 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improvement of Flood Extent Representation with Remote Sensing Data and Data Assimilation Applied to Hydrodynamic Numerical Models
Sep 17, 2021
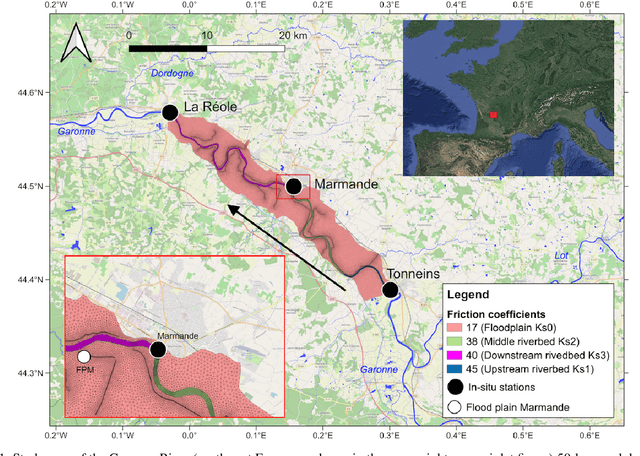
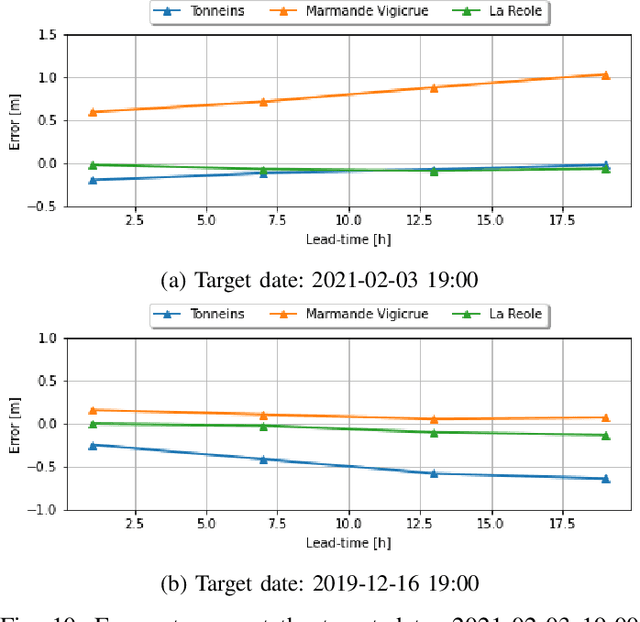
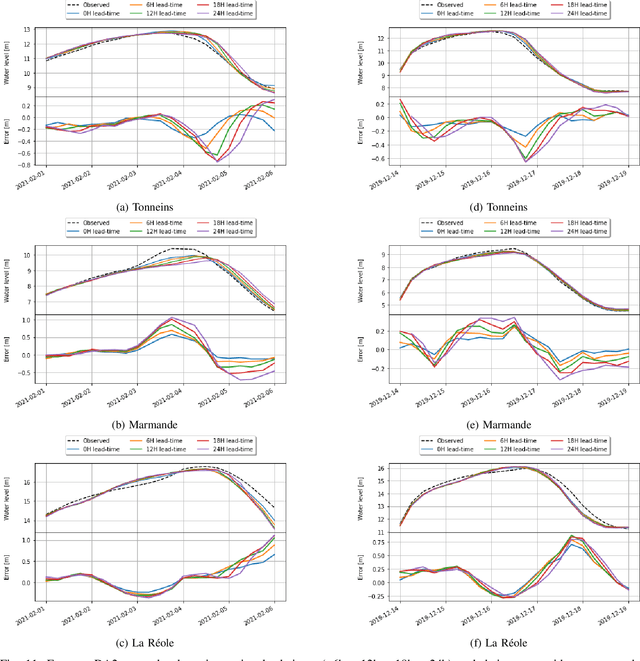
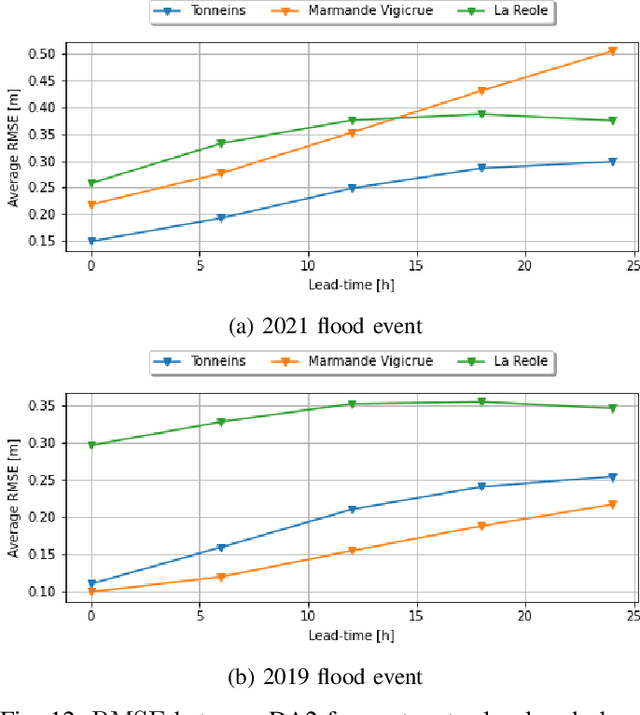
Flood simulation and forecast capability have been greatly improved thanks to advances in data assimilation. Such an approach combines in-situ gauge measurements with numerical hydrodynamic models to correct the hydraulic states and reduce the uncertainties in the model parameters. However, these methods depend strongly on the availability and quality of observations, thus necessitating other data sources to improve the flood simulation and forecast performances. Using Sentinel-1 images, a flood extent mapping method was carried out by applying a Random Forest algorithm trained on past flood events using manually delineated flood maps. The study area concerns a 50-km reach of the Garonne Marmandaise catchment. Two recent flood events are simulated in analysis and forecast modes, with a +24h lead time. This study demonstrates the merits of using SAR-derived flood extent maps to validate and improve the forecast results based on hydrodynamic numerical models with Telemac2D-EnKF. Quantitative 