 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Universal Deep Room Acoustics Estimator
Sep 29, 2021
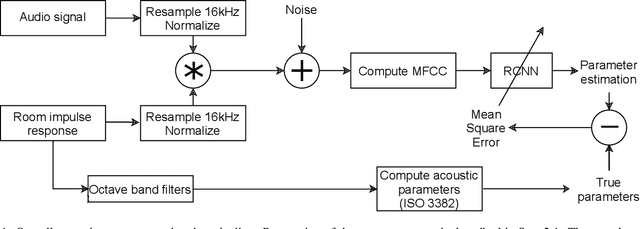
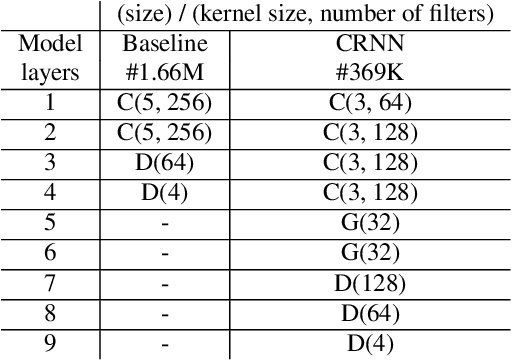
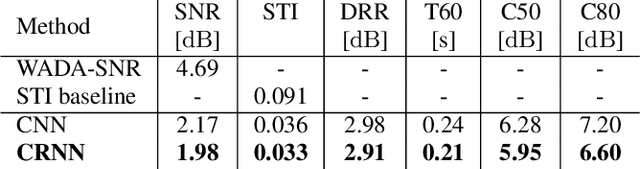
Speech audio quality is subject to degradation caused by an acoustic environment and isotropic ambient and point noises. The environment can lead to decreased speech intelligibility and loss of focus and attention by the listener. Basic acoustic parameters that characterize the environment well are (i) signal-to-noise ratio (SNR), (ii) speech transmission index, (iii) reverberation time, (iv) clarity, and (v) direct-to-reverberant ratio. Except for the SNR, these parameters are usually derived from the Room Impulse Response (RIR) measurements; however, such measurements are often not available. This work presents a universal room acoustic estimator design based on convolutional recurrent neural networks that estimate the acoustic environment measurement blindly and jointly. Our results indicate that the proposed system is robust to non-stationary signal variations and outperforms current state-of-the-art methods.
* Room acoustics, Convolutional Recurrent Neural Network, RT60, C50, DRR, STI, SNR
A Tutorial on Terahertz-Band Localization for 6G Communication Systems
Oct 16, 2021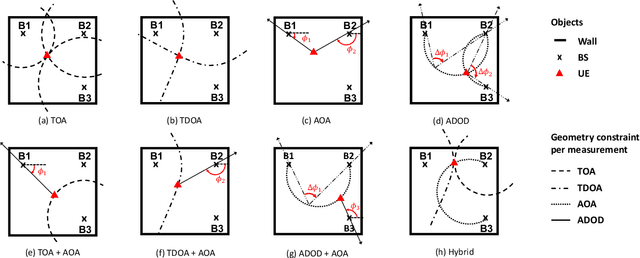
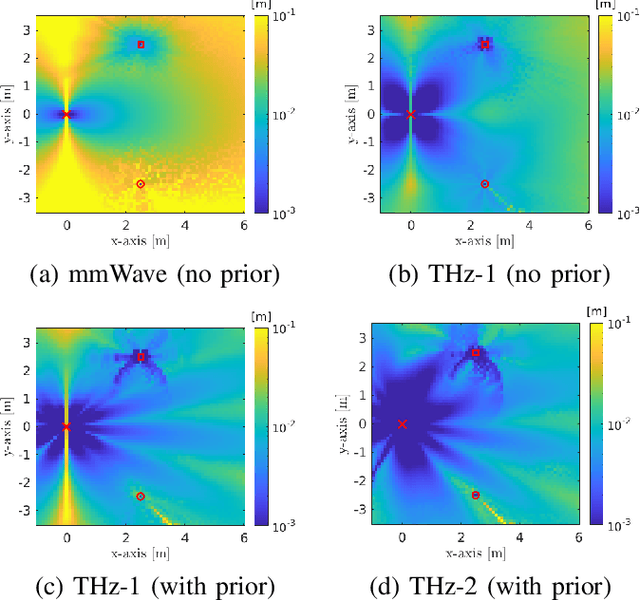
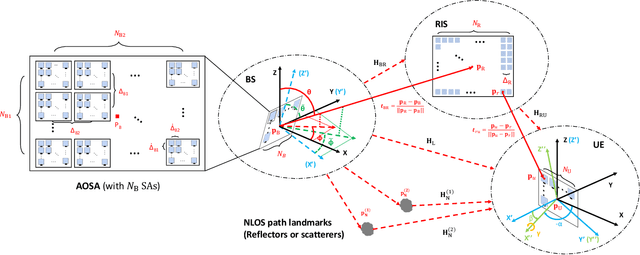
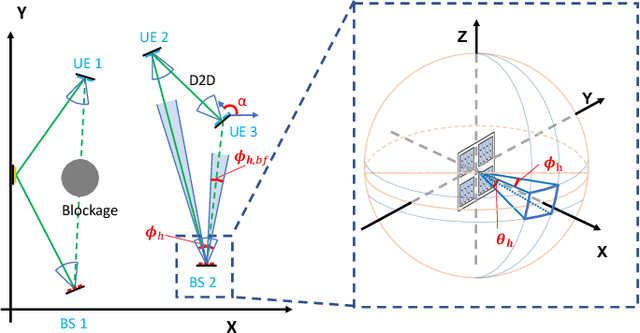
Terahertz (THz) communications are celebrated as key enablers for converged localization and sensing in future sixth-generation (6G) wireless communication systems and beyond. Instead of being a byproduct of the communication system, localization in 6G is indispensable for location-aware communications. Towards this end, we aim to identify the prospects, challenges, and requirements of THz