 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clustering of Pain Dynamics in Sickle Cell Disease from Sparse, Uneven Samples
Aug 31, 2021
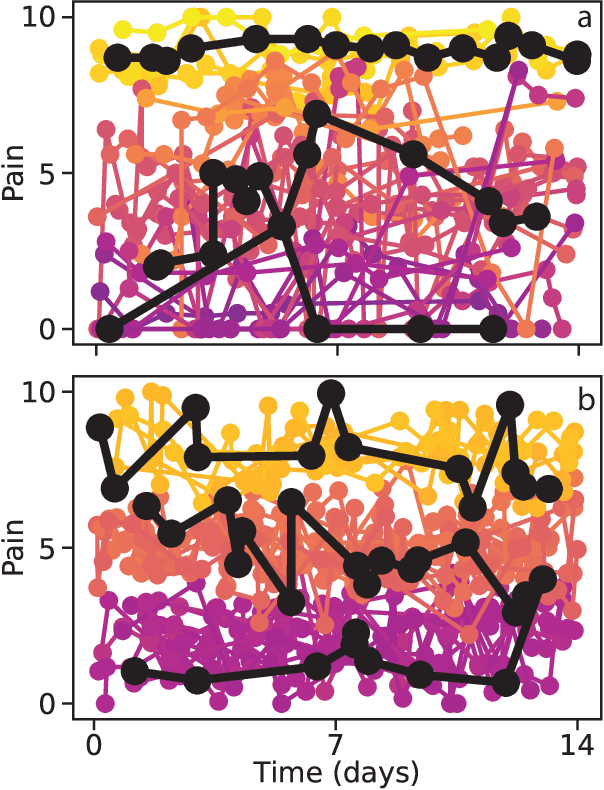
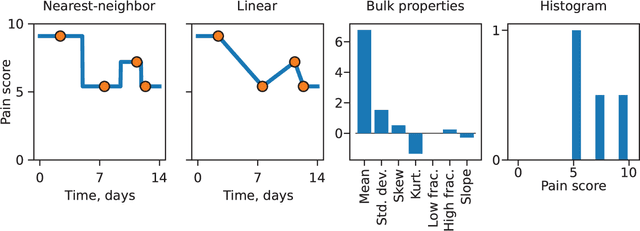
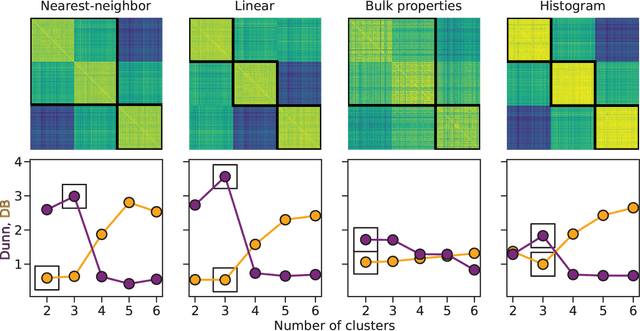
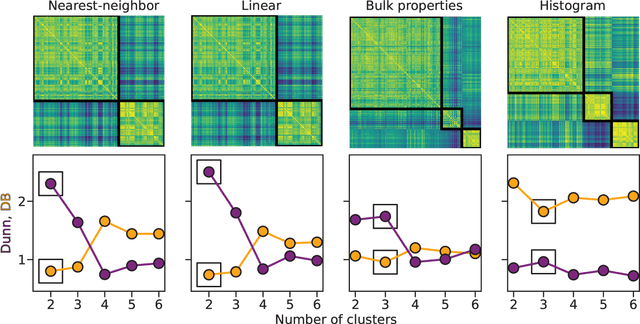
Irregularly sampled time series data are common in a variety of fields. Many typical methods for drawing insight from data fail in this case. Here we attempt to generalize methods for clustering trajectories to irregularly and sparsely sampled data. We first construct synthetic data sets, then propose and assess four methods of data alignment to allow for application of spectral clustering. We also repeat the same process for real data drawn from medical records of patients with sickle cell disease -- patients whose subjective experiences of pain were tracked for several months via a mobile app. We find that different methods for aligning irregularly sampled sparse data sets can lead to different optimal numbers of clusters, even for synthetic data with known properties. For the case of sickle cell disease, we find that three clusters is a reasonable choice, and these appear to correspond to (1) a low pain group with occasionally acute pain, (2) a group which experiences moderate mean pain that fluctuates often from low to high, and (3) a group that experiences persistent high levels of pain. Our results may help physicians and patients better understand and manage patients' pain levels over time, and we expect that the methods we develop will apply to a wide range of other data sources in medicine and beyond.
