 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Piecewise-constant Neural ODEs
Jun 11, 2021
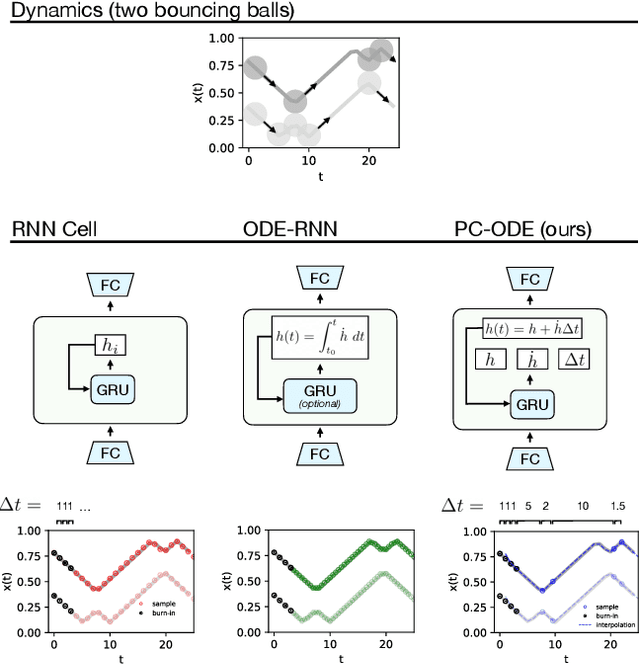
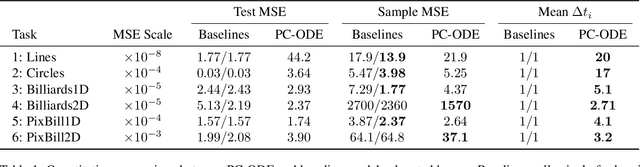
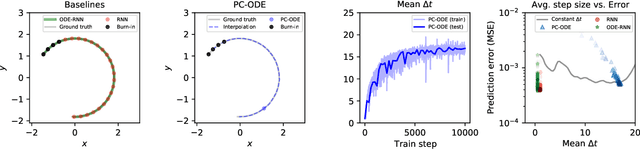
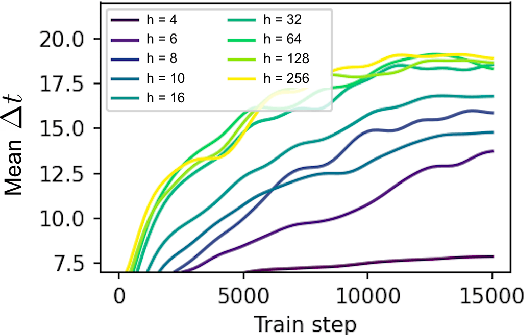
Neural networks are a popular tool for modeling sequential data but they generally do not treat time as a continuous variable. Neural ODEs represent an important exception: they parameterize the time derivative of a hidden state with a neural network and then integrate over arbitrary amounts of time. But these parameterizations, which have arbitrary curvature, can be hard to integrate and thus train and evaluate. In this paper, we propose making a piecewise-constant approximation to Neural ODEs to mitigate these issues. Our model can be integrated exactly via Euler integration and can generate autoregressive samples in 3-20 times fewer steps than comparable RNN and ODE-RNN models. We evaluate our model on several synthetic physics tasks and a planning task inspired by the game of billiards. We find that it matches the performance of baseline approaches while requiring less time to train and evaluate.
