 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021

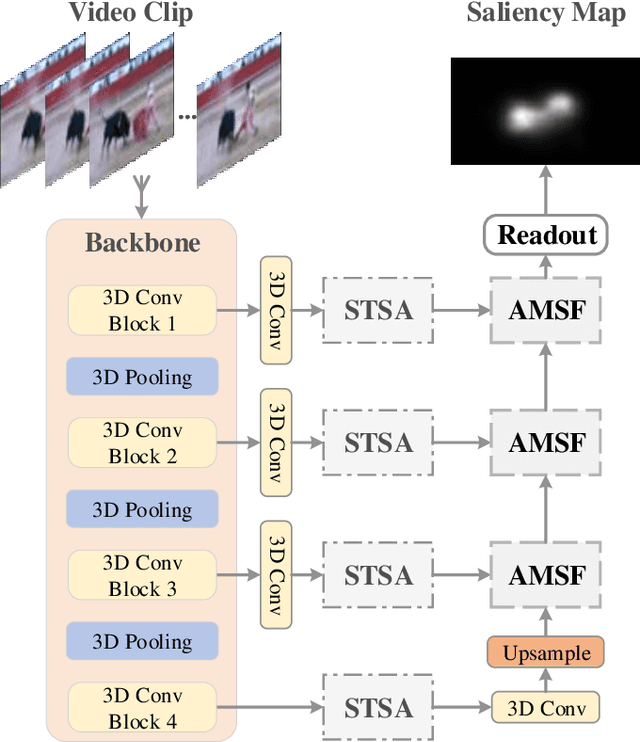
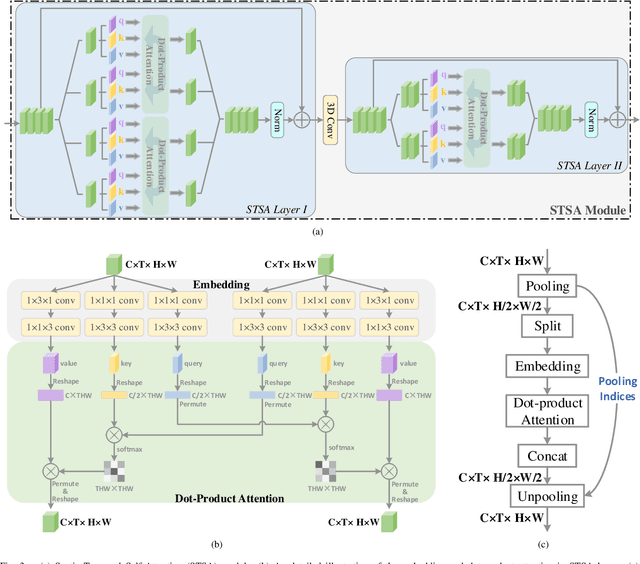
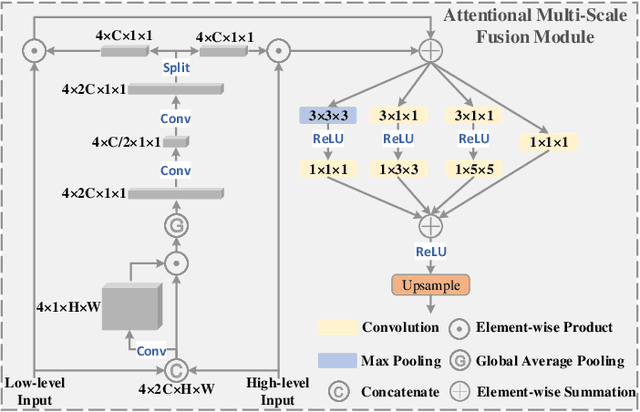
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
Reception strategies for sky-ground uplink non-orthogonal multiple access
Aug 15, 2021



Integration of unmanned aerial vehicles (UAVs) into fifth generation (5G) and beyond 5G (B5G) cellular networks is an intriguing problem that has recently tackled a lot of interest in both academia and industry. An effective solution is represented by cellular-connected UAVs, where traditional terrestrial users coexist with flying UAVs acting as additional aerial users, which access the 5G/B5G cellular network infrastructure from the sky. In this scenario, we study the challenging application in which an UAV acting as aerial user (AU) and a static (i.e., fixed) terrestrial user (TU) are paired to simultaneously transmit their uplink signals to a ground base station (BS) in the same time-frequency resource blocks. In such a case, due to the highly dynamic nature of the UAV, the signal transmitted by the AU experiences both time dispersion due to multipath propagation effects and frequency dispersion caused by Doppler shifts. On the other hand, for a static ground network, frequency dispersion of the signal transmitted by TU is negligible and only multipath effects have to be taken into account. To decode the superposed signals at the BS by using finite-length data record, we propose a novel sky-ground (SG) nonorthogonal multiple access (NOMA) receiving structure that additionally exploits the different circularity/noncircularity and almost-cyclostationarity properties of the AU and TU by means of improved channel estimation and time-varying successive interference cancellation. Numerical results demonstrate the usefulness of the proposed SG uplink NOMA reception scheme in future 5G/B5G networks.