localization techniques. We first review the history and trends of localization methods and discuss their objectives, constraints, and applications in contemporary communication systems. We then detail the latest advances in THz communications and introduce the THz-specific channel and system models. Afterward, we formulate THz-band localization as a 3D position/orientation estimation problem, detailing geometry-based localization techniques and describing potential THz localization and sensing extensions. We further formulate the offline design and online optimization of THz localization systems, provide numerical simulation results, and conclude by providing insight into interdisciplinary future research directions. Preliminary results illustrate that under the same total transmission power and time, THz-based localization is ~5 (~20) times more accurate than mmWave-based localization without (with) prior position information.
Ghost-DeblurGAN and Its Application to Fiducial Marker System
Sep 12, 2021
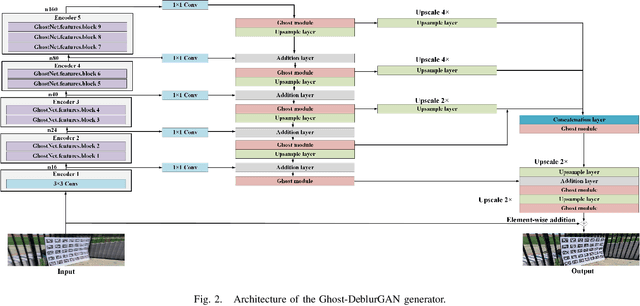
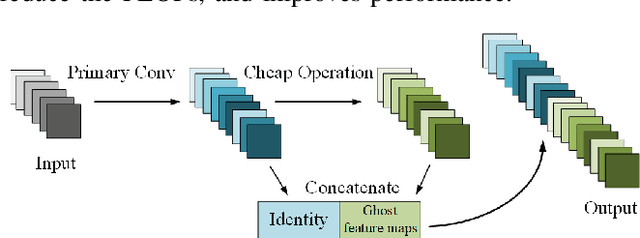
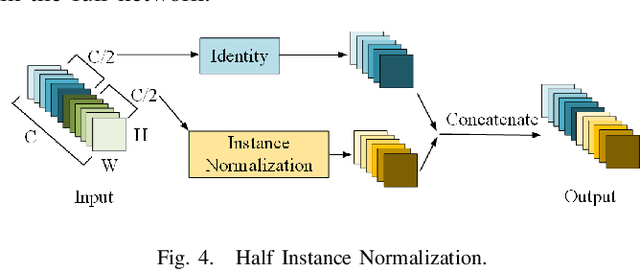
Motion blur can impede marker detection and marker-based pose estimation, which is common in real-world robotic applications involving fiducial markers. To solve this problem, we propose a novel lightweight generative adversarial network (GAN), Ghost-DeblurGAN, for real-time motion deblurring. Furthermore, a new large-scale dataset, YorkTag, provides pairs of sharp/blurred images containing fiducial markers and is proposed to train and qualitatively and quantitatively evaluate our model. Experimental results demonstrate that when applied along with fudicual marker systems to motion-blurred images, Ghost-DeblurGAN improves the marker detection significantly and mitigates the rotational ambiguity problem in marker-based pose estimation.
