 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reducing the Deployment-Time Inference Control Costs of Deep Reinforcement Learning Agents via an Asymmetric Architecture
May 30, 2021
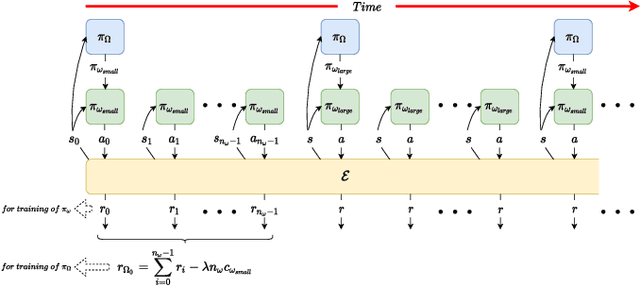
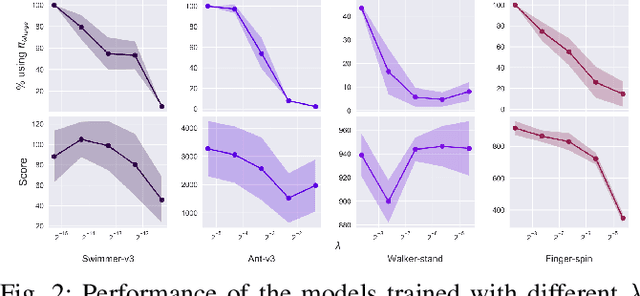
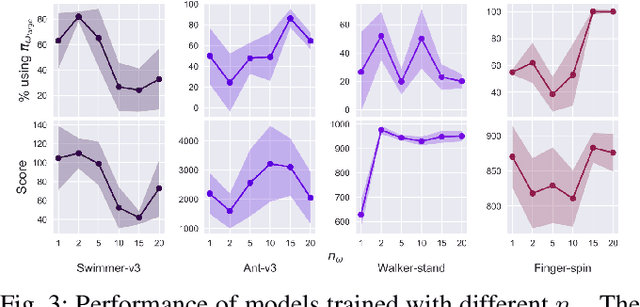
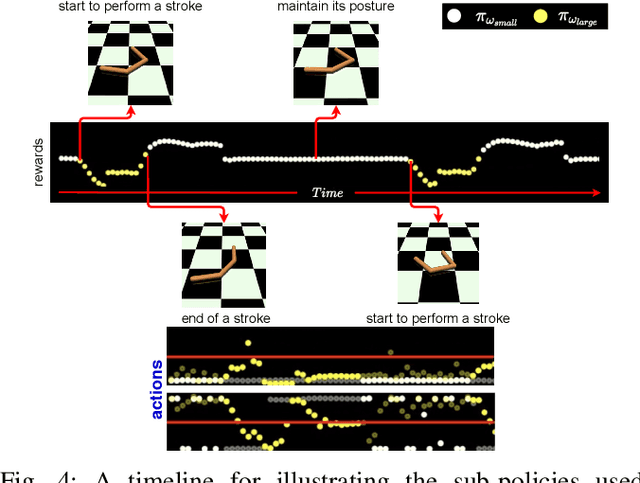
Deep reinforcement learning (DRL) has been demonstrated to provide promising results in several challenging decision making and control tasks. However, the required inference costs of deep neural networks (DNNs) could prevent DRL from being applied to mobile robots which cannot afford high energy-consuming computations. To enable DRL methods to be affordable in such energy-limited platforms, we propose an asymmetric architecture that reduces the overall inference costs via switching between a computationally expensive policy and an economic one. The experimental results evaluated on a number of representative benchmark suites for robotic control tasks demonstrate that our method is able to reduce the inference costs while retaining the agent's overall performance.
