 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Surprising Simplicity of the Early-Time Learning Dynamics of Neural Networks
Jun 25, 2020
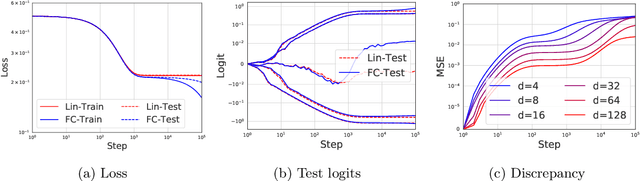
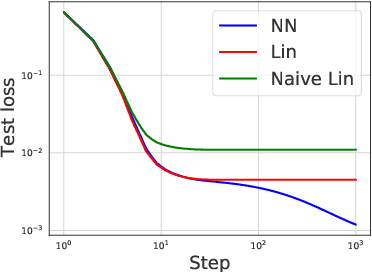
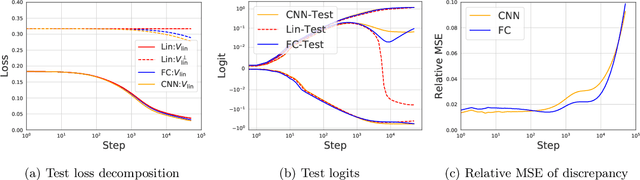
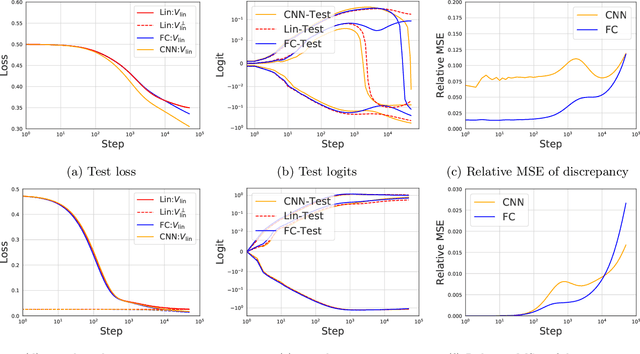
Modern neural networks are often regarded as complex black-box functions whose behavior is difficult to understand owing to their nonlinear dependence on the data and the nonconvexity in their loss landscapes. In this work, we show that these common perceptions can be completely false in the early phase of learning. In particular, we formally prove that, for a class of well-behaved input distributions, the early-time learning dynamics of a two-layer fully-connected neural network can be mimicked by training a simple linear model on the inputs. We additionally argue that this surprising simplicity can persist in networks with more layers and with convolutional architecture, which we verify empirically. Key to our analysis is to bound the spectral norm of the difference between the Neural Tangent Kernel (NTK) at initialization and an affine transform of the data kernel; however, unlike many previous results utilizing the NTK, we do not require the network to have disproportionately large width, and the network is allowed to escape the kernel regime later in training.
Multiple shooting with neural differential equations
Sep 14, 2021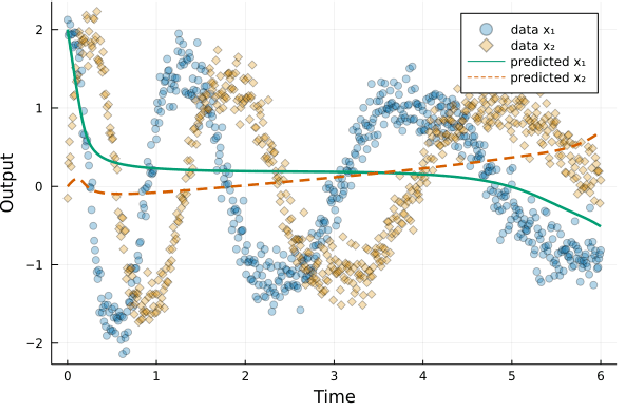
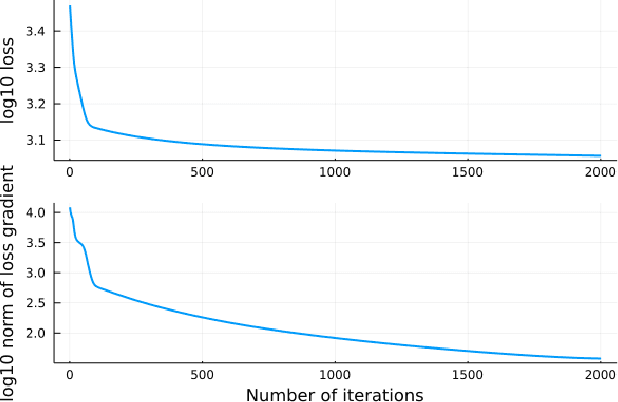
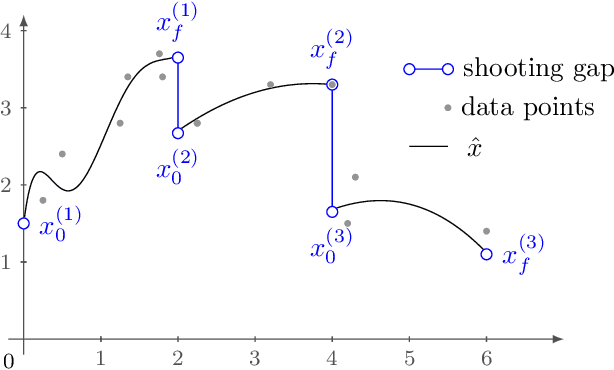
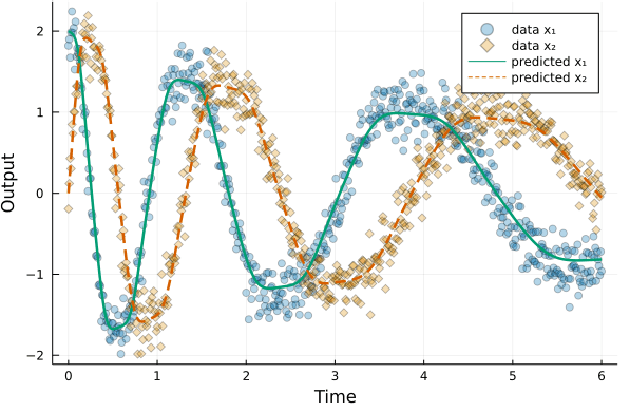