Towards Lightweight Controllable Audio Synthesis with Conditional Implicit Neural Representations
Nov 14, 2021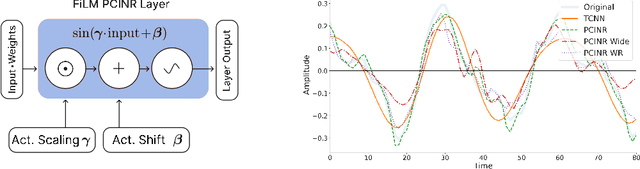
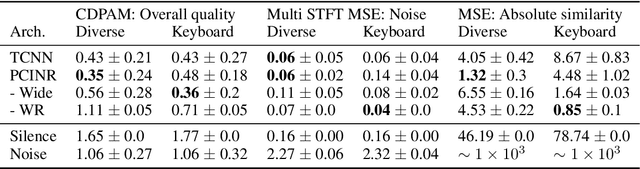
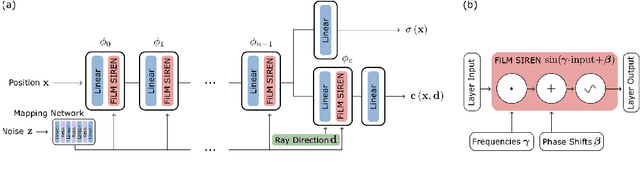
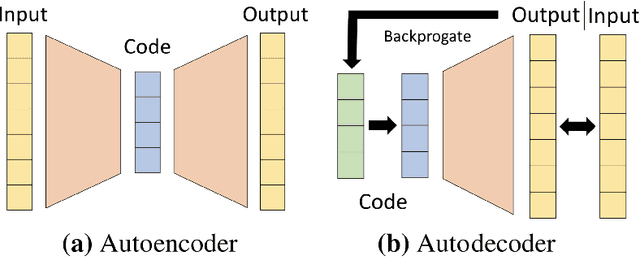
The high temporal resolution of audio and our perceptual sensitivity to small irregularities in waveforms make synthesizing at high sampling rates a complex and computationally intensive task, prohibiting real-time, controllable synthesis within many approaches. In this work we aim to shed light on the potential of Conditional Implicit Neural Representations (CINRs) as lightweight backbones in generative frameworks for audio synthesis. Implicit neural representations (INRs) are neural networks used to approximate low-dimensional functions, trained to represent a single geometric object by mapping input coordinates to structural information at input locations. In contrast with other neural methods for representing geometric objects, the memory required to parameterize the object is independent of resolution, and only scales with its complexity. A corollary of this is that INRs have infinite resolution, as they can be sampled at arbitrary resolutions. To apply the concept of INRs in the generative domain we frame generative modelling as learning a distribution of continuous functions. This can be achieved by introducing conditioning methods to INRs. Our experiments show that Periodic Conditional INRs (PCINRs) learn faster and generally produce quantitatively better audio reconstructions than Transposed Convolutional Neural Networks with equal parameter counts. However, their performance is very sensitive to activation scaling hyperparameters. When learning to represent more uniform sets, PCINRs tend to introduce artificial high-frequency components in reconstructions. We validate this noise can be minimized by applying standard weight regularization during training or decreasing the compositional depth of PCINRs, and suggest directions for future research.