Damage Estimation and Localization from Sparse Aerial Imagery
Nov 10, 2021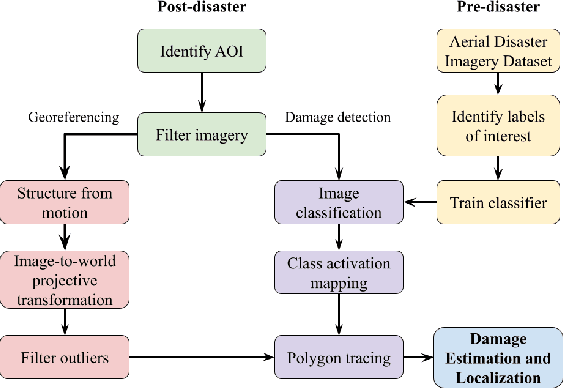

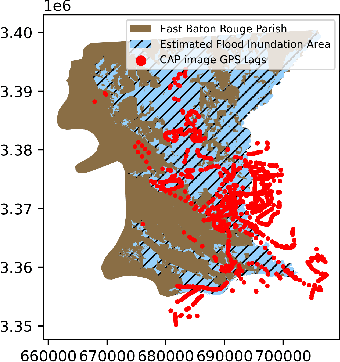
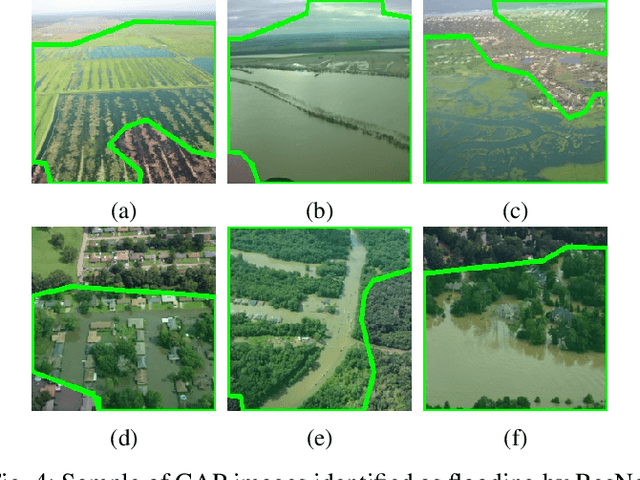
Aerial images provide important situational awareness for responding to natural disasters such as hurricanes. They are well-suited for providing information for damage estimation and localization (DEL); i.e., characterizing the type and spatial extent of damage following a disaster. Despite recent advances in sensing and unmanned aerial systems technology, much of post-disaster aerial imagery is still taken by handheld DSLR cameras from small, manned, fixed-wing aircraft. However, these handheld cameras lack IMU information, and images are taken opportunistically post-event by operators. As such, DEL from such imagery is still a highly manual and time-consuming process. We propose an approach to both detect damage in aerial images and localize it in world coordinates, with specific focus on detecting and localizing flooding. The approach is based on using structure from motion to relate image coordinates to world coordinates via a projective transformation, using class activation mapping to detect the extent of damage in an image, and applying the projective transformation to localize damage in world coordinates. We evaluate the performance of our approach on post-event data from the 2016 Louisiana floods, and find that our approach achieves a precision of 88%. Given this high precision using limited data, we argue that this approach is currently viable for fast and effective DEL from handheld aerial imagery for disaster response.
Fairness Maximization among Offline Agents in Online-Matching Markets
Sep 26, 2021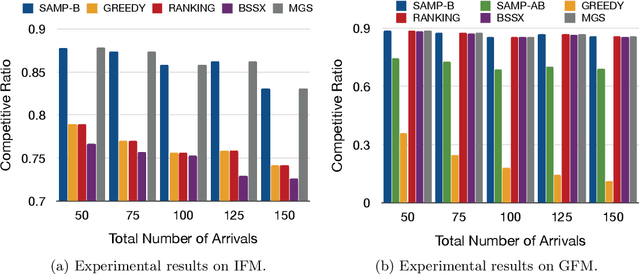
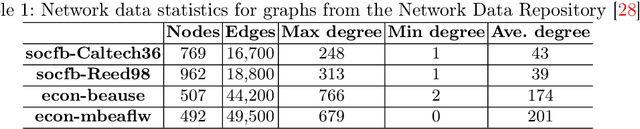
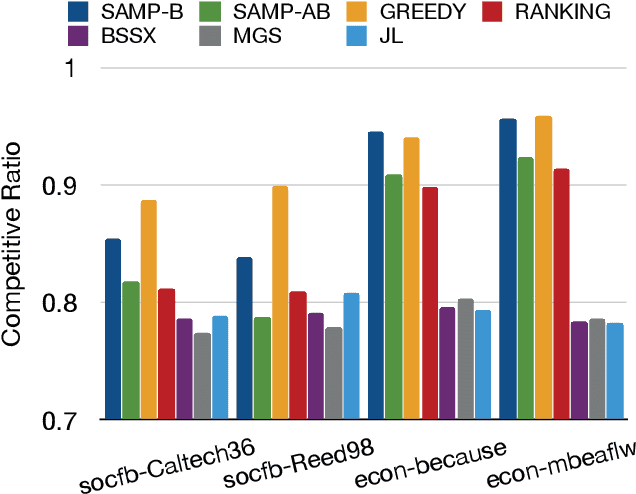
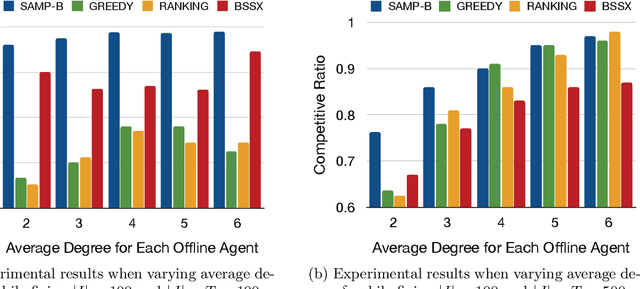
Matching markets involve heterogeneous agents (typically from two parties) who are paired for mutual benefit. During the last decade, matching markets have emerged and grown rapidly through the medium of the Internet. They have evolved into a new format, called Online Matching Markets (OMMs), with examples ranging from crowdsourcing to online recommendations to ridesharing. There are two features distinguishing OMMs from traditional matching markets. One is the dynamic arrival of one side of the market: we refer to these as online agents while the rest are offline agents. Examples of online and offline agents include keywords (online) and sponsors (offline) in Google Advertising; workers (online) and tasks (offline) in Amazon Mechanical Turk (AMT); riders (online) and drivers (offline when restricted to a short time window) in ridesharing. The second distinguishing feature of OMMs is the real-time decision-making element. However, studies have shown that the algorithms making decisions in these OMMs leave disparities in the match rates of offline agents. For example, tasks in neighborhoods of low socioeconomic status rarely get matched to gig workers, and drivers of certain races/genders get discriminated against in matchmaking. In this paper, we propose online matching algorithms which optimize for either individual or group-level fairness among offline agents in OMMs. We present two linear-programming (LP) based sampling algorithms, which achieve online competitive ratios at least 0.725 for individual fairness maximization (IFM) and 0.719 for group fairness maximization (GFM), respectively. We conduct extensive numerical experiments and results show that our boosted version of sampling algorithms are not only conceptually easy to implement but also highly effective in practical instances of fairness-maximization-related models.
