 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FAR Planner: Fast, Attemptable Route Planner using Dynamic Visibility Update
Oct 18, 2021


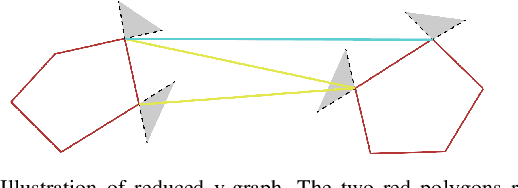
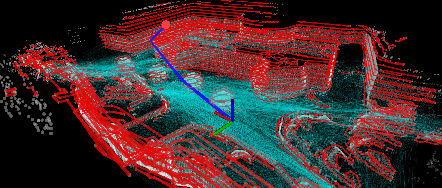
We present our work on a fast route planner based on visibility graph. The method extracts edge points around obstacles in the environment to form polygons, with which, the method dynamically updates a global visibility graph, expanding the visibility graph along with the navigation and removing edges that become occluded by dynamic obstacles. When guiding a vehicle to the goal, the method can deal with both known and unknown environments. In the latter case, the method is attemptable in discovering a way to the goal by picking up the environment layout on the fly. We evaluate the method using both ground and aerial vehicles, in simulated and real-world settings. In highly convoluted unknown or partially known environments, our method is able to reduce travel time by 13-27% compared to RRT*, RRT-Connect, A*, and D* Lite, and finds a path within 3ms in all of our experiments.
Multi-Attribute Balanced Sampling for Disentangled GAN Controls
Oct 28, 2021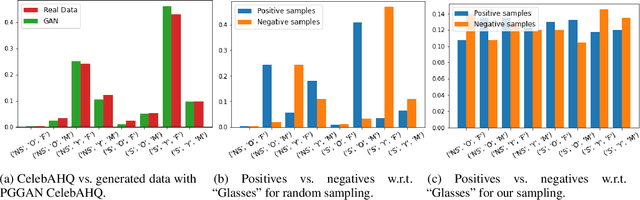
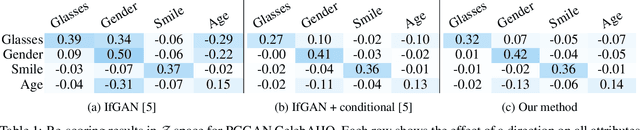
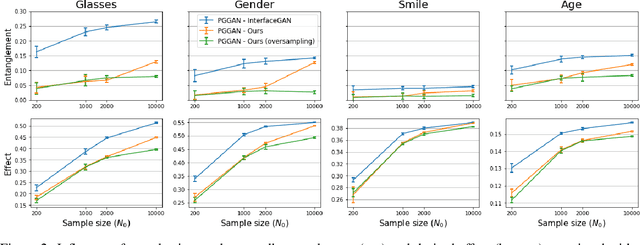
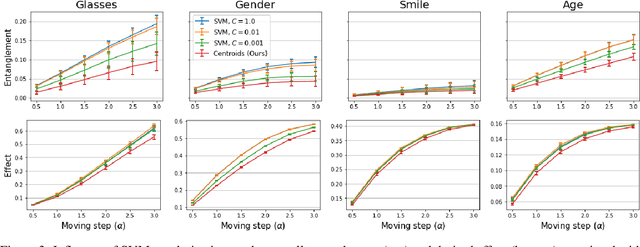
Various controls over the generated data can be extracted from the latent space of a pre-trained GAN, as it implicitly encodes the semantics of the training data. The discovered controls allow to vary semantic attributes in the generated images but usually lead to entangled edits that affect multiple attributes at the same time. Supervised approaches typically sample and annotate a collection of latent codes, then train classifiers in the latent space to identify the controls. Since the data generated by GANs reflects the biases of the original dataset, so do the resulting semantic controls. We propose to address disentanglement by subsampling the generated data to remove over-represented co-occuring attributes thus balancing the semantics of the dataset before training the classifiers. We demonstrate the effectiveness of this approach by extracting disentangled linear directions for face manipulation on two popular GAN architectures, PGGAN and StyleGAN, and two datasets, CelebAHQ and FFHQ. We show that this approach outperforms state-of-the-art classifier-based methods while avoiding the need for disentanglement-enforcing post-processing.
