 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Time Varying Risk Preferences from Investment Portfolios using Inverse Optimization with Applications on Mutual Funds
Oct 22, 2020

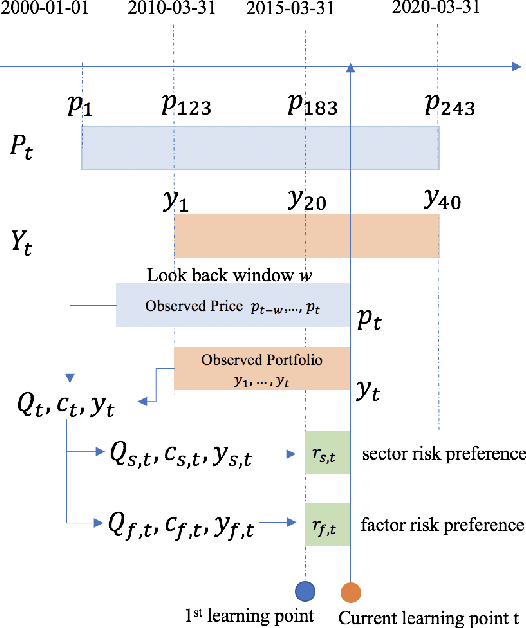

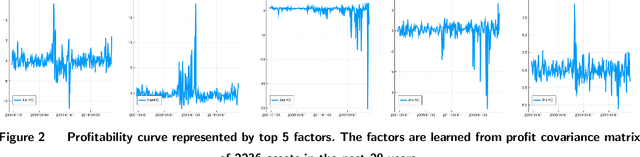
The fundamental principle in Modern Portfolio Theory (MPT) is based on the quantification of the portfolio's risk related to performance. Although MPT has made huge impacts on the investment world and prompted the success and prevalence of passive investing, it still has shortcomings in real-world applications. One of the main challenges is that the level of risk an investor can endure, known as \emph{risk-preference}, is a subjective choice that is tightly related to psychology and behavioral science in decision making. This paper presents a novel approach of measuring risk preference from existing portfolios using inverse optimization on the mean-variance portfolio allocation framework. Our approach allows the learner to continuously estimate real-time risk preferences using concurrent observed portfolios and market price data. We demonstrate our methods on real market data that consists of 20 years of asset pricing and 10 years of mutual fund portfolio holdings. Moreover, the quantified risk preference parameters are validated with two well-known risk measurements currently applied in the field. The proposed methods could lead to practical and fruitful innovations in automated/personalized portfolio management, such as Robo-advising, to augment financial advisors' decision intelligence in a long-term investment horizon.
Entropy-based adaptive Hamiltonian Monte Carlo
