 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Scalable Representation Learning for Multivariate Time Series
Jan 30, 2019
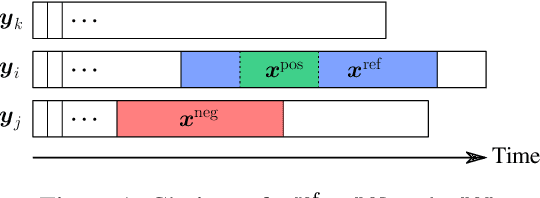
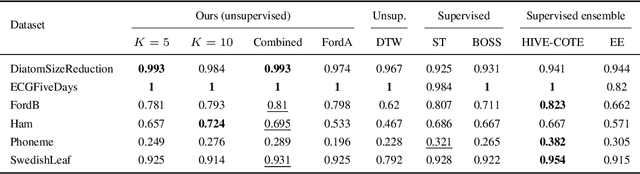
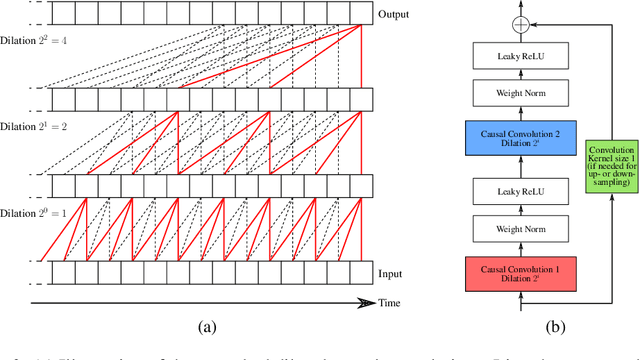
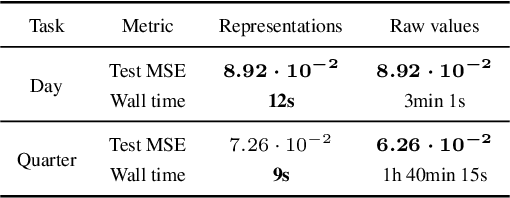
Time series constitute a challenging data type for machine learning algorithms, due to their highly variable lengths and sparse labeling in practice. In this paper, we tackle this challenge by proposing an unsupervised method to learn universal embeddings of time series. Unlike previous works, it is scalable with respect to their length and we demonstrate the quality, transferability and practicability of the learned representations with thorough experiments and comparisons. To this end, we combine an encoder based on causal dilated convolutions with a triplet loss employing time-based negative sampling, obtaining general-purpose representations for variable length and multivariate time series.
Robust Distributed Optimization With Randomly Corrupted Gradients
Jun 28, 2021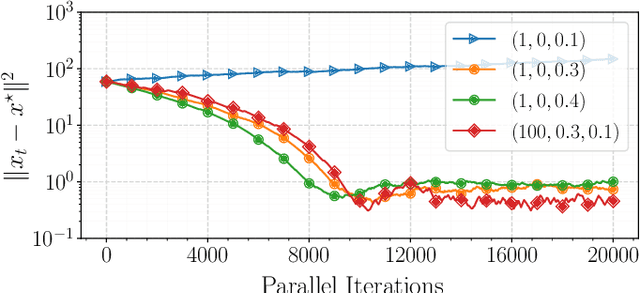
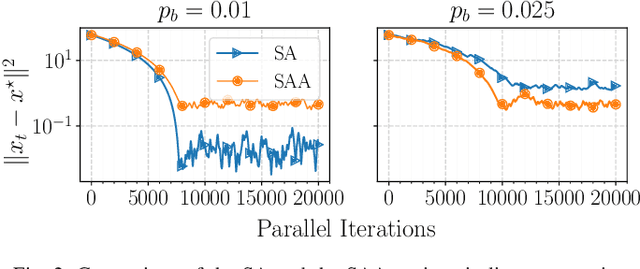
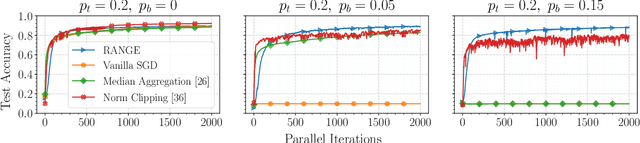
In this paper, we propose a first-order distributed optimization algorithm that is provably robust to Byzantine failures-arbitrary and potentially adversarial behavior, where all the participating agents are prone to failure. We model each agent's state over time as a two-state Markov chain that indicates Byzantine or trustworthy behaviors at different time instants. We set no restrictions on the maximum number of Byzantine agents at any given time. We design our method based on three layers of defense: 1) Temporal gradient averaging, 2) robust aggregation, and 3) gradient normalization. We study two settings for stochastic optimization, namely Sample Average Approximation and Stochastic Approximation, and prove that for strongly convex and smooth non-convex cost functions, our algorithm achieves order-optimal statistical error and convergence rates.