Evaluating deep transfer learning for whole-brain cognitive decoding
Nov 01, 2021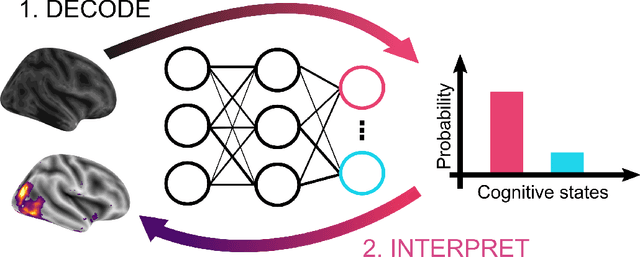
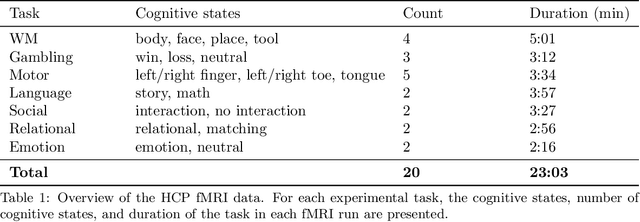

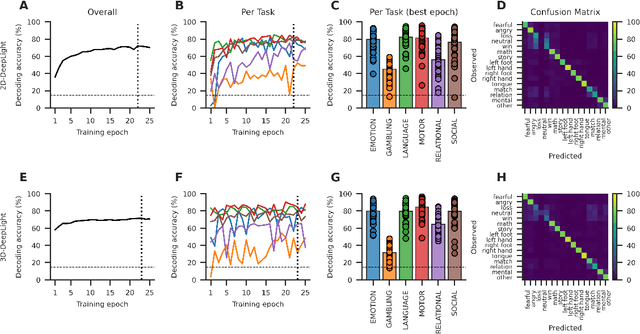
Research in many fields has shown that transfer learning (TL) is well-suited to improve the performance of deep learning (DL) models in datasets with small numbers of samples. This empirical success has triggered interest in the application of TL to cognitive decoding analyses with functional neuroimaging data. Here, we systematically evaluate TL for the application of DL models to the decoding of cognitive states (e.g., viewing images of faces or houses) from whole-brain functional Magnetic Resonance Imaging (fMRI) data. We first pre-train two DL architectures on a large, public fMRI dataset and subsequently evaluate their performance in an independent experimental task and a fully independent dataset. The pre-trained models consistently achieve higher decoding accuracies and generally require less training time and data than model variants that were not pre-trained, clearly underlining the benefits of pre-training. We demonstrate that these benefits arise from the ability of the pre-trained models to reuse many of their learned features when training with new data, providing deeper insights into the mechanisms giving rise to the benefits of pre-training. Yet, we also surface nuanced challenges for whole-brain cognitive decoding with DL models when interpreting the decoding decisions of the pre-trained models, as these have learned to utilize the fMRI data in unforeseen and counterintuitive ways to identify individual cognitive states.
