 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-Memory End-to-End Training for Iterative Joint Speech Dereverberation and Separation with A Neural Source Model
Oct 13, 2021
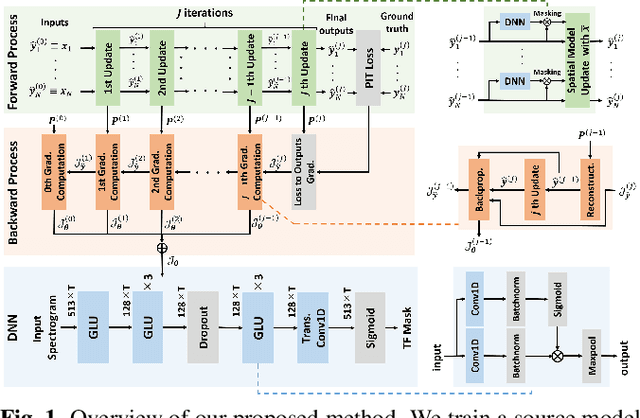

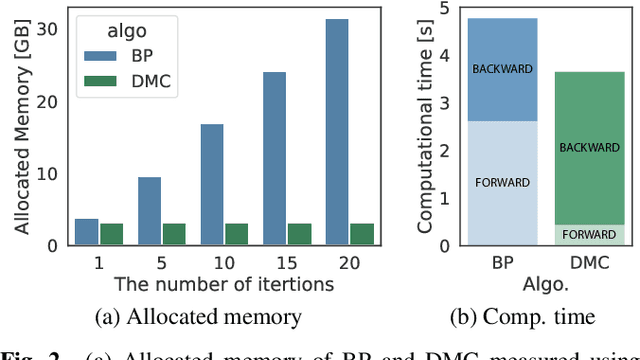
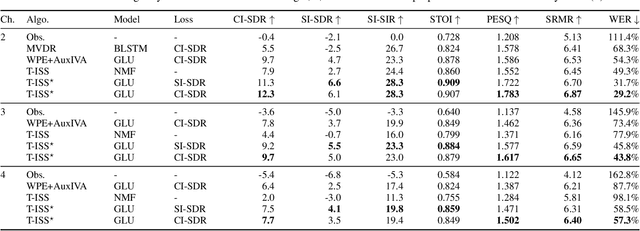
We propose an end-to-end framework for training iterative multi-channel joint dereverberation and source separation with a neural source model. We combine the unified dereverberation and separation update equations of ILRMA-T with a deep neural network (DNN) serving as source model. The weights of the model are directly trained by gradient descent with a permutation invariant loss on the output time-domain signals. One drawback of this approach is that backpropagation consumes memory linearly in the number of iterations. This severely limits the number of iterations, channels, or signal lengths that can be used during training. We introduce demixing matrix checkpointing to bypass this problem, a new technique that reduces the total memory cost to that of a single iteration. In experiments, we demonstrate that the introduced framework results in high-performance in terms of conventional speech quality metrics and word error rate. Furthermore, it generalizes to number of channels unseen during training.
Learning interaction rules from multi-animal trajectories via augmented behavioral models
Jul 14, 2021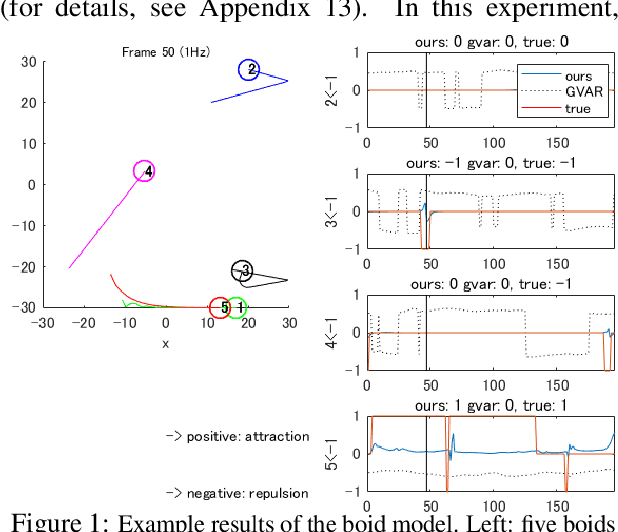
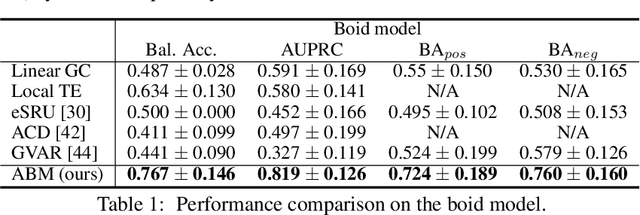
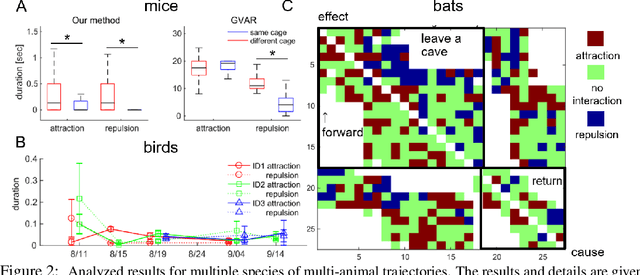
Extracting the interaction rules of biological agents from moving sequences pose challenges in various domains. Granger causality is a practical framework for analyzing the interactions from observed time-series data; however, this framework ignores the structures of the generative process in animal behaviors, which may lead to interpretational problems and sometimes erroneous assessments of causality. In this paper, we propose a new framework for learning Granger causality from multi-animal trajectories via augmented theory-based behavioral models with interpretable data-driven models. We adopt an approach for augmenting incomplete multi-agent