 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analysis of Language Change in Collaborative Instruction Following
Sep 09, 2021

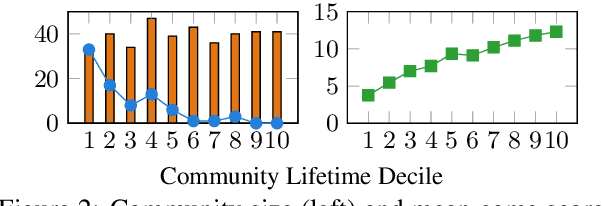
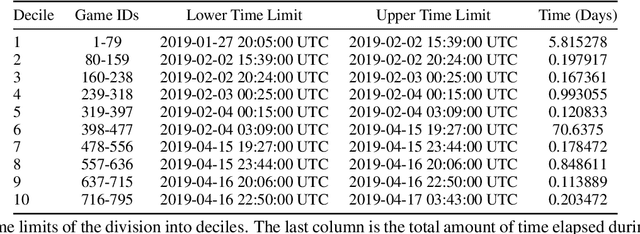
We analyze language change over time in a collaborative, goal-oriented instructional task, where utility-maximizing participants form conventions and increase their expertise. Prior work studied such scenarios mostly in the context of reference games, and consistently found that language complexity is reduced along multiple dimensions, such as utterance length, as conventions are formed. In contrast, we find that, given the ability to increase instruction utility, instructors increase language complexity along these previously studied dimensions to better collaborate with increasingly skilled instruction followers.
Literature Review on Endoscopic Robotic Systems in Ear and Sinus Surgery
Sep 28, 2021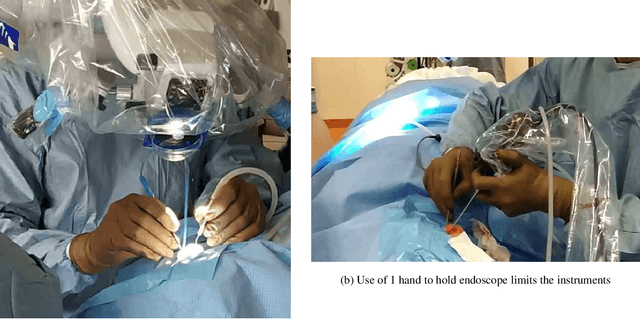
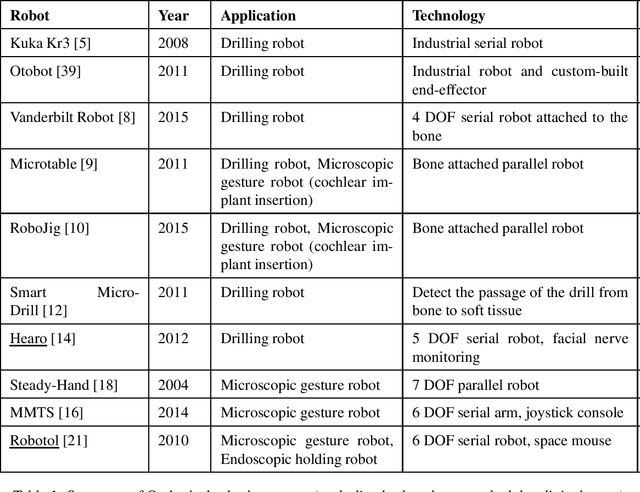
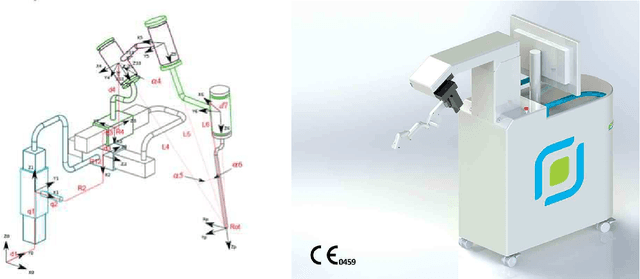
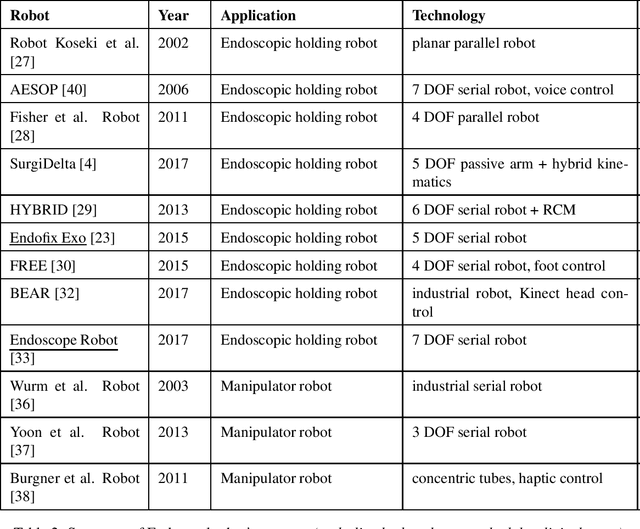
In otolaryngologic surgery, endoscopy is increasingly used to provide a better view of hard-to-reach areas and to promote minimally invasive surgery. However, the need to manipulate the endoscope limits the surgeon's ability to operate with only one instrument at a