 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Real-time Mispronunciation Detection in Kids' Speech
Mar 03, 2020
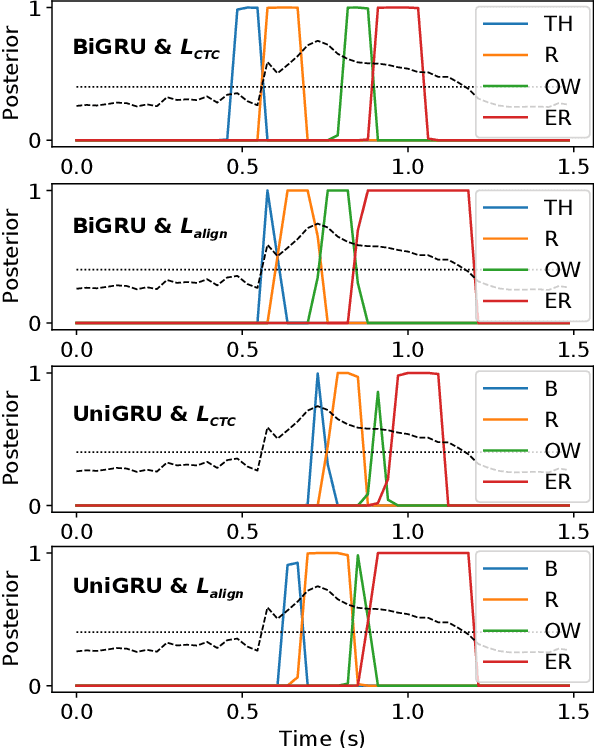
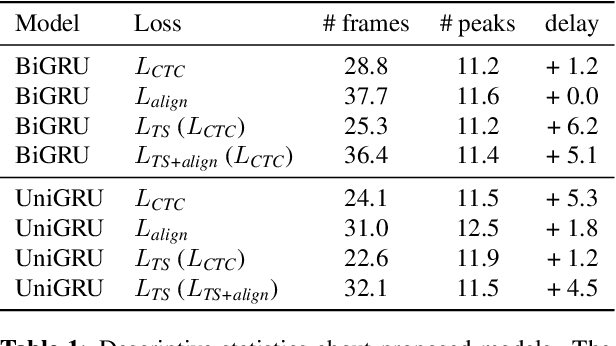
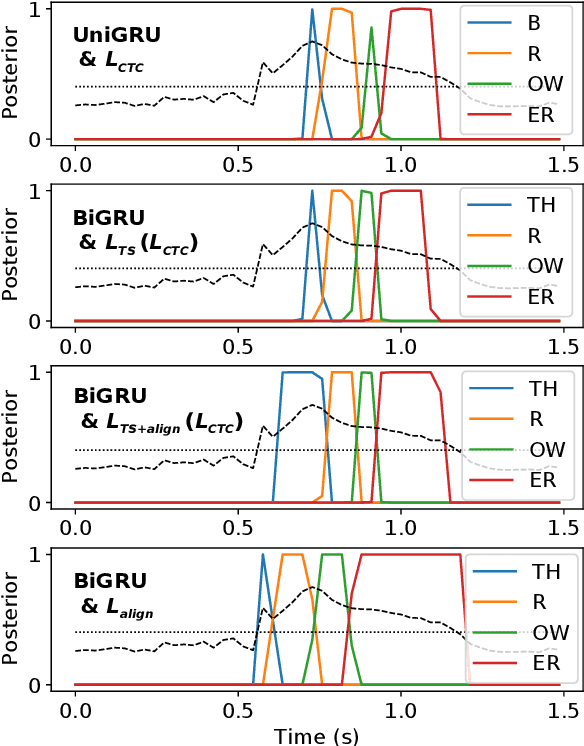
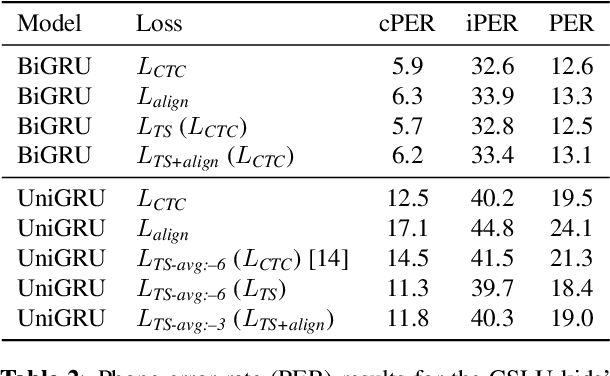
Modern mispronunciation detection and diagnosis systems have seen significant gains in accuracy due to the introduction of deep learning. However, these systems have not been evaluated for the ability to be run in real-time, an important factor in applications that provide rapid feedback. In particular, the state-of-the-art uses bi-directional recurrent networks, where a uni-directional network may be more appropriate. Teacher-student learning is a natural approach to use to improve a uni-directional model, but when using a CTC objective, this is limited by poor alignment of outputs to evidence. We address this limitation by trying two loss terms for improving the alignments of our models. One loss is an "alignment loss" term that encourages outputs only when features do not resemble silence. The other loss term uses a uni-directional model as teacher model to align the bi-directional model. Our proposed model uses these aligned bi-directional models as teacher models. Experiments on the CSLU kids' corpus show that these changes decrease the latency of the outputs, and improve the detection rates, with a trade-off between these goals.