Subadditivity of Probability Divergences on Bayes-Nets with Applications to Time Series GANs
Mar 02, 2020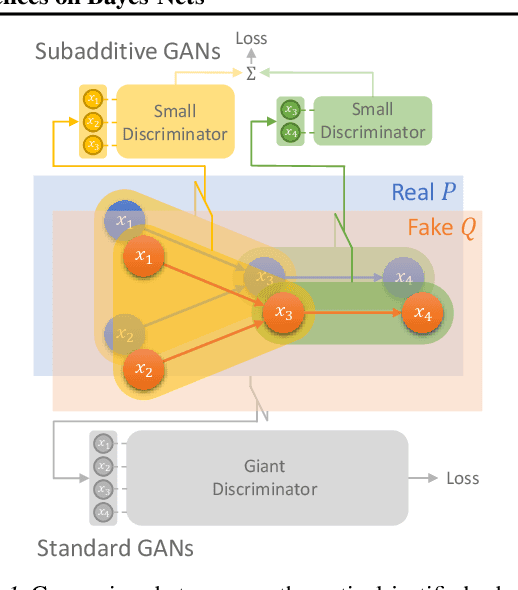
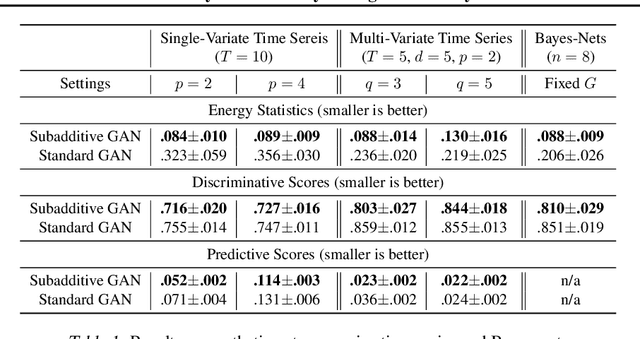
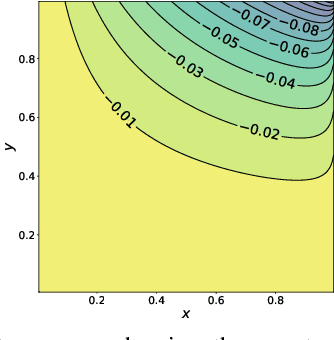

GANs for time series data often use sliding windows or self-attention to capture underlying time dependencies. While these techniques have no clear theoretical justification, they are successful in significantly reducing the discriminator size, speeding up the training process, and improving the generation quality. In this paper, we provide both theoretical foundations and a practical framework of GANs for high-dimensional distributions with conditional independence structure captured by a Bayesian network, such as time series data. We prove that several probability divergences satisfy subadditivity properties with respect to the neighborhoods of the Bayes-net graph, providing an upper bound on the distance between two Bayes-nets by the sum of (local) distances between their marginals on every neighborhood of the graph. This leads to our proposed Subadditive GAN framework that uses a set of simple discriminators on the neighborhoods of the Bayes-net, rather than a giant discriminator on the entire network, providing significant statistical and computational benefits. We show that several probability distances including Jensen-Shannon, Total Variation, and Wasserstein, have subadditivity or generalized subadditivity. Moreover, we prove that Integral Probability Metrics (IPMs), which encompass commonly-used loss functions in GANs, also enjoy a notion of subadditivity under some mild conditions. Furthermore, we prove that nearly all f-divergences satisfy local subadditivity in which subadditivity holds when the distributions are relatively close. Our experiments on synthetic as well as real-world datasets verify the proposed theory and the benefits of subadditive GANs.
A 2D Non-Stationary Channel Model for Underwater Acoustic Communication Systems
Aug 14, 2021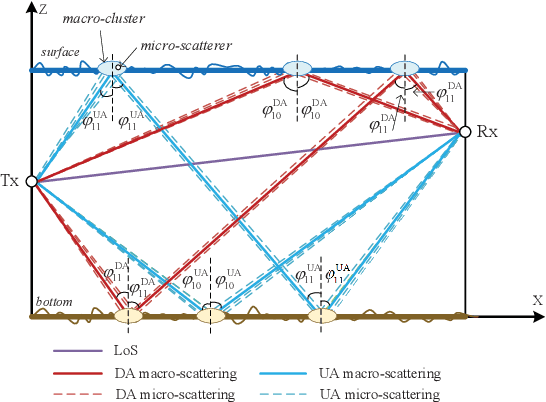
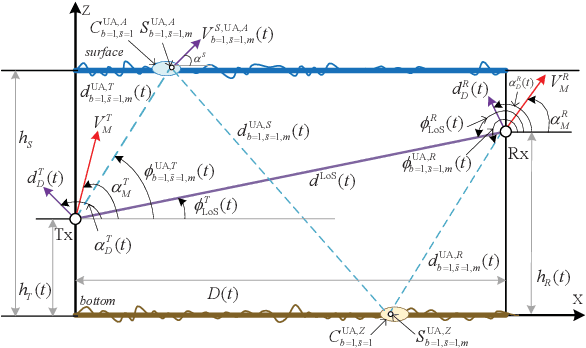
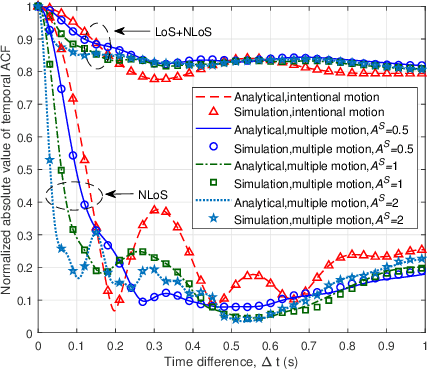
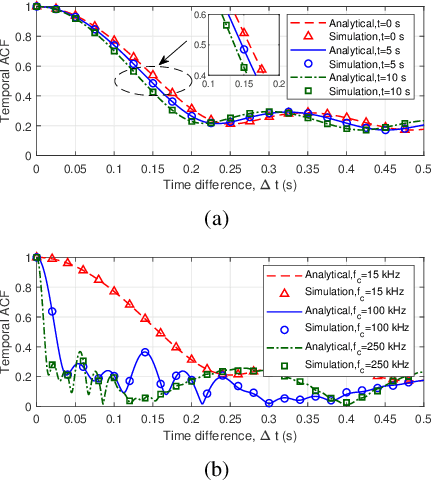
