 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-Memory End-to-End Training for Iterative Joint Speech Dereverberation and Separation with A Neural Source Model
Oct 13, 2021
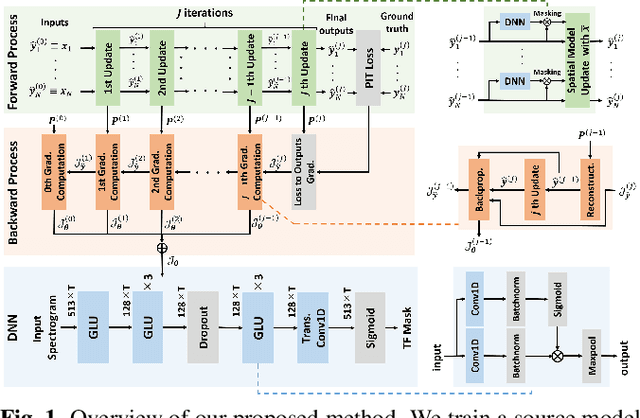

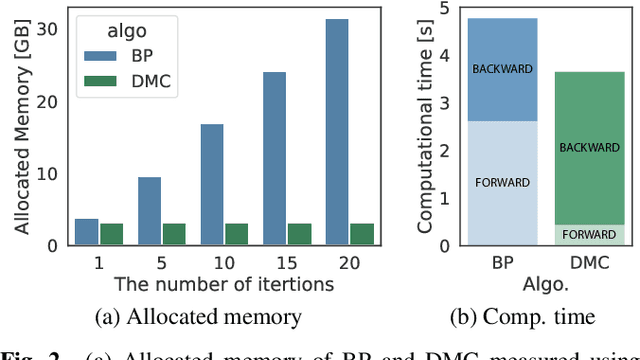
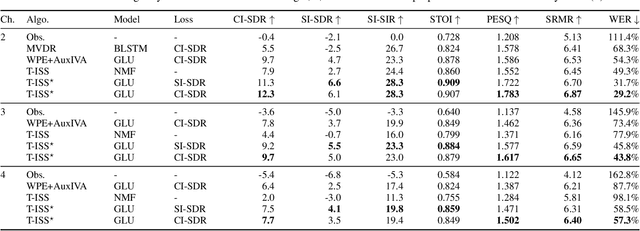
We propose an end-to-end framework for training iterative multi-channel joint dereverberation and source separation with a neural source model. We combine the unified dereverberation and separation update equations of ILRMA-T with a deep neural network (DNN) serving as source model. The weights of the model are directly trained by gradient descent with a permutation invariant loss on the output time-domain signals. One drawback of this approach is that backpropagation consumes memory linearly in the number of iterations. This severely limits the number of iterations, channels, or signal lengths that can be used during training. We introduce demixing matrix checkpointing to bypass this problem, a new technique that reduces the total memory cost to that of a single iteration. In experiments, we demonstrate that the introduced framework results in high-performance in terms of conventional speech quality metrics and word error rate. Furthermore, it generalizes to number of channels unseen during training.
Existence, uniqueness, and convergence rates for gradient flows in the training of artificial neural networks with ReLU activation
Aug 18, 2021The training of artificial neural networks (ANNs) with rectified linear unit (ReLU) activation via gradient descent (GD) type optimization schemes is nowadays a common industrially relevant procedure. Till this day in the scientific literature there is in general no mathematical convergence analysis which explains the numerical success of GD type optimization schemes in the training of ANNs with ReLU activation. GD type optimization schemes can be regarded as temporal discretization methods for the gradient flow (GF) differential equations associated to the considered optimization problem and, in view of this, it seems to be a natural direction of research to first aim to develop a mathematical convergence theory for time-continuous GF differential equations and, thereafter, to aim to extend such a time-continuous convergence theory to implementable time-discrete GD type optimization methods. In this article we establish two basic results for GF differential equations in the training of fully-connected feedforward ANNs with one hidden layer and ReLU activation. In the first main result of this article we establish in the training of such ANNs under the assumption that the probability distribution of the input data of the considered supervised learning problem is absolutely continuous with a bounded density function that every GF differential equation admits for every initial value a solution which is also unique among a suitable class of solutions. In the second main result of this article we prove in the training of such ANNs under the assumption that the target function and the density function of the probability distribution of the input data are piecewise polynomial that every non-divergent GF trajectory converges with an appropriate rate of convergence to a critical point and that the risk of the non-divergent GF trajectory converges with rate 1 to the risk of the critical point.
