 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficiently solving the thief orienteering problem with a max-min ant colony optimization approach
Sep 28, 2021

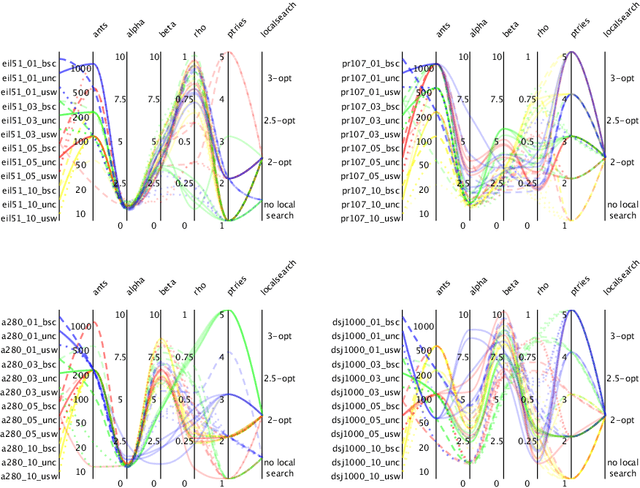
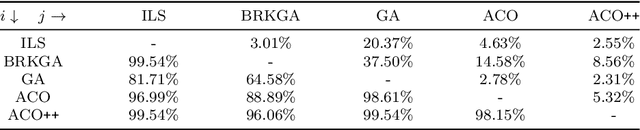
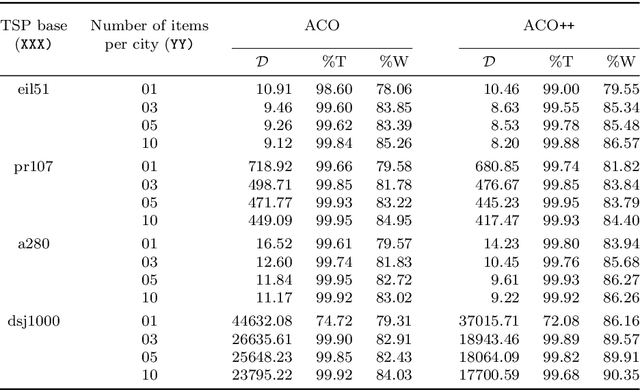
We tackle the Thief Orienteering Problem (ThOP), which is academic multi-component problem: it combines two classical combinatorial problems, namely the Knapsack Problem (KP) and the Orienteering Problem (OP). In this problem, a thief has a time limit to steal items that distributed in a given set of cities. While traveling, the thief collects items by storing them in their knapsack, which in turn reduces the travel speed. The thief has as the objective to maximize the total profit of the stolen items. In this article, we present an approach that combines swarm-intelligence with a randomized packing heuristic. Our solution approach outperforms existing works on almost all the 432 benchmarking instances, with significant improvements.
A New Algorithm based on Extent Bit-array for Computing Formal Concepts
Oct 29, 2021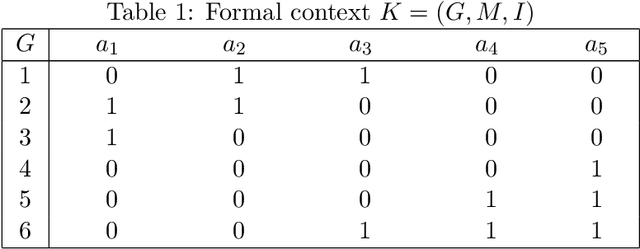


The emergence of Formal Concept Analysis (FCA) as a data analysis technique has increased the need for developing algorithms which can compute formal concepts quickly. The current efficient algorithms for FCA are variants of the Close-By-One (CbO) algorithm, such as In-Close2, In-Close3 and In-Close4, which are all based on horizontal storage of contexts. In this paper, based on algorithm In-Close4, a new algorithm based on the vertical storage of contexts, called In-Close5, is proposed, which can significantly reduce both the time complexity and space complexity of algorithm In-Close4. Technically, the new algorithm stores both context and extent of a concept as a vertical bit-array, while within In-Close4 algorithm the context is stored only as a horizontal bit-array, which is very slow in finding the intersection of two extent sets. Experimental results demonstrate that the proposed algorithm is much more effective than In-Close4 algorithm, and it also has a broader scope of applicability in computing formal concept in which one can solve the problems that cannot be solved by the In-Close4 algorithm.