Prediction of properties of metal alloy materials based on machine learning
Sep 20, 2021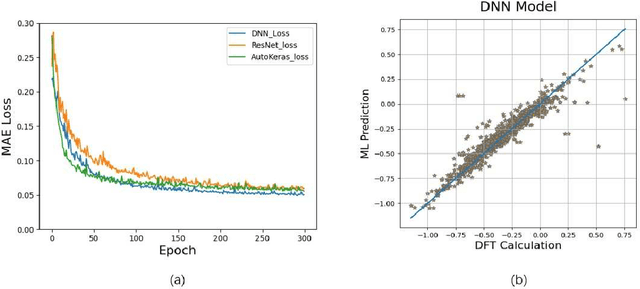
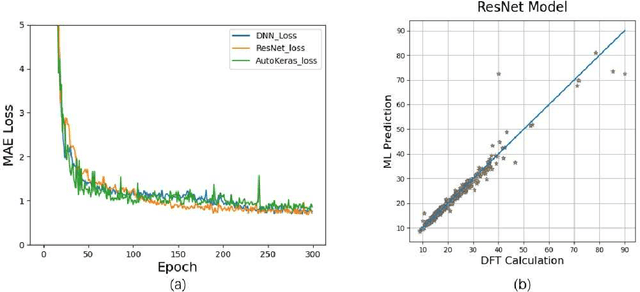
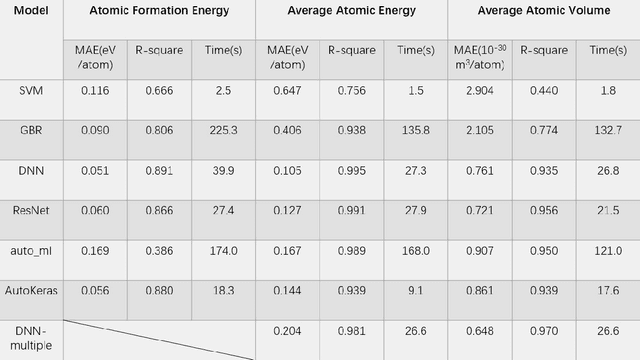
Density functional theory and its optimization algorithm are the main methods to calculate the properties in the field of materials. Although the calculation results are accurate, it costs a lot of time and money. In order to alleviate this problem, we intend to use machine learning to predict material properties. In this paper, we conduct experiments on atomic volume, atomic energy and atomic formation energy of metal alloys, using the open quantum material database. Through the traditional machine learning models, deep learning network and automated machine learning, we verify the feasibility of machine learning in material property prediction. The experimental results show that the machine learning can predict the material properties accurately.
Time Series Source Separation using Dynamic Mode Decomposition
Mar 04, 2019

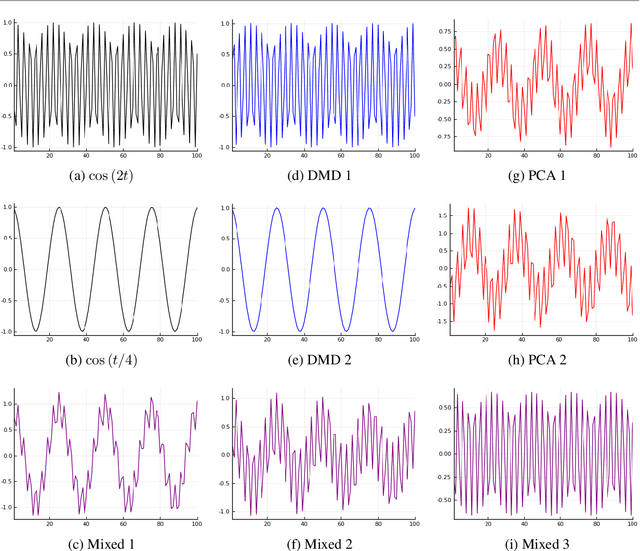
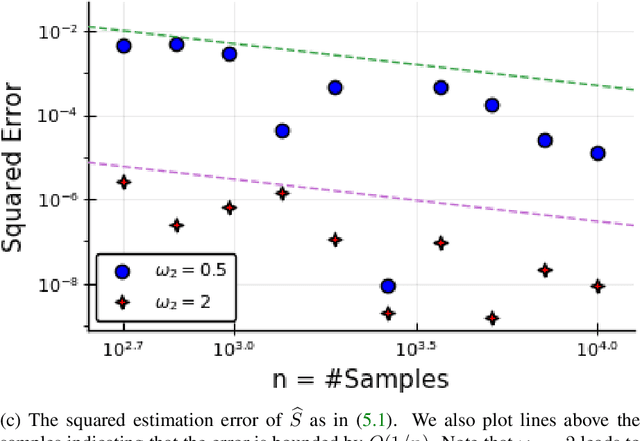
The dynamic mode decomposition (DMD) extracted dynamic modes are the non-orthogonal eigenvectors of the matrix that best approximates the one-step temporal evolution of the multivariate samples. In the context of dynamic system analysis, the extracted dynamic modes are a generalization of global stability modes. We apply DMD to a data matrix whose rows are linearly independent, additive mixtures of latent time series. We show that when the latent time series are uncorrelated at a lag of one time-step then, in the large sample limit, the recovered dynamic modes will approximate, up to a column-wise normalization, the columns of the mixing matrix. Thus, DMD is a time series blind source separation algorithm in disguise, but is different from closely related second order algorithms such as SOBI and AMUSE. All can unmix mixed ergodic Gaussian time series in a way that ICA fundamentally cannot. We use our insights on single lag DMD to develop a higher-lag extension, analyze the finite sample performance with and without randomly missing data, and identify settings where the higher lag variant can outperform the conventional single lag variant. We validate our results with numerical simulations, and highlight how DMD can be used in change point detection.
