 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-resolution rainfall-runoff modeling using graph neural network
Oct 21, 2021
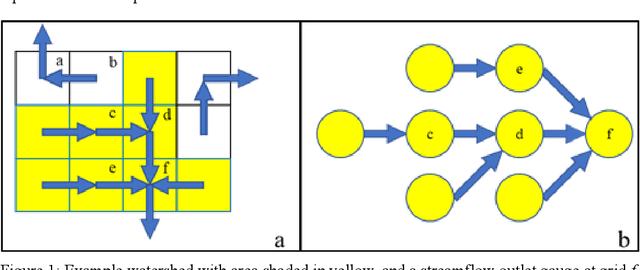
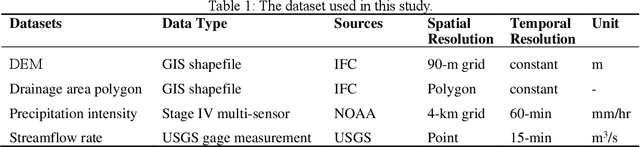
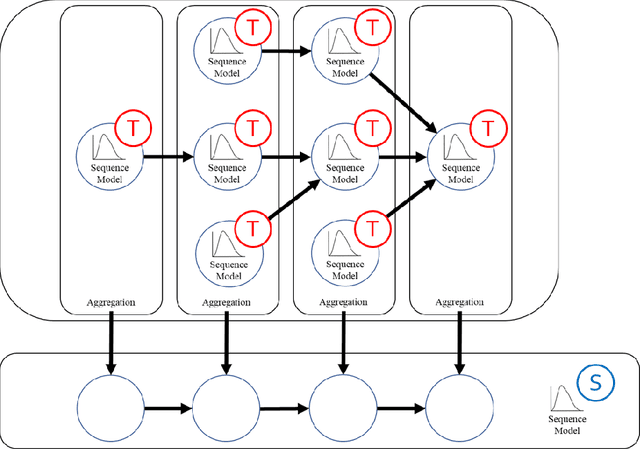
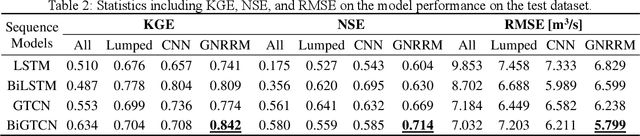
Time-series modeling has shown great promise in recent studies using the latest deep learning algorithms such as LSTM (Long Short-Term Memory). These studies primarily focused on watershed-scale rainfall-runoff modeling or streamflow forecasting, but the majority of them only considered a single watershed as a unit. Although this simplification is very effective, it does not take into account spatial information, which could result in significant errors in large watersheds. Several studies investigated the use of GNN (Graph Neural Networks) for data integration by decomposing a large watershed into multiple sub-watersheds, but each sub-watershed is still treated as a whole, and the geoinformation contained within the watershed is not fully utilized. In this paper, we propose the GNRRM (Graph Neural Rainfall-Runoff Model), a novel deep learning model that makes full use of spatial information from high-resolution precipitation data, including flow direction and geographic information. When compared to baseline models, GNRRM has less over-fitting and significantly improves model performance. Our findings support the importance of hydrological data in deep learning-based rainfall-runoff modeling, and we encourage researchers to include more domain knowledge in their models.
