 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MetroLoc: Metro Vehicle Mapping and Localization with LiDAR-Camera-Inertial Integration
Nov 01, 2021

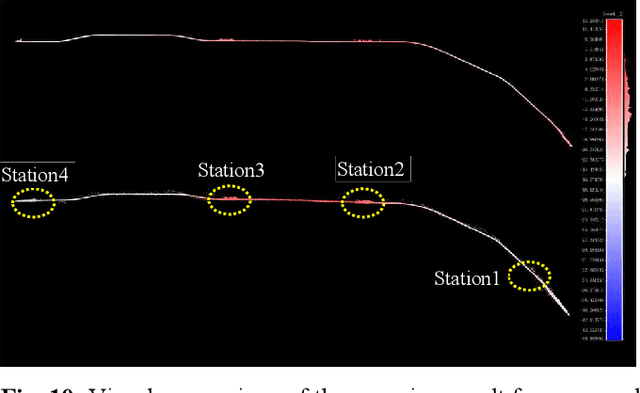
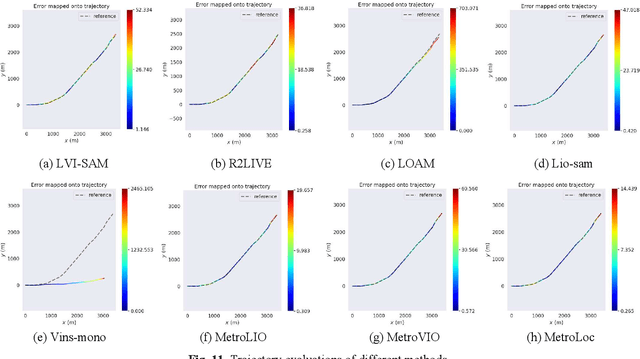

We propose an accurate and robust multi-modal sensor fusion framework, MetroLoc, towards one of the most extreme scenarios, the large-scale metro vehicle localization and mapping. MetroLoc is built atop an IMU-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, and inertial information with the convenience of loosely coupled methods. The proposed framework is composed of three submodules: IMU odometry, LiDAR-inertial odometry (LIO), and Visual-inertial odometry (VIO). The IMU is treated as the primary sensor, which achieves the observations from LIO and VIO to constrain the accelerometer and gyroscope biases. Compared to previous point-only LIO methods, our approach leverages more geometry information by introducing both line and plane features into motion estimation. The VIO also utilizes the environmental structure information by employing both lines and points. Our proposed method has been extensively tested in the long-during metro environments with a maintenance vehicle. Experimental results show the system more accurate and robust than the state-of-the-art approaches with real-time performance. Besides, we develop