time. Currently, several robotic systems are being developed, demonstrating the value of robotic assistance in microsurgery. The aim of this literature review is to present and classify current robotic systems that are used for otological and endonasal applications. For these solutions, an analysis of the functionalities in relation to the surgeon's needs will be carried out in order to produce a set of specifications for the creation of new robots.
Affordance Template Registration via Human-in-the-loop Corrections
Sep 28, 2021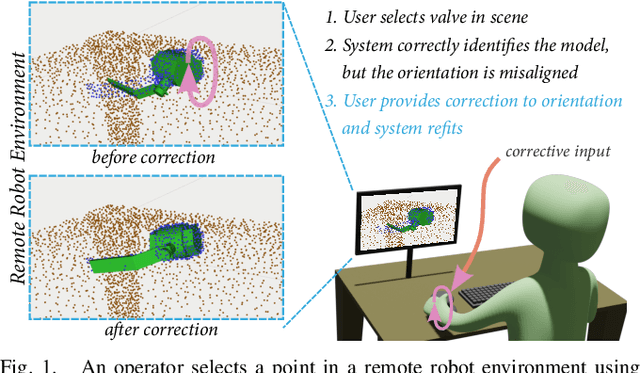
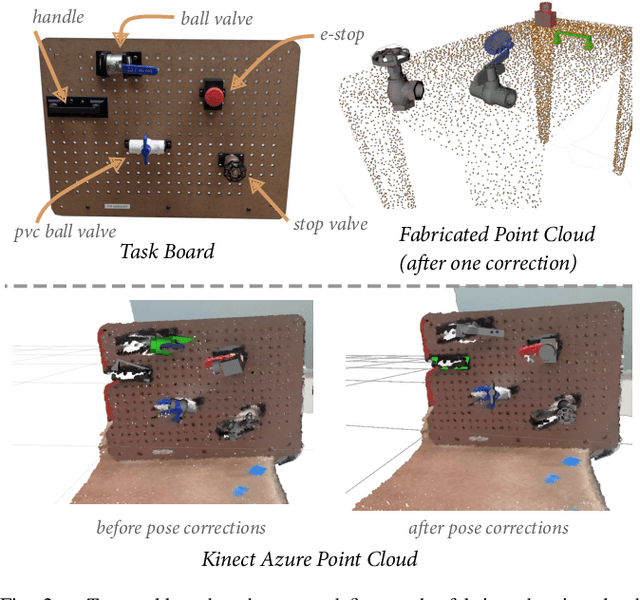
Affordance Templates (ATs) are a method for parameterizing objects for autonomous robot manipulations. In this approach, instances of an object are registered by positioning a model in a 3D environment, which requires a large amount of user input. We instead propose a registration method which combines autonomy and user corrections. For selected objects, the system determines both the model and corresponding pose autonomously. The user makes corrections only if the model or pose is incorrect. This method increases the level of autonomy compared to existing approaches which can reduce user input and time on task. In this paper, we present an overview of existing methods, a description of our method, preliminary results, and planned future work.
