 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Radio Frequency Interference Management with Free-Space Optical Communication and Photonic Signal Processing
Jul 25, 2021
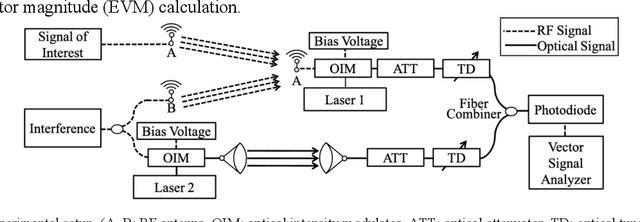
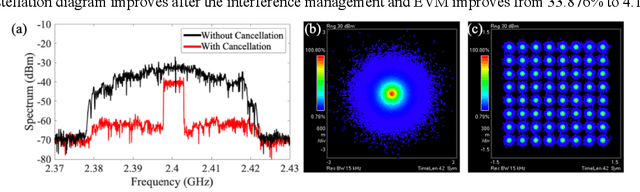
We design and experimentally demonstrate a radio frequency interference management system with free-space optical communication and photonic signal processing. The system provides real-time interference cancellation in 6 GHz wide bandwidth.
Evaluating deep transfer learning for whole-brain cognitive decoding
Nov 01, 2021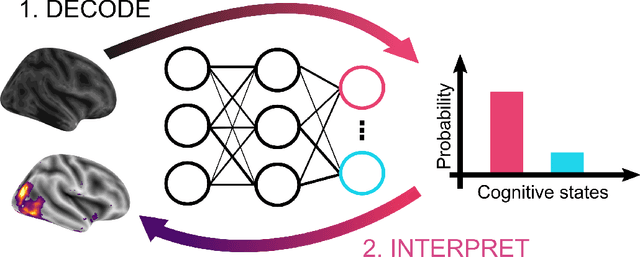
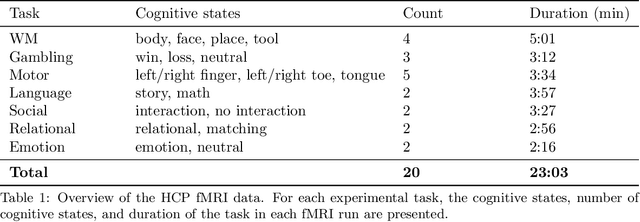

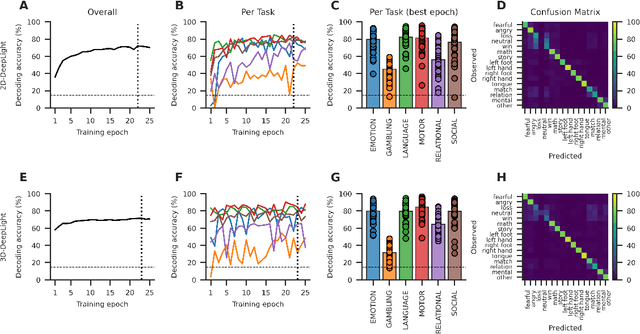
Research in many fields has shown that transfer learning (TL) is well-suited to improve the performance of deep learning (DL) models in datasets with small numbers of samples. This empirical success has triggered interest in the application of TL to cognitive decoding analyses with functional neuroimaging data. Here, we systematically evaluate TL for the application of DL models to the decoding of cognitive states (e.g., viewing images of faces or houses) from whole-brain functional Magnetic Resonance Imaging (fMRI) data. We first pre-train two DL architectures on a large, public fMRI dataset and subsequently evaluate their performance in an independent experimental task and a fully independent dataset. The pre-trained models consistently achieve higher decoding accuracies and generally require less training time and data than model variants that were not pre-trained, clearly underlining the benefits of pre-training. We demonstrate that these benefits arise from the ability of the pre-trained models to reuse many of their learned features when training with new data, providing deeper insights into the mechanisms giving rise to the benefits of pre-training. Yet, we also surface nuanced challenges for whole-brain cognitive decoding with DL models when interpreting the decoding decisions of the pre-trained models, as these have learned to utilize the fMRI data in unforeseen and counterintuitive ways to identify individual cognitive states.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021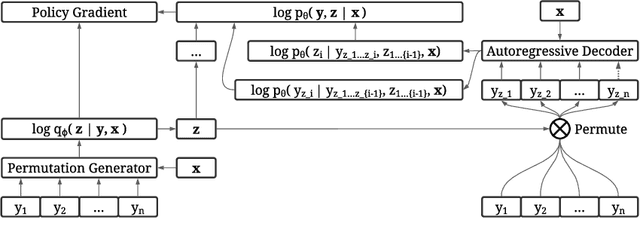