a series of Virtual Reality (VR) applications towards efficient, economical, and interactive rail vehicle state and trackside infrastructure monitoring, which has already been deployed to an outdoor testing railroad.
What a million Indian farmers say?: A crowdsourcing-based method for pest surveillance
Aug 07, 2021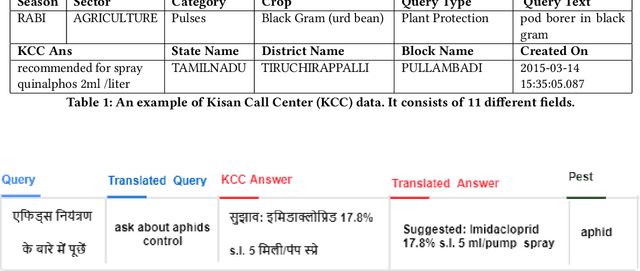
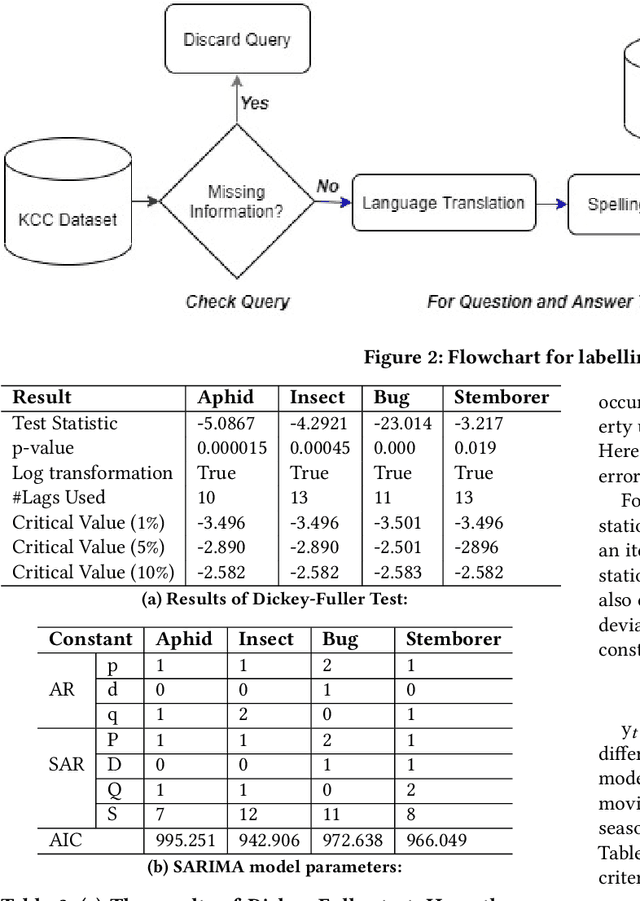
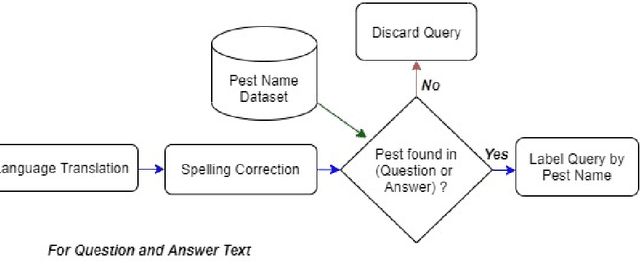
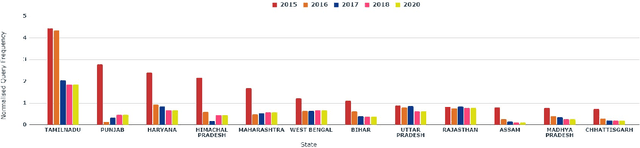
Many different technologies are used to detect pests in the crops, such as manual sampling, sensors, and radar. However, these methods have scalability issues as they fail to cover large areas, are uneconomical and complex. This paper proposes a crowdsourced based method utilising the real-time farmer queries gathered over telephones for pest surveillance. We developed data-driven strategies by aggregating and analyzing historical data to find patterns and get future insights into pest occurrence. We showed that it can be an accurate and economical method for pest surveillance capable of enveloping a large area with high spatio-temporal granularity. Forecasting the pest population will help farmers in making informed decisions at the right time. This will also help the government and policymakers to make the necessary preparations as and when required and may also ensure food security.