Semantic Image Alignment for Vehicle Localization
Oct 08, 2021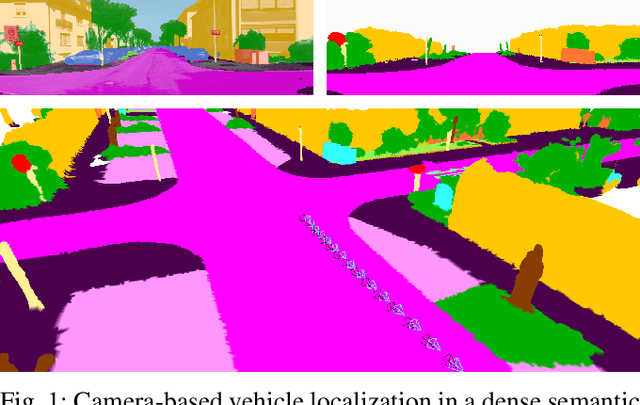
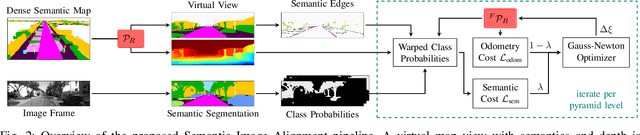
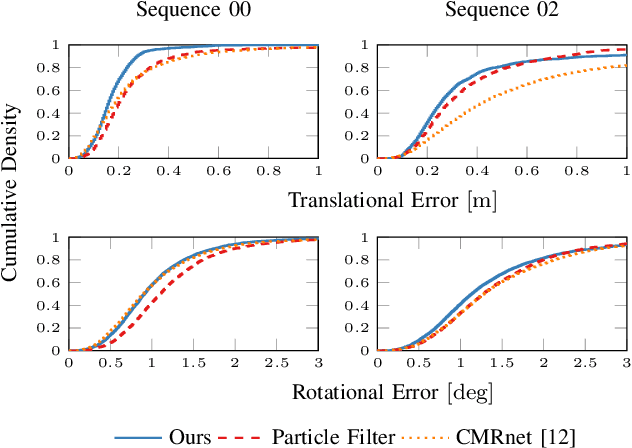
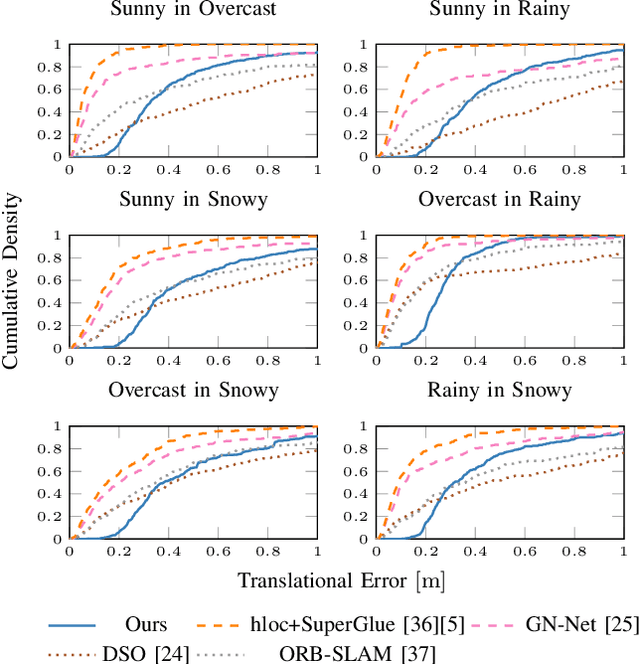
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning. In this paper, we present a novel approach to vehicle localization in dense semantic maps, including vectorized high-definition maps or 3D meshes, using semantic segmentation from a monocular camera. We formulate the localization task as a direct image alignment problem on semantic images, which allows our approach to robustly track the vehicle pose in semantically labeled maps by aligning virtual camera views rendered from the map to sequences of semantically segmented camera images. In contrast to existing visual localization approaches, the system does not require additional keypoint features, handcrafted localization landmark extractors or expensive LiDAR sensors. We demonstrate the wide applicability of our method on a diverse set of semantic mesh maps generated from stereo or LiDAR as well as manually annotated HD maps and show that it achieves reliable and accurate localization in real-time.