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 10, 2021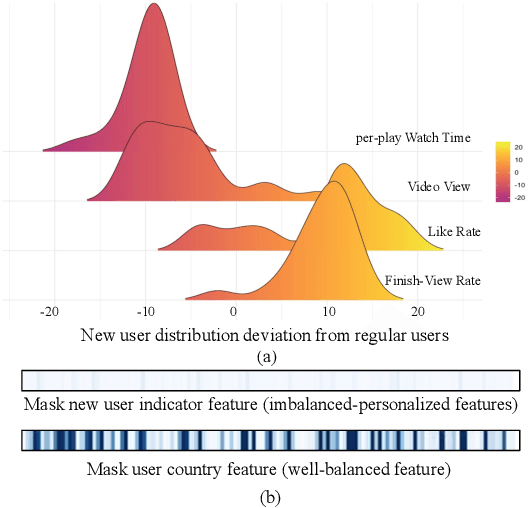
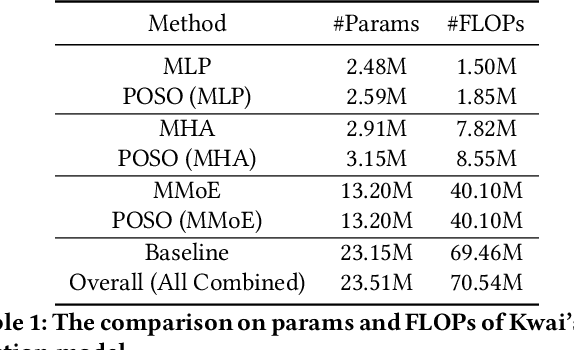
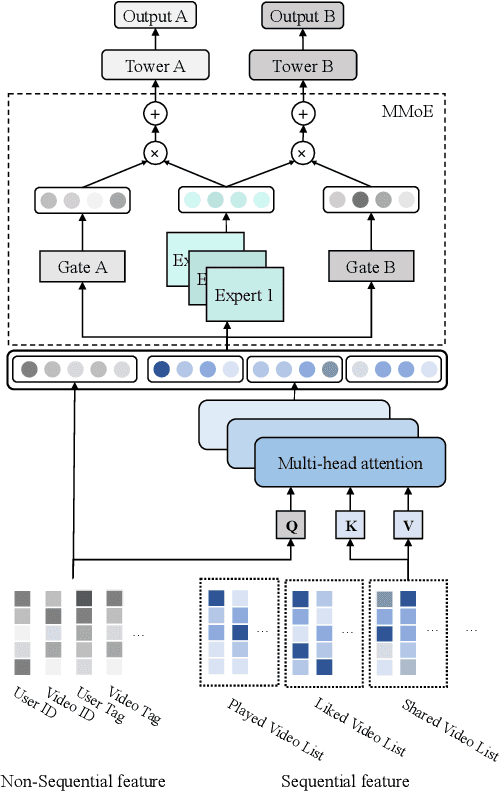
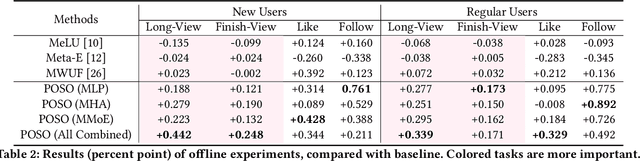
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the ``submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.
Single volume lung biomechanics from chest computed tomography using a mode preserving generative adversarial network
Oct 15, 2021
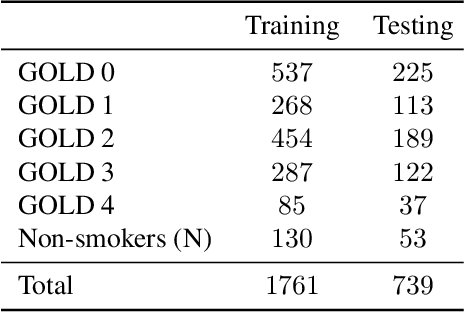
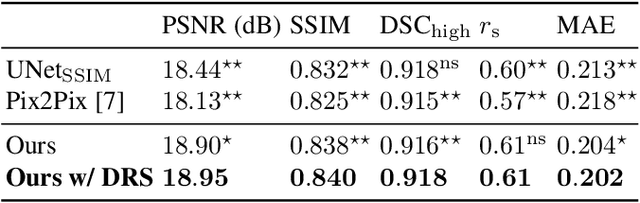

Local tissue expansion of the lungs is typically derived by registering computed tomography (CT) scans acquired at multiple lung volumes. However, acquiring multiple scans incurs increased radiation dose, time, and cost, and may not be possible in many cases, thus restricting the applicability of registration-based biomechanics. We propose a generative adversarial learning approach for estimating local tissue expansion directly from a single CT scan. The proposed framework was trained and evaluated on 2500 subjects from the SPIROMICS cohort. Once trained, the framework can be used as a registration-free method for predicting local tissue expansion. We evaluated model performance across varying degrees of disease severity and compared its performance with two image-to-image translation frameworks - UNet and Pix2Pix. Our model achieved an overall PSNR of 18.95 decibels, SSIM of 0.840, and Spearman's correlation of 0.61 at a high spatial resolution of 1 mm3.