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 03, 2021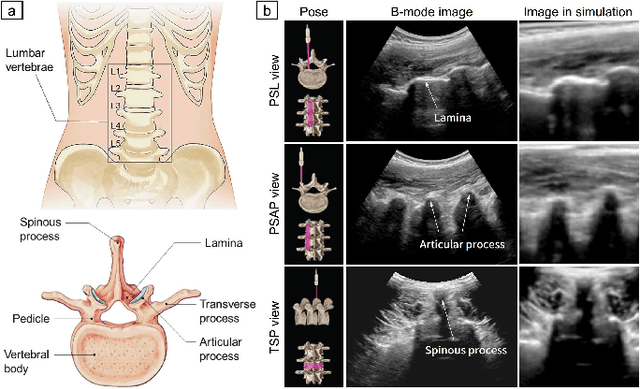
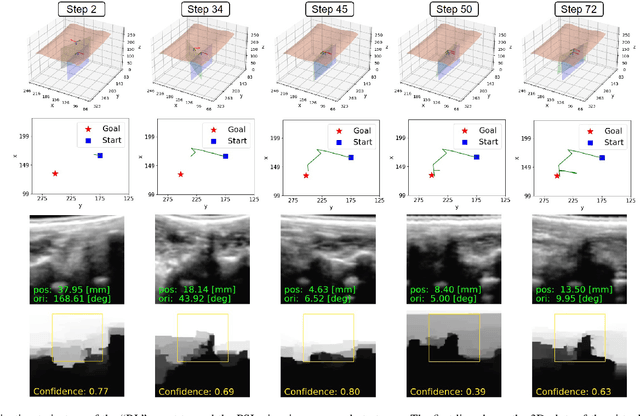
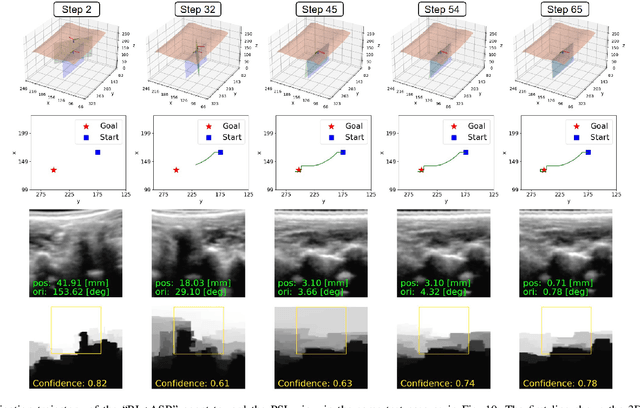
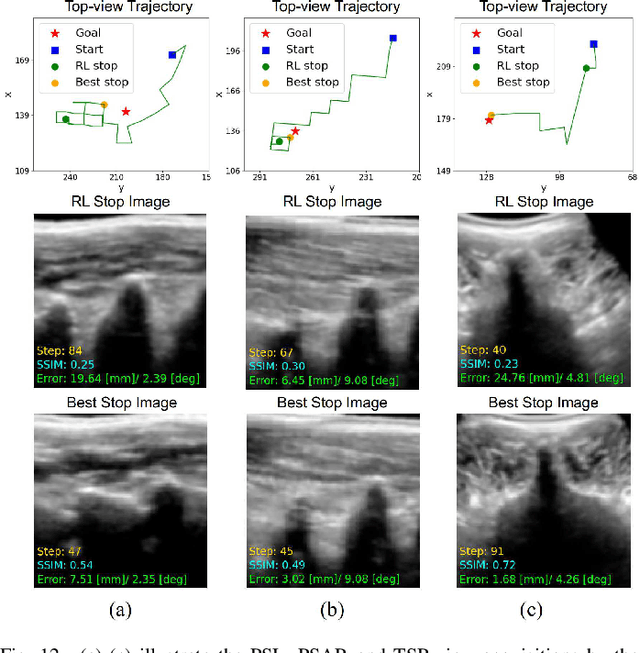
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from $17$ volunteers. The average navigation accuracy toward different standard views achieves $5.18mm/5.25^\circ$ and $12.87mm/17.49^\circ$ in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
TranSMS: Transformers for Super-Resolution Calibration in Magnetic Particle Imaging
Nov 03, 2021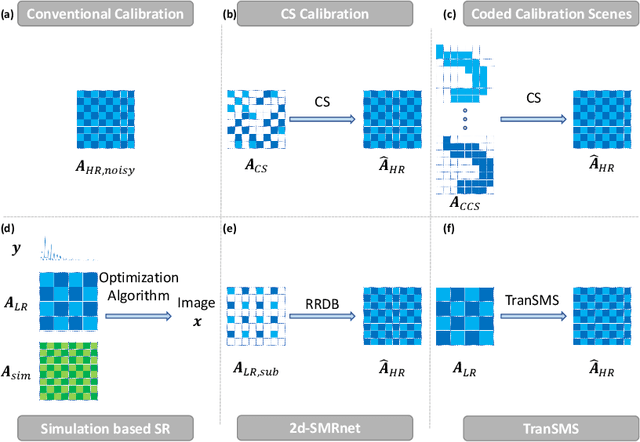
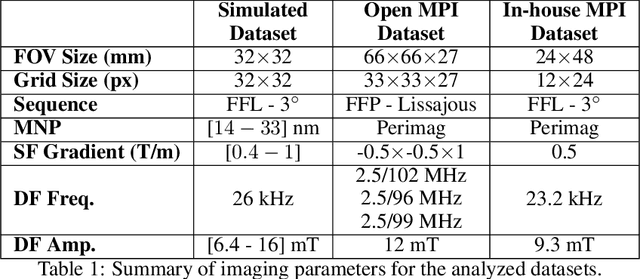
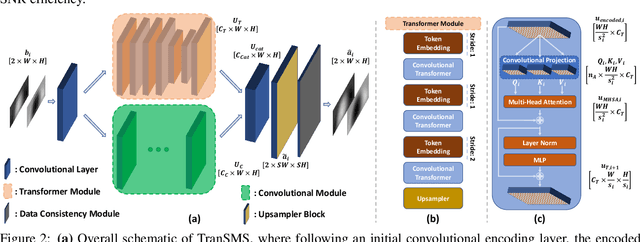
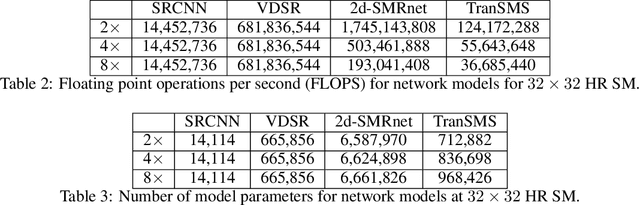
Magnetic particle imaging (MPI) is a recent modality that offers exceptional contrast for magnetic nanoparticles (MNP) at high spatio-temporal resolution. A common procedure in MPI starts with a calibration scan to measure the system matrix (SM), which is then used to setup an inverse problem to reconstruct images of the particle distribution during subsequent scans. This calibration enables the reconstruction to sensitively account for various system imperfections. Yet time-consuming SM measurements have to be repeated under notable drifts or changes in system properties. Here, we introduce a novel deep learning approach for accelerated MPI calibration based on transformers for SM super-resolution (TranSMS). Low-resolution SM measurements are performed using large MNP samples for improved signal-to-noise ratio efficiency, and the high-resolution SM is super-resolved via a model-based deep network. TranSMS leverages a vision transformer module to capture contextual relationships in low-resolution input images, a dense convolutional module for localizing high-resolution image features, and a data-consistency module to ensure consistency to measurements. Demonstrations on simulated and experimental data indicate that TranSMS achieves significantly improved SM recovery and image reconstruction in MPI, while enabling acceleration up to 64-fold during two-dimensional calibration.
