 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021
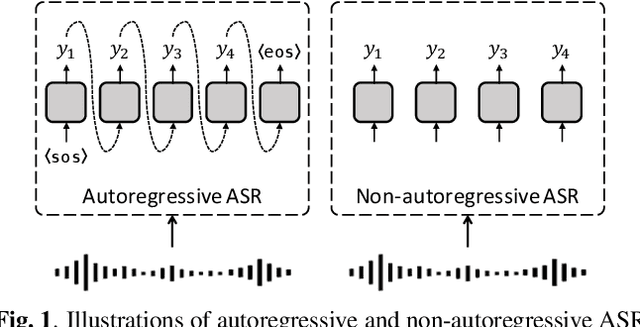

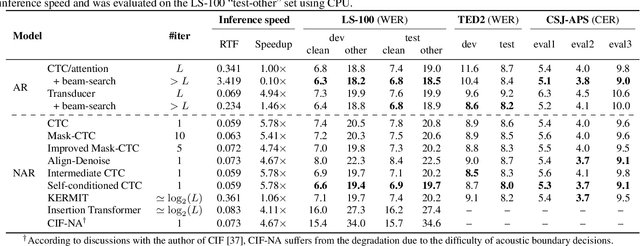
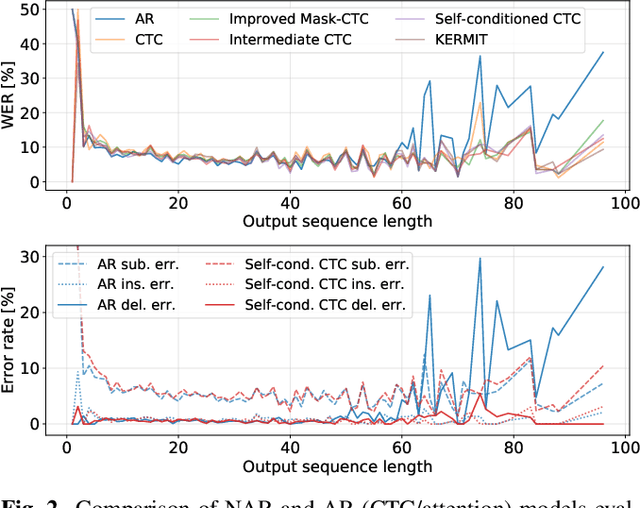
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Out-of-Distribution Detection for Medical Applications: Guidelines for Practical Evaluation
Sep 30, 2021
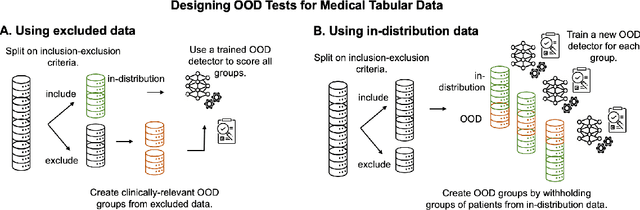
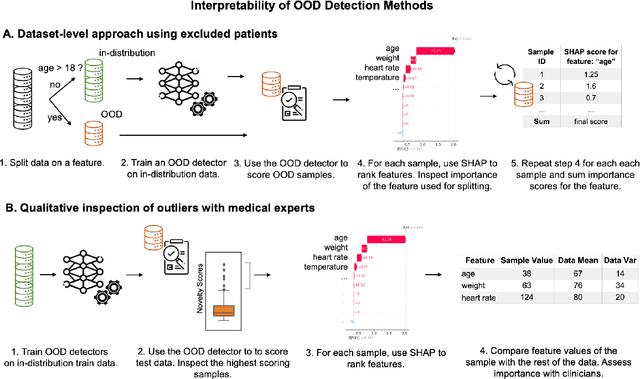
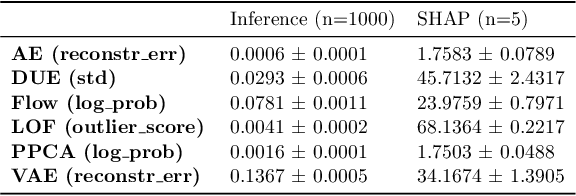
Detection of Out-of-Distribution (OOD) samples in real time is a crucial safety check for deployment of machine learning models in the medical field. Despite a growing number of uncertainty quantification techniques, there is a lack of evaluation guidelines on how to select OOD detection methods in practice. This gap impedes implementation of OOD detection methods for real-world applications. Here, we propose a series of practical considerations and tests to choose the best OOD detector for a specific medical dataset. These guidelines are illustrated on a real-life use case of Electronic Health Records (EHR). Our results can serve as a guide for implementation of OOD detection methods in clinical practice, mitigating risks associated with the use of machine learning models in healthcare.