A Self-adaptive LSAC-PID Approach based on Lyapunov Reward Shaping for Mobile Robots
Nov 03, 2021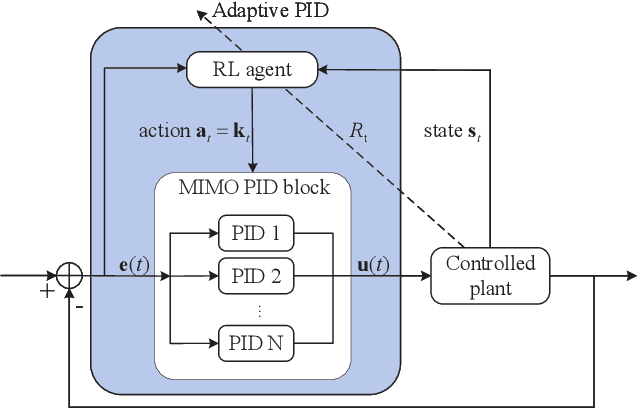
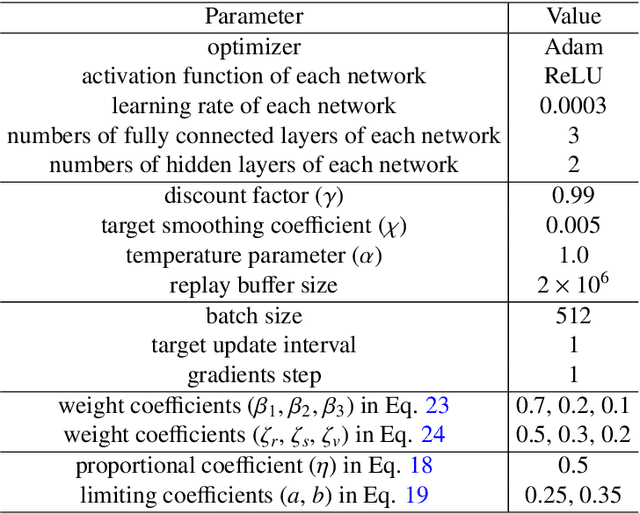
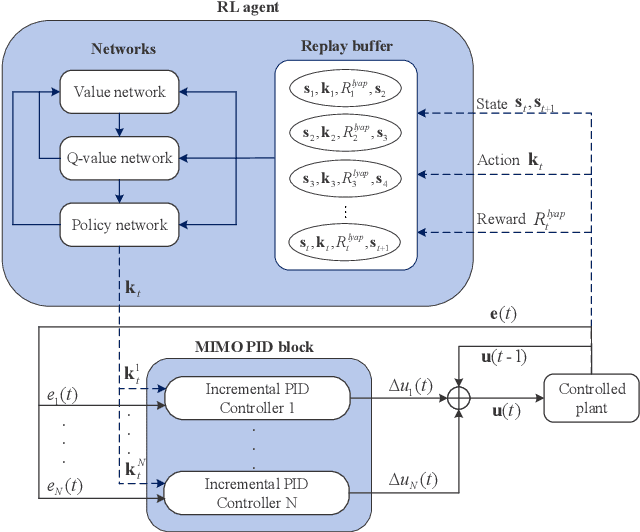

To solve the coupling problem of control loops and the adaptive parameter tuning problem in the multi-input multi-output (MIMO) PID control system, a self-adaptive LSAC-PID algorithm is proposed based on deep reinforcement learning (RL) and Lyapunov-based reward shaping in this paper. For complex and unknown mobile robot control environment, an RL-based MIMO PID hybrid control strategy is firstly presented. According to the dynamic information and environmental feedback of the mobile robot, the RL agent can output the optimal MIMO PID parameters in real time, without knowing mathematical model and decoupling multiple control loops. Then, to improve the convergence speed of RL and the stability of mobile robots, a Lyapunov-based reward shaping soft actor-critic (LSAC) algorithm is proposed based on Lyapunov theory and potential-based reward shaping method. The convergence and optimality of the algorithm are proved in terms of the policy evaluation and improvement step of soft policy iteration. In addition, for line-following robots, the region growing method is improved to adapt to the influence of forks and environmental interference. Through comparison, test and cross-validation, the simulation and real-environment experimental results all show good performance of the proposed LSAC-PID tuning algorithm.