Learning Scene Dynamics from Point Cloud Sequences
Nov 16, 2021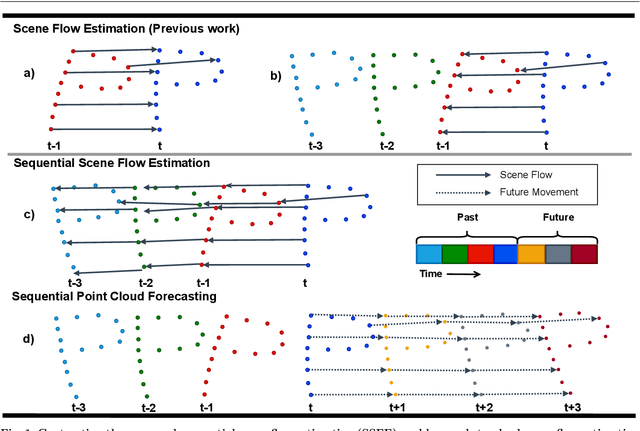

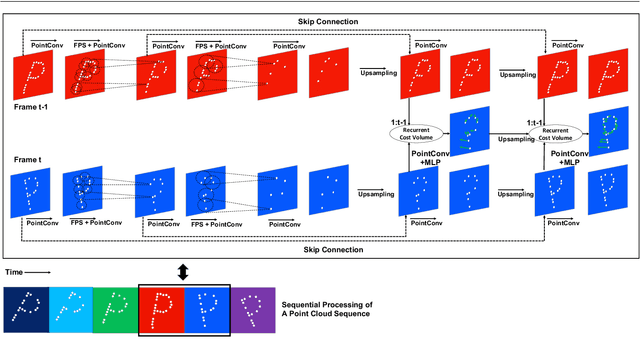
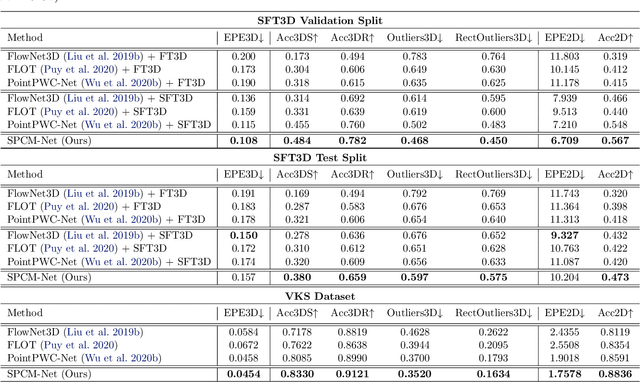
Understanding 3D scenes is a critical prerequisite for autonomous agents. Recently, LiDAR and other sensors have made large amounts of data available in the form of temporal sequences of point cloud frames. In this work, we propose a novel problem -- sequential scene flow estimation (SSFE) -- that aims to predict 3D scene flow for all pairs of point clouds in a given sequence. This is unlike the previously studied problem of scene flow estimation which focuses on two frames. We introduce the SPCM-Net architecture, which solves this problem by computing multi-scale spatiotemporal correlations between neighboring point clouds and then aggregating the correlation across time with an order-invariant recurrent unit. Our experimental evaluation confirms that recurrent processing of point cloud sequences results in significantly better SSFE compared to using only two frames. Additionally, we demonstrate that this approach can be effectively modified for sequential point cloud forecasting (SPF), a related problem that demands forecasting future point cloud frames. Our experimental results are evaluated using a new benchmark for both SSFE and SPF consisting of synthetic and real datasets. Previously, datasets for scene flow estimation have been limited to two frames. We provide non-trivial extensions to these datasets for multi-frame estimation and prediction. Due to the difficulty of obtaining ground truth motion for real-world datasets, we use self-supervised training and evaluation metrics. We believe that this benchmark will be pivotal to future research in this area. All code for benchmark and models will be made accessible.
