 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coupled Oscillatory Recurrent Neural Network (coRNN): An accurate and (gradient) stable architecture for learning long time dependencies
Oct 02, 2020
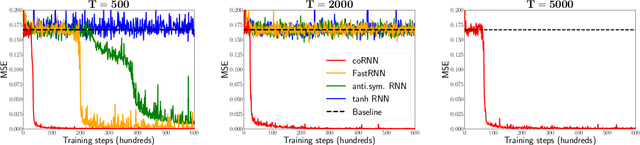
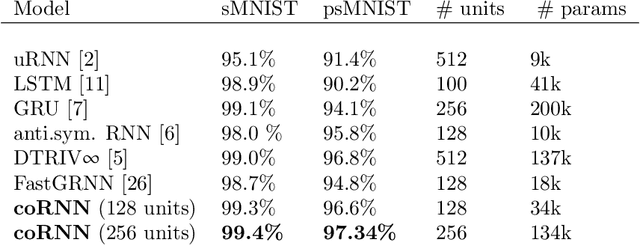
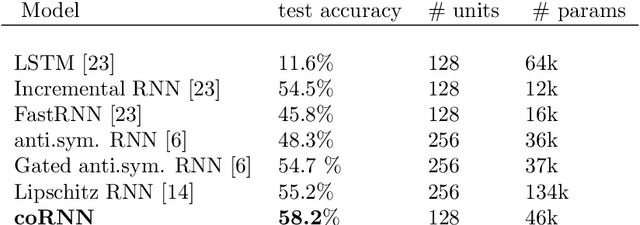
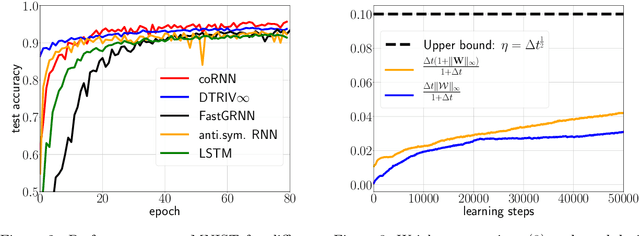
Circuits of biological neurons, such as in the functional parts of the brain can be modeled as networks of coupled oscillators. Inspired by the ability of these systems to express a rich set of outputs while keeping (gradients of) state variables bounded, we propose a novel architecture for recurrent neural networks. Our proposed RNN is based on a time-discretization of a system of second-order ordinary differential equations, modeling networks of controlled nonlinear oscillators. We prove precise bounds on the gradients of the hidden states, leading to the mitigation of the exploding and vanishing gradient problem for this RNN. Experiments show that the proposed RNN is comparable in performance to the state of the art on a variety of benchmarks, demonstrating the potential of this architecture to provide stable and accurate RNNs for processing complex sequential data.
Data-Driven Adaptive Network Slicing for Multi-Tenant Networks
Jun 07, 2021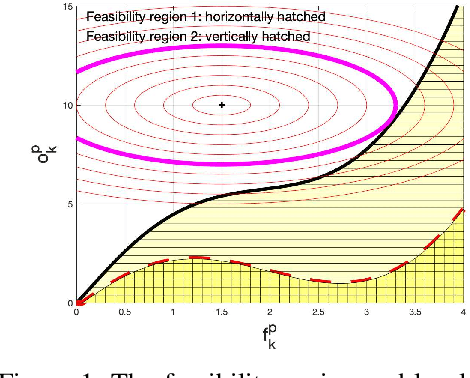
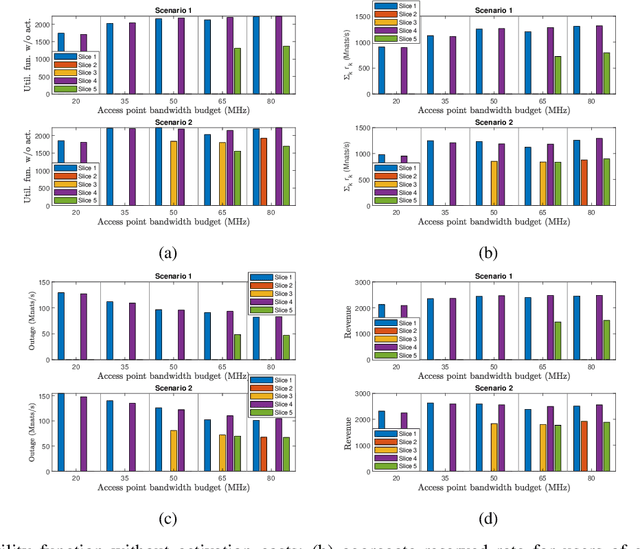
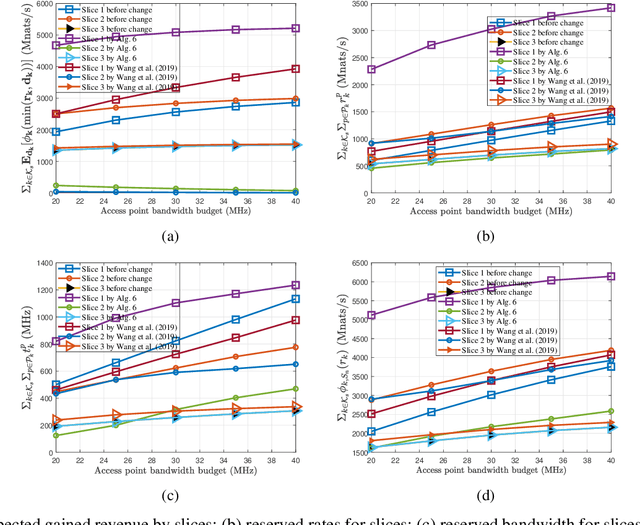

Network slicing to support multi-tenancy plays a key role in improving the performance of 5G networks. In this paper, we propose a two time-scale framework for the reservation-based network slicing in the backhaul and Radio Access Network (RAN). In the proposed two time-scale scheme, a subset of network slices is activated via a novel sparse optimization framework in the long time-scale with the goal of maximizing the expected utilities of tenants while in the short time-scale the