Advancing Brain Metastases Detection in T1-Weighted Contrast-Enhanced 3D MRI using Noisy Student-based Training
Nov 10, 2021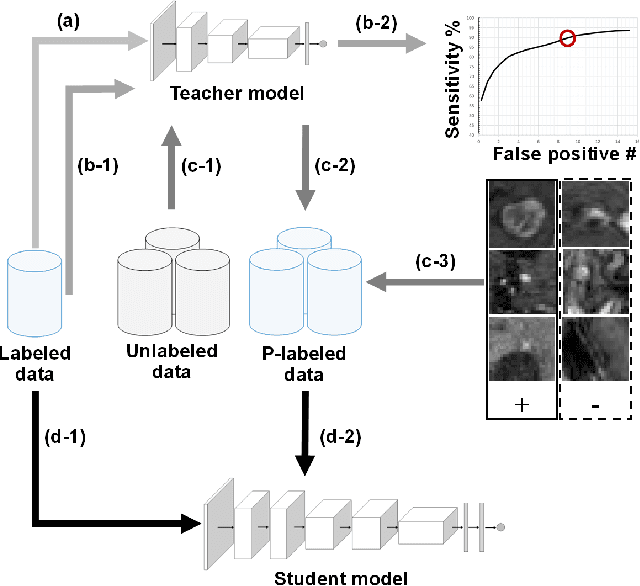
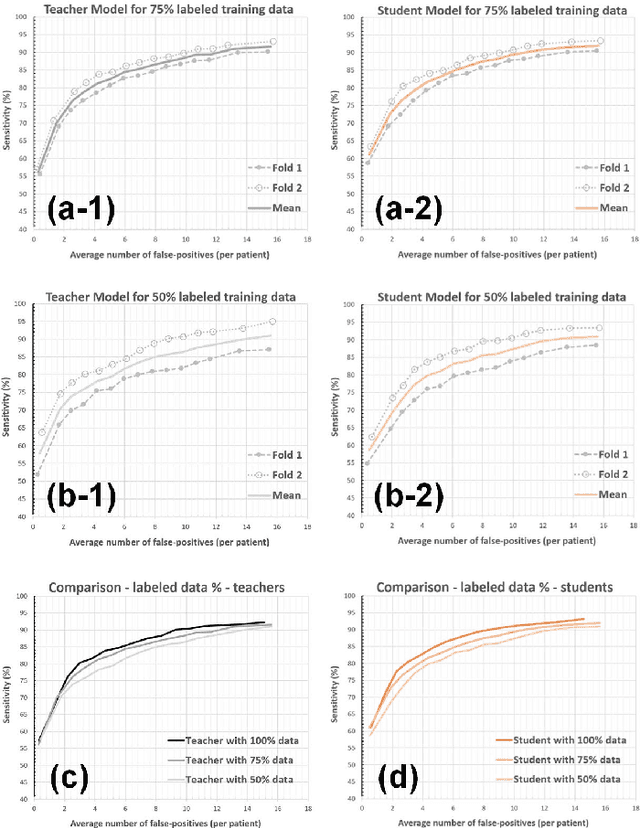
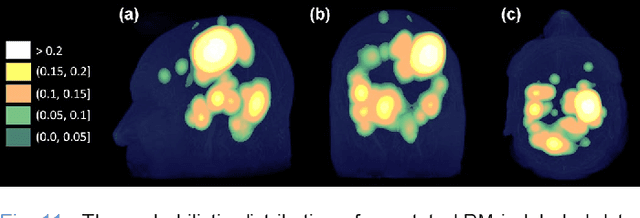
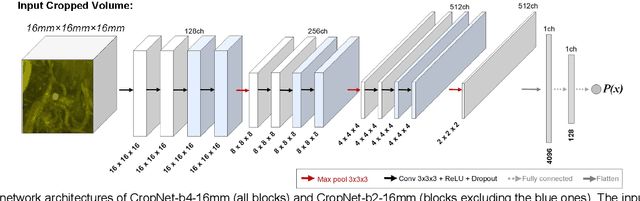
The detection of brain metastases (BM) in their early stages could have a positive impact on the outcome of cancer patients. We previously developed a framework for detecting small BM (with diameters of less than 15mm) in T1-weighted Contrast-Enhanced 3D Magnetic Resonance images (T1c) to assist medical experts in this time-sensitive and high-stakes task. The framework utilizes a dedicated convolutional neural network (CNN) trained using labeled T1c data, where the ground truth BM segmentations were provided by a radiologist. This study aims to advance the framework with a noisy student-based self-training strategy to make use of a large corpus of unlabeled T1c data (i.e., data without BM segmentations or detections). Accordingly, the work (1) describes the student and teacher CNN architectures, (2) presents data and model noising mechanisms, and (3) introduces a novel pseudo-labeling strategy factoring in the learned BM detection sensitivity of the framework. Finally, it describes a semi-supervised learning strategy utilizing these components. We performed the validation using 217 labeled and 1247 unlabeled T1c exams via 2-fold cross-validation. The framework utilizing only the labeled exams produced 9.23 false positives for 90% BM detection sensitivity; whereas, the framework using the introduced learning strategy led to ~9% reduction in false detections (i.e., 8.44) for the same sensitivity level. Furthermore, while experiments utilizing 75% and 50% of the labeled datasets resulted in algorithm performance degradation (12.19 and 13.89 false positives respectively), the impact was less pronounced with the noisy student-based training strategy (10.79 and 12.37 false positives respectively).