1D and 2D metrics were computed to assess water level time-series and flood extents between the simulations and observations. It was shown that the free run experiment without DA under-estimates flooding. On the other hand, the validation of DA results with respect to independent SAR-derived flood extent allows to diagnose a model-observation bias that leads to over-flooding. Once this bias is taken into account, DA provides a sequential correction of area-based friction coefficients and inflow discharge, yielding a better flood extent representation. This study paves the way towards a reliable solution for flood forecasting over poorly gauged catchments, thanks to available remote sensing datasets.
FedAdapt: Adaptive Offloading for IoT Devices in Federated Learning
Jul 09, 2021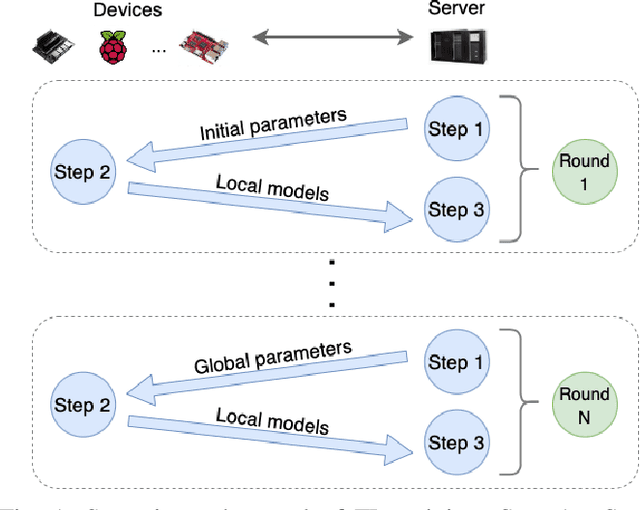
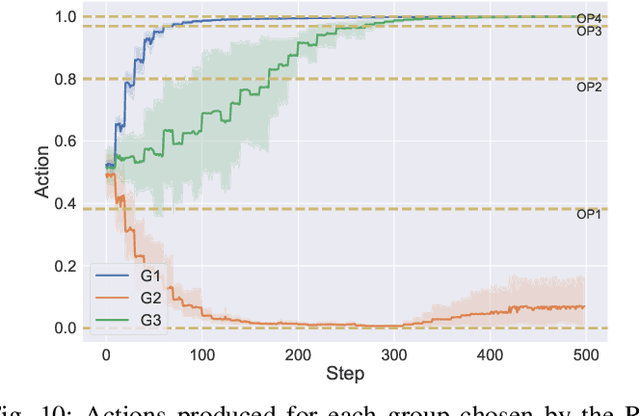
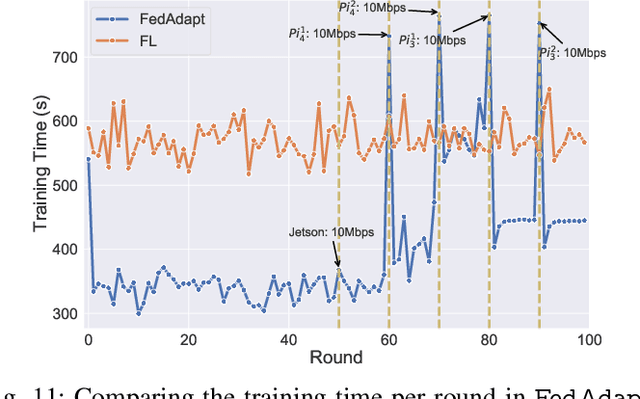
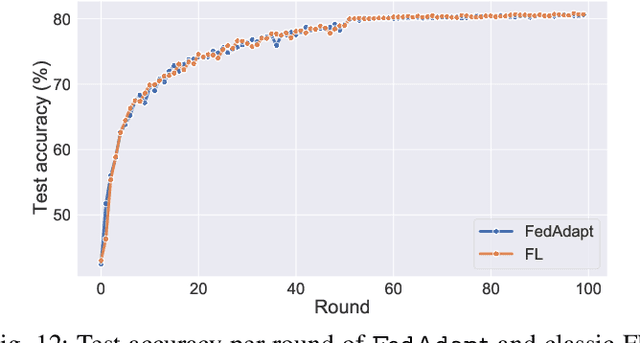
Applying Federated Learning (FL) on Internet-of-Things devices is necessitated by the large volumes of data they produce and growing concerns of data privacy. However, there are three challenges that need to be addressed to make FL efficient: (i) execute on devices with limited computational capabilities, (ii) account for stragglers due to computational heterogeneity of devices, and (iii) adapt to the changing