Diversified Sampling for Batched Bayesian Optimization with Determinantal Point Processes
Oct 22, 2021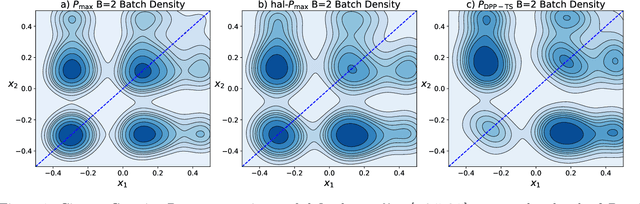
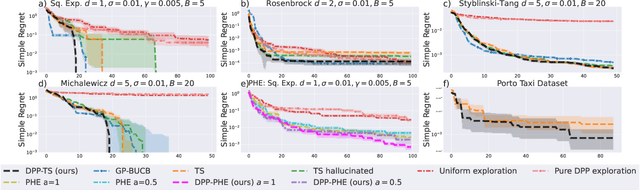
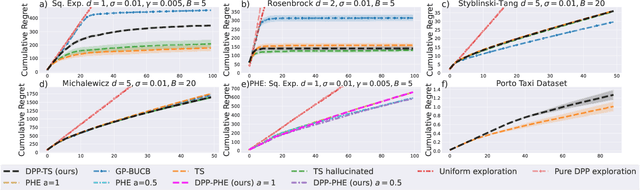
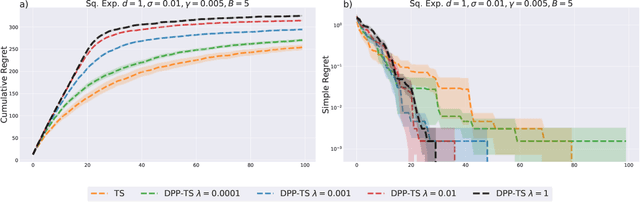
In Bayesian Optimization (BO) we study black-box function optimization with noisy point evaluations and Bayesian priors. Convergence of BO can be greatly sped up by batching, where multiple evaluations of the black-box function are performed in a single round. The main difficulty in this setting is to propose at the same time diverse and informative batches of evaluation points. In this work, we introduce DPP-Batch Bayesian Optimization (DPP-BBO), a universal framework for inducing batch diversity in sampling based BO by leveraging the repulsive properties of Determinantal Point Processes (DPP) to naturally diversify the batch sampling procedure. We illustrate this framework by formulating DPP-Thompson Sampling (DPP-TS) as a variant of the popular Thompson Sampling (TS) algorithm and introducing a Markov Chain Monte Carlo procedure to sample from it. We then prove novel Bayesian simple regret bounds for both classical batched TS as well as our counterpart DPP-TS, with the latter bound being tighter. Our real-world, as well as synthetic, experiments demonstrate improved performance of DPP-BBO over classical batching methods with Gaussian process and Cox process models.
Byakto Speech: Real-time long speech synthesis with convolutional neural network: Transfer learning from English to Bangla
May 31, 2021
Speech synthesis is one of the challenging tasks to automate by deep learning, also being a low-resource language there are very few attempts at Bangla speech synthesis. Most of the existing works can't work with anything other than simple Bangla characters script, very short sentences, etc. This work attempts to solve these problems by introducing Byakta, the first-ever open-source deep learning-based bilingual (Bangla and English) text to a speech synthesis system. A speech recognition model-based automated scoring metric was also proposed to evaluate the performance of a TTS model. We also introduce a test benchmark dataset for Bangla speech synthesis models for evaluating speech quality. The TTS is available at https://github.com/zabir-nabil/bangla-tts
Near-Optimal Dispersion on Arbitrary Anonymous Graphs
Jun 07, 2021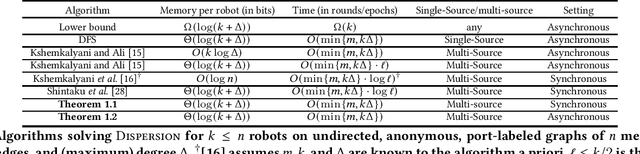
Given an undirected, anonymous, port-labeled graph of $n$ memory-less nodes, $m$ edges, and degree $\Delta$, we consider the problem of dispersing $k\leq n$ robots (or tokens) positioned initially arbitrarily on one or more nodes of the graph to exactly $k$ different nodes of the graph, one on each node. The objective is to simultaneously minimize time to achieve dispersion and memory requirement at each robot. If all $k$ robots are positioned initially on a single node, depth first search (DFS) traversal solves this problem in $O(\min\{m,k\Delta\})$ time with $\Theta(\log(k+\Delta))$ bits at each robot. However, if robots are positioned initially on multiple nodes, the best previously known algorithm solves this problem in $O(\min\{m,k\Delta\}\cdot \log \ell)$ time storing $\Theta(\log(k+\Delta))$ bits at each robot, where $\ell\leq k/2$ is the number of multiplicity nodes in the initial configuration. In this paper, we present a novel multi-source DFS traversal algorithm solving this problem in $O(\min\{m,k\Delta\})$ time with $\Theta(\log(k+\Delta))$ bits at each robot, improving the time bound of the best previously known algorithm by $O(\log \ell)$ and matching asymptotically the single-source DFS traversal bounds. This is the first algorithm for dispersion that is optimal in both time and memory in arbitrary anonymous graphs of constant degree, $\Delta=O(1)$. Furthermore, the result holds in both synchronous and asynchronous settings.