Mining frequency-based sequential trajectory co-clusters
Oct 27, 2021
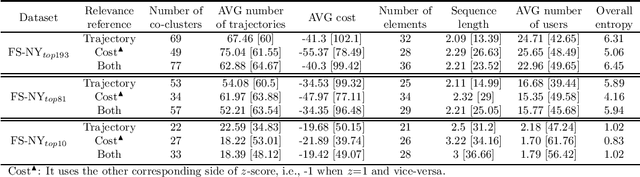
Co-clustering is a specific type of clustering that addresses the problem of finding groups of objects without necessarily considering all attributes. This technique has shown to have more consistent results in high-dimensional sparse data than traditional clustering. In trajectory co-clustering, the methods found in the literature have two main limitations: first, the space and time dimensions have to be constrained by user-defined thresholds; second, elements (trajectory points) are clustered ignoring the trajectory sequence, assuming that the points are independent among them. To address the limitations above, we propose a new trajectory co-clustering method for mining semantic trajectory co-clusters. It simultaneously clusters the trajectories and their elements taking into account the order in which they appear. This new method uses the element frequency to identify candidate co-clusters. Besides, it uses an objective cost function that automatically drives the co-clustering process, avoiding the need for constraining dimensions. We evaluate the proposed approach using real-world a publicly available dataset. The experimental results show that our proposal finds frequent and meaningful contiguous sequences revealing mobility patterns, thereby the most relevant elements.
Single-Modal Entropy based Active Learning for Visual Question Answering
Oct 21, 2021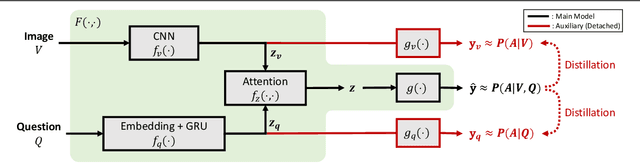
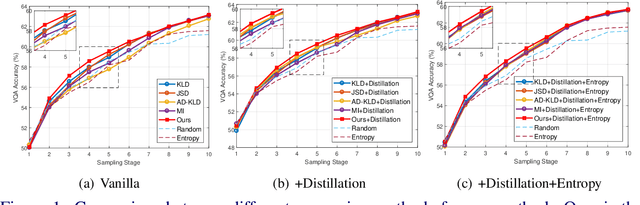
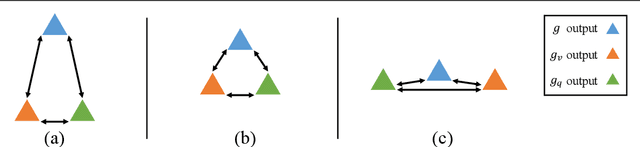
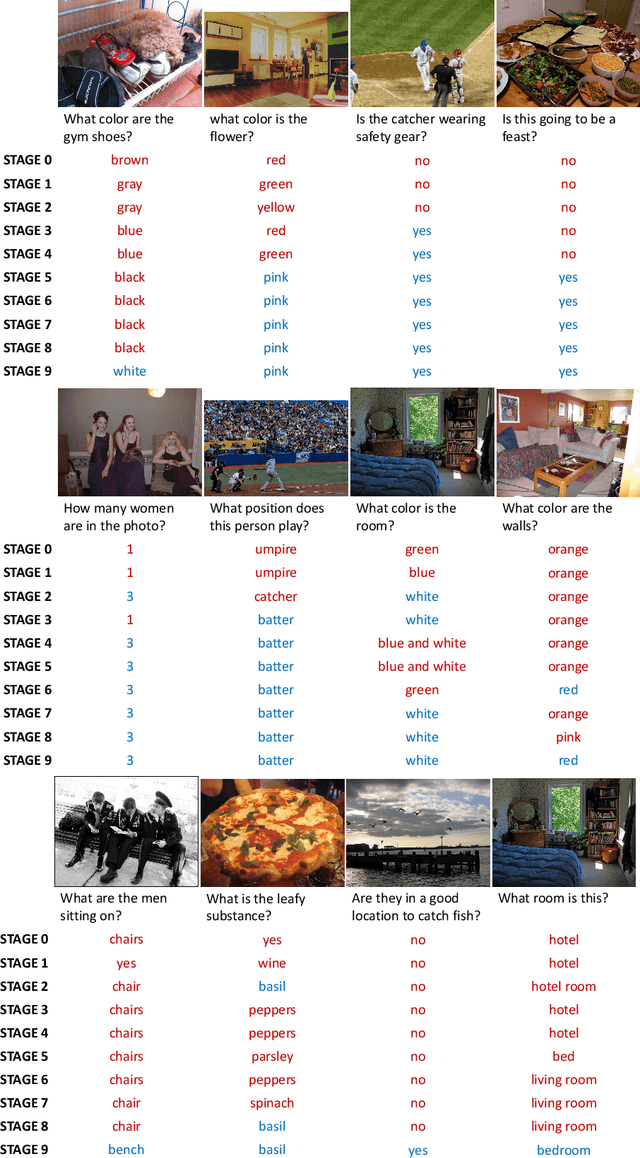
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Dynamic Pricing and Demand Learning on a Large Network of Products: A PAC-Bayesian Approach
