 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Vehicle Routing Problems with Soft Time Windows: A Multi-Agent Reinforcement Learning Approach
Feb 13, 2020
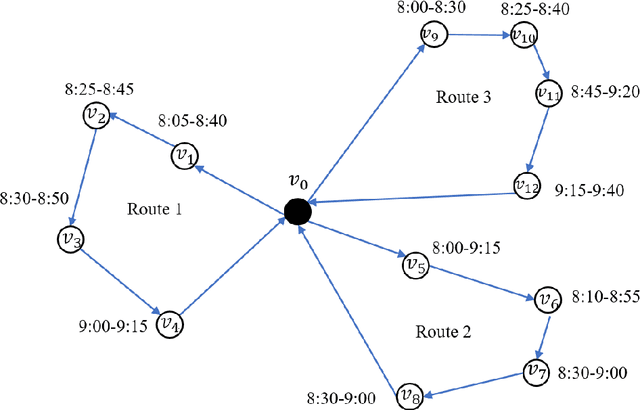
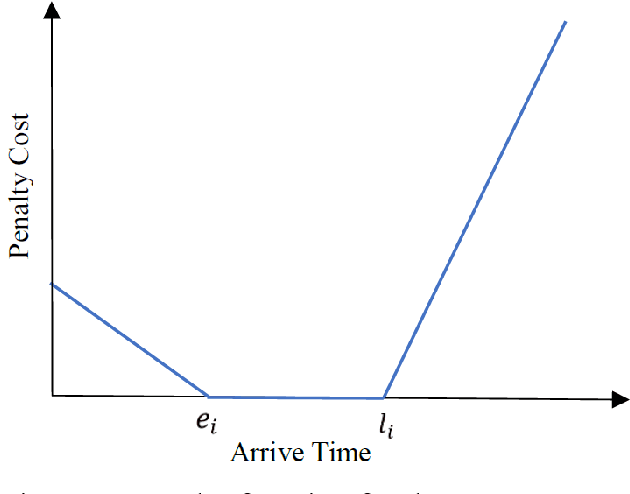
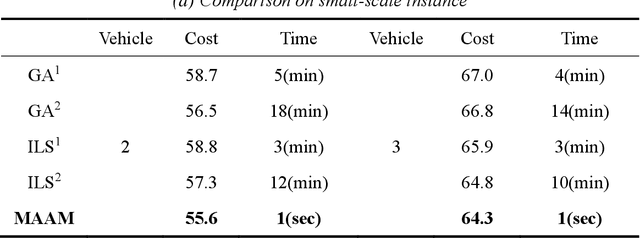
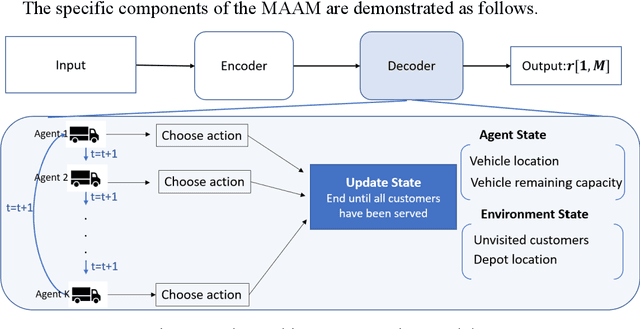
Multi-vehicle routing problem with soft time windows (MVRPSTW) is an indispensable constituent in urban logistics distribution system. In the last decade, numerous methods for MVRPSTW have sprung up, but most of them are based on heuristic rules which require huge computation time. With the rapid increasing of logistics demand, traditional methods incur the dilemma of computation efficiency. To efficiently solve the problem, we propose a novel reinforcement learning algorithm named Multi-Agent Attention Model in this paper. Specifically, the vehicle routing problem is regarded as a vehicle tour generation process, and an encoder-decoder framework with attention layers is proposed to generate tours of multiple vehicles iteratively. Furthermore, a multi-agent reinforcement learning method with an unsupervised auxiliary network is developed for model training. By evaluated on three synthetic networks with different scale, the results demonstrate that the proposed method consistently outperforms traditional methods with little computation time. In addition, we validate the extensibility of the well-trained model by varying the number of customers and capacity of vehicles. Finally, the impact of parameters settings on the algorithmic performance are investigated.
Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Oct 11, 2021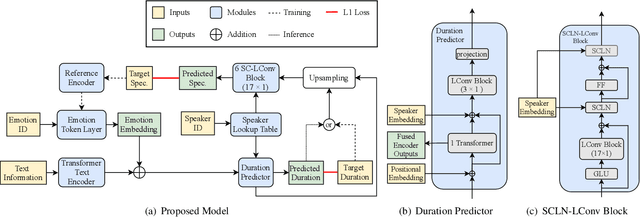
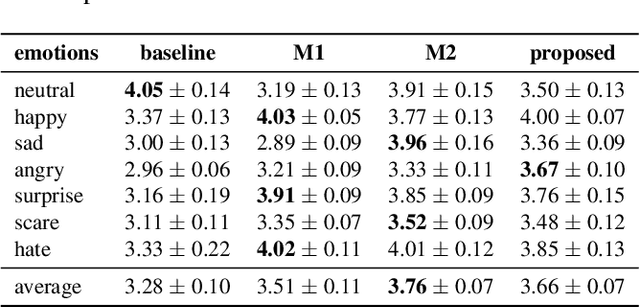
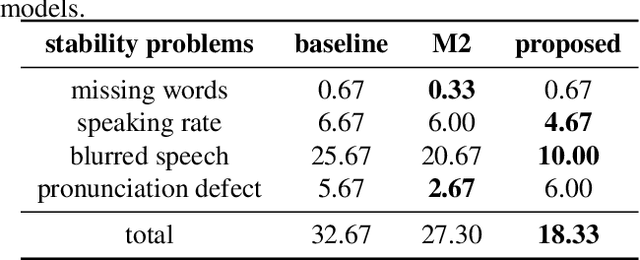
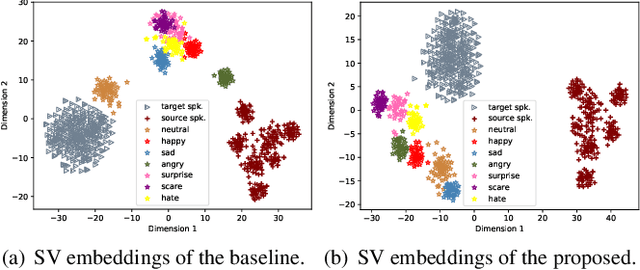
In expressive speech synthesis, there are high requirements for emotion interpretation. However, it is time-consuming to acquire emotional audio corpus for arbitrary speakers due to their deduction ability. In response to this problem, this paper proposes a cross-speaker emotion transfer method that can realize the transfer of emotions from source speaker to target speaker. A set of emotion tokens is firstly defined to represent various categories of emotions. They are trained to be highly correlated with corresponding emotions for controllable synthesis by cross-entropy loss and semi-supervised training strategy. Meanwhile, to eliminate the down-gradation to the timbre similarity from cross-speaker emotion transfer, speaker condition layer normalization is implemented to model speaker characteristics. Experimental results show that the proposed method outperforms the multi-reference based baseline in terms of timbre similarity, stability and emotion perceive evaluations.
Precision and Recall for Time Series
Oct 28, 2018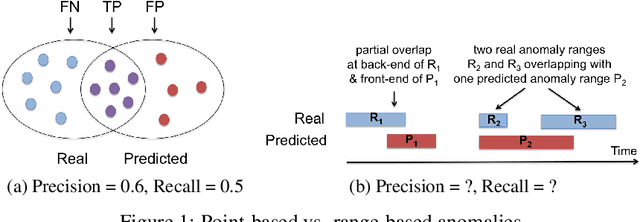


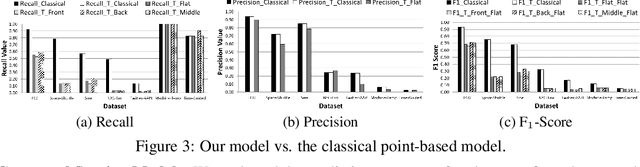
Classical anomaly detection is principally concerned with point-based anomalies, those anomalies that occur at a single point in time. Yet, many real-world anomalies are range-based, meaning they occur over a period of time. Motivated by this observation, we present a new mathematical model to evaluate the accuracy of time series classification algorithms. Our model expands the well-known Precision and Recall metrics to measure ranges, while simultaneously enabling customization support for domain-specific preferences.
