 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prioritization of COVID-19-related literature via unsupervised keyphrase extraction and document representation learning
Oct 17, 2021
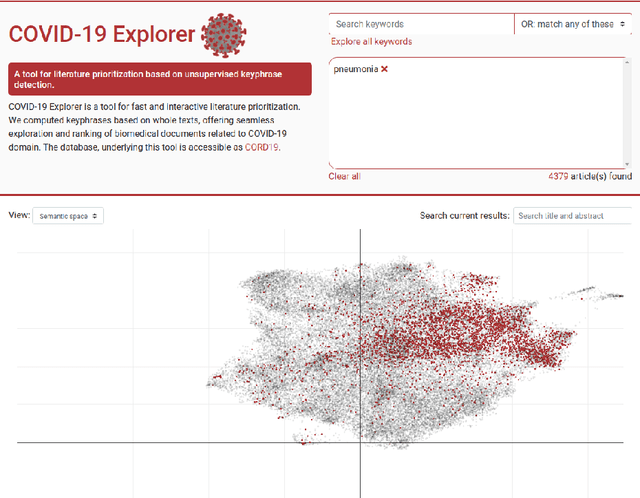
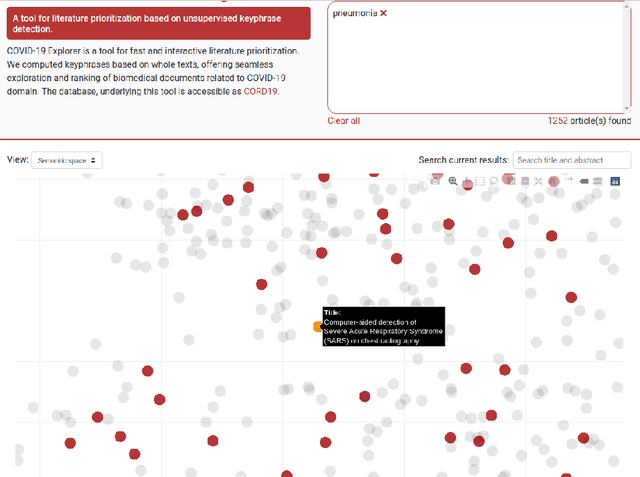
The COVID-19 pandemic triggered a wave of novel scientific literature that is impossible to inspect and study in a reasonable time frame manually. Current machine learning methods offer to project such body of literature into the vector space, where similar documents are located close to each other, offering an insightful exploration of scientific papers and other knowledge sources associated with COVID-19. However, to start searching, such texts need to be appropriately annotated, which is seldom the case due to the lack of human resources. In our system, the current body of COVID-19-related literature is annotated using unsupervised keyphrase extraction, facilitating the initial queries to the latent space containing the learned document embeddings (low-dimensional representations). The solution is accessible through a web server capable of interactive search, term ranking, and exploration of potentially interesting literature. We demonstrate the usefulness of the approach via case studies from the medicinal chemistry domain.
Context-gloss Augmentation for Improving Word Sense Disambiguation
Oct 14, 2021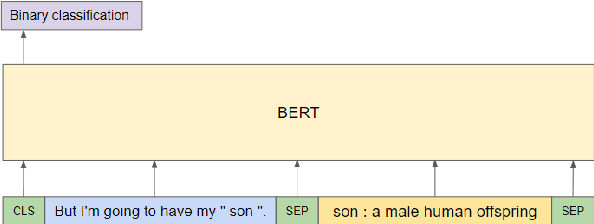

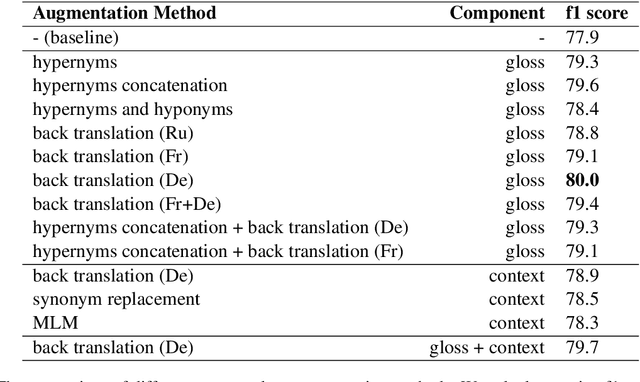

The goal of Word Sense Disambiguation (WSD) is to identify the sense of a polysemous word in a specific context. Deep-learning techniques using BERT have achieved very promising results in the field and different methods have been proposed to integrate structured knowledge to enhance performance. At the same time, an increasing number of data augmentation techniques have been proven to be useful for NLP tasks. Building upon previous works leveraging BERT and WordNet knowledge, we explore different data augmentation techniques on context-gloss pairs to improve the performance of WSD. In our experiment, we show that both sentence-level and word-level augmentation methods are effective strategies for WSD. Also, we find out that performance can be improved by adding hypernyms' glosses obtained from a lexical knowledge base. We compare and analyze different context-gloss augmentation techniques, and the results show that applying back translation on gloss performs the best.