Oct 27, 2021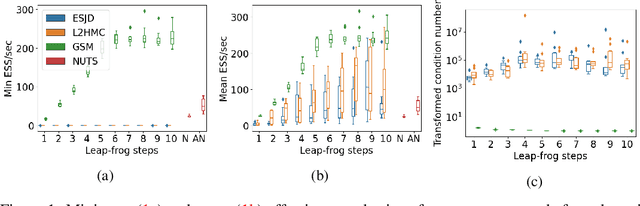

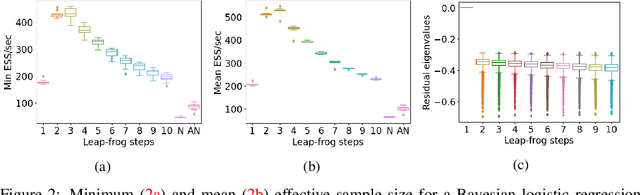
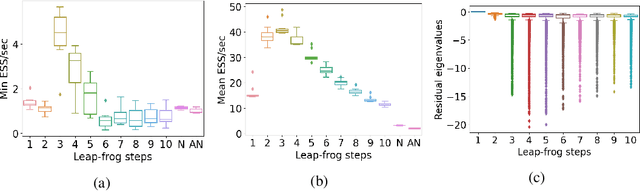
Hamiltonian Monte Carlo (HMC) is a popular Markov Chain Monte Carlo (MCMC) algorithm to sample from an unnormalized probability distribution. A leapfrog integrator is commonly used to implement HMC in practice, but its performance can be sensitive to the choice of mass matrix used therein. We develop a gradient-based algorithm that allows for the adaptation of the mass matrix by encouraging the leapfrog integrator to have high acceptance rates while also exploring all dimensions jointly. In contrast to previous work that adapt the hyperparameters of HMC using some form of expected squared jumping distance, the adaptation strategy suggested here aims to increase sampling efficiency by maximizing an approximation of the proposal entropy. We illustrate that using multiple gradients in the HMC proposal can be beneficial compared to a single gradient-step in Metropolis-adjusted Langevin proposals. Empirical evidence suggests that the adaptation method can outperform different versions of HMC schemes by adjusting the mass matrix to the geometry of the target distribution and by providing some control on the integration time.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 13, 2021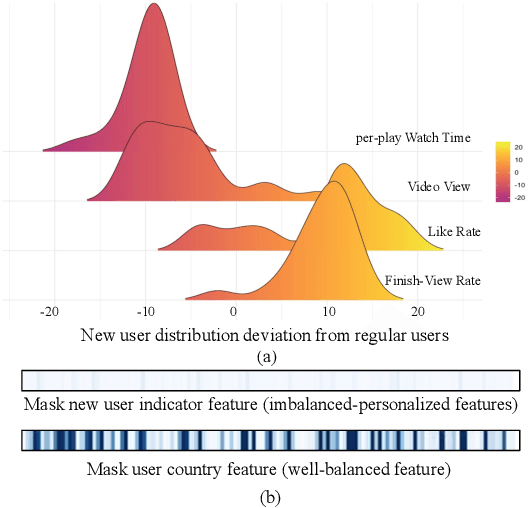
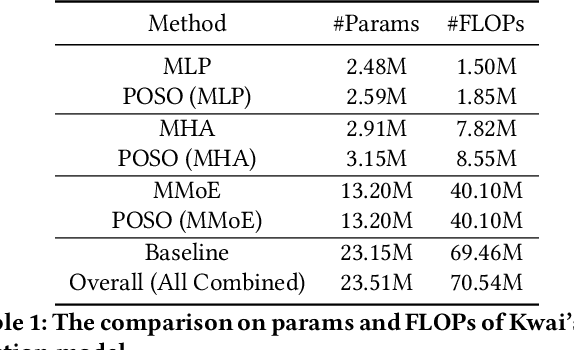
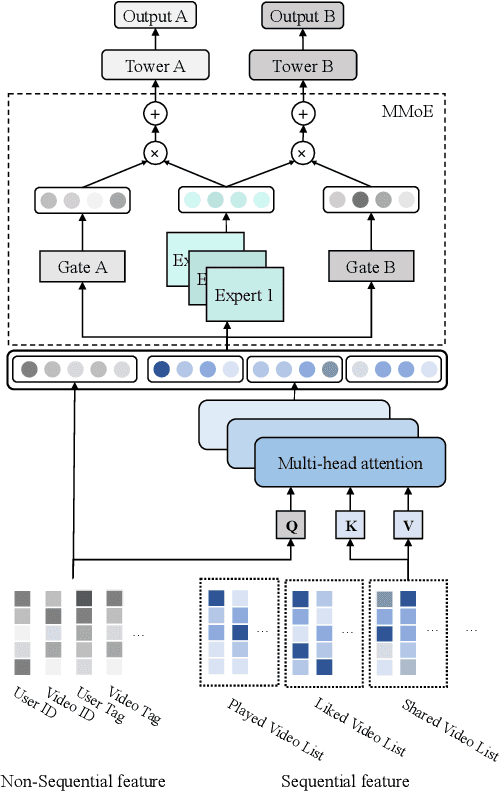
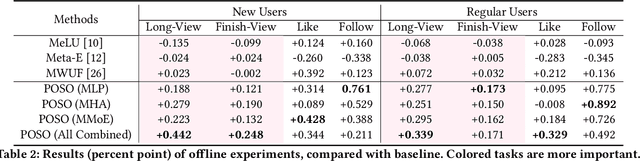
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the "submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.