network bandwidths. This paper presents FedAdapt, an adaptive offloading FL framework to mitigate the aforementioned challenges. FedAdapt accelerates local training in computationally constrained devices by leveraging layer offloading of deep neural networks (DNNs) to servers. Further, FedAdapt adopts reinforcement learning-based optimization and clustering to adaptively identify which layers of the DNN should be offloaded for each individual device on to a server to tackle the challenges of computational heterogeneity and changing network bandwidth. Experimental studies are carried out on a lab-based testbed comprising five IoT devices. By offloading a DNN from the device to the server FedAdapt reduces the training time of a typical IoT device by over half compared to classic FL. The training time of extreme stragglers and the overall training time can be reduced by up to 57%. Furthermore, with changing network bandwidth, FedAdapt is demonstrated to reduce the training time by up to 40% when compared to classic FL, without sacrificing accuracy. FedAdapt can be downloaded from https://github.com/qub-blesson/FedAdapt.
Containerized Distributed Value-Based Multi-Agent Reinforcement Learning
Oct 15, 2021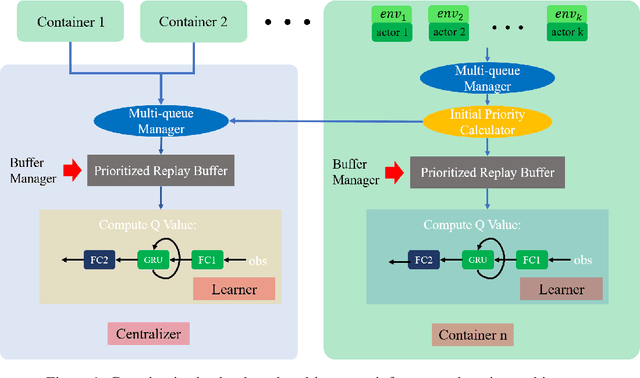
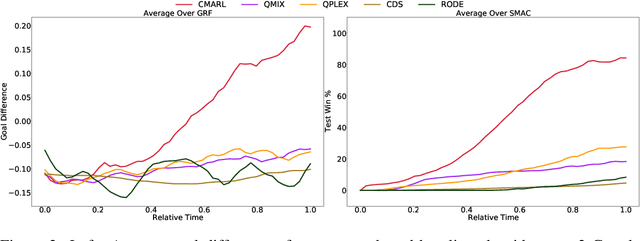
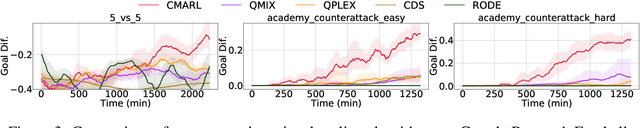