NRC-GAMMA: Introducing a Novel Large Gas Meter Image Dataset
Nov 12, 2021



Automatic meter reading technology is not yet widespread. Gas, electricity, or water accumulation meters reading is mostly done manually on-site either by an operator or by the homeowner. In some countries, the operator takes a picture as reading proof to confirm the reading by checking offline with another operator and/or using it as evidence in case of conflicts or complaints. The whole process is time-consuming, expensive, and prone to errors. Automation can optimize and facilitate such labor-intensive and human error-prone processes. With the recent advances in the fields of artificial intelligence and computer vision, automatic meter reading systems are becoming more viable than ever. Motivated by the recent advances in the field of artificial intelligence and inspired by open-source open-access initiatives in the research community, we introduce a novel large benchmark dataset of real-life gas meter images, named the NRC-GAMMA dataset. The data were collected from an Itron 400A diaphragm gas meter on January 20, 2020, between 00:05 am and 11:59 pm. We employed a systematic approach to label the images, validate the labellings, and assure the quality of the annotations. The dataset contains 28,883 images of the entire gas meter along with 57,766 cropped images of the left and the right dial displays. We hope the NRC-GAMMA dataset helps the research community to design and implement accurate, innovative, intelligent, and reproducible automatic gas meter reading solutions.
Topology, Convergence, and Reconstruction of Predictive States
Sep 19, 2021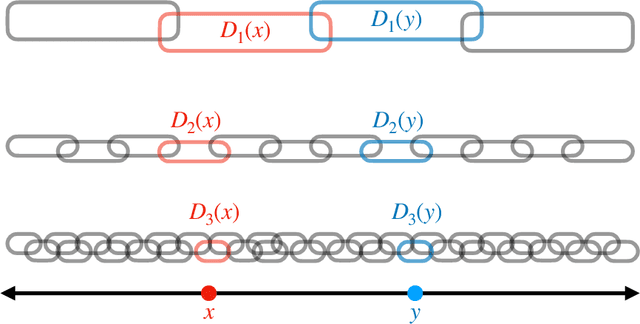
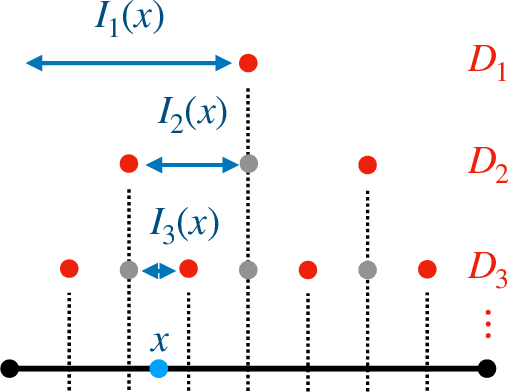
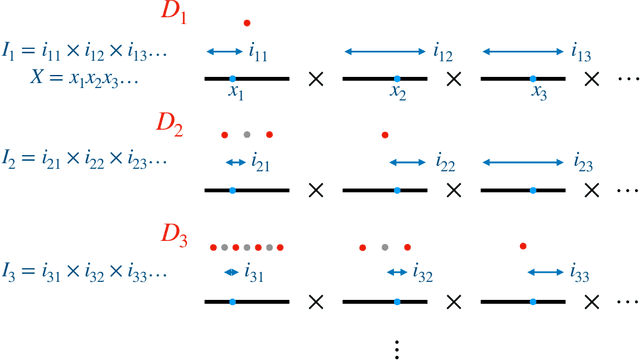
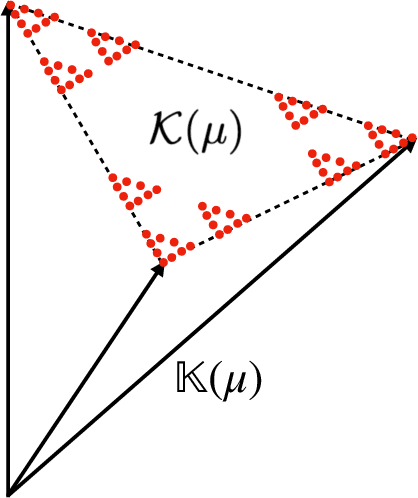
Predictive equivalence in discrete stochastic processes have been applied with great success to identify randomness and structure in statistical physics and chaotic dynamical systems and to inferring hidden Markov models. We examine the conditions under which they can be reliably reconstructed from time-series data, showing that convergence of predictive states can be achieved from empirical samples in the weak topology of measures. Moreover, predictive states may be represented in Hilbert spaces that replicate the weak topology. We mathematically explain how these representations are particularly beneficial when reconstructing high-memory processes and connect them to reproducing kernel Hilbert spaces.
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Nov 03, 2021


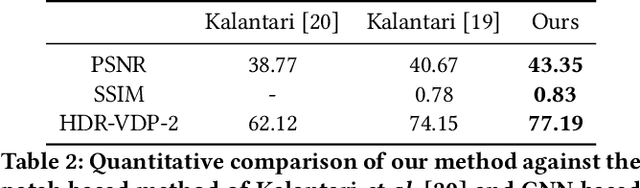