NViT: Vision Transformer Compression and Parameter Redistribution
Oct 10, 2021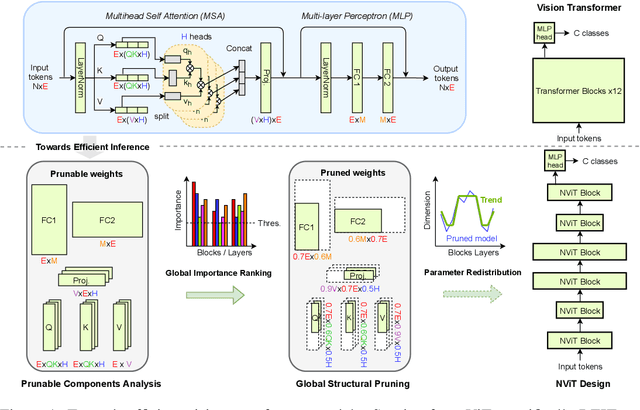
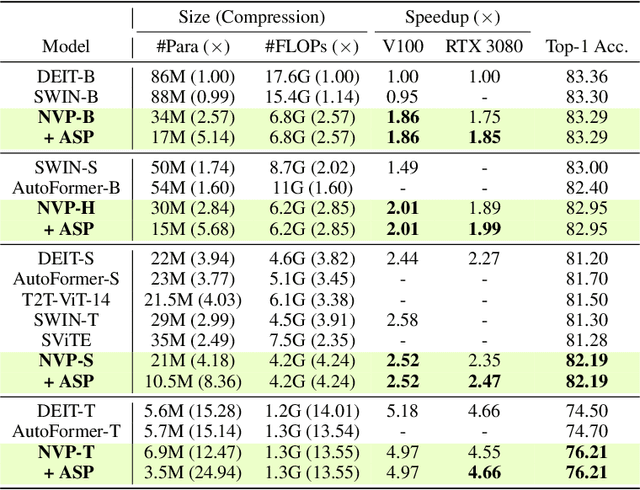
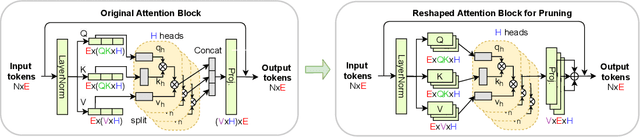
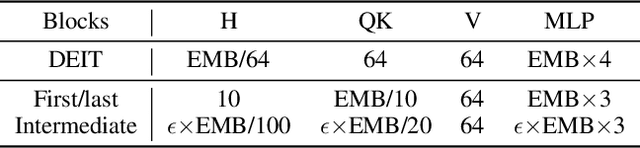
Transformers yield state-of-the-art results across many tasks. However, they still impose huge computational costs during inference. We apply global, structural pruning with latency-aware regularization on all parameters of the Vision Transformer (ViT) model for latency reduction. Furthermore, we analyze the pruned architectures and find interesting regularities in the final weight structure. Our discovered insights lead to a new architecture called NViT (Novel ViT), with a redistribution of where parameters are used. This architecture utilizes parameters more efficiently and enables control of the latency-accuracy trade-off. On ImageNet-1K, we prune the DEIT-Base (Touvron et al., 2021) model to a 2.6x FLOPs reduction, 5.1x parameter reduction, and 1.9x run-time speedup with only 0.07% loss in accuracy. We achieve more than 1% accuracy gain when compressing the base model to the throughput of the Small/Tiny variants. NViT gains 0.1-1.1% accuracy over the hand-designed DEIT family when trained from scratch, while being faster.