Adaptive Transmit Waveform Design
Nov 16, 2021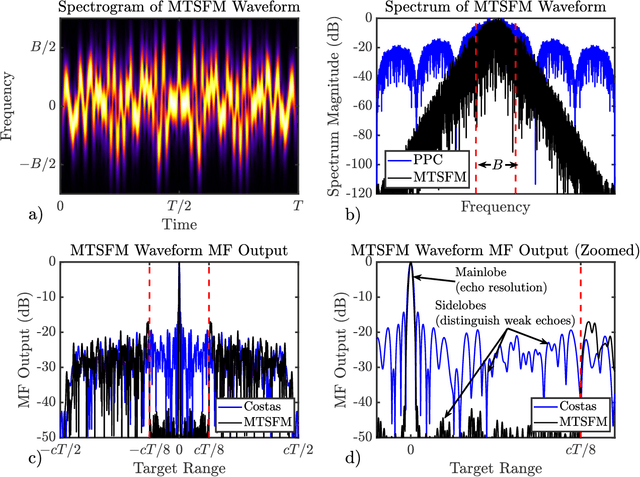
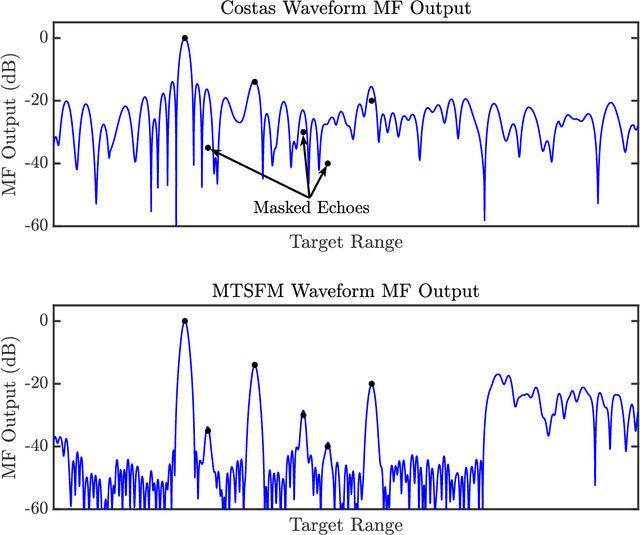
Recent research efforts in the Anti-Submarine Warfare (ASW) community have focused on developing sonar systems that adapt to their acoustic environment, referred to as "cognitive" sonars. Cognitive active sonar systems utilize principles of the perception action cycle of cognition to leverage information gathered from earlier sensing interactions with the underwater acoustic environment. This in turn informs the selection of system parameters to optimize target detection, classification, localization, and tracking performance in that acoustic environment. Of the many system parameters such a cognitive sonar system could potentially adapt, the acoustic signal transmitted into the medium, also known as the transmit waveform, has a profound impact on system performance. Many of the physical characteristics of the acoustic environment are contained in the return echo signal that is composed of amplitude scaled (target strength), time-delayed (target range) and Doppler shifted (target range-rate) echoes of the transmit waveform. This paper briefly describes a spectrally compact adaptive FM waveform model using Multi-Tone Sinusoidal Frequency Modulation (MTSFM). The MTSFM waveform's frequency and phase modulation functions are composed of a finite set of weighted sinusoidal harmonics. The weights for each harmonic are utilized as a discrete set of design coefficients. Adjusting these coefficients results in constant amplitude, spectrally compact FM waveforms with unique characteristics. The adaptability of the MTSFM combined with its transmitter friendly properties make it an attractive waveform type for a variety of active sonar applications and may provide a cognitive sonar system the ability to generate a complementary set of finely tuned waveforms for the novel scenarios and environments that it may encounter.