Towards automatic detection and classification of orca (Orcinus orca) calls using cross-correlation methods
Nov 03, 2021

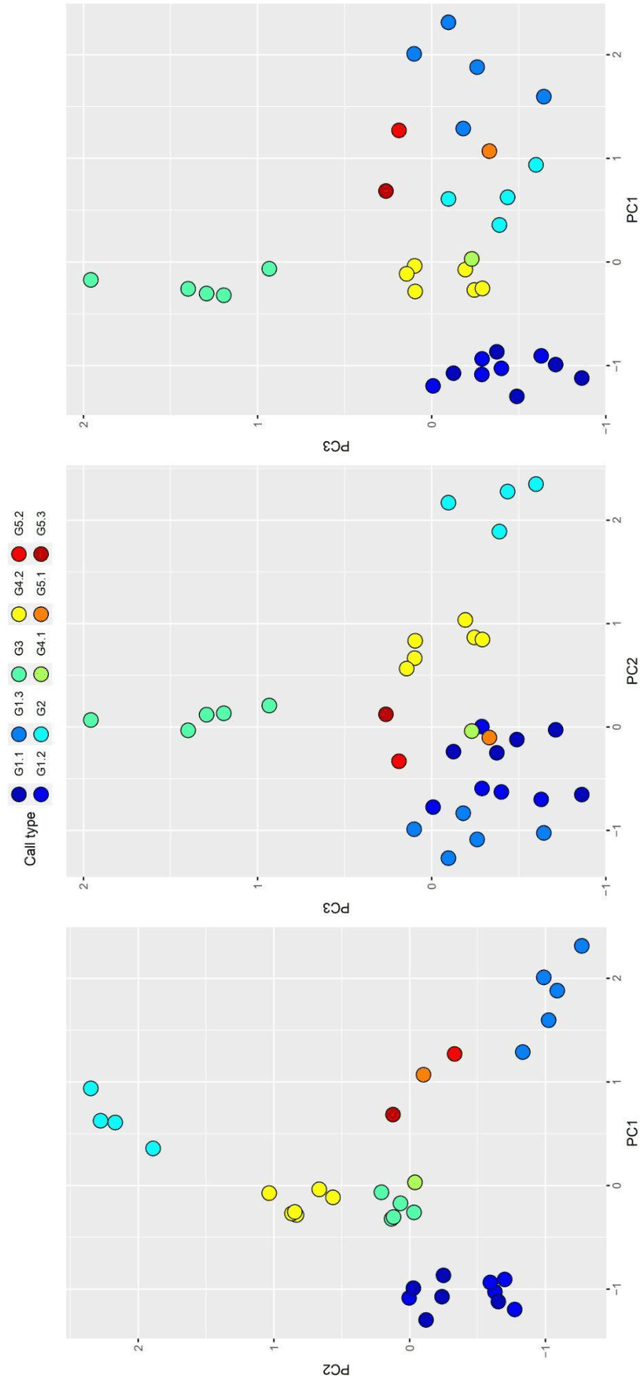
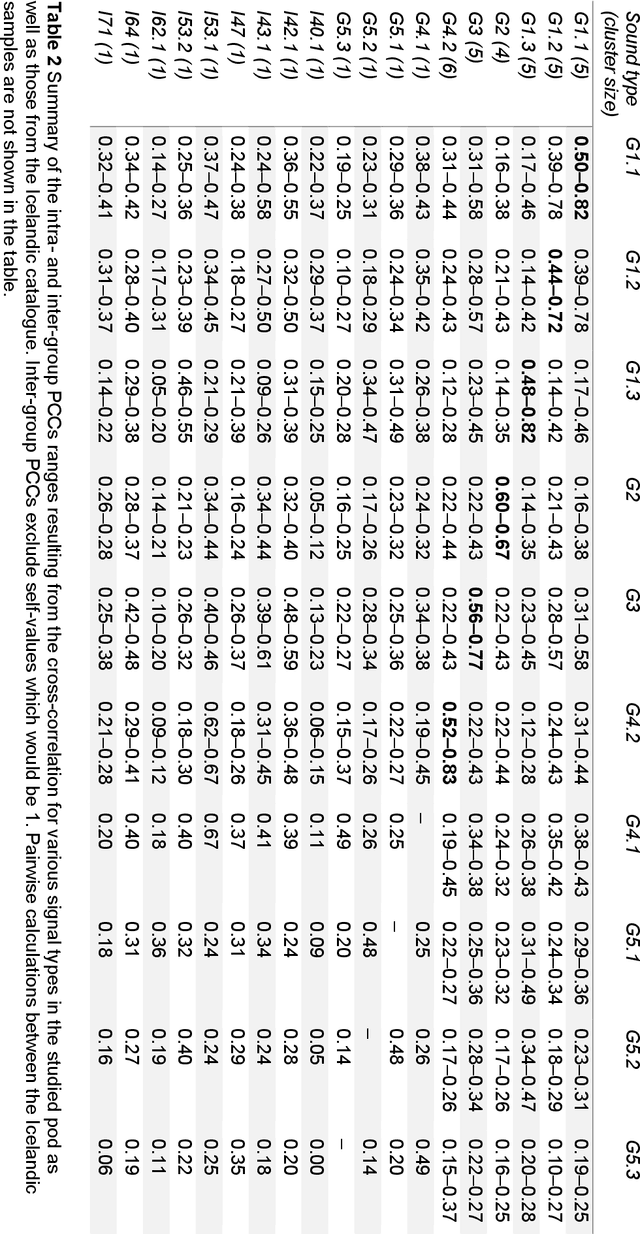
Orca (Orcinus orca) is known for complex vocalisation. Their social structure consists of pods and clans sharing unique dialects due to geographic isolation. Sound type repertoires are fundamental for monitoring orca populations and are typically created visually and aurally. An orca pod occurring in the Ligurian Sea (Pelagos Sanctuary) in December 2019 provided a unique occasion for long-term recordings. The numerous data collected with the bottom recorder were analysed with a traditional human-driven inspection to create a repertoire of this pod and to compare it to catalogues from different orca populations (Icelandic and Antarctic) investigating its origins. Automatic signal detection and cross-correlation methods (R package warbleR) were used for the first time in orca studies. We found the Pearson cross-correlation method to be efficient for most pairwise calculations (> 85%) but with false positives. One sound type from our repertoire presented a high positive match (range 0.62-0.67) with one from the Icelandic catalogue, which was confirmed visually and aurally. Our first attempt to automatically classify orca sound types presented limitations due to background noise and sound complexity of orca communication. We show cross-correlation methods can be a powerful tool for sound type classification in combination with conventional methods.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Sep 23, 2021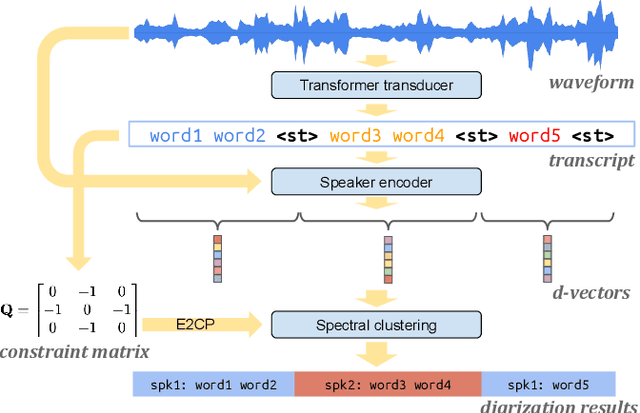