Advancing Brain Metastases Detection in T1-Weighted Contrast-Enhanced 3D MRI using Noisy Student-based Training
Nov 19, 2021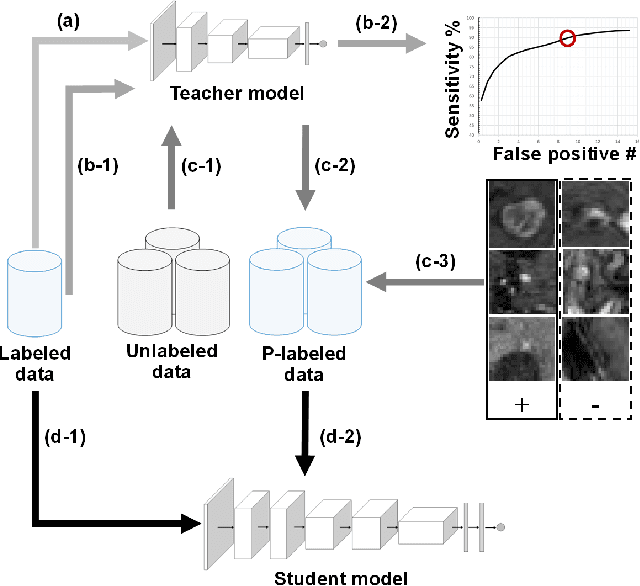
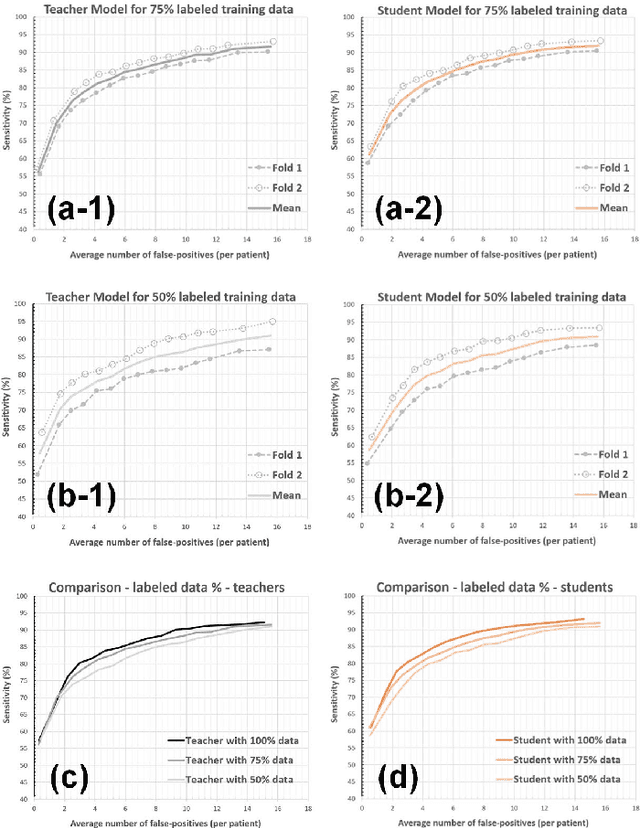
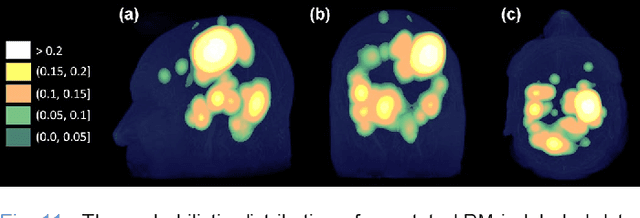
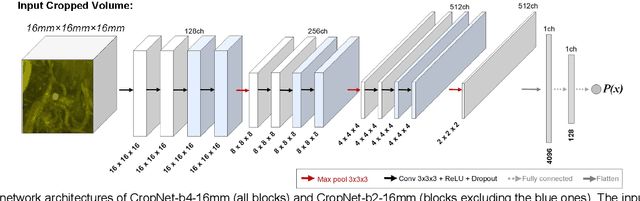
The detection of brain metastases (BM) in their early stages could have a positive impact on the outcome of cancer patients. We previously developed a framework for detecting small BM (with diameters of less than 15mm) in T1-weighted Contrast-Enhanced 3D Magnetic Resonance images (T1c) to assist medical experts in this time-sensitive and high-stakes task. The framework utilizes a dedicated convolutional neural network (CNN) trained using labeled T1c data, where the ground truth BM segmentations were provided by a radiologist. This study aims to advance the framework with a noisy student-based self-training strategy to make use of a large corpus of unlabeled T1c data (i.e., data without BM segmentations or detections). Accordingly, the work (1) describes the student and teacher CNN architectures, (2) presents data and model noising mechanisms, and (3) introduces a novel pseudo-labeling strategy factoring in the learned BM detection sensitivity of the framework. Finally, it describes a semi-supervised learning strategy utilizing these components. We performed the validation using 217 labeled and 1247 unlabeled T1c exams via 2-fold cross-validation. The framework utilizing only the labeled exams produced 9.23 false positives for 90% BM detection sensitivity; whereas, the framework using the introduced learning strategy led to ~9% reduction in false detections (i.e., 8.44) for the same sensitivity level. Furthermore, while experiments utilizing 75% and 50% of the labeled datasets resulted in algorithm performance degradation (12.19 and 13.89 false positives respectively), the impact was less pronounced with the noisy student-based training strategy (10.79 and 12.37 false positives respectively).
Average Outward Flux Skeletons for Environment Mapping and Topology Matching