Neural networks based post-equalization in coherent optical systems: regression versus classification
Sep 28, 2021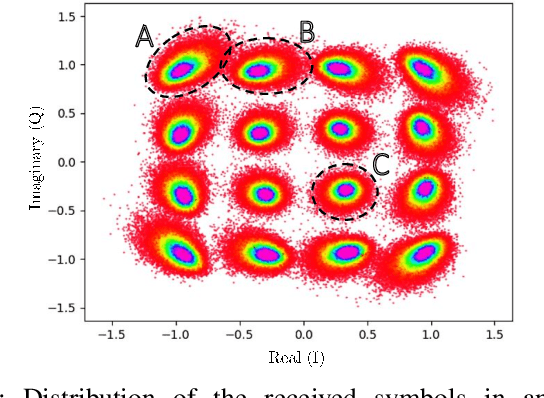
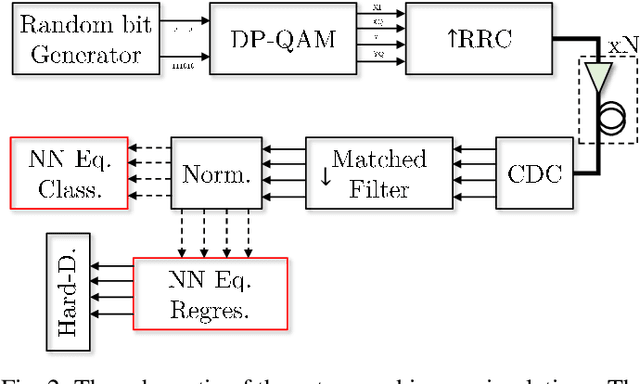
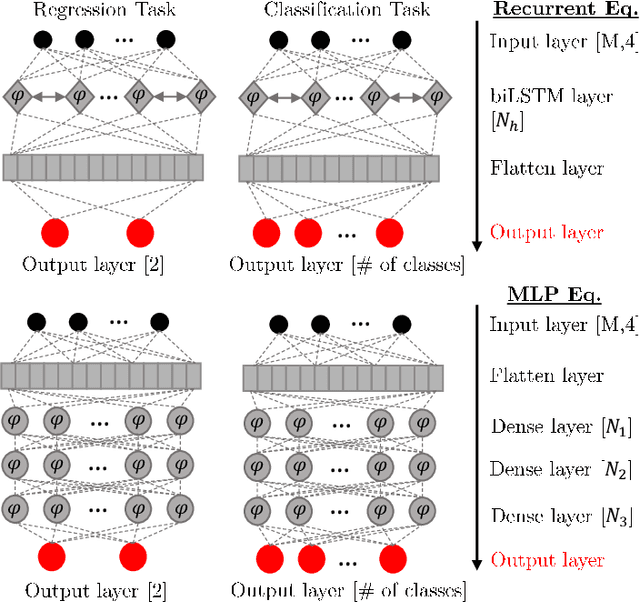
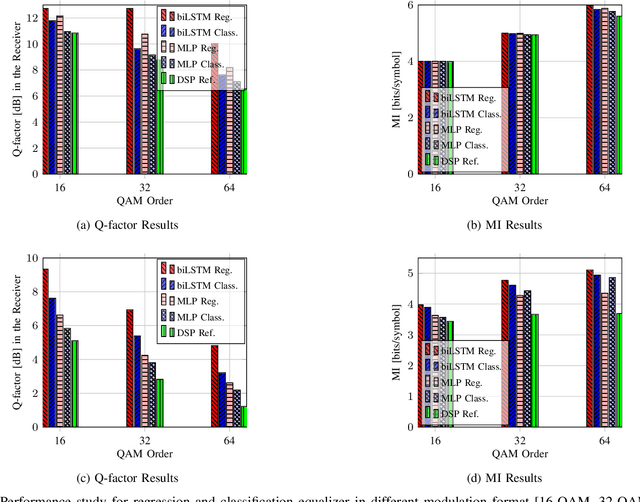
In this paper, we address the question of which type of predictive modeling, classification, or regression, fits better the task of equalization using neural networks (NN) based post-processing in coherent optical communication, where the transmission channel is nonlinear and dispersive. For the first time, we presented some possible drawbacks in using each type of predictive task in a machine learning context for the nonlinear channel equalization problem. We studied two types of equalizers based on the feed-forward and recurrent neural networks over several different transmission scenarios, in linear and nonlinear regimes of the optical channel. We observed in all those cases that the training based on regression results in faster convergence and finally a superior performance, in terms of Q-factor and achievable information rate.