 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021
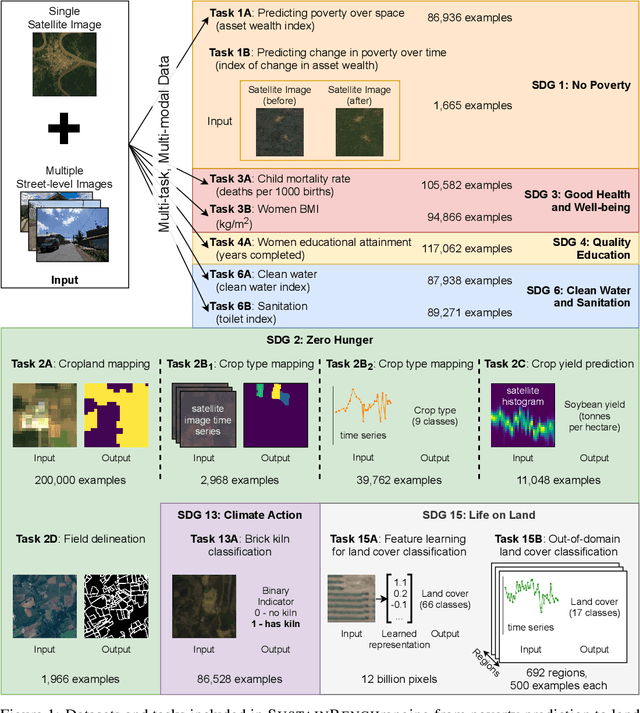
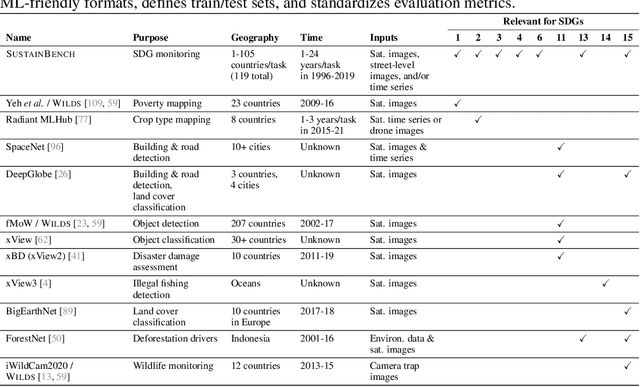
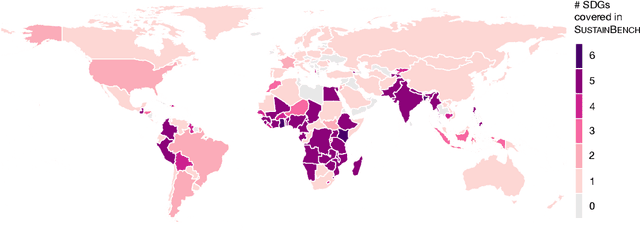
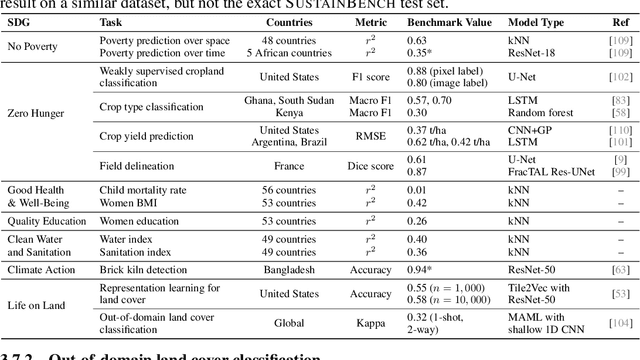
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
Online Trajectory Optimization for Dynamic Aerial Motions of a Quadruped Robot
Oct 12, 2021



This work presents a two part framework for online planning and execution of dynamic aerial motions on a quadruped robot. Motions are planned via a centroidal momentum-based nonlinear optimization that is general enough to produce rich sets of novel dynamic motions based solely on the user-specified contact schedule and desired launch velocity of the robot. Since this nonlinear optimization is not tractable for real-time receding horizon control, motions are planned once via nonlinear optimization in preparation of an aerial motion and then tracked continuously using a variational-based optimal controller that offers robustness to the uncertainties that exist in the real hardware such as modeling error or disturbances. Motion planning typically takes between 0.05-0.15 seconds, while the optimal controller finds stabilizing feedback inputs at 500 Hz. Experimental results on the MIT Mini Cheetah demonstrate that the framework can reliably produce successful aerial motions such as jumps onto and off of platforms, spins, flips, barrel rolls, and running jumps over obstacles.