Deep Reinforcement Learning for Optimizing RIS-Assisted HD-FD Wireless Systems
Oct 10, 2021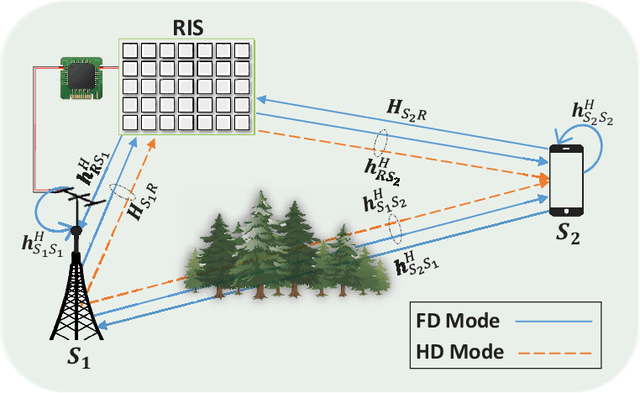
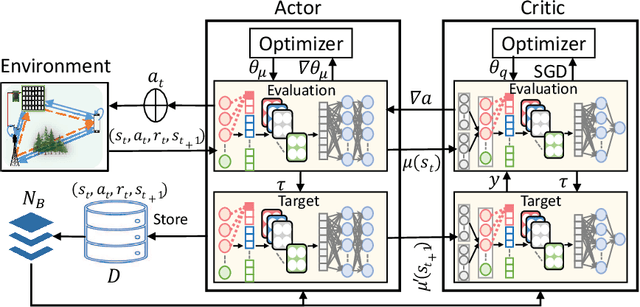
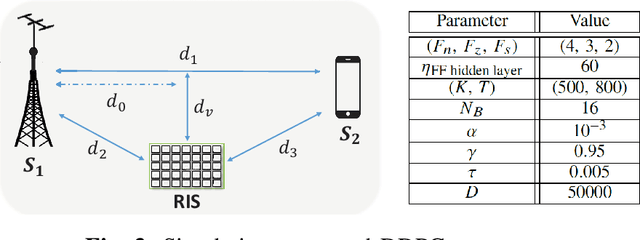
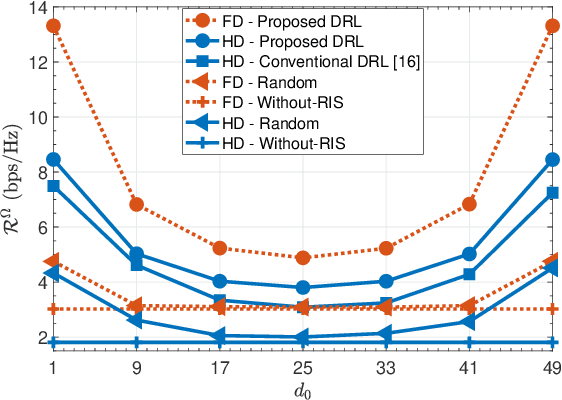
This letter investigates the reconfigurable intelligent surface (RIS)-assisted multiple-input single-output (MISO) wireless system, where both half-duplex (HD) and full-duplex (FD) operating modes are considered together, for the first time in the literature. The goal is to maximize the rate by optimizing the RIS phase shifts. A novel deep reinforcement learning (DRL) algorithm is proposed to solve the formulated non-convex optimization problem. The complexity analysis and Monte Carlo simulations illustrate that the proposed DRL algorithm significantly improves the rate compared to the non-optimized scenario in both HD and FD operating modes using a single parameter setting. Besides, it significantly reduces the computational complexity of the downlink HD MISO system and improves the achievable rate with a reduced number of steps per episode compared to the conventional DRL algorithm.
