 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smartphone Transportation Mode Recognition Using a Hierarchical Machine Learning Classifier and Pooled Features From Time and Frequency Domains
Jun 12, 2020
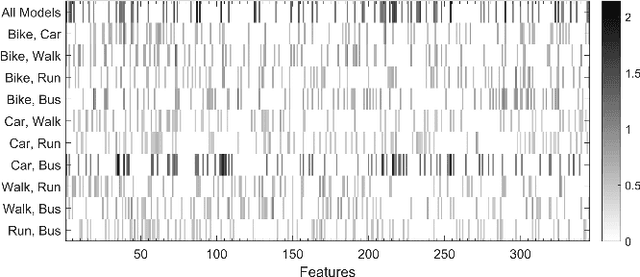
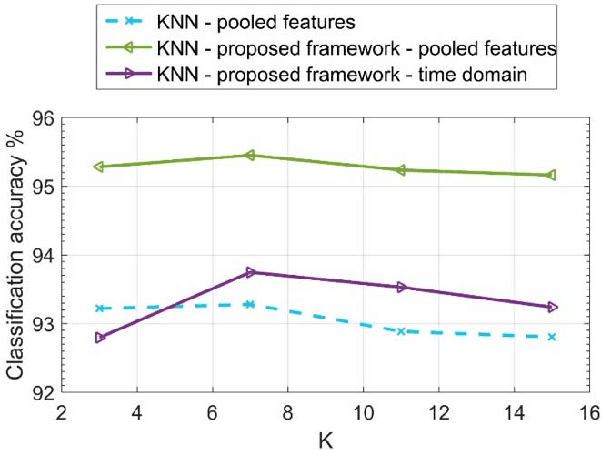
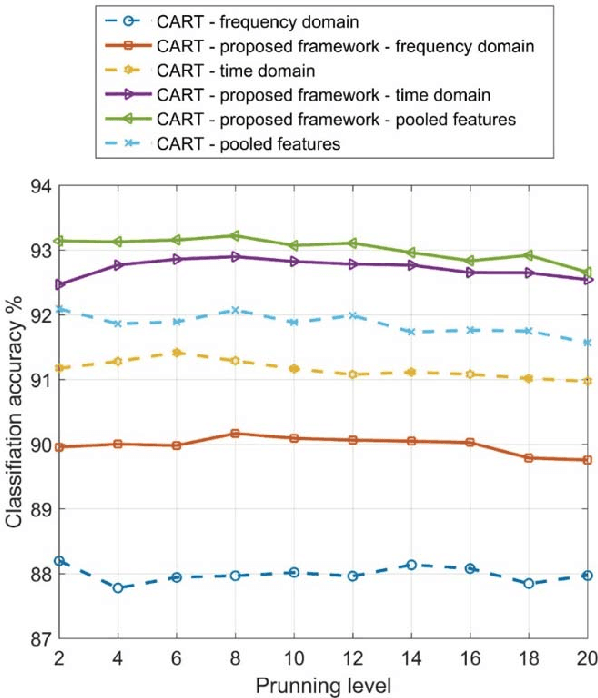
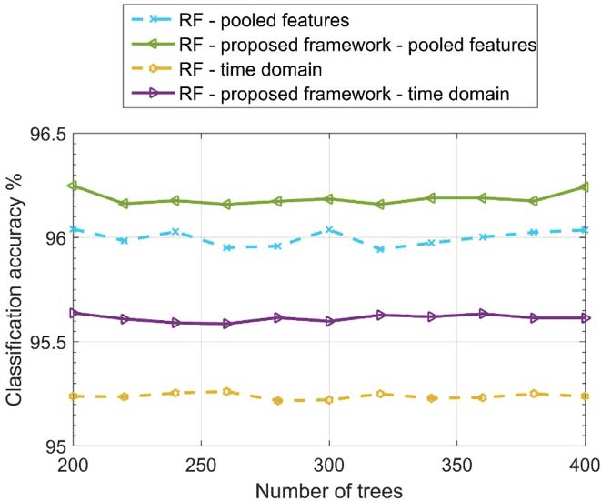
This paper develops a novel two-layer hierarchical classifier that increases the accuracy of traditional transportation mode classification algorithms. This paper also enhances classification accuracy by extracting new frequency domain features. Many researchers have obtained these features from global positioning system data; however, this data was excluded in this paper, as the system use might deplete the smartphone's battery and signals may be lost in some areas. Our proposed two-layer framework differs from previous classification attempts in three distinct ways: 1) the outputs of the two layers are combined using Bayes' rule to choose the transportation mode with the largest posterior probability; 2) the proposed framework combines the new extracted features with traditionally used time domain features to create a pool of features; and 3) a different subset of extracted features is used in each layer based on the classified modes. Several machine learning techniques were used, including k-nearest neighbor, classification and regression tree, support vector machine, random forest, and a heterogeneous framework of random forest and support vector machine. Results show that the classification accuracy of the proposed framework outperforms traditional approaches. Transforming the time domain features to the frequency domain also adds new features in a new space and provides more control on the loss of information. Consequently, combining the time domain and the frequency domain features in a large pool and then choosing the best subset results in higher accuracy than using either domain alone. The proposed two-layer classifier obtained a maximum classification accuracy of 97.02%.