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Oct 13, 2021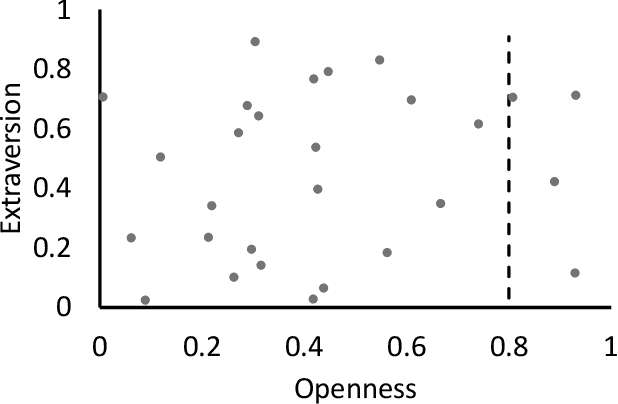
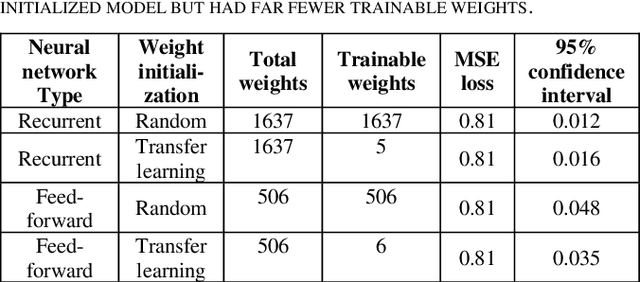
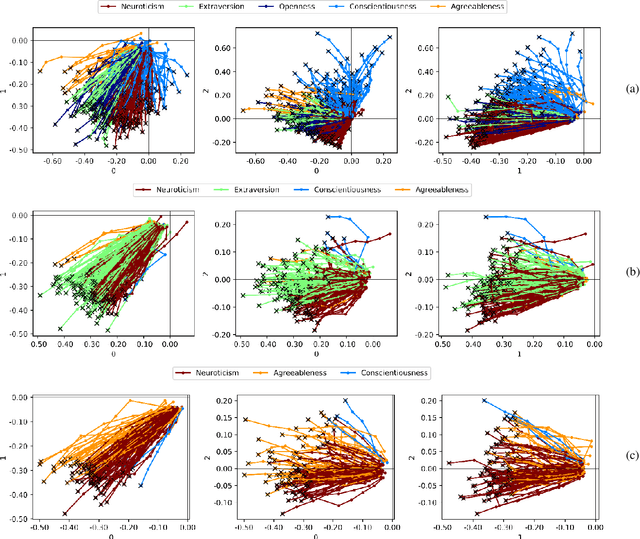
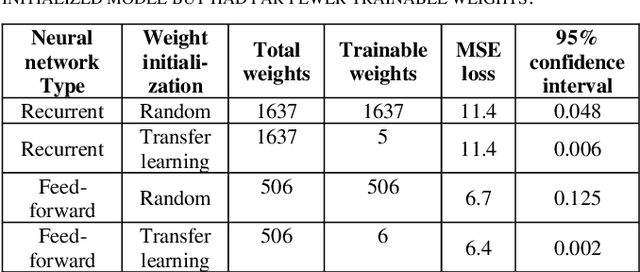
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In a novel approach, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only coarse segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
Geometry-informed irreversible perturbations for accelerated convergence of Langevin dynamics
Aug 18, 2021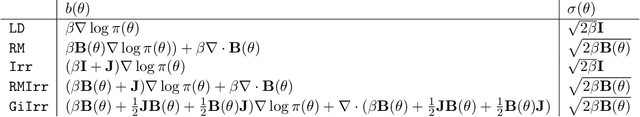
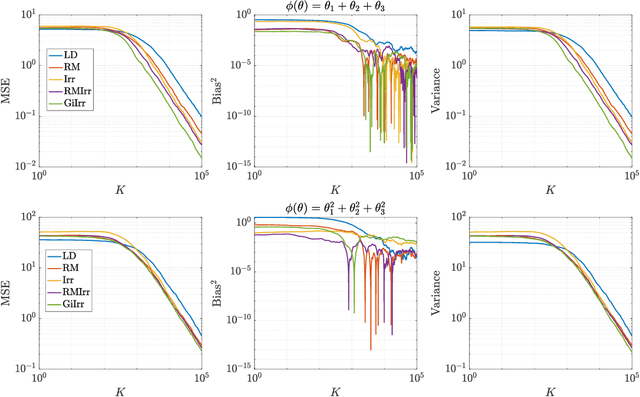
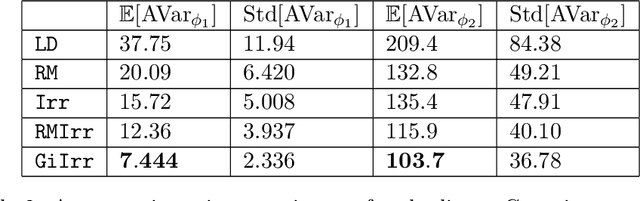
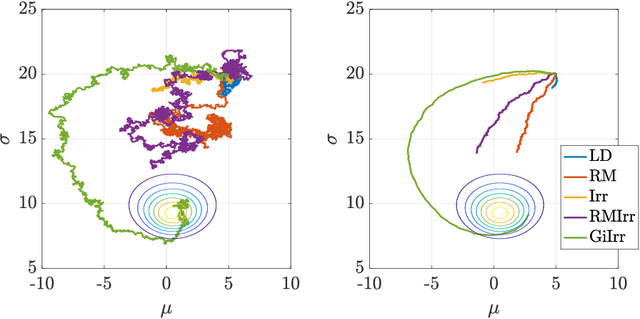
We introduce a novel geometry-informed irreversible perturbation that accelerates convergence of the Langevin algorithm for Bayesian computation. It is well documented that there exist perturbations to the Langevin dynamics that preserve its invariant measure while accelerating its convergence. Irreversible perturbations and reversible perturbations (such as Riemannian manifold Langevin dynamics (RMLD)) have separately been shown to improve the performance of Langevin samplers. We consider these two perturbations simultaneously by presenting a novel form of irreversible perturbation for RMLD that is informed by the underlying geometry. Through numerical examples, we show that this new irreversible perturbation can improve performance of the estimator over reversible perturbations that do not take the geometry into account. Moreover we demonstrate that irreversible perturbations generally can be implemented in conjunction with the stochastic gradient version of the Langevin algorithm. Lastly, while continuous-time irreversible perturbations cannot impair the performance of a Langevin estimator, the situation can sometimes be more complicated when discretization is considered. To this end, we describe a discrete-time example in which irreversibility increases both the bias and variance of the resulting estimator.