Neural differential equations have recently emerged as a flexible data-driven/hybrid approach to model time-series data. This work experimentally demonstrates that if the data contains oscillations, then standard fitting of a neural differential equation may give flattened out trajectory that fails to describe the data. We then introduce the multiple shooting method and present successful demonstrations of this method for the fitting of a neural differential equation to two datasets (synthetic and experimental) that the standard approach fails to fit. Constraints introduced by multiple shooting can be satisfied using a penalty or augmented Lagrangian method.
Guided-GAN: Adversarial Representation Learning for Activity Recognition with Wearables
Oct 12, 2021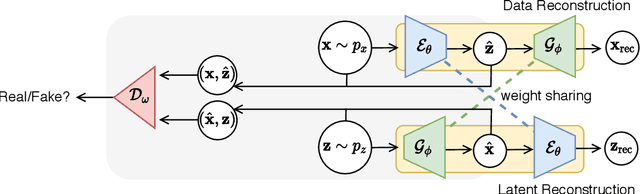

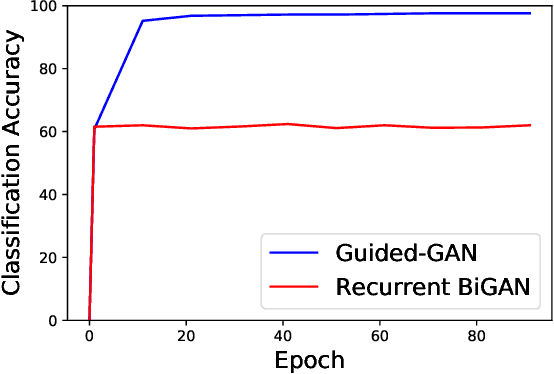
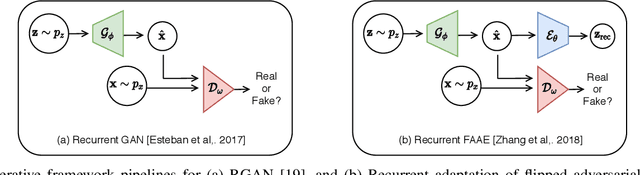
Human activity recognition (HAR) is an important research field in ubiquitous computing where the acquisition of large-scale labeled sensor data is tedious, labor-intensive and time consuming. State-of-the-art unsupervised remedies investigated to alleviate the burdens of data annotations in HAR mainly explore training autoencoder frameworks. In this paper: we explore generative adversarial network (GAN) paradigms to learn unsupervised feature representations from wearable sensor data; and design a new GAN framework-Geometrically-Guided GAN or Guided-GAN-for the task. To demonstrate the effectiveness of our formulation, we evaluate the features learned by Guided-GAN in an unsupervised manner on three downstream classification benchmarks. Our results demonstrate Guided-GAN to outperform existing unsupervised approaches whilst closely approaching the performance with fully supervised learned representations. The proposed approach paves the way to bridge the gap between unsupervised and supervised human activity recognition whilst helping to reduce the cost of human data annotation tasks.