Real-time Denoising and Dereverberation with Tiny Recurrent U-Net
Feb 10, 2021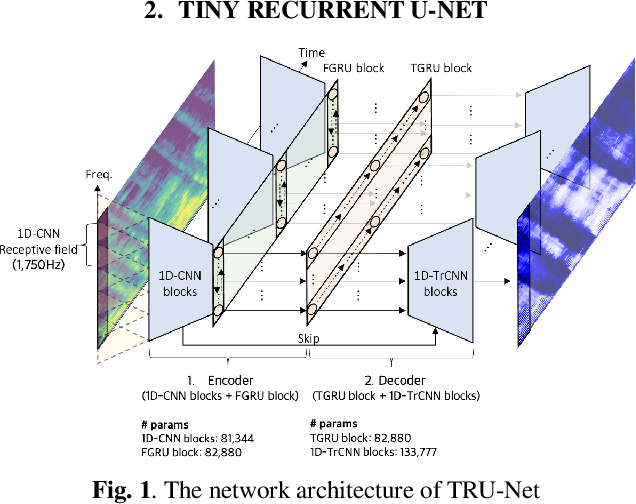
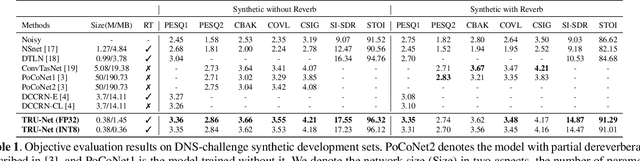
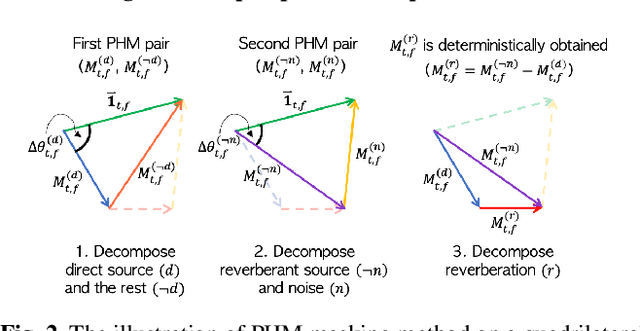
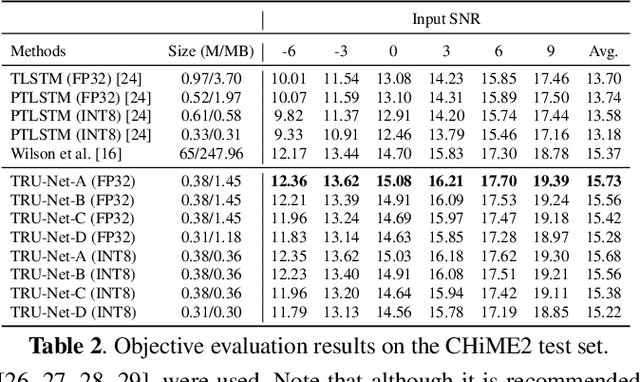
Modern deep learning-based models have seen outstanding performance improvement with speech enhancement tasks. The number of parameters of state-of-the-art models, however, is often too large to be deployed on devices for real-world applications. To this end, we propose Tiny Recurrent U-Net (TRU-Net), a lightweight online inference model that matches the performance of current state-of-the-art models. The size of the quantized version of TRU-Net is 362 kilobytes, which is small enough to be deployed on edge devices. In addition, we combine the small-sized model with a new masking method called phase-aware $\beta$-sigmoid mask, which enables simultaneous denoising and dereverberation. Results of both objective and subjective evaluations have shown that our model can achieve competitive performance with the current state-of-the-art models on benchmark datasets using fewer parameters by orders of magnitude.