Anytime Game-Theoretic Planning with Active Reasoning About Humans' Latent States for Human-Centered Robots
Sep 26, 2021
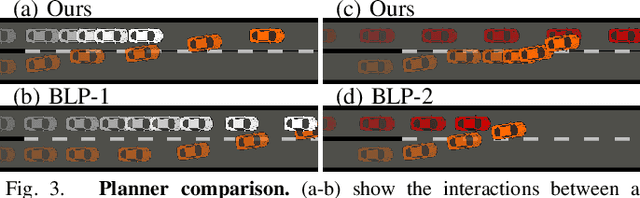

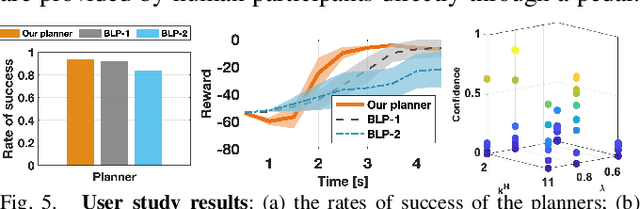
A human-centered robot needs to reason about the cognitive limitation and potential irrationality of its human partner to achieve seamless interactions. This paper proposes an anytime game-theoretic planner that integrates iterative reasoning models, a partially observable Markov decision process, and chance-constrained Monte-Carlo belief tree search for robot behavioral planning. Our planner enables a robot to safely and actively reason about its human partner's latent cognitive states (bounded intelligence and irrationality) in real-time to maximize its utility better. We validate our approach in an autonomous driving domain where our behavioral planner and a low-level motion controller hierarchically control an autonomous car to negotiate traffic merges. Simulations and user studies are conducted to show our planner's effectiveness.
Snippet Policy Network for Multi-class Varied-length ECG Early Classification
Jul 28, 2021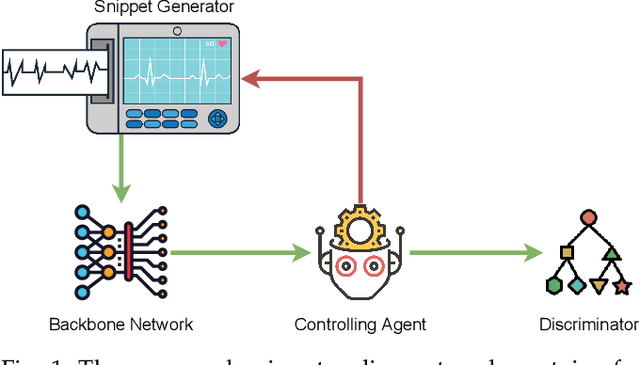
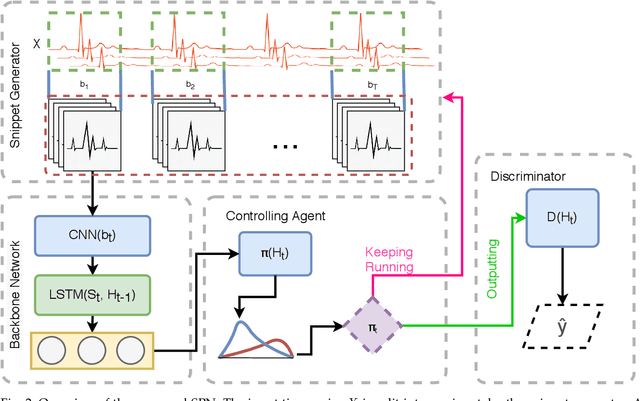
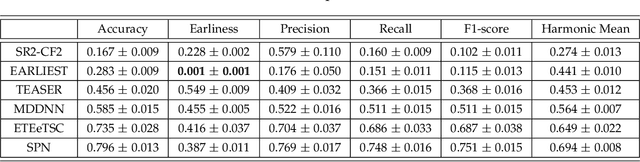
Arrhythmia detection from ECG is an important research subject in the prevention and diagnosis of cardiovascular diseases. The prevailing studies formulate arrhythmia detection from ECG as a time series classification problem. Meanwhile, early detection of arrhythmia presents a real-world demand for early prevention and diagnosis. In this paper, we address a problem of cardiovascular disease early classification, which is a varied-length and long-length time series early classification problem as well. For solving this problem, we propose a deep reinforcement learning-based framework, namely Snippet Policy Network (SPN), consisting of four modules, snippet generator, backbone network, controlling agent, and discriminator. Comparing to the existing approaches, the proposed framework features flexible input length, solves the dual-optimization solution of the earliness and accuracy goals. Experimental results demonstrate that SPN achieves an excellent performance of over 80\% in terms of accuracy. Compared to the state-of-the-art methods, at least 7% improvement on different metrics, including the precision, recall, F1-score, and harmonic mean, is delivered by the proposed SPN. To the best of our knowledge, this is the first work focusing on solving the cardiovascular early classification problem based on varied-length ECG data. Based on these excellent features from SPN, it offers a good exemplification for addressing all kinds of varied-length time series early classification problems.
