 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Surprising Simplicity of the Early-Time Learning Dynamics of Neural Networks
Jun 25, 2020
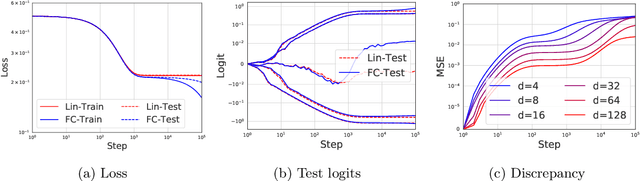
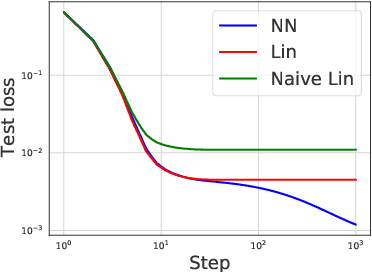
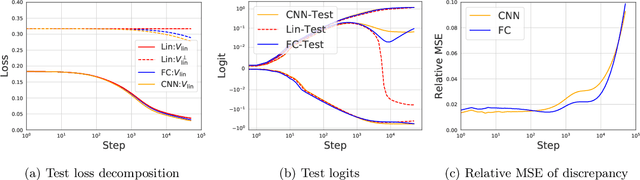
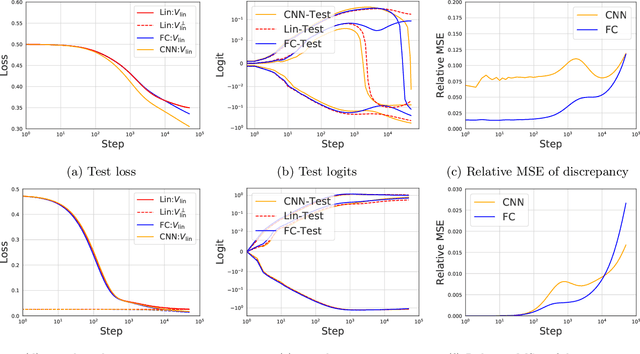
Modern neural networks are often regarded as complex black-box functions whose behavior is difficult to understand owing to their nonlinear dependence on the data and the nonconvexity in their loss landscapes. In this work, we show that these common perceptions can be completely false in the early phase of learning. In particular, we formally prove that, for a class of well-behaved input distributions, the early-time learning dynamics of a two-layer fully-connected neural network can be mimicked by training a simple linear model on the inputs. We additionally argue that this surprising simplicity can persist in networks with more layers and with convolutional architecture, which we verify empirically. Key to our analysis is to bound the spectral norm of the difference between the Neural Tangent Kernel (NTK) at initialization and an affine transform of the data kernel; however, unlike many previous results utilizing the NTK, we do not require the network to have disproportionately large width, and the network is allowed to escape the kernel regime later in training.
Mining frequency-based sequential trajectory co-clusters
Oct 27, 2021
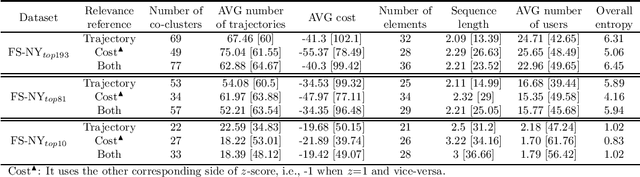
Co-clustering is a specific type of clustering that addresses the problem of finding groups of objects without necessarily considering all attributes. This technique has shown to have more consistent results in high-dimensional sparse data than traditional clustering. In trajectory co-clustering, the methods found in the literature have two main limitations: first, the space and time dimensions have to be constrained by user-defined thresholds; second, elements (trajectory points) are clustered ignoring the trajectory sequence, assuming that the points are independent among them. To address the limitations above, we propose a new trajectory co-clustering method for mining semantic trajectory co-clusters. It simultaneously clusters the trajectories and their elements taking into account the order in which they appear. This new method uses the element frequency to identify candidate co-clusters. Besides, it uses an objective cost function that automatically drives the co-clustering process, avoiding the need for constraining dimensions. We evaluate the proposed approach using real-world a publicly available dataset. The experimental results show that our proposal finds frequent and meaningful contiguous sequences revealing mobility patterns, thereby the most relevant elements.