RST-MODNet: Real-time Spatio-temporal Moving Object Detection for Autonomous Driving
Dec 01, 2019



Moving Object Detection (MOD) is a critical task for autonomous vehicles as moving objects represent higher collision risk than static ones. The trajectory of the ego-vehicle is planned based on the future states of detected moving objects. It is quite challenging as the ego-motion has to be modelled and compensated to be able to understand the motion of the surrounding objects. In this work, we propose a real-time end-to-end CNN architecture for MOD utilizing spatio-temporal context to improve robustness. We construct a novel time-aware architecture exploiting temporal motion information embedded within sequential images in addition to explicit motion maps using optical flow images.We demonstrate the impact of our algorithm on KITTI dataset where we obtain an improvement of 8% relative to the baselines. We compare our algorithm with state-of-the-art methods and achieve competitive results on KITTI-Motion dataset in terms of accuracy at three times better run-time. The proposed algorithm runs at 23 fps on a standard desktop GPU targeting deployment on embedded platforms.
Generating Disentangled Arguments with Prompts: A Simple Event Extraction Framework that Works
Oct 09, 2021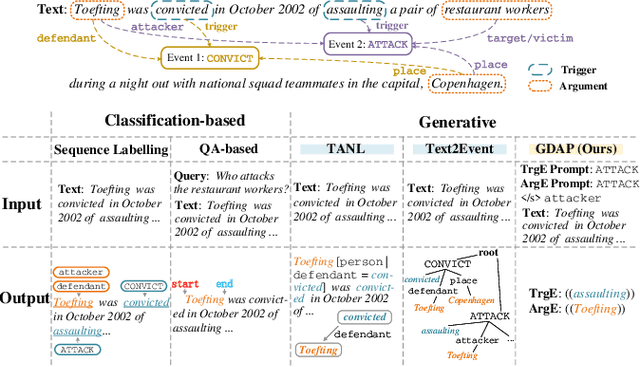
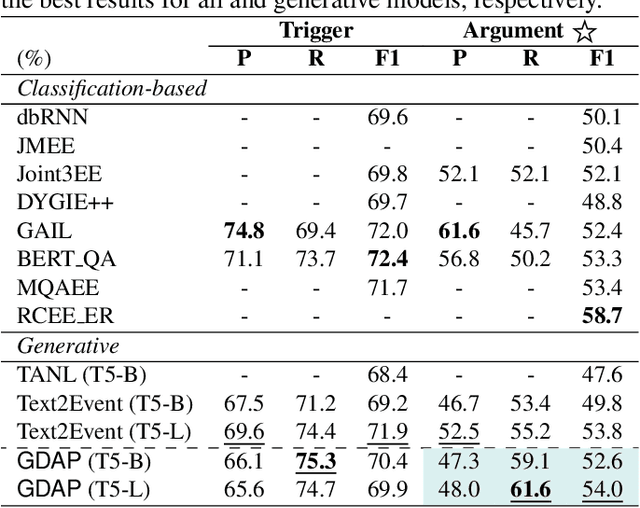
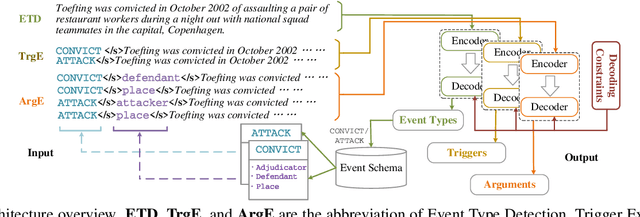
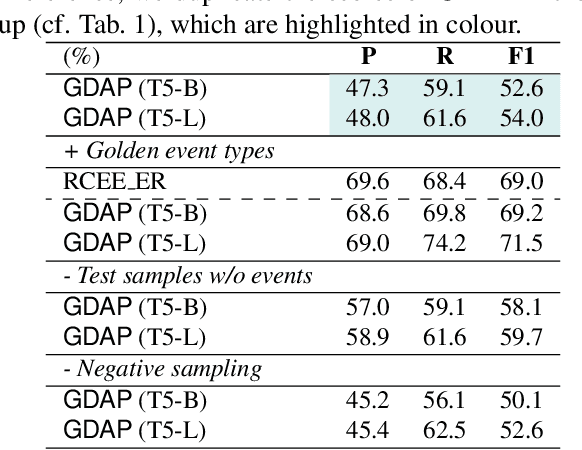
Event Extraction bridges the gap between text and event signals. Based on the assumption of trigger-argument dependency, existing approaches have achieved state-of-the-art performance with expert-designed templates or complicated decoding constraints. In this