EISPY2D: An Open-Source Python Library for the Development and Comparison of Algorithms in Two-Dimensional Electromagnetic Inverse Scattering Problems
Nov 03, 2021
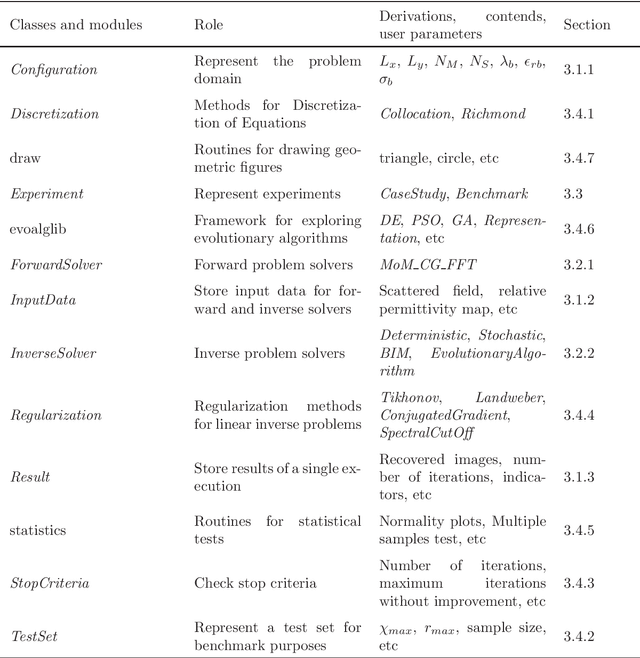
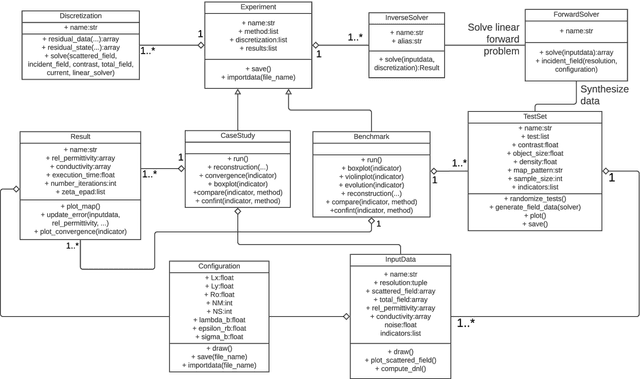

Microwave Imaging is an essential technique for reconstructing the electrical properties of an inaccessible medium. Many approaches have been proposed employing algorithms to solve the Electromagnetic Inverse Scattering Problem associated with this technique. In addition to the algorithm, one needs to implement adequate structures to represent the problem domain, the input data, the results of the adopted metrics, and experimentation routines. We introduce an open-source Python library that offers a modular and standardized framework for implementing and evaluating the performance of algorithms for the problem. Based on the implementation of fundamental components for the execution of algorithms, this library aims to facilitate the development and discussion of new methods. Through a modular structure organized into classes, researchers can design their case studies and benchmarking experiments relying on features such as test randomization, specific metrics, and statistical comparison. To the best of the authors' knowledge, it is the first time that such tools for benchmarking and comparison are introduced for microwave imaging algorithms. In addition, two new metrics for location and shape recovery are presented. In this work, we introduce the principles for the design of the problem components and provide studies to exemplify the main aspects of this library. It is freely distributed through a Github repository that can be accessed from https://andre-batista.github.io/eispy2d/.
Fairness Maximization among Offline Agents in Online-Matching Markets
Sep 18, 2021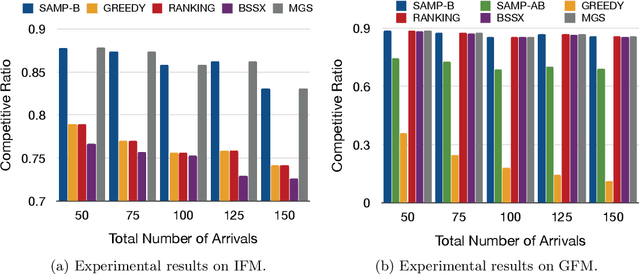
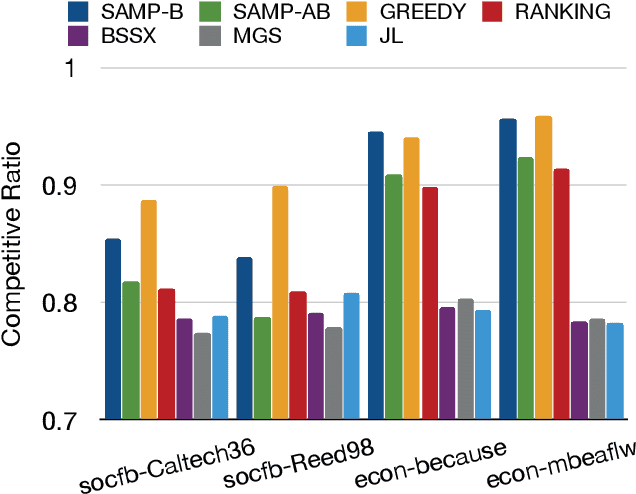
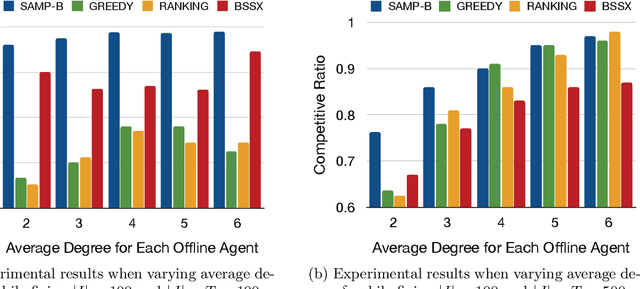
Matching markets involve heterogeneous agents (typically from two parties) who are paired for mutual benefit. During the last decade, matching markets have emerged and grown rapidly through the medium of the Internet. They have evolved into a new format, called Online Matching Markets (OMMs), with examples ranging from crowdsourcing to online recommendations to ridesharing. There are two features distinguishing OMMs from traditional matching markets. One is the dynamic arrival of one side of the market: we refer to these as online agents while the rest are offline agents. Examples of online and offline agents include keywords (online) and sponsors (offline) in Google Advertising; workers (online) and tasks (offline) in Amazon Mechanical Turk (AMT); riders (online) and drivers (offline when restricted to a short time window) in ridesharing. The second distinguishing feature of OMMs is the real-time decision-making element. However, studies have shown that the algorithms making decisions in these OMMs leave disparities in the match rates of offline agents. For example, tasks in neighborhoods of low socioeconomic status rarely get matched to gig workers, and drivers of certain races/genders get discriminated against in matchmaking. In this paper, we propose online matching algorithms which optimize for either individual or group-level fairness among offline agents in OMMs. We present two linear-programming (LP) based sampling algorithms, which achieve online competitive ratios at least 0.725 for individual fairness maximization (IFM) and 0.719 for group fairness maximization (GFM), respectively. We conduct extensive numerical experiments and results show that our boosted version of sampling algorithms are not only conceptually easy to implement but also highly effective in practical instances of fairness-maximization-related models.
Learning Not to Reconstruct Anomalies
Oct 24, 2021
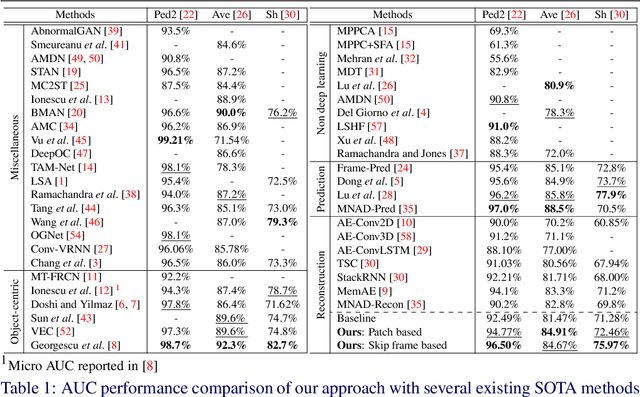
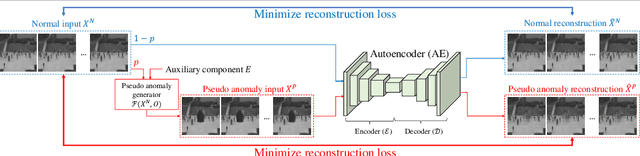

Video anomaly detection is often seen as one-class classification (OCC) problem due to the limited availability of anomaly examples. Typically, to tackle this problem, an autoencoder (AE) is trained to reconstruct the input with training set consisting only of normal data. At test time, the AE is then expected to well reconstruct the normal data while poorly reconstructing the anomalous data. However, several studies have shown that, even with only normal data training, AEs can often start reconstructing anomalies as well which depletes the anomaly detection performance. To mitigate this problem, we propose a novel methodology to train AEs with the objective of reconstructing only normal data, regardless of the input (i.e., normal or abnormal). Since no real anomalies are available in the OCC settings, the training is assisted by pseudo anomalies that are generated by manipulating normal data to simulate the out-of-normal-data distribution. We additionally propose two ways to generate pseudo anomalies: patch and skip frame based. Extensive experiments on three challenging video anomaly datasets demonstrate the effectiveness of our method in improving conventional AEs, achieving state-of-the-art performance.