Using Interaction Data to Predict Engagement with Interactive Media
Aug 04, 2021
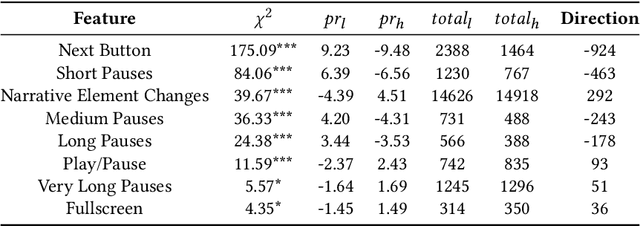
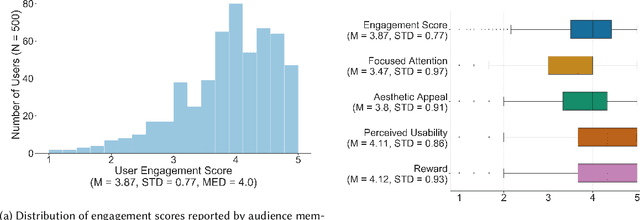
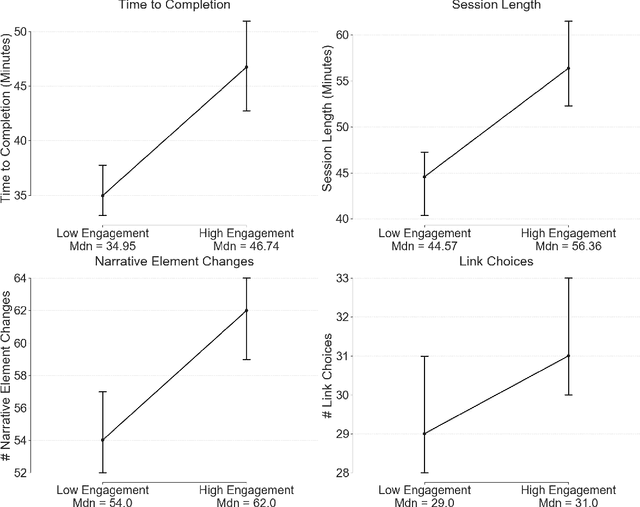
Media is evolving from traditional linear narratives to personalised experiences, where control over information (or how it is presented) is given to individual audience members. Measuring and understanding audience engagement with this media is important in at least two ways: (1) a post-hoc understanding of how engaged audiences are with the content will help production teams learn from experience and improve future productions; (2), this type of media has potential for real-time measures of engagement to be used to enhance the user experience by adapting content on-the-fly. Engagement is typically measured by asking samples of users to self-report, which is time consuming and expensive. In some domains, however, interaction data have been used to infer engagement. Fortuitously, the nature of interactive media facilitates a much richer set of interaction data than traditional media; our research aims to understand if these data can be used to infer audience engagement. In this paper, we report a study using data captured from audience interactions with an interactive TV show to model and predict engagement. We find that temporal metrics, including overall time spent on the experience and the interval between events, are predictive of engagement. The results demonstrate that interaction data can be used to infer users' engagement during and after an experience, and the proposed techniques are relevant to better understand audience preference and responses.