RDD-Eclat: Approaches to Parallelize Eclat Algorithm on Spark RDD Framework (Extended Version)
Oct 22, 2021Frequent itemset mining (FIM) is a highly computational and data intensive algorithm. Therefore, parallel and distributed FIM algorithms have been designed to process large volume of data in a reduced time. Recently, a number of FIM algorithms have been designed on Hadoop MapReduce, a distributed big data processing framework. But, due to heavy disk I/O, MapReduce is found to be inefficient for the highly iterative FIM algorithms. Therefore, Spark, a more efficient distributed data processing framework, has been developed with in-memory computation and resilient distributed dataset (RDD) features to support the iterative algorithms. On this framework, Apriori and FP-Growth based FIM algorithms have been designed on the Spark RDD framework, but Eclat-based algorithm has not been explored yet. In this paper, RDD-Eclat, a parallel Eclat algorithm on the Spark RDD framework is proposed with its five variants. The proposed algorithms are evaluated on the various benchmark datasets, and the experimental results show that RDD-Eclat outperforms the Spark-based Apriori by many times. Also, the experimental results show the scalability of the proposed algorithms on increasing the number of cores and size of the dataset.
SIM-ECG: A Signal Importance Mask-driven ECGClassification System
Oct 28, 2021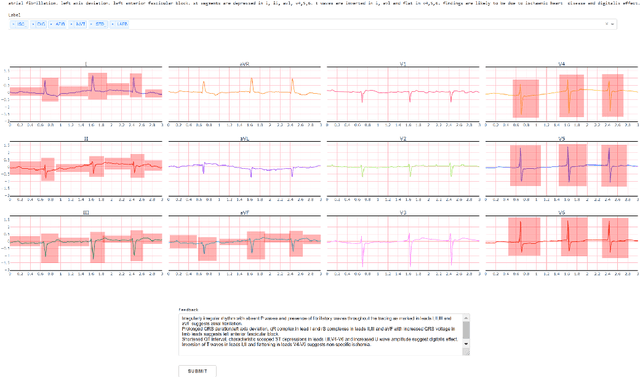

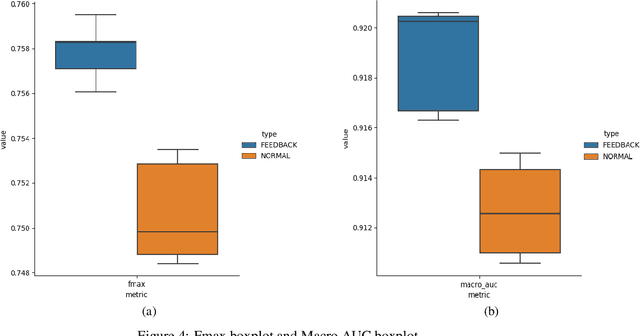
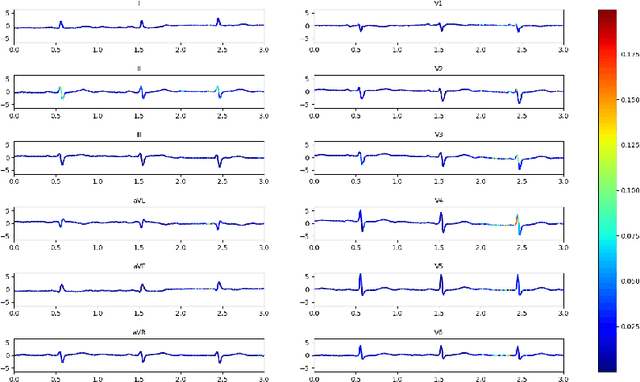
Heart disease is the number one killer, and ECGs can assist in the early diagnosis and prevention of deadly outcomes. Accurate ECG interpretation is critical in detecting heart diseases; however, they are often misinterpreted due to a lack of training or insufficient time spent to detect minute anomalies. Subsequently, researchers turned to machine learning to assist in the analysis. However, existing systems are not as accurate as skilled ECG readers, and black-box approaches to providing diagnosis result in a lack of trust by medical personnel in a given diagnosis. To address these issues, we propose a signal importance mask feedback-based machine learning system that continuously accepts feedback, improves accuracy, and ex-plains the resulting diagnosis. This allows medical personnel to quickly glance at the output and either accept the results, validate the explanation and diagnosis, or quickly correct areas of misinterpretation, giving feedback to the system for improvement. We have tested our system on a publicly available dataset consisting of healthy and disease-indicating samples. We empirically show that our algorithm is better in terms of standard performance measures such as F-score and MacroAUC compared to normal training baseline (without feedback); we also show that our model generates better interpretability maps.