paper, for the first time we introduce the prompt-based learning strategy to the domain of Event Extraction, which empowers the automatic exploitation of label semantics on both input and output sides. To validate the effectiveness of the proposed generative method, we conduct extensive experiments with 11 diverse baselines. Empirical results show that, in terms of F1 score on Argument Extraction, our simple architecture is stronger than any other generative counterpart and even competitive with algorithms that require template engineering. Regarding the measure of recall, it sets new overall records for both Argument and Trigger Extractions. We hereby recommend this framework to the community, with the code publicly available at https://git.io/GDAP.
Unsupervised Scalable Representation Learning for Multivariate Time Series
Jan 30, 2019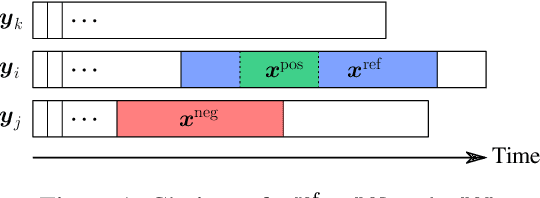
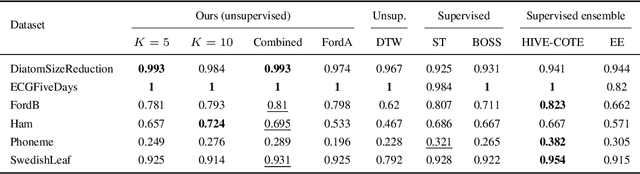
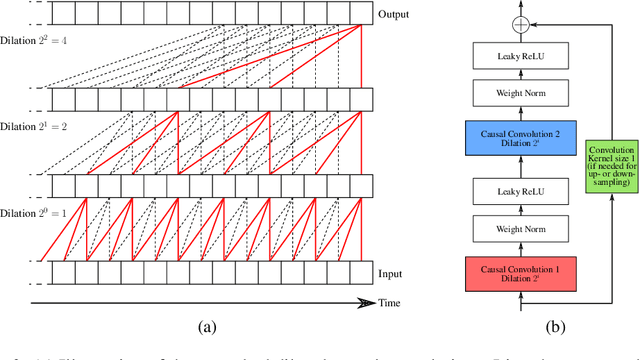
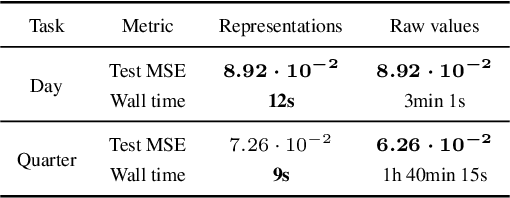
Time series constitute a challenging data type for machine learning algorithms, due to their highly variable lengths and sparse labeling in practice. In this paper, we tackle this challenge by proposing an unsupervised method to learn universal embeddings of time series. Unlike previous works, it is scalable with respect to their length and we demonstrate the quality, transferability and practicability of the learned representations with thorough experiments and comparisons. To this end, we combine an encoder based on causal dilated convolutions with a triplet loss employing time-based negative sampling, obtaining general-purpose representations for variable length and multivariate time series.