Blockage Prediction Using Wireless Signatures: Deep Learning Enables Real-World Demonstration
Nov 16, 2021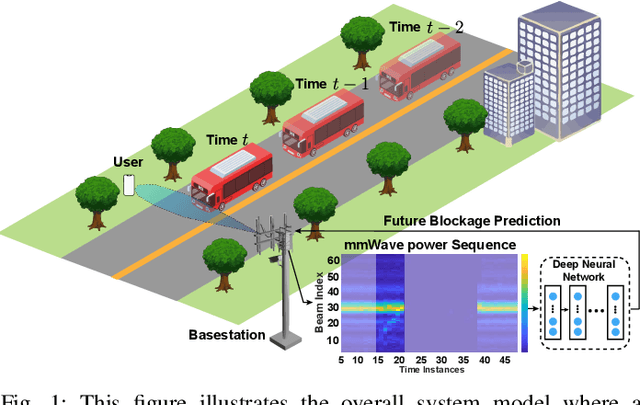
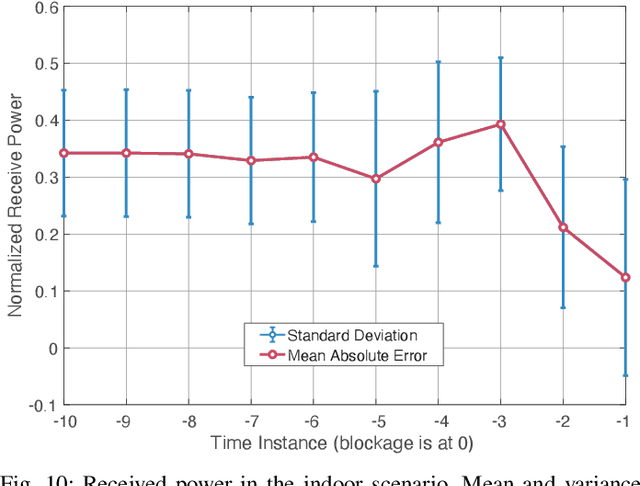
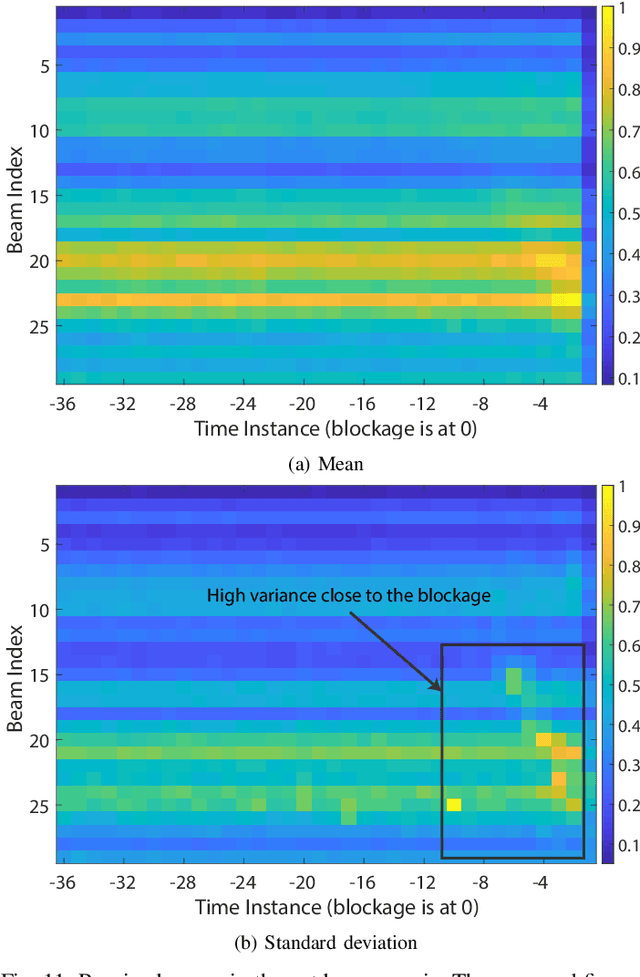
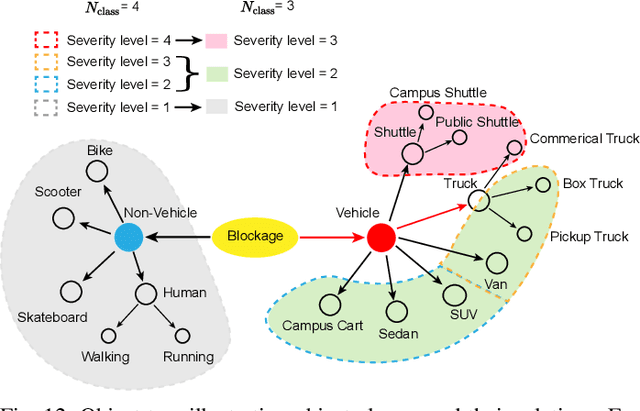
Overcoming the link blockage challenges is essential for enhancing the reliability and latency of millimeter wave (mmWave) and sub-terahertz (sub-THz) communication networks. Previous approaches relied mainly on either (i) multiple-connectivity, which under-utilizes the network resources, or on (ii) the use of out-of-band and non-RF sensors to predict link blockages, which is associated with increased cost and system complexity. In this paper, we propose a novel solution that relies only on in-band mmWave wireless measurements to proactively predict future dynamic line-of-sight (LOS) link blockages. The proposed solution utilizes deep neural networks and special patterns of received signal power, that we call pre-blockage wireless signatures to infer future blockages. Specifically, the developed machine learning models attempt to predict: (i) If a future blockage will occur? (ii) When will this blockage happen? (iii) What is the type of the blockage? And (iv) what is the direction of the moving blockage? To evaluate our proposed approach, we build a large-scale real-world dataset comprising nearly $0.5$ million data points (mmWave measurements) for both indoor and outdoor blockage scenarios. The results, using this dataset, show that the proposed approach can successfully predict the occurrence of future dynamic blockages with more than 85\% accuracy. Further, for the outdoor scenario with highly-mobile vehicular blockages, the proposed model can predict the exact time of the future blockage with less than $80$ms error for blockages happening within the future $500$ms. These results, among others, highlight the promising gains of the proposed proactive blockage prediction solution which could potentially enhance the reliability and latency of future wireless networks.