activated slices are reconfigured according to the time-varying user traffic and channel states. Specifically, using the statistics from users and channels and also considering the expected utility from serving users of a slice and the reconfiguration cost, we formulate a sparse optimization problem to update the configuration of a slice resources such that the maximum isolation of reserved resources is enforced. The formulated optimization problems for long and short time-scales are non-convex and difficult to solve. We use the $\ell_q$-norm, $0<q<1$, and group LASSO regularizations to iteratively find convex approximations of the optimization problems. We propose a Frank-Wolfe algorithm to iteratively solve approximated problems in long time-scales. To cope with the dynamical nature of traffic variations, we propose a fast, distributed algorithm to solve the approximated optimization problems in short time-scales. Simulation results demonstrate the performance of our approaches relative to optimal solutions and the existing state of the art method.
Evolving-Graph Gaussian Processes
Jun 29, 2021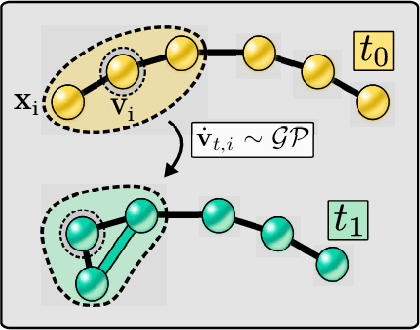
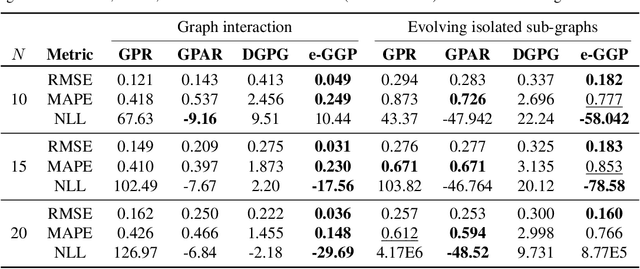
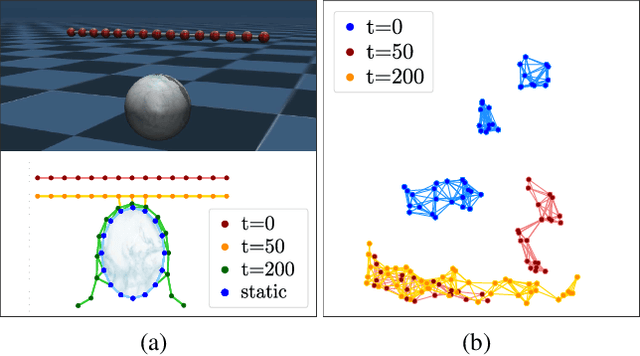

Graph Gaussian Processes (GGPs) provide a data-efficient solution on graph structured domains. Existing approaches have focused on static structures, whereas many real graph data represent a dynamic structure, limiting the applications of GGPs. To overcome this we propose evolving-Graph Gaussian Processes (e-GGPs). The proposed method is capable of learning the transition function of graph vertices over time with a neighbourhood kernel to model the connectivity and interaction changes between vertices. We assess the performance of our method on time-series regression problems where graphs evolve over time. We demonstrate the benefits of e-GGPs over static graph Gaussian Process approaches.
MaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Nov 21, 2021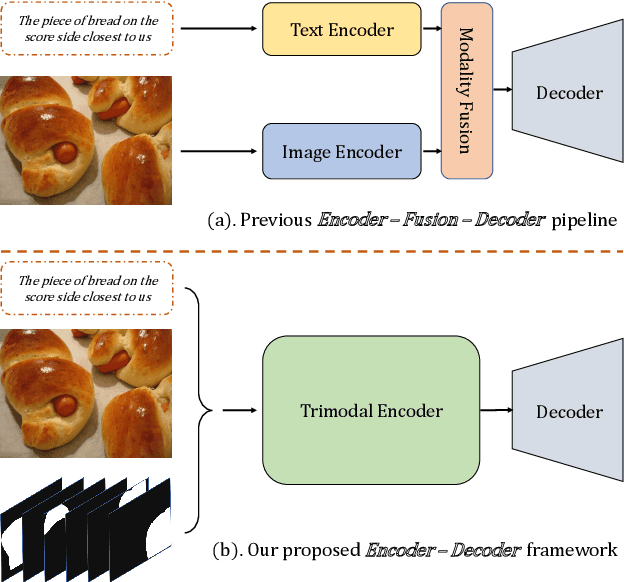
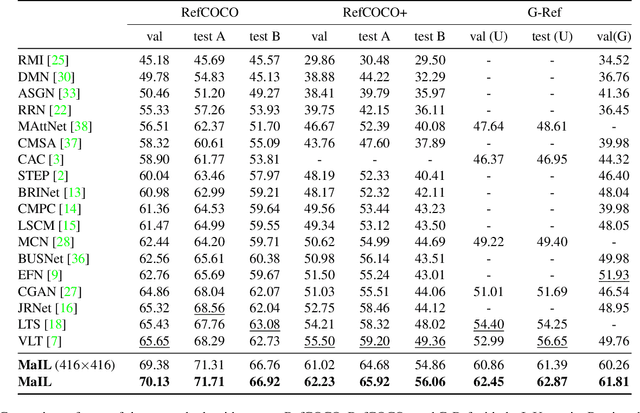
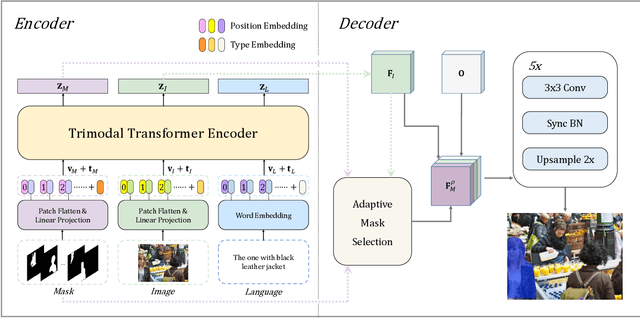
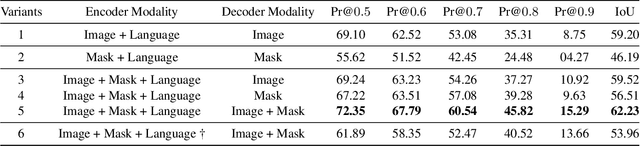
Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
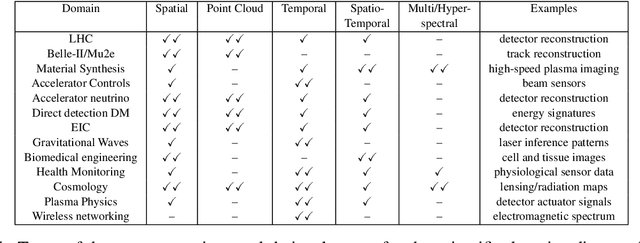
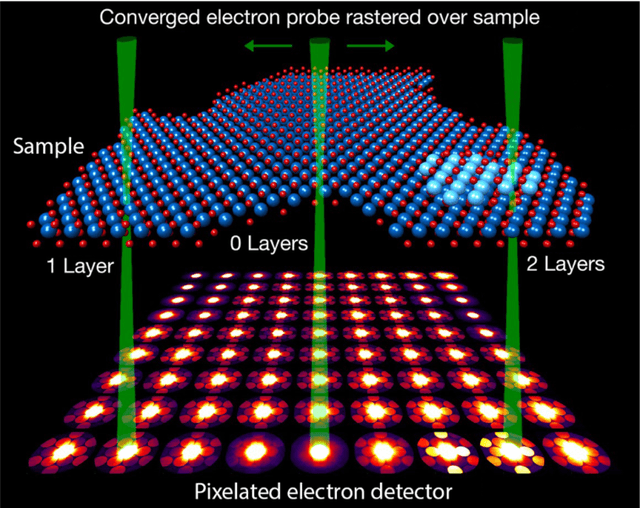
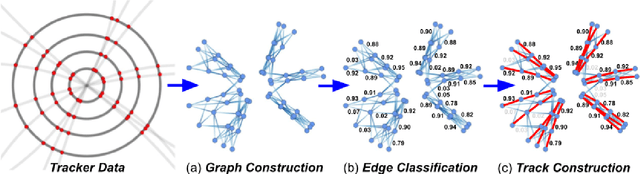
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Hybrid Analog and Digital Beamforming Design for Channel Estimation in Correlated Massive MIMO Systems
Jul 15, 2021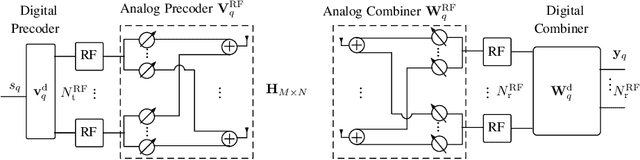
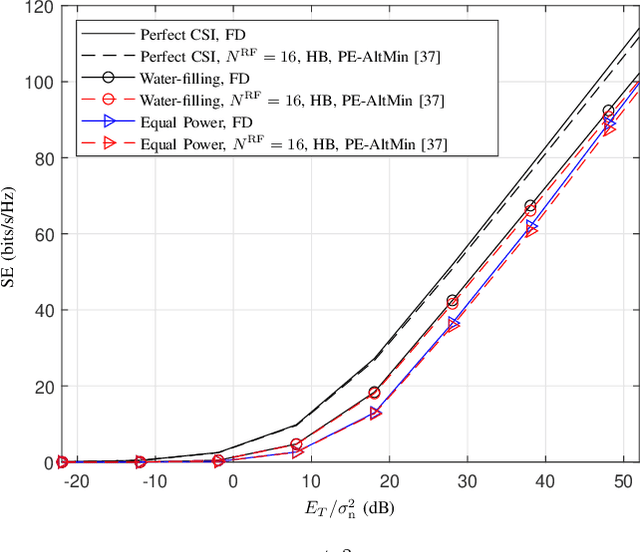
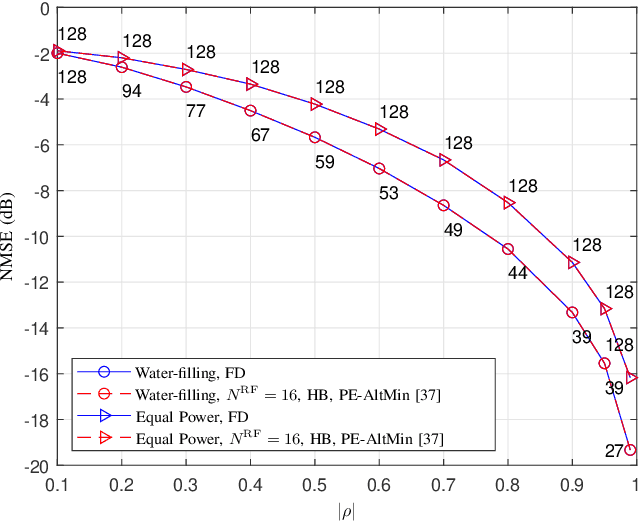
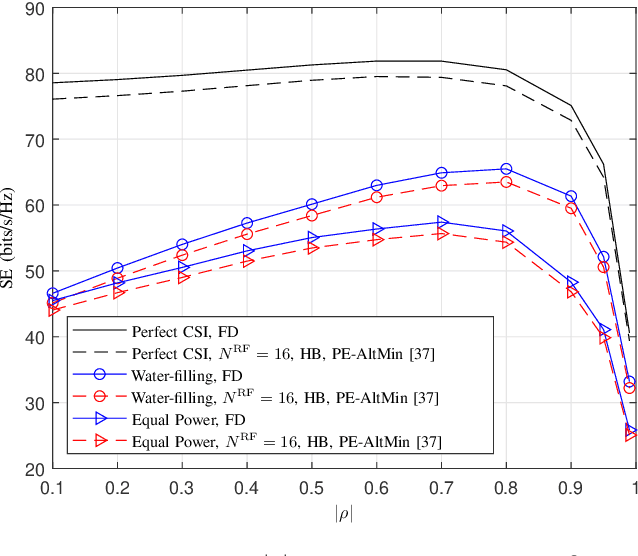
In this paper, we study the channel estimation problem in correlated massive multiple-input-multiple-output (MIMO) systems with a reduced number of radio-frequency (RF) chains. Importantly, other than the knowledge of channel correlation matrices, we make no