Tree in Tree: from Decision Trees to Decision Graphs
Oct 01, 2021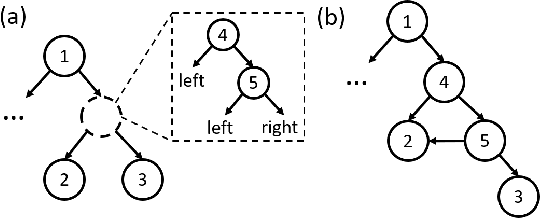

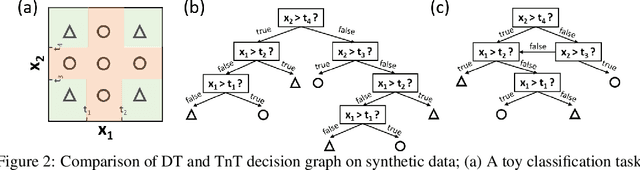
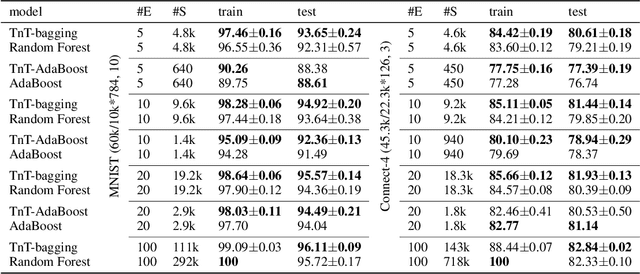
Decision trees have been widely used as classifiers in many machine learning applications thanks to their lightweight and interpretable decision process. This paper introduces Tree in Tree decision graph (TnT), a framework that extends the conventional decision tree to a more generic and powerful directed acyclic graph. TnT constructs decision graphs by recursively growing decision trees inside the internal or leaf nodes instead of greedy training. The time complexity of TnT is linear to the number of nodes in the graph, and it can construct decision graphs on large datasets. Compared to decision trees, we show that TnT achieves better classification performance with reduced model size, both as a stand-alone classifier and as a base estimator in bagging/AdaBoost ensembles. Our proposed model is a novel, more efficient, and accurate alternative to the widely-used decision trees.
Using Google Trends as a proxy for occupant behavior to predict building energy consumption
Oct 31, 2021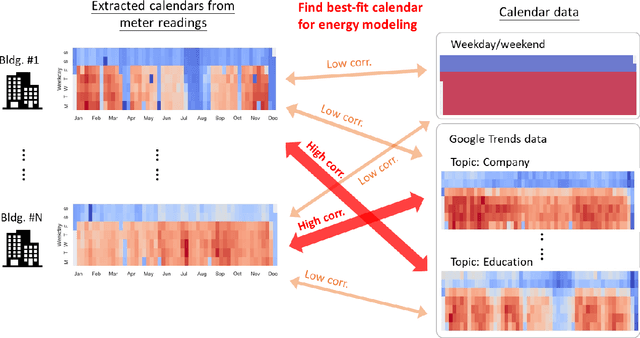
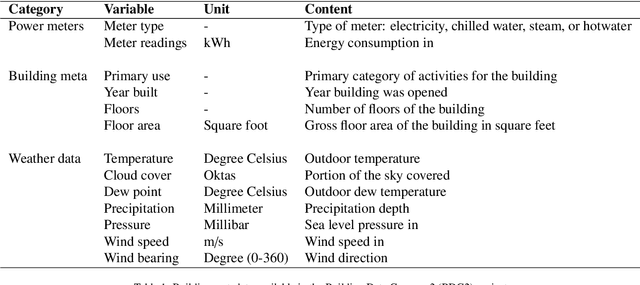
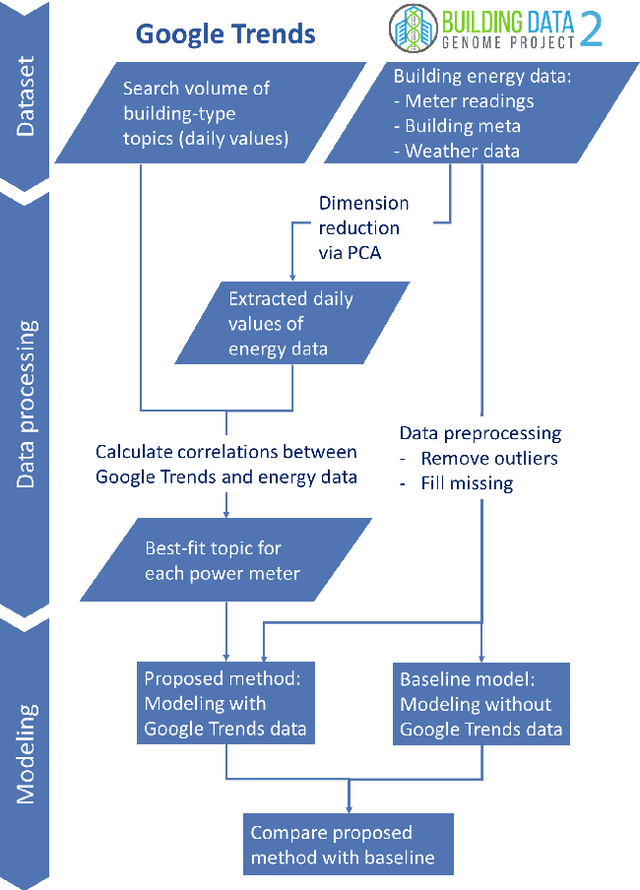

In recent years, the availability of larger amounts of energy data and advanced machine learning algorithms has created a surge in building energy prediction research. However, one of the variables in energy prediction models, occupant behavior, is crucial for prediction performance but hard-to-measure or time-consuming to collect from each building. This study proposes an approach that utilizes the search volume of topics (e.g., education} or Microsoft Excel) on the Google Trends platform as a proxy of occupant behavior and use of buildings. Linear correlations were first examined to explore the relationship between energy meter data and Google Trends search terms to infer building occupancy. Prediction errors before and after the inclusion of the trends of these terms were compared and analyzed based on the ASHRAE Great Energy Predictor III (GEPIII) competition dataset. The results show that highly correlated Google Trends data can effectively reduce the overall RMSLE error for a subset of the buildings to the level of the GEPIII competition's top five winning teams' performance. In particular, the RMSLE error reduction during public holidays and days with site-specific schedules are respectively reduced by 20-30% and 2-5%. These results show the potential of using Google Trends to improve energy prediction for a portion of the building stock by automatically identifying site-specific and holiday schedules.
Efficient Locally Optimal Number Set Partitioning for Scheduling, Allocation and Fair Selection
Sep 10, 2021We study the optimization version of the set partition problem (where the difference between the partition sums are minimized), which has numerous applications in decision theory literature. While the set partitioning problem is NP-hard and requires exponential complexity to solve (i.e., intractable); we formulate a weaker version of this NP-hard problem, where the goal is to find a locally optimal solution. We show that our proposed algorithms can find a locally optimal solution in near linear time. Our algorithms require neither positive nor integer elements in the input set, hence, they are more widely applicable.