"The Squawk Bot": Joint Learning of Time Series and Text Data Modalities for Automated Financial Information Filtering
Dec 20, 2019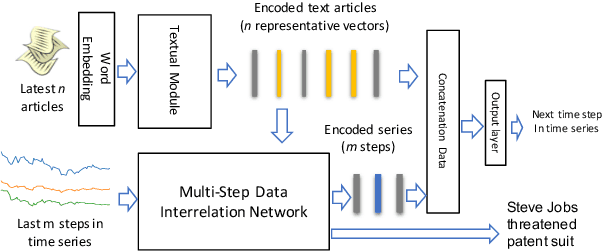
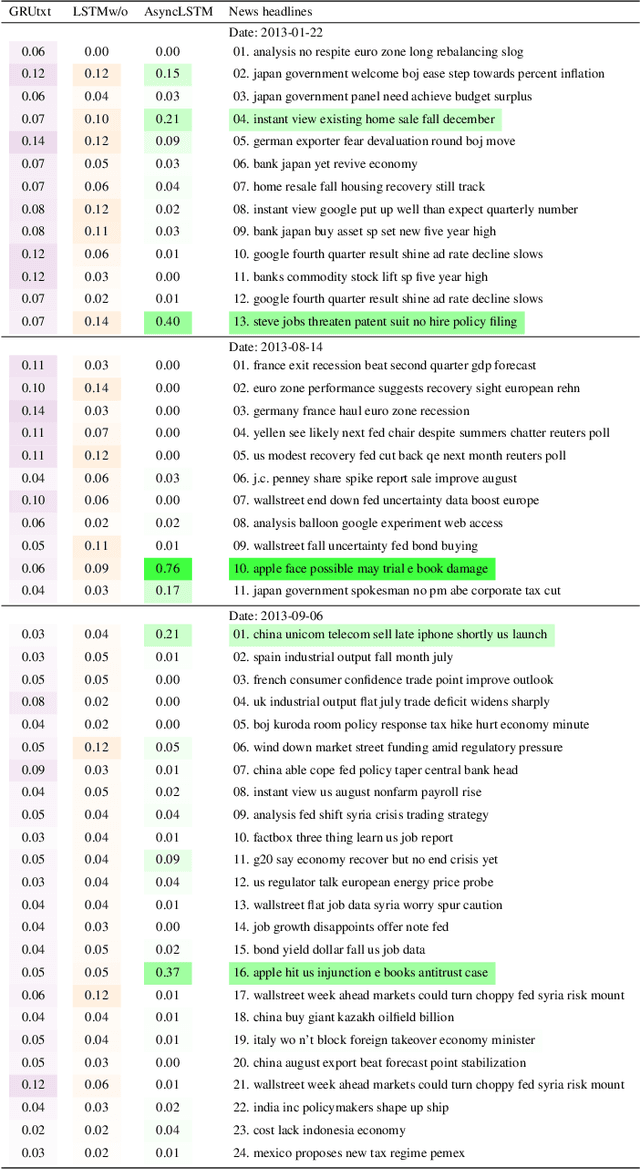
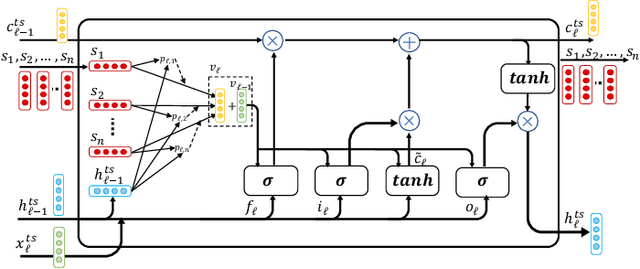
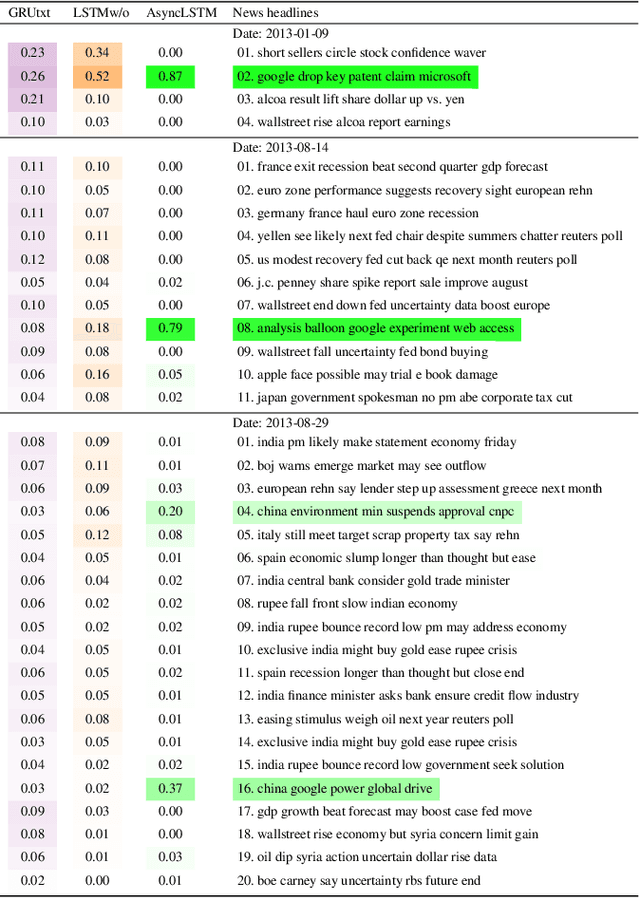
Multimodal analysis that uses numerical time series and textual corpora as input data sources is becoming a promising approach, especially in the financial industry. However, the main focus of such analysis has been on achieving high prediction accuracy while little effort has been spent on the important task of understanding the association between the two data modalities. Performance on the time series hence receives little explanation though human-understandable textual information is available. In this work, we address the problem of given a numerical time series, and a general corpus of textual stories collected in the same period of the time series, the task is to timely discover a succinct set of textual stories associated with that time series. Towards this goal, we propose a novel multi-modal neural model called MSIN that jointly learns both numerical time series and categorical text articles in order to unearth the association between them. Through multiple steps of data interrelation between the two data modalities, MSIN learns to focus on a small subset of text articles that best align with the performance in the time series. This succinct set is timely discovered and presented as recommended documents, acting as automated information filtering, for the given time series. We empirically evaluate the performance of our model on discovering relevant news articles for two stock time series from Apple and Google companies, along with the daily news articles collected from the Thomson Reuters over a period of seven consecutive years. The experimental results demonstrate that MSIN achieves up to 84.9% and 87.2% in recalling the ground truth articles respectively to the two examined time series, far more superior to state-of-the-art algorithms that rely on conventional attention mechanism in deep learning.