Preference Communication in Multi-Objective Normal-Form Games
Nov 17, 2021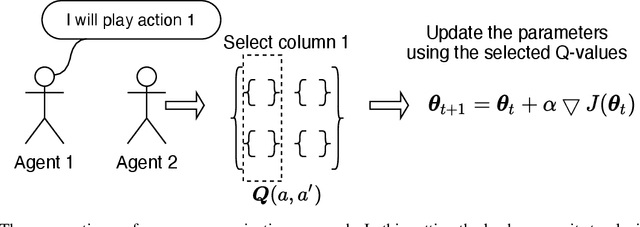
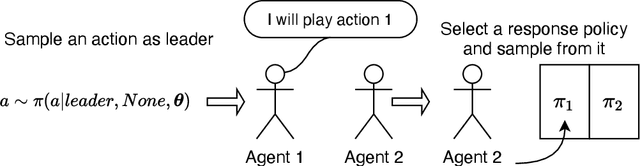

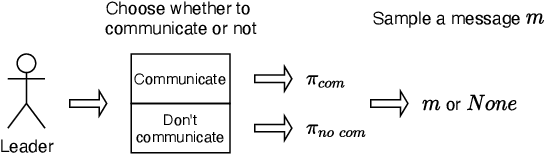
We study the problem of multiple agents learning concurrently in a multi-objective environment. Specifically, we consider two agents that repeatedly play a multi-objective normal-form game. In such games, the payoffs resulting from joint actions are vector valued. Taking a utility-based approach, we assume a utility function exists that maps vectors to scalar utilities and consider agents that aim to maximise the utility of expected payoff vectors. As agents do not necessarily know their opponent's utility function or strategy, they must learn optimal policies to interact with each other. To aid agents in arriving at adequate solutions, we introduce four novel preference communication protocols for both cooperative as well as self-interested communication. Each approach describes a specific protocol for one agent communicating preferences over their actions and how another agent responds. These protocols are subsequently evaluated on a set of five benchmark games against baseline agents that do not communicate. We find that preference communication can drastically alter the learning process and lead to the emergence of cyclic Nash equilibria which had not been previously observed in this setting. Additionally, we introduce a communication scheme where agents must learn when to communicate. For agents in games with Nash equilibria, we find that communication can be beneficial but difficult to learn when agents have different preferred equilibria. When this is not the case, agents become indifferent to communication. In games without Nash equilibria, our results show differences across learning rates. When using faster learners, we observe that explicit communication becomes more prevalent at around 50% of the time, as it helps them in learning a compromise joint policy. Slower learners retain this pattern to a lesser degree, but show increased indifference.