PP-LCNet: A Lightweight CPU Convolutional Neural Network
Sep 17, 2021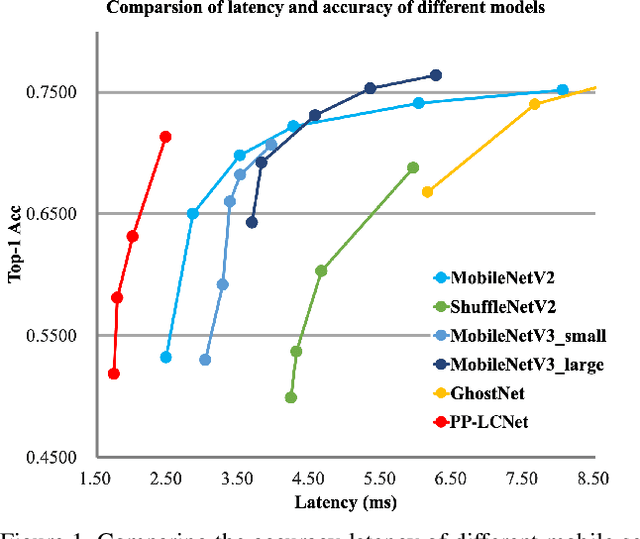
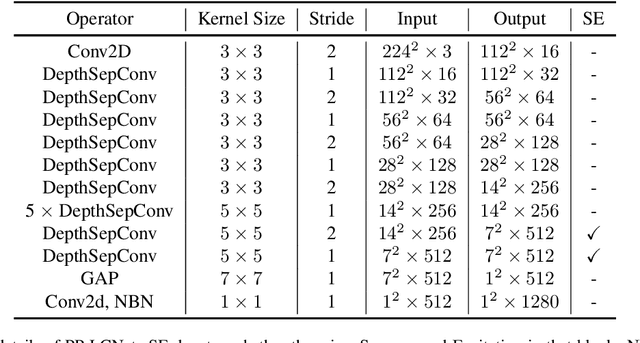
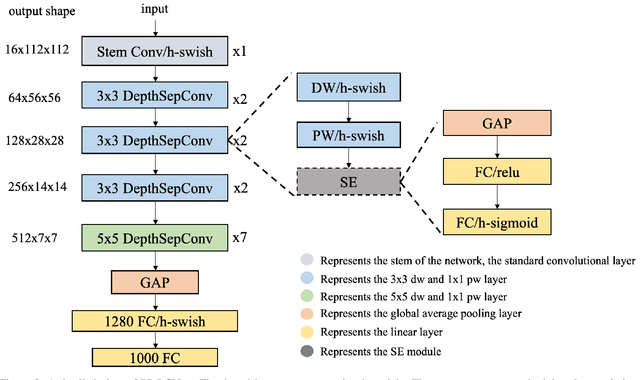
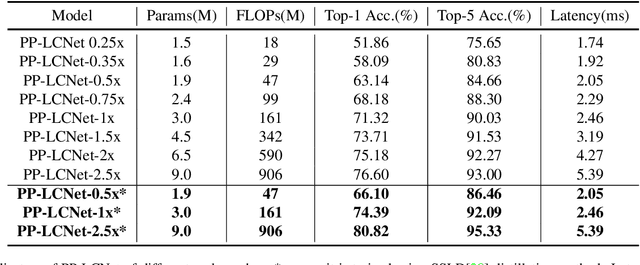
We propose a lightweight CPU network based on the MKLDNN acceleration strategy, named PP-LCNet, which improves the performance of lightweight models on multiple tasks. This paper lists technologies which can improve network accuracy while the latency is almost constant. With these improvements, the accuracy of PP-LCNet can greatly surpass the previous network structure with the same inference time for classification. As shown in Figure 1, it outperforms the most state-of-the-art models. And for downstream tasks of computer vision, it also performs very well, such as object detection, semantic segmentation, etc. All our experiments are implemented based on PaddlePaddle. Code and pretrained models are available at PaddleClas.