Quality-aware Cine Cardiac MRI Reconstruction and Analysis from Undersampled k-space Data
Sep 16, 2021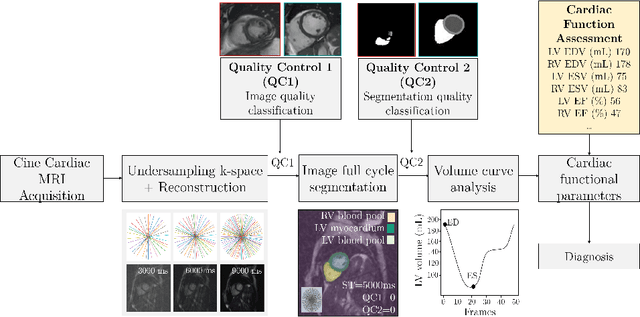
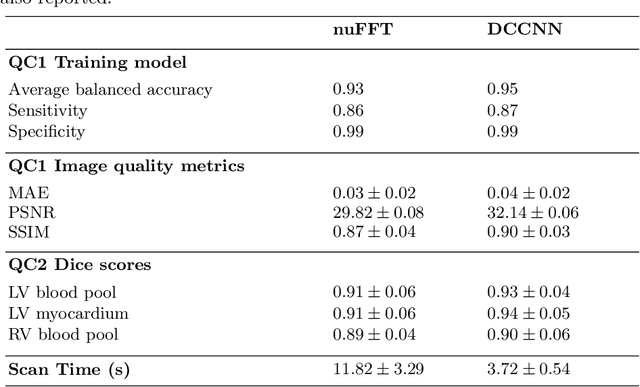
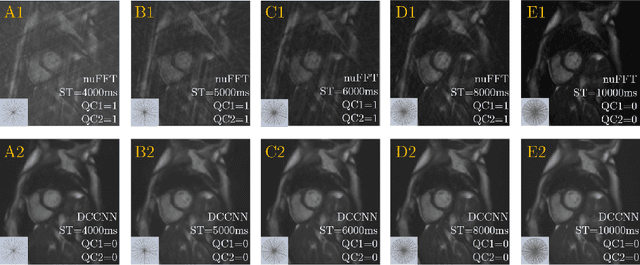
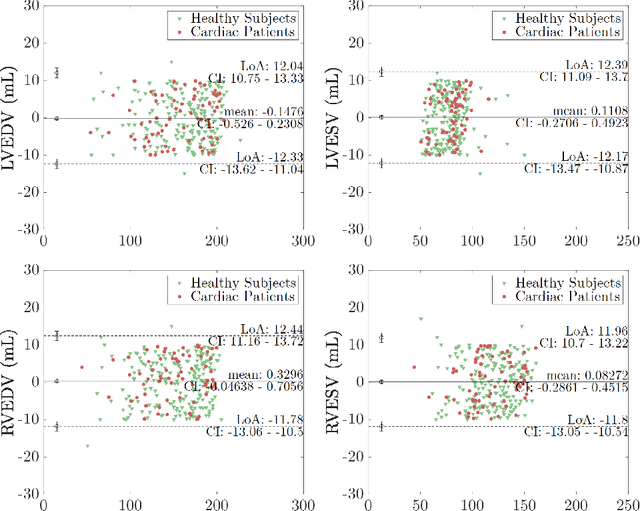
Cine cardiac MRI is routinely acquired for the assessment of cardiac health, but the imaging process is slow and typically requires several breath-holds to acquire sufficient k-space profiles to ensure good image quality. Several undersampling-based reconstruction techniques have been proposed during the last decades to speed up cine cardiac MRI acquisition. However, the undersampling factor is commonly fixed to conservative values before acquisition to ensure diagnostic image quality, potentially leading to unnecessarily long scan times. In this paper, we propose an end-to-end quality-aware cine short-axis cardiac MRI framework that combines image acquisition and reconstruction with downstream tasks such as segmentation, volume curve analysis and estimation of cardiac functional parameters. The goal is to reduce scan time by acquiring only a fraction of k-space data to enable the reconstruction of images that can