behavioral models described by time-varying dynamical systems with neural networks. For efficient and interpretable learning, our model leverages theory-based architectures separating navigation and motion processes, and the theory-guided regularization for reliable behavioral modeling. This can provide interpretable signs of Granger-causal effects over time, i.e., when specific others cause the approach or separation. In experiments using synthetic datasets, our method achieved better performance than various baselines. We then analyzed multi-animal datasets of mice, flies, birds, and bats, which verified our method and obtained novel biological insights.
Optimizing Sparse Matrix Multiplications for Graph Neural Networks
Oct 30, 2021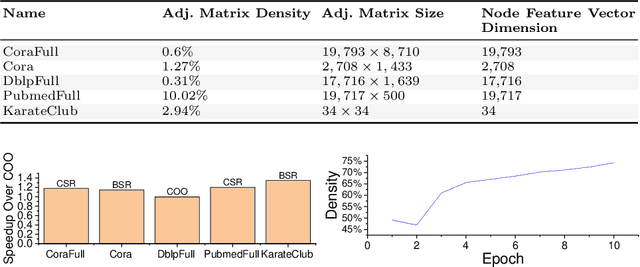
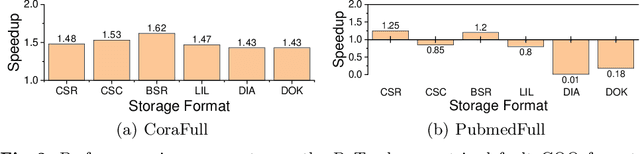
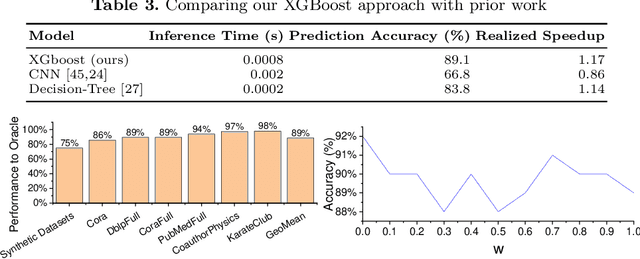

Graph neural networks (GNNs) are emerging as a powerful technique for modeling graph structures. Due to the sparsity of real-world graph data, GNN performance is limited by extensive sparse matrix multiplication (SpMM) operations involved in computation. While the right sparse matrix storage format varies across input data, existing deep learning frameworks employ a single, static storage format, leaving much room for improvement. This paper investigates how the choice of sparse matrix storage formats affect the GNN performance. We observe that choosing a suitable sparse matrix storage format can significantly improve the GNN training performance, but the right format depends on the input workloads and can change as the GNN iterates over the input graph. We then develop a predictive model to dynamically choose a sparse matrix storage format to be used by a GNN layer based on the input matrices. Our model is first trained offline using training matrix samples, and the trained model can be applied to any input matrix and GNN kernels with SpMM computation. We implement our approach on top of PyTorch and apply it to 5 representative GNN models running on a multi-core CPU using real-life and synthetic datasets. Experimental results show that our approach gives an average speedup of 1.17x (up to 3x) for GNN running time.