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers
Oct 09, 2021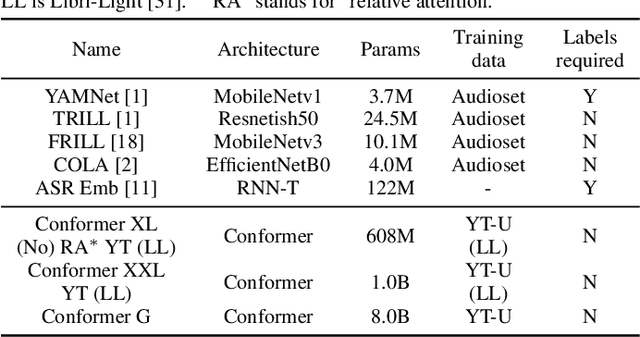
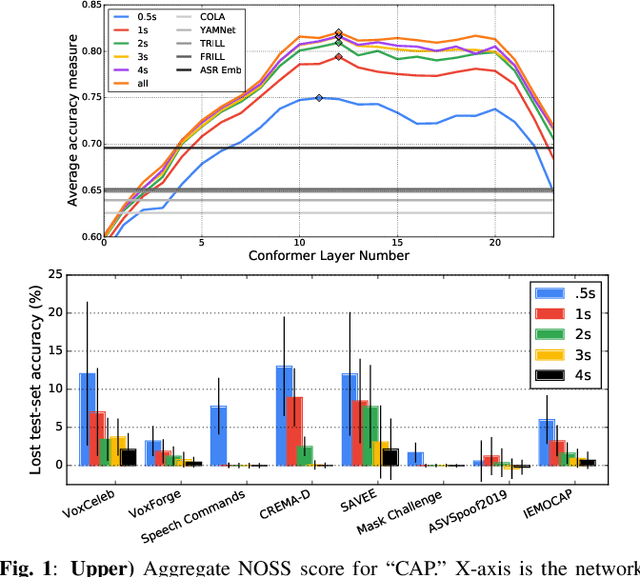
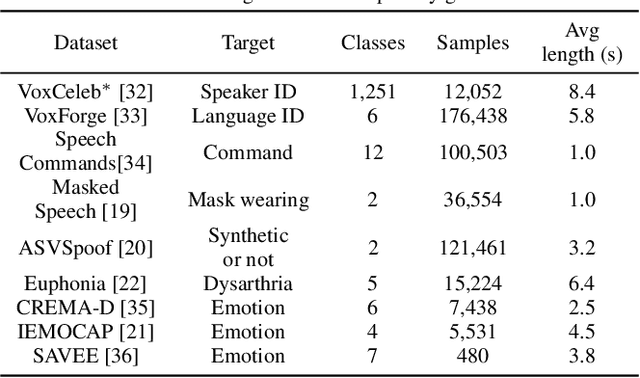
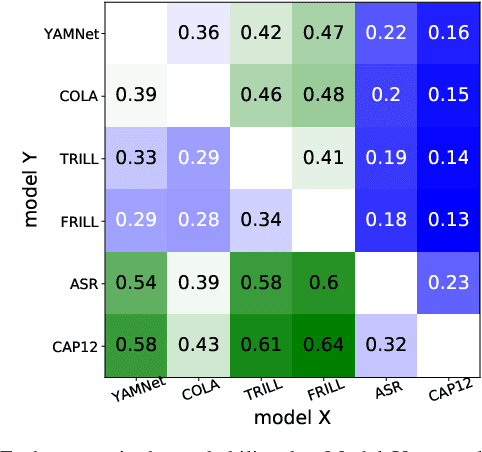
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 98% the performance of the Conformers that use the full long-term context. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
Sep 30, 2020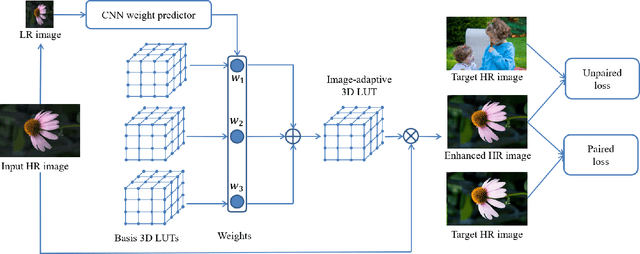

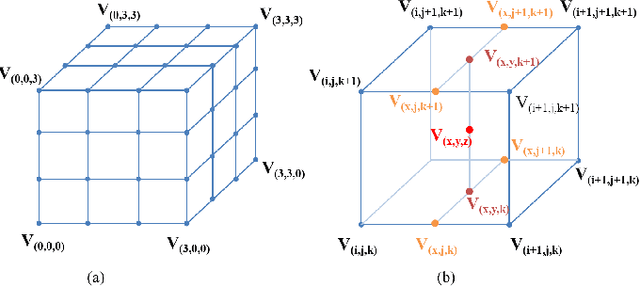
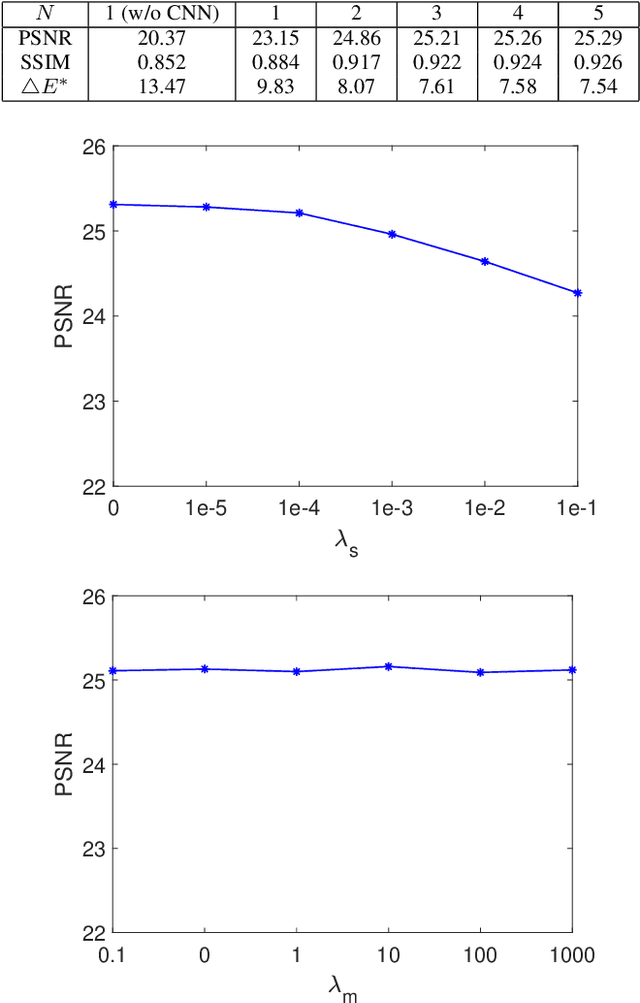
Recent years have witnessed the increasing popularity of learning based methods to enhance the color and tone of photos. However, many existing photo enhancement methods either deliver unsatisfactory results or consume too much computational and memory resources, hindering their application to high-resolution images (usually with more than 12 megapixels) in practice. In this paper, we learn image-adaptive 3-dimensional lookup tables (3D LUTs) to achieve fast and robust photo enhancement. 3D LUTs are widely used for manipulating color and tone of photos, but they are usually manually tuned and fixed in camera imaging pipeline or photo editing tools. We, for the first time to our best knowledge, propose to learn 3D LUTs from annotated data using pairwise or unpaired learning. More importantly, our learned 3D LUT is image-adaptive for flexible photo enhancement. We learn multiple basis 3D LUTs and a small convolutional neural network (CNN) simultaneously in an end-to-end manner. The small CNN works on the down-sampled version of the input image to predict content-dependent weights to fuse the multiple basis 3D LUTs into an image-adaptive one, which is employed