 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Logic Programming: A Sequel
Nov 22, 2021
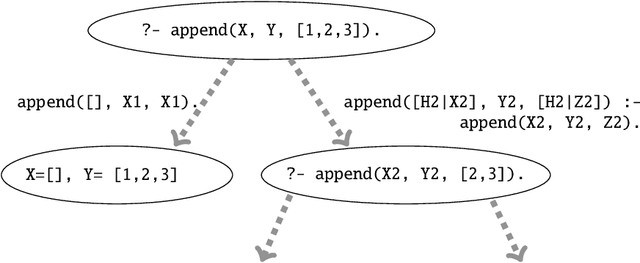
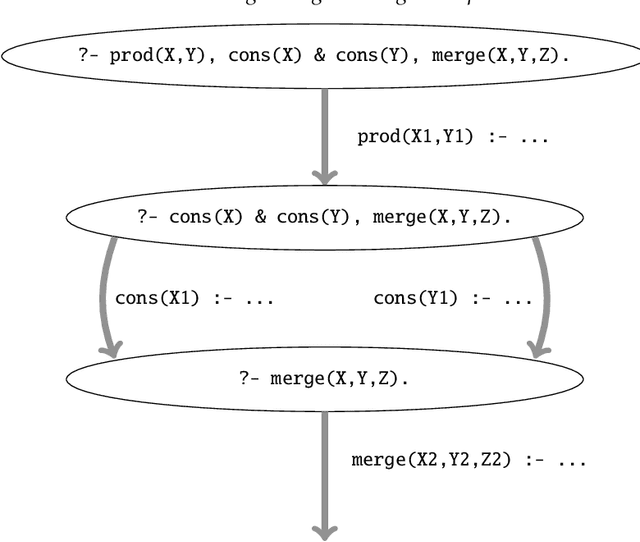
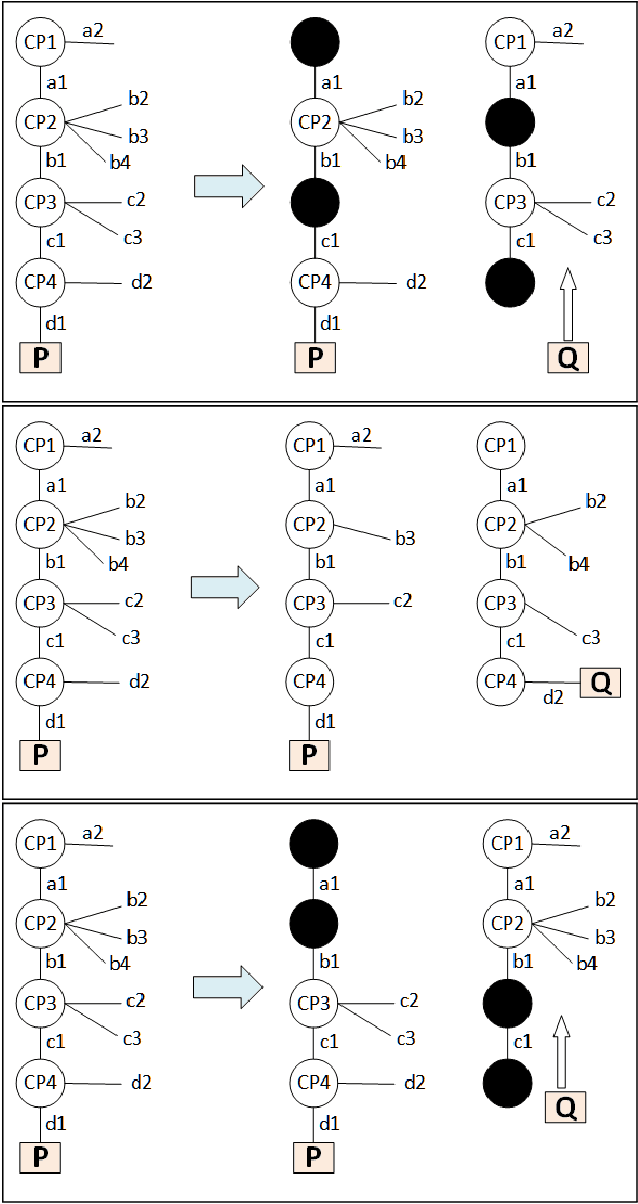
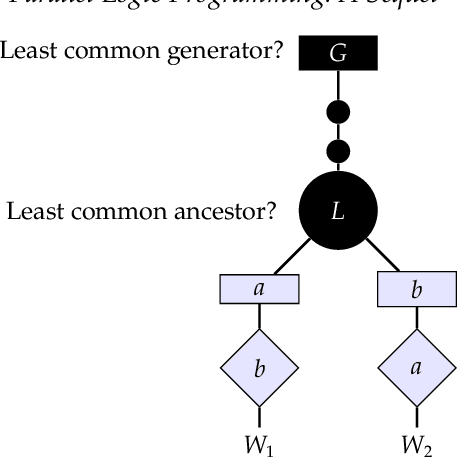
Multi-core and highly-connected architectures have become ubiquitous, and this has brought renewed interest in language-based approaches to the exploitation of parallelism. Since its inception, logic programming has been recognized as a programming paradigm with great potential for automated exploitation of parallelism. The comprehensive survey of the first twenty years of research in parallel logic programming, published in 2001, has served since as a fundamental reference to researchers and developers. The contents are quite valid today, but at the same time the field has continued evolving at a fast pace in the years that have followed. Many of these achievements and ongoing research have been driven by the rapid pace of technological innovation, that has led to advances such as very large clusters, the wide diffusion of multi-core processors, the game-changing role of general-purpose graphic processing units, and the ubiquitous adoption of cloud computing. This has been paralleled by significant advances within logic programming, such as tabling, more powerful static analysis and verification, the rapid growth of Answer Set Programming, and in general, more mature implementations and systems. This survey provides a review of the research in parallel logic programming covering the period since 2001, thus providing a natural continuation of the previous survey. The goal of the survey is to serve not only as a reference for researchers and developers of logic programming systems, but also as engaging reading for anyone interested in logic and as a useful source for researchers in parallel systems outside logic programming. Under consideration in Theory and Practice of Logic Programming (TPLP).