Convergence of Batch Asynchronous Stochastic Approximation With Applications to Reinforcement Learning
Sep 08, 2021The stochastic approximation (SA) algorithm is a widely used probabilistic method for finding a solution to an equation of the form $\mathbf{f}(\boldsymbol{\theta}) = \mathbf{0}$ where $\mathbf{f} : \mathbb{R}^d \rightarrow \mathbb{R}^d$, when only noisy measurements of $\mathbf{f}(\cdot)$ are available. In the literature to date, one can make a distinction between "synchronous" updating, whereby the entire vector of the current guess $\boldsymbol{\theta}_t$ is updated at each time, and "asynchronous" updating, whereby ony one component of $\boldsymbol{\theta}_t$ is updated. In convex and nonconvex optimization, there is also the notion of "batch" updating, whereby some but not all components of $\boldsymbol{\theta}_t$ are updated at each time $t$. In addition, there is also a distinction between using a "local" clock versus a "global" clock. In the literature to date, convergence proofs when a local clock is used make the assumption that the measurement noise is an i.i.d\ sequence, an assumption that does not hold in Reinforcement Learning (RL). In this note, we provide a general theory of convergence for batch asymchronous stochastic approximation (BASA), that works whether the updates use a local clock or a global clock, for the case where the measurement noises form a martingale difference sequence. This is the most general result to date and encompasses all others.
Guided Evolution for Neural Architecture Search
Oct 28, 2021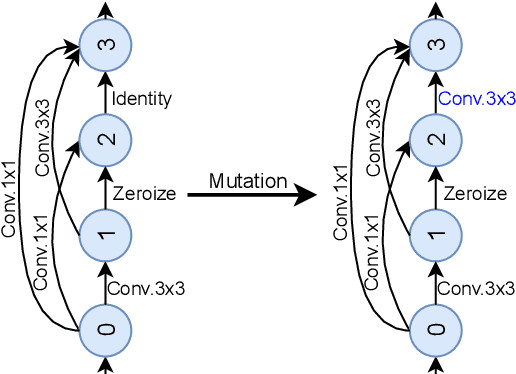