Wav2vec-S: Semi-Supervised Pre-Training for Speech Recognition
Oct 09, 2021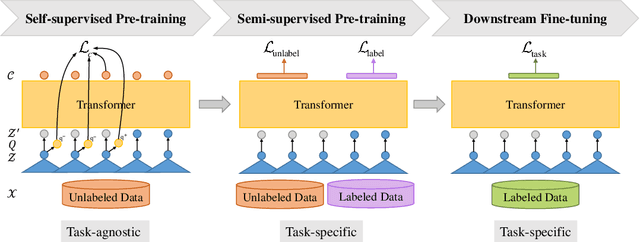
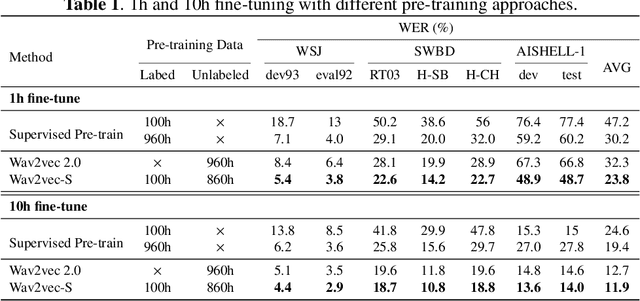
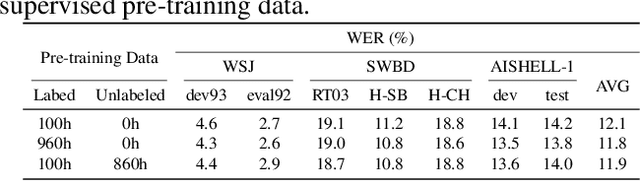
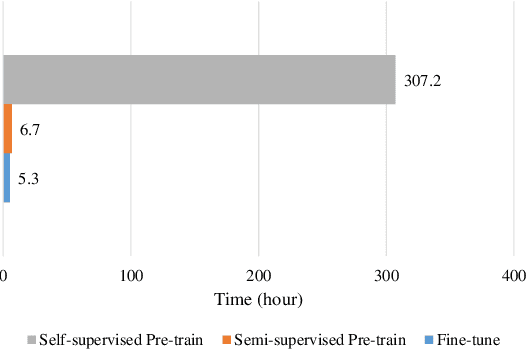
Self-supervised pre-training has dramatically improved the performance of automatic speech recognition (ASR). However, most existing self-supervised pre-training approaches are task-agnostic, i.e., could be applied to various downstream tasks. And there is a gap between the task-agnostic pre-training and the task-specific downstream fine-tuning, which may degrade the downstream performance. In this work, we propose a novel pre-training paradigm called wav2vec-S, where we use task-specific semi-supervised pre-training to bridge this gap. Specifically, the semi-supervised pre-training is conducted on the basis of self-supervised pre-training such as wav2vec 2.0. Experiments on ASR show that compared to wav2vec 2.0, wav2vec-S only requires marginal increment of pre-training time but could significantly improve ASR performance on in-domain, cross-domain and cross-lingual datasets. The average relative WER reductions are 26.3% and 6.3% for 1h and 10h fine-tuning, respectively.
Dynamic texture recognition using time-causal and time-recursive spatio-temporal receptive fields
Jun 21, 2018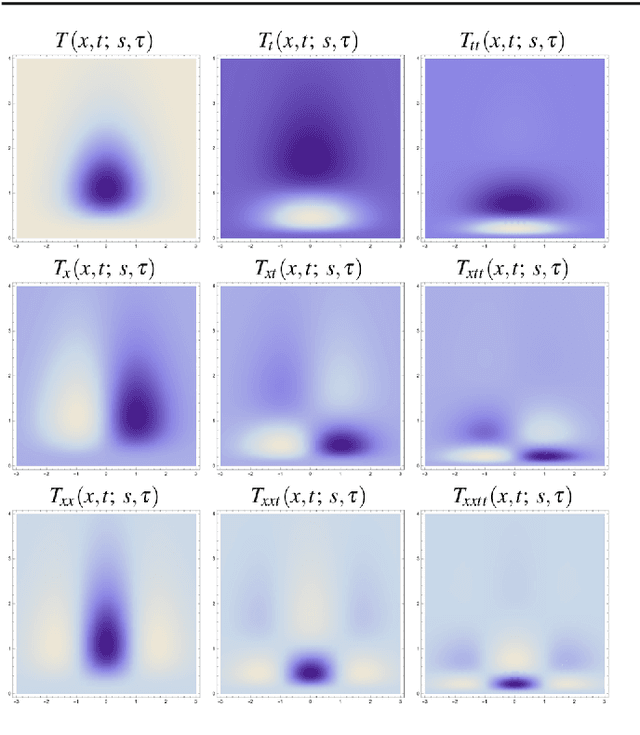

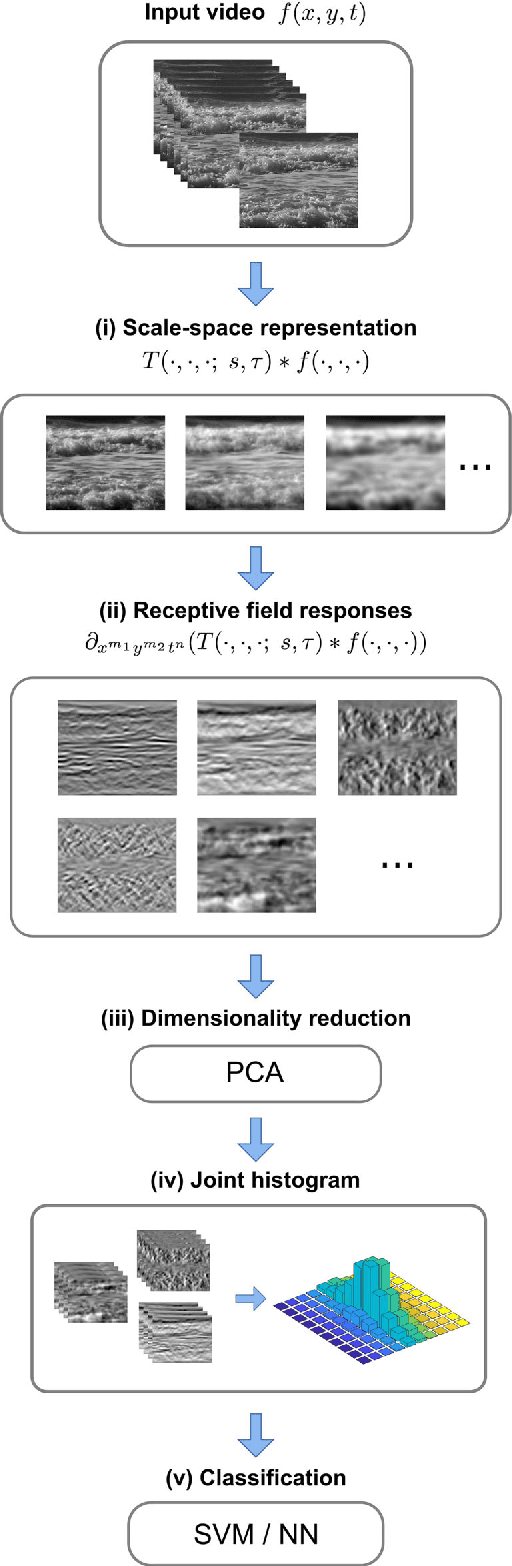
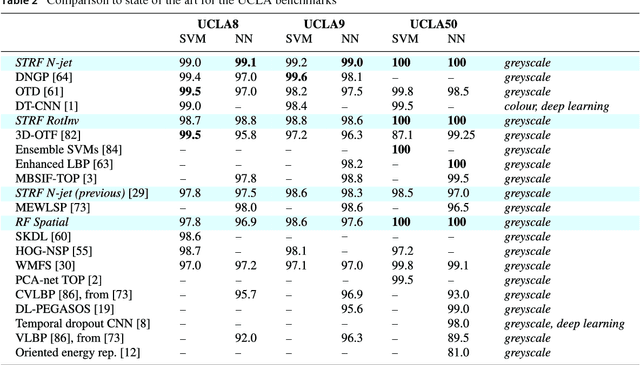
This work presents a first evaluation of using spatio-temporal receptive fields from a recently proposed time-causal spatio-temporal scale-space framework as primitives for video analysis. We propose a new family of video descriptors based on regional statistics of spatio-temporal receptive field responses and evaluate this approach on the problem of dynamic texture recognition. Our approach generalises a previously used method, based on joint histograms of receptive field responses, from the spatial to the spatio-temporal domain and from object recognition to dynamic texture recognition. The time-recursive formulation enables computationally efficient time-causal recognition. The experimental evaluation demonstrates competitive performance compared to state-of-the-art. Especially, it is shown that binary versions of our dynamic texture descriptors achieve improved performance compared to a large range of similar methods using different primitives either handcrafted or learned from data. Further, our qualitative and quantitative investigation into parameter choices and the use of different sets of receptive fields highlights the robustness and flexibility of our approach. Together, these results support the descriptive power of this family of time-causal spatio-temporal receptive fields, validate our approach for dynamic texture recognition and point towards the possibility of designing a range of video analysis methods based on these new time-causal spatio-temporal primitives.