Underwater acoustic (UWA) communication plays a key role in the process of exploring and studying the ocean. In this paper, a modified non-stationary wideband channel model for UWA communication in shallow water scenarios is proposed. In this geometry-based stochastic model (GBSM), multiple motion effects, time-varying angles, distances, clusters' locations with the channel geometry, and the ultra-wideband property are considered, which makes the proposed model more realistic and capable of supporting long time/distance simulations. Some key statistical properties are investigated, including temporal autocorrelation function (ACF), power delay profile (PDP), average delay, and root mean square (RMS) delay spread. The impacts of multiple motion factors on temporal ACFs are analyzed. Simulation results show that the proposed model can mimic the non-stationarity of UWA channels. Finally, the proposed model is validated with measurement data.
Facial Landmark Points Detection Using Knowledge Distillation-Based Neural Networks
Nov 13, 2021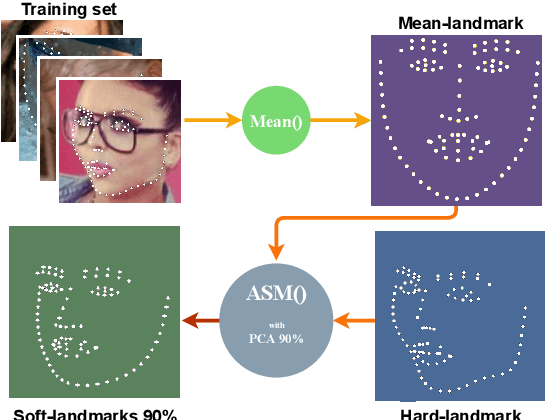
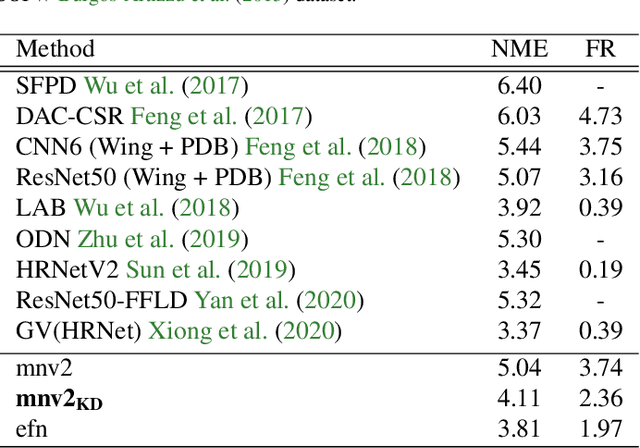

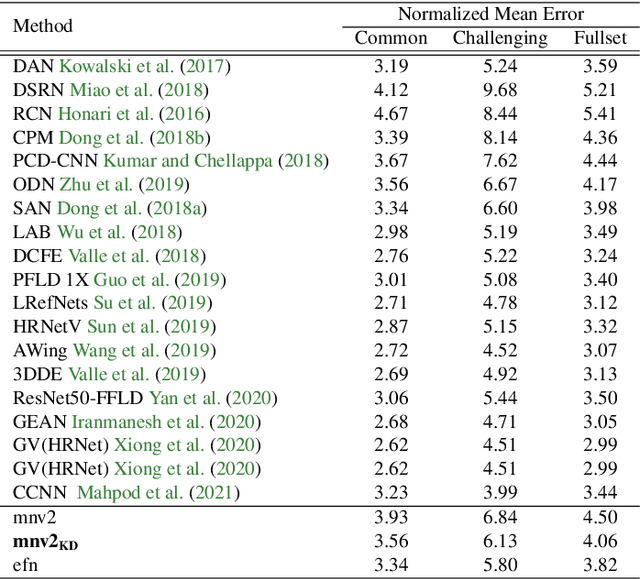
Facial landmark detection is a vital step for numerous facial image analysis applications. Although some deep learning-based methods have achieved good performances in this task, they are often not suitable for running on mobile devices. Such methods rely on networks with many parameters, which makes the training and inference time-consuming. Training lightweight neural networks such as MobileNets are often challenging, and the models might have low accuracy. Inspired by knowledge distillation (KD), this paper presents a novel loss function to train a lightweight Student network (e.g., MobileNetV2) for facial landmark detection. We use two Teacher networks, a Tolerant-Teacher and a Tough-Teacher in conjunction with the Student network. The Tolerant-Teacher is trained using Soft-landmarks created by active shape models, while the Tough-Teacher is trained using the ground truth (aka Hard-landmarks) landmark points. To utilize the facial landmark points predicted by the Teacher networks, we define an Assistive Loss (ALoss) for each Teacher network. Moreover, we define a loss function called KD-Loss that utilizes the facial landmark points predicted by the two pre-trained Teacher networks (EfficientNet-b3) to guide the lightweight Student network towards predicting the Hard-landmarks. Our experimental results on three challenging facial datasets show that the proposed architecture will result in a better-trained Student network that can extract facial landmark points with high accuracy.