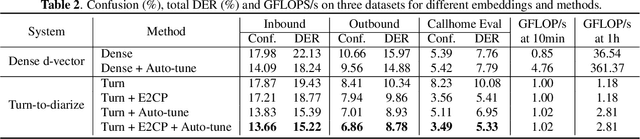
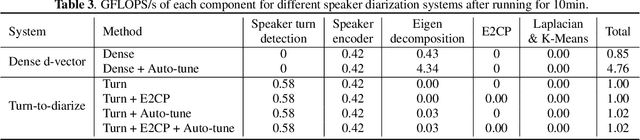
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
A New Algorithm based on Extent Bit-array for Computing Formal Concepts
Oct 29, 2021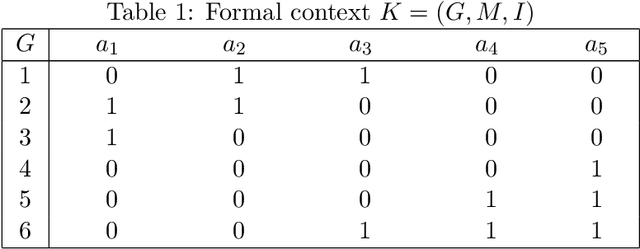


The emergence of Formal Concept Analysis (FCA) as a data analysis technique has increased the need for developing algorithms which can compute formal concepts quickly. The current efficient algorithms for FCA are variants of the Close-By-One (CbO) algorithm, such as In-Close2, In-Close3 and In-Close4, which are all based on horizontal storage of contexts. In this paper, based on algorithm In-Close4, a new algorithm based on the vertical storage of contexts, called In-Close5, is proposed, which can significantly reduce both the time complexity and space complexity of algorithm In-Close4. Technically, the new algorithm stores both context and extent of a concept as a vertical bit-array, while within In-Close4 algorithm the context is stored only as a horizontal bit-array, which is very slow in finding the intersection of two extent sets. Experimental results demonstrate that the proposed algorithm is much more effective than In-Close4 algorithm, and it also has a broader scope of applicability in computing formal concept in which one can solve the problems that cannot be solved by the In-Close4 algorithm.