Medical Instrument Segmentation in 3D US by Hybrid Constrained Semi-Supervised Learning
Jul 30, 2021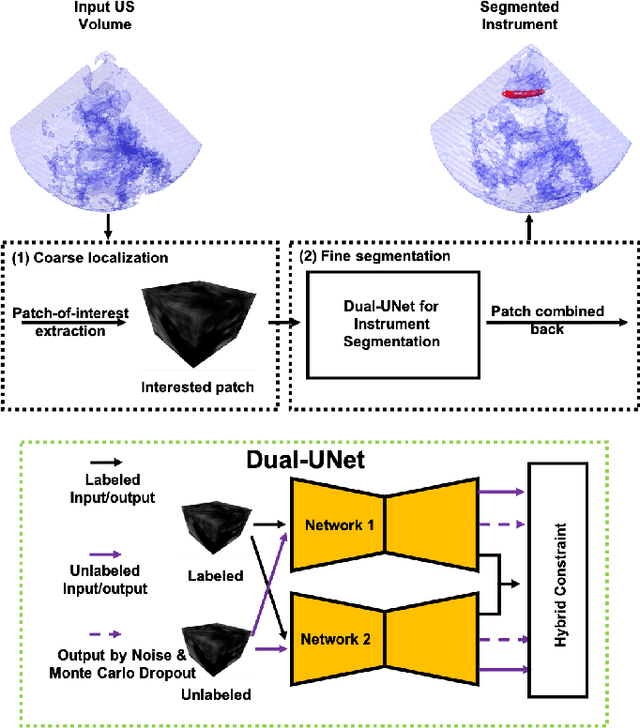

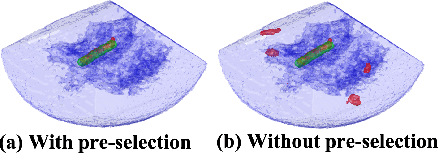
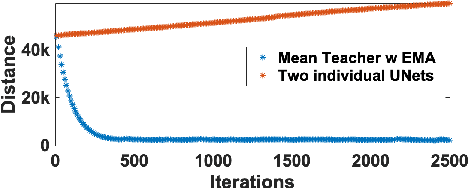
Medical instrument segmentation in 3D ultrasound is essential for image-guided intervention. However, to train a successful deep neural network for instrument segmentation, a large number of labeled images are required, which is expensive and time-consuming to obtain. In this article, we propose a semi-supervised learning (SSL) framework for instrument segmentation in 3D US, which requires much less annotation effort than the existing methods. To achieve the SSL learning, a Dual-UNet is proposed to segment the instrument. The Dual-UNet leverages unlabeled data using a novel hybrid loss function, consisting of uncertainty and contextual constraints. Specifically, the uncertainty constraints leverage the uncertainty estimation of the predictions of the UNet, and therefore improve the unlabeled information for SSL training. In addition, contextual constraints exploit the contextual information of the training images, which are used as the complementary information for voxel-wise uncertainty estimation. Extensive experiments on multiple ex-vivo and in-vivo datasets show that our proposed method achieves Dice score of about 68.6%-69.1% and the inference time of about 1 sec. per volume. These results are better than the state-of-the-art SSL methods and the inference time is comparable to the supervised approaches.