to transform the color and tone of source images efficiently. Our model contains less than 600K parameters and takes less than 2 ms to process an image of 4K resolution using one Titan RTX GPU. While being highly efficient, our model also outperforms the state-of-the-art photo enhancement methods by a large margin in terms of PSNR, SSIM and a color difference metric on two publically available benchmark datasets.
Passive Phased Array Acoustic Emission Localisation via Recursive Signal-Averaged Lamb Waves with an Applied Warped Frequency Transformation
Oct 13, 2021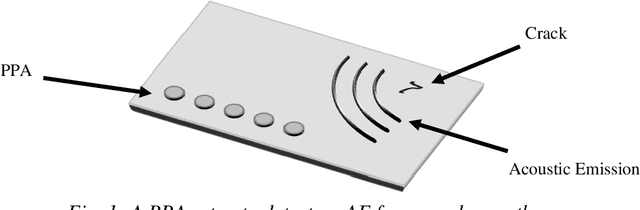

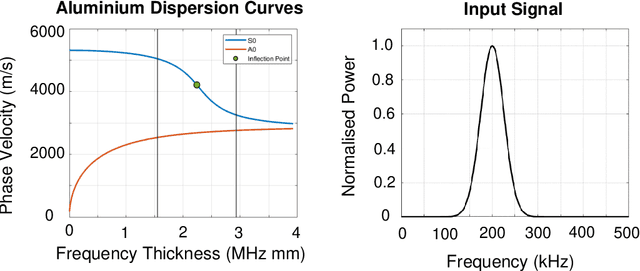

This work presents a concept for the localisation of Lamb waves using a Passive Phased Array (PPA). A Warped Frequency Transformation (WFT) is applied to the acquired signals using numerically determined phase velocity information to compensate for signal dispersion. Whilst powerful, uncertainty between material properties cannot completely remove dispersion and hence the close intra-element spacing of the array is leveraged to allow for the assumption that each acquired signal is a scaled, translated, and noised copy of its adjacent counterparts. Following this, a recursive signal-averaging method using artificial time-locking to denoise the acquired signals by assuming the presence of non-correlated, zero mean noise is applied. Unlike the application of bandpass filters, the signal-averaging method does not remove potentially useful frequency components. The proposed methodology is compared against a bandpass filtered approach through a parametric study. A further discussion is made regarding applications and future developments of this technique.