MetaICL: Learning to Learn In Context
Oct 29, 2021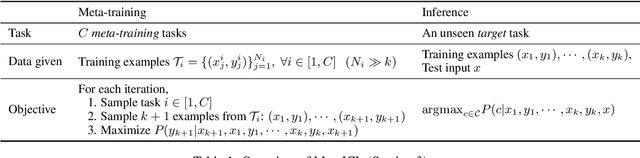
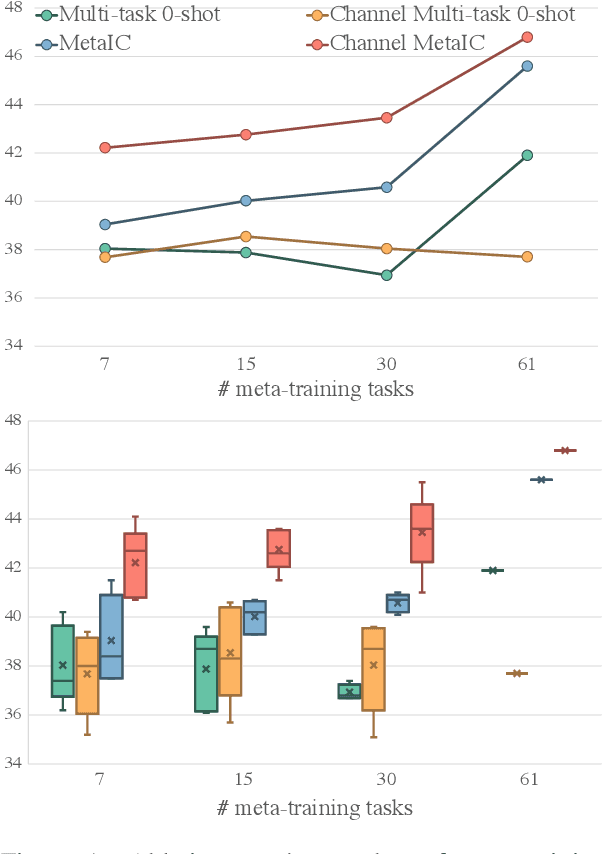
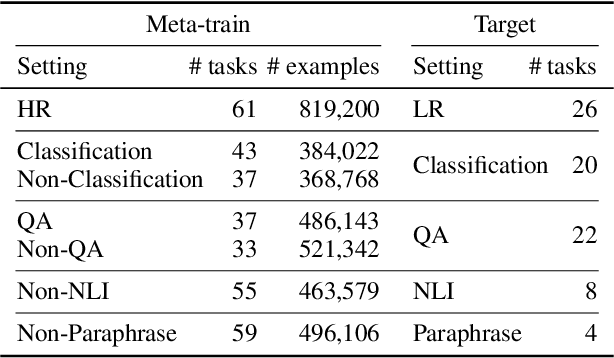
We introduce MetaICL (Meta-training for In-Context Learning), a new meta-training framework for few-shot learning where a pretrained language model is tuned to do in-context learn-ing on a large set of training tasks. This meta-training enables the model to more effectively learn a new task in context at test time, by simply conditioning on a few training examples with no parameter updates or task-specific templates. We experiment on a large, diverse collection of tasks consisting of 142 NLP datasets including classification, question answering, natural language inference, paraphrase detection and more, across seven different meta-training/target splits. MetaICL outperforms a range of baselines including in-context learning without meta-training and multi-task learning followed by zero-shot transfer. We find that the gains are particularly significant for target tasks that have domain shifts from the meta-training tasks, and that using a diverse set of the meta-training tasks is key to improvements. We also show that MetaICL approaches (and sometimes beats) the performance of models fully finetuned on the target task training data, and outperforms much bigger models with nearly 8x parameters.