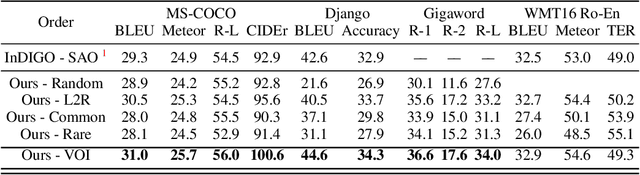
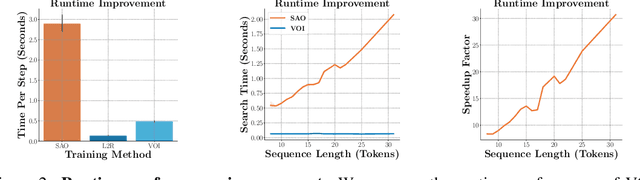
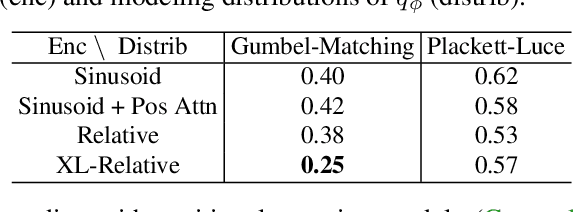
The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.
Comparing Heuristics, Constraint Optimization, and Reinforcement Learning for an Industrial 2D Packing Problem
Oct 27, 2021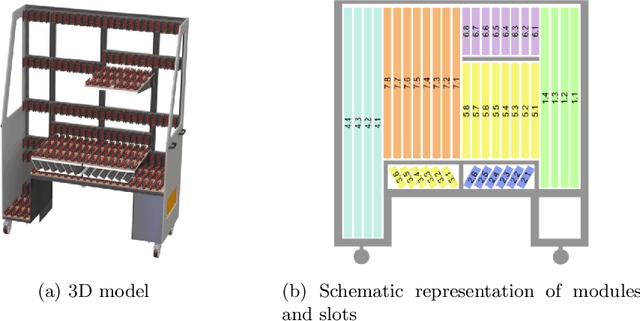
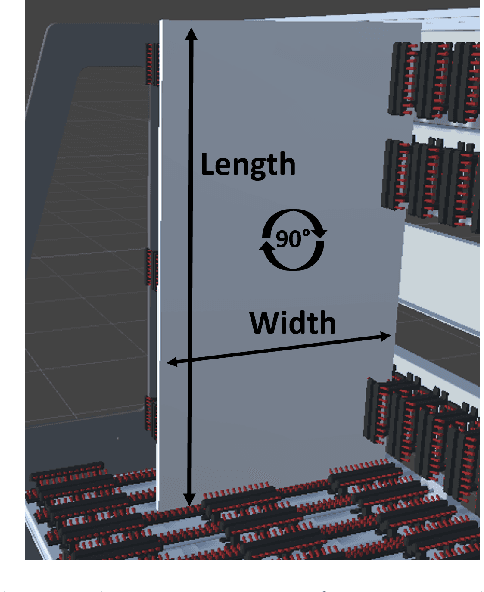
Cutting and Packing problems are occurring in different industries with a direct impact on the revenue of businesses. Generally, the goal in Cutting and Packing is to assign a set of smaller objects to a set of larger objects. To solve Cutting and Packing problems, practitioners can resort to heuristic and exact methodologies. Lately, machine learning is increasingly used for solving such problems. This paper considers a 2D packing problem from the furniture industry, where a set of wooden workpieces must be assigned to different modules of a trolley in the most space-saving way. We present an experimental setup to compare heuristics, constraint optimization, and deep reinforcement learning for the given problem. The used methodologies and their results get collated in terms of their solution quality and runtime. In the given use case a greedy heuristic produces optimal results and outperforms the other approaches in terms of runtime. Constraint optimization also produces optimal results but requires more time to perform. The deep reinforcement learning approach did not always produce optimal or even feasible solutions. While we assume this could be remedied with more training, considering the good results with the heuristic, deep reinforcement learning seems to be a bad fit for the given use case.