Risk Measurement, Risk Entropy, and Autonomous Driving Risk Modeling
Sep 15, 2021


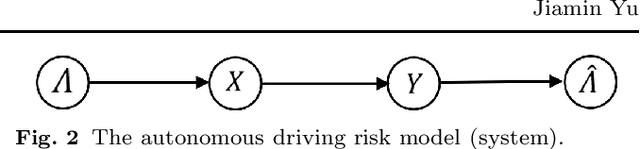
It has been for a long time to use big data of autonomous vehicles for perception, prediction, planning, and control of driving. Naturally, it is increasingly questioned why not using this big data for risk management and actuarial modeling. This article examines the emerging technical difficulties, new ideas, and methods of risk modeling under autonomous driving scenarios. Compared with the traditional risk model, the novel model is more consistent with the real road traffic and driving safety performance. More importantly, it provides technical feasibility for realizing risk assessment and car insurance pricing under a computer simulation environment.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Oct 13, 2021
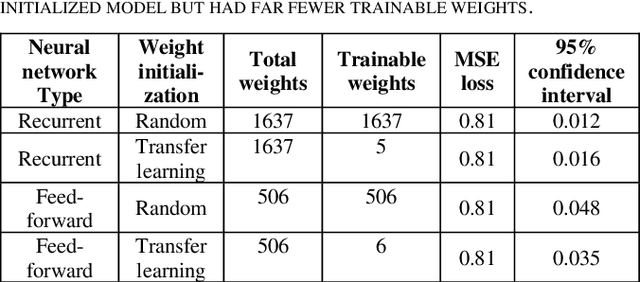
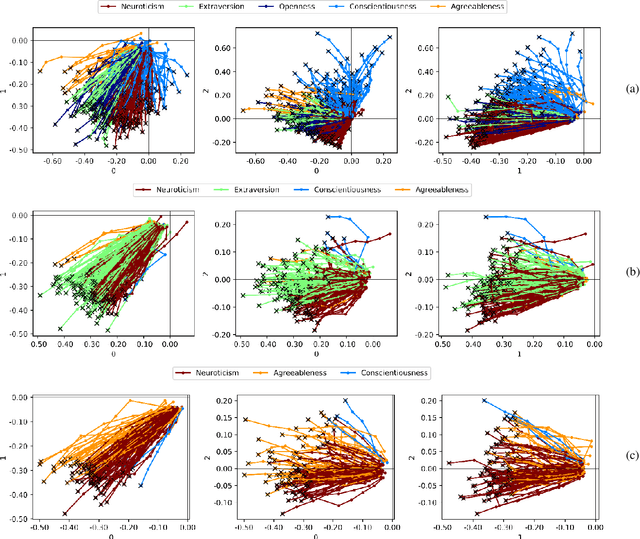
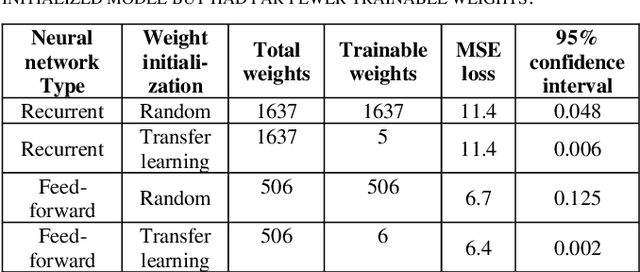
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In a novel approach, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only coarse segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
PIMIP: An Open Source Platform for Pathology Information Management and Integration
Nov 09, 2021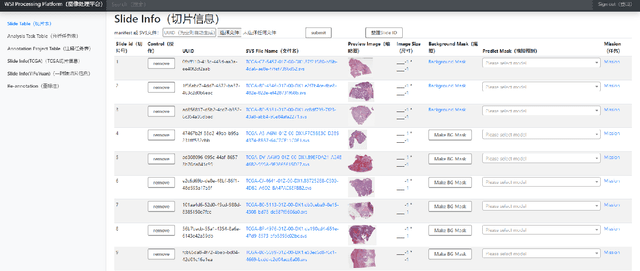
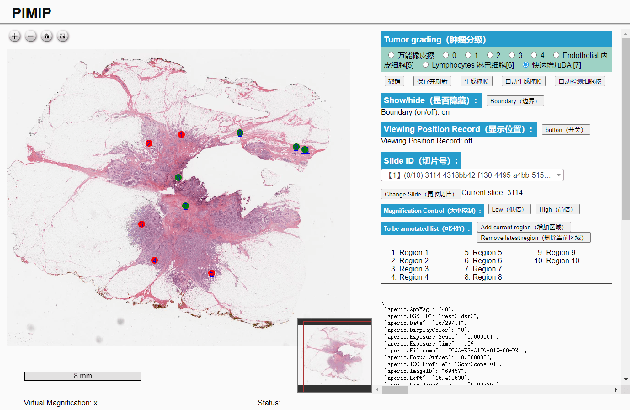
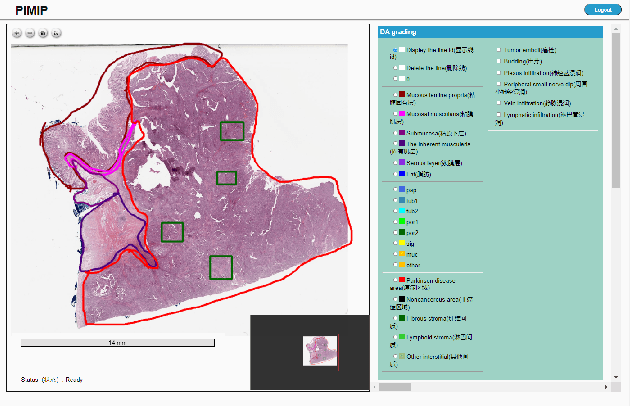
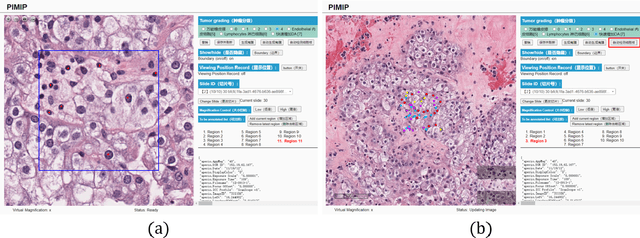
Digital pathology plays a crucial role in the development of artificial intelligence in the medical field. The digital pathology platform can make the pathological resources digital and networked, and realize the permanent storage of visual data and the synchronous browsing processing without the limitation of time and space. It has been widely used in various fields of pathology. However, there is still a lack of an open and universal digital pathology platform to assist doctors in the management and analysis of digital pathological sections, as well as the management and structured description of relevant patient information. Most platforms cannot integrate image viewing, annotation and analysis, and text information management. To solve the above problems, we propose a comprehensive and extensible platform PIMIP. Our PIMIP has developed the image annotation functions based on the visualization of digital pathological sections. Our annotation functions support multi-user collaborative annotation and multi-device annotation, and realize the automation of some annotation tasks. In the annotation task, we invited a professional pathologist for guidance. We introduce a machine learning module for image analysis. The data we collected included public data from local hospitals and clinical examples. Our platform is more clinical and suitable for clinical use. In addition to image data, we also structured the management and display of text information. So our platform is comprehensive. The platform framework is built in a modular way to support users to add machine learning modules independently, which makes our platform extensible.