Rep Works in Speaker Verification
Oct 19, 2021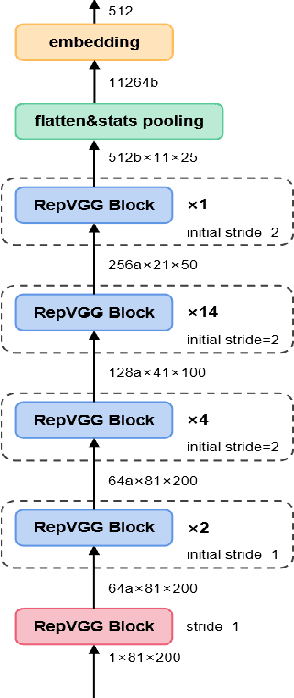
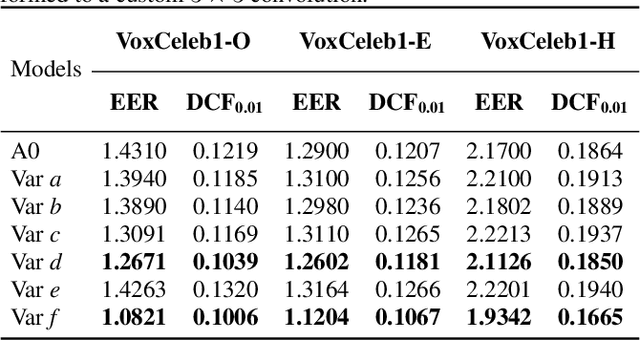
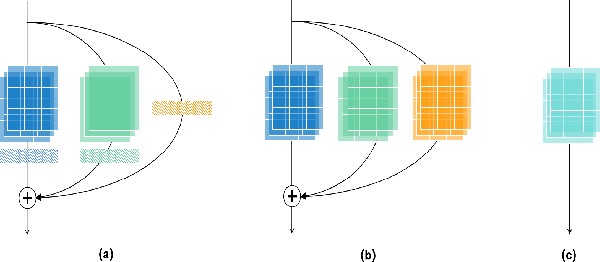
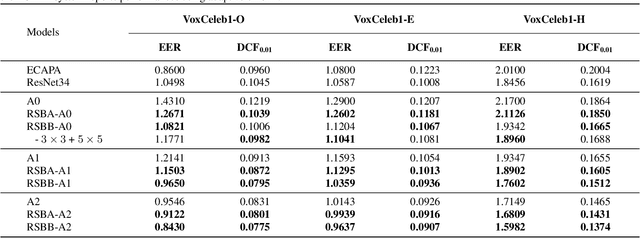
Multi-branch convolutional neural network architecture has raised lots of attention in speaker verification since the aggregation of multiple parallel branches can significantly improve performance. However, this design is not efficient enough during the inference time due to the increase of model parameters and extra operations. In this paper, we present a new multi-branch network architecture RepSPKNet that uses a re-parameterization technique. With this technique, our backbone model contains an efficient VGG-like inference state while its training state is a complicated multi-branch structure. We first introduce the specific structure of RepVGG into speaker verification and propose several variants of this structure. The performance is evaluated on VoxCeleb-based test sets. We demonstrate that both the branch diversity and the branch capacity play important roles in RepSPKNet designing. Our RepSPKNet achieves state-of-the-art performance with a 1.5982% EER and a 0.1374 minDCF on VoxCeleb1-H.