Multivariate Time Series Forecasting Based on Causal Inference with Transfer Entropy and Graph Neural Network
May 03, 2020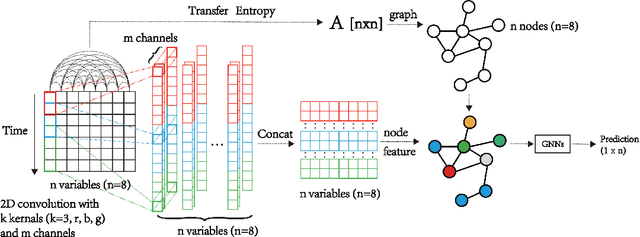
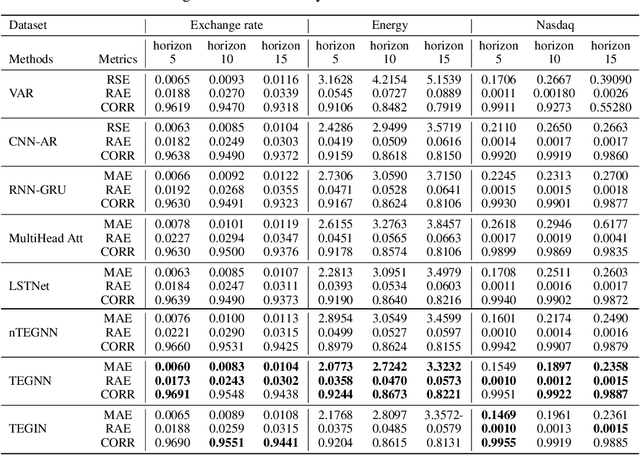
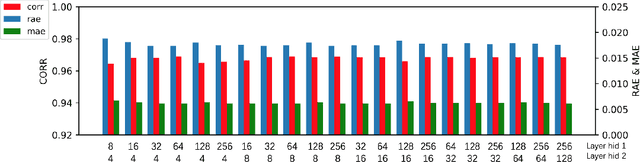
Multivariate time series (MTS) forecasting is an important problem in many fields. Accurate forecasting results can effectively help decision-making and reduce subjectivity. To date, many MTS forecasting methods have been proposed and widely applied. However, these methods assume that the value to be predicted of a single variable is related to all other variables, which makes it difficult to select the true key variable in high-dimensional situations. To address the above issue, a novel end-to-end deep learning model, termed transfer entropy graph neural network (TEGNN) is proposed in this paper. For accurate variable selection, the transfer entropy (TE) graph is introduced to characterize the causal information among variables, in which each variable is regarded as a graph node. In addition, convolutional neural network (CNN) filters with different perception scales are used for time series feature extraction. What is more, graph neural network (GNN) is adopted to tackle the embedding and forecasting problem of graph structure composed of MTS. MTS data collected from the real world are used to evaluate the prediction performance of TEGNN. Our comprehensive experiments demonstrate that the proposed TEGNN consistently outperforms state-of-the-art MTS forecasting baselines.
National-scale electricity peak load forecasting: Traditional, machine learning, or hybrid model?
Jun 30, 2021



As the volatility of electricity demand increases owing to climate change and electrification, the importance of accurate peak load forecasting is increasing. Traditional peak load forecasting has been conducted through time series-based models; however, recently, new models based on machine or deep learning are being introduced. This study performs a comparative analysis to determine the most accurate peak load-forecasting model for Korea, by comparing the performance of time series, machine learning, and hybrid models. Seasonal autoregressive integrated moving average with exogenous variables (SARIMAX) is used for the time series model. Artificial neural network (ANN), support vector regression (SVR), and long short-term memory (LSTM) are used for the machine learning models. SARIMAX-ANN, SARIMAX-SVR, and SARIMAX-LSTM are used for the hybrid models. The results indicate that the hybrid models exhibit significant improvement over the SARIMAX model. The LSTM-based models outperformed the others; the single and hybrid LSTM models did not exhibit a significant performance difference. In the case of Korea's highest peak load in 2019, the predictive power of the LSTM model proved to be greater than that of the SARIMAX-LSTM model. The LSTM, SARIMAX-SVR, and SARIMAX-LSTM models outperformed the current time series-based forecasting model used in Korea. Thus, Korea's peak load-forecasting performance can be improved by including machine learning or hybrid models.