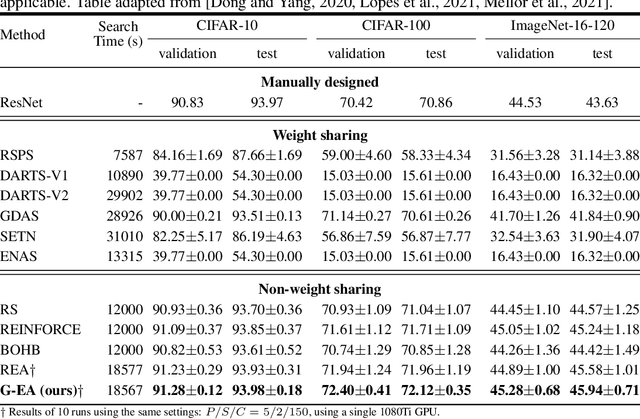
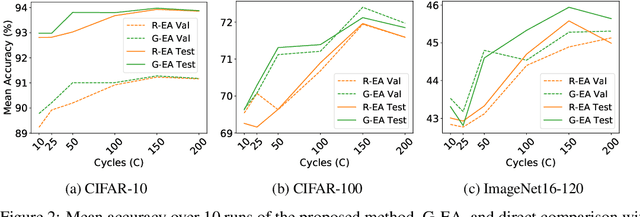
Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Deep Real-Time Decoding of bimanual grip force from EEG & fNIRS
Mar 09, 2021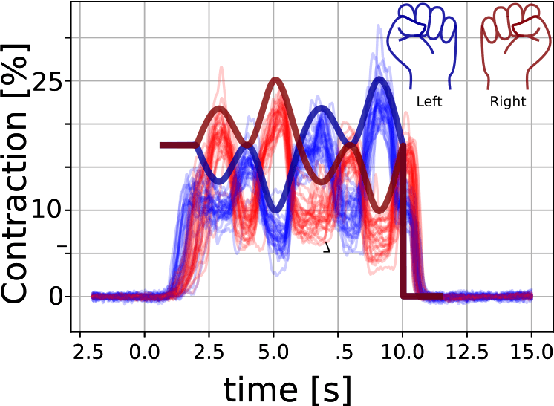
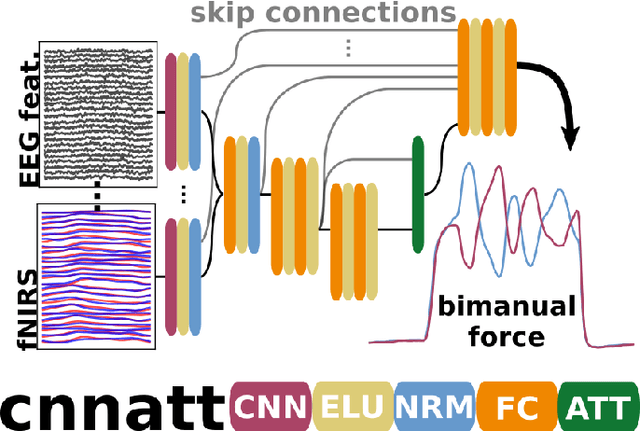
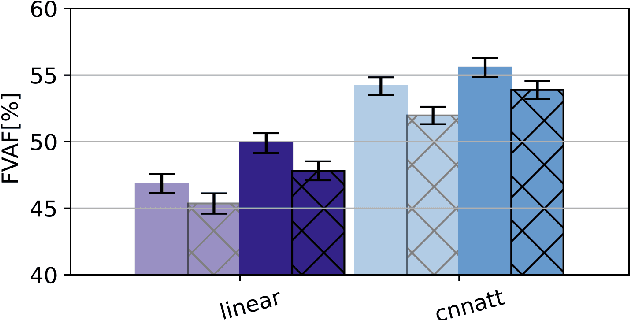
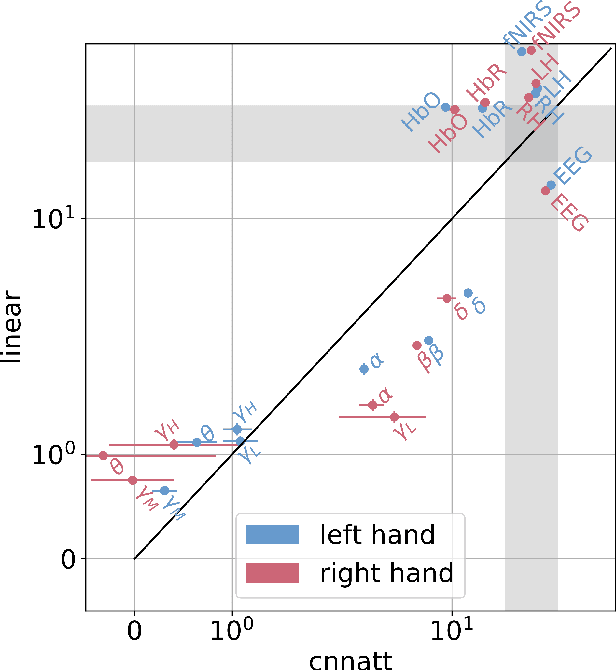
Non-invasive cortical neural interfaces have only achieved modest performance in cortical decoding of limb movements and their forces, compared to invasive brain-computer interfaces (BCIs). While non-invasive methodologies are safer, cheaper and vastly more accessible technologies, signals suffer from either poor resolution in the space domain (EEG) or the temporal domain (BOLD signal of functional Near Infrared Spectroscopy, fNIRS). The non-invasive BCI decoding of bimanual force generation and the continuous force signal has not been realised before and so we introduce an isometric grip force tracking task to evaluate the decoding. We find that combining EEG and fNIRS using deep neural networks works better than linear models to decode continuous grip force modulations produced by the left and the right hand. Our multi-modal deep learning decoder achieves 55.2 FVAF[%] in force reconstruction and improves the decoding performance by at least 15% over each individual modality. Our results show a way to achieve continuous hand force decoding using cortical signals obtained with non-invasive mobile brain imaging has immediate impact for rehabilitation, restoration and consumer applications.