Nov 01, 2021We consider a seller offering a large network of $N$ products over a time horizon of $T$ periods. The seller does not know the parameters of the products' linear demand model, and can dynamically adjust product prices to learn the demand model based on sales observations. The seller aims to minimize its pseudo-regret, i.e., the expected revenue loss relative to a clairvoyant who knows the underlying demand model. We consider a sparse set of demand relationships between products to characterize various connectivity properties of the product network. In particular, we study three different sparsity frameworks: (1) $L_0$ sparsity, which constrains the number of connections in the network, and (2) off-diagonal sparsity, which constrains the magnitude of cross-product price sensitivities, and (3) a new notion of spectral sparsity, which constrains the asymptotic decay of a similarity metric on network nodes. We propose a dynamic pricing-and-learning policy that combines the optimism-in-the-face-of-uncertainty and PAC-Bayesian approaches, and show that this policy achieves asymptotically optimal performance in terms of $N$ and $T$. We also show that in the case of spectral and off-diagonal sparsity, the seller can have a pseudo-regret linear in $N$, even when the network is dense.
Longitudinal Speech Biomarkers for Automated Alzheimer's Detection
Nov 22, 2021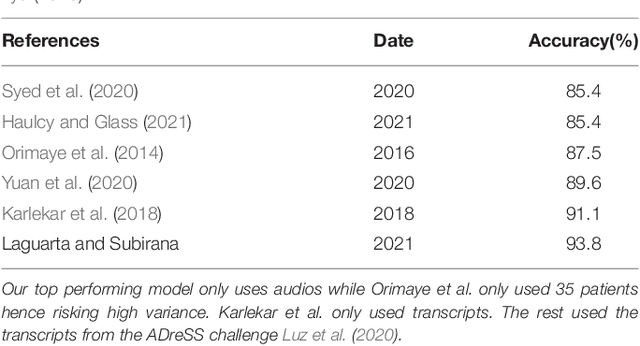
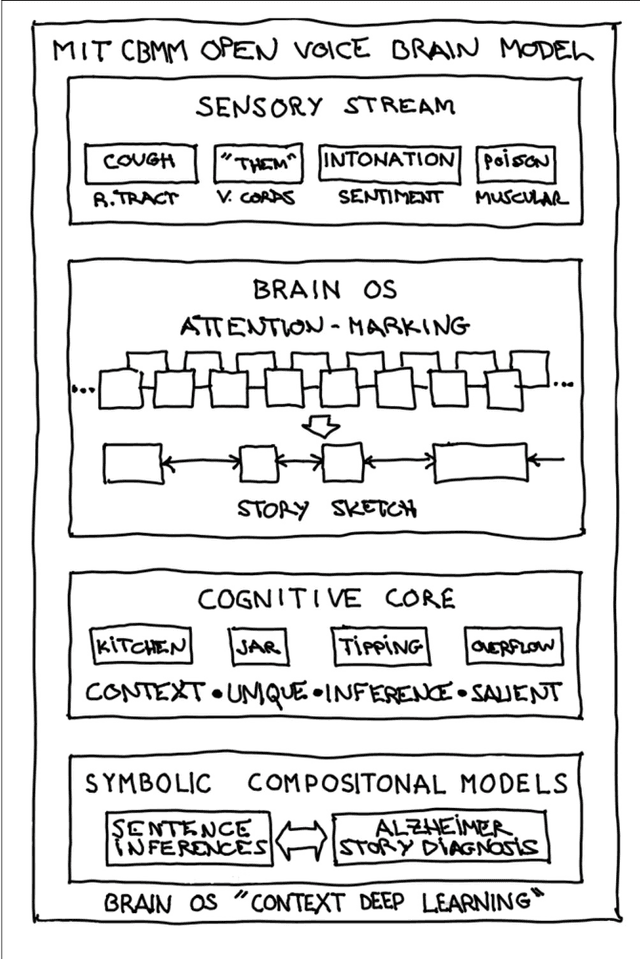
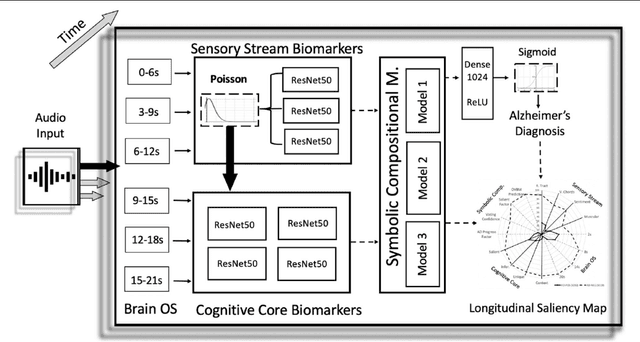
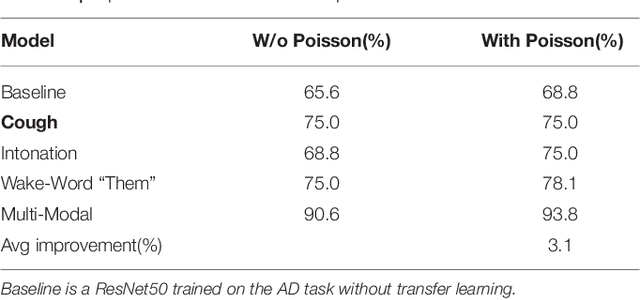