Nov 27, 2021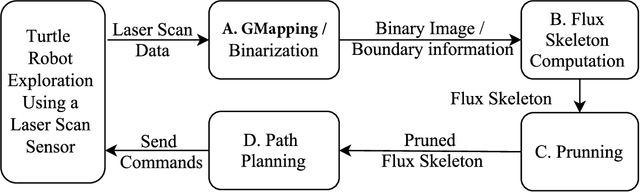
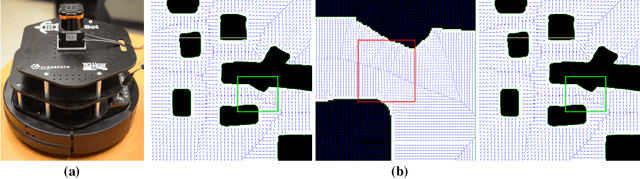
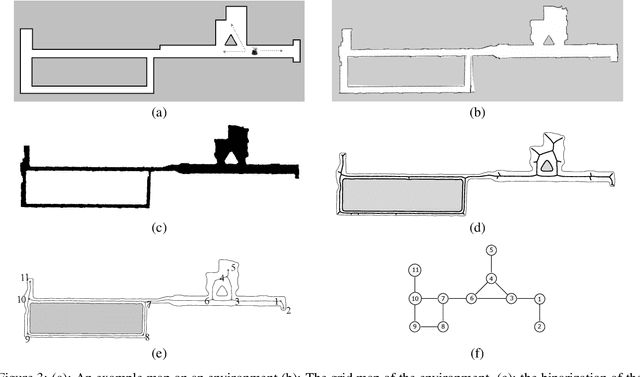
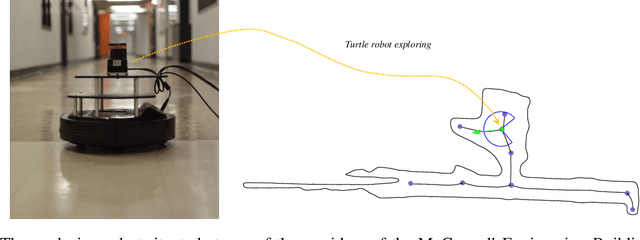
We consider how to directly extract a road map (also known as a topological representation) of an initially-unknown 2-dimensional environment via an online procedure that robustly computes a retraction of its boundaries. In this article, we first present the online construction of a topological map and the implementation of a control law for guiding the robot to the nearest unexplored area, first presented in [1]. The proposed method operates by allowing the robot to localize itself on a partially constructed map, calculate a path to unexplored parts of the environment (frontiers), compute a robust terminating condition when the robot has fully explored the environment, and achieve loop closure detection. The proposed algorithm results in smooth safe paths for the robot's navigation needs. The presented approach is any time algorithm that has the advantage that it allows for the active creation of topological maps from laser scan data, as it is being acquired. We also propose a navigation strategy based on a heuristic where the robot is directed towards nodes in the topological map that open to empty space. We then extend the work in [1] by presenting a topology matching algorithm that leverages the strengths of a particular spectral correspondence method [2], to match the mapped environments generated from our topology-making algorithm. Here, we concentrated on implementing a system that could be used to match the topologies of the mapped environment by using AOF Skeletons. In topology matching between two given maps and their AOF skeletons, we first find correspondences between points on the AOF skeletons of two different environments. We then align the (2D) points of the environments themselves. We also compute a distance measure between two given environments, based on their extracted AOF skeletons and their topology, as the sum of the matching errors between corresponding points.