Block Contextual MDPs for Continual Learning
Oct 13, 2021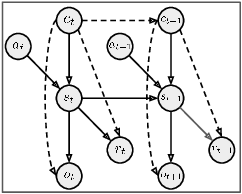
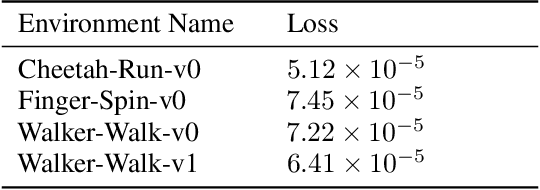
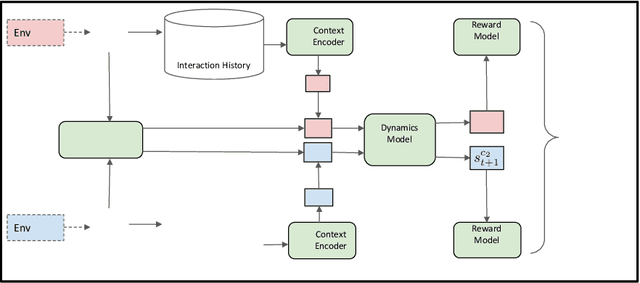
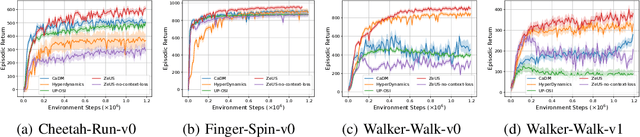
In reinforcement learning (RL), when defining a Markov Decision Process (MDP), the environment dynamics is implicitly assumed to be stationary. This assumption of stationarity, while simplifying, can be unrealistic in many scenarios. In the continual reinforcement learning scenario, the sequence of tasks is another source of nonstationarity. In this work, we propose to examine this continual reinforcement learning setting through the block contextual MDP (BC-MDP) framework, which enables us to relax the assumption of stationarity. This framework challenges RL algorithms to handle both nonstationarity and rich observation settings and, by additionally leveraging smoothness properties, enables us to study generalization bounds for this setting. Finally, we take inspiration from adaptive control to propose a novel algorithm that addresses the challenges introduced by this more realistic BC-MDP setting, allows for zero-shot adaptation at evaluation time, and achieves strong performance on several nonstationary environments.
Poformer: A simple pooling transformer for speaker verification
Oct 10, 2021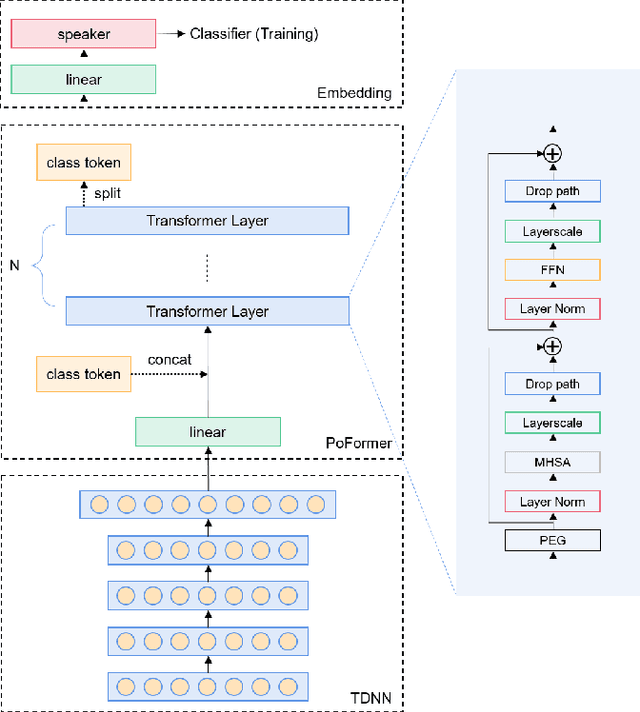
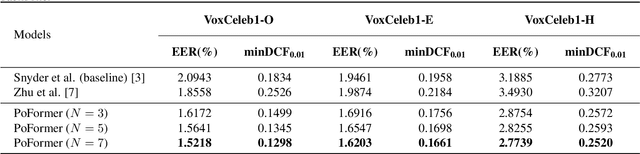
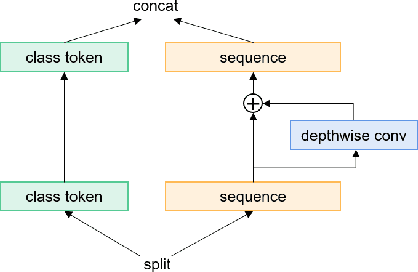
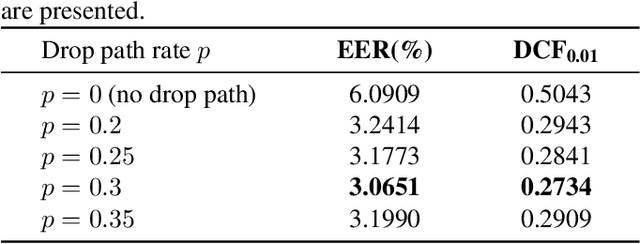