Programmable FPGA-based Memory Controller
Aug 21, 2021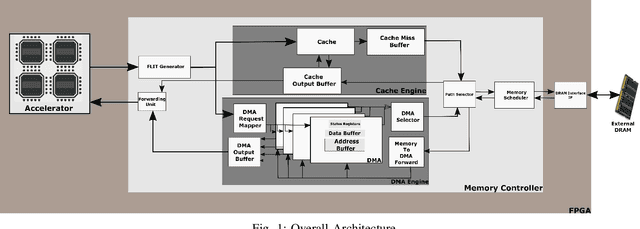
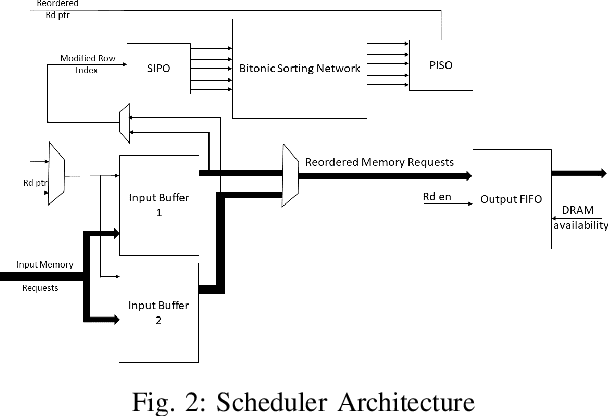
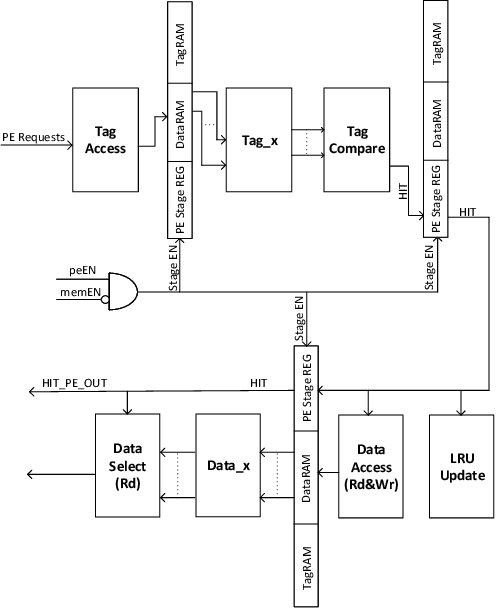
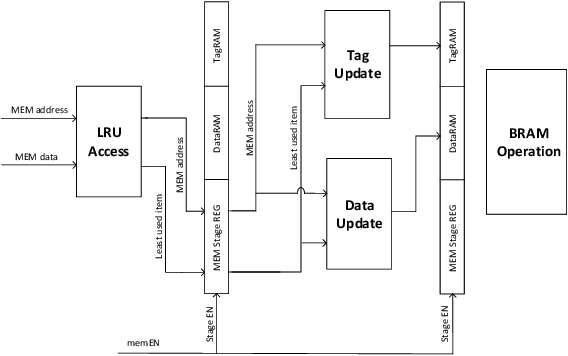
Even with generational improvements in DRAM technology, memory access latency still remains the major bottleneck for application accelerators, primarily due to limitations in memory interface IPs which cannot fully account for variations in target applications, the algorithms used, and accelerator architectures. Since developing memory controllers for different applications is time-consuming, this paper introduces a modular and programmable memory controller that can be configured for different target applications on available hardware resources. The proposed memory controller efficiently supports cache-line accesses along with bulk memory transfers. The user can configure the controller depending on the available logic resources on the FPGA, memory access pattern, and external memory specifications. The modular design supports various memory access optimization techniques including, request scheduling, internal caching, and direct memory access. These techniques contribute to reducing the overall latency while maintaining high sustained bandwidth. We implement the system on a state-of-the-art FPGA and evaluate its performance using two widely studied domains: graph analytics and deep learning workloads. We show improved overall memory access time up to 58% on CNN and GCN workloads compared with commercial memory controller IPs.