The Possibilistic Horn Non-Clausal Knowledge Bases
Nov 15, 2021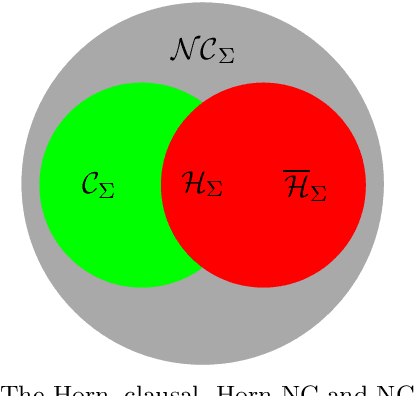
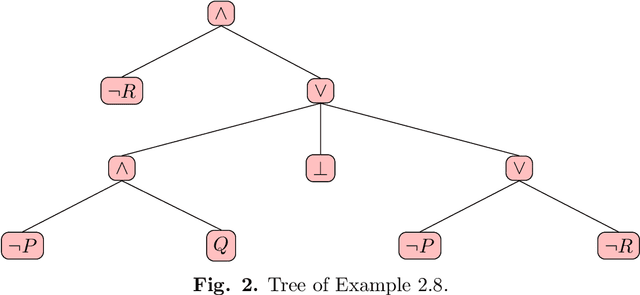
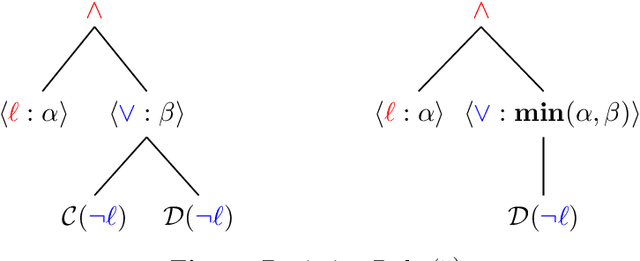
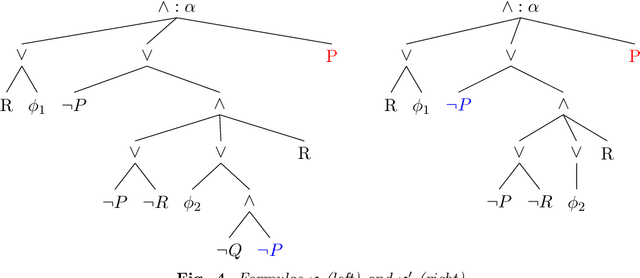
Posibilistic logic is the most extended approach to handle uncertain and partially inconsistent information. Regarding normal forms, advances in possibilistic reasoning are mostly focused on clausal form. Yet, the encoding of real-world problems usually results in a non-clausal (NC) formula and NC-to-clausal translators produce severe drawbacks that heavily limit the practical performance of clausal reasoning. Thus, by computing formulas in its original NC form, we propose several contributions showing that notable advances are also possible in possibilistic non-clausal reasoning. {\em Firstly,} we define the class of {\em Possibilistic Horn Non-Clausal Knowledge Bases,} or $\mathcal{\overline{H}}_\Sigma$, which subsumes the classes: possibilistic Horn and propositional Horn-NC. $\mathcal{\overline{H}}_\Sigma $ is shown to be a kind of NC analogous of the standard Horn class. {\em Secondly}, we define {\em Possibilistic Non-Clausal Unit-Resolution,} or $ \mathcal{UR}_\Sigma $, and prove that $ \mathcal{UR}_\Sigma $ correctly computes the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $members. $\mathcal{UR}_\Sigma $ had not been proposed before and is formulated in a clausal-like manner, which eases its understanding, formal proofs and future extension towards non-clausal resolution. {\em Thirdly}, we prove that computing the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $ members takes polynomial time. Although there already exist tractable classes in possibilistic logic, all of them are clausal, and thus, $\mathcal{\overline{H}}_\Sigma $ turns out to be the first characterized polynomial non-clausal class within possibilistic reasoning.