MAF-GNN: Multi-adaptive Spatiotemporal-flow Graph Neural Network for Traffic Speed Forecasting
Aug 08, 2021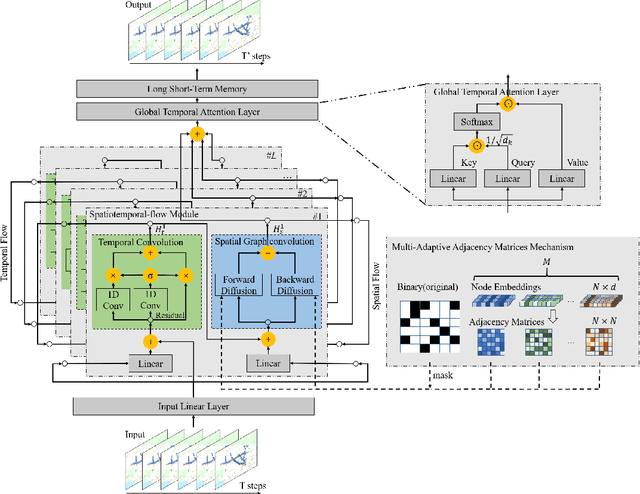
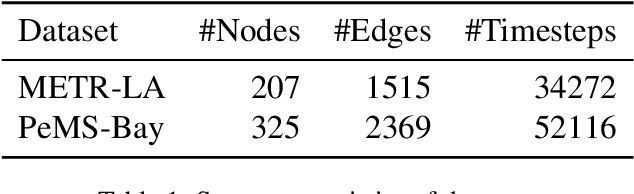
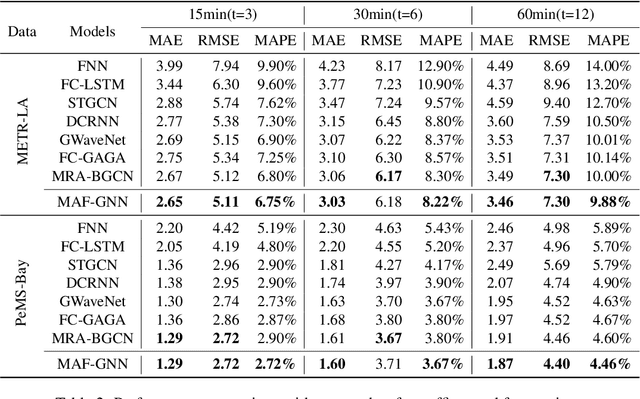
Traffic forecasting is a core element of intelligent traffic monitoring system. Approaches based on graph neural networks have been widely used in this task to effectively capture spatial and temporal dependencies of road networks. However, these approaches can not effectively define the complicated network topology. Besides, their cascade network structures have limitations in transmitting distinct features in the time and space dimensions. In this paper, we propose a Multi-adaptive Spatiotemporal-flow Graph Neural Network (MAF-GNN) for traffic speed forecasting. MAF-GNN introduces an effective Multi-adaptive Adjacency Matrices Mechanism to capture multiple latent spatial dependencies between traffic nodes. Additionally, we propose Spatiotemporal-flow Modules aiming to further enhance feature propagation in both time and space dimensions. MAF-GNN achieves better performance than other models on two real-world datasets of public traffic network, METR-LA and PeMS-Bay, demonstrating the effectiveness of the proposed approach.
Model-free online motion adaptation for energy efficient flights of multicopters
Aug 09, 2021



Limited flight distance and time is a common problem for multicopters. We propose a method for finding the optimal speed and heading of multicopters while flying a given path to achieve the longest flight distance or time. Since flight speed and heading are often free variables in multicopter path planning, they can be changed without changing the mission. The proposed method is based on a novel multivariable extremum seeking controller with adaptive step size. It (a) does not require any power consumption model of the vehicle, (b) can be executed online, (c) is computationally efficient and runs on low-cost embedded computers in real-time, and (d) converges faster than the standard extremum seeking controller with constant step size. We prove the stability of this proposed extremum seeking controller, and conduct outdoor experiments to validate the effectiveness of this method with different initial conditions, with and without payload. This method could be especially useful for applications such as package delivery, where the weight, size and shape of the payload vary between deliveries and the power consumption of the vehicle is hard to model. Experiments show that compared to flying at the maximum speed with a bad heading angle, flying at the optimal range speed and heading reduces the energy consumed per distance by 24.9% without payload and 33.5% with a box payload. In addition, compared to hovering, flying at the optimal endurance speed and heading reduces the the power consumption by 7.0% without payload and 12.6% with a box payload.