C-OPH: Improving the Accuracy of One Permutation Hashing (OPH) with Circulant Permutations
Nov 18, 2021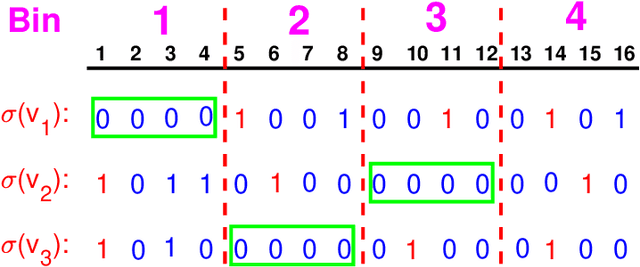
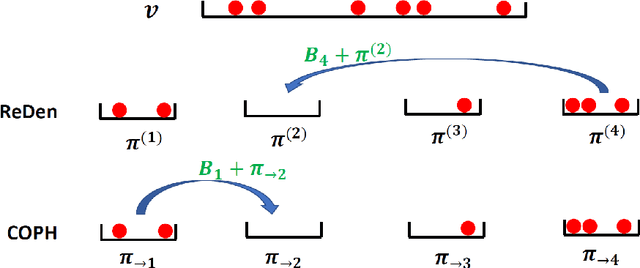
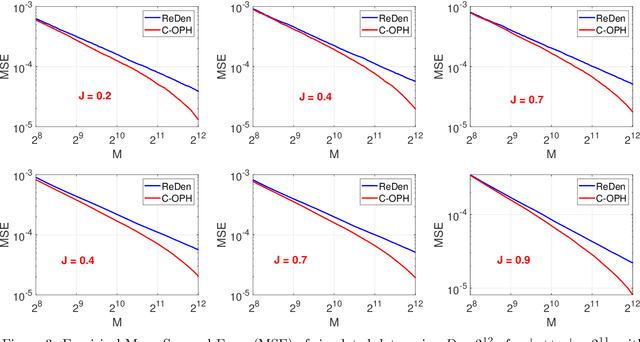
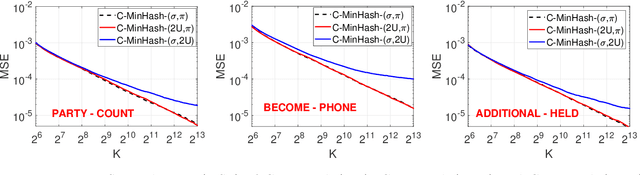
Minwise hashing (MinHash) is a classical method for efficiently estimating the Jaccrad similarity in massive binary (0/1) data. To generate $K$ hash values for each data vector, the standard theory of MinHash requires $K$ independent permutations. Interestingly, the recent work on "circulant MinHash" (C-MinHash) has shown that merely two permutations are needed. The first permutation breaks the structure of the data and the second permutation is re-used $K$ time in a circulant manner. Surprisingly, the estimation accuracy of C-MinHash is proved to be strictly smaller than that of the original MinHash. The more recent work further demonstrates that practically only one permutation is needed. Note that C-MinHash is different from the well-known work on "One Permutation Hashing (OPH)" published in NIPS'12. OPH and its variants using different "densification" schemes are popular alternatives to the standard MinHash. The densification step is necessary in order to deal with empty bins which exist in One Permutation Hashing. In this paper, we propose to incorporate the essential ideas of C-MinHash to improve the accuracy of One Permutation Hashing. Basically, we develop a new densification method for OPH, which achieves the smallest estimation variance compared to all existing densification schemes for OPH. Our proposed method is named C-OPH (Circulant OPH). After the initial permutation (which breaks the existing structure of the data), C-OPH only needs a "shorter" permutation of length $D/K$ (instead of $D$), where $D$ is the original data dimension and $K$ is the total number of bins in OPH. This short permutation is re-used in $K$ bins in a circulant shifting manner. It can be shown that the estimation variance of the Jaccard similarity is strictly smaller than that of the existing (densified) OPH methods.