Swarm intelligence algorithms applied to Virtual Reference Feedback Tuning to increase controller robustness -- a one-shot technique
Nov 03, 2021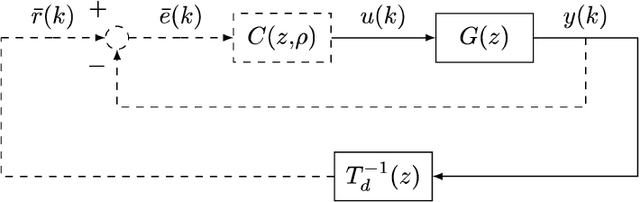

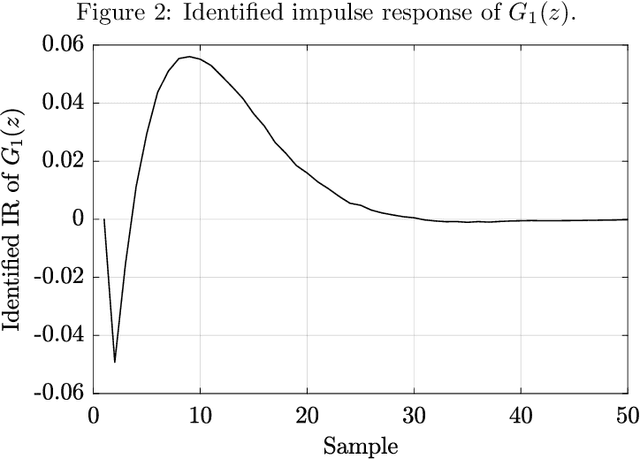

This work presents a data-driven one-shot method for increasing robustness of a discrete-time closed-loop system by changing the controller parameters using swarm intelligence algorithms. Four swarm intelligence algorithms - Particle Swarm Optimization (PSO), Artificial Bee Colony (ABC), Grey Wolf Optimization (GWO), and Improved Grey Wolf Optimization (I-GWO) - are described. Data-driven controller design is commented, focusing on the Virtual Reference Feedback Tuning (VRFT) algorithms. The estimation of the $\mathcal{H}_{\infty}$ norm of $S(z)$ via impulse response is presented. Two illustrative real-world based examples, regarding a Boost-like second order plant and a SEPIC-like fourth order plant, are tested for all commented swarm intelligence algorithms with the proposed method. Each algorithm at each case was run for 50 times, with 100 search agents, and maximum number of iterations limited to 100. For both examples, I-GWO presented the the best desired behavior, with the least number of outliers and no bad outlier in terms of fitness and $||S(z)||_{\infty}$ norm, as well as faster convergence, lowering the $||S(z)||_{\infty}$ norm of the plant from values greater than 2.0 to 1.8, still maintaining a low fitness value.
PI(t)D(t) Control and Motion Profiling for Omnidirectional Mobile Robots
Oct 19, 2021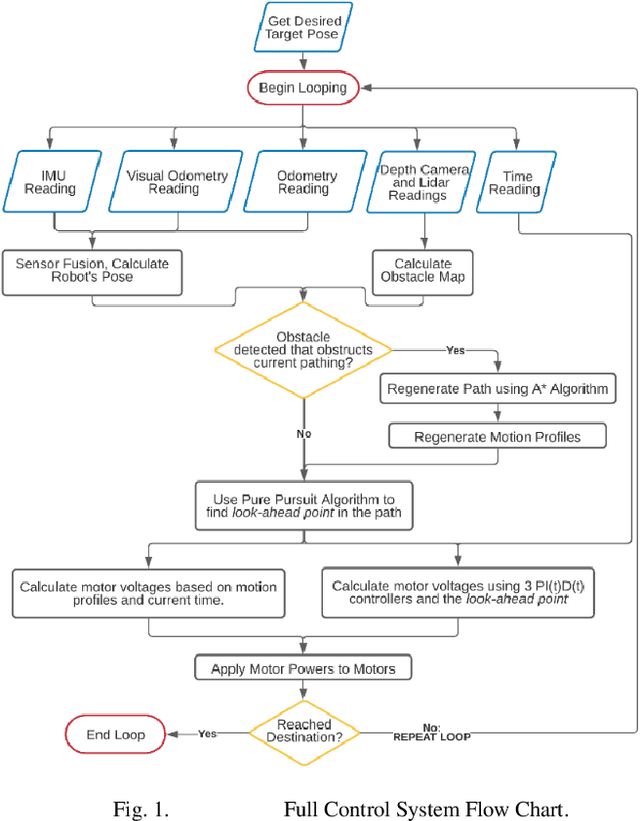

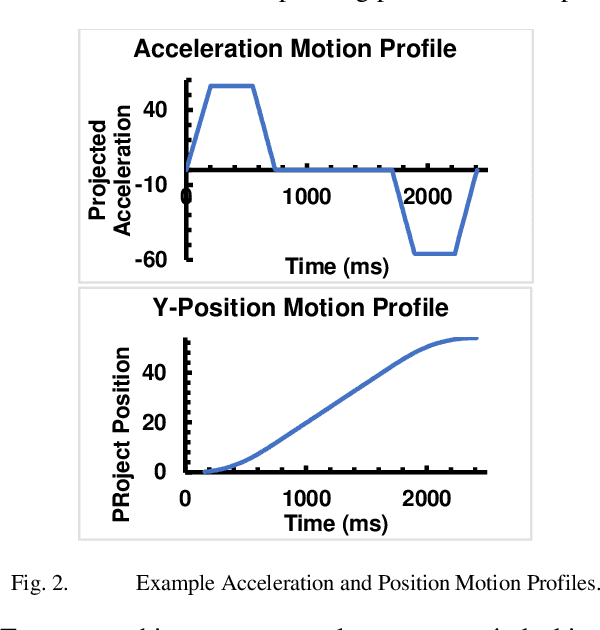
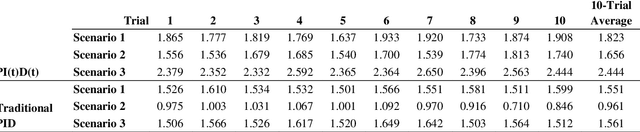
Recently, a trend is emerging toward human-servicing autonomous mobile robots, with diverse applications including delivery of supplies in hospitals, hotels, or labs where personnel are scarce, or reacting to indoor emergencies. However, existing autonomous mobile robot (AMR) motion is slow and inefficient, a foundational barrier to proliferation of human-servicing applications. This