Deep Learning Based Reconstruction of Total Solar Irradiance
Jul 23, 2021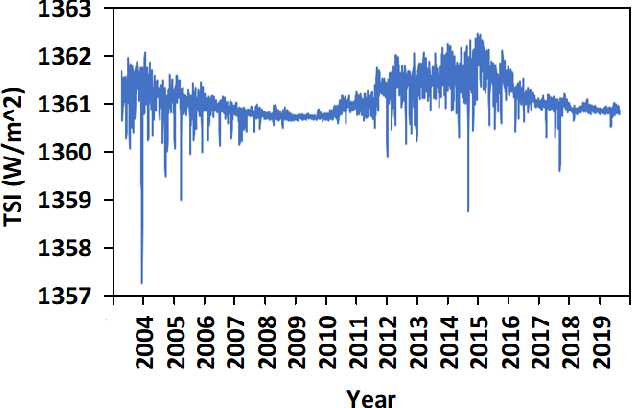
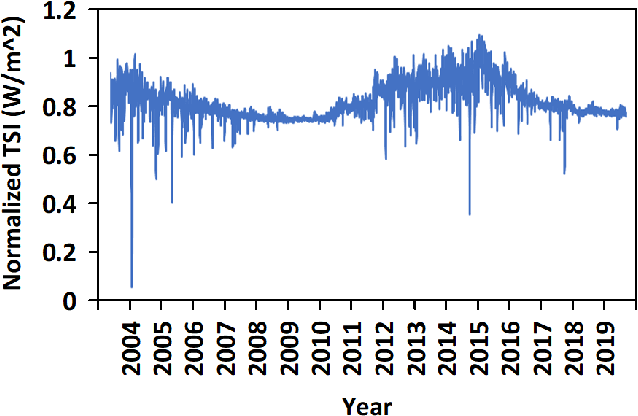
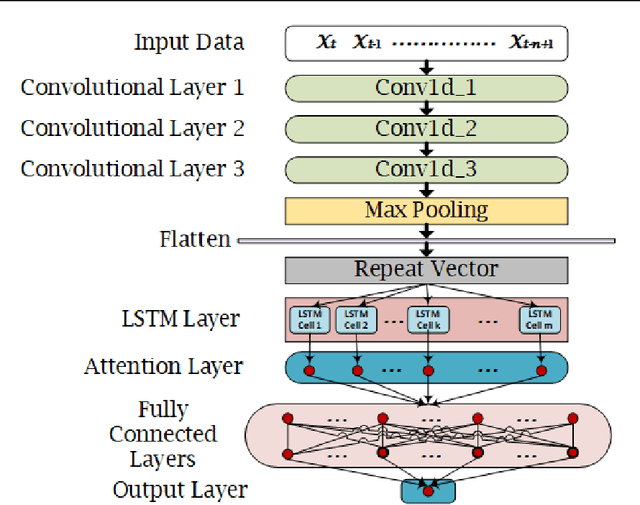
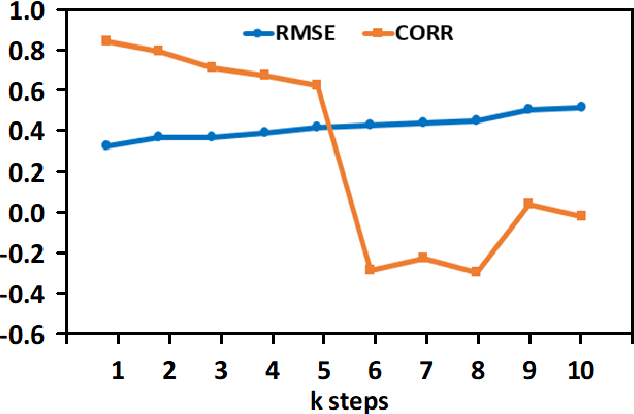
The Earth's primary source of energy is the radiant energy generated by the Sun, which is referred to as solar irradiance, or total solar irradiance (TSI) when all of the radiation is measured. A minor change in the solar irradiance can have a significant impact on the Earth's climate and atmosphere. As a result, studying and measuring solar irradiance is crucial in understanding climate changes and solar variability. Several methods have been developed to reconstruct total solar irradiance for long and short periods of time; however, they are physics-based and rely on the availability of data, which does not go beyond 9,000 years. In this paper we propose a new method, called TSInet, to reconstruct total solar irradiance by deep learning for short and long periods of time that span beyond the physical models' data availability. On the data that are available, our method agrees well with the state-of-the-art physics-based reconstruction models. To our knowledge, this is the first time that deep learning has been used to reconstruct total solar irradiance for more than 9,000 years.