GraPE: fast and scalable Graph Processing and Embedding
Oct 12, 2021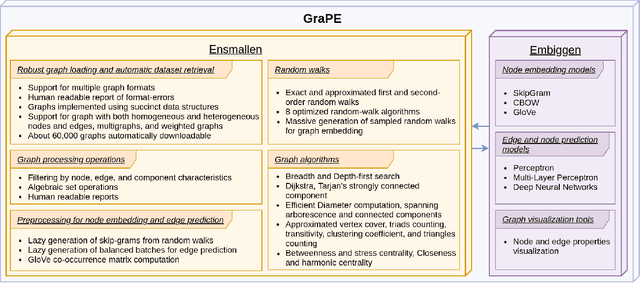
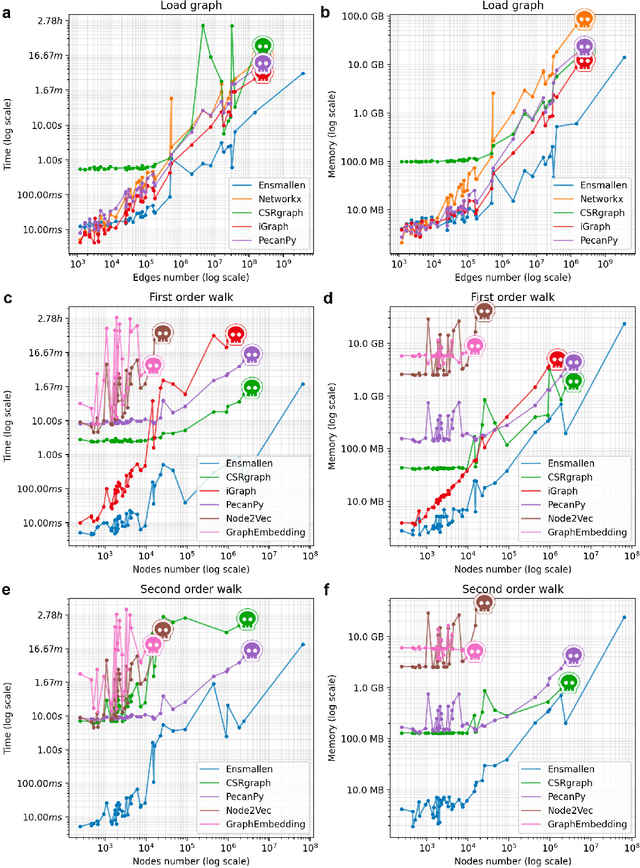
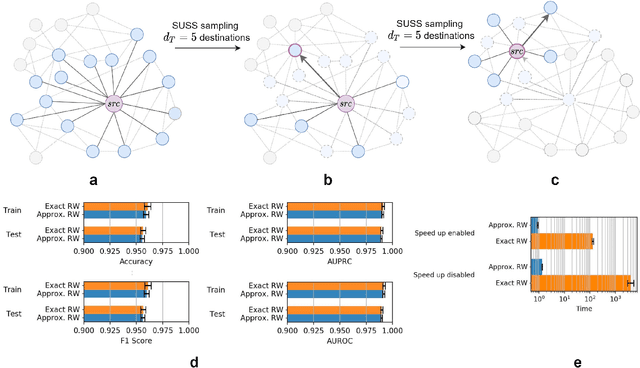
Graph Representation Learning methods have enabled a wide range of learning problems to be addressed for data that can be represented in graph form. Nevertheless, several real world problems in economy, biology, medicine and other fields raised relevant scaling problems with existing methods and their software implementation, due to the size of real world graphs characterized by millions of nodes and billions of edges. We present GraPE, a software resource for graph processing and random walk based embedding, that can scale with large and high-degree graphs and significantly speed up-computation. GraPE comprises specialized data structures, algorithms, and a fast parallel implementation that displays everal orders of magnitude improvement in empirical space and time complexity compared to state of the art software resources, with a corresponding boost in the performance of machine learning methods for edge and node label prediction and for the unsupervised analysis of graphs.GraPE is designed to run on laptop and desktop computers, as well as on high performance computing clusters
ADVERSARIALuscator: An Adversarial-DRL Based Obfuscator and Metamorphic Malware SwarmGenerator
Sep 23, 2021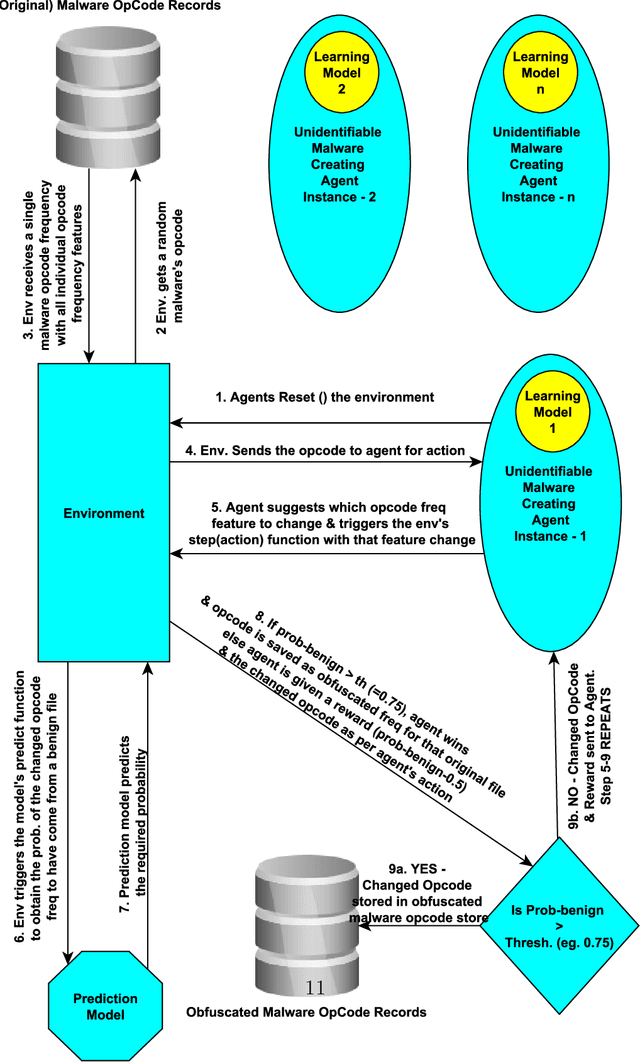

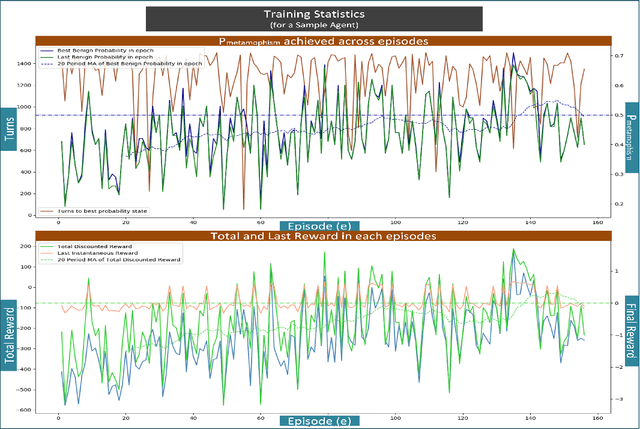
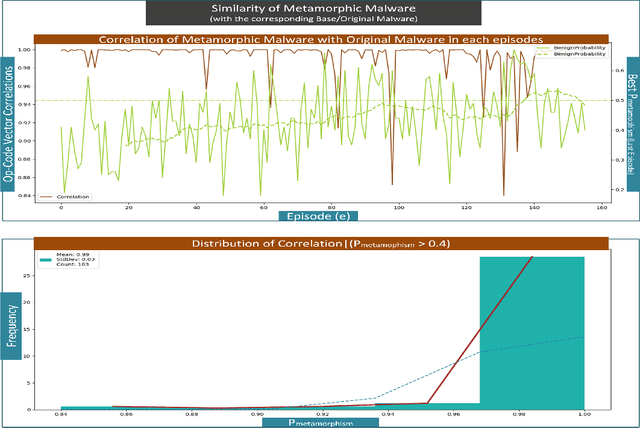