Multi-agent reinforcement learning tasks put a high demand on the volume of training samples. Different from its single-agent counterpart, distributed value-based multi-agent reinforcement learning faces the unique challenges of demanding data transfer, inter-process communication management, and high requirement of exploration. We propose a containerized learning framework to solve these problems. We pack several environment instances, a local learner and buffer, and a carefully designed multi-queue manager which avoids blocking into a container. Local policies of each container are encouraged to be as diverse as possible, and only trajectories with highest priority are sent to a global learner. In this way, we achieve a scalable, time-efficient, and diverse distributed MARL learning framework with high system throughput. To own knowledge, our method is the first to solve the challenging Google Research Football full game $5\_v\_5$. On the StarCraft II micromanagement benchmark, our method gets $4$-$18\times$ better results compared to state-of-the-art non-distributed MARL algorithms.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021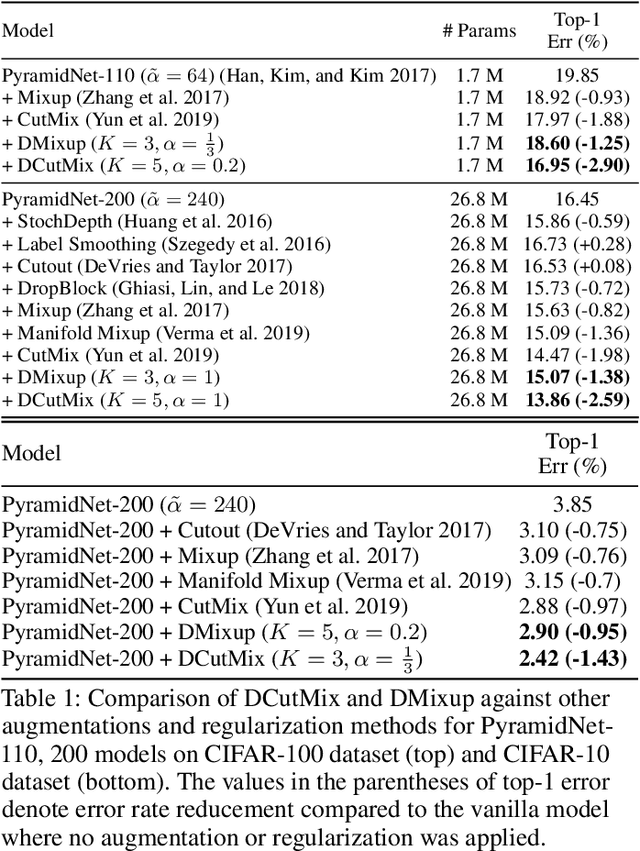
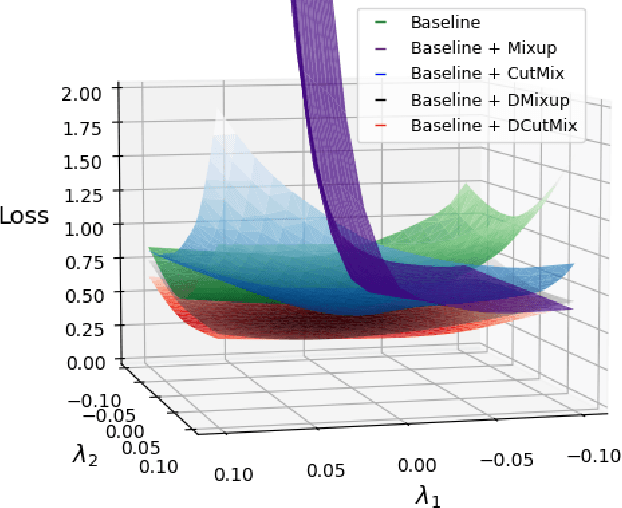

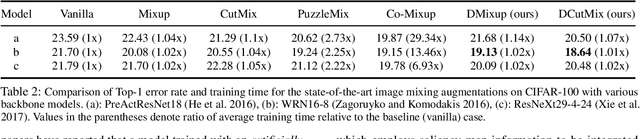
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021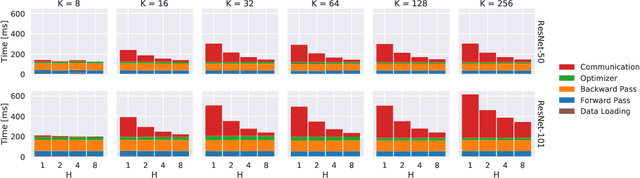