pass quality control checks and produce reliable estimates of cardiac functional parameters. The framework consists of a deep learning model for the reconstruction of 2D+t cardiac cine MRI images from undersampled data, an image quality-control step to detect good quality reconstructions, followed by a deep learning model for bi-ventricular segmentation, a quality-control step to detect good quality segmentations and automated calculation of cardiac functional parameters. To demonstrate the feasibility of the proposed approach, we perform simulations using a cohort of selected participants from the UK Biobank (n=270), 200 healthy subjects and 70 patients with cardiomyopathies. Our results show that we can produce quality-controlled images in a scan time reduced from 12 to 4 seconds per slice, enabling reliable estimates of cardiac functional parameters such as ejection fraction within 5% mean absolute error.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021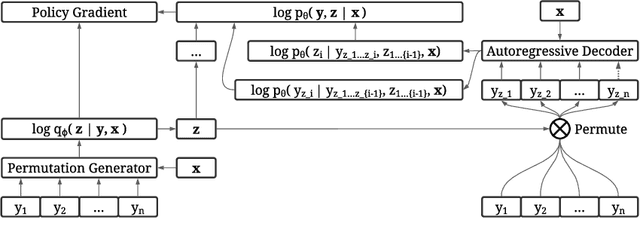
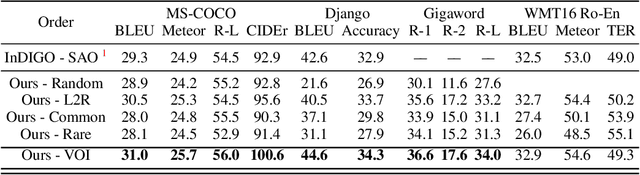
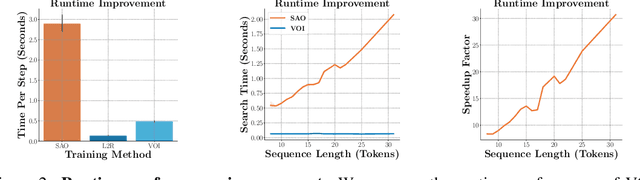
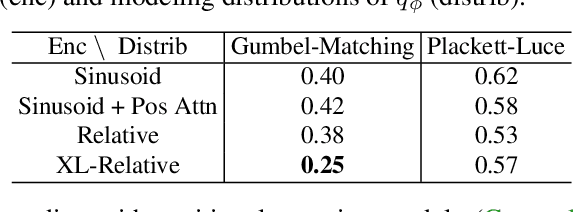
The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.