Attention-based Neural Load Forecasting: A Dynamic Feature Selection Approach
Aug 25, 2021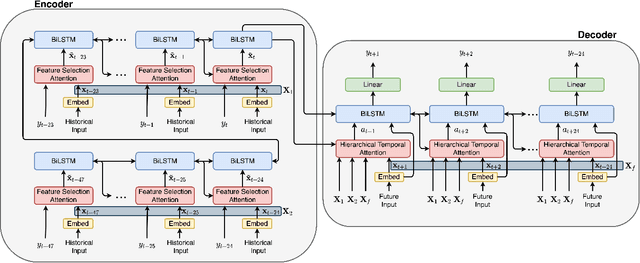
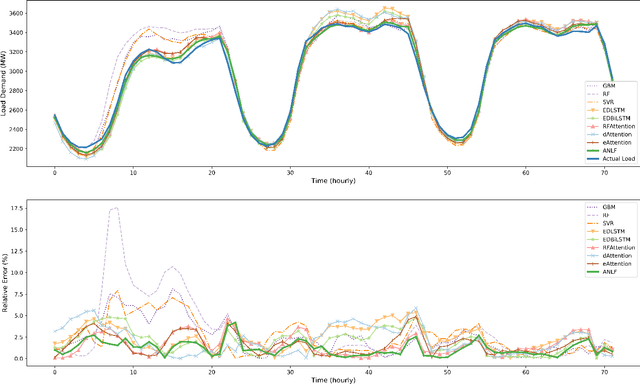
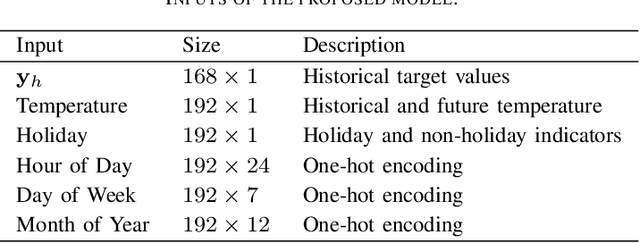
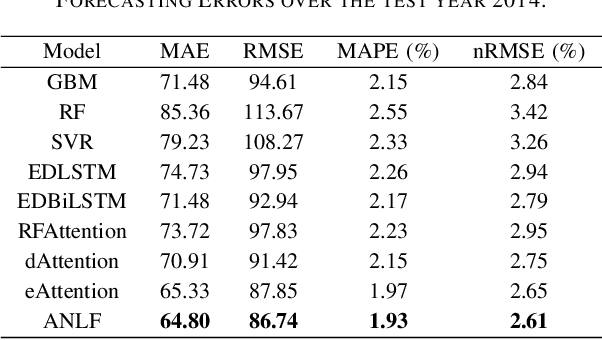
Encoder-decoder-based recurrent neural network (RNN) has made significant progress in sequence-to-sequence learning tasks such as machine translation and conversational models. Recent works have shown the advantage of this type of network in dealing with various time series forecasting tasks. The present paper focuses on the problem of multi-horizon short-term load forecasting, which plays a key role in the power system's planning and operation. Leveraging the encoder-decoder RNN, we develop an attention model to select the relevant features and similar temporal information adaptively. First, input features are assigned with different weights by a feature selection attention layer, while the updated historical features are encoded by a bi-directional long short-term memory (BiLSTM) layer. Then, a decoder with hierarchical temporal attention enables a similar day selection, which re-evaluates the importance of historical information at each time step. Numerical results tested on the dataset of the global energy forecasting competition 2014 show that our proposed model significantly outperforms some existing forecasting schemes.
TESDA: Transform Enabled Statistical Detection of Attacks in Deep Neural Networks
Oct 16, 2021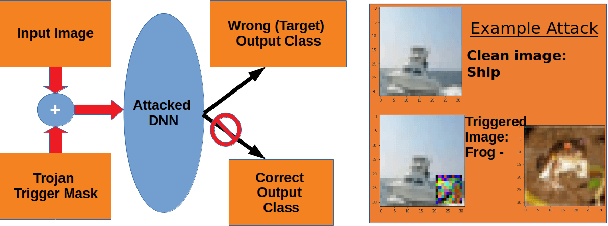
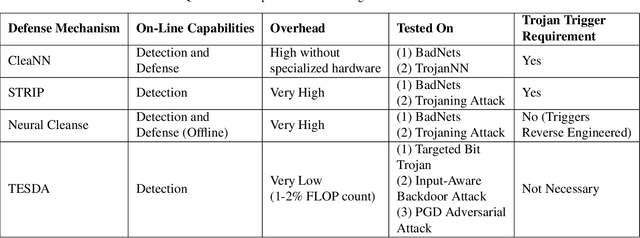
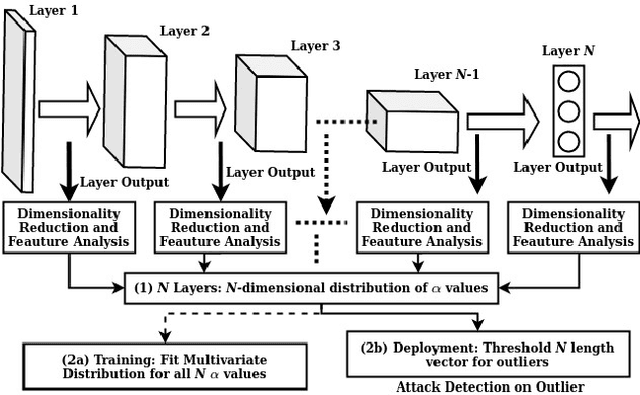
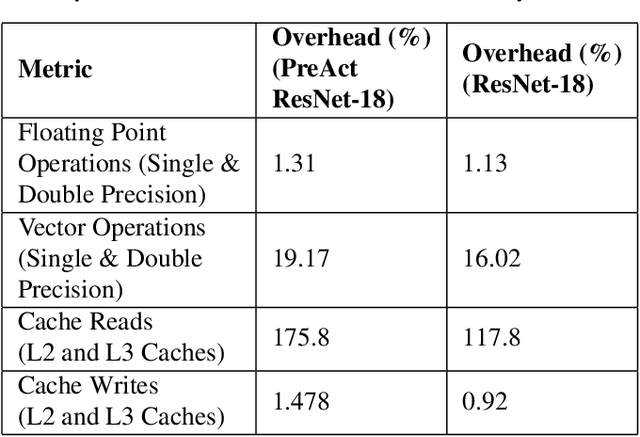