Spatial Constraint Generation for Motion Planning in Dynamic Environments
Oct 27, 2021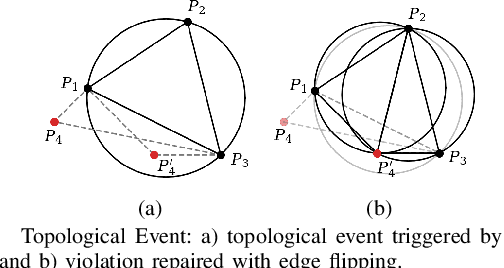
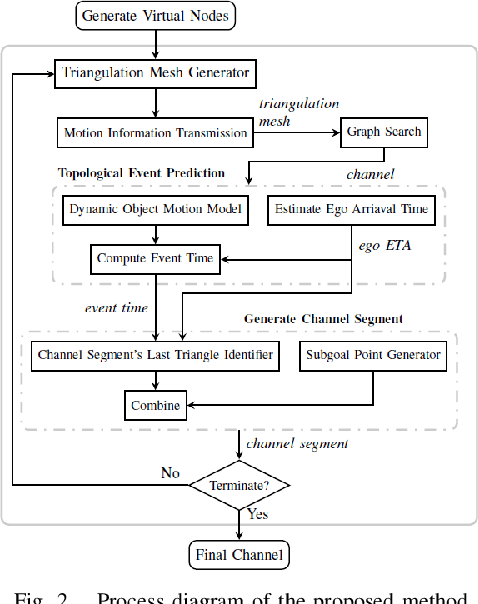
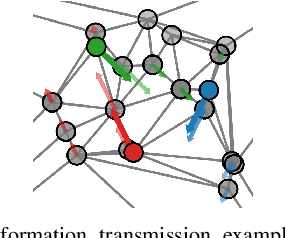
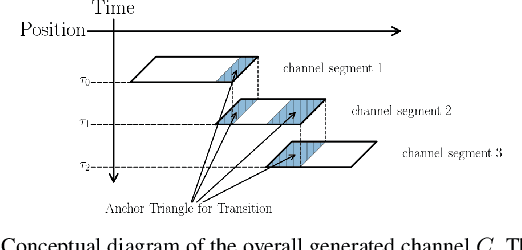
This paper presents a novel method to generate spatial constraints for motion planning in dynamic environments. Motion planning methods for autonomous driving and mobile robots typically need to rely on the spatial constraints imposed by a map-based global planner to generate a collision-free trajectory. These methods may fail without an offline map or where the map is invalid due to dynamic changes in the environment such as road obstruction, construction, and traffic congestion. To address this problem, triangulation-based methods can be used to obtain a spatial constraint. However, the existing methods fall short when dealing with dynamic environments and may lead the motion planner to an unrecoverable state. In this paper, we propose a new method to generate a sequence of channels across different triangulation mesh topologies to serve as the spatial constraints. This can be applied to motion planning of autonomous vehicles or robots in cluttered, unstructured environments. The proposed method is evaluated and compared with other triangulation-based methods in synthetic and complex scenarios collected from a real-world autonomous driving dataset. We have shown that the proposed method results in a more stable, long-term plan with a higher task completion rate, faster arrival time, a higher rate of successful plans, and fewer collisions compared to existing methods.