Dynamic Pricing and Demand Learning on a Large Network of Products: A PAC-Bayesian Approach
Nov 01, 2021We consider a seller offering a large network of $N$ products over a time horizon of $T$ periods. The seller does not know the parameters of the products' linear demand model, and can dynamically adjust product prices to learn the demand model based on sales observations. The seller aims to minimize its pseudo-regret, i.e., the expected revenue loss relative to a clairvoyant who knows the underlying demand model. We consider a sparse set of demand relationships between products to characterize various connectivity properties of the product network. In particular, we study three different sparsity frameworks: (1) $L_0$ sparsity, which constrains the number of connections in the network, and (2) off-diagonal sparsity, which constrains the magnitude of cross-product price sensitivities, and (3) a new notion of spectral sparsity, which constrains the asymptotic decay of a similarity metric on network nodes. We propose a dynamic pricing-and-learning policy that combines the optimism-in-the-face-of-uncertainty and PAC-Bayesian approaches, and show that this policy achieves asymptotically optimal performance in terms of $N$ and $T$. We also show that in the case of spectral and off-diagonal sparsity, the seller can have a pseudo-regret linear in $N$, even when the network is dense.
Multiple Object Trackers in OpenCV: A Benchmark
Oct 11, 2021
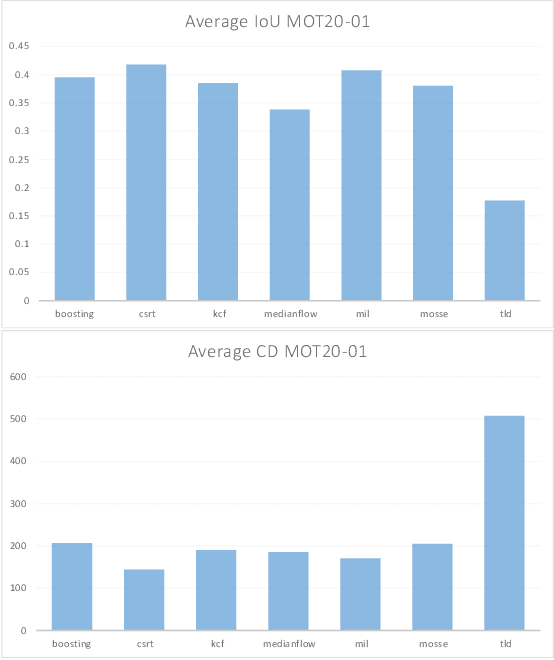
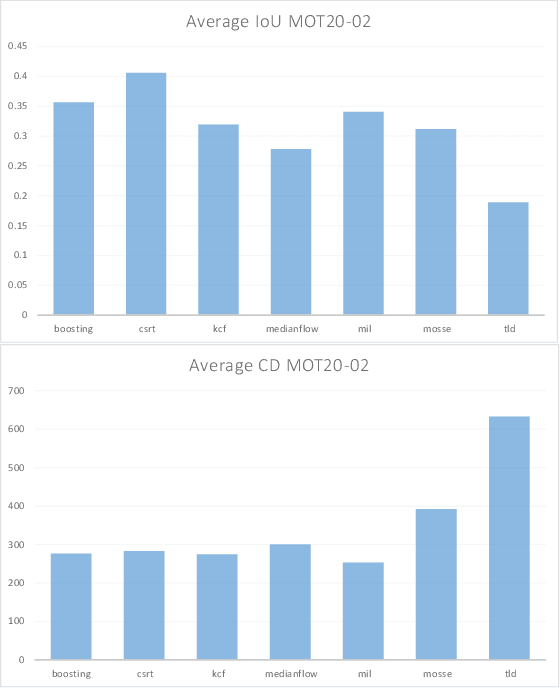
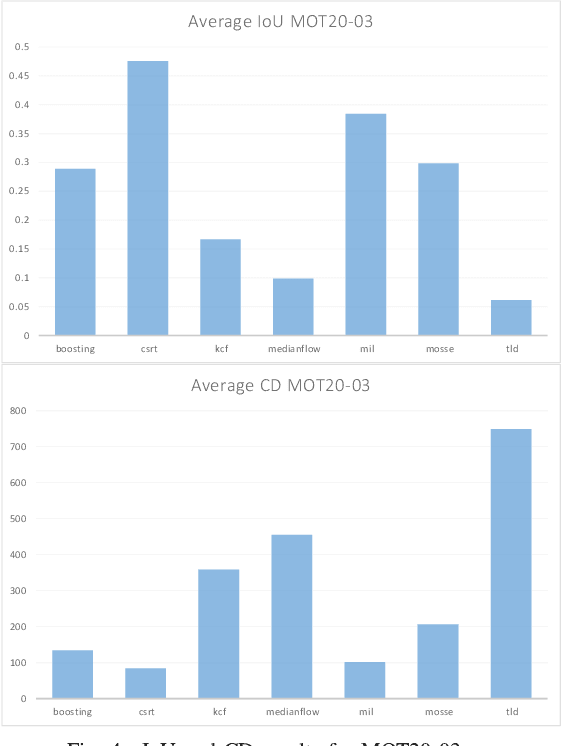
Object tracking is one of the most important and fundamental disciplines of Computer Vision. Many Computer Vision applications require specific object tracking capabilities, including autonomous and smart vehicles, video surveillance, medical treatments, and many others. The OpenCV as one of the most popular libraries for Computer Vision includes several hundred Computer Vision algorithms. Object tracking tasks in the library can be roughly clustered in single and multiple object trackers. The library is widely used for real-time applications, but there are a lot of unanswered questions such as when to use a specific tracker, how to evaluate its performance, and for what kind of objects will the tracker yield the best results? In this paper, we evaluate 7 trackers implemented in OpenCV against the MOT20 dataset. The results are shown based on Multiple Object Tracking Accuracy (MOTA) and Multiple Object Tracking Precision (MOTP) metrics.