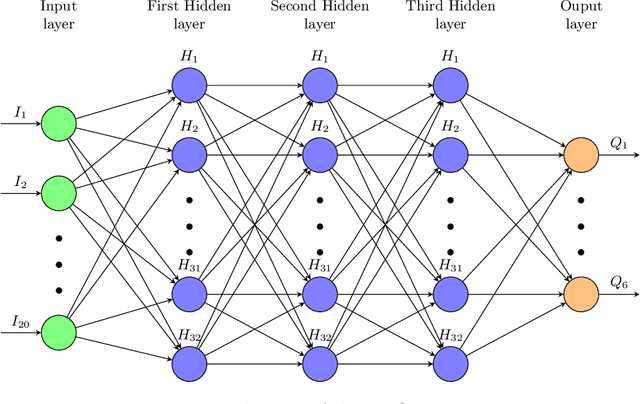
Cognitively Inspired Learning of Incremental Drifting Concepts
Oct 09, 2021
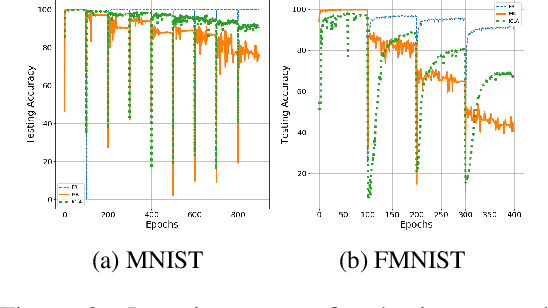
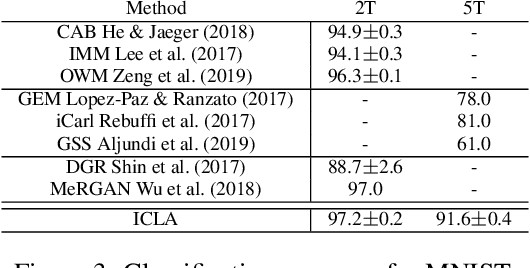
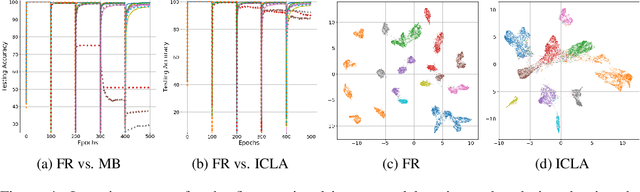
Humans continually expand their learned knowledge to new domains and learn new concepts without any interference with past learned experiences. In contrast, machine learning models perform poorly in a continual learning setting, where input data distribution changes over time. Inspired by the nervous system learning mechanisms, we develop a computational model that enables a deep neural network to learn new concepts and expand its learned knowledge to new domains incrementally in a continual learning setting. We rely on the Parallel Distributed Processing theory to encode abstract concepts in an embedding space in terms of a multimodal distribution. This embedding space is modeled by internal data representations in a hidden network layer. We also leverage the Complementary Learning Systems theory to equip the model with a memory mechanism to overcome catastrophic forgetting through implementing pseudo-rehearsal. Our model can generate pseudo-data points for experience replay and accumulate new experiences to past learned experiences without causing cross-task interference.