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Online Algorithms and Policies Using Adaptive and Machine Learning Approaches
May 27, 2021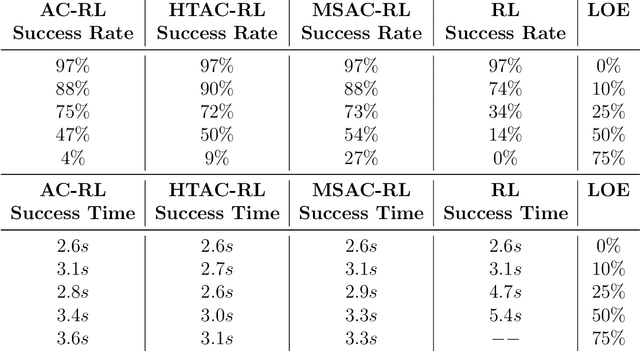
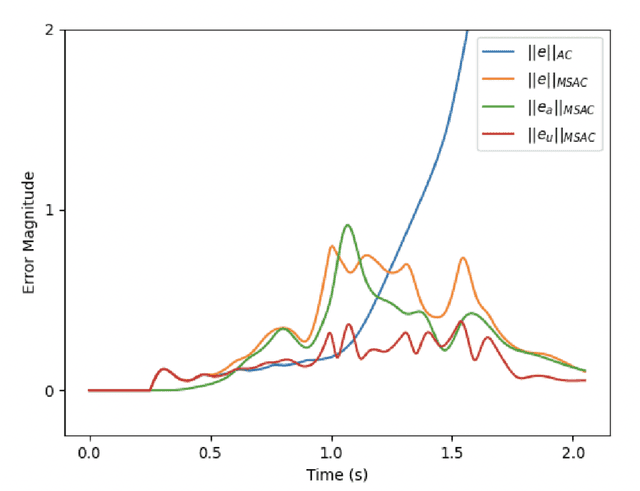
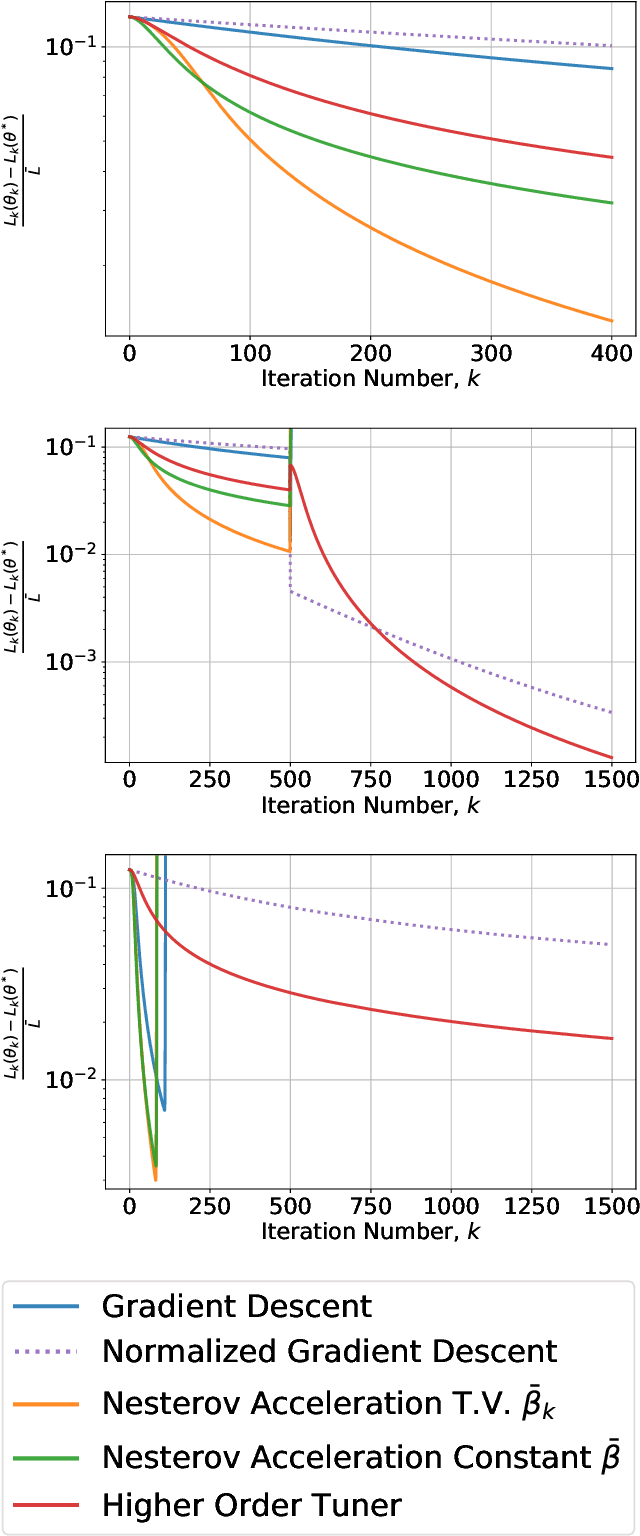
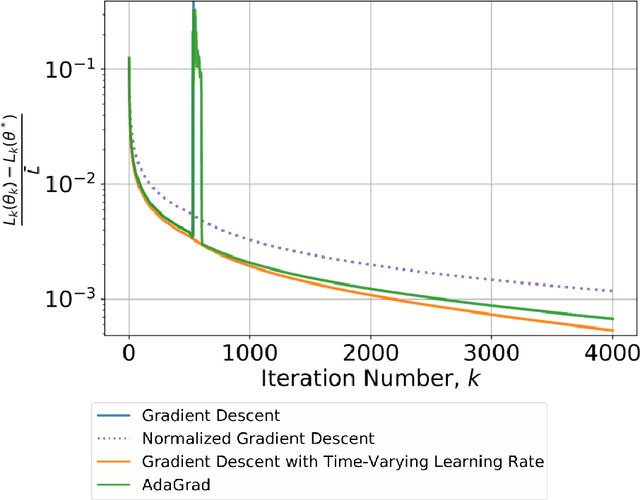
This paper considers the problem of real-time control and learning in dynamic systems subjected to uncertainties. Adaptive approaches are proposed to address the problem, which are combined to with methods and tools in Reinforcement Learning (RL) and Machine Learning (ML). Algorithms are proposed in continuous-time that combine adaptive approaches with RL leading to online control policies that guarantee stable behavior in the presence of parametric uncertainties that occur in real-time. Algorithms are proposed in discrete-time that combine adaptive approaches proposed for parameter and output estimation and ML approaches proposed for accelerated performance that guarantee stable estimation even in the presence of time-varying regressors, and for accelerated learning of the parameters with persistent excitation. Numerical validations of all algorithms are carried out using a quadrotor landing task on a moving platform and benchmark problems in ML. All results clearly point out the advantage of adaptive approaches for real-time control and learning.