HASHTAG: Hash Signatures for Online Detection of Fault-Injection Attacks on Deep Neural Networks
Nov 02, 2021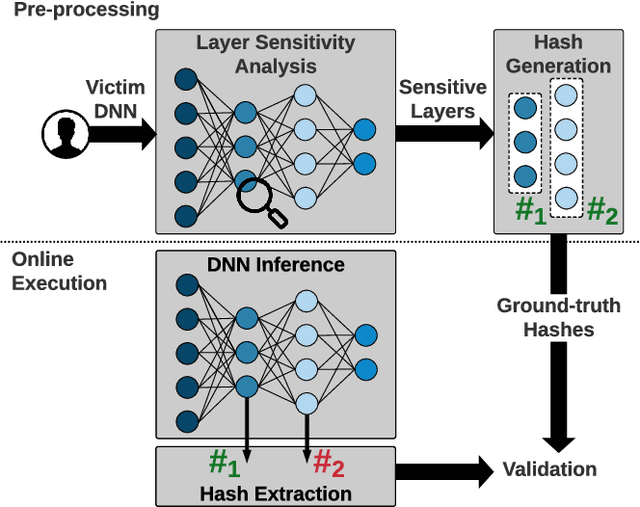
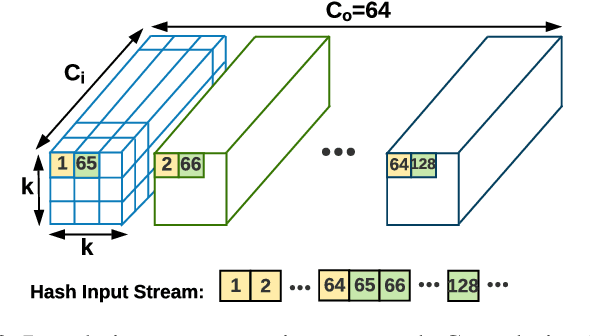
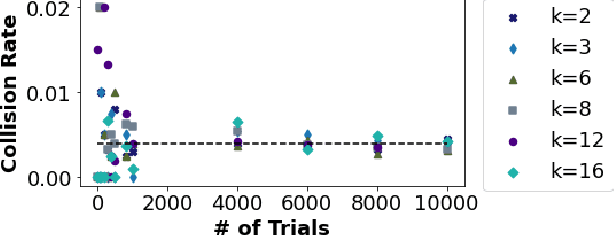
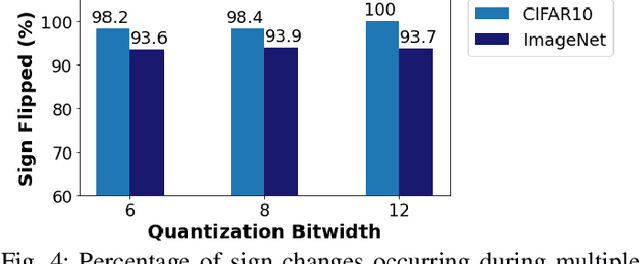
We propose HASHTAG, the first framework that enables high-accuracy detection of fault-injection attacks on Deep Neural Networks (DNNs) with provable bounds on detection performance. Recent literature in fault-injection attacks shows the severe DNN accuracy degradation caused by bit flips. In this scenario, the attacker changes a few weight bits during DNN execution by tampering with the program's DRAM memory. To detect runtime bit flips, HASHTAG extracts a unique signature from the benign DNN prior to deployment. The signature is later used to validate the integrity of the DNN and verify the inference output on the fly. We propose a novel sensitivity analysis scheme that accurately identifies the most vulnerable DNN layers to the fault-injection attack. The DNN signature is then constructed by encoding the underlying weights in the vulnerable layers using a low-collision hash function. When the DNN is deployed, new hashes are extracted from the target layers during inference and compared against the ground-truth signatures. HASHTAG incorporates a lightweight methodology that ensures a low-overhead and real-time fault detection on embedded platforms. Extensive evaluations with the state-of-the-art bit-flip attack on various DNNs demonstrate the competitive advantage of HASHTAG in terms of both attack detection and execution overhead.