Deep neural networks (DNNs) are now the de facto choice for computer vision tasks such as image classification. However, their complexity and "black box" nature often renders the systems they're deployed in vulnerable to a range of security threats. Successfully identifying such threats, especially in safety-critical real-world applications is thus of utmost importance, but still very much an open problem. We present TESDA, a low-overhead, flexible, and statistically grounded method for {online detection} of attacks by exploiting the discrepancies they cause in the distributions of intermediate layer features of DNNs. Unlike most prior work, we require neither dedicated hardware to run in real-time, nor the presence of a Trojan trigger to detect discrepancies in behavior. We empirically establish our method's usefulness and practicality across multiple architectures, datasets and diverse attacks, consistently achieving detection coverages of above 95% with operation count overheads as low as 1-2%.
Using Clinical Notes with Time Series Data for ICU Management
Sep 12, 2019
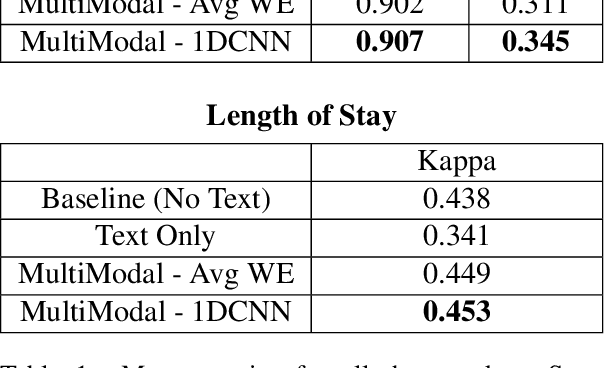
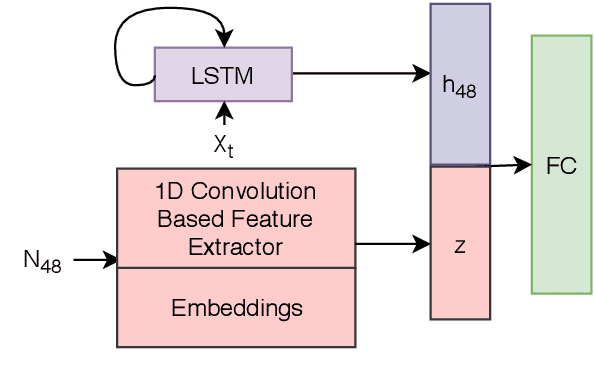
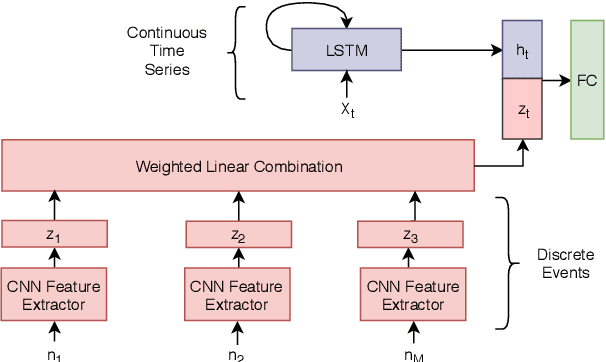
Monitoring patients in ICU is a challenging and high-cost task. Hence, predicting the condition of patients during their ICU stay can help provide better acute care and plan the hospital's resources. There has been continuous progress in machine learning research for ICU management, and most of this work has focused on using time series signals recorded by ICU instruments. In our work, we show that adding clinical notes as another modality improves the performance of the model for three benchmark tasks: in-hospital mortality prediction, modeling decompensation, and length of stay forecasting that play an important role in ICU management. While the time-series data is measured at regular intervals, doctor notes are charted at irregular times, making it challenging to model them together. We propose a method to model them jointly, achieving considerable improvement across benchmark tasks over baseline time-series model. Our implementation can be found at \url{https://github.com/kaggarwal/ClinicalNotesICU}.