Single-Modal Entropy based Active Learning for Visual Question Answering
Oct 21, 2021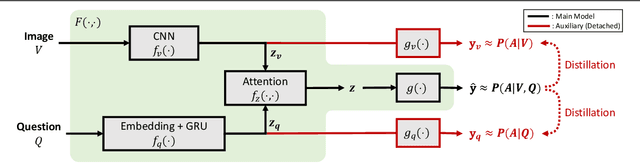
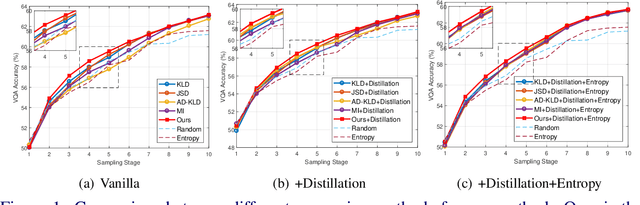
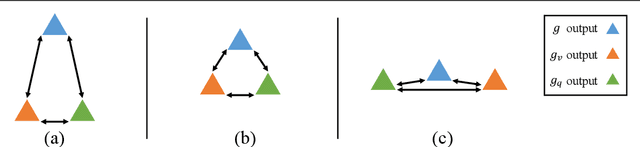
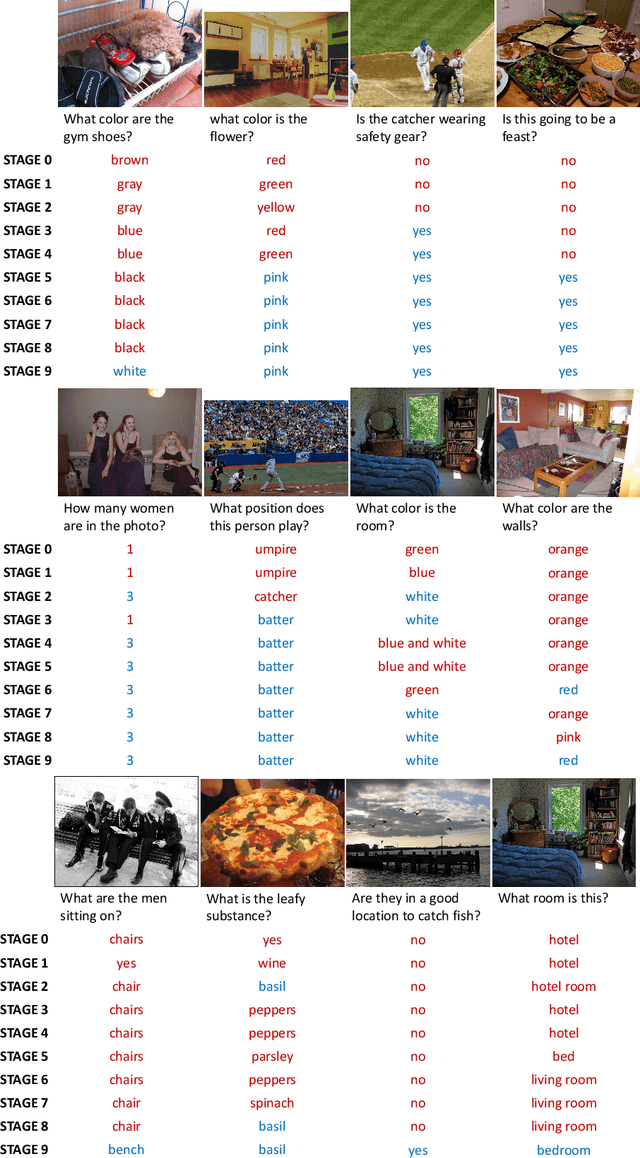
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
An Explanation of In-context Learning as Implicit Bayesian Inference
Nov 14, 2021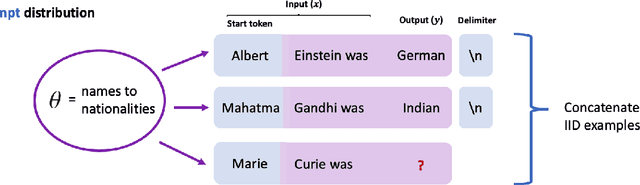
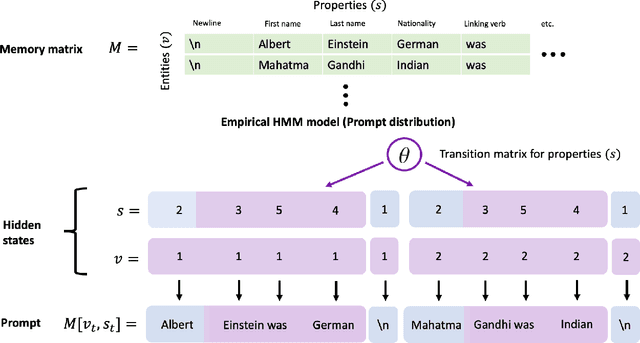
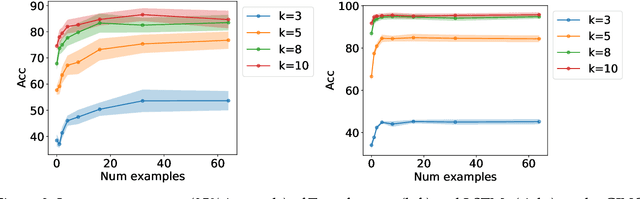

Large pretrained language models such as GPT-3 have the surprising ability to do in-context learning, where the model learns to do a downstream task simply by conditioning on a prompt consisting of input-output examples. Without being explicitly pretrained to do so, the language model learns from these examples during its forward pass without parameter updates on "out-of-distribution" prompts. Thus, it is unclear what mechanism enables in-context learning. In this paper, we study the role of the pretraining distribution on the emergence of in-context learning under a mathematical setting where the pretraining texts have long-range coherence. Here, language model pretraining requires inferring a latent document-level concept from the conditioning text to generate coherent next tokens. At test time, this mechanism enables in-context learning by inferring