We introduce a novel audio processing architecture, the Open Voice Brain Model (OVBM), improving detection accuracy for Alzheimer's (AD) longitudinal discrimination from spontaneous speech. We also outline the OVBM design methodology leading us to such architecture, which in general can incorporate multimodal biomarkers and target simultaneously several diseases and other AI tasks. Key in our methodology is the use of multiple biomarkers complementing each other, and when two of them uniquely identify different subjects in a target disease we say they are orthogonal. We illustrate the methodology by introducing 16 biomarkers, three of which are orthogonal, demonstrating simultaneous above state-of-the-art discrimination for apparently unrelated diseases such as AD and COVID-19. Inspired by research conducted at the MIT Center for Brain Minds and Machines, OVBM combines biomarker implementations of the four modules of intelligence: The brain OS chunks and overlaps audio samples and aggregates biomarker features from the sensory stream and cognitive core creating a multi-modal graph neural network of symbolic compositional models for the target task. We apply it to AD, achieving above state-of-the-art accuracy of 93.8% on raw audio, while extracting a subject saliency map that longitudinally tracks relative disease progression using multiple biomarkers, 16 in the reported AD task. The ultimate aim is to help medical practice by detecting onset and treatment impact so that intervention options can be longitudinally tested. Using the OBVM design methodology, we introduce a novel lung and respiratory tract biomarker created using 200,000+ cough samples to pre-train a model discriminating cough cultural origin. This cough dataset sets a new benchmark as the largest audio health dataset with 30,000+ subjects participating in April 2020, demonstrating for the first-time cough cultural bias.
