 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AnthroScore: A Computational Linguistic Measure of Anthropomorphism
Feb 03, 2024
Anthropomorphism, or the attribution of human-like characteristics to non-human entities, has shaped conversations about the impacts and possibilities of technology. We present AnthroScore, an automatic metric of implicit anthropomorphism in language. We use a masked language model to quantify how non-human entities are implicitly framed as human by the surrounding context. We show that AnthroScore corresponds with human judgments of anthropomorphism and dimensions of anthropomorphism described in social science literature. Motivated by concerns of misleading anthropomorphism in computer science discourse, we use AnthroScore to analyze 15 years of research papers and downstream news articles. In research papers, we find that anthropomorphism has steadily increased over time, and that papers related to language models have the most anthropomorphism. Within ACL papers, temporal increases in anthropomorphism are correlated with key neural advancements. Building upon concerns of scientific misinformation in mass media, we identify higher levels of anthropomorphism in news headlines compared to the research papers they cite. Since AnthroScore is lexicon-free, it can be directly applied to a wide range of text sources.
Is Registering Raw Tagged-MR Enough for Strain Estimation in the Era of Deep Learning?
Jan 31, 2024Magnetic Resonance Imaging with tagging (tMRI) has long been utilized for quantifying tissue motion and strain during deformation. However, a phenomenon known as tag fading, a gradual decrease in tag visibility over time, often complicates post-processing. The first contribution of this study is to model tag fading by considering the interplay between $T_1$ relaxation and the repeated application of radio frequency (RF) pulses during serial imaging sequences. This is a factor that has been overlooked in prior research on tMRI post-processing. Further, we have observed an emerging trend of utilizing raw tagged MRI within a deep learning-based (DL) registration framework for motion estimation. In this work, we evaluate and analyze the impact of commonly used image similarity objectives in training DL registrations on raw tMRI. This is then compared with the Harmonic Phase-based approach, a traditional approach which is claimed to be robust to tag fading. Our findings, derived from both simulated images and an actual phantom scan, reveal the limitations of various similarity losses in raw tMRI and emphasize caution in registration tasks where image intensity changes over time.
Predicting ATP binding sites in protein sequences using Deep Learning and Natural Language Processing
Feb 02, 2024Predicting ATP-Protein Binding sites in genes is of great significance in the field of Biology and Medicine. The majority of research in this field has been conducted through time- and resource-intensive 'wet experiments' in laboratories. Over the years, researchers have been investigating computational methods computational methods to accomplish the same goals, utilising the strength of advanced Deep Learning and NLP algorithms. In this paper, we propose to develop methods to classify ATP-Protein binding sites. We conducted various experiments mainly using PSSMs and several word embeddings as features. We used 2D CNNs and LightGBM classifiers as our chief Deep Learning Algorithms. The MP3Vec and BERT models have also been subjected to testing in our study. The outcomes of our experiments demonstrated improvement over the state-of-the-art benchmarks.
Conditioning non-linear and infinite-dimensional diffusion processes
Feb 02, 2024Generative diffusion models and many stochastic models in science and engineering naturally live in infinite dimensions before discretisation. To incorporate observed data for statistical and learning tasks, one needs to condition on observations. While recent work has treated conditioning linear processes in infinite dimensions, conditioning non-linear processes in infinite dimensions has not been explored. This paper conditions function valued stochastic processes without prior discretisation. To do so, we use an infinite-dimensional version of Girsanov's theorem to condition a function-valued stochastic process, leading to a stochastic differential equation (SDE) for the conditioned process involving the score. We apply this technique to do time series analysis for shapes of organisms in evolutionary biology, where we discretise via the Fourier basis and then learn the coefficients of the score function with score matching methods.
Control-Theoretic Techniques for Online Adaptation of Deep Neural Networks in Dynamical Systems
Feb 01, 2024Deep neural networks (DNNs), trained with gradient-based optimization and backpropagation, are currently the primary tool in modern artificial intelligence, machine learning, and data science. In many applications, DNNs are trained offline, through supervised learning or reinforcement learning, and deployed online for inference. However, training DNNs with standard backpropagation and gradient-based optimization gives no intrinsic performance guarantees or bounds on the DNN, which is essential for applications such as controls. Additionally, many offline-training and online-inference problems, such as sim2real transfer of reinforcement learning policies, experience domain shift from the training distribution to the real-world distribution. To address these stability and transfer learning issues, we propose using techniques from control theory to update DNN parameters online. We formulate the fully-connected feedforward DNN as a continuous-time dynamical system, and we propose novel last-layer update laws that guarantee desirable error convergence under various conditions on the time derivative of the DNN input vector. We further show that training the DNN under spectral normalization controls the upper bound of the error trajectories of the online DNN predictions, which is desirable when numerically differentiated quantities or noisy state measurements are input to the DNN. The proposed online DNN adaptation laws are validated in simulation to learn the dynamics of the Van der Pol system under domain shift, where parameters are varied in inference from the training dataset. The simulations demonstrate the effectiveness of using control-theoretic techniques to derive performance improvements and guarantees in DNN-based learning systems.