A Survey on Knowledge integration techniques with Artificial Neural Networks for seq-2-seq/time series models
Aug 13, 2020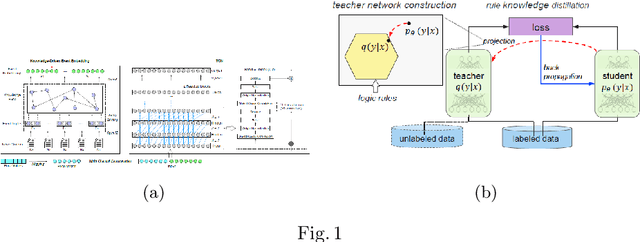
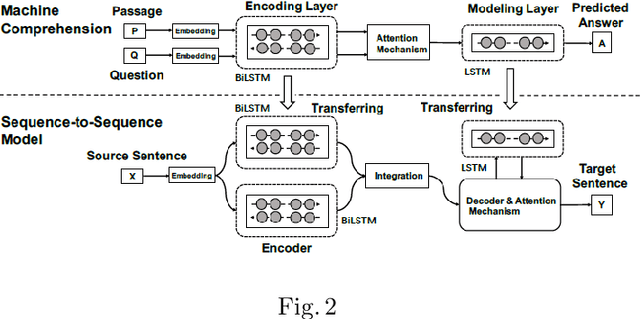
In recent years, with the advent of massive computational power and the availability of huge amounts of data, Deep neural networks have enabled the exploration of uncharted areas in several domains. But at times, they under-perform due to insufficient data, poor data quality, data that might not be covering the domain broadly, etc. Knowledge-based systems leverage expert knowledge for making decisions and suitably take actions. Such systems retain interpretability in the decision-making process. This paper focuses on exploring techniques to integrate expert knowledge to the Deep Neural Networks for sequence-to-sequence and time series models to improve their performance and interpretability.
MetroLoc: Metro Vehicle Mapping and Localization with LiDAR-Camera-Inertial Integration
Nov 01, 2021
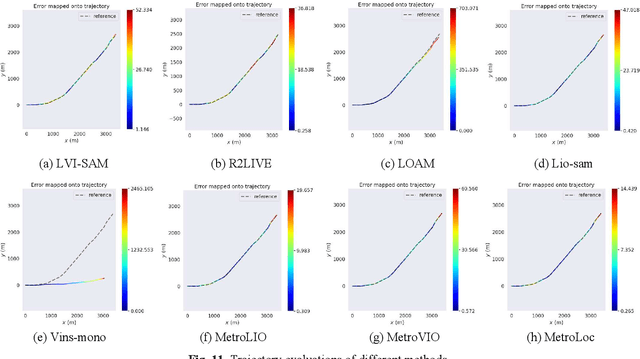

We propose an accurate and robust multi-modal sensor fusion framework, MetroLoc, towards one of the most extreme scenarios, the large-scale metro vehicle localization and mapping. MetroLoc is built atop an IMU-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, and inertial information with the convenience of loosely coupled methods. The proposed framework is composed of three submodules: IMU odometry, LiDAR-inertial odometry (LIO), and Visual-inertial odometry (VIO). The IMU is treated as the primary sensor, which achieves the observations from LIO and VIO to constrain the accelerometer and gyroscope biases. Compared to previous point-only LIO methods, our approach leverages more geometry information by introducing both line and plane features into motion estimation. The VIO also utilizes the environmental structure information by employing both lines and points. Our proposed method has been extensively tested in the long-during metro environments with a maintenance vehicle. Experimental results show the system more accurate and robust than the state-of-the-art approaches with real-time performance. Besides, we develop a series of Virtual Reality (VR) applications towards efficient, economical, and interactive rail vehicle state and trackside infrastructure monitoring, which has already been deployed to an outdoor testing railroad.