On Margin Maximization in Linear and ReLU Networks
Oct 07, 2021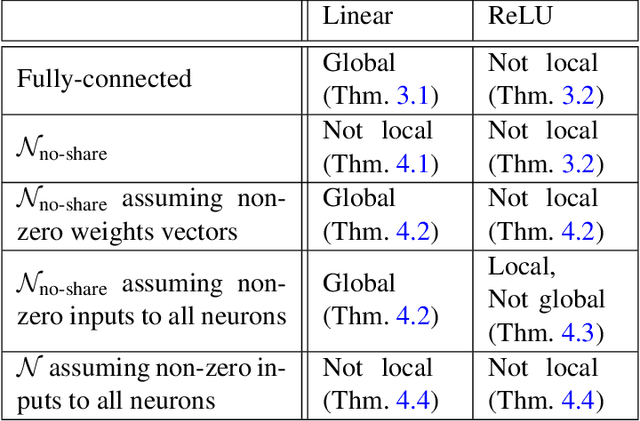
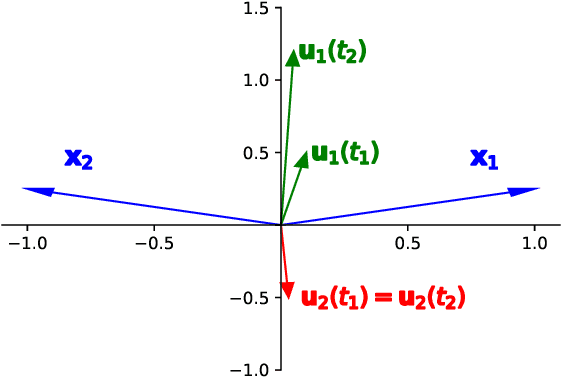
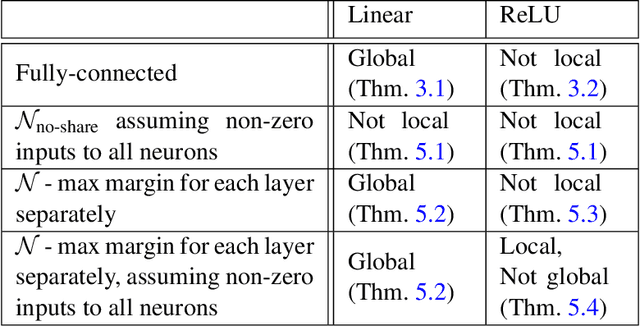
The implicit bias of neural networks has been extensively studied in recent years. Lyu and Li [2019] showed that in homogeneous networks trained with the exponential or the logistic loss, gradient flow converges to a KKT point of the max margin problem in the parameter space. However, that leaves open the question of whether this point will generally be an actual optimum of the max margin problem. In this paper, we study this question in detail, for several neural network architectures involving linear and ReLU activations. Perhaps surprisingly, we show that in many cases, the KKT point is not even a local optimum of the max margin problem. On the flip side, we identify multiple settings where a local or global optimum can be guaranteed. Finally, we answer a question posed in Lyu and Li [2019] by showing that for non-homogeneous networks, the normalized margin may strictly decrease over time.