LatticeGraphNet: A two-scale graph neural operator for simulating lattice structures
Feb 01, 2024This study introduces a two-scale Graph Neural Operator (GNO), namely, LatticeGraphNet (LGN), designed as a surrogate model for costly nonlinear finite-element simulations of three-dimensional latticed parts and structures. LGN has two networks: LGN-i, learning the reduced dynamics of lattices, and LGN-ii, learning the mapping from the reduced representation onto the tetrahedral mesh. LGN can predict deformation for arbitrary lattices, therefore the name operator. Our approach significantly reduces inference time while maintaining high accuracy for unseen simulations, establishing the use of GNOs as efficient surrogate models for evaluating mechanical responses of lattices and structures.
Evaluation of Zadoff-Chu, Kasami and Chirp based encoding schemes for Acoustic Local Positioning Systems
Feb 04, 2024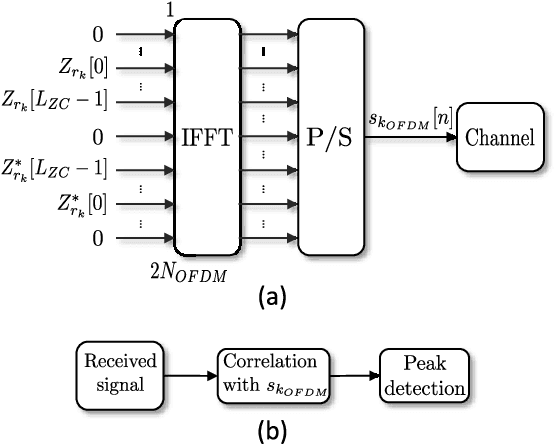
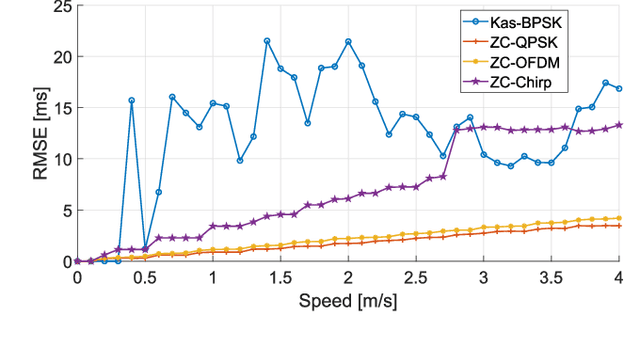
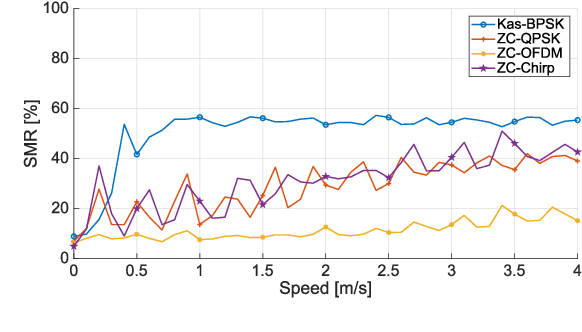
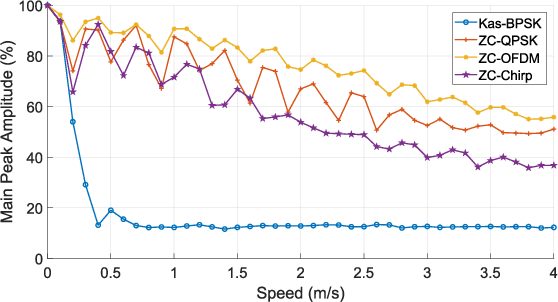
The task of determining the physical coordinates of a target in indoor environments is still a key factor for many applications including people and robot navigation, user tracking, location-based advertising, augmented reality, gaming, emergency response or ambient assisted living environments. Among the different possibilities for indoor positioning, Acoustic Local Positioning Systems (ALPS) have the potential for centimeter level positioning accuracy with coverage distances up to tens of meters. In addition, acoustic transducers are small, low cost and reliable thanks to the room constrained propagation of these mechanical waves. Waveform design (coding and modulation) is usually incorporated into these systems to facilitate the detection of the transmitted signals at the receiver. The aperiodic correlation properties of the emitted signals have a large impact on how the ALPS cope with common impairment factors such as multipath propagation, multiple access interference, Doppler shifting, near-far effect or ambient noise. This work analyzes three of the most promising families of codes found in the literature for ALPS: Kasami codes, Zadoff-Chu and Orthogonal Chirp signals. The performance of these codes is evaluated in terms of time of arrival accuracy and characterized by means of model simulation under realistic conditions and by means of experimental tests in controlled environments. The results derived from this study can be of interest for other applications based on spreading sequences, such as underwater acoustic systems, ultrasonic imaging or even Code Division Multiple Access (CDMA) communications systems.