A Decoupled Uncertainty Model for MRI Segmentation Quality Estimation
Sep 06, 2021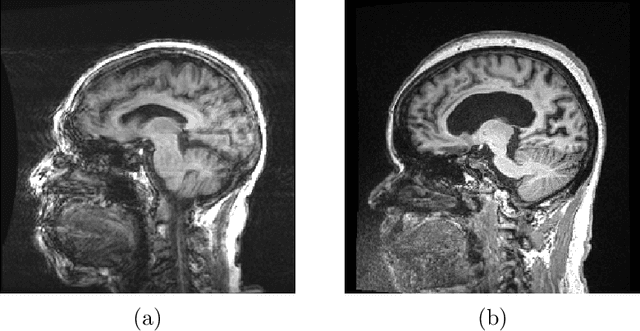
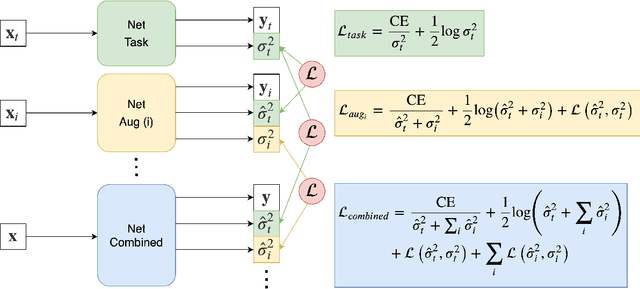
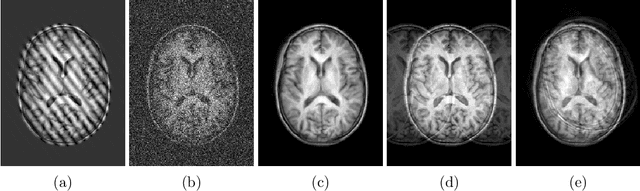
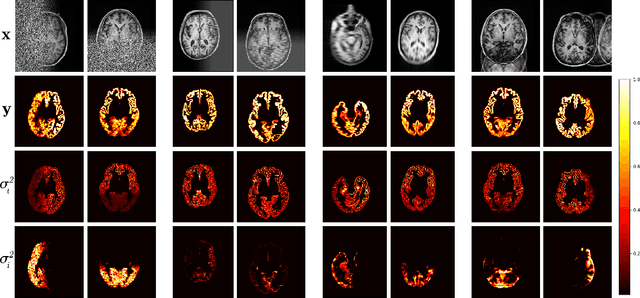
Quality control (QC) of MR images is essential to ensure that downstream analyses such as segmentation can be performed successfully. Currently, QC is predominantly performed visually and subjectively, at significant time and operator cost. We aim to automate the process using a probabilistic network that estimates segmentation uncertainty through a heteroscedastic noise model, providing a measure of task-specific quality. By augmenting training images with k-space artefacts, we propose a novel CNN architecture to decouple sources of uncertainty related to the task and different k-space artefacts in a self-supervised manner. This enables the prediction of separate uncertainties for different types of data degradation. While the uncertainty predictions reflect the presence and severity of artefacts, the network provides more robust and generalisable segmentation predictions given the quality of the data. We show that models trained with artefact augmentation provide informative measures of uncertainty on both simulated artefacts and problematic real-world images identified by human raters, both qualitatively and quantitatively in the form of error bars on volume measurements. Relating artefact uncertainty to segmentation Dice scores, we observe that our uncertainty predictions provide a better estimate of MRI quality from the point of view of the task (gray matter segmentation) compared to commonly used metrics of quality including signal-to-noise ratio (SNR) and contrast-to-noise ratio (CNR), hence providing a real-time quality metric indicative of segmentation quality.