* 29 pages, 16 figures
Adversarial Training for Face Recognition Systems using Contrastive Adversarial Learning and Triplet Loss Fine-tuning
Oct 09, 2021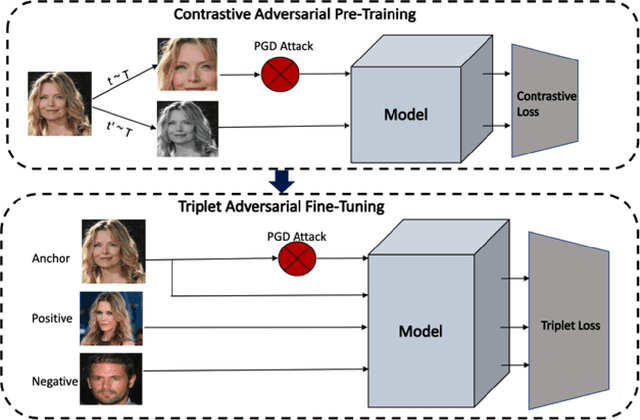

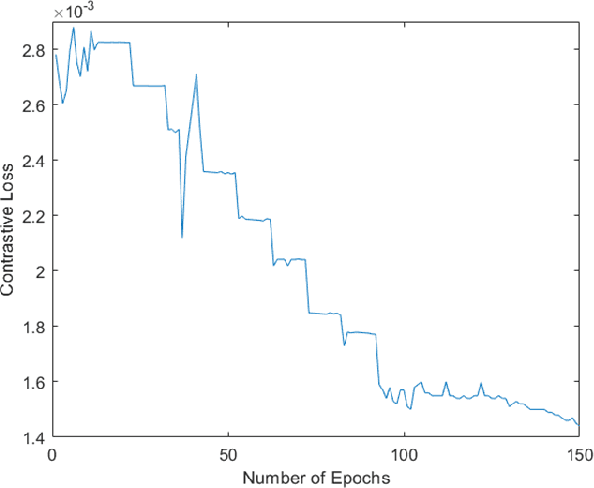
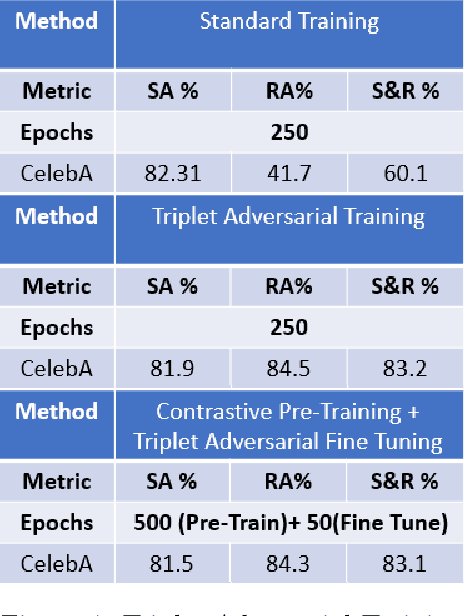
Though much work has been done in the domain of improving the adversarial robustness of facial recognition systems, a surprisingly small percentage of it has focused on self-supervised approaches. In this work, we present an approach that combines Ad-versarial Pre-Training with Triplet Loss AdversarialFine-Tuning. We compare our methods with the pre-trained ResNet50 model that forms the backbone of FaceNet, finetuned on our CelebA dataset. Through comparing adversarial robustness achieved without adversarial training, with triplet loss adversarial training, and our contrastive pre-training combined with triplet loss adversarial fine-tuning, we find that our method achieves comparable results with far fewer epochs re-quired during fine-tuning. This seems promising, increasing the training time for fine-tuning should yield even better results. In addition to this, a modified semi-supervised experiment was conducted, which demonstrated the improvement of contrastive adversarial training with the introduction of small amounts of labels.
Deep Reinforcement Learning for Decentralized Multi-Robot Exploration with Macro Actions
Oct 05, 2021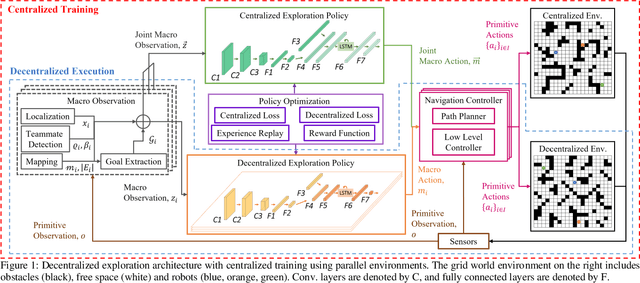
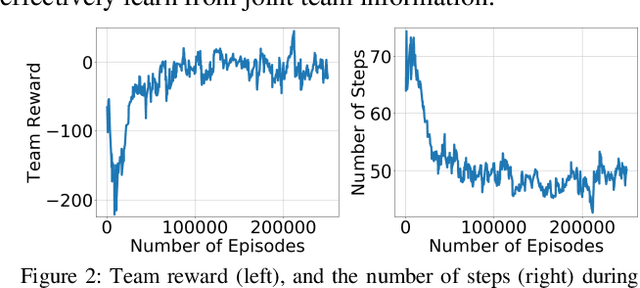
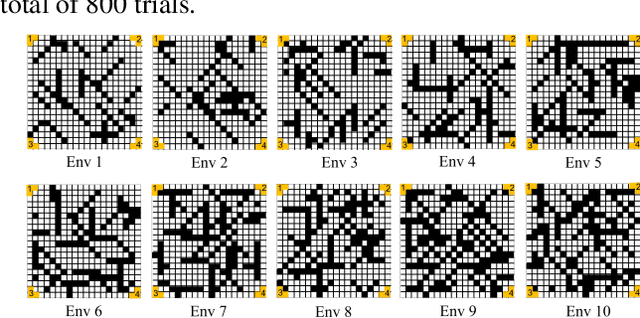
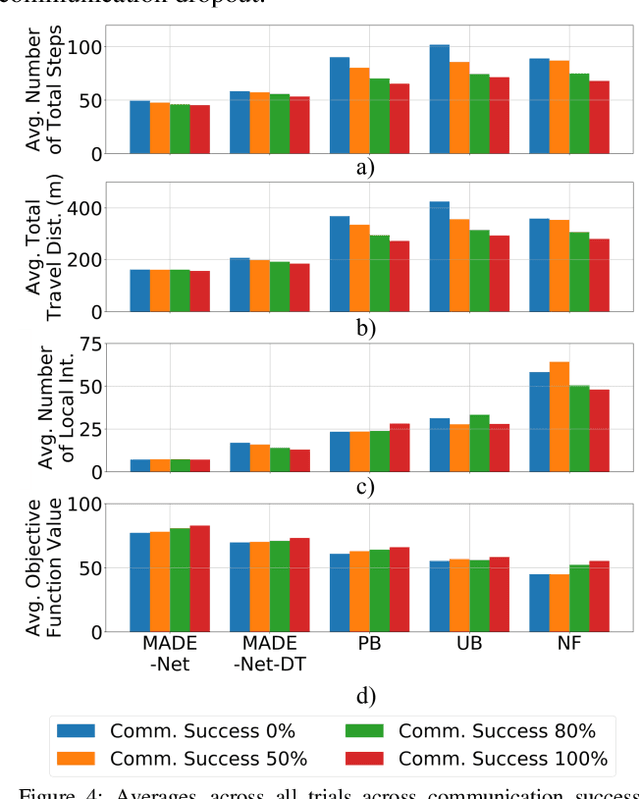
Cooperative multi-robot teams need to be able to explore cluttered and unstructured environments together while dealing with communication challenges. Specifically, during communication dropout, local information about robots can no longer be exchanged to maintain robot team coordination. Therefore, robots need to consider high-level teammate intentions during action selection. In this paper, we present the first Macro Action Decentralized Exploration Network (MADE-Net) using multi-agent deep reinforcement