Auto-Encoding Knowledge Graph for Unsupervised Medical Report Generation
Nov 08, 2021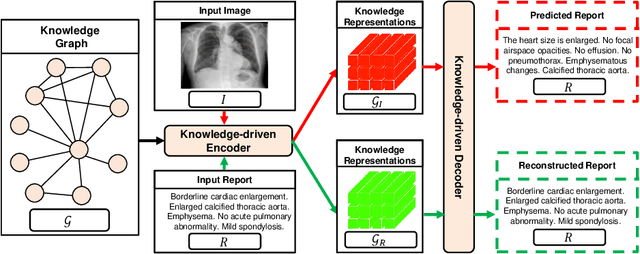
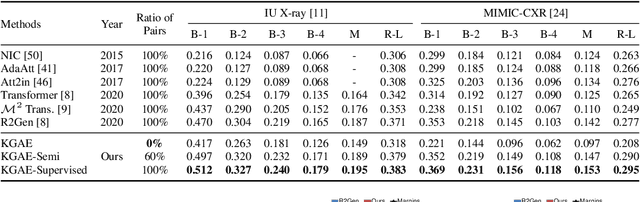
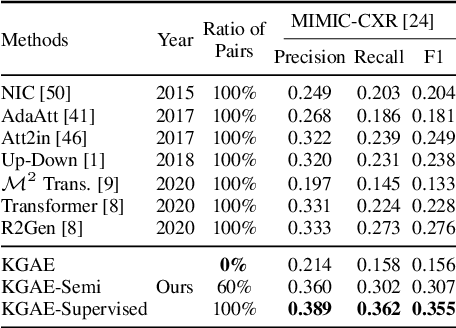

Medical report generation, which aims to automatically generate a long and coherent report of a given medical image, has been receiving growing research interests. Existing approaches mainly adopt a supervised manner and heavily rely on coupled image-report pairs. However, in the medical domain, building a large-scale image-report paired dataset is both time-consuming and expensive. To relax the dependency on paired data, we propose an unsupervised model Knowledge Graph Auto-Encoder (KGAE) which accepts independent sets of images and reports in training. KGAE consists of a pre-constructed knowledge graph, a knowledge-driven encoder and a knowledge-driven decoder. The knowledge graph works as the shared latent space to bridge the visual and textual domains; The knowledge-driven encoder projects medical images and reports to the corresponding coordinates in this latent space and the knowledge-driven decoder generates a medical report given a coordinate in this space. Since the knowledge-driven encoder and decoder can be trained with independent sets of images and reports, KGAE is unsupervised. The experiments show that the unsupervised KGAE generates desirable medical reports without using any image-report training pairs. Moreover, KGAE can also work in both semi-supervised and supervised settings, and accept paired images and reports in training. By further fine-tuning with image-report pairs, KGAE consistently outperforms the current state-of-the-art models on two datasets.