Drawing Robust Scratch Tickets: Subnetworks with Inborn Robustness Are Found within Randomly Initialized Networks
Nov 06, 2021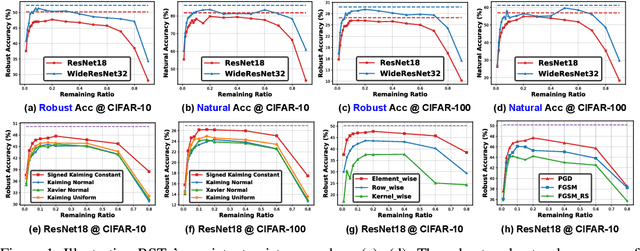
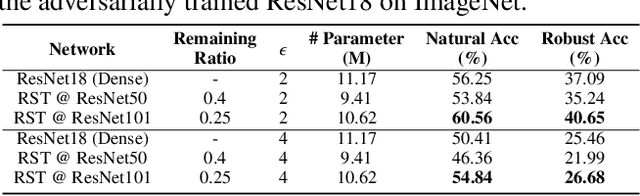
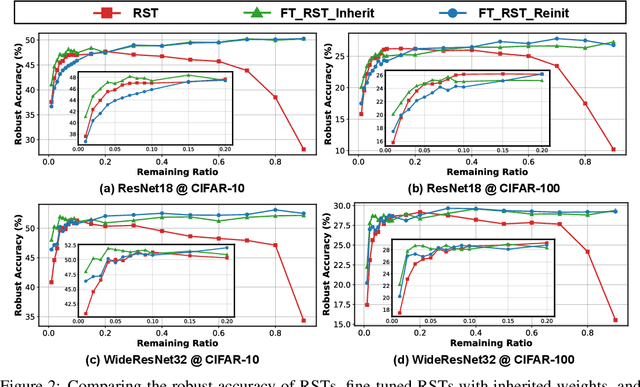
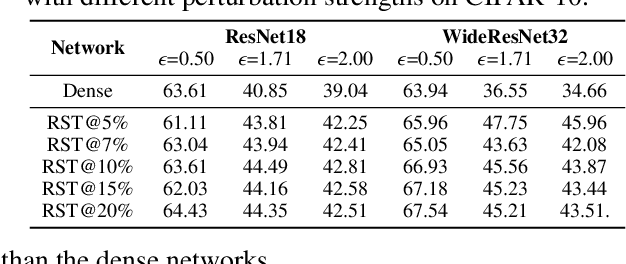
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks, i.e., an imperceptible perturbation to the input can mislead DNNs trained on clean images into making erroneous predictions. To tackle this, adversarial training is currently the most effective defense method, by augmenting the training set with adversarial samples generated on the fly. Interestingly, we discover for the first time that there exist subnetworks with inborn robustness, matching or surpassing the robust accuracy of the adversarially trained networks with comparable model sizes, within randomly initialized networks without any model training, indicating that adversarial training on model weights is not indispensable towards adversarial robustness. We name such subnetworks Robust Scratch Tickets (RSTs), which are also by nature efficient. Distinct from the popular lottery ticket hypothesis, neither the original dense networks nor the identified RSTs need to be trained. To validate and understand this fascinating finding, we further conduct extensive experiments to study the existence and properties of RSTs under different models, datasets, sparsity patterns, and attacks, drawing insights regarding the relationship between DNNs' robustness and their initialization/overparameterization. Furthermore, we identify the poor adversarial transferability between RSTs of different sparsity ratios drawn from the same randomly initialized dense network, and propose a Random RST Switch (R2S) technique, which randomly switches between different RSTs, as a novel defense method built on top of RSTs. We believe our findings about RSTs have opened up a new perspective to study model robustness and extend the lottery ticket hypothesis.
One Proxy Device Is Enough for Hardware-Aware Neural Architecture Search
Nov 01, 2021

Convolutional neural networks (CNNs) are used in numerous real-world applications such as vision-based autonomous driving and video content analysis. To run CNN inference on various target devices, hardware-aware neural architecture search (NAS) is crucial. A key requirement of efficient hardware-aware NAS is the fast evaluation of inference latencies in order to rank different architectures. While building a latency predictor for each target device has been commonly used in state of the art, this is a very time-consuming process, lacking scalability in the presence of extremely diverse devices. In this work, we address the scalability challenge by exploiting latency monotonicity -- the architecture latency rankings on different devices are often correlated. When strong latency monotonicity exists, we can re-use architectures searched for one proxy device on new target devices, without losing optimality. In the absence of strong latency monotonicity, we propose an efficient proxy adaptation technique to significantly boost the latency monotonicity. Finally, we validate our approach and conduct experiments with devices of different platforms on multiple mainstream search spaces, including MobileNet-V2, MobileNet-V3, NAS-Bench-201, ProxylessNAS and FBNet. Our results highlight that, by using just one proxy device, we can find almost the same Pareto-optimal architectures as the existing per-device NAS, while avoiding the prohibitive cost of building a latency predictor for each device.