Generalized Multi-Task Learning from Substantially Unlabeled Multi-Source Medical Image Data
Oct 25, 2021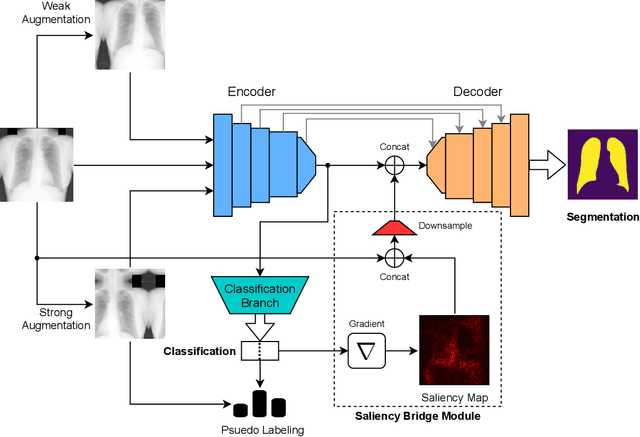
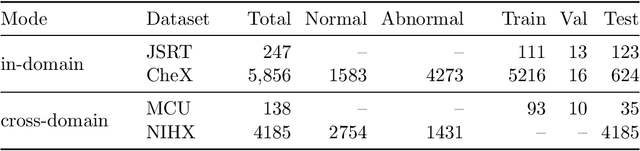
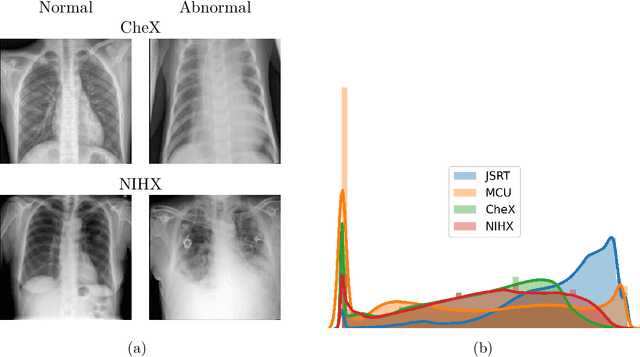
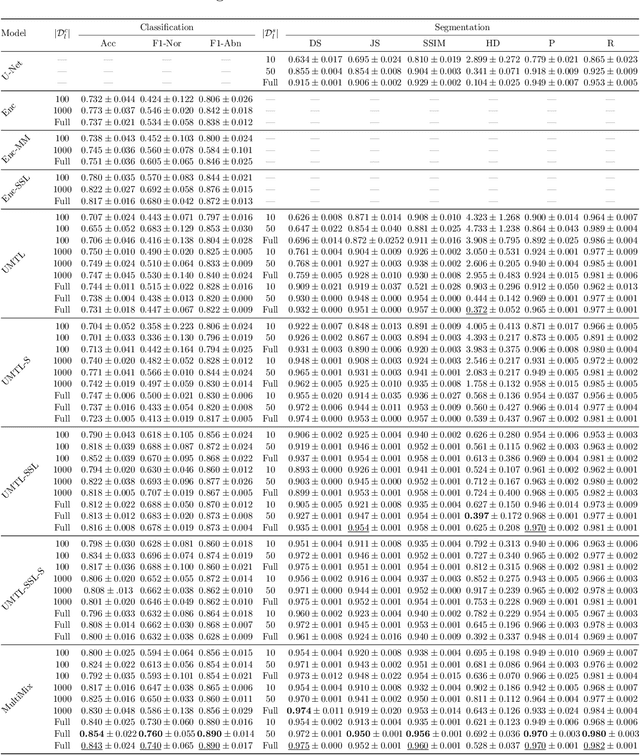
Deep learning-based models, when trained in a fully-supervised manner, can be effective in performing complex image analysis tasks, although contingent upon the availability of large labeled datasets. Especially in the medical imaging domain, however, expert image annotation is expensive, time-consuming, and prone to variability. Semi-supervised learning from limited quantities of labeled data has shown promise as an alternative. Maximizing knowledge gains from copious unlabeled data benefits semi-supervised learning models. Moreover, learning multiple tasks within the same model further improves its generalizability. We propose MultiMix, a new multi-task learning model that jointly learns disease classification and anatomical segmentation in a semi-supervised manner, while preserving explainability through a novel saliency bridge between the two tasks. Our experiments with varying quantities of multi-source labeled data in the training sets confirm the effectiveness of MultiMix in the simultaneous classification of pneumonia and segmentation of the lungs in chest X-ray images. Moreover, both in-domain and cross-domain evaluations across these tasks further showcase the potential of our model to adapt to challenging generalization scenarios.