Learning Scene Dynamics from Point Cloud Sequences
Nov 16, 2021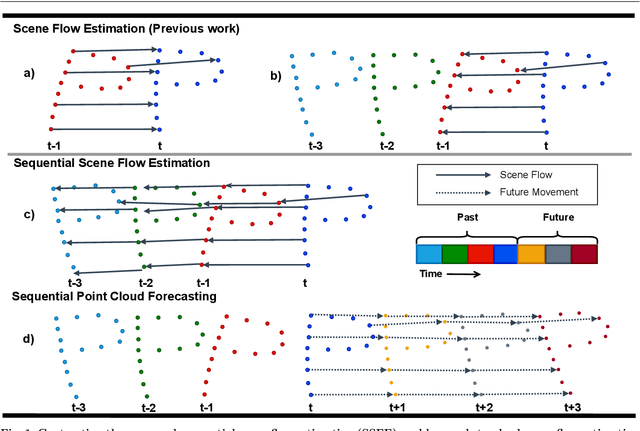

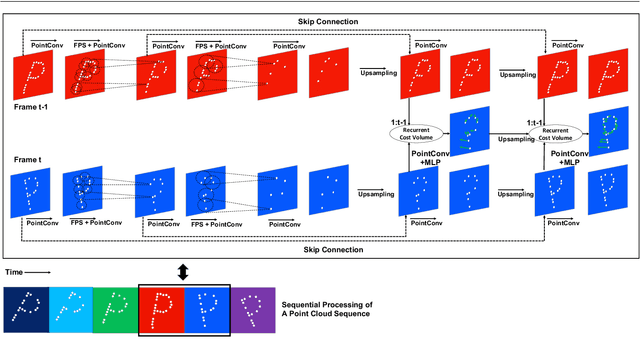
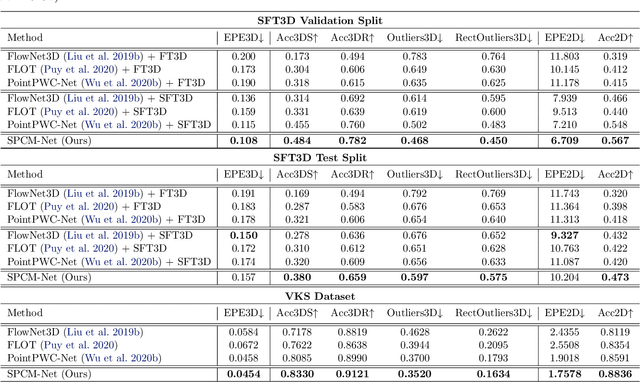
Understanding 3D scenes is a critical prerequisite for autonomous agents. Recently, LiDAR and other sensors have made large amounts of data available in the form of temporal sequences of point cloud frames. In this work, we propose a novel problem -- sequential scene flow estimation (SSFE) -- that aims to predict 3D scene flow for all pairs of point clouds in a given sequence. This is unlike the previously studied problem of scene flow estimation which focuses on two frames. We introduce the SPCM-Net architecture, which solves this problem by computing multi-scale spatiotemporal correlations between neighboring point clouds and then aggregating the correlation across time with an order-invariant recurrent unit. Our experimental evaluation confirms that recurrent processing of point cloud sequences results in significantly better SSFE compared to using only two frames. Additionally, we demonstrate that this approach can be effectively modified for sequential point cloud forecasting (SPF), a related problem that demands forecasting future point cloud frames. Our experimental results are evaluated using a new benchmark for both SSFE and SPF consisting of synthetic and real datasets. Previously, datasets for scene flow estimation have been limited to two frames. We provide non-trivial extensions to these datasets for multi-frame estimation and prediction. Due to the difficulty of obtaining ground truth motion for real-world datasets, we use self-supervised training and evaluation metrics. We believe that this benchmark will be pivotal to future research in this area. All code for benchmark and models will be made accessible.