the shared latent concept between prompt examples and applying it to make a prediction on the test example. Concretely, we prove that in-context learning occurs implicitly via Bayesian inference of the latent concept when the pretraining distribution is a mixture of HMMs. This can occur despite the distribution mismatch between prompts and pretraining data. In contrast to messy large-scale pretraining datasets for in-context learning in natural language, we generate a family of small-scale synthetic datasets (GINC) where Transformer and LSTM language models both exhibit in-context learning. Beyond the theory which focuses on the effect of the pretraining distribution, we empirically find that scaling model size improves in-context accuracy even when the pretraining loss is the same.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021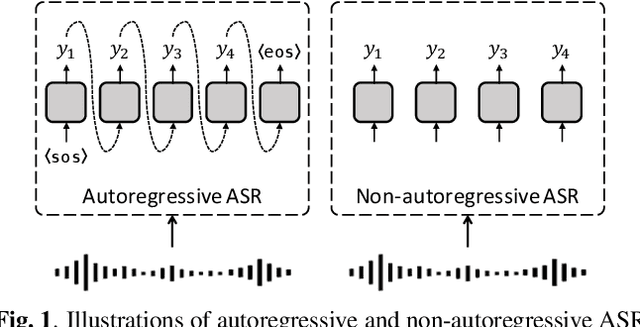

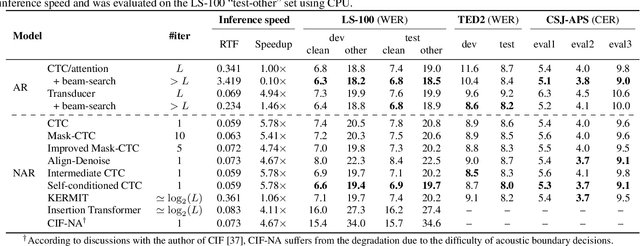
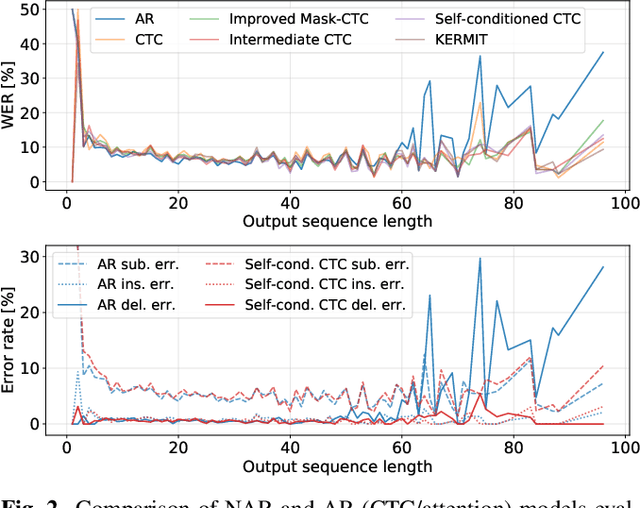
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Evaluation on Energy Efficiency of UE in UL Cell-Free Massive MIMO System With Power Control Methods
Oct 04, 2021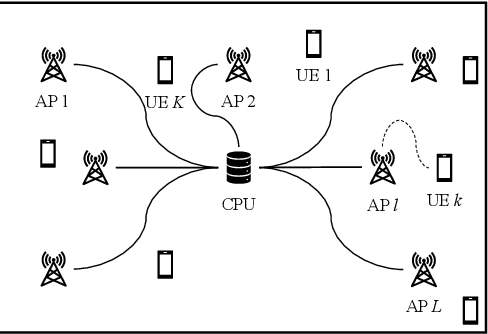
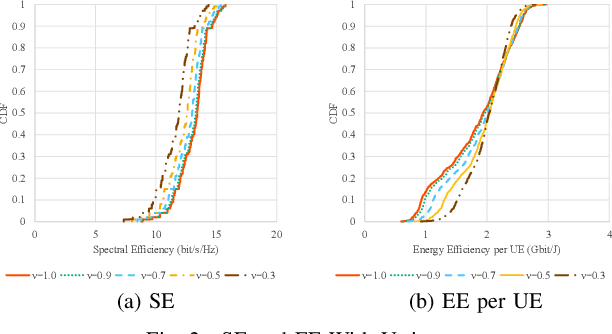
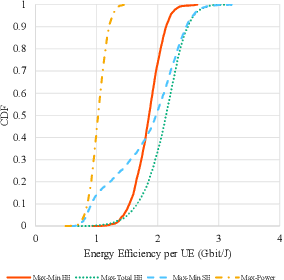
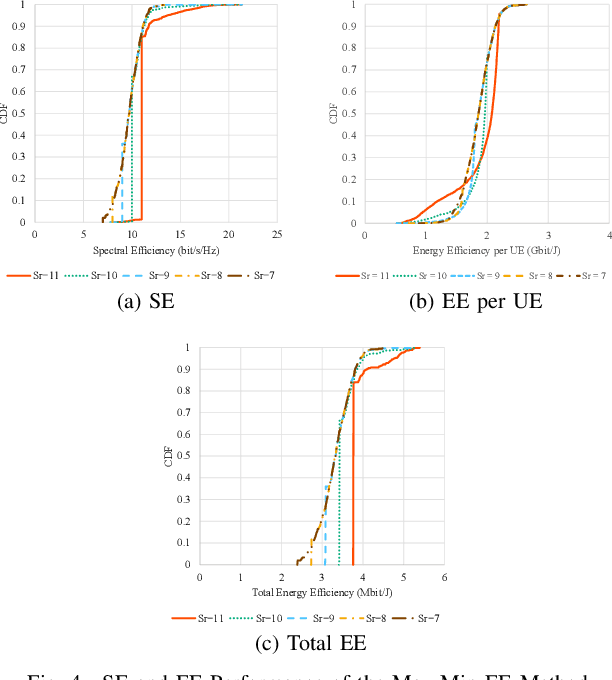
Cell-free massive multiple-input multiple-output (CF mMIMO) systems are expected to provide faster and more robust connections to user equipments (UEs) by cooperation of a massive number of distributed access points, and to be one of the key technologies for beyond 5G (B5G). In B5G, energy efficiency (EE) is one of the most important key indicators because various kinds of devices connect to the network and communicate with each other. While previously proposed transmit power control methods in CF mMIMO systems have aimed to maximize spectral efficiency or total EE, we evaluate in this paper a different approach for maximizing the minimum EE among all UEs. We show that this algorithm can provide the optimum solution in polynomial time, and demonstrate with simulations the improved minimum EE compared to conventional methods.
Biologically Plausible Learning Rules for Perceptual Systems that Maximize Mutual Information
Sep 07, 2021It is widely believed that the perceptual system of an organism is optimized for the properties of the environment to which it is exposed. A specific instance of this principle known as the Infomax principle holds that the purpose of early perceptual processing is to maximize the mutual information between the neural coding and the incoming sensory signal. In this article, we show a model to implement this principle accurately with spatio-temporal local, spike-based, and continuous-time learning rules.