Effects of VLSI Circuit Constraints on Temporal-Coding Multilayer Spiking Neural Networks
Jun 25, 2021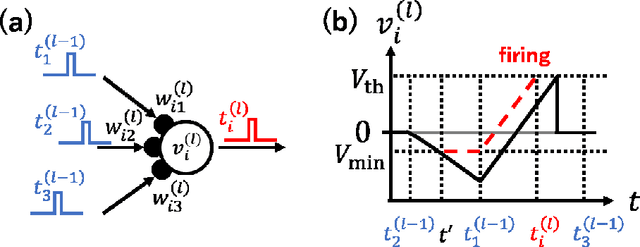
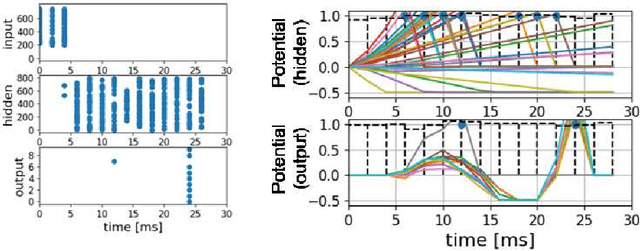
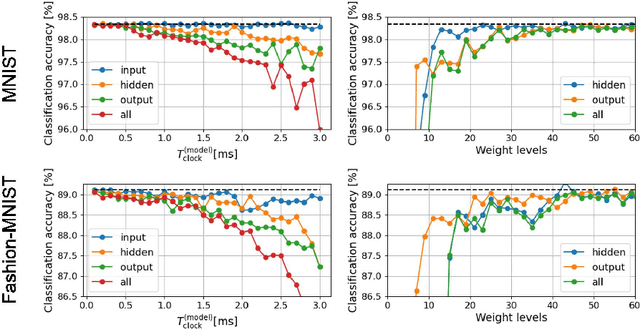
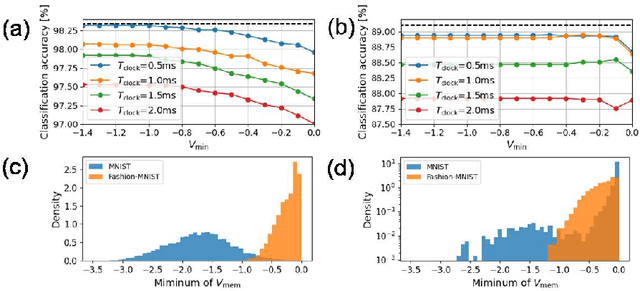
The spiking neural network (SNN) has been attracting considerable attention not only as a mathematical model for the brain, but also as an energy-efficient information processing model for real-world applications. In particular, SNNs based on temporal coding are expected to be much more efficient than those based on rate coding, because the former requires substantially fewer spikes to carry out tasks. As SNNs are continuous-state and continuous-time models, it is favorable to implement them with analog VLSI circuits. However, the construction of the entire system with continuous-time analog circuits would be infeasible when the system size is very large. Therefore, mixed-signal circuits must be employed, and the time discretization and quantization of the synaptic weights are necessary. Moreover, the analog VLSI implementation of SNNs exhibits non-idealities, such as the effects of noise and device mismatches, as well as other constraints arising from the analog circuit operation. In this study, we investigated the effects of the time discretization and/or weight quantization on the performance of SNNs. Furthermore, we elucidated the effects the lower bound of the membrane potentials and the temporal fluctuation of the firing threshold. Finally, we propose an optimal approach for the mapping of mathematical SNN models to analog circuits with discretized time.