FedParking: A Federated Learning based Parking Space Estimation with Parked Vehicle assisted Edge Computing
Oct 19, 2021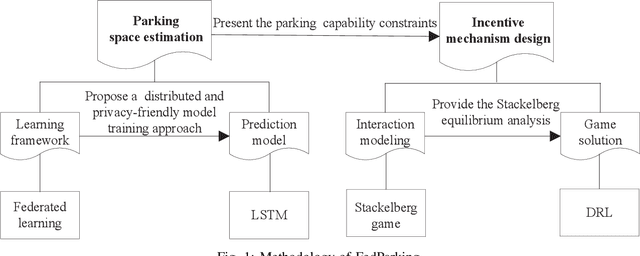
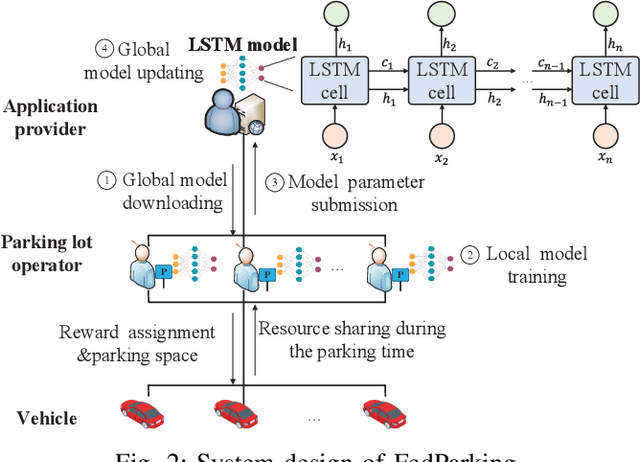
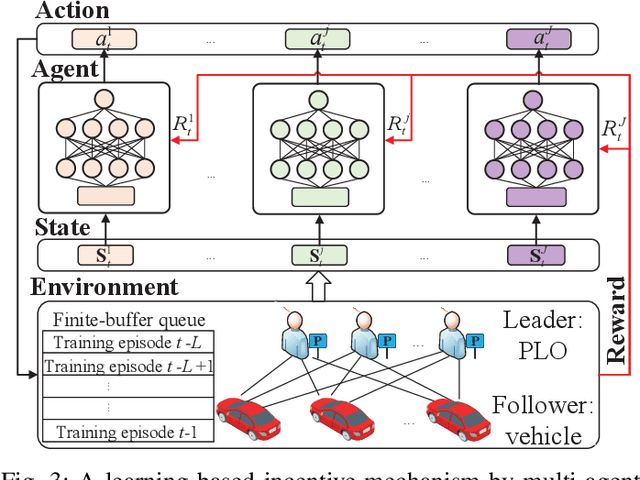
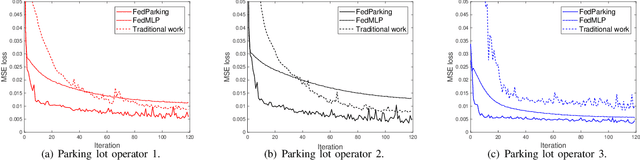
As a distributed learning approach, federated learning trains a shared learning model over distributed datasets while preserving the training data privacy. We extend the application of federated learning to parking management and introduce FedParking in which Parking Lot Operators (PLOs) collaborate to train a long short-term memory model for parking space estimation without exchanging the raw data. Furthermore, we investigate the management of Parked Vehicle assisted Edge Computing (PVEC) by FedParking. In PVEC, different PLOs recruit PVs as edge computing nodes for offloading services through an incentive mechanism, which is designed according to the computation demand and parking capacity constraints derived from FedParking. We formulate the interactions among the PLOs and vehicles as a multi-lead multi-follower Stackelberg game. Considering the dynamic arrivals of the vehicles and time-varying parking capacity constraints, we present a multi-agent deep reinforcement learning approach to gradually reach the Stackelberg equilibrium in a distributed yet privacy-preserving manner. Finally, numerical results are provided to demonstrate the effectiveness and efficiency of our scheme.