assumption as to the structure of the channel. To address the limitation in the number of RF chains, we employ hybrid beamforming, comprising a low dimensional digital beamformer followed by an analog beamformer implemented using phase shifters. Since there is no dedicated RF chain per transmitter/receiver antenna, the conventional channel estimation techniques for fully-digital systems are impractical. By exploiting the fact that the channel entries are uncorrelated in its eigen-domain, we seek to estimate the channel entries in this domain. Due to the limited number of RF chains, channel estimation is typically performed in multiple time slots. Under a total energy budget, we aim to design the hybrid transmit beamformer (precoder) and the receive beamformer (combiner) in each training time slot, in order to estimate the channel using the minimum mean squared error criterion. To this end, we choose the precoder and combiner in each time slot such that they are aligned to transmitter and receiver eigen-directions, respectively. Further, we derive a water-filling-type expression for the optimal energy allocation at each time slot. This expression illustrates that, with a low training energy budget, only significant components of the channel need to be estimated. In contrast, with a large training energy budget, the energy is almost equally distributed among all eigen-directions. Simulation results show that the proposed channel estimation scheme can efficiently estimate correlated massive MIMO channels within a few training time slots.
Demystifying Deep Learning Models for Retinal OCT Disease Classification using Explainable AI
Nov 06, 2021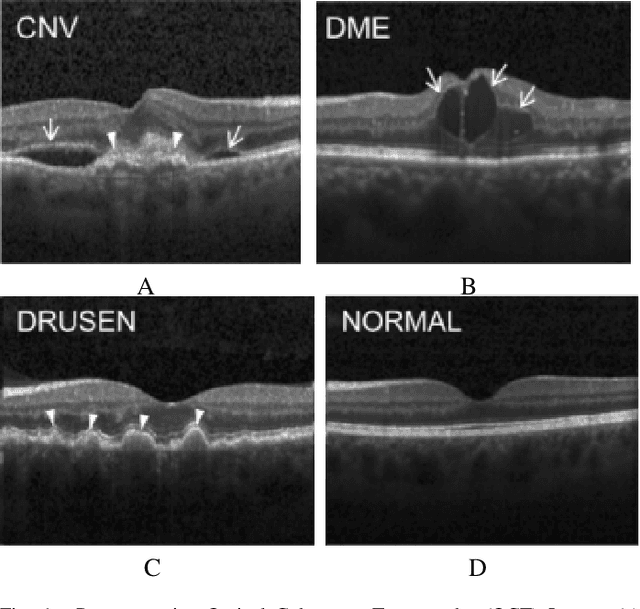
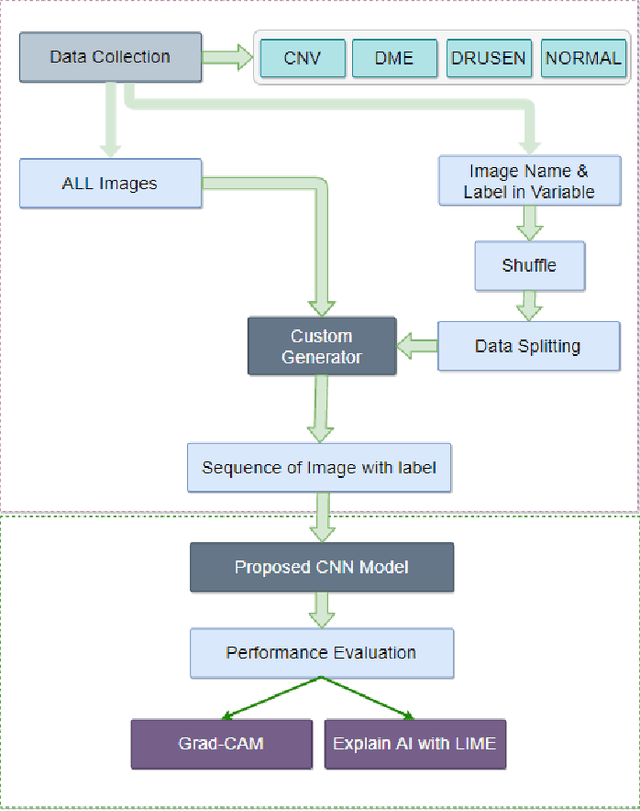
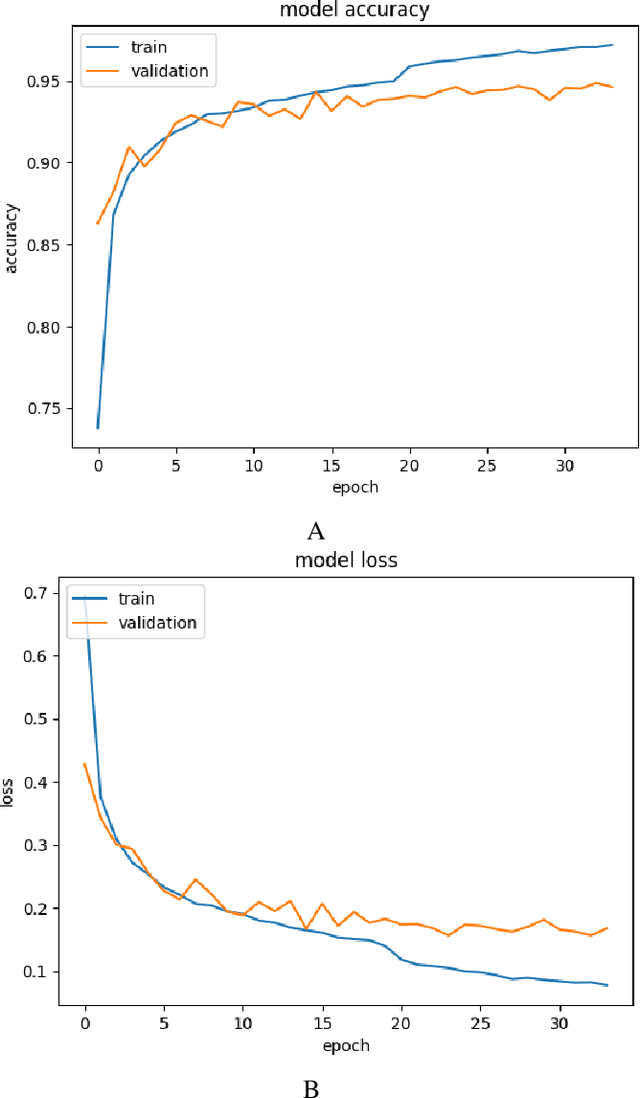
In the world of medical diagnostics, the adoption of various deep learning techniques is quite common as well as effective, and its statement is equally true when it comes to implementing it into the retina Optical Coherence Tomography (OCT) sector, but (i)These techniques have the black box characteristics that prevent the medical professionals to completely trust the results generated from them (ii)Lack of precision of these methods restricts their implementation in clinical and complex cases (iii)The existing works and models on the OCT classification are substantially large and complicated and they require a considerable amount of memory and computational power, reducing the quality of classifiers in real-time applications. To meet these problems, in this paper a self-developed CNN model has been proposed which is comparatively smaller and simpler along with the use of Lime that introduces Explainable AI to the study and helps to increase the interpretability of the model. This addition will be an asset to the medical experts for getting major and detailed information and will help them in making final decisions and will also reduce the opacity and vulnerability of the conventional deep learning models.