AnchorGAE: General Data Clustering via $O(n)$ Bipartite Graph Convolution
Nov 12, 2021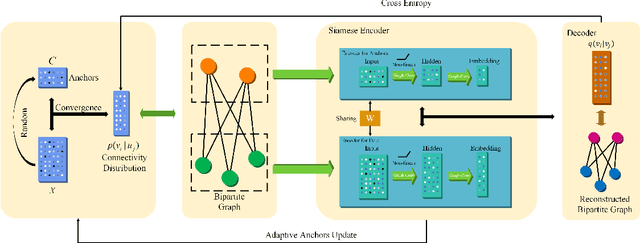
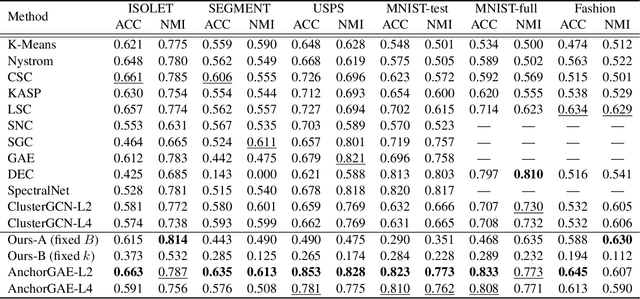

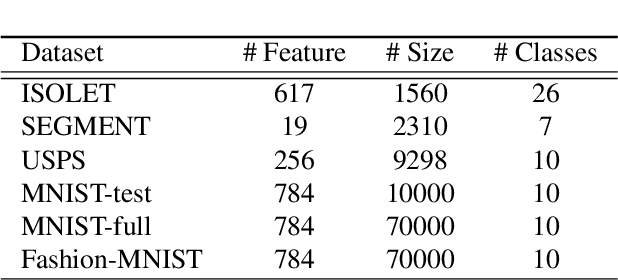
Graph-based clustering plays an important role in clustering tasks. As graph convolution network (GCN), a variant of neural networks on graph-type data, has achieved impressive performance, it is attractive to find whether GCNs can be used to augment the graph-based clustering methods on non-graph data, i.e., general data. However, given $n$ samples, the graph-based clustering methods usually need at least $O(n^2)$ time to build graphs and the graph convolution requires nearly $O(n^2)$ for a dense graph and $O(|\mathcal{E}|)$ for a sparse one with $|\mathcal{E}|$ edges. In other words, both graph-based clustering and GCNs suffer from severe inefficiency problems. To tackle this problem and further employ GCN to promote the capacity of graph-based clustering, we propose a novel clustering method, AnchorGAE. As the graph structure is not provided in general clustering scenarios, we first show how to convert a non-graph dataset into a graph by introducing the generative graph model, which is used to build GCNs. Anchors are generated from the original data to construct a bipartite graph such that the computational complexity of graph convolution is reduced from $O(n^2)$ and $O(|\mathcal{E}|)$ to $O(n)$. The succeeding steps for clustering can be easily designed as $O(n)$ operations. Interestingly, the anchors naturally lead to a siamese GCN architecture. The bipartite graph constructed by anchors is updated dynamically to exploit the high-level information behind data. Eventually, we theoretically prove that the simple update will lead to degeneration and a specific strategy is accordingly designed.
