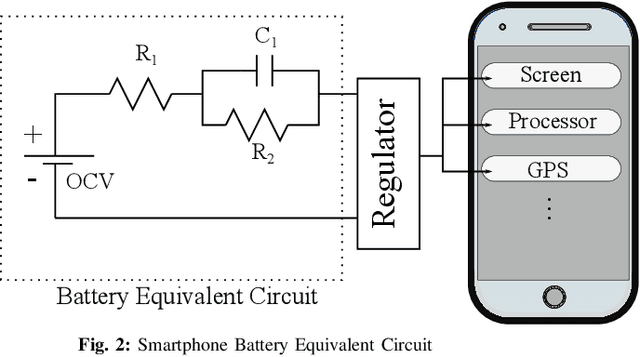
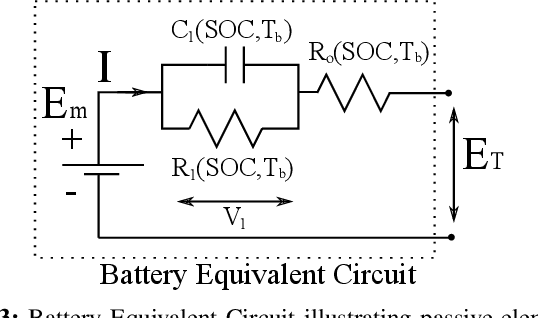
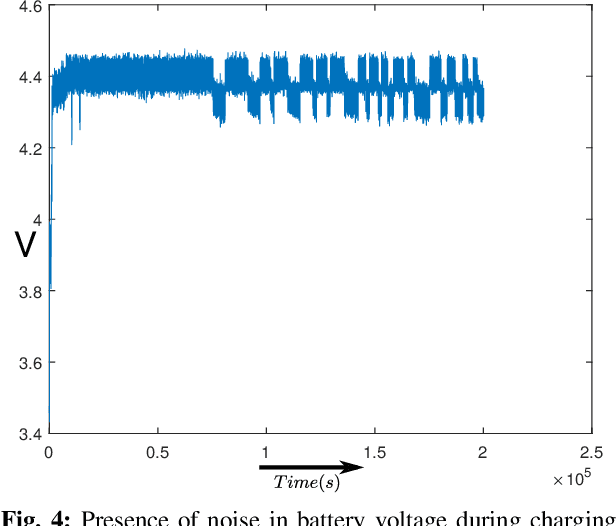
Internet of Things (IoT) applications have opened up numerous possibilities to improve our lives. Most of the remote devices, part of the IoT network, such as smartphones, data loggers and wireless sensors are battery powered. It is vital to collect battery measurement data (Voltage or State-of-Charge (SOC)) from these remote devices. Presence of noise in these measurements restricts effective utilization of this dataset. This paper presents the application of Unscented Kalman Filter (UKF) to mitigate measurement noise in smartphone dataset. The simplicity of this technique makes it a constructive approach for noise removal. The datasets obtained after noise removal could be used to improve data-driven time series forecasting models which aid to accurately estimate critical battery parameters such as SOC. UKF was tested on noisy charge and discharge dataset of a smartphone. An overall Mean Squared Error (MSE) of 0.0017 and 0.0010 was obtained for Voltage charge and discharge measurements. MSE for SOC charge and discharge data measurements were 0.0018 and 0.0010 respectively.