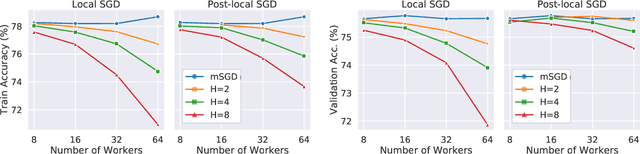
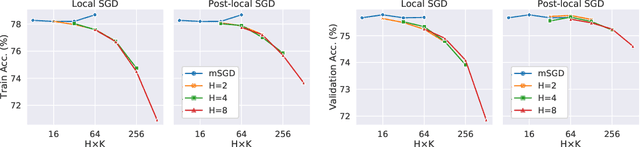
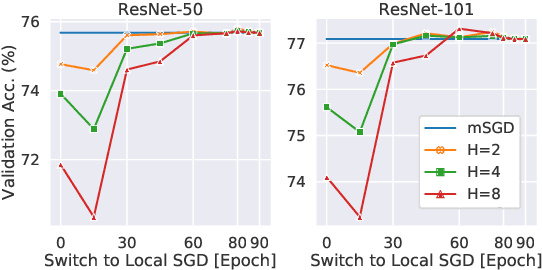
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Combining Image Features and Patient Metadata to Enhance Transfer Learning
Oct 08, 2021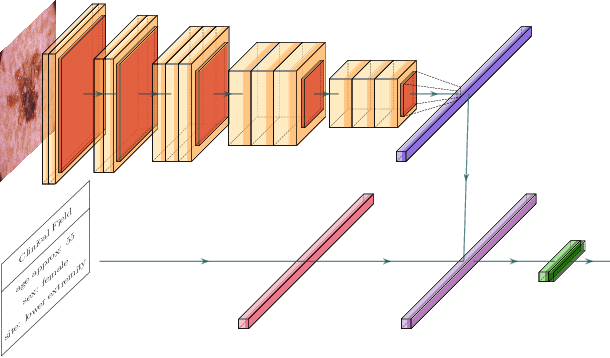
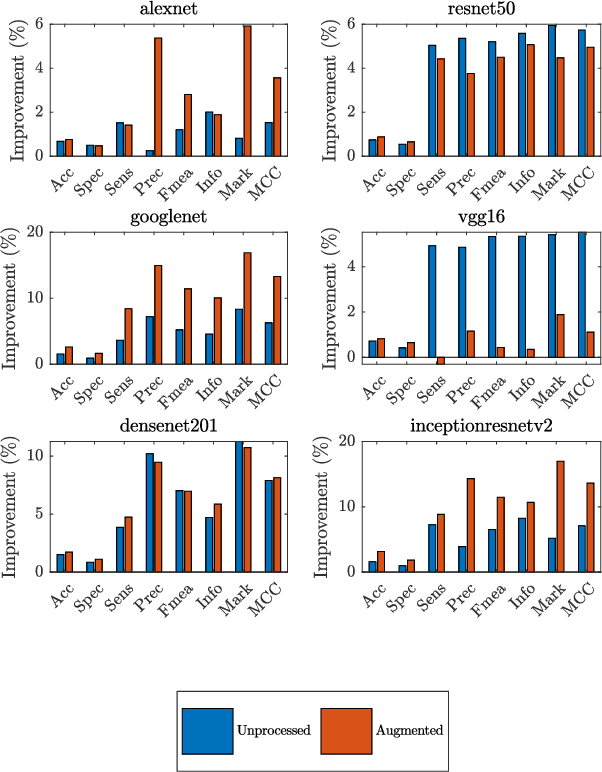
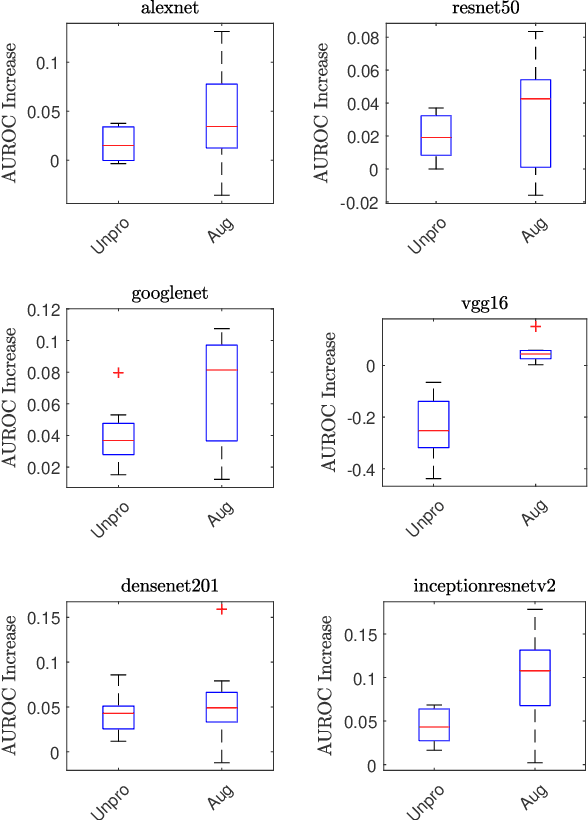
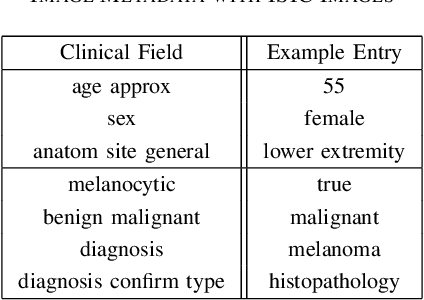
In this work, we compare the performance of six state-of-the-art deep neural networks in classification tasks when using only image features, to when these are combined with patient metadata. We utilise transfer learning from networks pretrained on ImageNet to extract image features from the ISIC HAM10000 dataset prior to classification. Using several classification performance metrics, we evaluate the effects of including metadata with the image features. Furthermore, we repeat our experiments with data augmentation. Our results show an overall enhancement in performance of each network as assessed by all metrics, only noting degradation in a vgg16 architecture. Our results indicate that this performance enhancement may be a general property of deep networks and should be explored in other areas. Moreover, these improvements come at a negligible additional cost in computation time, and therefore are a practical method for other applications.