Error-feedback Stochastic Configuration Strategy on Convolutional Neural Networks for Time Series Forecasting
Feb 03, 2020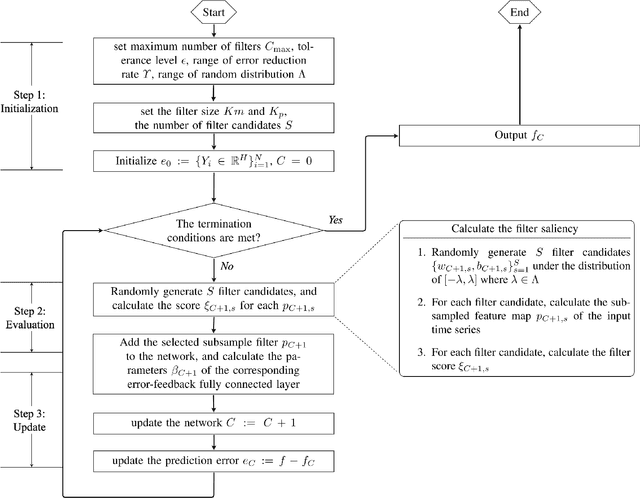
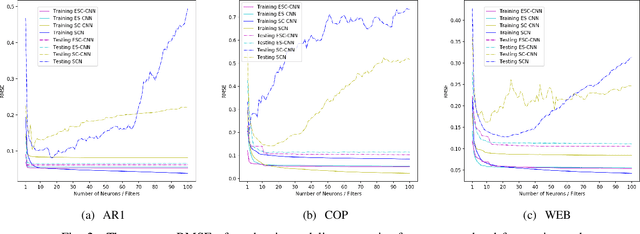
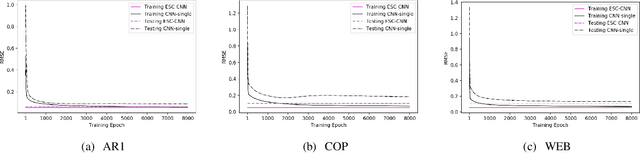
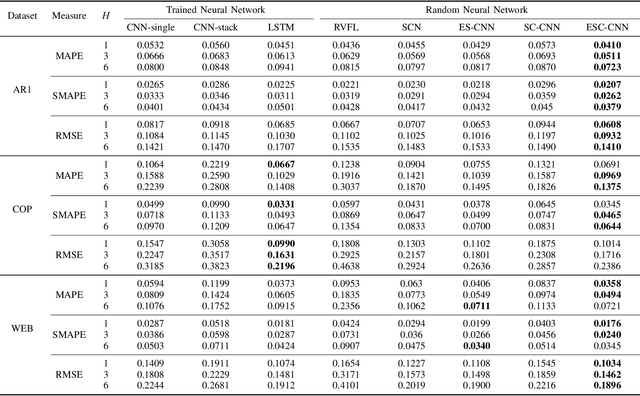
Despite the superiority of convolutional neural networks demonstrated in time series modeling and forecasting, it has not been fully explored on the design of the neural network architecture as well as the tuning of the hyper-parameters. Inspired by the iterative construction strategy for building a random multilayer perceptron, we propose a novel Error-feedback Stochastic Configuration (ESC) strategy to construct a random Convolutional Neural Network (ESC-CNN) for time series forecasting task, which builds the network architecture adaptively. The ESC strategy suggests that random filters and neurons of the error-feedback fully connected layer are incrementally added in a manner that they can steadily compensate the prediction error during the construction process, and a filter selection strategy is introduced to secure that ESC-CNN holds the universal approximation property, providing helpful information at each iterative process for the prediction. The performance of ESC-CNN is justified on its prediction accuracy for one-step-ahead and multi-step-ahead forecasting tasks. Comprehensive experiments on a synthetic dataset and two real-world datasets show that the proposed ESC-CNN not only outperforms the state-of-art random neural networks, but also exhibits strong predictive power in comparison to trained Convolution Neural Networks and Long Short-Term Memory models, demonstrating the effectiveness of ESC-CNN in time series forecasting.