Optimization-Based GenQSGD for Federated Edge Learning
Oct 25, 2021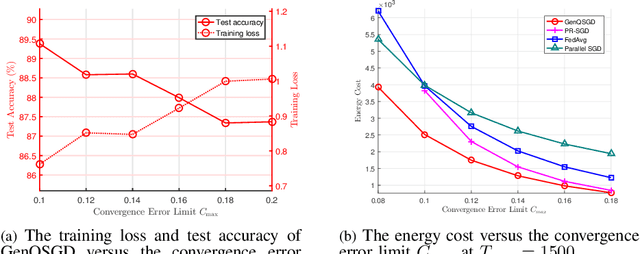
Optimal algorithm design for federated learning (FL) remains an open problem. This paper explores the full potential of FL in practical edge computing systems where workers may have different computation and communication capabilities, and quantized intermediate model updates are sent between the server and workers. First, we present a general quantized parallel mini-batch stochastic gradient descent (SGD) algorithm for FL, namely GenQSGD, which is parameterized by the number of global iterations, the numbers of local iterations at all workers, and the mini-batch size. We also analyze its convergence error for any choice of the algorithm parameters. Then, we optimize the algorithm parameters to minimize the energy cost under the time constraint and convergence error constraint. The optimization problem is a challenging non-convex problem with non-differentiable constraint functions. We propose an iterative algorithm to obtain a KKT point using advanced optimization techniques. Numerical results demonstrate the significant gains of GenQSGD over existing FL algorithms and reveal the importance of optimally designing FL algorithms.
HSVI fo zs-POSGs using Concavity, Convexity and Lipschitz Properties
Oct 25, 2021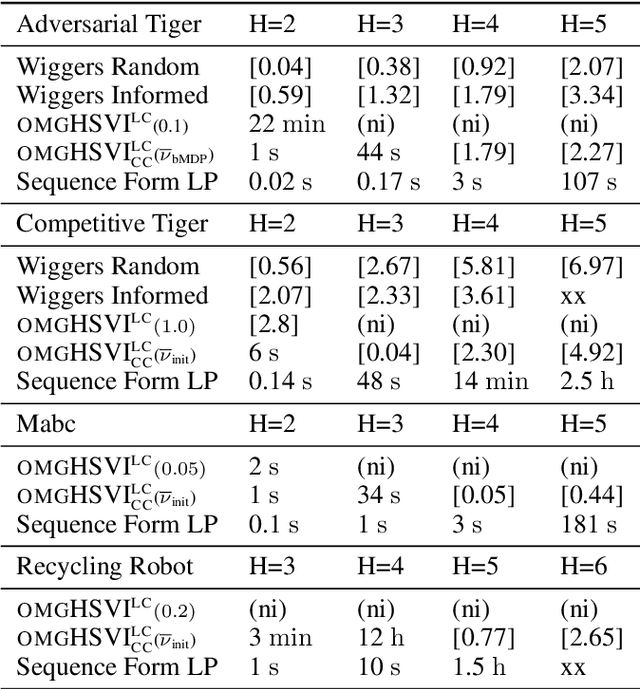
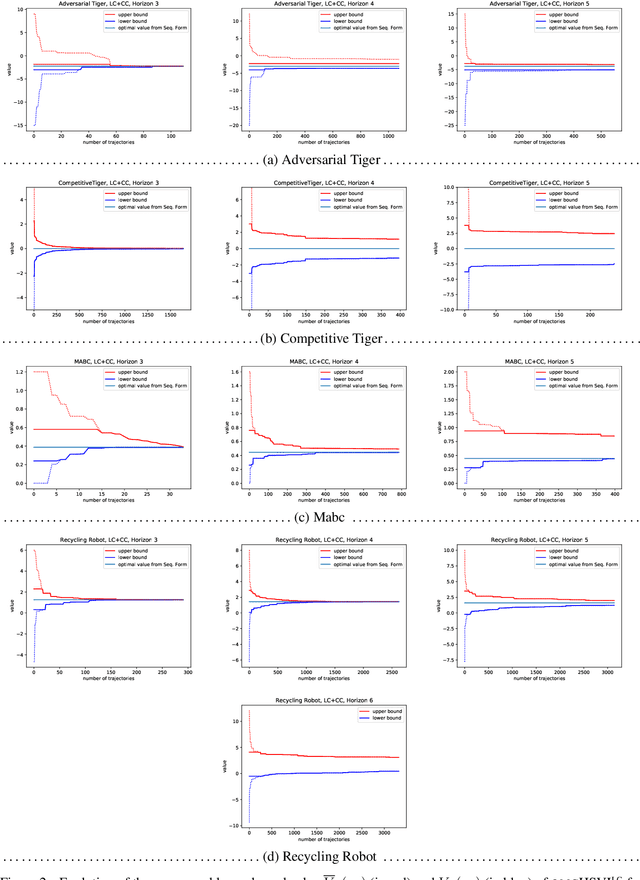
Dynamic programming and heuristic search are at the core of state-of-the-art solvers for sequential decision-making problems. In partially observable or collaborative settings (\eg, POMDPs and Dec-POMDPs), this requires introducing an appropriate statistic that induces a fully observable problem as well as bounding (convex) approximators of the optimal value function. This approach has succeeded in some subclasses of 2-player zero-sum partially