Physics-Informed Neural Operator for Learning Partial Differential Equations
Nov 06, 2021
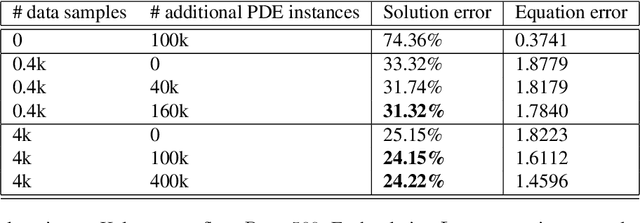
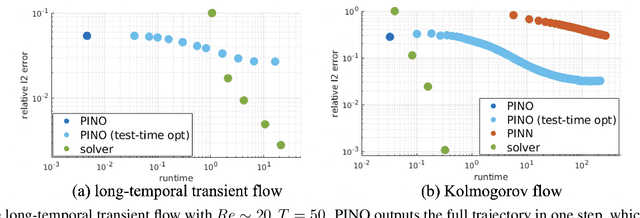

Machine learning methods have recently shown promise in solving partial differential equations (PDEs). They can be classified into two broad categories: approximating the solution function and learning the solution operator. The Physics-Informed Neural Network (PINN) is an example of the former while the Fourier neural operator (FNO) is an example of the latter. Both these approaches have shortcomings. The optimization in PINN is challenging and prone to failure, especially on multi-scale dynamic systems. FNO does not suffer from this optimization issue since it carries out supervised learning on a given dataset, but obtaining such data may be too expensive or infeasible. In this work, we propose the physics-informed neural operator (PINO), where we combine the operating-learning and function-optimization frameworks. This integrated approach improves convergence rates and accuracy over both PINN and FNO models. In the operator-learning phase, PINO learns the solution operator over multiple instances of the parametric PDE family. In the test-time optimization phase, PINO optimizes the pre-trained operator ansatz for the querying instance of the PDE. Experiments show PINO outperforms previous ML methods on many popular PDE families while retaining the extraordinary speed-up of FNO compared to solvers. In particular, PINO accurately solves challenging long temporal transient flows and Kolmogorov flows where other baseline ML methods fail to converge.
DICoE@FinSim-3: Financial Hypernym Detection using Augmented Terms and Distance-based Features
Sep 30, 2021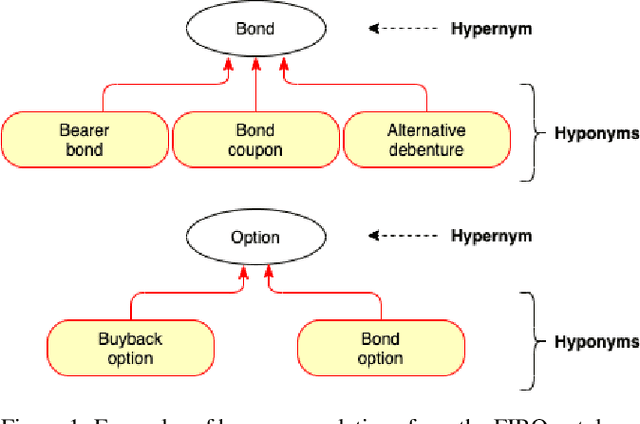
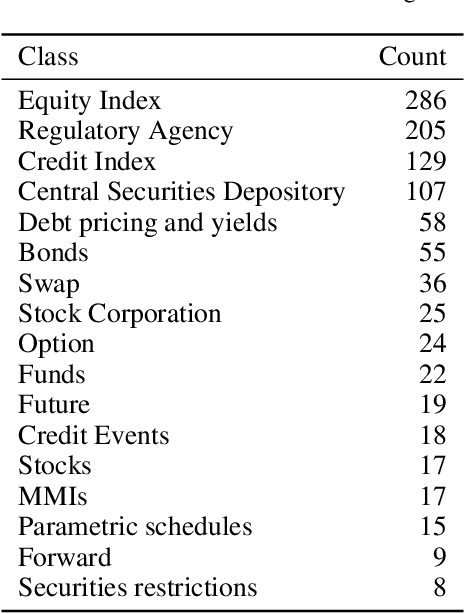
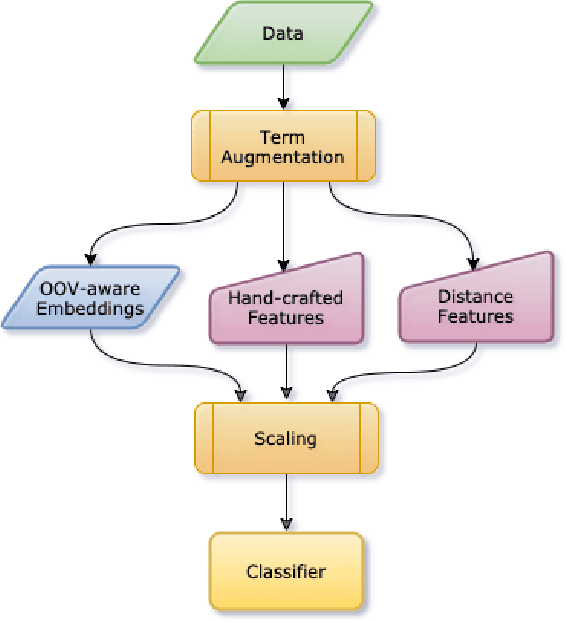
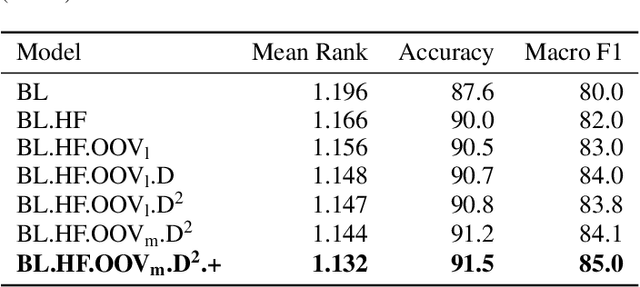
We present the submission of team DICoE for FinSim-3, the 3rd Shared Task on Learning Semantic Similarities for the Financial Domain. The task provides a set of terms in the financial domain and requires to classify them into the most relevant hypernym from a financial ontology. After augmenting the terms with their Investopedia definitions, our system employs a Logistic Regression classifier over financial word embeddings and a mix of