Joint inference and input optimization in equilibrium networks
Nov 25, 2021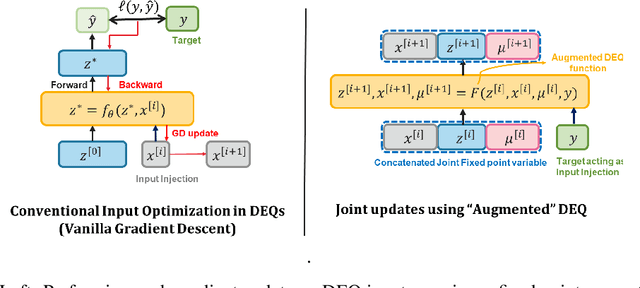
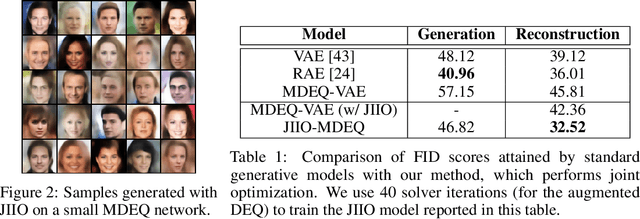
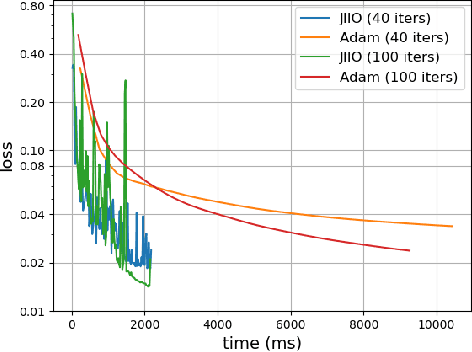
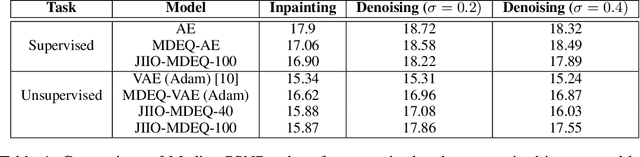
Many tasks in deep learning involve optimizing over the \emph{inputs} to a network to minimize or maximize some objective; examples include optimization over latent spaces in a generative model to match a target image, or adversarially perturbing an input to worsen classifier performance. Performing such optimization, however, is traditionally quite costly, as it involves a complete forward and backward pass through the network for each gradient step. In a separate line of work, a recent thread of research has developed the deep equilibrium (DEQ) model, a class of models that foregoes traditional network depth and instead computes the output of a network by finding the fixed point of a single nonlinear layer. In this paper, we show that there is a natural synergy between these two settings. Although, naively using DEQs for these optimization problems is expensive (owing to the time needed to compute a fixed point for each gradient step), we can leverage the fact that gradient-based optimization can \emph{itself} be cast as a fixed point iteration to substantially improve the overall speed. That is, we \emph{simultaneously} both solve for the DEQ fixed point \emph{and} optimize over network inputs, all within a single ``augmented'' DEQ model that jointly encodes both the original network and the optimization process. Indeed, the procedure is fast enough that it allows us to efficiently \emph{train} DEQ models for tasks traditionally relying on an ``inner'' optimization loop. We demonstrate this strategy on various tasks such as training generative models while optimizing over latent codes, training models for inverse problems like denoising and inpainting, adversarial training and gradient based meta-learning.