Efficient and Generic Interactive Segmentation Framework to Correct Mispredictions during Clinical Evaluation of Medical Images
Aug 06, 2021
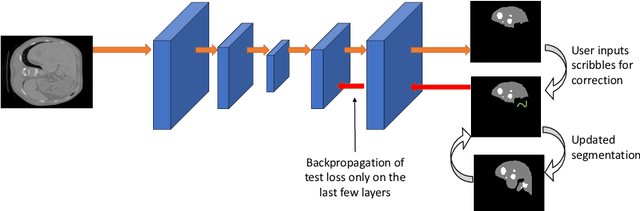
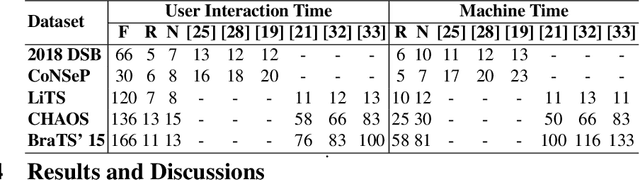

Semantic segmentation of medical images is an essential first step in computer-aided diagnosis systems for many applications. However, given many disparate imaging modalities and inherent variations in the patient data, it is difficult to consistently achieve high accuracy using modern deep neural networks (DNNs). This has led researchers to propose interactive image segmentation techniques where a medical expert can interactively correct the output of a DNN to the desired accuracy. However, these techniques often need separate training data with the associated human interactions, and do not generalize to various diseases, and types of medical images. In this paper, we suggest a novel conditional inference technique for DNNs which takes the intervention by a medical expert as test time constraints and performs inference conditioned upon these constraints. Our technique is generic can be used for medical images from any modality. Unlike other methods, our approach can correct multiple structures simultaneously and add structures missed at initial segmentation. We report an improvement of 13.3, 12.5, 17.8, 10.2, and 12.4 times in user annotation time than full human annotation for the nucleus, multiple cells, liver and tumor, organ, and brain segmentation respectively. We report a time saving of 2.8, 3.0, 1.9, 4.4, and 8.6 fold compared to other interactive segmentation techniques. Our method can be useful to clinicians for diagnosis and post-surgical follow-up with minimal intervention from the medical expert. The source-code and the detailed results are available here [1].
BRAIN2DEPTH: Lightweight CNN Model for Classification of Cognitive States from EEG Recordings
Jun 12, 2021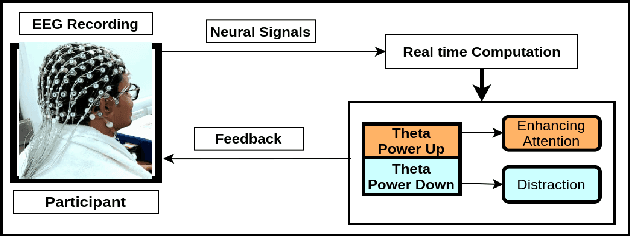

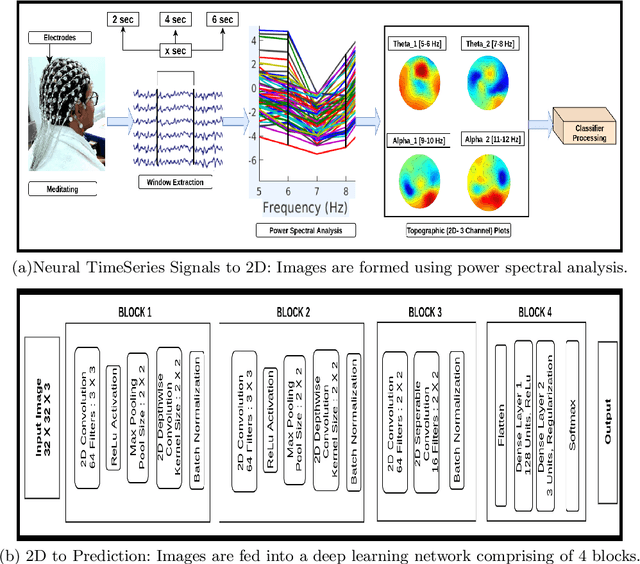
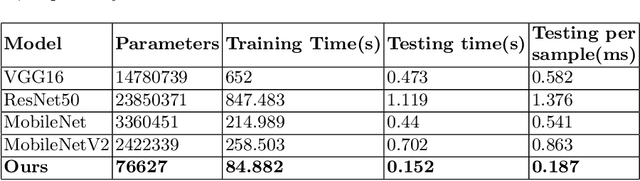
Several Convolutional Deep Learning models have been proposed to classify the cognitive states utilizing several neuro-imaging domains. These models have achieved significant results, but they are heavily designed with millions of parameters, which increases train and test time, making the model complex and less suitable for real-time analysis. This paper proposes a simple, lightweight CNN model to classify cognitive states from Electroencephalograph (EEG) recordings. We develop a novel pipeline to learn distinct cognitive representation consisting of two stages. The first stage is to generate the 2D spectral images from neural time series signals in a particular frequency band. Images are generated to preserve the relationship between the neighboring electrodes and the spectral property of the cognitive events. The second is to develop a time-efficient, computationally less loaded, and high-performing model. We design a network containing 4 blocks and major components include standard and depth-wise convolution for increasing the performance and followed by separable convolution to decrease the number of parameters which maintains the tradeoff between time and performance. We experiment on open access EEG meditation dataset comprising expert, nonexpert meditative, and control states. We compare performance with six commonly used machine learning classifiers and four state of the art deep learning models. We attain comparable performance utilizing less than 4\% of the parameters of other models. This model can be employed in a real-time computation environment such as neurofeedback.