Time-Sensitive Networking for robotics
Sep 11, 2018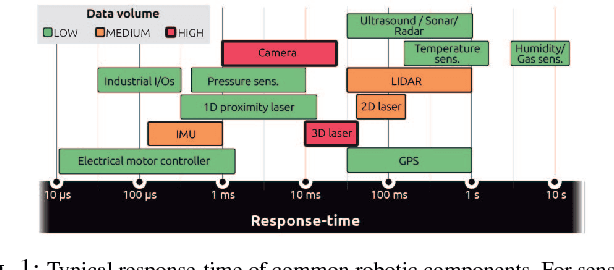
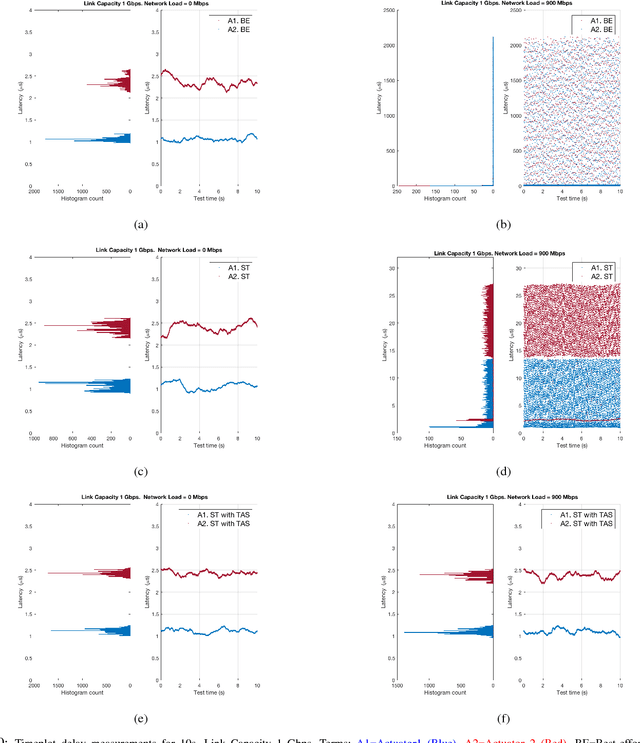
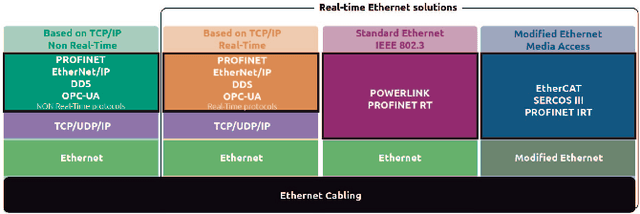
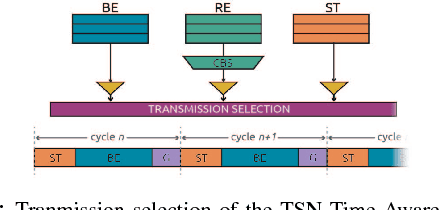
We argue that Time-Sensitive Networking (TSN) will become the de facto standard for real-time communications in robotics. We present a review and classification of the different communication standards which are relevant for the field and introduce the typical problems with traditional switched Ethernet networks. We discuss some of the TSN features relevant for deterministic communications and evaluate experimentally one of the shaping mechanisms in an exemplary robotic scenario. In particular, and based on our results, we claim that many of the existing real-time industrial solutions will slowly be replaced by TSN. And that this will lead towards a unified landscape of physically interoperable robot and robot components.