BECLR: Batch Enhanced Contrastive Few-Shot Learning
Feb 04, 2024Learning quickly from very few labeled samples is a fundamental attribute that separates machines and humans in the era of deep representation learning. Unsupervised few-shot learning (U-FSL) aspires to bridge this gap by discarding the reliance on annotations at training time. Intrigued by the success of contrastive learning approaches in the realm of U-FSL, we structurally approach their shortcomings in both pretraining and downstream inference stages. We propose a novel Dynamic Clustered mEmory (DyCE) module to promote a highly separable latent representation space for enhancing positive sampling at the pretraining phase and infusing implicit class-level insights into unsupervised contrastive learning. We then tackle the, somehow overlooked yet critical, issue of sample bias at the few-shot inference stage. We propose an iterative Optimal Transport-based distribution Alignment (OpTA) strategy and demonstrate that it efficiently addresses the problem, especially in low-shot scenarios where FSL approaches suffer the most from sample bias. We later on discuss that DyCE and OpTA are two intertwined pieces of a novel end-to-end approach (we coin as BECLR), constructively magnifying each other's impact. We then present a suite of extensive quantitative and qualitative experimentation to corroborate that BECLR sets a new state-of-the-art across ALL existing U-FSL benchmarks (to the best of our knowledge), and significantly outperforms the best of the current baselines (codebase available at: https://github.com/stypoumic/BECLR).
EK-Net:Real-time Scene Text Detection with Expand Kernel Distance
Jan 22, 2024Recently, scene text detection has received significant attention due to its wide application. However, accurate detection in complex scenes of multiple scales, orientations, and curvature remains a challenge. Numerous detection methods adopt the Vatti clipping (VC) algorithm for multiple-instance training to address the issue of arbitrary-shaped text. Yet we identify several bias results from these approaches called the "shrinked kernel". Specifically, it refers to a decrease in accuracy resulting from an output that overly favors the text kernel. In this paper, we propose a new approach named Expand Kernel Network (EK-Net) with expand kernel distance to compensate for the previous deficiency, which includes three-stages regression to complete instance detection. Moreover, EK-Net not only realize the precise positioning of arbitrary-shaped text, but also achieve a trade-off between performance and speed. Evaluation results demonstrate that EK-Net achieves state-of-the-art or competitive performance compared to other advanced methods, e.g., F-measure of 85.72% at 35.42 FPS on ICDAR 2015, F-measure of 85.75% at 40.13 FPS on CTW1500.
TrackGPT -- A generative pre-trained transformer for cross-domain entity trajectory forecasting
Jan 29, 2024The forecasting of entity trajectories at future points in time is a critical capability gap in applications across both Commercial and Defense sectors. Transformers, and specifically Generative Pre-trained Transformer (GPT) networks have recently revolutionized several fields of Artificial Intelligence, most notably Natural Language Processing (NLP) with the advent of Large Language Models (LLM) like OpenAI's ChatGPT. In this research paper, we introduce TrackGPT, a GPT-based model for entity trajectory forecasting that has shown utility across both maritime and air domains, and we expect to perform well in others. TrackGPT stands as a pioneering GPT model capable of producing accurate predictions across diverse entity time series datasets, demonstrating proficiency in generating both long-term forecasts with sustained accuracy and short-term forecasts with high precision. We present benchmarks against state-of-the-art deep learning techniques, showing that TrackGPT's forecasting capability excels in terms of accuracy, reliability, and modularity. Importantly, TrackGPT achieves these results while remaining domain-agnostic and requiring minimal data features (only location and time) compared to models achieving similar performance. In conclusion, our findings underscore the immense potential of applying GPT architectures to the task of entity trajectory forecasting, exemplified by the innovative TrackGPT model.