learning to address the challenges of communication dropouts during multi-robot exploration in unseen, unstructured, and cluttered environments. Simulated robot team exploration experiments were conducted and compared to classical and deep reinforcement learning methods. The results showed that our MADE-Net method was able to outperform all benchmark methods in terms of computation time, total travel distance, number of local interactions between robots, and exploration rate across various degrees of communication dropouts; highlighting the effectiveness and robustness of our method.
WareVR: Virtual Reality Interface for Supervision of Autonomous Robotic System Aimed at Warehouse Stocktaking
Oct 21, 2021
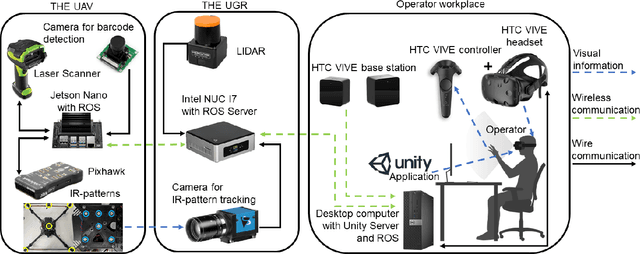
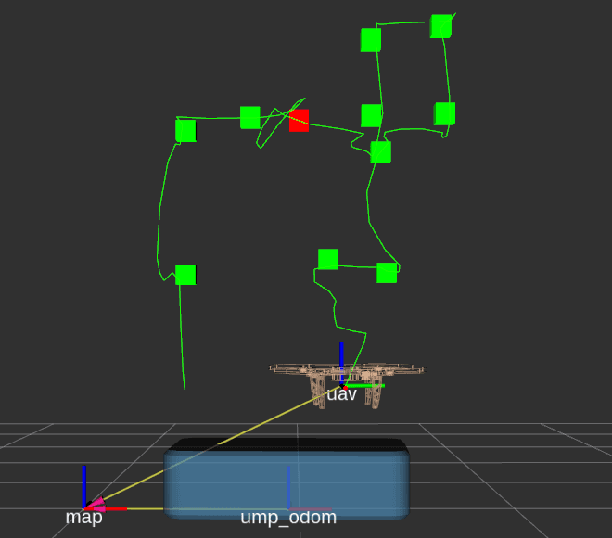

WareVR is a novel human-robot interface based on a virtual reality (VR) application to interact with a heterogeneous robotic system for automated inventory management. We have created an interface to supervise an autonomous robot remotely from a secluded workstation in a warehouse that could benefit during the current pandemic COVID-19 since the stocktaking is a necessary and regular process in warehouses, which involves a group of people. The proposed interface allows regular warehouse workers without experience in robotics to control the heterogeneous robotic system consisting of an unmanned ground vehicle (UGV) and unmanned aerial vehicle (UAV). WareVR provides visualization of the robotic system in a digital twin of the warehouse, which is accompanied by a real-time video stream from the real environment through an on-board UAV camera. Using the WareVR interface, the operator can conduct different levels of stocktaking, monitor the inventory process remotely, and teleoperate the drone for a more detailed inspection. Besides, the developed interface includes remote control of the UAV for intuitive and straightforward human interaction with the autonomous robot for stocktaking. The effectiveness of the VR-based interface was evaluated through the user study in a "visual inspection" scenario.