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021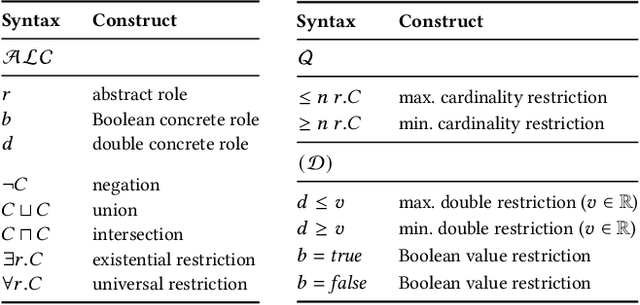
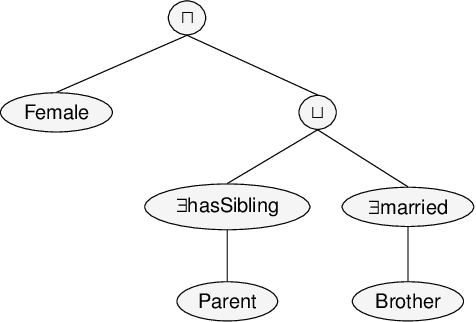
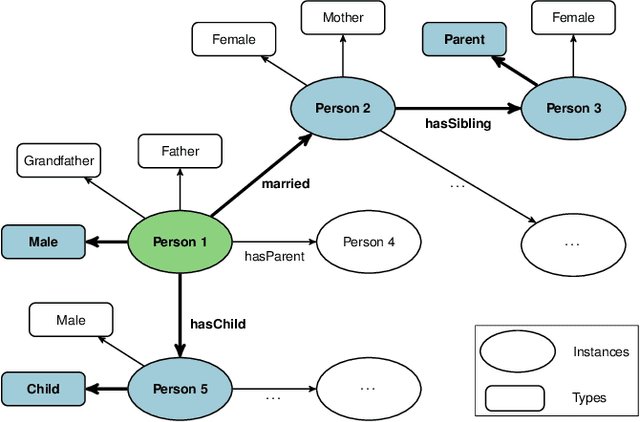
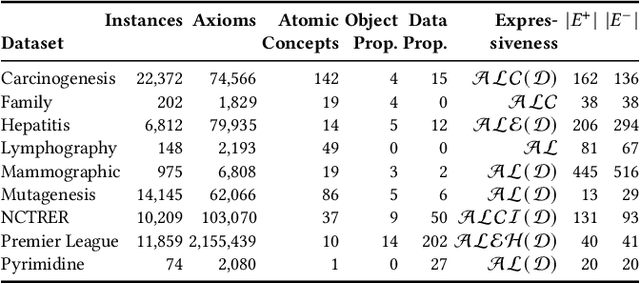
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021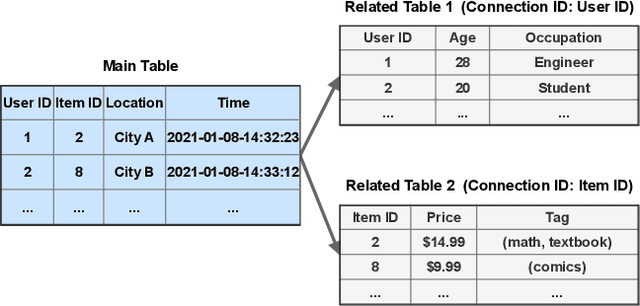

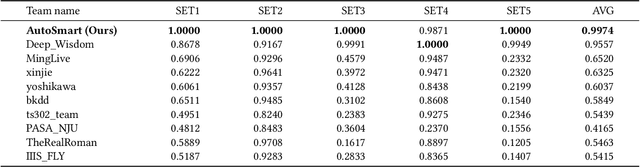
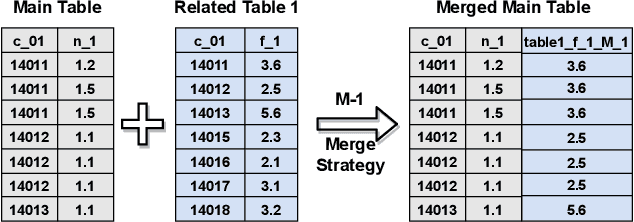
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.
A Realistic Example in 2 Dimension that Gradient Descent Takes Exponential Time to Escape Saddle Points
Aug 17, 2020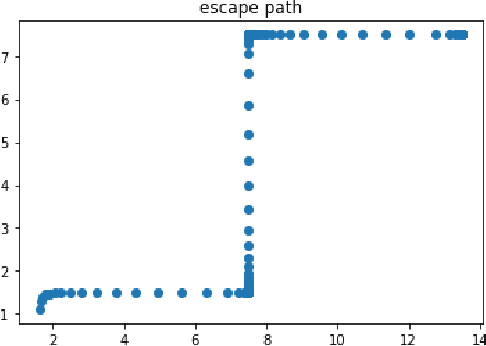
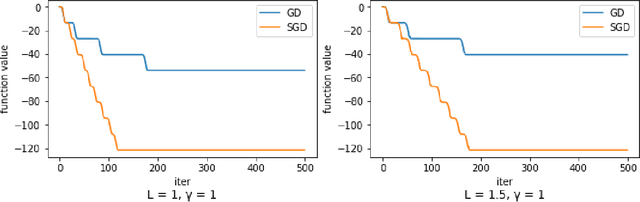
Gradient descent is a popular algorithm in optimization, and its performance in convex settings is mostly well understood. In non-convex settings, it has been shown that gradient descent is able to escape saddle points asymptotically and converge to local minimizers [Lee et. al. 2016]. Recent studies also show a perturbed version of gradient descent is enough to escape saddle points efficiently [Jin et. al. 2015, Ge et. al. 2017]. In this paper we show a negative result: gradient descent may take exponential time to escape saddle points, with non-pathological two dimensional functions. While our focus is theoretical, we also conduct experiments verifying our theoretical result. Through our analysis we demonstrate that stochasticity is essential to escape saddle points efficiently.