Poformer: A simple pooling transformer for speaker verification
Oct 10, 2021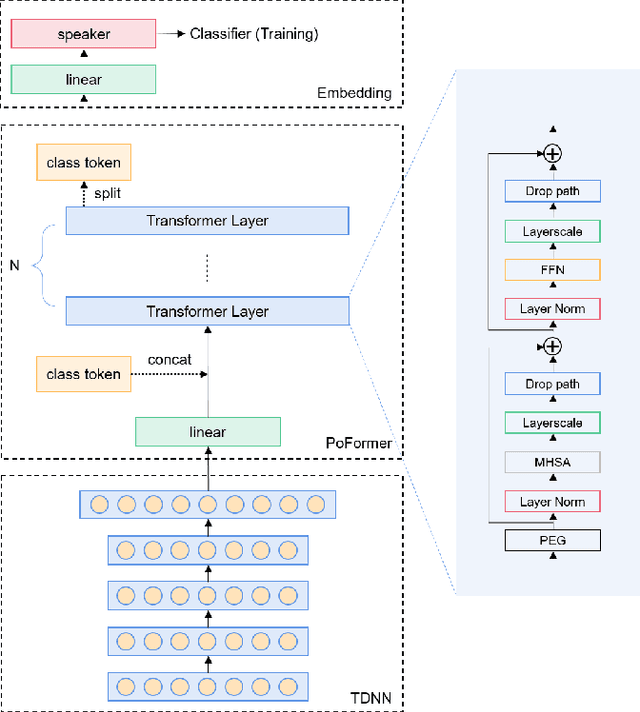
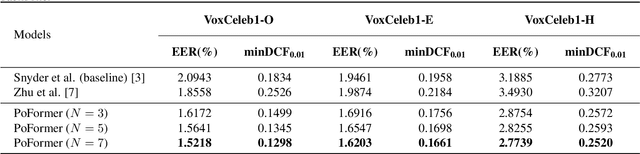
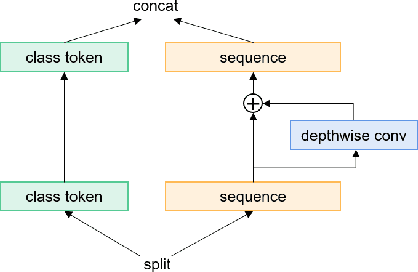
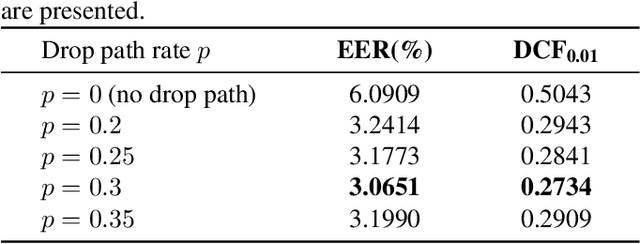
Most recent speaker verification systems are based on extracting speaker embeddings using a deep neural network. The pooling layer in the network aims to aggregate frame-level features extracted by the backbone. In this paper, we propose a new transformer based pooling structure called PoFormer to enhance the ability of the pooling layer to capture information along the whole time axis. Different from previous works that apply attention mechanism in a simple way or implement the multi-head mechanism in serial instead of in parallel, PoFormer follows the initial transformer structure with some minor modifications like a positional encoding generator, drop path and LayerScale to make the training procedure more stable and to prevent overfitting. Evaluated on various datasets, PoFormer outperforms the existing pooling system with at least a 13.00% improvement in EER and a 9.12% improvement in minDCF.