ORSA: Outlier Robust Stacked Aggregation for Best- and Worst-Case Approximations of Ensemble Systems\
Nov 17, 2021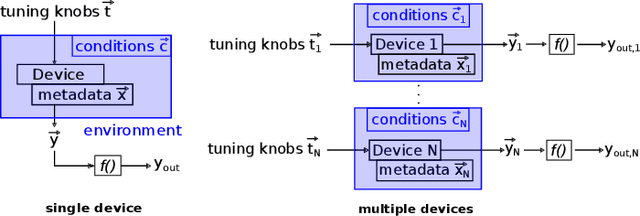
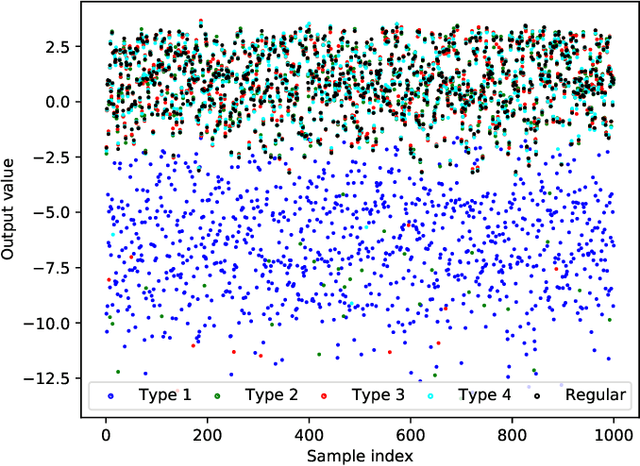
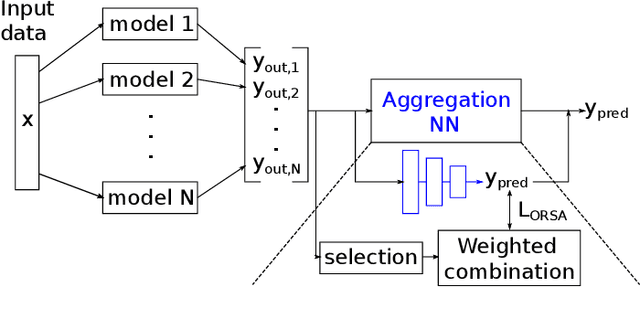
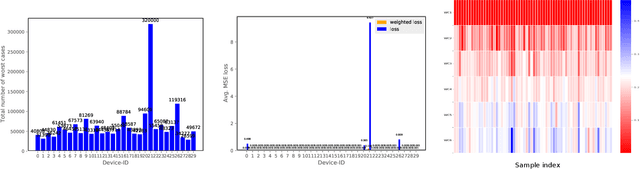
In recent years, the usage of ensemble learning in applications has grown significantly due to increasing computational power allowing the training of large ensembles in reasonable time frames. Many applications, e.g., malware detection, face recognition, or financial decision-making, use a finite set of learning algorithms and do aggregate them in a way that a better predictive performance is obtained than any other of the individual learning algorithms. In the field of Post-Silicon Validation for semiconductor devices (PSV), data sets are typically provided that consist of various devices like, e.g., chips of different manufacturing lines. In PSV, the task is to approximate the underlying function of the data with multiple learning algorithms, each trained on a device-specific subset, instead of improving the performance of arbitrary classifiers on the entire data set. Furthermore, the expectation is that an unknown number of subsets describe functions showing very different characteristics. Corresponding ensemble members, which are called outliers, can heavily influence the approximation. Our method aims to find a suitable approximation that is robust to outliers and represents the best or worst case in a way that will apply to as many types as possible. A 'soft-max' or 'soft-min' function is used in place of a maximum or minimum operator. A Neural Network (NN) is trained to learn this 'soft-function' in a two-stage process. First, we select a subset of ensemble members that is representative of the best or worst case. Second, we combine these members and define a weighting that uses the properties of the Local Outlier Factor (LOF) to increase the influence of non-outliers and to decrease outliers. The weighting ensures robustness to outliers and makes sure that approximations are suitable for most types.