research has developed a motion control architecture that demonstrates the potential of several algorithms for increasing speed and efficiency. These include a novel PI(t)D(t) controller that sets integral and derivative gains as functions of time, and motion-profiling applied for holonomic motion. Resulting performance indicates potential for faster, more efficient AMRs, that maintain high levels of accuracy and repeatability. The hope is that this research can serve as a proof of concept for faster motion-control, to remove a key barrier to further use of human-servicing mobile robots.
Heuristical choice of SVM parameters
Nov 03, 2021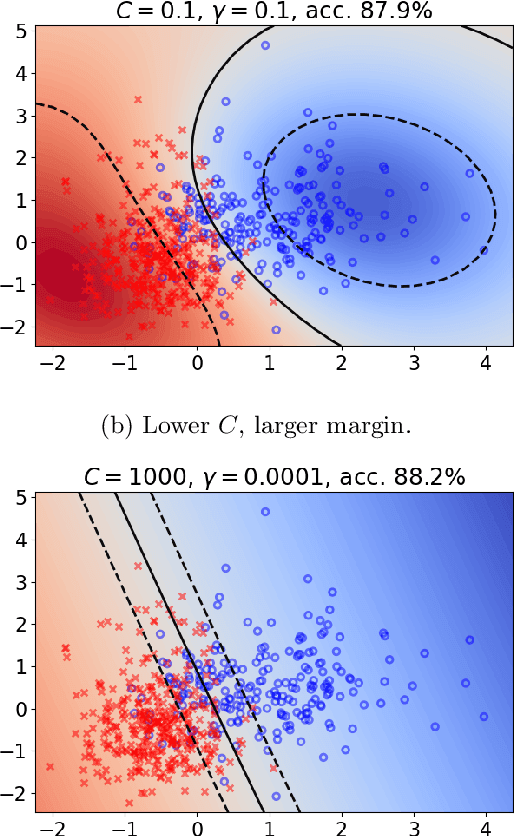
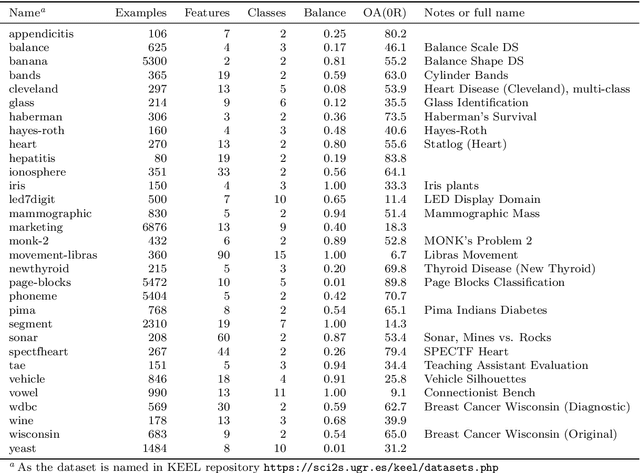
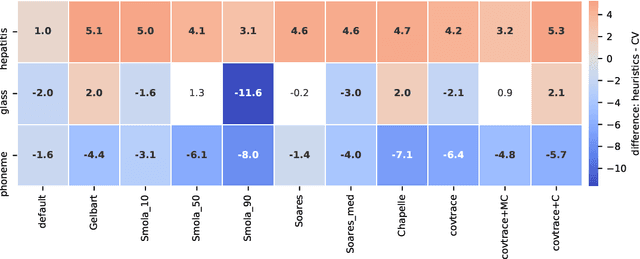
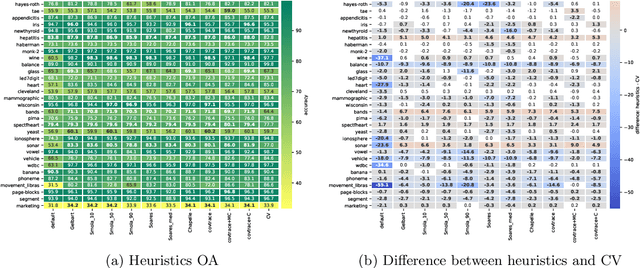
Support Vector Machine (SVM) is one of the most popular classification methods, and a de-facto reference for many Machine Learning approaches. Its performance is determined by parameter selection, which is usually achieved by a time-consuming grid search cross-validation procedure. There exist, however, several unsupervised heuristics that take advantage of the characteristics of the dataset for selecting parameters instead of using class label information. Unsupervised heuristics, while an order of magnitude faster, are scarcely used under the assumption that their results are significantly worse than those of grid search. To challenge that assumption we have conducted a wide study of various heuristics for SVM parameter selection on over thirty datasets, in both supervised and semi-supervised scenarios. In most cases, the cross-validation grid search did not achieve a significant advantage over the heuristics. In particular, heuristical parameter selection may be preferable for high dimensional and unbalanced datasets or when a small number of examples is available. Our results also show that using a heuristic to determine the starting point of further cross-validation does not yield significantly better results than the default start.