Event Detection on Dynamic Graphs
Oct 23, 2021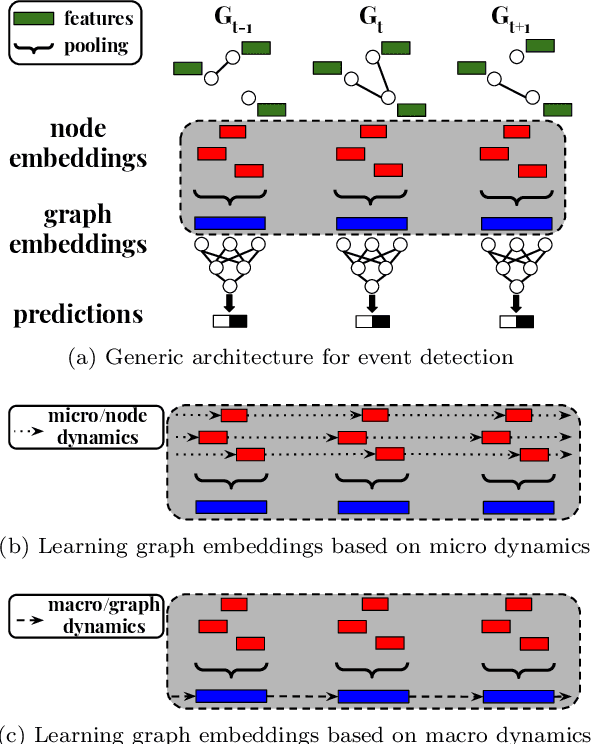
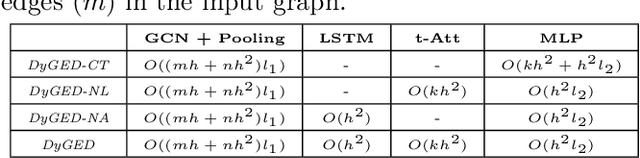
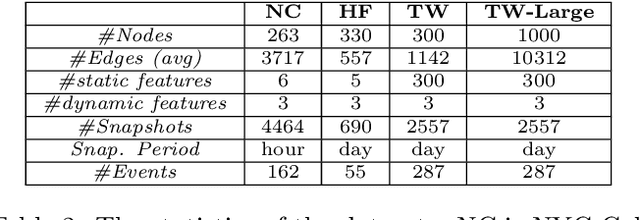
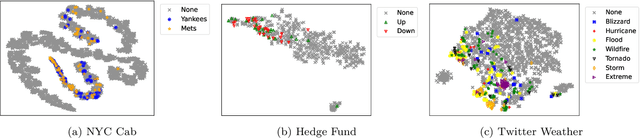
Event detection is a critical task for timely decision-making in graph analytics applications. Despite the recent progress towards deep learning on graphs, event detection on dynamic graphs presents particular challenges to existing architectures. Real-life events are often associated with sudden deviations of the normal behavior of the graph. However, existing approaches for dynamic node embedding are unable to capture the graph-level dynamics related to events. In this paper, we propose DyGED, a simple yet novel deep learning model for event detection on dynamic graphs. DyGED learns correlations between the graph macro dynamics -- i.e. a sequence of graph-level representations -- and labeled events. Moreover, our approach combines structural and temporal self-attention mechanisms to account for application-specific node and time importances effectively. Our experimental evaluation, using a representative set of datasets, demonstrates that DyGED outperforms competing solutions in terms of event detection accuracy by up to 8.5% while being more scalable than the top alternatives. We also present case studies illustrating key features of our model.