Novel EEG based Schizophrenia Detection with IoMT Framework for Smart Healthcare
Nov 19, 2021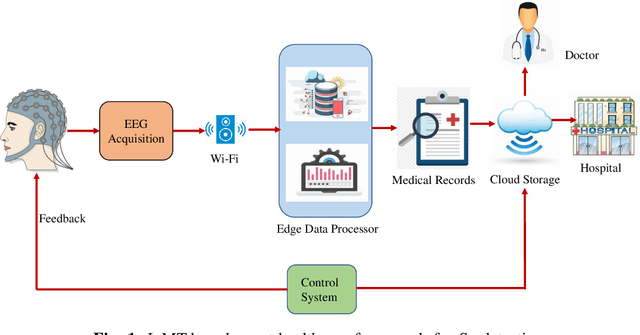
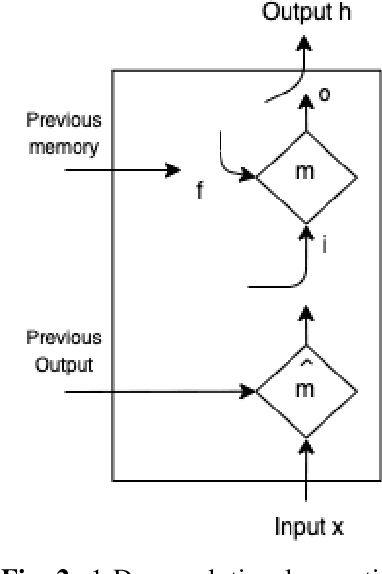
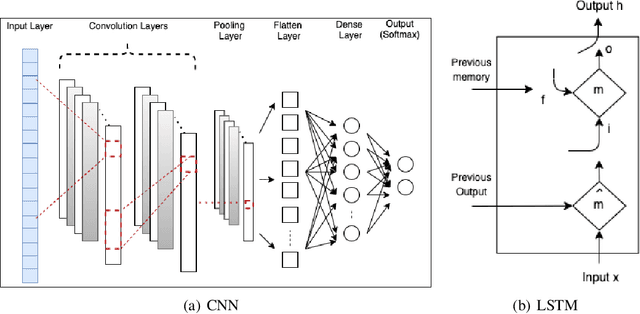
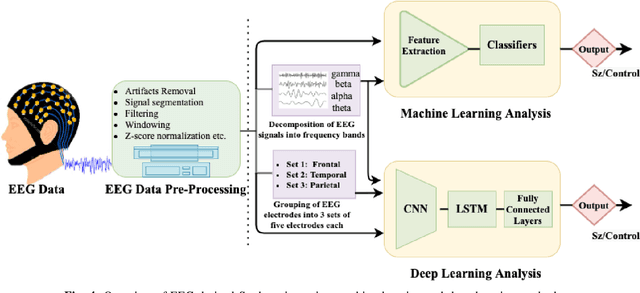
In the field of neuroscience, Brain activity analysis is always considered as an important area. Schizophrenia(Sz) is a brain disorder that severely affects the thinking, behaviour, and feelings of people all around the world. Electroencephalography (EEG) is proved to be an efficient biomarker in Sz detection. EEG is a non-linear time-seriesi signal and utilizing it for investigation is rather crucial due to its non-linear structure. This paper aims to improve the performance of EEG based Sz detection using a deep learning approach. A novel hybrid deep learning model known as SzHNN (Schizophrenia Hybrid Neural Network), a combination of Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) has been proposed. CNN network is used for local feature extraction and LSTM has been utilized for classification. The proposed model has been compared with CNN only, LSTM only, and machine learning-based models. All the models have been evaluated on two different datasets wherein Dataset 1 consists of 19 subjects and Dataset 2 consists of 16 subjects. Several experiments have been conducted for the same using various parametric settings on different frequency bands and using different sets of electrodes on the scalp. Based on all the experiments, it is evident that the proposed hybrid model (SzHNN) provides the highest classification accuracy of 99.9% in comparison to other existing models. The proposed model overcomes the influence of different frequency bands and even showed a much better accuracy of 91% with only 5 electrodes. The proposed model is also evaluated on the Internet of Medical Things (IoMT) framework for smart healthcare and remote monitoring applications.
FinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance
Nov 07, 2021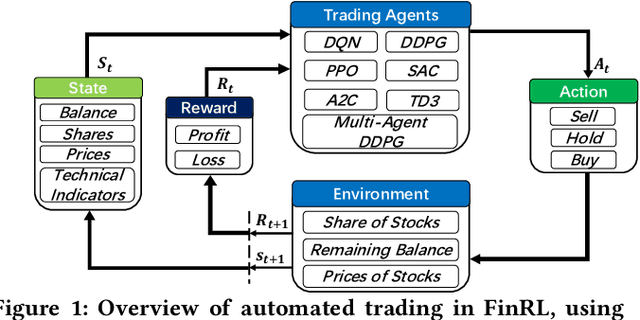
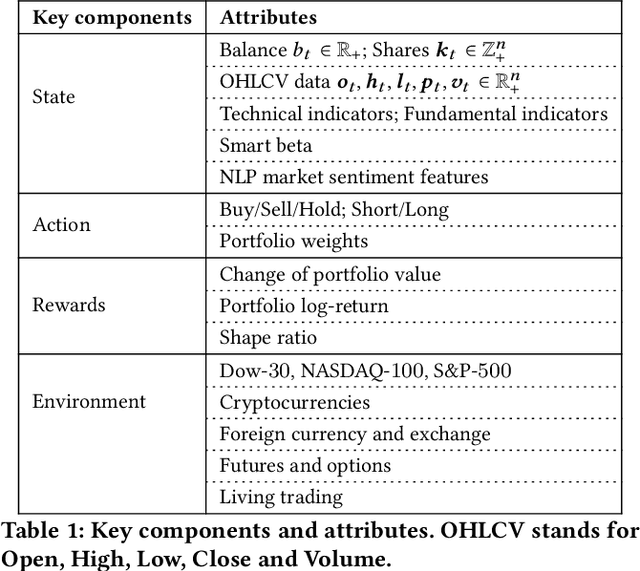
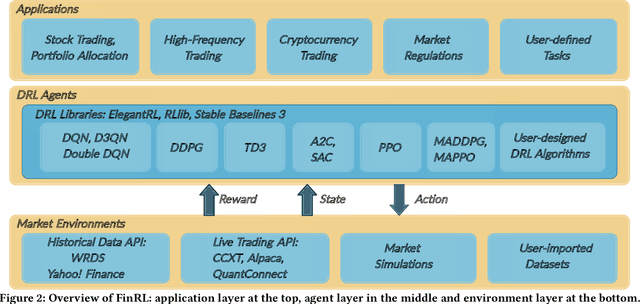