Advanced metamorphic malware and ransomware, by using obfuscation, could alter their internal structure with every attack. If such malware could intrude even into any of the IoT networks, then even if the original malware instance gets detected, by that time it can still infect the entire network. It is challenging to obtain training data for such evasive malware. Therefore, in this paper, we present ADVERSARIALuscator, a novel system that uses specialized Adversarial-DRL to obfuscate malware at the opcode level and create multiple metamorphic instances of the same. To the best of our knowledge, ADVERSARIALuscator is the first-ever system that adopts the Markov Decision Process-based approach to convert and find a solution to the problem of creating individual obfuscations at the opcode level. This is important as the machine language level is the least at which functionality could be preserved so as to mimic an actual attack effectively. ADVERSARIALuscator is also the first-ever system to use efficient continuous action control capable of deep reinforcement learning agents like the Proximal Policy Optimization in the area of cyber security. Experimental results indicate that ADVERSARIALuscator could raise the metamorphic probability of a corpus of malware by >0.45. Additionally, more than 33% of metamorphic instances generated by ADVERSARIALuscator were able to evade the most potent IDS. If such malware could intrude even into any of the IoT networks, then even if the original malware instance gets detected, by that time it can still infect the entire network. Hence ADVERSARIALuscator could be used to generate data representative of a swarm of very potent and coordinated AI-based metamorphic malware attacks. The so generated data and simulations could be used to bolster the defenses of an IDS against an actual AI-based metamorphic attack from advanced malware and ransomware.