Non-deep Networks
Oct 14, 2021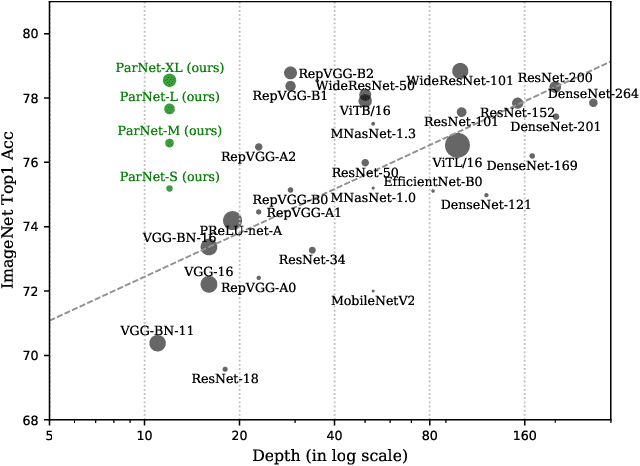
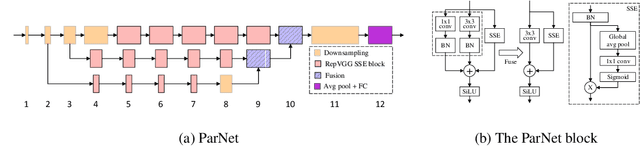
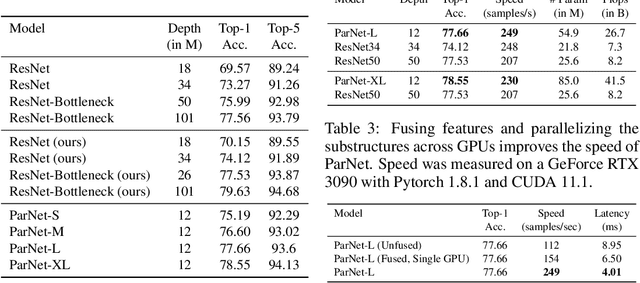

Depth is the hallmark of deep neural networks. But more depth means more sequential computation and higher latency. This begs the question -- is it possible to build high-performing "non-deep" neural networks? We show that it is. To do so, we use parallel subnetworks instead of stacking one layer after another. This helps effectively reduce depth while maintaining high performance. By utilizing parallel substructures, we show, for the first time, that a network with a depth of just 12 can achieve top-1 accuracy over 80% on ImageNet, 96% on CIFAR10, and 81% on CIFAR100. We also show that a network with a low-depth (12) backbone can achieve an AP of 48% on MS-COCO. We analyze the scaling rules for our design and show how to increase performance without changing the network's depth. Finally, we provide a proof of concept for how non-deep networks could be used to build low-latency recognition systems. Code is available at https://github.com/imankgoyal/NonDeepNetworks.