DeepAuditor: Distributed Online Intrusion Detection System for IoT devices via Power Side-channel Auditing
Jun 24, 2021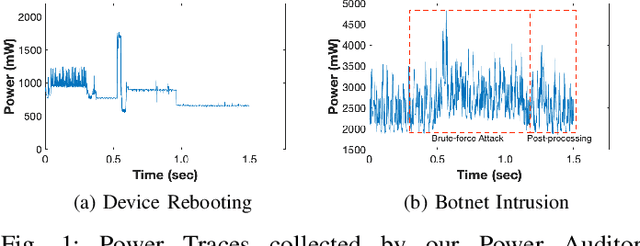
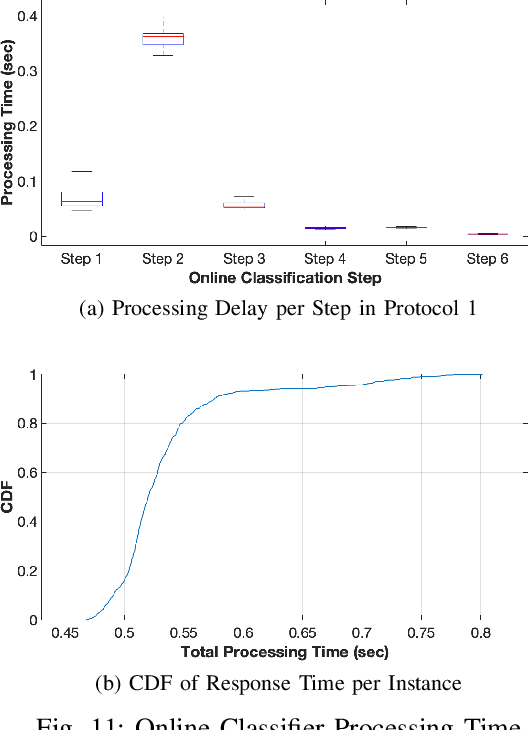
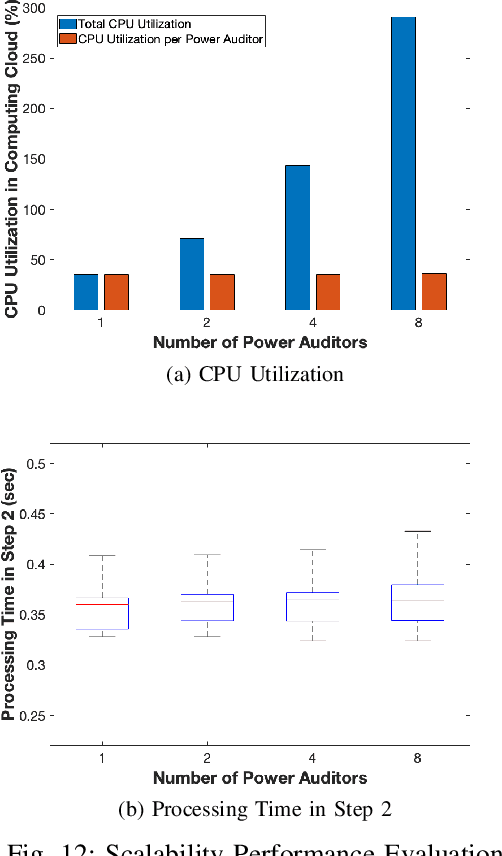
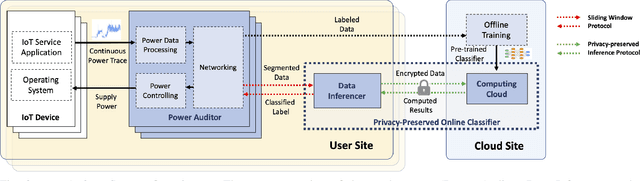
As the number of IoT devices has increased rapidly, IoT botnets have exploited the vulnerabilities of IoT devices. However, it is still challenging to detect the initial intrusion on IoT devices prior to massive attacks. Recent studies have utilized power side-channel information to characterize this intrusion behavior on IoT devices but still lack real-time detection approaches. This study aimed to design an online intrusion detection system called DeepAuditor for IoT devices via power auditing. To realize the real-time system, we first proposed a lightweight power auditing device called Power Auditor. With the Power Auditor, we developed a Distributed CNN classifier for online inference in our laboratory setting. In order to protect data leakage and reduce networking redundancy, we also proposed a privacy-preserved inference protocol via Packed Homomorphic Encryption and a sliding window protocol in our system. The classification accuracy and processing time were measured in our laboratory settings. We also demonstrated that the distributed CNN design is secure against any distributed components. Overall, the measurements were shown to the feasibility of our real-time distributed system for intrusion detection on IoT devices.