Deep-Learning Based Auction-Driven Beamforming for Wireless Information and Power Transfer
Jul 07, 2021
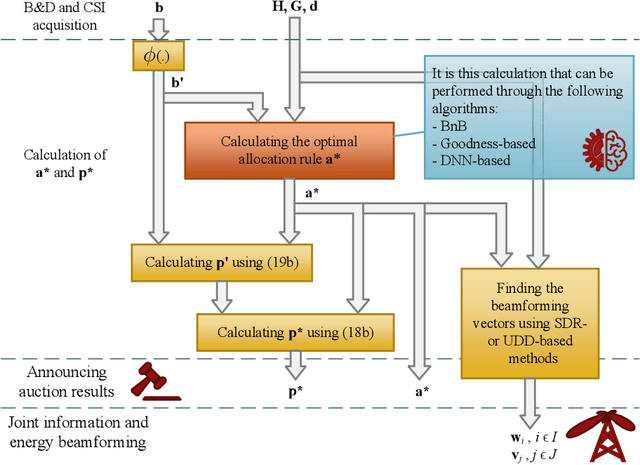
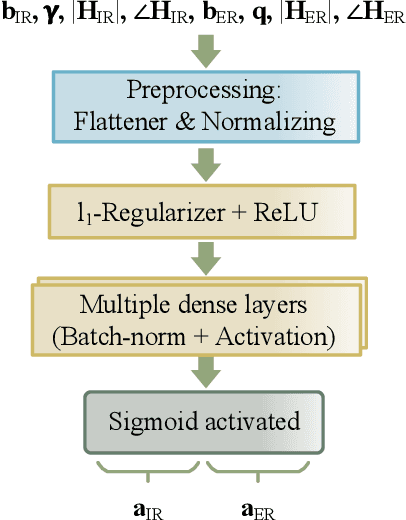
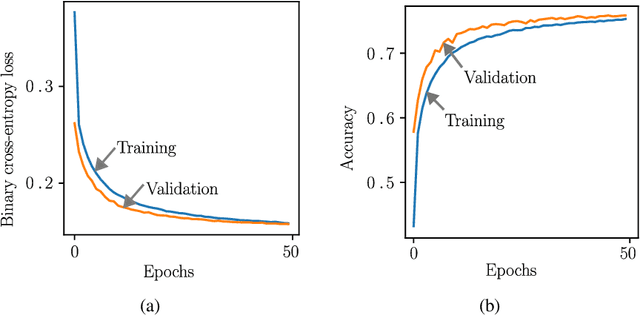
In this paper, we design a deep learning based resource allocation framework, in the form of an auction, for simultaneous information and power transfer from a hybrid access point (AP) to information devices and energy harvesting devices, respectively. Using Myerson's lemma and the concept of virtual welfare maximization, we develop an optimal dominant-strategy incentive-compatible mechanism for the AP to maximize its expected revenue, based on the devices' bid profiles, valuation distributions, demand profiles, and channel state information. In so doing, we formulate the revenue maximization problem, which is a mixed-integer non-linear program, and propose an efficient Branch-and-Bound (BnB) algorithm to solve the problem using semidefinite relaxation technique in each branch. Since the problem has exponential time complexity, using BnB algorithms can be impractical for real-time applications. To circumvent this, a deep neural network (DNN) is proposed, and trained to predict the optimal mechanism for beamforming the data and the energy towards the information and energy devices, respectively. We use the BnB algorithm to solve the problem offline and populate the training dataset. The proposed DNN architecture is indeed a multi-layer perceptron, which is trained well to map the heterogeneous input to the desired output with high accuracy. Furthermore, we propose a heuristic iterative solution whose accuracy performance is comparable to that of the DNN-based solution. The heuristic solution has polynomial time complexity whereas the DNN-based solution has linear time complexity.