GOMP-FIT: Grasp-Optimized Motion Planning for Fast Inertial Transport
Oct 28, 2021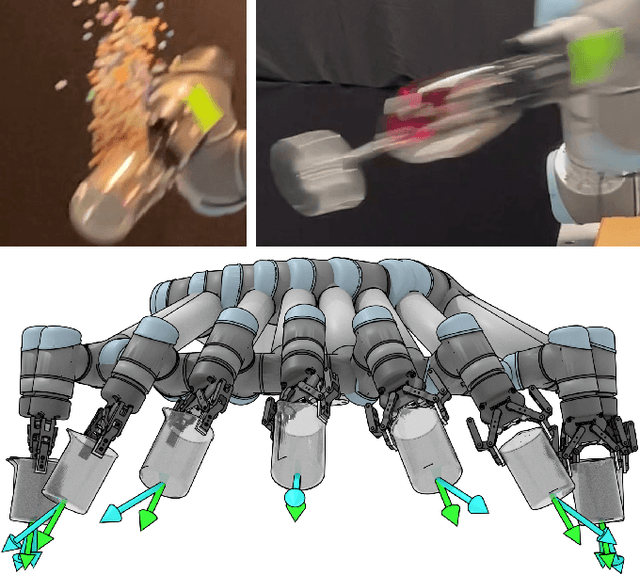
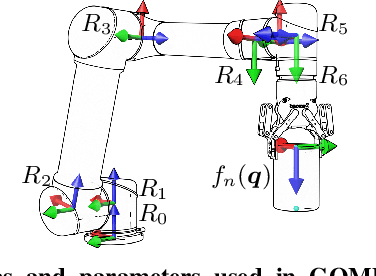


High-speed motions in pick-and-place operations are critical to making robots cost-effective in many automation scenarios, from warehouses and manufacturing to hospitals and homes. However, motions can be too fast -- such as when the object being transported has an open-top, is fragile, or both. One way to avoid spills or damage, is to move the arm slowly. We propose Grasp-Optimized Motion Planning for Fast Inertial Transport (GOMP-FIT), a time-optimizing motion planner based on our prior work, that includes constraints based on accelerations at the robot end-effector. With GOMP-FIT, a robot can perform high-speed motions that avoid obstacles and use inertial forces to its advantage. In experiments transporting open-top containers with varying tilt tolerances, whereas GOMP computes sub-second motions that spill up to 90% of the contents during transport, GOMP-FIT generates motions that spill 0% of contents while being slowed by as little as 0% when there are few obstacles, 30% when there are high obstacles and 45-degree tolerances, and 50% when there 15-degree tolerances and few obstacles.