MCTS Based Agents for Multistage Single-Player Card Game
Sep 24, 2021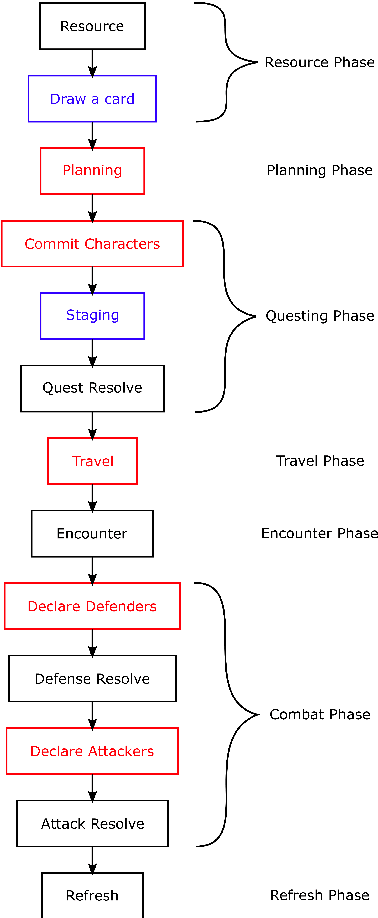
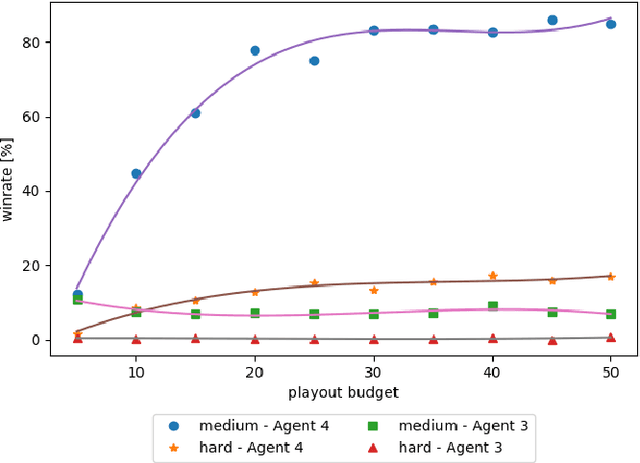
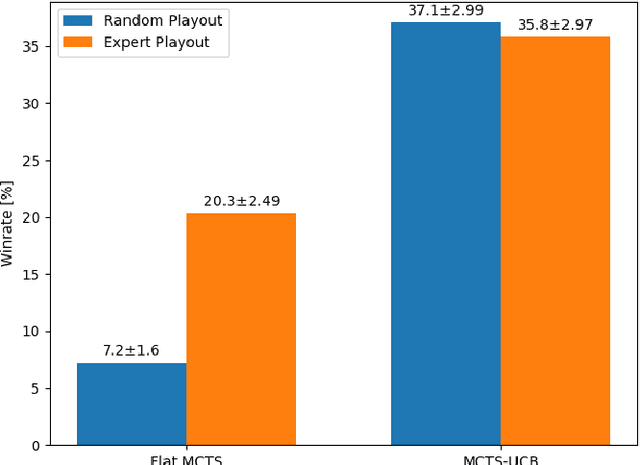
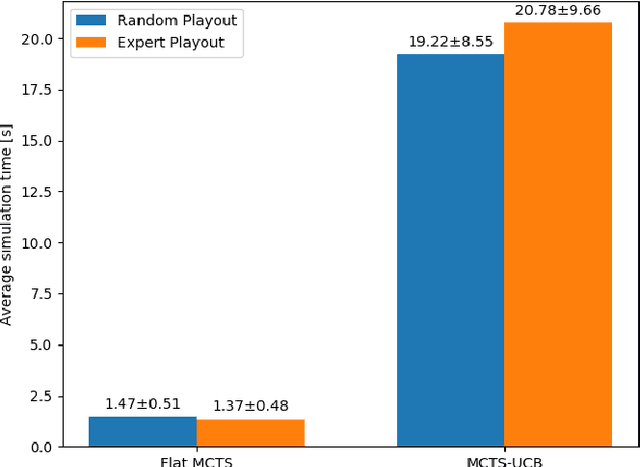
The article presents the use of Monte Carlo Tree Search algorithms for the card game Lord of the Rings. The main challenge was the complexity of the game mechanics, in which each round consists of 5 decision stages and 2 random stages. To test various decision-making algorithms, a game simulator has been implemented. The research covered an agent based on expert rules, using flat Monte-Carlo search, as well as complete MCTS-UCB. Moreover different playout strategies has been compared. As a result of experiments, an optimal (assuming a limited time) combination of algorithms were formulated. The developed MCTS based method have demonstrated a advantage over agent with expert knowledge.