Event Detection on Dynamic Graphs
Oct 23, 2021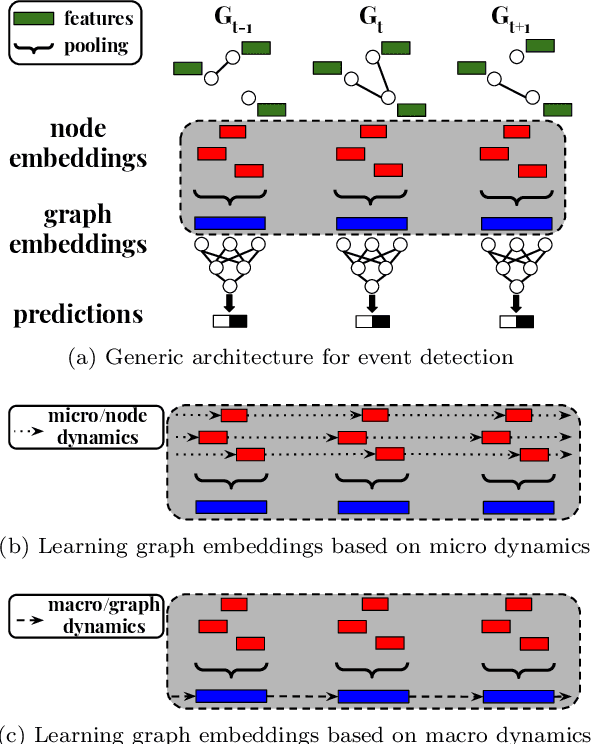
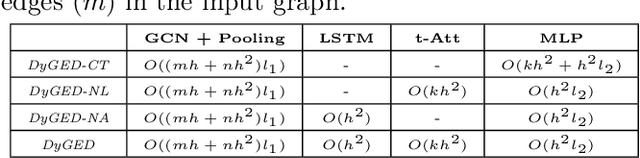
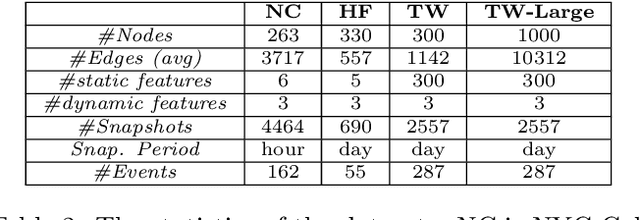
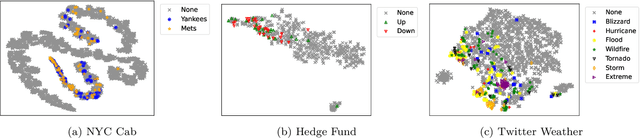
Event detection is a critical task for timely decision-making in graph analytics applications. Despite the recent progress towards deep learning on graphs, event detection on dynamic graphs presents particular challenges to existing architectures. Real-life events are often associated with sudden deviations of the normal behavior of the graph. However, existing approaches for dynamic node embedding are unable to capture the graph-level dynamics related to events. In this paper, we propose DyGED, a simple yet novel deep learning model for event detection on dynamic graphs. DyGED learns correlations between the graph macro dynamics -- i.e. a sequence of graph-level representations -- and labeled events. Moreover, our approach combines structural and temporal self-attention mechanisms to account for application-specific node and time importances effectively. Our experimental evaluation, using a representative set of datasets, demonstrates that DyGED outperforms competing solutions in terms of event detection accuracy by up to 8.5% while being more scalable than the top alternatives. We also present case studies illustrating key features of our model.
Disentangled Sequence to Sequence Learning for Compositional Generalization
Oct 09, 2021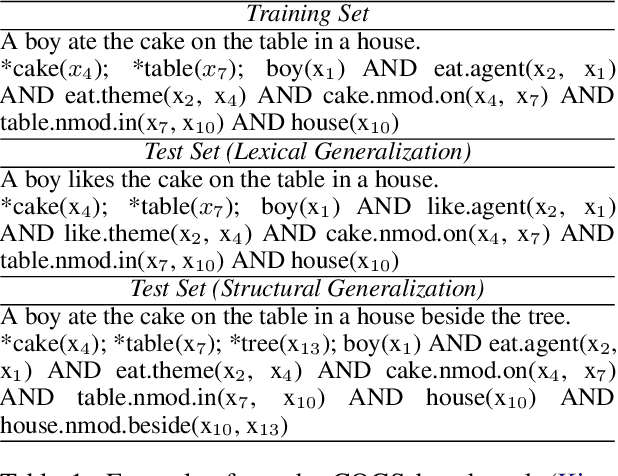
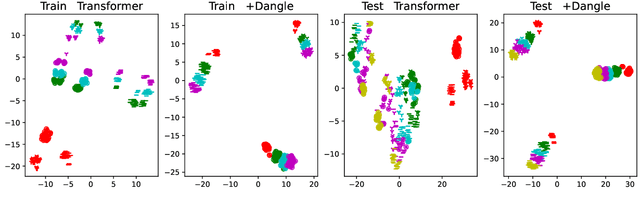
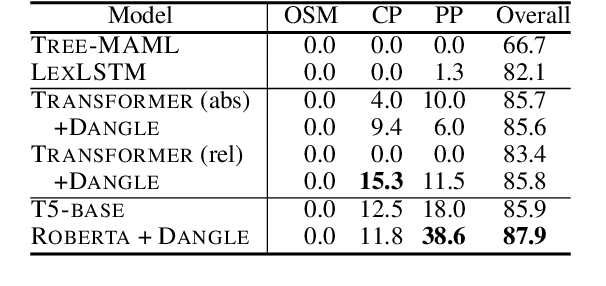
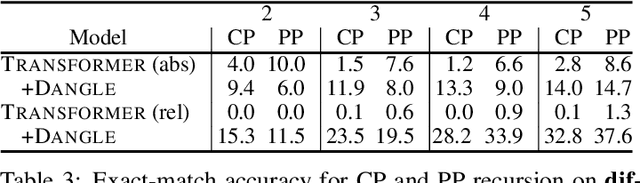
There is mounting evidence that existing neural network models, in particular the very popular sequence-to-sequence architecture, struggle with compositional generalization, i.e., the ability to systematically generalize to unseen compositions of seen components. In this paper we demonstrate that one of the reasons hindering compositional generalization relates to the representations being entangled. We propose an extension to sequence-to-sequence models which allows us to learn disentangled representations by adaptively re-encoding (at each time step) the source input. Specifically, we condition the source representations on the newly decoded target context which makes it easier for the encoder to exploit specialized information for each prediction rather than capturing all source information in a single forward pass. Experimental results on semantic parsing and machine translation empirically show that our proposal yields more disentangled representations and better generalization.