Most recent speaker verification systems are based on extracting speaker embeddings using a deep neural network. The pooling layer in the network aims to aggregate frame-level features extracted by the backbone. In this paper, we propose a new transformer based pooling structure called PoFormer to enhance the ability of the pooling layer to capture information along the whole time axis. Different from previous works that apply attention mechanism in a simple way or implement the multi-head mechanism in serial instead of in parallel, PoFormer follows the initial transformer structure with some minor modifications like a positional encoding generator, drop path and LayerScale to make the training procedure more stable and to prevent overfitting. Evaluated on various datasets, PoFormer outperforms the existing pooling system with at least a 13.00% improvement in EER and a 9.12% improvement in minDCF.
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 03, 2021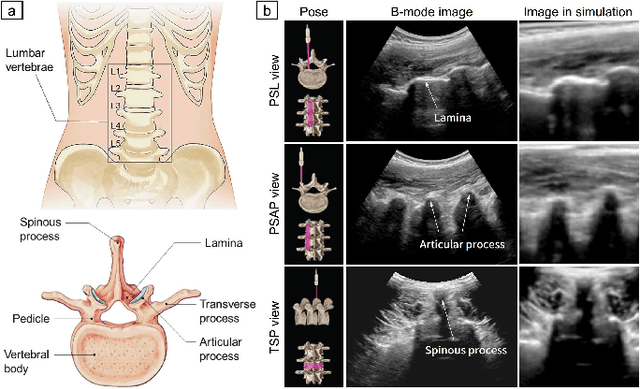
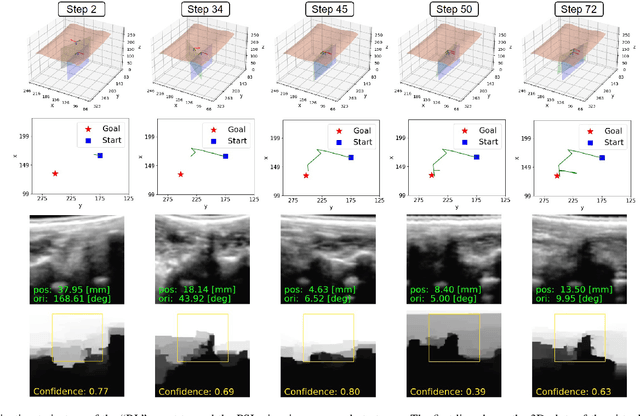
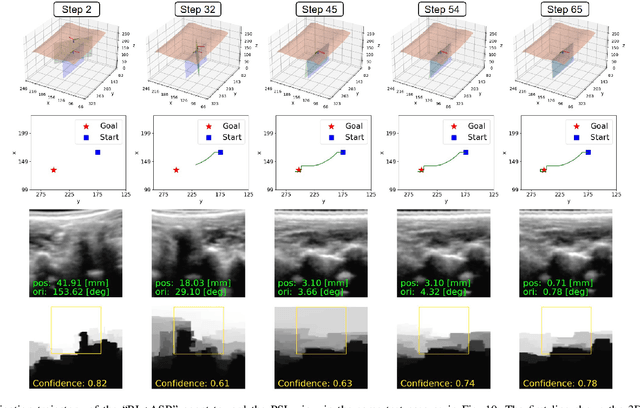
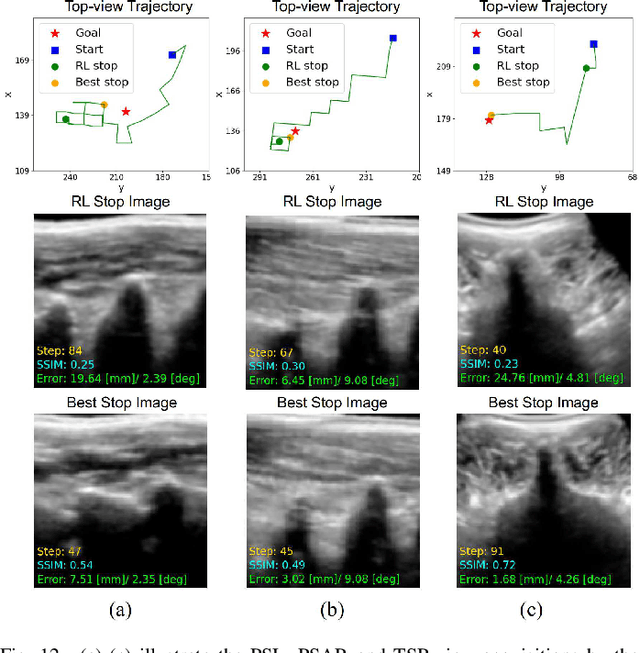
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from $17$ volunteers. The average navigation accuracy toward different standard views achieves $5.18mm/5.25^\circ$ and $12.87mm/17.49^\circ$ in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
TranSMS: Transformers for Super-Resolution Calibration in Magnetic Particle Imaging
Nov 03, 2021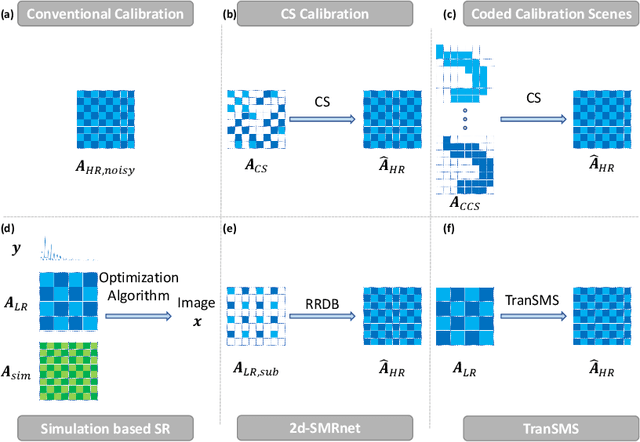