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021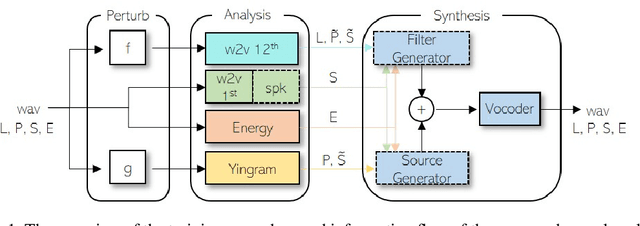

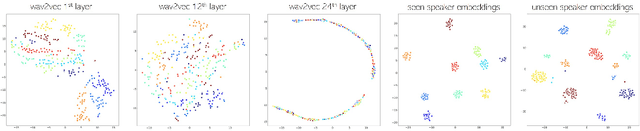
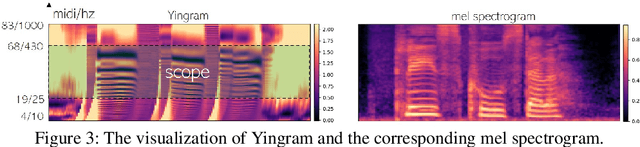
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
DFW-PP: Dynamic Feature Weighting based Popularity Prediction for Social Media Content
Oct 16, 2021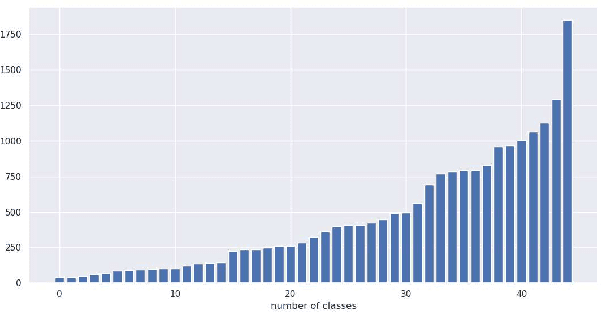
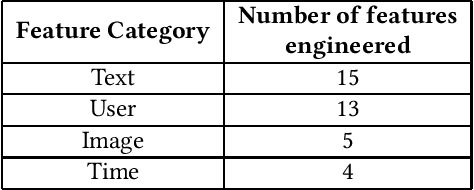
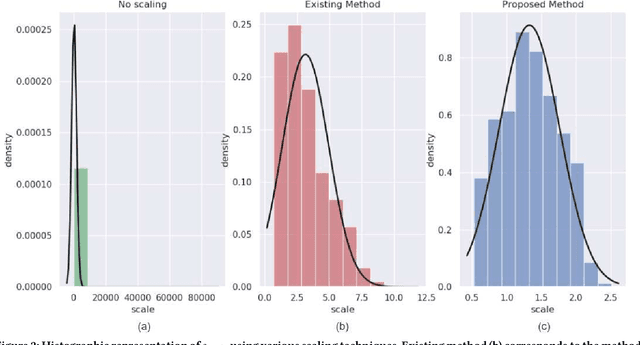

The increasing popularity of social media platforms makes it important to study user engagement, which is a crucial aspect of any marketing strategy or business model. The over-saturation of content on social media platforms has persuaded us to identify the important factors that affect content popularity. This comes from the fact that only an iota of the humongous content available online receives the attention of the target audience. Comprehensive research has been done in the area of popularity prediction using several Machine Learning techniques. However, we observe that there is still significant scope for improvement in analyzing the social importance of media content. We propose the DFW-PP framework, to learn the importance of different features that vary over time. Further, the proposed method controls the skewness of the distribution of the features by applying a log-log normalization. The proposed method is experimented with a benchmark dataset, to show promising results. The code will be made publicly available at https://github.com/chaitnayabasava/DFW-PP.