Physics-Informed Neural Networks (PINNs) for Sound Field Predictions with Parameterized Sources and Impedance Boundaries
Sep 24, 2021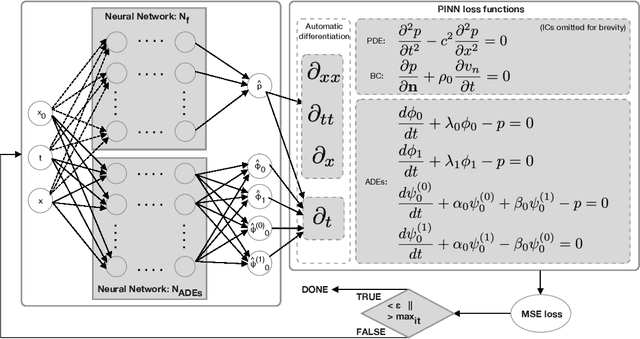

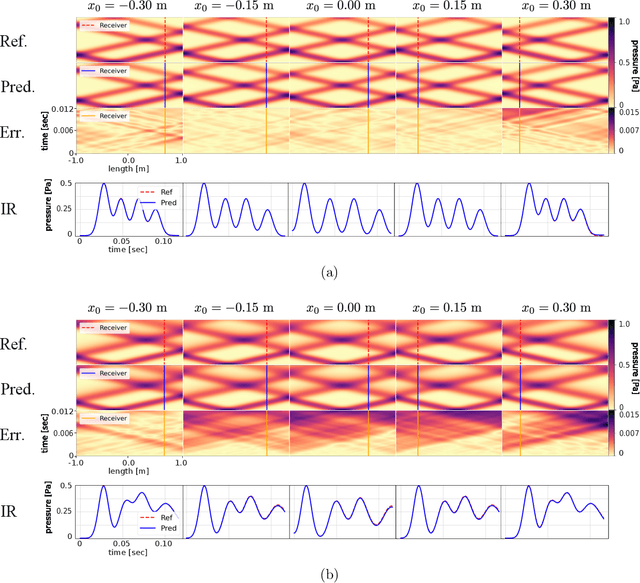
Realistic sound is essential in virtual environments, such as computer games and mixed reality. Efficient and accurate numerical methods for pre-calculating acoustics have been developed over the last decade, however, pre-calculating acoustics makes handling dynamic scenes with moving sources challenging and requires intractable memory storage. A Physics-Informed Neural Networks (PINNS) method is presented, learning a compact and efficient surrogate model with parameterized moving sources and impedance boundaries, satisfying a system of coupled equations. The trained model shows relative mean errors below 2%/0.2 dB, indicating that acoustics with moving sources and impedance boundaries can be predicted in real-time using PINNs.
The eDiscovery Medicine Show
Sep 28, 2021The practice of bloodletting gradually fell into disfavor as a growing body of scientific evidence showed its ineffectiveness and demonstrated the effectiveness of various pharmaceuticals for the prevention and treatment of certain diseases. At the same time, the patent medicine industry promoted ineffective remedies at medicine shows featuring entertainment, testimonials, and pseudo-scientific claims with all the trappings--but none of the methodology--of science. Today, many producing parties and eDiscovery vendors similarly promote obsolete technology as well as unvetted tools labeled "artificial intelligence" or "technology-assisted review," along with unsound validation protocols. This situation will end only when eDiscovery technologies and tools are subject to testing using the methods of information retrieval.