hand-crafted and distance-based features. Also, for the first time in this task, we employ different replacement methods for out-of-vocabulary terms, leading to improved performance. Finally, we have also experimented with word representations generated from various financial corpora. Our best-performing submission ranked 4th on the task's leaderboard.
A distributed, plug-n-play algorithm for multi-robot applications with a priori non-computable objective functions
Nov 14, 2021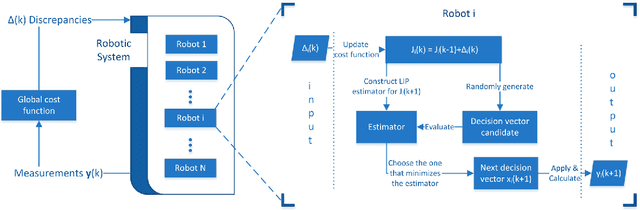

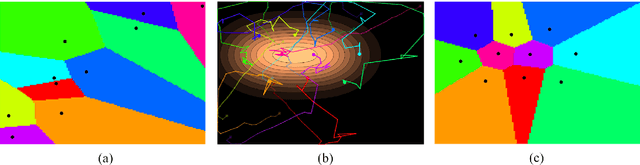
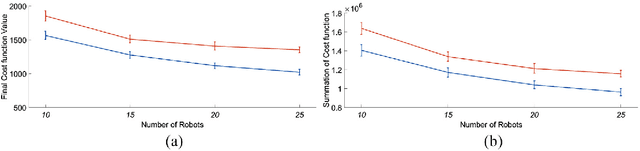
This paper presents a distributed algorithm applicable to a wide range of practical multi-robot applications. In such multi-robot applications, the user-defined objectives of the mission can be cast as a general optimization problem, without explicit guidelines of the subtasks per different robot. Owing to the unknown environment, unknown robot dynamics, sensor nonlinearities, etc., the analytic form of the optimization cost function is not available a priori. Therefore, standard gradient-descent-like algorithms are not applicable to these problems. To tackle this, we introduce a new algorithm that carefully designs each robot's subcost function, the optimization of which can accomplish the overall team objective. Upon this transformation, we propose a distributed methodology based on the cognitive-based adaptive optimization (CAO) algorithm, that is able to approximate the evolution of each robot's cost function and to adequately optimize its decision variables (robot actions). The latter can be achieved by online learning only the problem-specific characteristics that affect the accomplishment of mission objectives. The overall, low-complexity algorithm can straightforwardly incorporate any kind of operational constraint, is fault tolerant, and can appropriately tackle time-varying cost functions. A cornerstone of this approach is that it shares the same convergence characteristics as those of block coordinate descent algorithms. The proposed algorithm is evaluated in three heterogeneous simulation set-ups under multiple scenarios, against both general-purpose and problem-specific algorithms. Source code is available at \url{https://github.com/athakapo/A-distributed-plug-n-play-algorithm-for-multi-robot-applications}.