Data Smashing 2.0: Sequence Likelihood (SL) Divergence For Fast Time Series Comparison
Oct 08, 2019
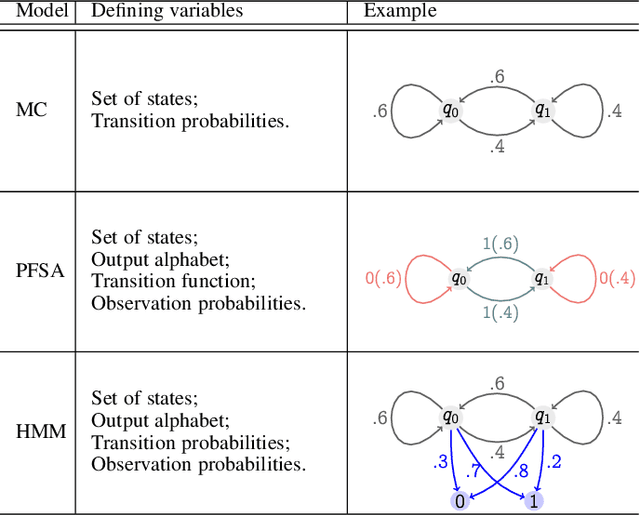
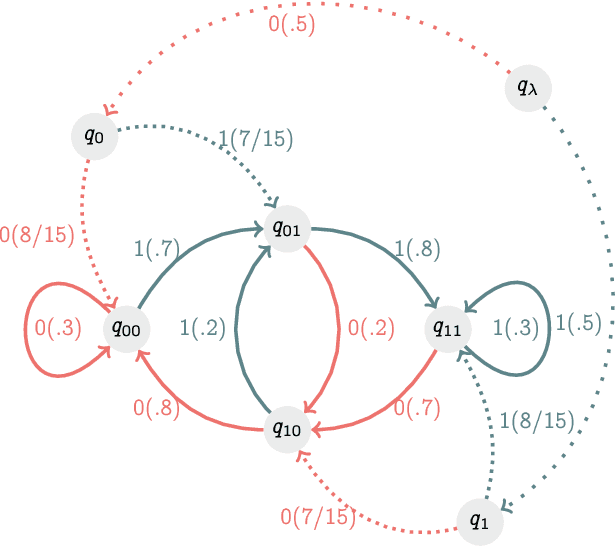
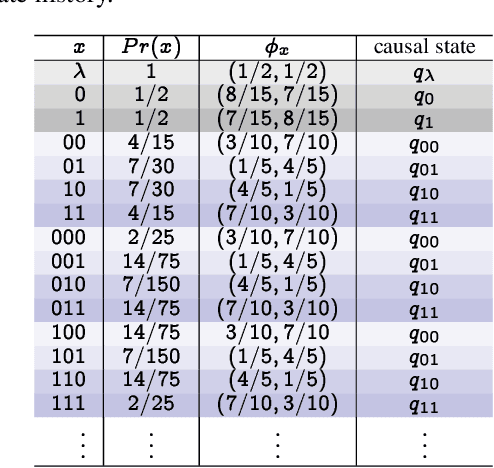
Recognizing subtle historical patterns is central to modeling and forecasting problems in time series analysis. Here we introduce and develop a new approach to quantify deviations in the underlying hidden generators of observed data streams, resulting in a new efficiently computable universal metric for time series. The proposed metric is in the sense that we can compare and contrast data streams regardless of where and how they are generated and without any feature engineering step. The approach proposed in this paper is conceptually distinct from our previous work on data smashing, and vastly improves discrimination performance and computing speed. The core idea here is the generalization of the notion of KL divergence often used to compare probability distributions to a notion of divergence in time series. We call this the sequence likelihood (SL) divergence, which may be used to measure deviations within a well-defined class of discrete-valued stochastic processes. We devise efficient estimators of SL divergence from finite sample paths and subsequently formulate a universal metric useful for computing distance between time series produced by hidden stochastic generators.
Longitudinal Speech Biomarkers for Automated Alzheimer's Detection
Nov 22, 2021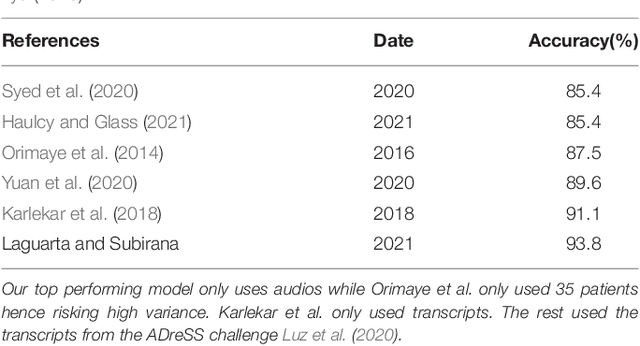
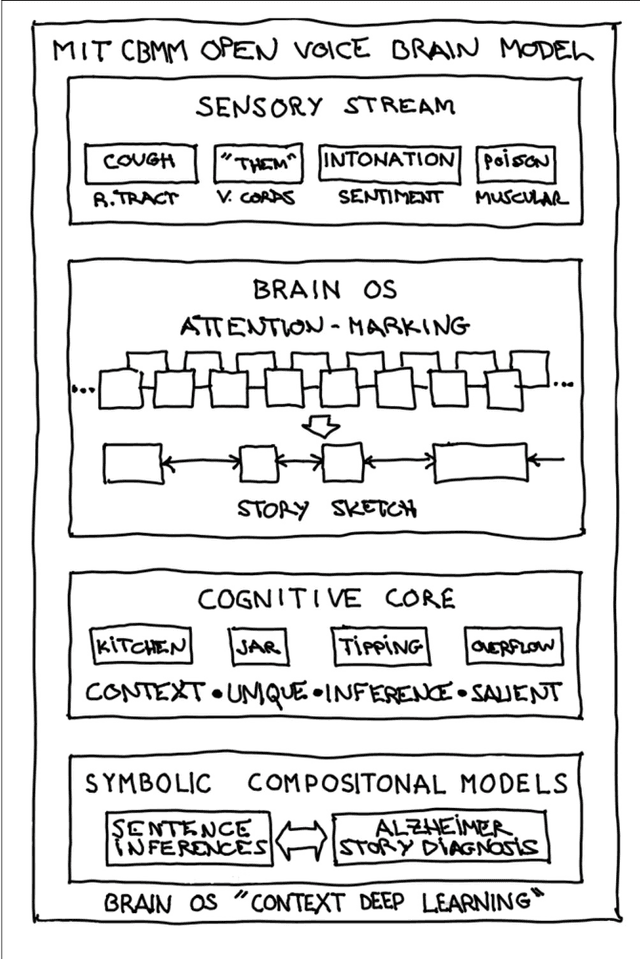
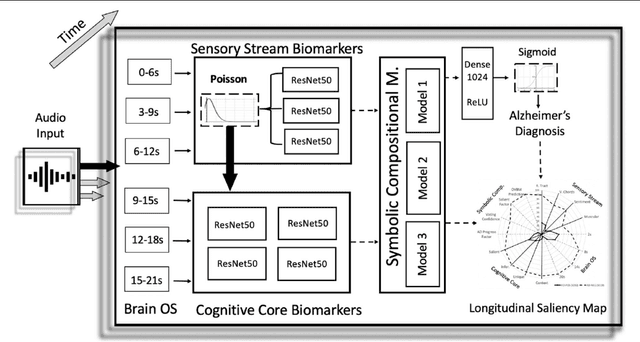
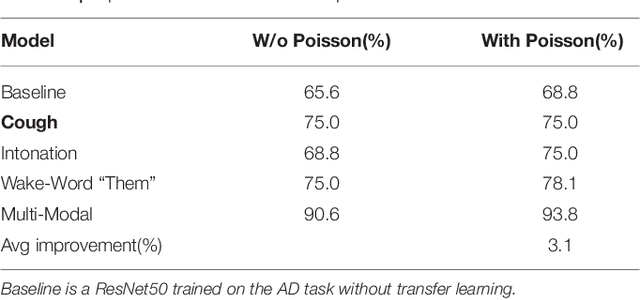