Improved Feature Importance Computations for Tree Models: Shapley vs. Banzhaf
Aug 09, 2021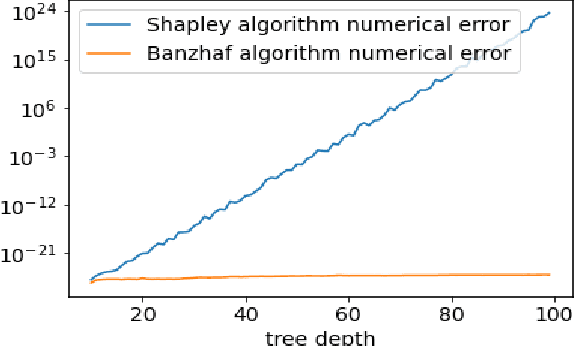
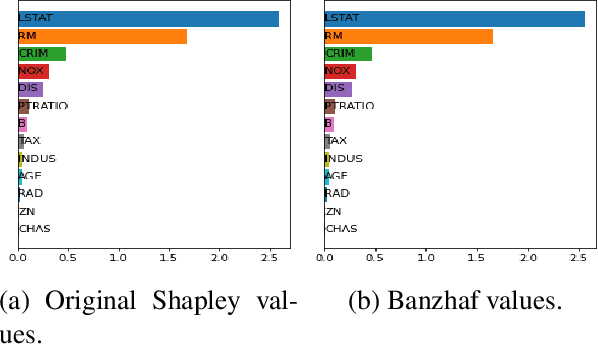
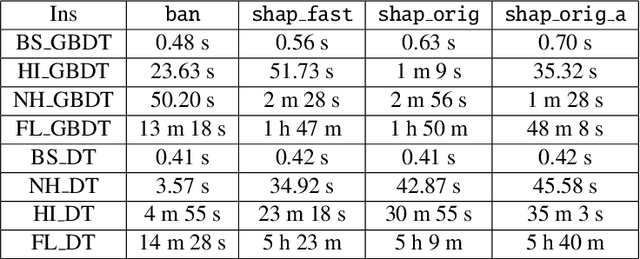
Shapley values are one of the main tools used to explain predictions of tree ensemble models. The main alternative to Shapley values are Banzhaf values that have not been understood equally well. In this paper we make a step towards filling this gap, providing both experimental and theoretical comparison of these model explanation methods. Surprisingly, we show that Banzhaf values offer several advantages over Shapley values while providing essentially the same explanations. We verify that Banzhaf values: (1) have a more intuitive interpretation, (2) allow for more efficient algorithms, and (3) are much more numerically robust. We provide an experimental evaluation of these theses. In particular, we show that on real world instances. Additionally, from a theoretical perspective we provide new and improved algorithm computing the same Shapley value based explanations as the algorithm of Lundberg et al. [Nat. Mach. Intell. 2020]. Our algorithm runs in $O(TLD+n)$ time, whereas the previous algorithm had $O(TLD^2+n)$ running time bound. Here, $T$ is the number of trees, $L$ is the maximum number of leaves in a tree, and $D$ denotes the maximum depth of a tree in the ensemble. Using the computational techniques developed for Shapley values we deliver an optimal $O(TL+n)$ time algorithm for computing Banzhaf values based explanations. In our experiments these algorithms give running times smaller even by an order of magnitude.
RAANet: Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Density Level Estimation
Nov 18, 2021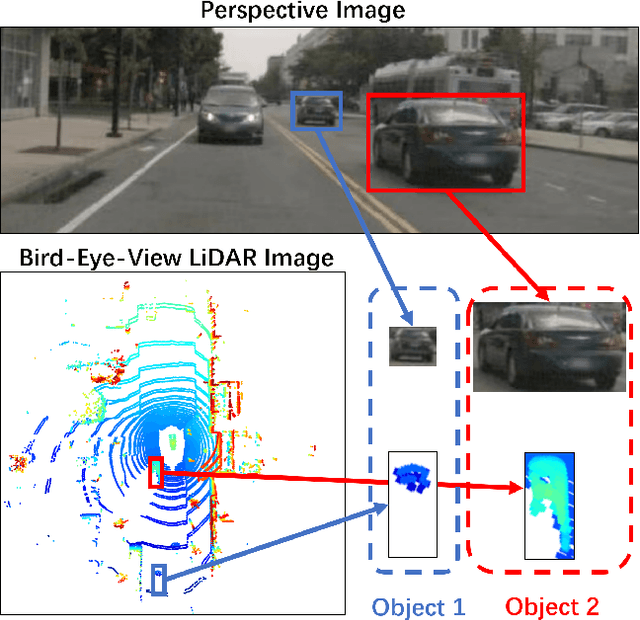
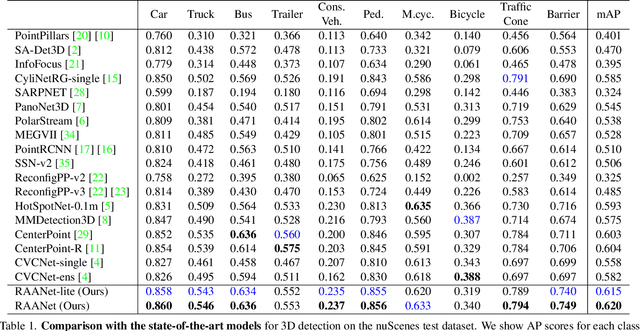
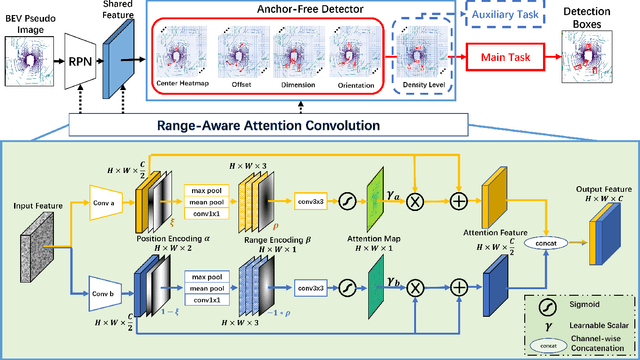

3D object detection from LiDAR data for autonomous driving has been making remarkable strides in recent years. Among the state-of-the-art methodologies, encoding point clouds into a bird's-eye view (BEV) has been demonstrated to be both effective and efficient. Different from perspective views, BEV preserves rich spatial and distance information between objects; and while farther objects of the same type do not appear smaller in the BEV, they contain sparser point cloud features. This