Paperfetcher: A tool to automate handsearch for systematic reviews
Oct 27, 2021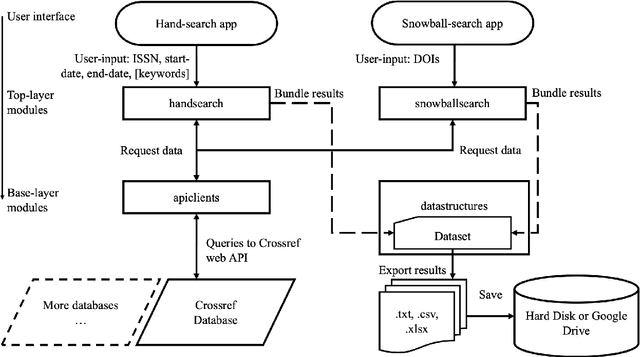
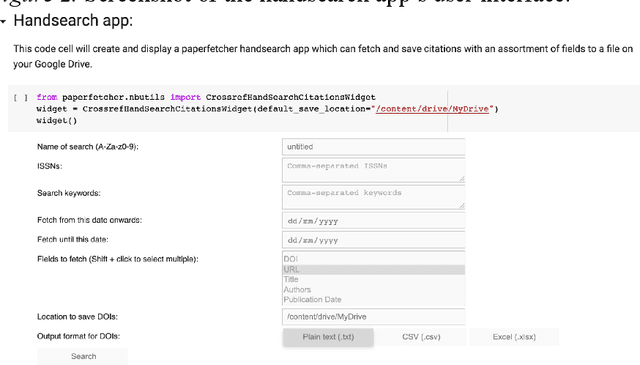
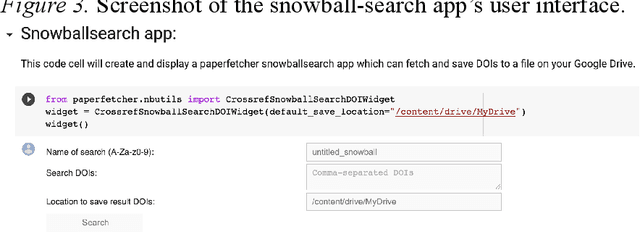
This paper presents a browser-based software tool, Paperfetcher, to automate the handsearch portion of systematic reviews. Paperfetcher has two parts: an extensible back-end framework written in Python, which does all the heavy lifting, and a set of easy-to-use front-end apps for researchers. The front-end apps can be run online, with no setup, on a cloud platform. Privacy-conscious users can run the app on their computers after a few steps of installation, and advanced users can modify the source code and extend the back-end interface for their own specific needs. Paperfetcher's website has user guidelines and a step-by-step setup video to coach researchers to use the software. With Paperfetcher's assistance, researchers can retrieve articles from designated journals and a given timeframe with just a few clicks. Researchers can also restrict their search to papers matching a set of keywords. In addition, Paperfetcher automates snowball-search, which retrieves all references from selected articles. Paperfetcher helps save a considerable amount of time and energy in the literature search portion of systematic reviews.
CineFilter: Unsupervised Filtering for Real Time Autonomous Camera Systems
Dec 11, 2019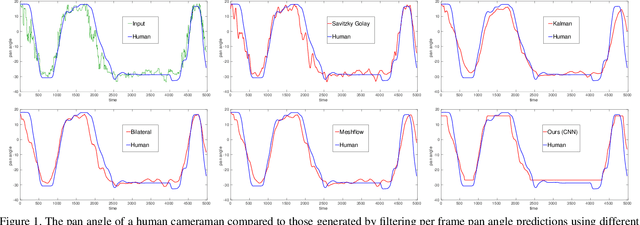
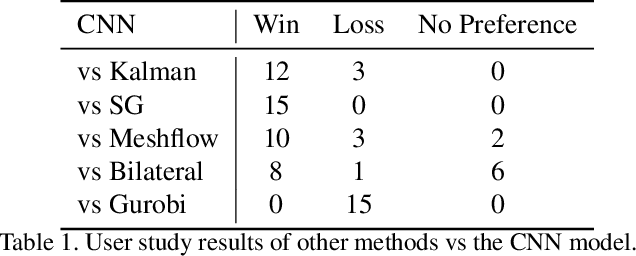
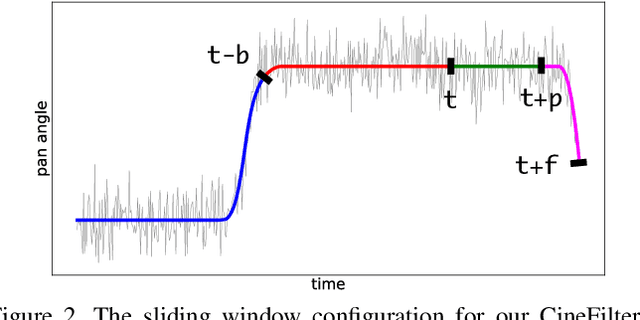
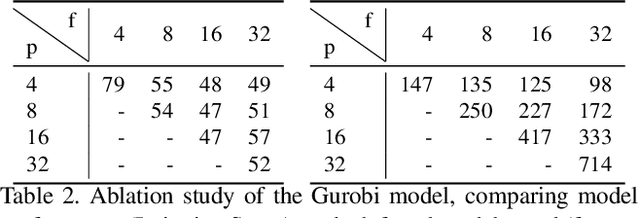
Learning to mimic the smooth and deliberate camera movement of a human cameraman is an essential requirement for autonomous camera systems. This paper presents a novel formulation for online and real-time estimation of smooth camera trajectories. Many works have focused on global optimization of