MetroLoc: Metro Vehicle Mapping and Localization with LiDAR-Camera-Inertial Integration
Nov 01, 2021
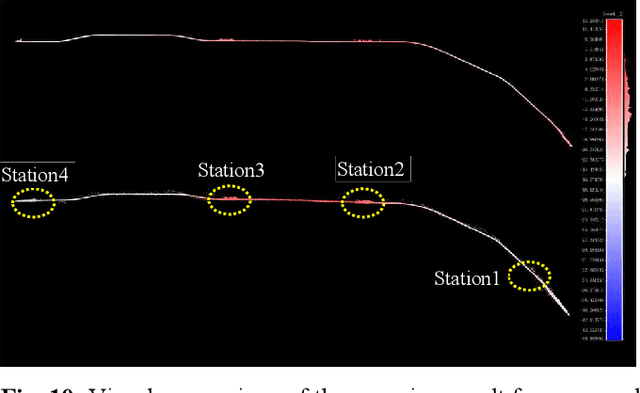
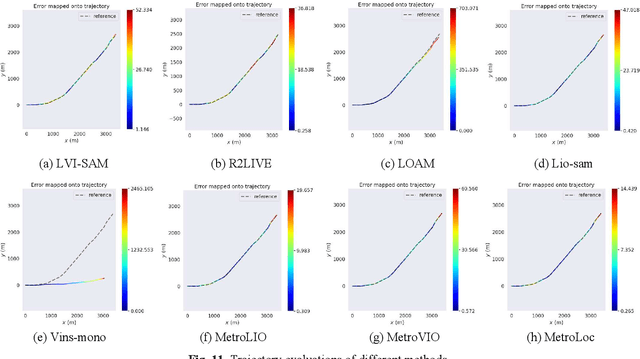

We propose an accurate and robust multi-modal sensor fusion framework, MetroLoc, towards one of the most extreme scenarios, the large-scale metro vehicle localization and mapping. MetroLoc is built atop an IMU-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, and inertial information with the convenience of loosely coupled methods. The proposed framework is composed of three submodules: IMU odometry, LiDAR-inertial odometry (LIO), and Visual-inertial odometry (VIO). The IMU is treated as the primary sensor, which achieves the observations from LIO and VIO to constrain the accelerometer and gyroscope biases. Compared to previous point-only LIO methods, our approach leverages more geometry information by introducing both line and plane features into motion estimation. The VIO also utilizes the environmental structure information by employing both lines and points. Our proposed method has been extensively tested in the long-during metro environments with a maintenance vehicle. Experimental results show the system more accurate and robust than the state-of-the-art approaches with real-time performance. Besides, we develop a series of Virtual Reality (VR) applications towards efficient, economical, and interactive rail vehicle state and trackside infrastructure monitoring, which has already been deployed to an outdoor testing railroad.