Differentiable NAS Framework and Application to Ads CTR Prediction
Oct 25, 2021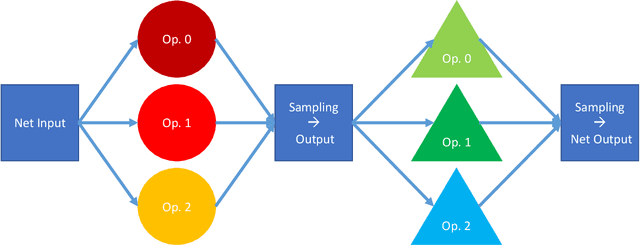
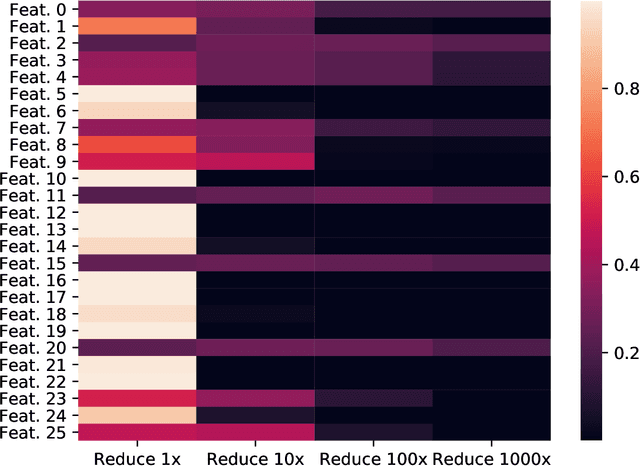
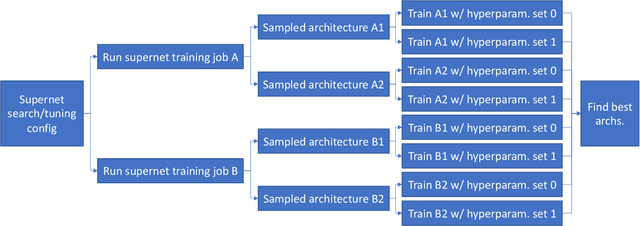
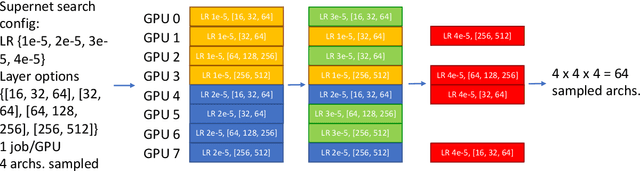
Neural architecture search (NAS) methods aim to automatically find the optimal deep neural network (DNN) architecture as measured by a given objective function, typically some combination of task accuracy and inference efficiency. For many areas, such as computer vision and natural language processing, this is a critical, yet still time consuming process. New NAS methods have recently made progress in improving the efficiency of this process. We implement an extensible and modular framework for Differentiable Neural Architecture Search (DNAS) to help solve this problem. We include an overview of the major components of our codebase and how they interact, as well as a section on implementing extensions to it (including a sample), in order to help users adopt our framework for their applications across different categories of deep learning models. To assess the capabilities of our methodology and implementation, we apply DNAS to the problem of ads click-through rate (CTR) prediction, arguably the highest-value and most worked on AI problem at hyperscalers today. We develop and tailor novel search spaces to a Deep Learning Recommendation Model (DLRM) backbone for CTR prediction, and report state-of-the-art results on the Criteo Kaggle CTR prediction dataset.