* Neurips 2021
Optimal Sensor Placement for Source Localization: A Unified ADMM Approach
Sep 08, 2021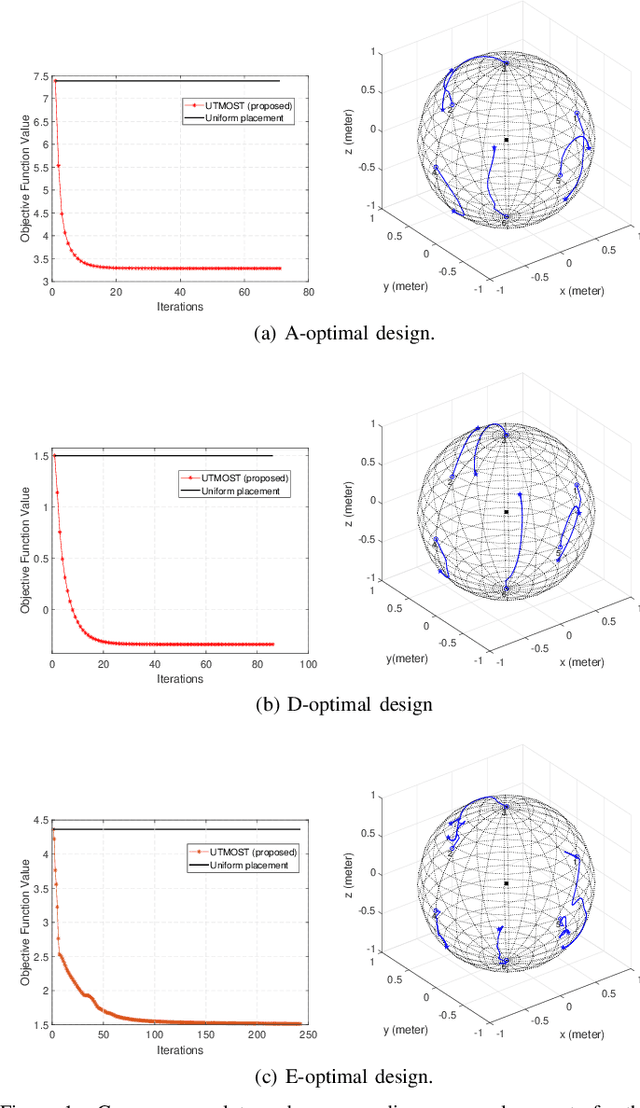
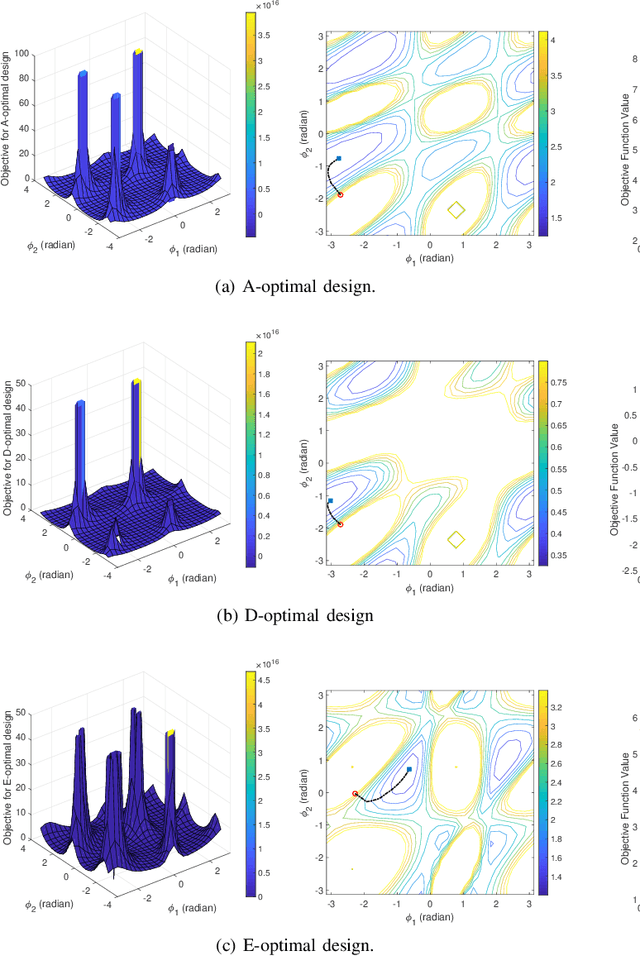
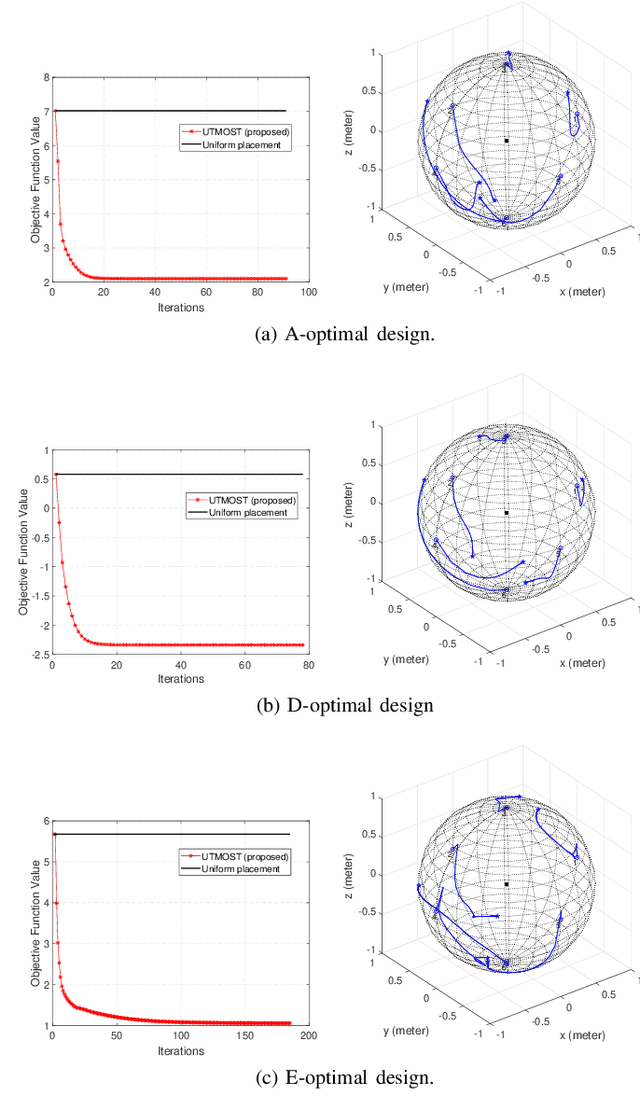
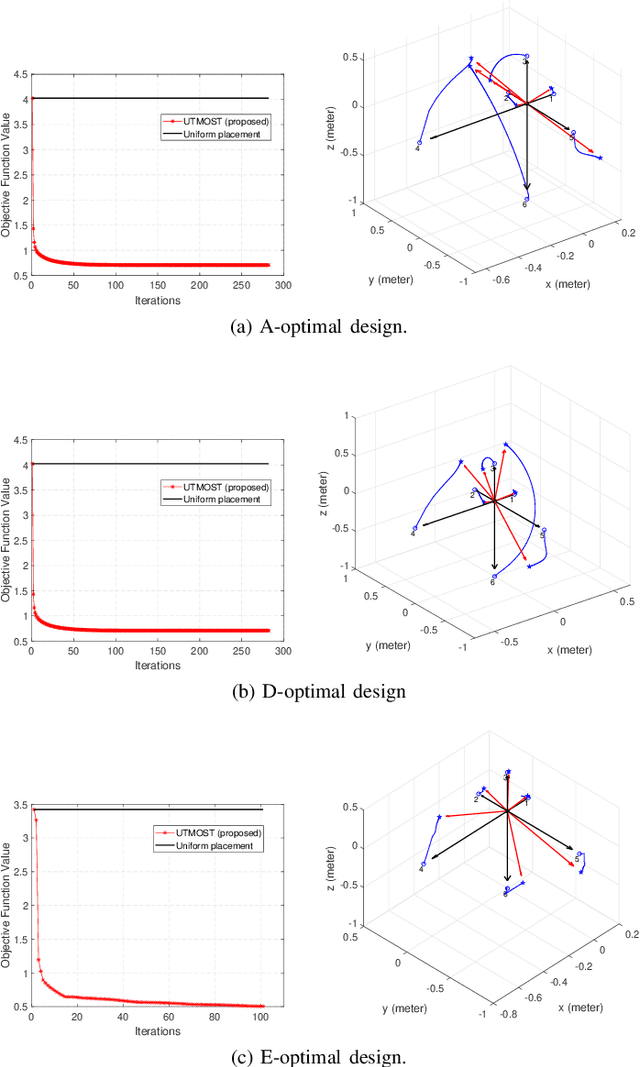
Source localization plays a key role in many applications including radar, wireless and underwater communications. Among various localization methods, the most popular ones are Time-Of-Arrival (TOA), Time-Difference-Of-Arrival (TDOA), and Received Signal Strength (RSS) based. Since the Cram\'{e}r-Rao lower bounds (CRLB) of these methods depend on the sensor geometry explicitly, sensor placement becomes a crucial issue in source localization applications. In this paper, we consider finding the optimal sensor placements for the TOA, TDOA and RSS based localization scenarios. We first unify the three localization models by a generalized problem formulation based on the CRLB-related metric. Then a unified optimization framework for optimal sensor placement (UTMOST) is developed through the combination of the alternating direction method of multipliers (ADMM) and majorization-minimization (MM) techniques. Unlike the majority of the state-of-the-art works, the proposed UTMOST neither approximates the design criterion nor considers only uncorrelated noise in the measurements. It can readily adapt to to different design criteria (i.e. A, D and E-optimality) with slight modifications within the framework and yield the optimal sensor placements correspondingly. Extensive numerical experiments are performed to exhibit the efficacy and flexibility of the proposed framework.