Tile Embedding: A General Representation for Procedural Level Generation via Machine Learning
Oct 07, 2021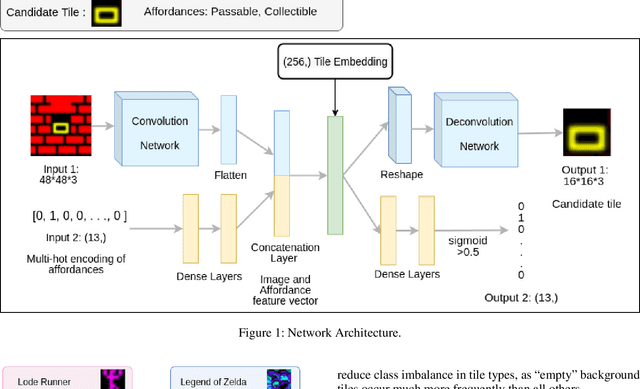
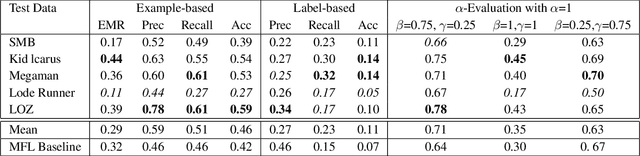
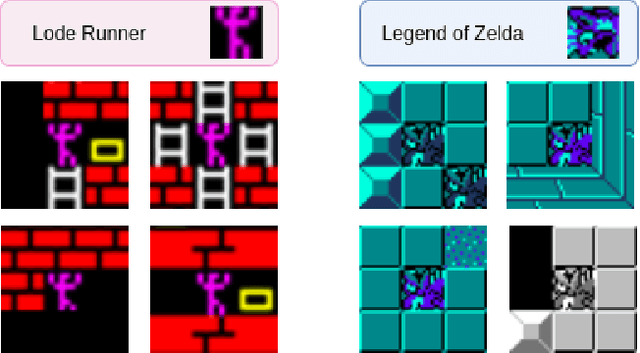
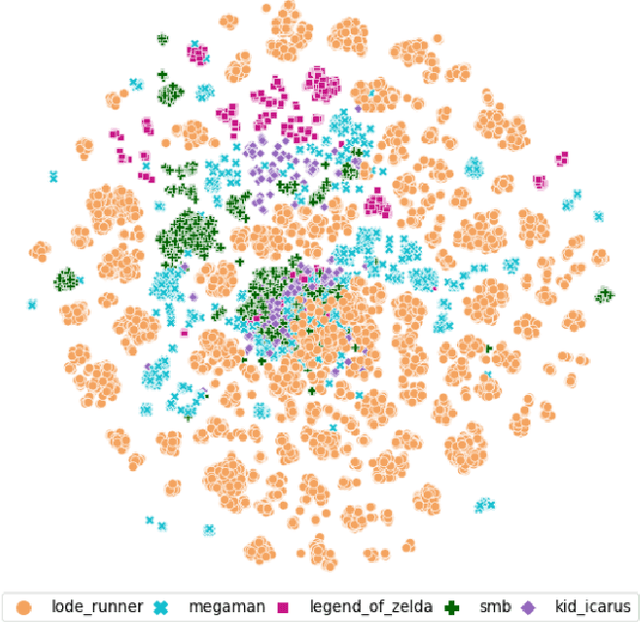
In recent years, Procedural Level Generation via Machine Learning (PLGML) techniques have been applied to generate game levels with machine learning. These approaches rely on human-annotated representations of game levels. Creating annotated datasets for games requires domain knowledge and is time-consuming. Hence, though a large number of video games exist, annotated datasets are curated only for a small handful. Thus current PLGML techniques have been explored in limited domains, with Super Mario Bros. as the most common example. To address this problem, we present tile embeddings, a unified, affordance-rich representation for tile-based 2D games. To learn this embedding, we employ autoencoders trained on the visual and semantic information of tiles from a set of existing, human-annotated games. We evaluate this representation on its ability to predict affordances for unseen tiles, and to serve as a PLGML representation for annotated and unannotated games.