Literature Review on Endoscopic Robotic Systems in Ear and Sinus Surgery
Sep 28, 2021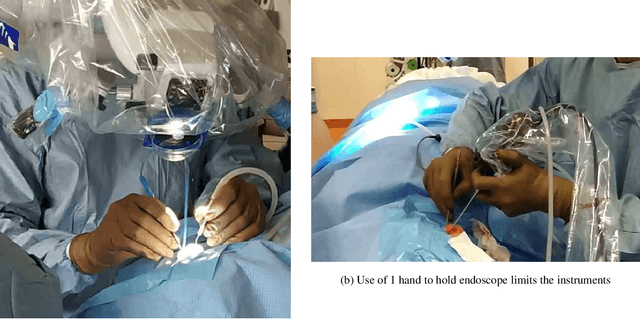
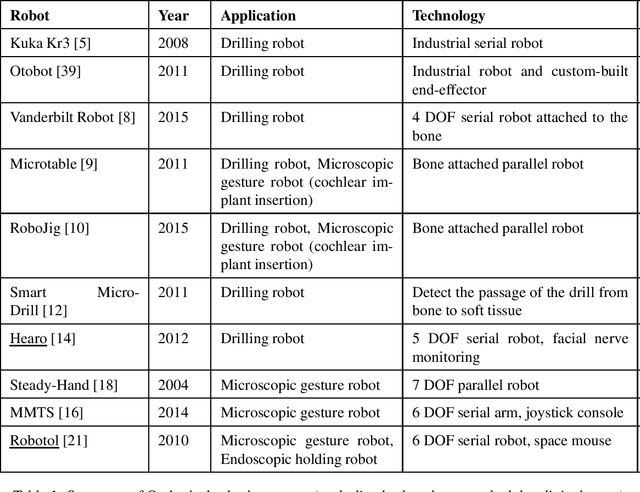
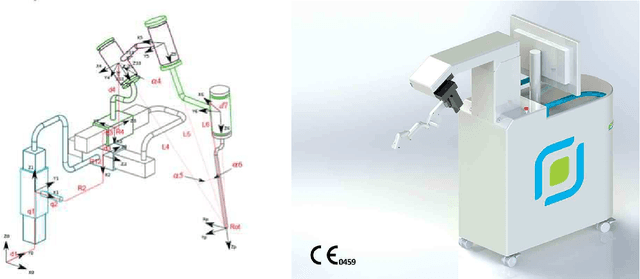
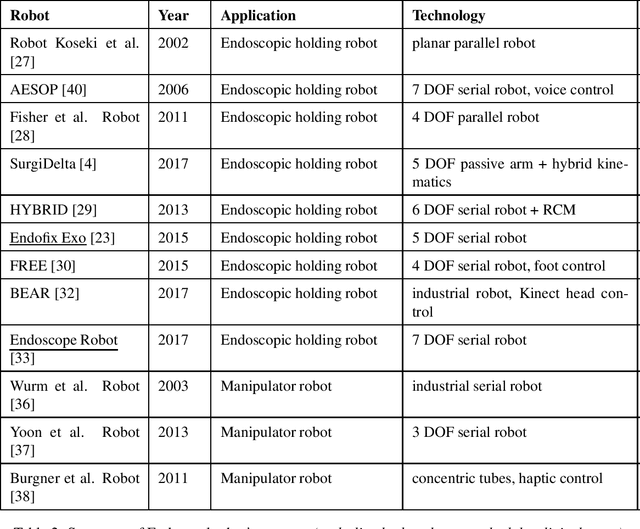
In otolaryngologic surgery, endoscopy is increasingly used to provide a better view of hard-to-reach areas and to promote minimally invasive surgery. However, the need to manipulate the endoscope limits the surgeon's ability to operate with only one instrument at a time. Currently, several robotic systems are being developed, demonstrating the value of robotic assistance in microsurgery. The aim of this literature review is to present and classify current robotic systems that are used for otological and endonasal applications. For these solutions, an analysis of the functionalities in relation to the surgeon's needs will be carried out in order to produce a set of specifications for the creation of new robots.