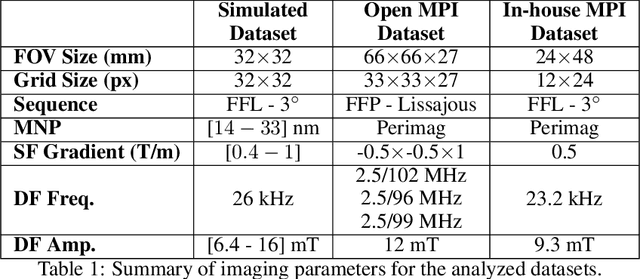
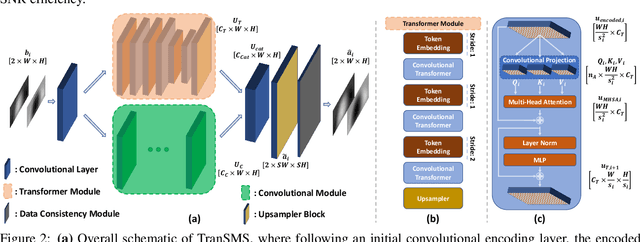
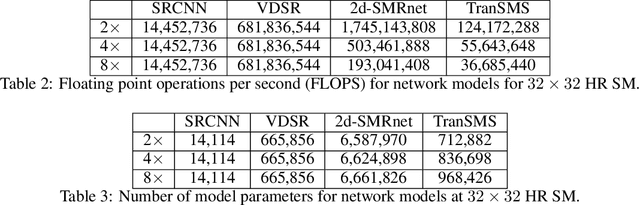
Magnetic particle imaging (MPI) is a recent modality that offers exceptional contrast for magnetic nanoparticles (MNP) at high spatio-temporal resolution. A common procedure in MPI starts with a calibration scan to measure the system matrix (SM), which is then used to setup an inverse problem to reconstruct images of the particle distribution during subsequent scans. This calibration enables the reconstruction to sensitively account for various system imperfections. Yet time-consuming SM measurements have to be repeated under notable drifts or changes in system properties. Here, we introduce a novel deep learning approach for accelerated MPI calibration based on transformers for SM super-resolution (TranSMS). Low-resolution SM measurements are performed using large MNP samples for improved signal-to-noise ratio efficiency, and the high-resolution SM is super-resolved via a model-based deep network. TranSMS leverages a vision transformer module to capture contextual relationships in low-resolution input images, a dense convolutional module for localizing high-resolution image features, and a data-consistency module to ensure consistency to measurements. Demonstrations on simulated and experimental data indicate that TranSMS achieves significantly improved SM recovery and image reconstruction in MPI, while enabling acceleration up to 64-fold during two-dimensional calibration.