Deep reinforcement learning (DRL) has been envisioned to have a competitive edge in quantitative finance. However, there is a steep development curve for quantitative traders to obtain an agent that automatically positions to win in the market, namely \textit{to decide where to trade, at what price} and \textit{what quantity}, due to the error-prone programming and arduous debugging. In this paper, we present the first open-source framework \textit{FinRL} as a full pipeline to help quantitative traders overcome the steep learning curve. FinRL is featured with simplicity, applicability and extensibility under the key principles, \textit{full-stack framework, customization, reproducibility} and \textit{hands-on tutoring}. Embodied as a three-layer architecture with modular structures, FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads. Thus, we help users pipeline the strategy design at a high turnover rate. At multiple levels of time granularity, FinRL simulates various markets as training environments using historical data and live trading APIs. Being highly extensible, FinRL reserves a set of user-import interfaces and incorporates trading constraints such as market friction, market liquidity and investor's risk-aversion. Moreover, serving as practitioners' stepping stones, typical trading tasks are provided as step-by-step tutorials, e.g., stock trading, portfolio allocation, cryptocurrency trading, etc.
* ACM International Conference on AI in Finance
Temporal Convolutions for Multi-Step Quadrotor Motion Prediction
Oct 08, 2021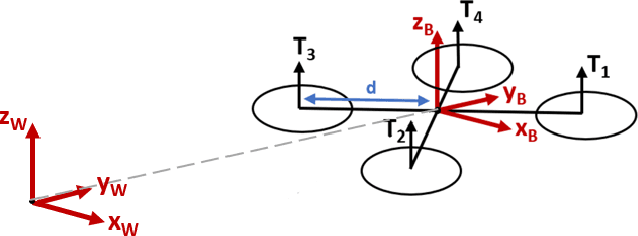
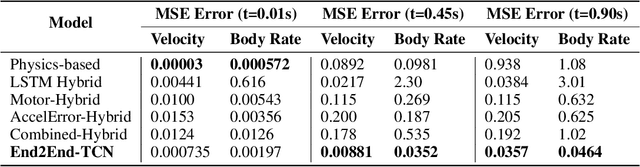
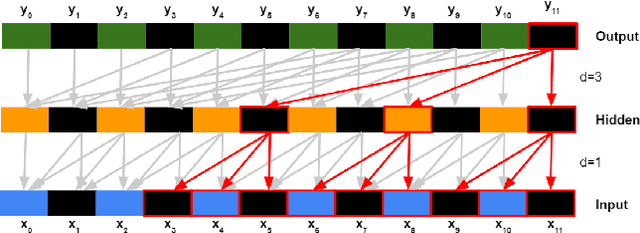
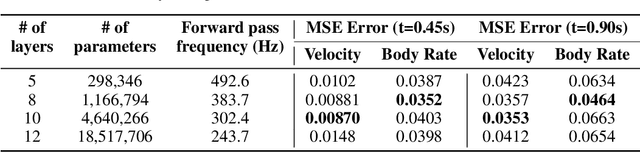
Model-based control methods for robotic systems such as quadrotors, autonomous driving vehicles and flexible manipulators require motion models that generate accurate predictions of complex nonlinear system dynamics over long periods of time. Temporal Convolutional Networks (TCNs) can be adapted to this challenge by formulating multi-step prediction as a sequence-to-sequence modeling problem. We present End2End-TCN: a fully convolutional architecture that integrates future control inputs to compute multi-step motion predictions in one forward pass. We demonstrate the approach with a thorough analysis of TCN performance for the quadrotor modeling task, which includes an investigation of scaling effects and ablation studies. Ultimately, End2End-TCN provides 55% error reduction over the state of the art in multi-step prediction on an aggressive indoor quadrotor flight dataset. The model yields accurate predictions across 90 timestep horizons over a 900 ms interval.