Multi-Task Processes
Oct 29, 2021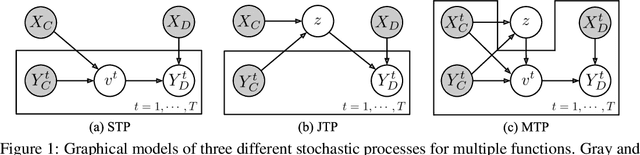
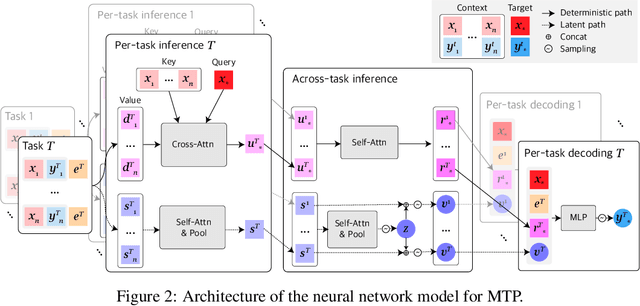
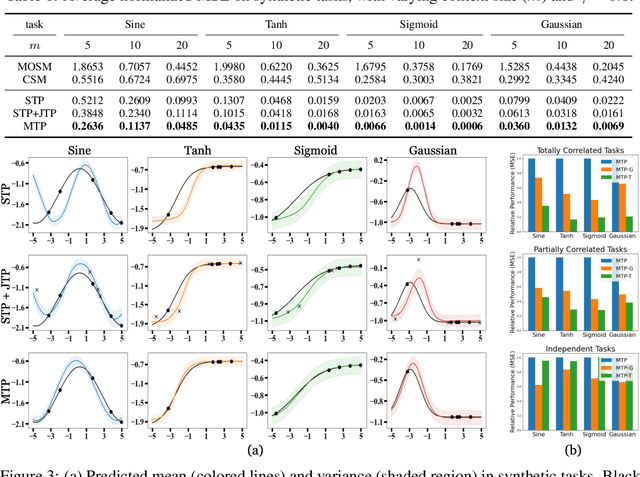
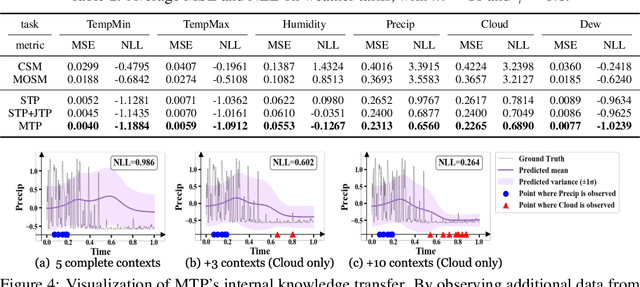
Neural Processes (NPs) consider a task as a function realized from a stochastic process and flexibly adapt to unseen tasks through inference on functions. However, naive NPs can model data from only a single stochastic process and are designed to infer each task independently. Since many real-world data represent a set of correlated tasks from multiple sources (e.g., multiple attributes and multi-sensor data), it is beneficial to infer them jointly and exploit the underlying correlation to improve the predictive performance. To this end, we propose Multi-Task Processes (MTPs), an extension of NPs designed to jointly infer tasks realized from multiple stochastic processes. We build our MTPs in a hierarchical manner such that inter-task correlation is considered by conditioning all per-task latent variables on a single global latent variable. In addition, we further design our MTPs so that they can address multi-task settings with incomplete data (i.e., not all tasks share the same set of input points), which has high practical demands in various applications. Experiments demonstrate that MTPs can successfully model multiple tasks jointly by discovering and exploiting their correlations in various real-world data such as time series of weather attributes and pixel-aligned visual modalities.