Multiple Object Trackers in OpenCV: A Benchmark
Oct 11, 2021
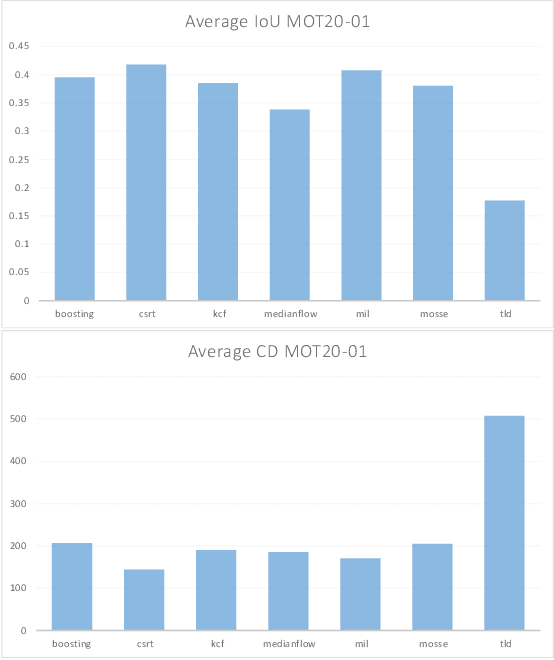
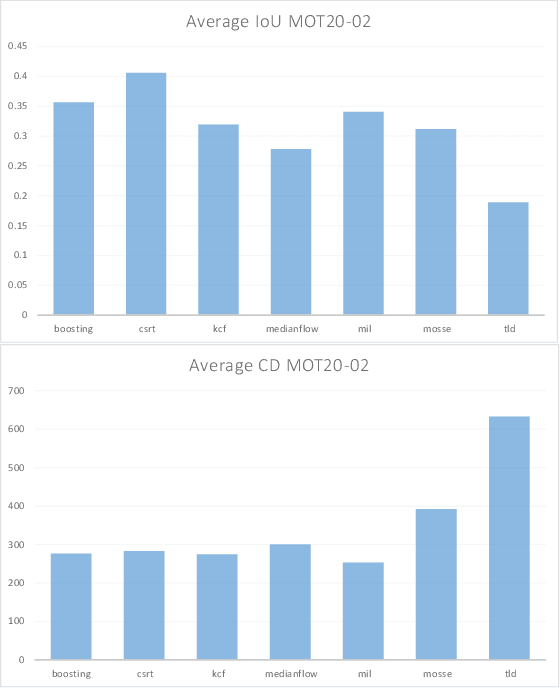
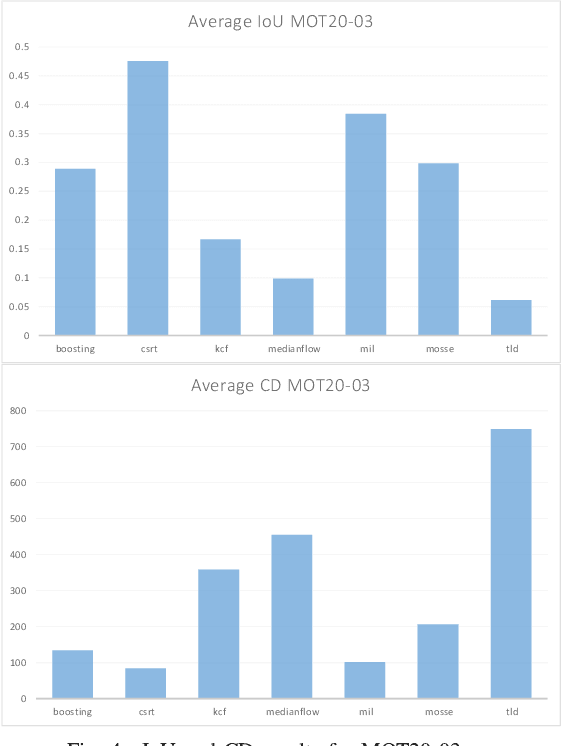
Object tracking is one of the most important and fundamental disciplines of Computer Vision. Many Computer Vision applications require specific object tracking capabilities, including autonomous and smart vehicles, video surveillance, medical treatments, and many others. The OpenCV as one of the most popular libraries for Computer Vision includes several hundred Computer Vision algorithms. Object tracking tasks in the library can be roughly clustered in single and multiple object trackers. The library is widely used for real-time applications, but there are a lot of unanswered questions such as when to use a specific tracker, how to evaluate its performance, and for what kind of objects will the tracker yield the best results? In this paper, we evaluate 7 trackers implemented in OpenCV against the MOT20 dataset. The results are shown based on Multiple Object Tracking Accuracy (MOTA) and Multiple Object Tracking Precision (MOTP) metrics.