Customs Fraud Detection in the Presence of Concept Drift
Sep 29, 2021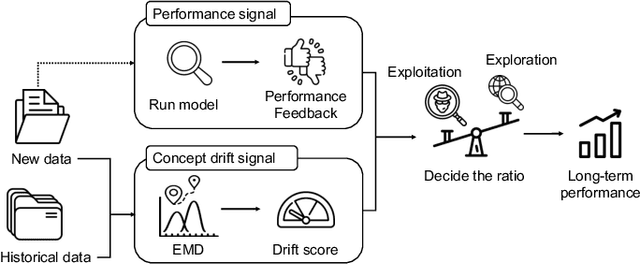
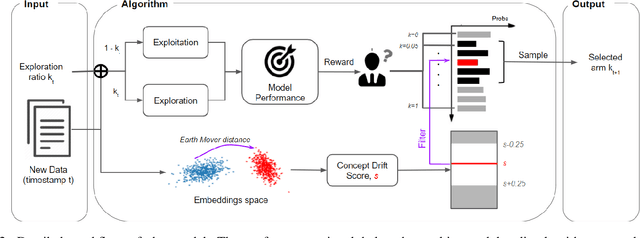
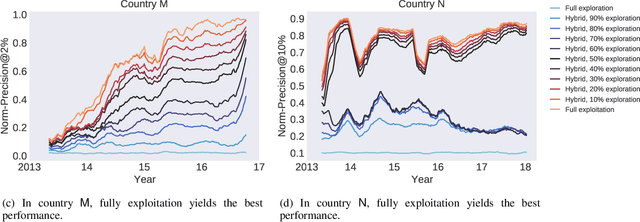
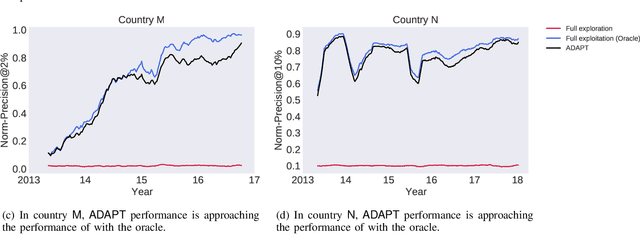
Capturing the changing trade pattern is critical in customs fraud detection. As new goods are imported and novel frauds arise, a drift-aware fraud detection system is needed to detect both known frauds and unknown frauds within a limited budget. The current paper proposes ADAPT, an adaptive selection method that controls the balance between exploitation and exploration strategies used for customs fraud detection. ADAPT makes use of the model performance trends and the amount of concept drift to determine the best exploration ratio at every time. Experiments on data from four countries over several years show that each country requires a different amount of exploration for maintaining its fraud detection system. We find the system with ADAPT can gradually adapt to the dataset and find the appropriate amount of exploration ratio with high performance.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 01, 2021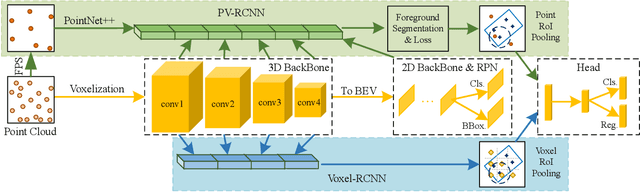
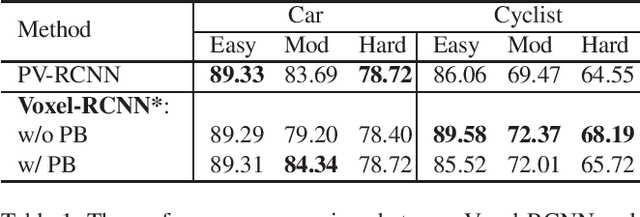

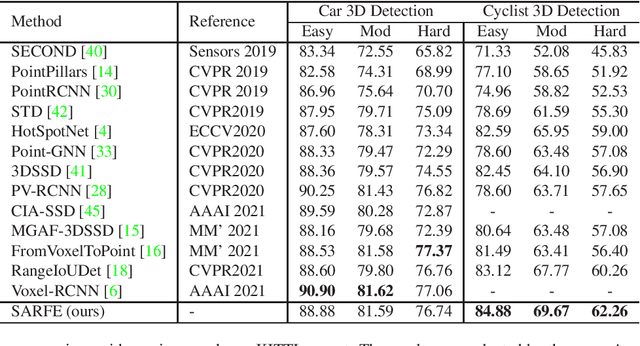
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.
Think Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
Oct 16, 2021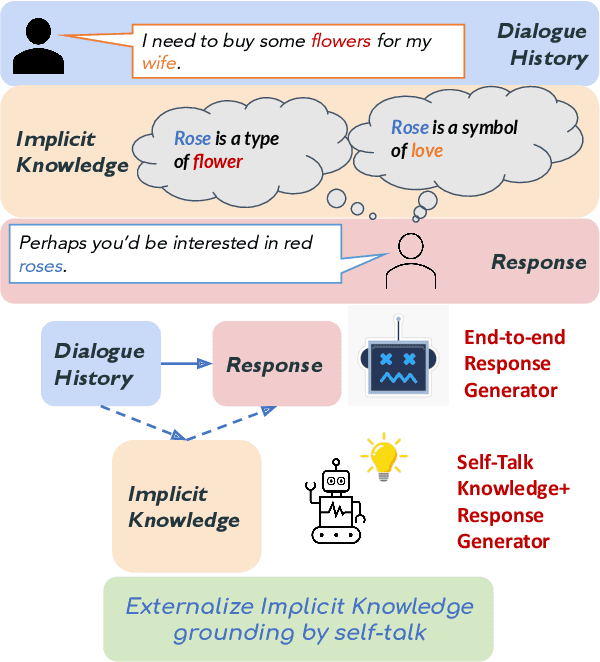
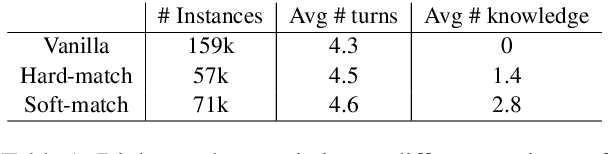
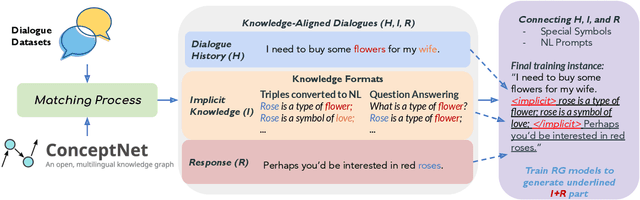

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.