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021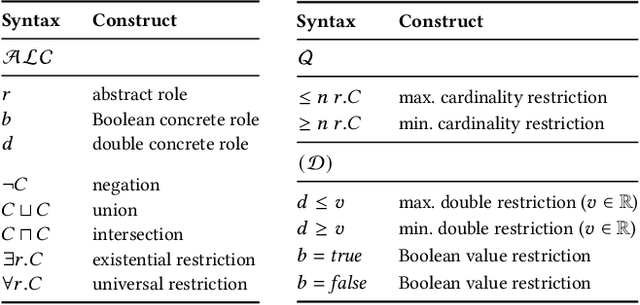
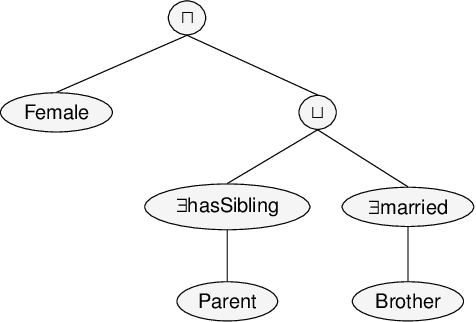
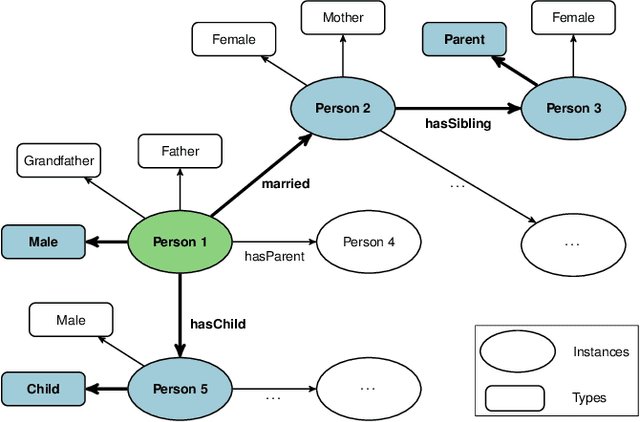
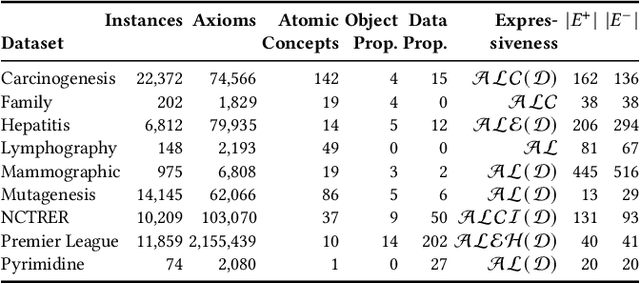
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.
Order Constraints in Optimal Transport
Oct 14, 2021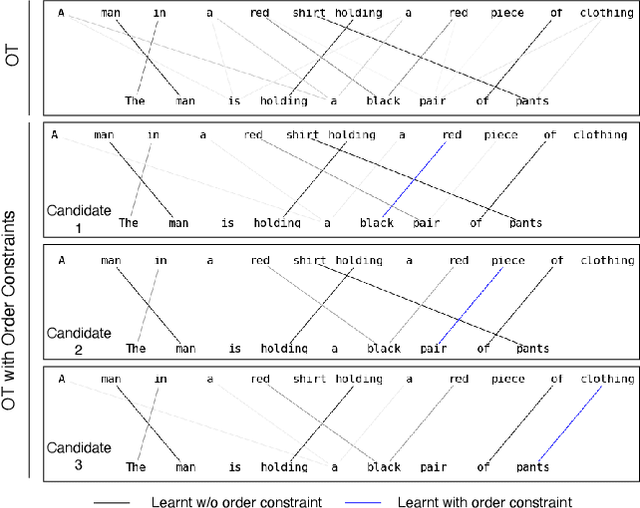

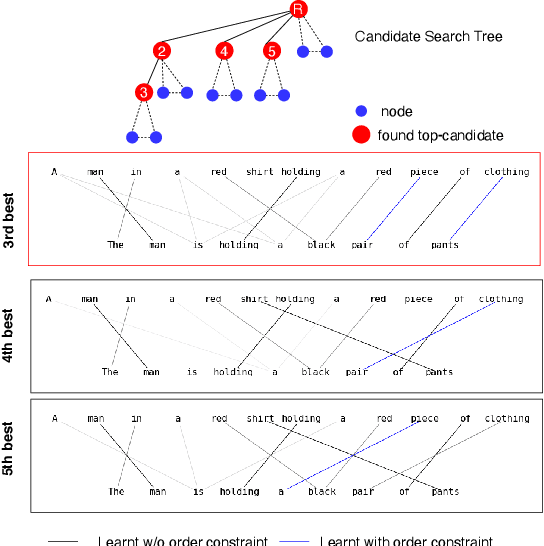
Optimal transport is a framework for comparing measures whereby a cost is incurred for transporting one measure to another. Recent works have aimed to improve optimal transport plans through the introduction of various forms of structure. We introduce novel order constraints into the optimal transport formulation to allow for the incorporation of structure. While there will are now quadratically many constraints as before, we prove a $\delta-$approximate solution to the order-constrained optimal transport problem can be obtained in $\mathcal{O}(L^2\delta^{-2} \kappa(\delta(2cL_\infty (1+(mn)^{1/2}))^{-1}) \cdot mn\log mn)$ time. We derive computationally efficient lower bounds that allow for an explainable approach to adding structure to the optimal transport plan through order constraints. We demonstrate experimentally that order constraints improve explainability using the e-SNLI (Stanford Natural Language Inference) dataset that includes human-annotated rationales for each assignment.