the trajectory to produce an offline output. Some recent works have tried to extend this to the online setting, but lack either in the quality of the camera trajectories or need large labeled datasets to train their supervised model. We propose two models, one a convex optimization based approach and another a CNN based model, both of which can exploit the temporal trends in the camera behavior. Our model is built in an unsupervised way without any ground truth trajectories and is robust to noisy outliers. We evaluate our models on two different settings namely a basketball dataset and a stage performance dataset and compare against multiple baselines and past approaches. Our models outperform other methods on quantitative and qualitative metrics and produce smooth camera trajectories that are motivated by cinematographic principles. These models can also be easily adopted to run in real-time with a low computational cost, making them fit for a variety of applications.
Long Short-term Cognitive Networks
Jun 30, 2021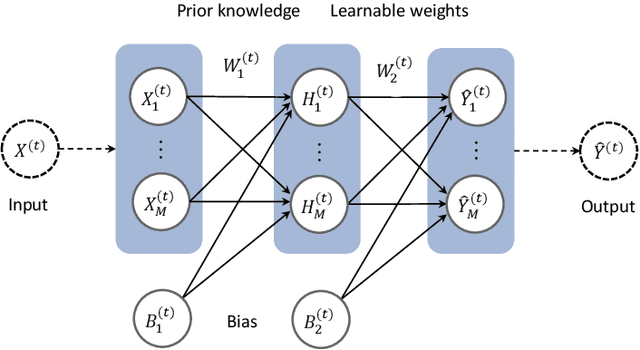
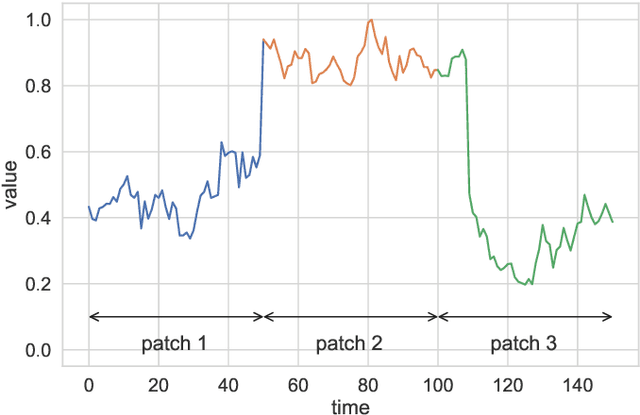
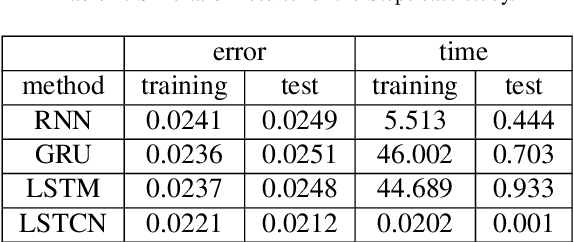
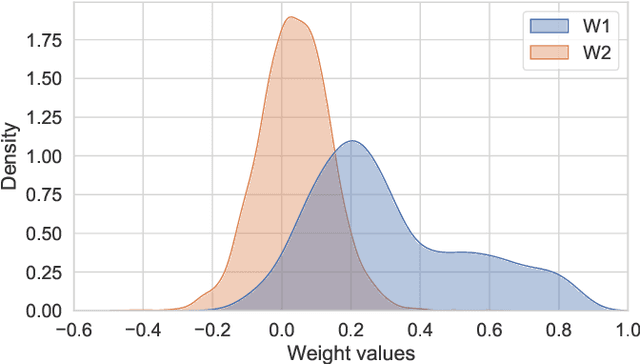
In this paper, we present a recurrent neural system named Long Short-term Cognitive Networks (LSTCNs) as a generalisation of the Short-term Cognitive Network (STCN) model. Such a generalisation is motivated by the difficulty of forecasting very long time series in an efficient, greener fashion. The LSTCN model can be defined as a collection of STCN blocks, each processing a specific time patch of the (multivariate) time series being modelled. In this neural ensemble, each block passes information to the subsequent one in the form of a weight matrix referred to as the prior knowledge matrix. As a second contribution, we propose a deterministic learning algorithm to compute the learnable