observable stochastic games (zs-POSGs) as well, but failed in the general case despite known concavity and convexity properties, which only led to heuristic algorithms with poor convergence guarantees. We overcome this issue, leveraging on these properties to derive bounding approximators and efficient update and selection operators, before deriving a prototypical solver inspired by HSVI that provably converges to an $\epsilon$-optimal solution in finite time, and which we empirically evaluate. This opens the door to a novel family of promising approaches complementing those relying on linear programming or iterative methods.
FMA-ETA: Estimating Travel Time Entirely Based on FFN With Attention
Jun 07, 2020
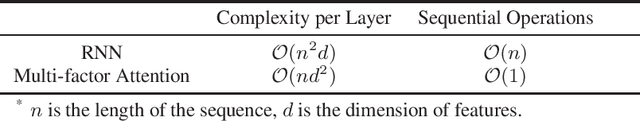
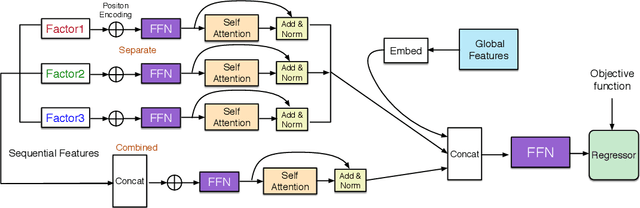
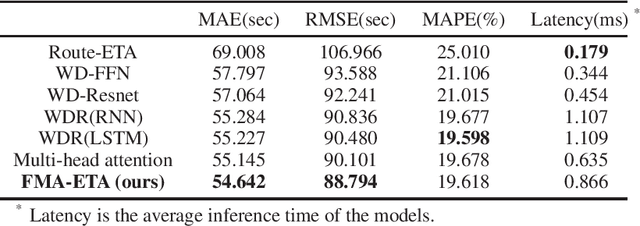
Estimated time of arrival (ETA) is one of the most important services in intelligent transportation systems and becomes a challenging spatial-temporal (ST) data mining task in recent years. Nowadays, deep learning based methods, specifically recurrent neural networks (RNN) based ones are adapted to model the ST patterns from massive data for ETA and become the state-of-the-art. However, RNN is suffering from slow training and inference speed, as its structure is unfriendly to parallel computing. To solve this problem, we propose a novel, brief and effective framework mainly based on feed-forward network (FFN) for ETA, FFN with Multi-factor self-Attention (FMA-ETA). The novel Multi-factor self-attention mechanism is proposed to deal with different category features and aggregate the information purposefully. Extensive experimental results on the real-world vehicle travel dataset show FMA-ETA is competitive with state-of-the-art methods in terms of the prediction accuracy with significantly better inference speed.