* 8 pages, 5 figures, AIIDE 2021
Attention Mechanism for Multivariate Time Series Recurrent Model Interpretability Applied to the Ironmaking Industry
Jul 15, 2020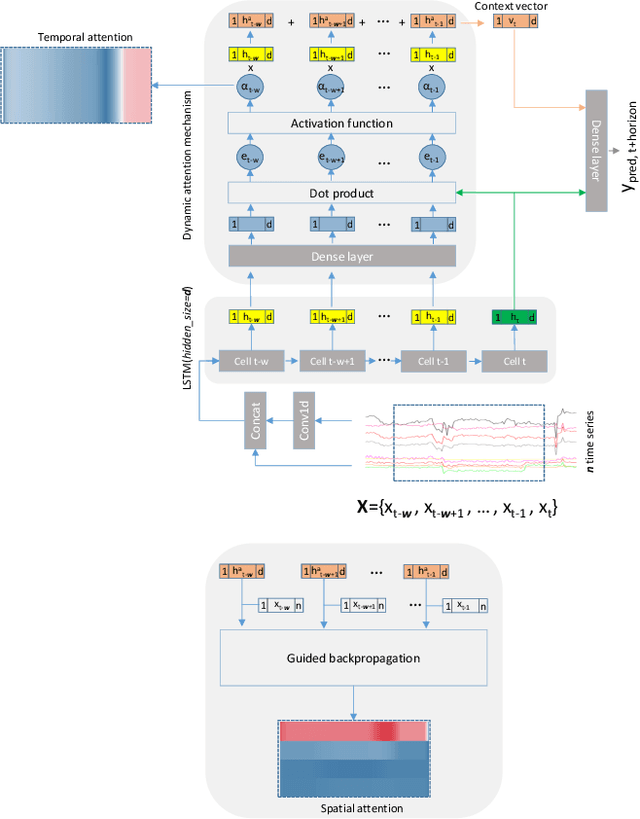
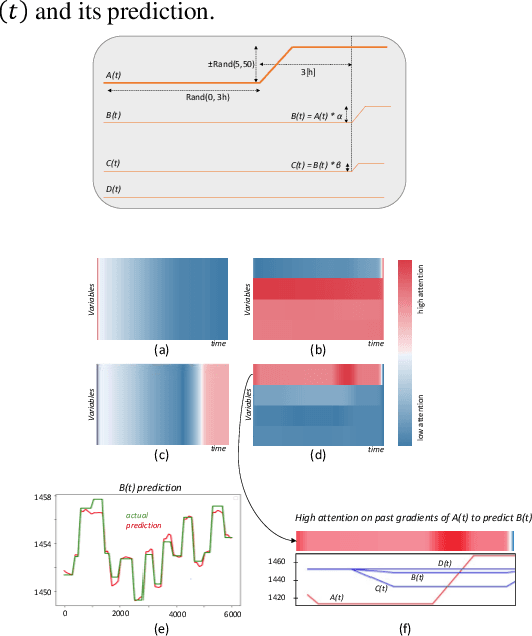
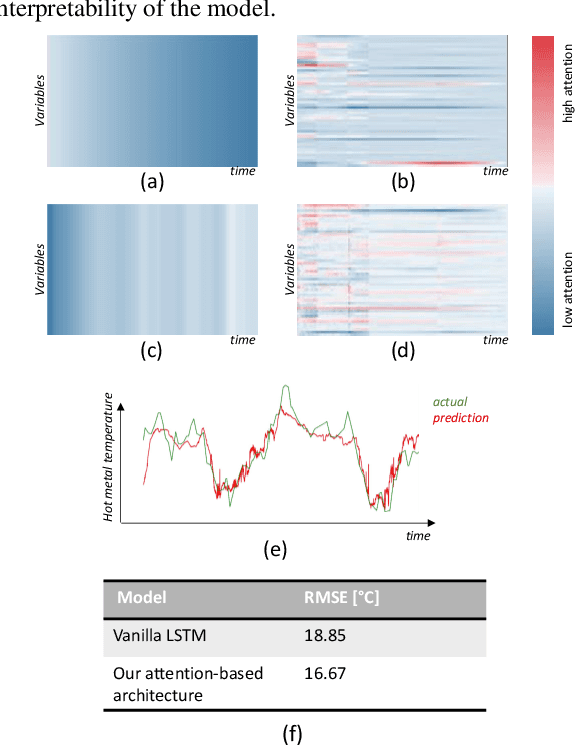
Data-driven model interpretability is a requirement to gain the acceptance of process engineers to rely on the prediction of a data-driven model to regulate industrial processes in the ironmaking industry. In the research presented in this paper, we focus on the development of an interpretable multivariate time series forecasting deep learning architecture for the temperature of the hot metal produced by a blast furnace. A Long Short-Term Memory (LSTM) based architecture enhanced with attention mechanism and guided backpropagation is proposed to accommodate the prediction with a local temporal interpretability for each input. Results are showing high potential for this architecture applied to blast furnace data and providing interpretability correctly reflecting the true complex variables relations dictated by the inherent blast furnace process, and with reduced prediction error compared to a recurrent-based deep learning architecture.