Learning suction graspability considering grasp quality and robot reachability for bin-picking
Nov 04, 2021
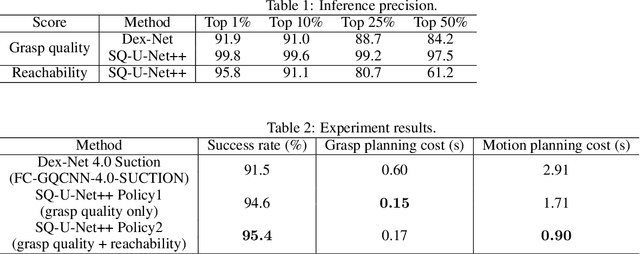
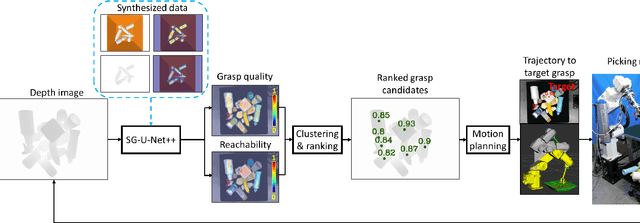
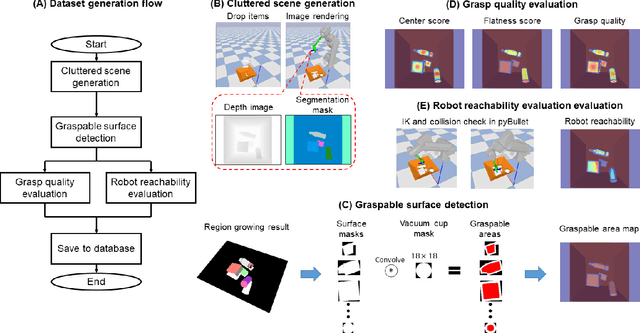
Deep learning has been widely used for inferring robust grasps. Although human-labeled RGB-D datasets were initially used to learn grasp configurations, preparation of this kind of large dataset is expensive. To address this problem, images were generated by a physical simulator, and a physically inspired model (e.g., a contact model between a suction vacuum cup and object) was used as a grasp quality evaluation metric to annotate the synthesized images. However, this kind of contact model is complicated and requires parameter identification by experiments to ensure real world performance. In addition, previous studies have not considered manipulator reachability such as when a grasp configuration with high grasp quality is unable to reach the target due to collisions or the physical limitations of the robot. In this study, we propose an intuitive geometric analytic-based grasp quality evaluation metric. We further incorporate a reachability evaluation metric. We annotate the pixel-wise grasp quality and reachability by the proposed evaluation metric on synthesized images in a simulator to train an auto-encoder--decoder called suction graspability U-Net++ (SG-U-Net++). Experiment results show that our intuitive grasp quality evaluation metric is competitive with a physically-inspired metric. Learning the reachability helps to reduce motion planning computation time by removing obviously unreachable candidates. The system achieves an overall picking speed of 560 PPH (pieces per hour).