We introduce a novel audio processing architecture, the Open Voice Brain Model (OVBM), improving detection accuracy for Alzheimer's (AD) longitudinal discrimination from spontaneous speech. We also outline the OVBM design methodology leading us to such architecture, which in general can incorporate multimodal biomarkers and target simultaneously several diseases and other AI tasks. Key in our methodology is the use of multiple biomarkers complementing each other, and when two of them uniquely identify different subjects in a target disease we say they are orthogonal. We illustrate the methodology by introducing 16 biomarkers, three of which are orthogonal, demonstrating simultaneous above state-of-the-art discrimination for apparently unrelated diseases such as AD and COVID-19. Inspired by research conducted at the MIT Center for Brain Minds and Machines, OVBM combines biomarker implementations of the four modules of intelligence: The brain OS chunks and overlaps audio samples and aggregates biomarker features from the sensory stream and cognitive core creating a multi-modal graph neural network of symbolic compositional models for the target task. We apply it to AD, achieving above state-of-the-art accuracy of 93.8% on raw audio, while extracting a subject saliency map that longitudinally tracks relative disease progression using multiple biomarkers, 16 in the reported AD task. The ultimate aim is to help medical practice by detecting onset and treatment impact so that intervention options can be longitudinally tested. Using the OBVM design methodology, we introduce a novel lung and respiratory tract biomarker created using 200,000+ cough samples to pre-train a model discriminating cough cultural origin. This cough dataset sets a new benchmark as the largest audio health dataset with 30,000+ subjects participating in April 2020, demonstrating for the first-time cough cultural bias.