A Case Study to Reveal if an Area of Interest has a Trend in Ongoing Tweets Using Word and Sentence Embeddings
Oct 02, 2021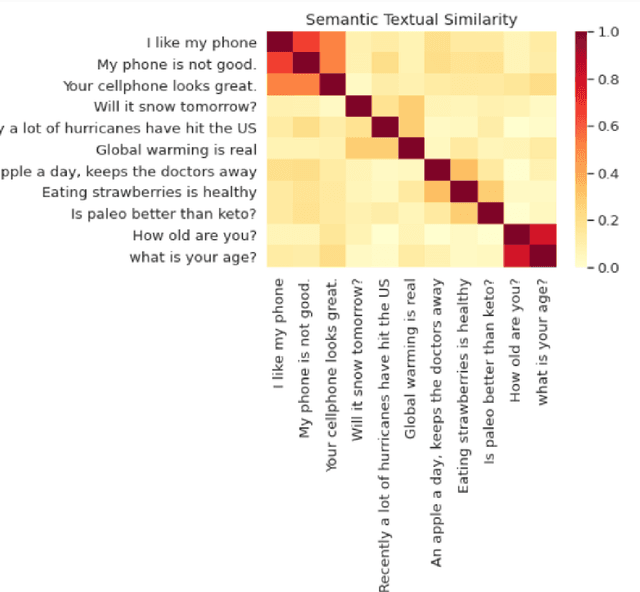
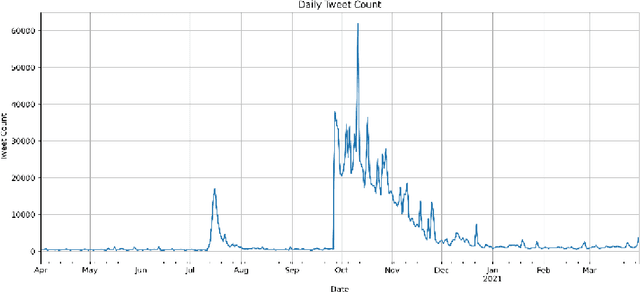
In the field of Natural Language Processing, information extraction from texts has been the objective of many researchers for years. Many different techniques have been applied in order to reveal the opinion that a tweet might have, thus understanding the sentiment of the small writing up to 280 characters. Other than figuring out the sentiment of a tweet, a study can also focus on finding the correlation of the tweets with a certain area of interest, which constitutes the purpose of this study. In order to reveal if an area of interest has a trend in ongoing tweets, we have proposed an easily applicable automated methodology in which the Daily Mean Similarity Scores that show the similarity between the daily tweet corpus and the target words representing our area of interest is calculated by using a na\"ive correlation-based technique without training any Machine Learning Model. The Daily Mean Similarity Scores have mainly based on cosine similarity and word/sentence embeddings computed by Multilanguage Universal Sentence Encoder and showed main opinion stream of the tweets with respect to a certain area of interest, which proves that an ongoing trend of a specific subject on Twitter can easily be captured in almost real time by using the proposed methodology in this study. We have also compared the effectiveness of using word versus sentence embeddings while applying our methodology and realized that both give almost the same results, whereas using word embeddings requires less computational time than sentence embeddings, thus being more effective. This paper will start with an introduction followed by the background information about the basics, then continue with the explanation of the proposed methodology and later on finish by interpreting the results and concluding the findings.
The Neural Data Router: Adaptive Control Flow in Transformers Improves Systematic Generalization
Oct 14, 2021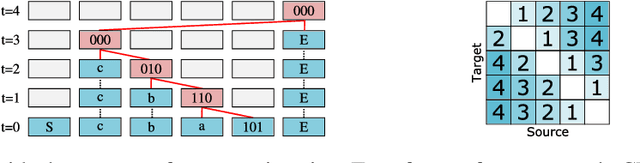
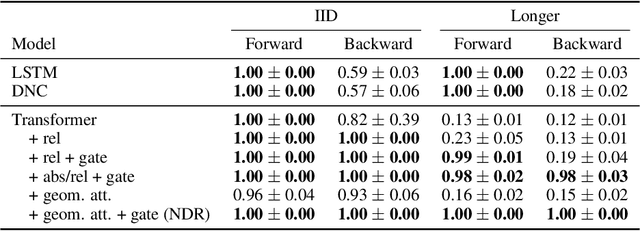

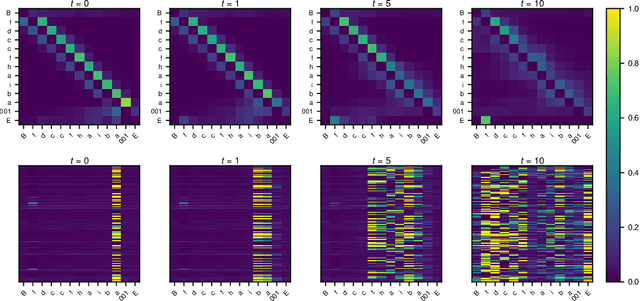
Despite successes across a broad range of applications, Transformers have limited success in systematic generalization. The situation is especially frustrating in the case of algorithmic tasks, where they often fail to find intuitive solutions that route relevant information to the right node/operation at the right time in the grid represented by Transformer columns. To facilitate the learning of useful control flow, we propose two modifications to the Transformer architecture, copy gate and geometric attention. Our novel Neural Data Router (NDR) achieves 100% length generalization accuracy on the classic compositional table lookup task, as well as near-perfect accuracy on the simple arithmetic task and a new variant of ListOps testing for generalization across computational depth. NDR's attention and gating patterns tend to be interpretable as an intuitive form of neural routing. Our code is public.