weights while preserving the prior knowledge resulting from previous learning processes. As a third contribution, we introduce a feature influence score as a proxy to explain the forecasting process in multivariate time series. The simulations using three case studies show that our neural system reports small forecasting errors while being up to thousands of times faster than state-of-the-art recurrent models.
Melatect: A Machine Learning Model Approach For Identifying Malignant Melanoma in Skin Growths
Sep 07, 2021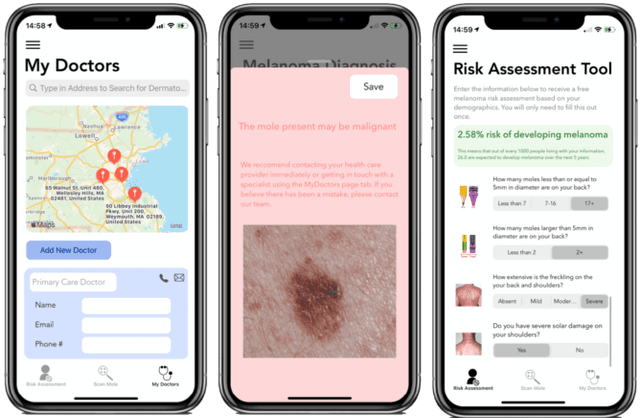
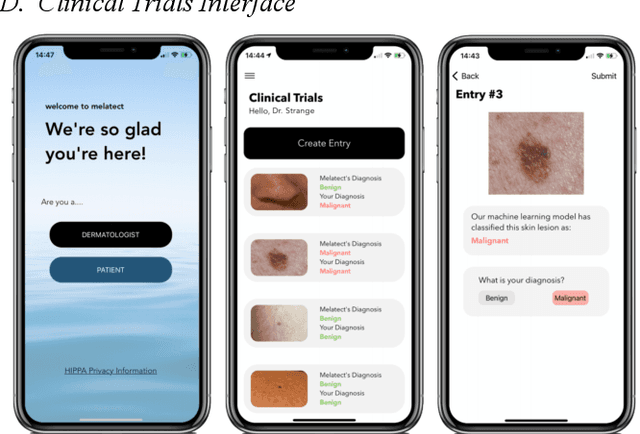
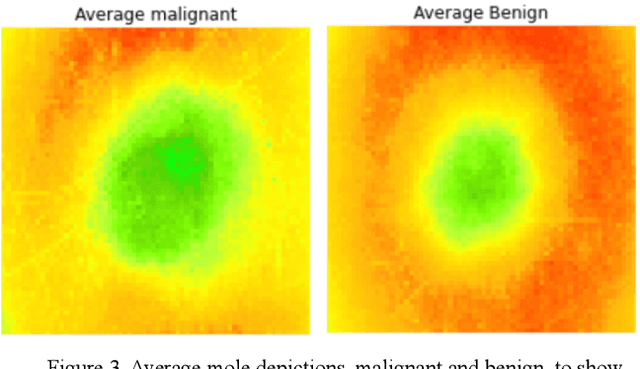
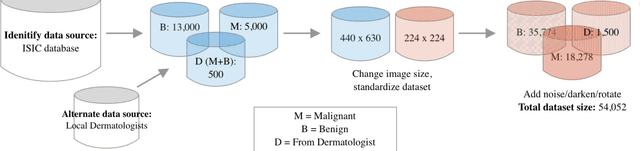
Malignant melanoma is a common skin cancer that is mostly curable before metastasis, where melanoma growths spawn in organs away from the original site. Melanoma is the most dangerous type of skin cancer if left untreated due to the high chance of metastasis. This paper presents Melatect, a machine learning model that identifies potential malignant melanoma. A recursive computer image analysis algorithm was used to create a machine learning model which is capable of detecting likely melanoma. The comparison is performed using 20,000 raw images of benign and malignant lesions from the International Skin Imaging Collaboration (ISIC) archive that were augmented to 60,000 images. Tests of the algorithm using subsets of the ISIC images suggest it accurately classifies lesions as malignant or benign over 95% of the time with no apparent bias or overfitting. The Melatect iOS app was later created (unpublished), in which the machine learning model was embedded. With the app, users have the ability to take pictures of skin lesions (moles) using the app, which are then processed through the machine learning model, and users are notified whether their lesion could be abnormal or not. Melatect provides a convenient way to get free advice on lesions and track these lesions over time.