Deep Reinforcement Learning Based Multidimensional Resource Management for Energy Harvesting Cognitive NOMA Communications
Sep 17, 2021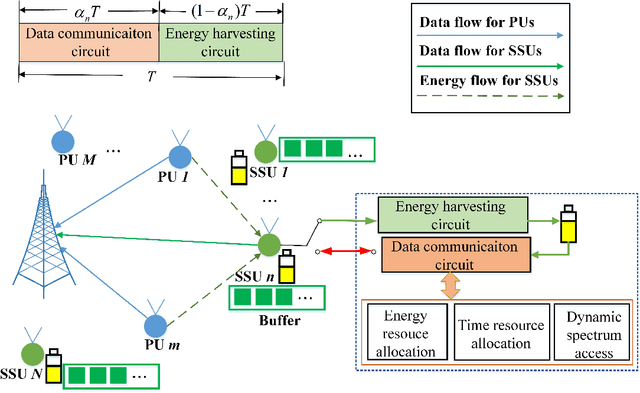
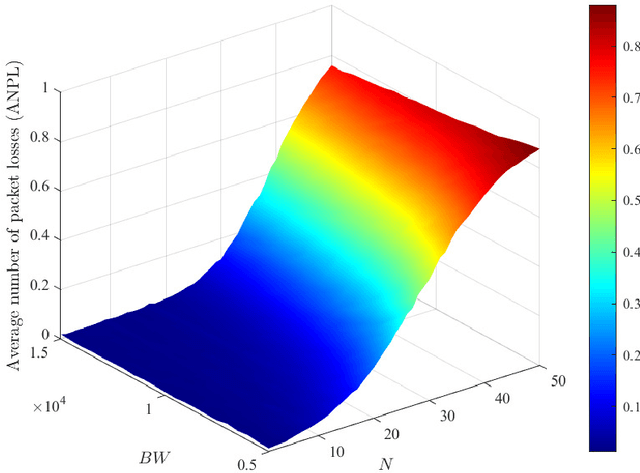
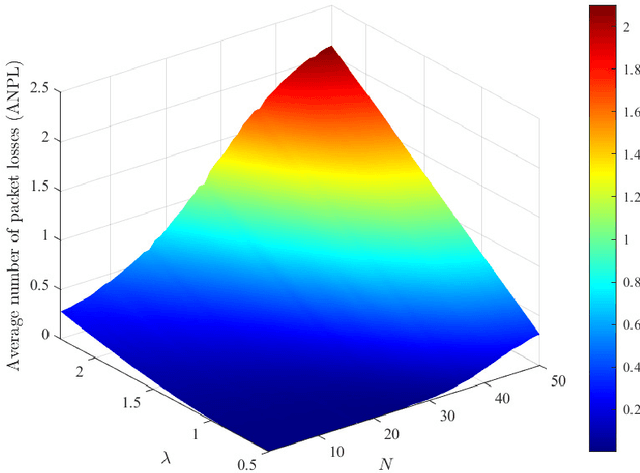
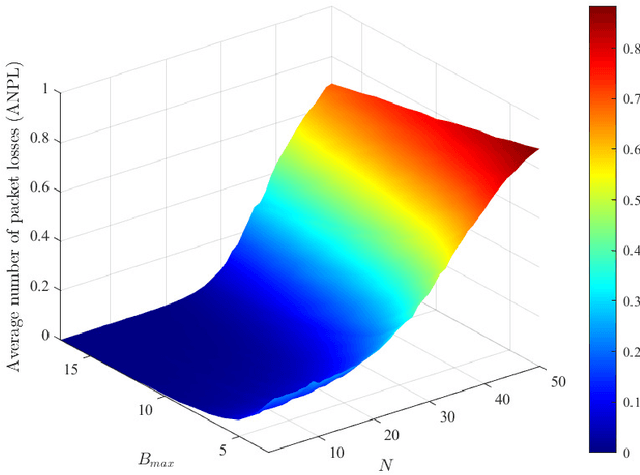
The combination of energy harvesting (EH), cognitive radio (CR), and non-orthogonal multiple access (NOMA) is a promising solution to improve energy efficiency and spectral efficiency of the upcoming beyond fifth generation network (B5G), especially for support the wireless sensor communications in Internet of things (IoT) system. However, how to realize intelligent frequency, time, and energy resource allocation to support better performances is an important problem to be solved. In this paper, we study joint spectrum, energy, and time resource management for the EH-CR-NOMA IoT systems. Our goal is to minimize the number of data packets losses for all secondary sensing users (SSU), while satisfying the constraints on the maximum charging battery capacity, maximum transmitting power, maximum buffer capacity, and minimum data rate of primary users (PU) and SSUs. Due to the non-convexity of this optimization problem and the stochastic nature of the wireless environment, we propose a distributed multidimensional resource management algorithm based on deep reinforcement learning (DRL). Considering the continuity of the resources to be managed, the deep deterministic policy gradient (DDPG) algorithm is adopted, based on which each agent (SSU) can manage its own multidimensional resources without collaboration. In addition, a simplified but practical action adjuster (AA) is introduced for improving the training efficiency and battery performance protection. The provided results show that the convergence speed of the proposed algorithm is about 4 times faster than that of DDPG, and the average number of packet losses (ANPL) is about 8 times lower than that of the greedy algorithm.