A Spatial-temporal Graph Deep Learning Model for Urban Flood Nowcasting Leveraging Heterogeneous Community Features
Nov 17, 2021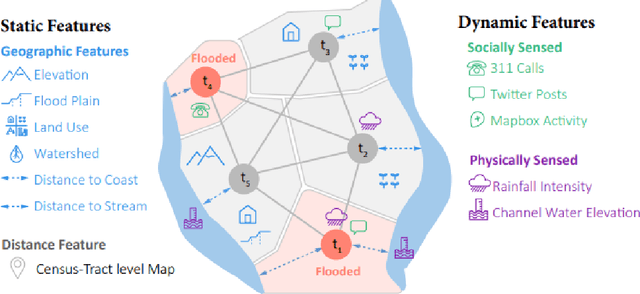
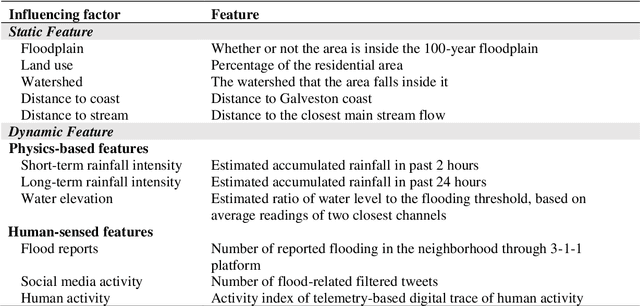
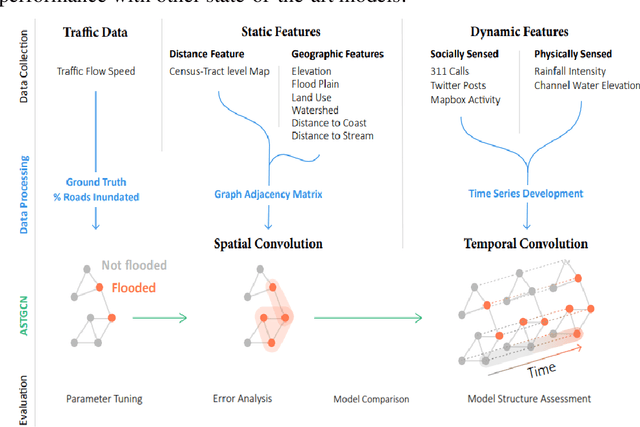
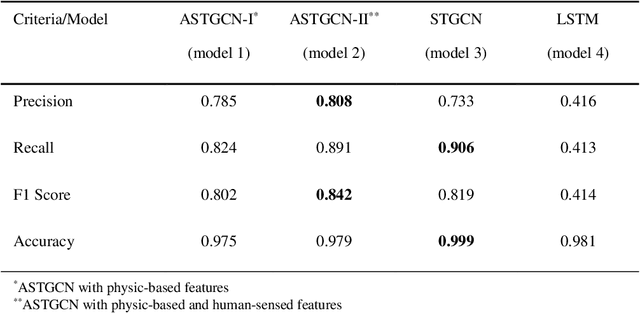
The objective of this study is to develop and test a novel structured deep-learning modeling framework for urban flood nowcasting by integrating physics-based and human-sensed features. We present a new computational modeling framework including an attention-based spatial-temporal graph convolution network (ASTGCN) model and different streams of data that are collected in real-time, preprocessed, and fed into the model to consider spatial and temporal information and dependencies that improve flood nowcasting. The novelty of the computational modeling framework is threefold; first, the model is capable of considering spatial and temporal dependencies in inundation propagation thanks to the spatial and temporal graph convolutional modules; second, it enables capturing the influence of heterogeneous temporal data streams that can signal flooding status, including physics-based features such as rainfall intensity and water elevation, and human-sensed data such as flood reports and fluctuations of human activity. Third, its attention mechanism enables the model to direct its focus on the most influential features that vary dynamically. We show the application of the modeling framework in the context of Harris County, Texas, as the case study and Hurricane Harvey as the flood event. Results indicate that the model provides superior performance for the nowcasting of urban flood inundation at the census tract level, with a precision of 0.808 and a recall of 0.891, which shows the model performs better compared with some other novel models. Moreover, ASTGCN model performance improves when heterogeneous dynamic features are added into the model that solely relies on physics-based features, which demonstrates the promise of using heterogenous human-sensed data for flood nowcasting,
On-Line Audio-to-Lyrics Alignment Based on a Reference Performance
Jul 30, 2021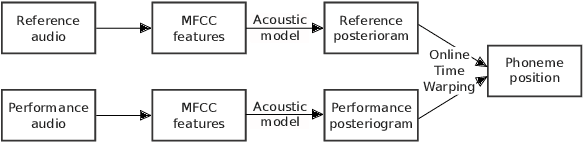
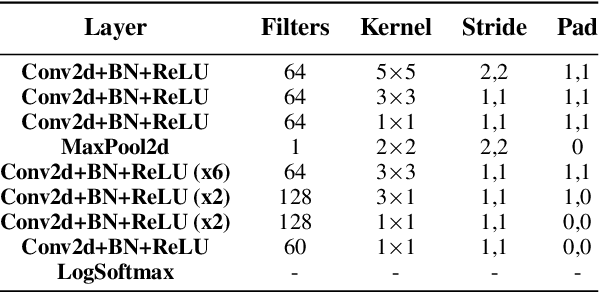
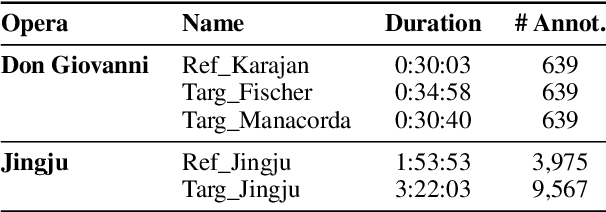

Audio-to-lyrics alignment has become an increasingly active research task in MIR, supported by the emergence of several open-source datasets of audio recordings with word-level lyrics annotations. However, there are still a number of open problems, such as a lack of robustness in the face of severe duration mismatches between audio and lyrics representation; a certain degree of language-specificity caused by acoustic differences across languages; and the fact that most successful methods in the field are not suited to work in real-time. Real-time lyrics alignment (tracking) would have many useful applications, such as fully automated subtitle display in live concerts and opera. In this work, we describe the first real-time-capable audio-to-lyrics alignment pipeline that is able to robustly track the lyrics of different languages, without additional language information. The proposed model predicts, for each audio frame, a probability vector over (European) phoneme classes, using a very small temporal context, and aligns this vector with a phoneme posteriogram matrix computed beforehand from another recording of the same work, which serves as a reference and a proxy to the written-out lyrics. We evaluate our system's tracking accuracy on the challenging genre of classical opera. Finally, robustness to out-of-training languages is demonstrated in an experiment on Jingju (Beijing opera).