Influence of image noise on crack detection performance of deep convolutional neural networks
Nov 03, 2021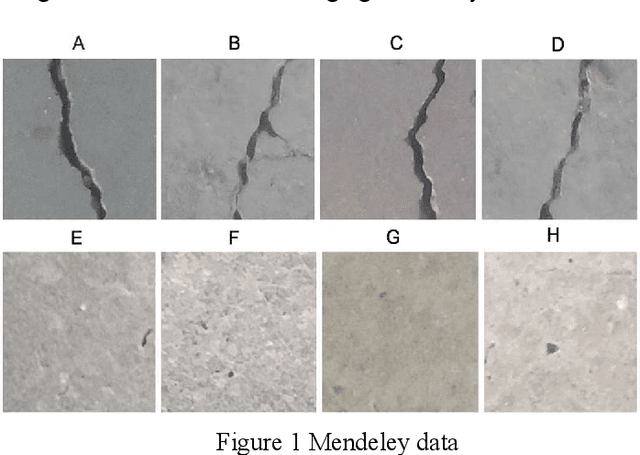
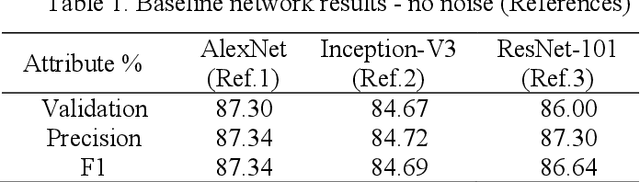

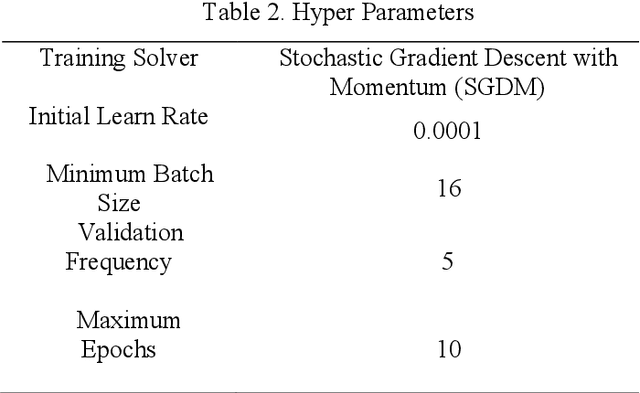
Development of deep learning techniques to analyse image data is an expansive and emerging field. The benefits of tracking, identifying, measuring, and sorting features of interest from image data has endless applications for saving cost, time, and improving safety. Much research has been conducted on classifying cracks from image data using deep convolutional neural networks; however, minimal research has been conducted to study the efficacy of network performance when noisy images are used. This paper will address the problem and is dedicated to investigating the influence of image noise on network accuracy. The methods used incorporate a benchmark image data set, which is purposely deteriorated with two types of noise, followed by treatment with image enhancement pre-processing techniques. These images, including their native counterparts, are then used to train and validate two different networks to study the differences in accuracy and performance. Results from this research reveal that noisy images have a moderate to high impact on the network's capability to accurately classify images despite the application of image pre-processing. A new index has been developed for finding the most efficient method for classification in terms of computation timing and accuracy. Consequently, AlexNet was selected as the most efficient model based on the proposed index.
* 8 pages, 16 figures, 4 tables