A deep learning model for classification of diabetic retinopathy in eye fundus images based on retinal lesion detection
Oct 14, 2021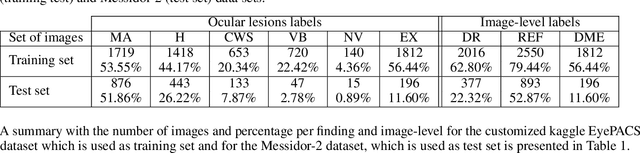
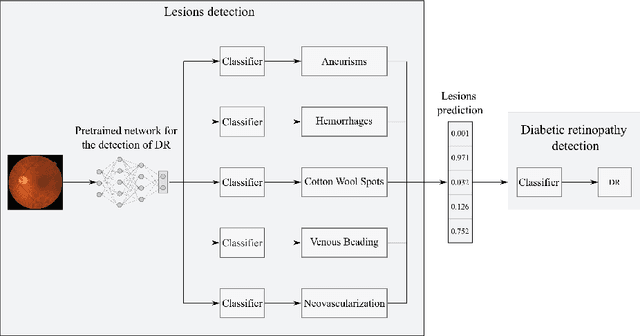
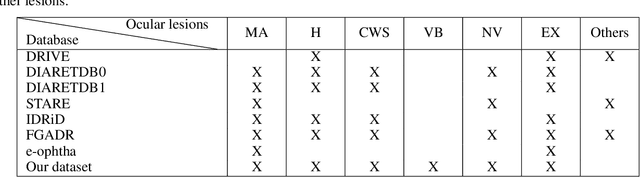
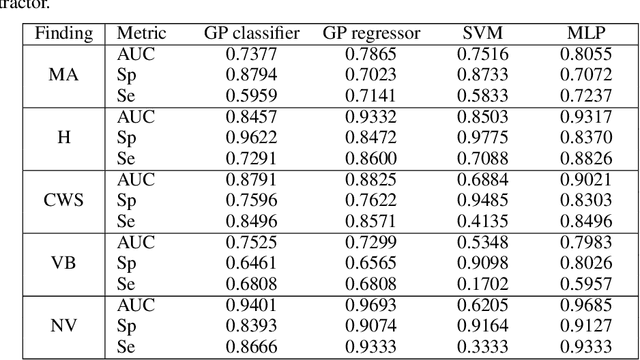
Diabetic retinopathy (DR) is the result of a complication of diabetes affecting the retina. It can cause blindness, if left undiagnosed and untreated. An ophthalmologist performs the diagnosis by screening each patient and analyzing the retinal lesions via ocular imaging. In practice, such analysis is time-consuming and cumbersome to perform. This paper presents a model for automatic DR classification on eye fundus images. The approach identifies the main ocular lesions related to DR and subsequently diagnoses the illness. The proposed method follows the same workflow as the clinicians, providing information that can be interpreted clinically to support the prediction. A subset of the kaggle EyePACS and the Messidor-2 datasets, labeled with ocular lesions, is made publicly available. The kaggle EyePACS subset is used as a training set and the Messidor-2 as a test set for lesions and DR classification models. For DR diagnosis, our model has an area-under-the-curve, sensitivity, and specificity of 0.948, 0.886, and 0.875, respectively, which competes with state-of-the-art approaches.