Stochastic Deep Model Reference Adaptive Control
Aug 04, 2021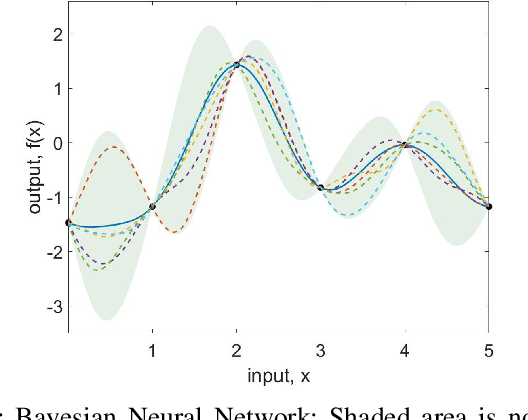
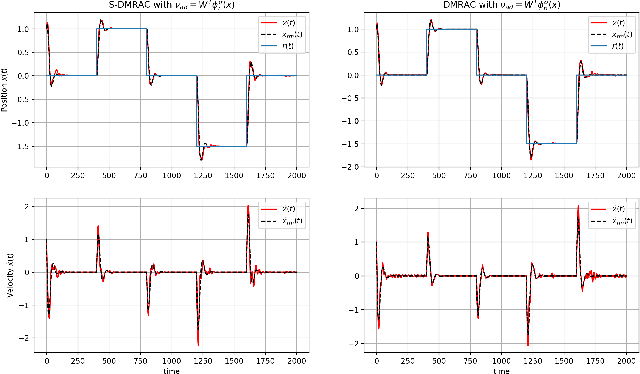
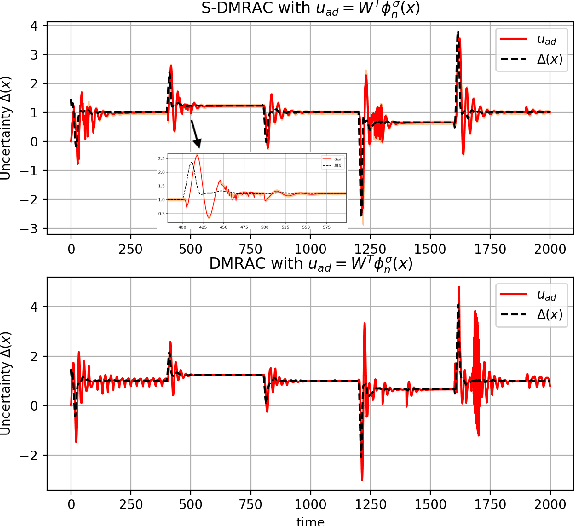
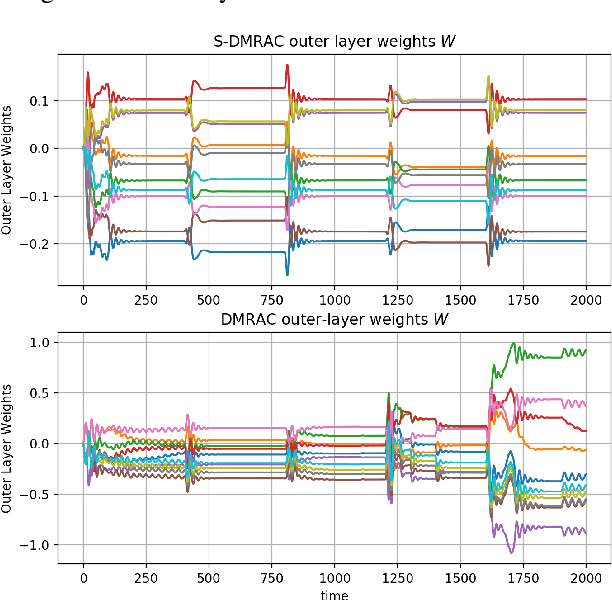
In this paper, we present a Stochastic Deep Neural Network-based Model Reference Adaptive Control. Building on our work "Deep Model Reference Adaptive Control", we extend the controller capability by using Bayesian deep neural networks (DNN) to represent uncertainties and model non-linearities. Stochastic Deep Model Reference Adaptive Control uses a Lyapunov-based method to adapt the output-layer weights of the DNN model in real-time, while a data-driven supervised learning algorithm is used to update the inner-layers parameters. This asynchronous network update ensures boundedness and guaranteed tracking performance with a learning-based real-time feedback controller. A Bayesian approach to DNN learning helped avoid over-fitting the data and provide confidence intervals over the predictions. The controller's stochastic nature also ensured "Induced Persistency of excitation," leading to convergence of the overall system signal.
Application of Machine Learning to Sleep Stage Classification
Nov 04, 2021
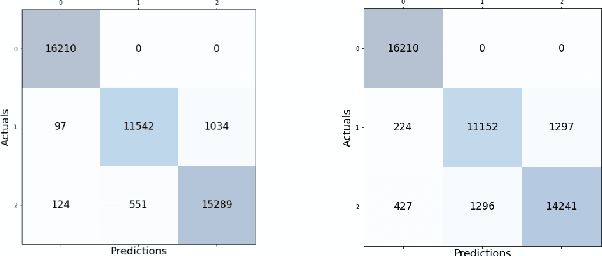
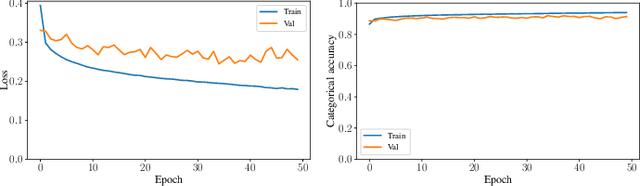
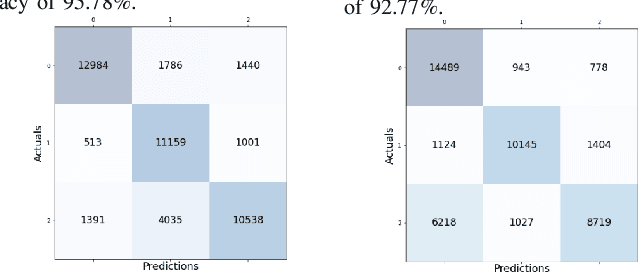
Sleep studies are imperative to recapitulate phenotypes associated with sleep loss and uncover mechanisms contributing to psychopathology. Most often, investigators manually classify the polysomnography into vigilance states, which is time-consuming, requires extensive training, and is prone to inter-scorer variability. While many works have successfully developed automated vigilance state classifiers based on multiple EEG channels, we aim to produce an automated and open-access classifier that can reliably predict vigilance state based on a single cortical electroencephalogram (EEG) from rodents to minimize the disadvantages that accompany tethering small animals via wires to computer programs. Approximately 427 hours of continuously monitored EEG, electromyogram (EMG), and activity were labeled by a domain expert out of 571 hours of total data. Here we evaluate the performance of various machine learning techniques on classifying 10-second epochs into one of three discrete classes: paradoxical, slow-wave, or wake. Our investigations include Decision Trees, Random Forests, Naive Bayes Classifiers, Logistic Regression Classifiers, and Artificial Neural Networks. These methodologies have achieved accuracies ranging from approximately 74% to approximately 96%. Most notably, the Random Forest and the ANN achieved remarkable accuracies of 95.78% and 93.31%, respectively. Here we have shown the potential of various machine learning classifiers to automatically, accurately, and reliably classify vigilance states based on a single EEG reading and a single EMG reading.