EMG-Based Feature Extraction and Classification for Prosthetic Hand Control
Jul 01, 2021
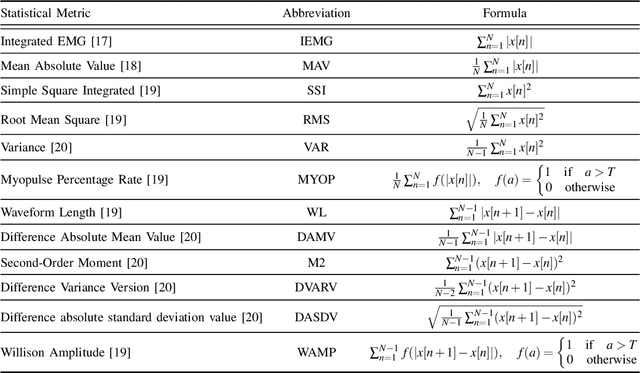
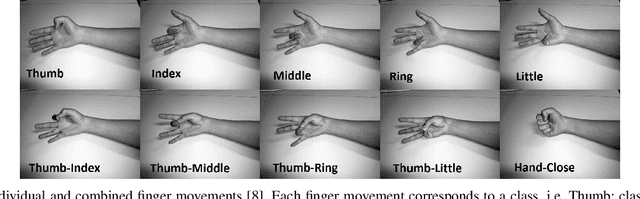

In recent years, real-time control of prosthetic hands has gained a great deal of attention. In particular, real-time analysis of Electromyography (EMG) signals has several challenges to achieve an acceptable accuracy and execution delay. In this paper, we address some of these challenges by improving the accuracy in a shorter signal length. We first introduce a set of new feature extraction functions applying on each level of wavelet decomposition. Then, we propose a postprocessing approach to process the neural network outputs. The experimental results illustrate that the proposed method enhances the accuracy of real-time classification of EMG signals up to $95.5\%$ for $800$ msec signal length. The proposed postprocessing method achieves higher consistency compared with conventional majority voting and Bayesian fusion methods.
Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
Apr 27, 2020
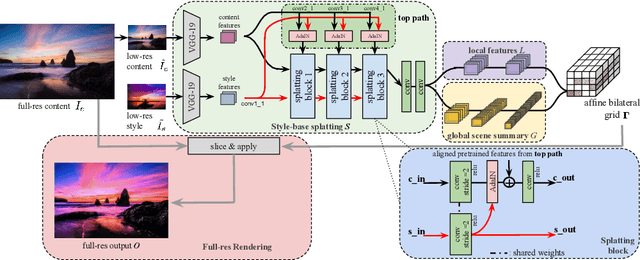


Photorealistic style transfer is the task of transferring the artistic style of an image onto a content target, producing a result that is plausibly taken with a camera. Recent approaches, based on deep neural networks, produce impressive results but are either too slow to run at practical resolutions, or still contain objectionable artifacts. We propose a new end-to-end model for photorealistic style transfer that is both fast and inherently generates photorealistic results. The core of our approach is a feed-forward neural network that learns local edge-aware affine transforms that automatically obey the photorealism constraint. When trained on a diverse set of images and a variety of styles, our model can robustly apply style transfer to an arbitrary pair of input images. Compared to the state of the art, our method produces visually superior results and is three orders of magnitude faster, enabling real-time performance at 4K on a mobile phone. We validate our method with ablation and user studies.