* Accepted by the ACM SIGMETRICS 2022. Published in the Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 5, no. 3, Article 34, December 2021
Mapping illegal waste dumping sites with neural-network classification of satellite imagery
Oct 16, 2021

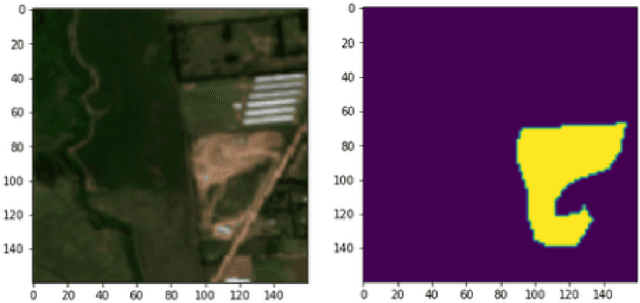
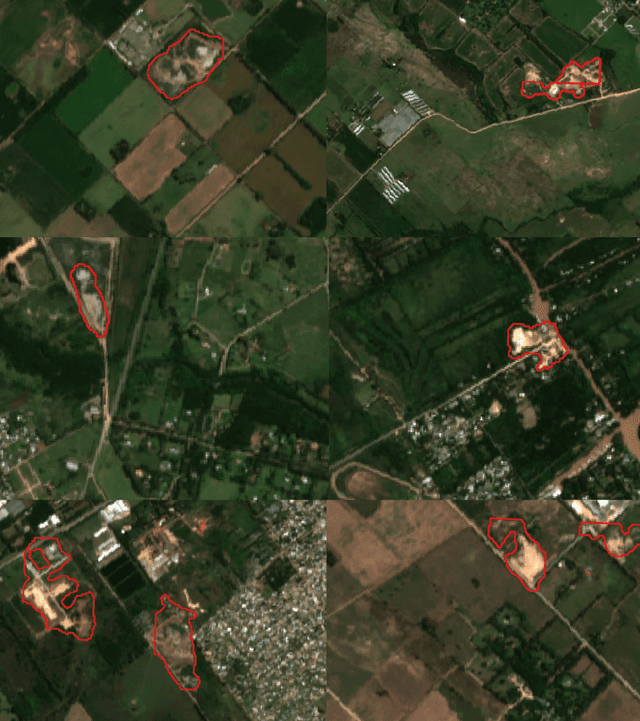
Public health and habitat quality are crucial goals of urban planning. In recent years, the severe social and environmental impact of illegal waste dumping sites has made them one of the most serious problems faced by cities in the Global South, in a context of scarce information available for decision making. To help identify the location of dumping sites and track their evolution over time we adopt a data-driven model from the machine learning domain, analyzing satellite images. This allows us to take advantage of the increasing availability of geo-spatial open-data, high-resolution satellite imagery, and open source tools to train machine learning algorithms with a small set of known waste dumping sites in Buenos Aires, and then predict the location of other sites over vast areas at high speed and low cost. This case study shows the results of a collaboration between Dymaxion Labs and Fundaci\'on Bunge y Born to harness this technique in order to create a comprehensive map of potential locations of illegal waste dumping sites in the region.
Byakto Speech: Real-time long speech synthesis with convolutional neural network: Transfer learning from English to Bangla
May 31, 2021
Speech synthesis is one of the challenging tasks to automate by deep learning, also being a low-resource language there are very few attempts at Bangla speech synthesis. Most of the existing works can't work with anything other than simple Bangla characters script, very short sentences, etc. This work attempts to solve these problems by introducing Byakta, the first-ever open-source deep learning-based bilingual (Bangla and English) text to a speech synthesis system. A speech recognition model-based automated scoring metric was also proposed to evaluate the performance of a TTS model. We also introduce a test benchmark dataset for Bangla speech synthesis models for evaluating speech quality. The TTS is available at https://github.com/zabir-nabil/bangla-tts