Wide and Deep Graph Neural Network with Distributed Online Learning
Jul 19, 2021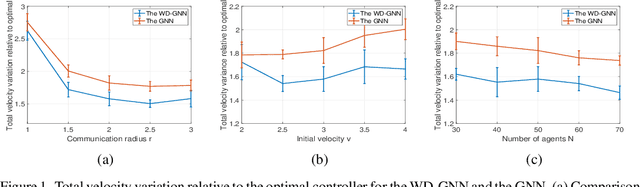
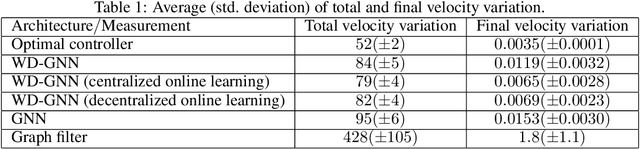
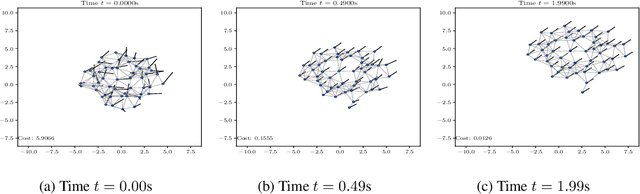
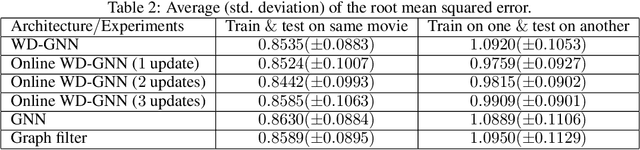
Graph neural networks (GNNs) are naturally distributed architectures for learning representations from network data. This renders them suitable candidates for decentralized tasks. In these scenarios, the underlying graph often changes with time due to link failures or topology variations, creating a mismatch between the graphs on which GNNs were trained and the ones on which they are tested. Online learning can be leveraged to retrain GNNs at testing time to overcome this issue. However, most online algorithms are centralized and usually offer guarantees only on convex problems, which GNNs rarely lead to. This paper develops the Wide and Deep GNN (WD-GNN), a novel architecture that can be updated with distributed online learning mechanisms. The WD-GNN consists of two components: the wide part is a linear graph filter and the deep part is a nonlinear GNN. At training time, the joint wide and deep architecture learns nonlinear representations from data. At testing time, the wide, linear part is retrained, while the deep, nonlinear one remains fixed. This often leads to a convex formulation. We further propose a distributed online learning algorithm that can be implemented in a decentralized setting. We also show the stability of the WD-GNN to changes of the underlying graph and analyze the convergence of the proposed online learning procedure. Experiments on movie recommendation, source localization and robot swarm control corroborate theoretical findings and show the potential of the WD-GNN for distributed online learning.