MetaICL: Learning to Learn In Context
Oct 29, 2021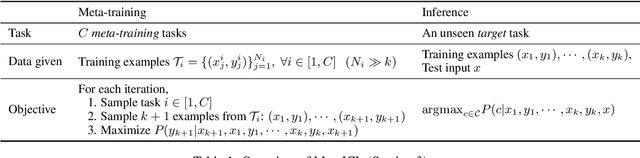
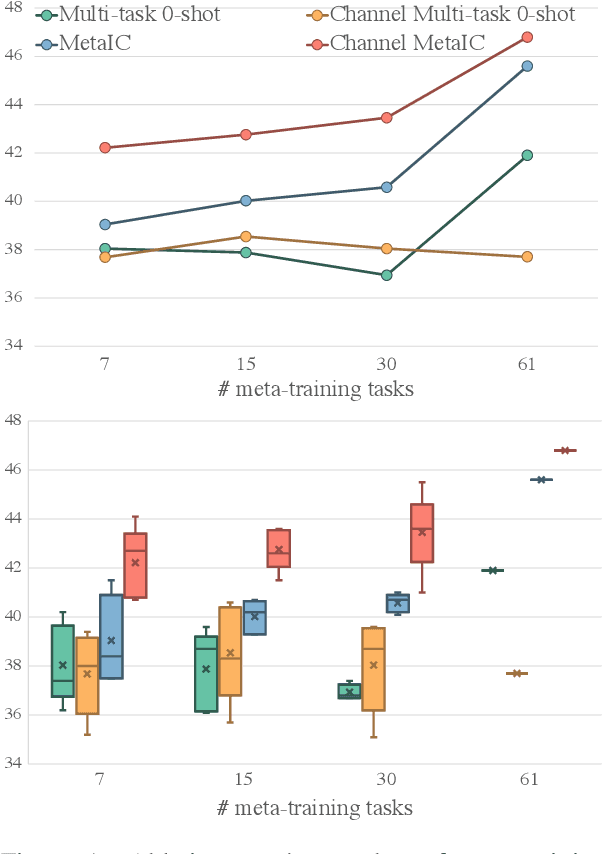
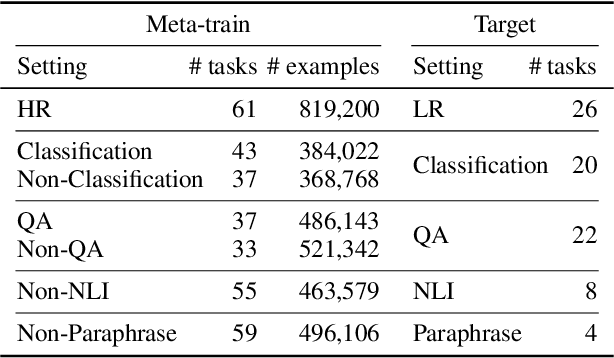
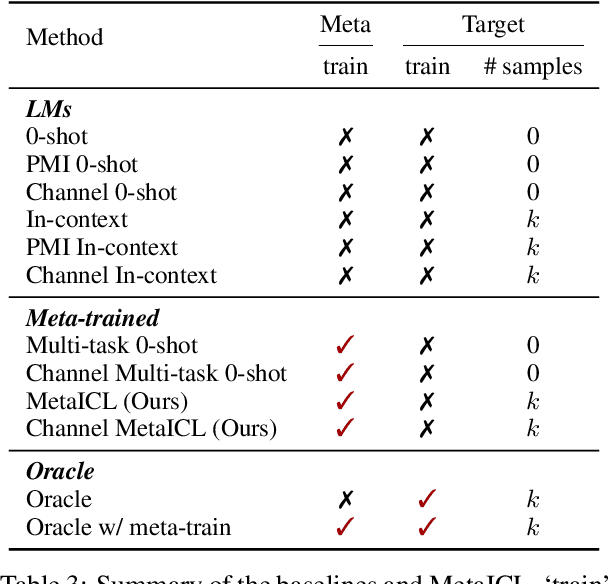
We introduce MetaICL (Meta-training for In-Context Learning), a new meta-training framework for few-shot learning where a pretrained language model is tuned to do in-context learn-ing on a large set of training tasks. This meta-training enables the model to more effectively learn a new task in context at test time, by simply conditioning on a few training examples with no parameter updates or task-specific templates. We experiment on a large, diverse collection of tasks consisting of 142 NLP datasets including classification, question answering, natural language inference, paraphrase detection and more, across seven different meta-training/target splits. MetaICL outperforms a range of baselines including in-context learning without meta-training and multi-task learning followed by zero-shot transfer. We find that the gains are particularly significant for target tasks that have domain shifts from the meta-training tasks, and that using a diverse set of the meta-training tasks is key to improvements. We also show that MetaICL approaches (and sometimes beats) the performance of models fully finetuned on the target task training data, and outperforms much bigger models with nearly 8x parameters.