fact weakens BEV feature extraction using shared-weight convolutional neural networks. In order to address this challenge, we propose Range-Aware Attention Network (RAANet), which extracts more powerful BEV features and generates superior 3D object detections. The range-aware attention (RAA) convolutions significantly improve feature extraction for near as well as far objects. Moreover, we propose a novel auxiliary loss for density estimation to further enhance the detection accuracy of RAANet for occluded objects. It is worth to note that our proposed RAA convolution is lightweight and compatible to be integrated into any CNN architecture used for the BEV detection. Extensive experiments on the nuScenes dataset demonstrate that our proposed approach outperforms the state-of-the-art methods for LiDAR-based 3D object detection, with real-time inference speed of 16 Hz for the full version and 22 Hz for the lite version. The code is publicly available at an anonymous Github repository https://github.com/anonymous0522/RAAN.
Satellite Image Time Series Classification with Pixel-Set Encoders and Temporal Self-Attention
Nov 18, 2019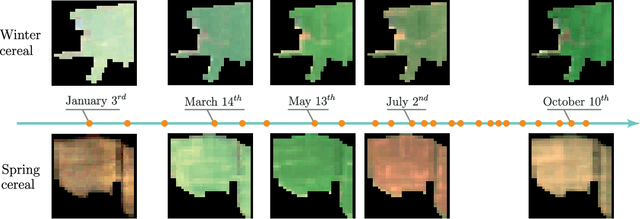

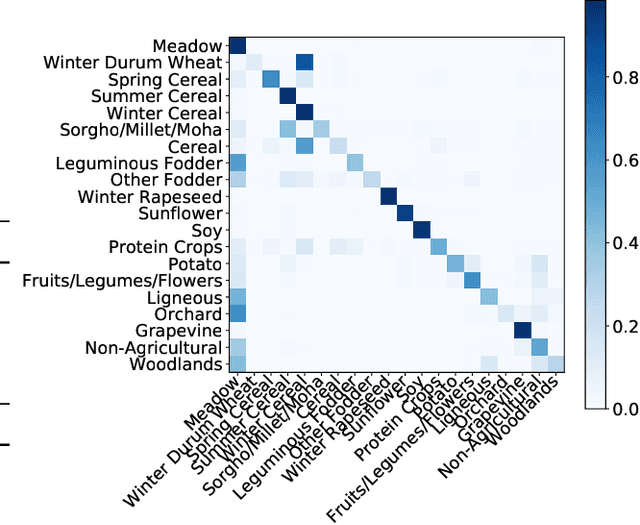

Satellite image time series, bolstered by their growing availability, are at the forefront of an extensive effort towards automated Earth monitoring by international institutions. In particular, large-scale control of agricultural parcels is an issue of major political and economic importance. In this regard, hybrid convolutional-recurrent neural architectures have shown promising results for the automated classification of satellite image time series.We propose an alternative approach in which the convolutional layers are advantageously replaced with encoders operating on unordered sets of pixels to exploit the typically coarse resolution of publicly available satellite images. We also propose to extract temporal features using a bespoke neural architecture based on self-attention instead of recurrent networks. We demonstrate experimentally that our method not only outperforms previous state-of-the-art approaches in terms of precision, but also significantly decreases processing time and memory requirements. Lastly, we release a large open-access annotated dataset as a benchmark for future work on satellite image time series.