Research on the inverse kinematics prediction of a soft actuator via BP neural network
Oct 26, 2021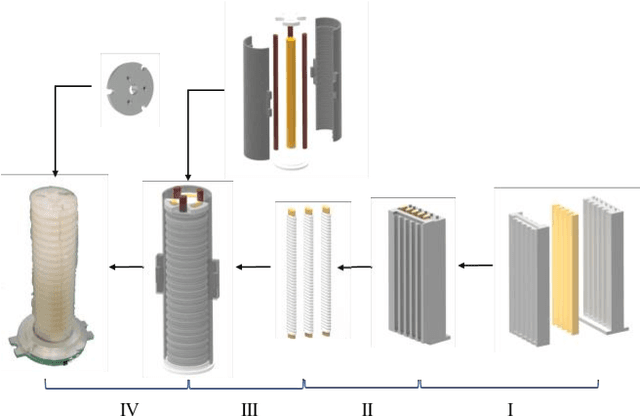

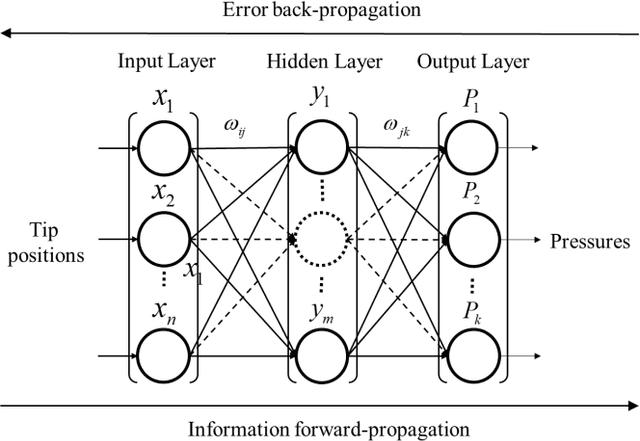
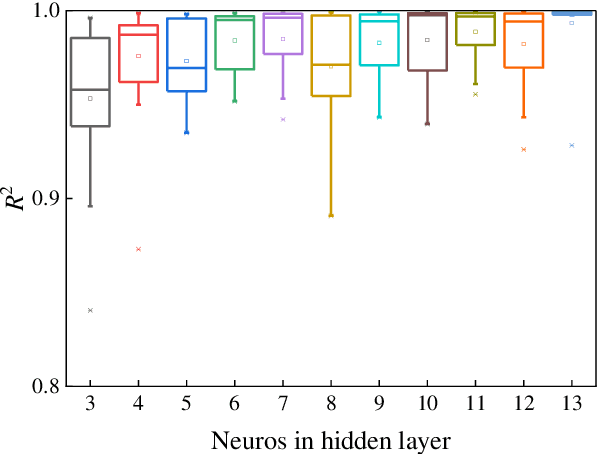
In this work we address the inverse kinetics problem of motion planning of the soft actuators driven by three chambers. Although the mathematical model describing inverse dynamics of this kind of actuator can been employed, this model is still a complex system. On the one hand, the differential equations are nonlinear, therefore, it is very difficult and time consuming to get the analytical solutions. Since the exact solutions of the mechanical model are not available, the elements of the Jacobian matrix cannot be calculated. On the other hand, material model is a complicated system with significant nonlinearity, non-stationarity, and uncertainty, making it challenging to develop an appropriate system model. To overcome these intrinsic problems, we propose a back-propagation (BP) neural network learning the inverse kinetics of the soft manipulator moving in three-dimensional space. After the training, the BP neural network model can represent the relation between the manipulator tip position and the pressures applied to the chambers. The proposed algorithm is very precise, and computationally efficient. The results show that a desired terminal position can be achieved with a degree of accuracy of 2.59% relative average error with respect to the total actuator length, demonstrate the ability of the model to realize inverse kinematic control.