A Simple Yet Effective Approach to Robust Optimization Over Time
Sep 05, 2019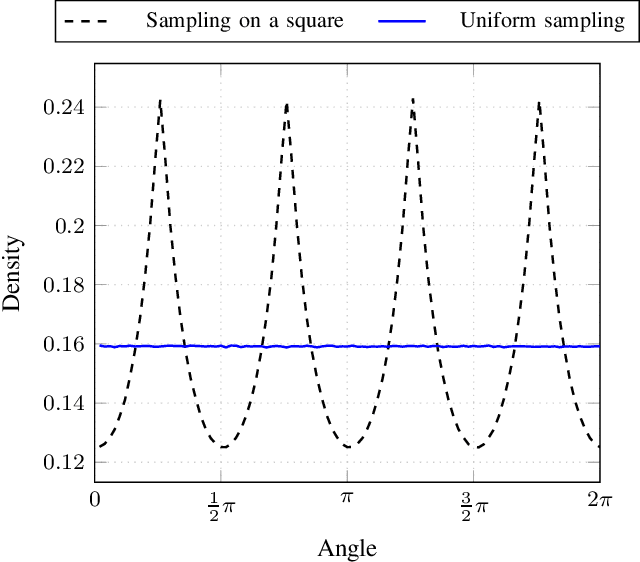
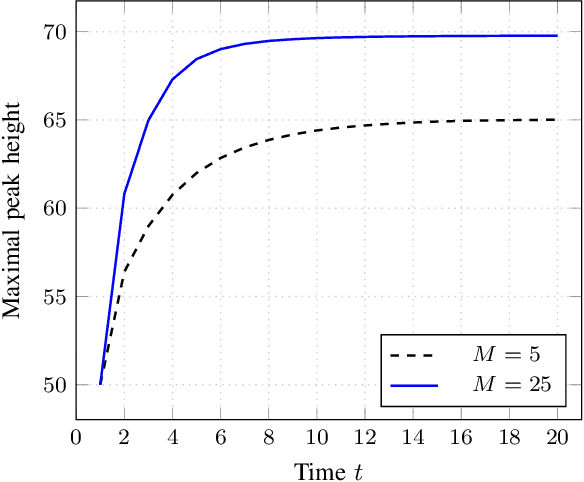
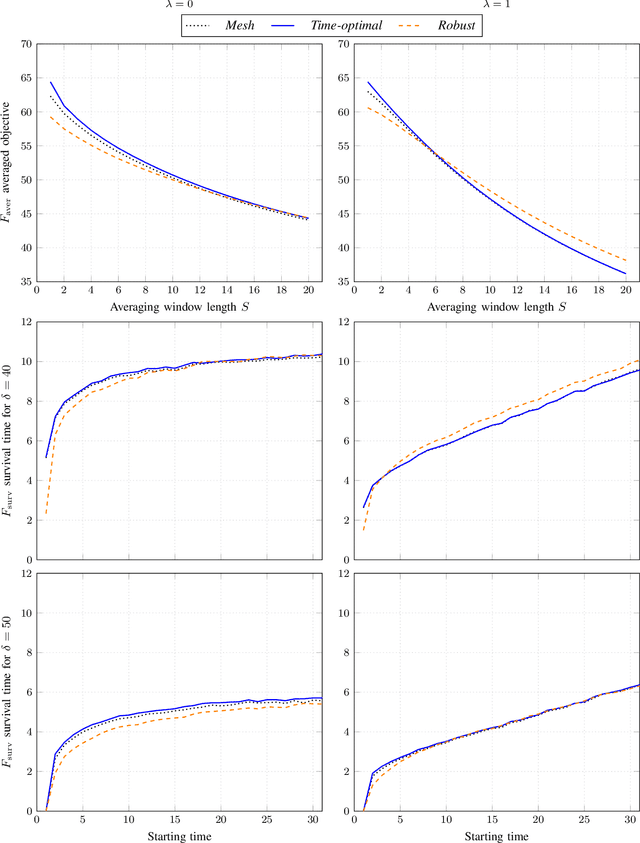
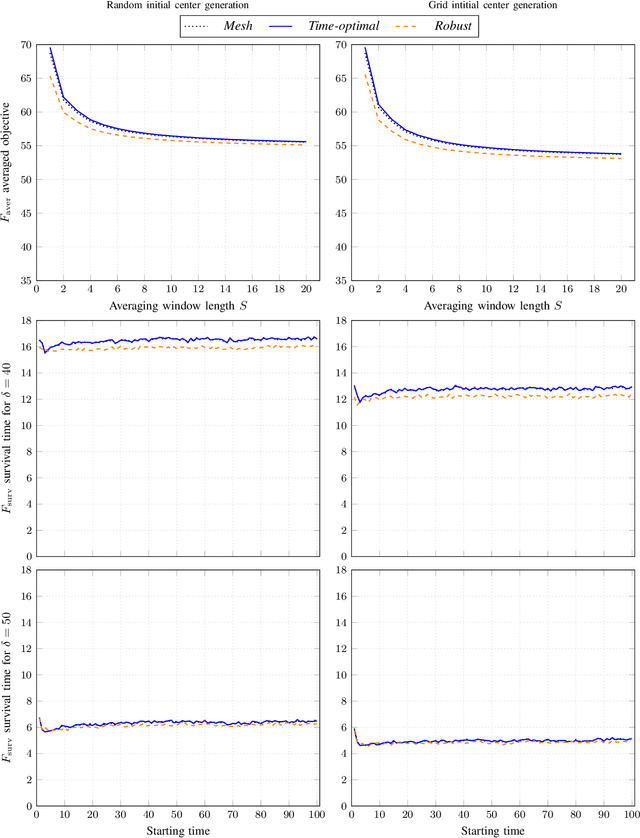
Robust optimization over time (ROOT) refers to an optimization problem where its performance is evaluated over a period of future time. Most of the existing algorithms use particle swarm optimization combined with another method which predicts future solutions to the optimization problem. We argue that this approach may perform subpar and suggest instead a method based on a random sampling of the search space. We prove its theoretical guarantees and show that it significantly outperforms the state-of-the-art methods for ROOT.
Policy Optimization Using Semiparametric Models for Dynamic Pricing
Sep 13, 2021In this paper, we study the contextual dynamic pricing problem where the market value of a product is linear in its observed features plus some market noise. Products are sold one at a time, and only a binary response indicating success or failure of a sale is observed. Our model setting is similar to Javanmard and Nazerzadeh [2019] except that we expand the demand curve to a semiparametric model and need to learn dynamically both parametric and nonparametric components. We propose a dynamic statistical learning and decision-making policy that combines semiparametric estimation from a generalized linear model with an unknown link and online decision-making to minimize regret (maximize revenue). Under mild conditions, we show that for a market noise c.d.f. $F(\cdot)$ with $m$-th order derivative ($m\geq 2$), our policy achieves a regret upper bound of $\tilde{O}_{d}(T^{\frac{2m+1}{4m-1}})$, where $T$ is time horizon and $\tilde{O}_{d}$ is the order that hides logarithmic terms and the dimensionality of feature $d$. The upper bound is further reduced to $\tilde{O}_{d}(\sqrt{T})$ if $F$ is super smooth whose Fourier transform decays exponentially. In terms of dependence on the horizon $T$, these upper bounds are close to $\Omega(\sqrt{T})$, the lower bound where $F$ belongs to a parametric class. We further generalize these results to the case with dynamically dependent product features under the strong mixing condition.