Improvements in Micro-CT Method for Characterizing X-ray Monocapillary Optics
Jun 28, 2021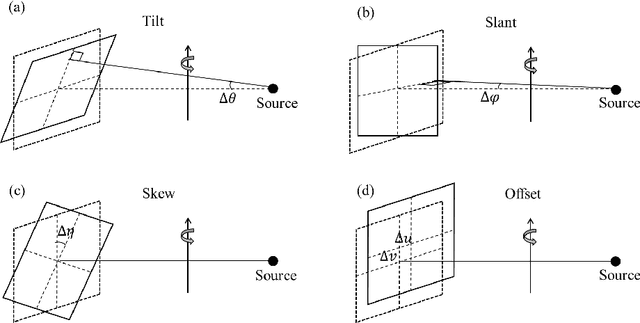
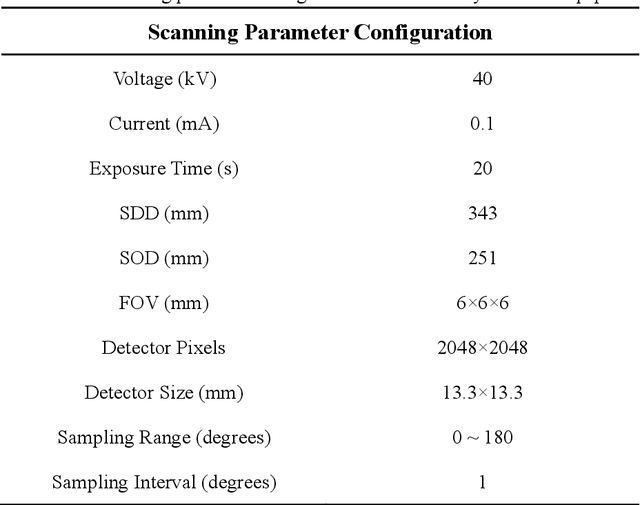
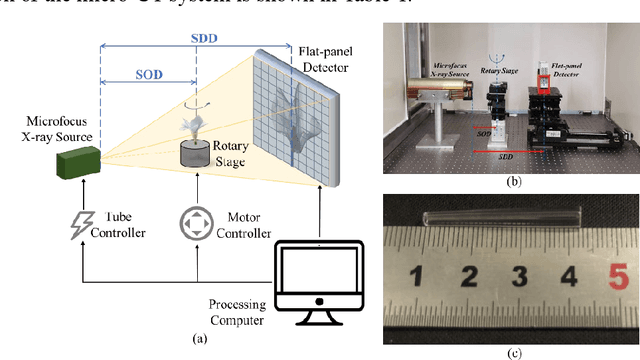

Accurate characterization of the inner surface of X-ray monocapillary optics (XMCO) is of great significance in X-ray optics research. Compared with other characterization methods, the micro computed tomography (micro-CT) method has its unique advantages but also has some disadvantages, such as a long scanning time, long image reconstruction time, and inconvenient scanning process. In this paper, sparse sampling was proposed to shorten the scanning time, GPU acceleration technology was used to improve the speed of image reconstruction, and a simple geometric calibration algorithm was proposed to avoid the calibration phantom and simplify the scanning process. These methodologies will popularize the use of the micro-CT method in XMCO characterization.