Continual Learning on Noisy Data Streams via Self-Purified Replay
Oct 14, 2021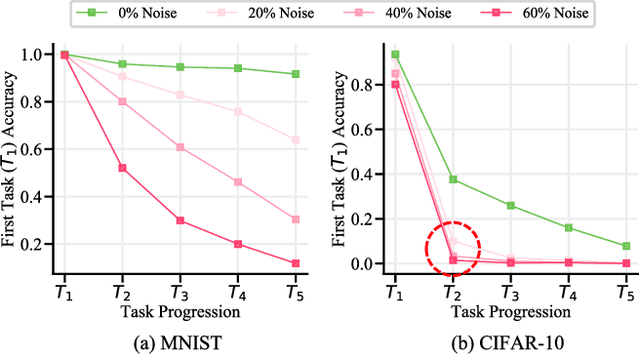
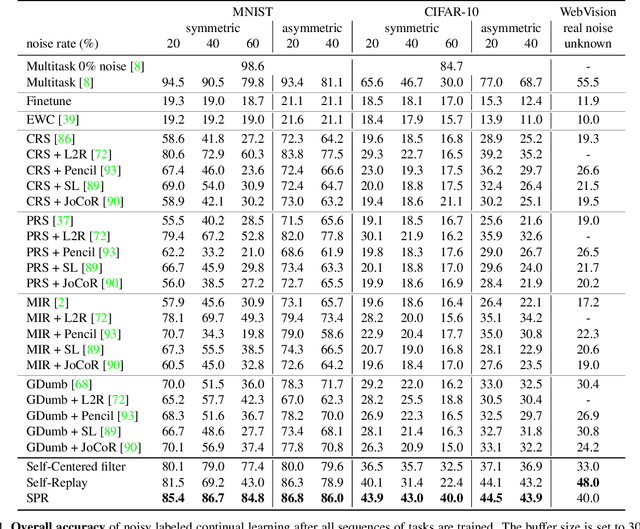
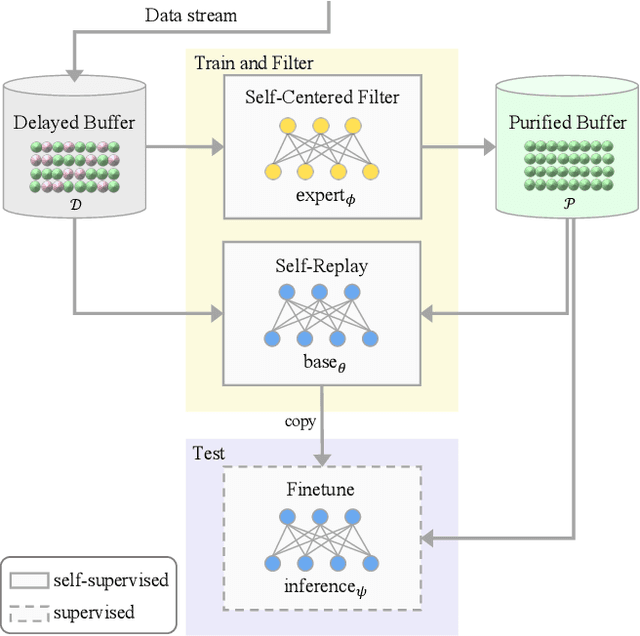
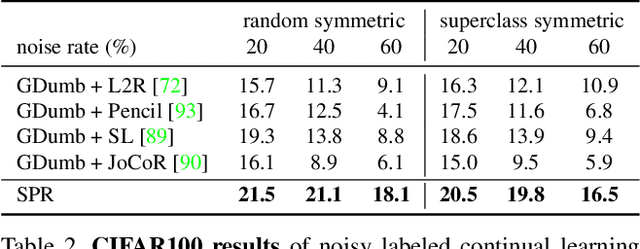
Continually learning in the real world must overcome many challenges, among which noisy labels are a common and inevitable issue. In this work, we present a repla-ybased continual learning framework that simultaneously addresses both catastrophic forgetting and noisy labels for the first time. Our solution is based on two observations; (i) forgetting can be mitigated even with noisy labels via self-supervised learning, and (ii) the purity of the replay buffer is crucial. Building on this regard, we propose two key components of our method: (i) a self-supervised replay technique named Self-Replay which can circumvent erroneous training signals arising from noisy labeled data, and (ii) the Self-Centered filter that maintains a purified replay buffer via centrality-based stochastic graph ensembles. The empirical results on MNIST, CIFAR-10, CIFAR-100, and WebVision with real-world noise demonstrate that our framework can maintain a highly pure replay buffer amidst noisy streamed data while greatly outperforming the combinations of the state-of-the-art continual learning and noisy label learning methods. The source code is available at http://vision.snu.ac.kr/projects/SPR