A generative adversarial approach to facilitate archival-quality histopathologic diagnoses from frozen tissue sections
Aug 24, 2021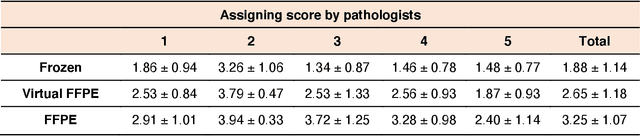
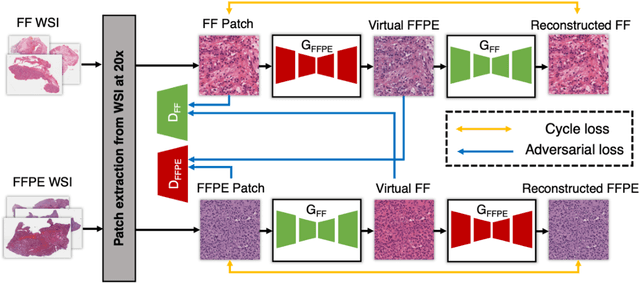
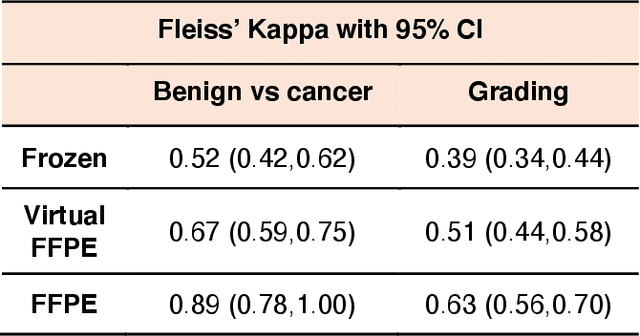
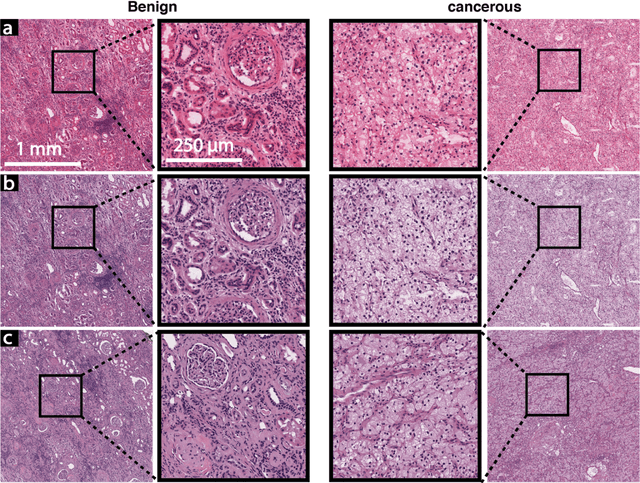
In clinical diagnostics and research involving histopathology, formalin fixed paraffin embedded (FFPE) tissue is almost universally favored for its superb image quality. However, tissue processing time (more than 24 hours) can slow decision-making. In contrast, fresh frozen (FF) processing (less than 1 hour) can yield rapid information but diagnostic accuracy is suboptimal due to lack of clearing, morphologic deformation and more frequent artifacts. Here, we bridge this gap using artificial intelligence. We synthesize FFPE-like images ,virtual FFPE, from FF images using a generative adversarial network (GAN) from 98 paired kidney samples derived from 40 patients. Five board-certified pathologists evaluated the results in a blinded test. Image quality of the virtual FFPE data was assessed to be high and showed a close resemblance to real FFPE images. Clinical assessments of disease on the virtual FFPE images showed a higher inter-observer agreement compared to FF images. The nearly instantaneously generated virtual FFPE images can not only reduce time to information but can facilitate more precise diagnosis from routine FF images without extraneous costs and effort.
A Novel Cluster Detection of COVID-19 Patients and Medical Disease Conditions Using Improved Evolutionary Clustering Algorithm Star
Sep 20, 2021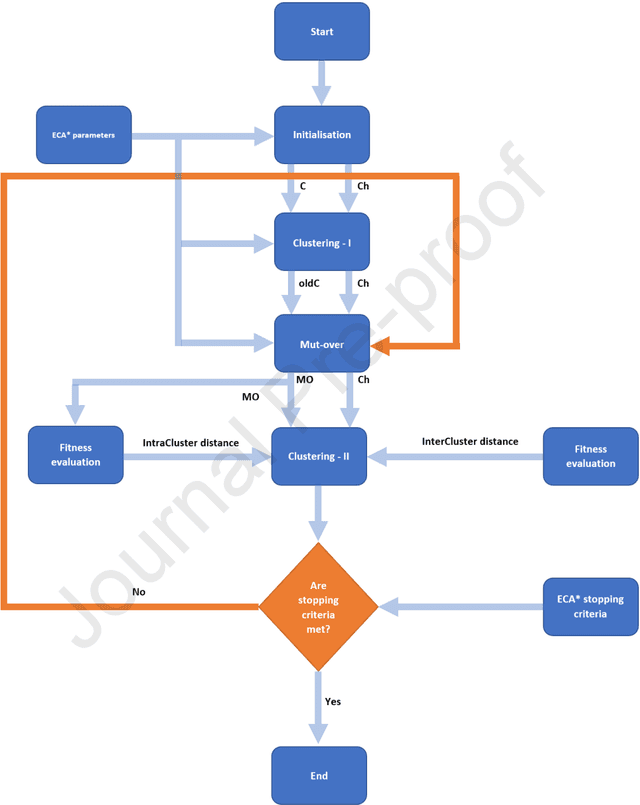
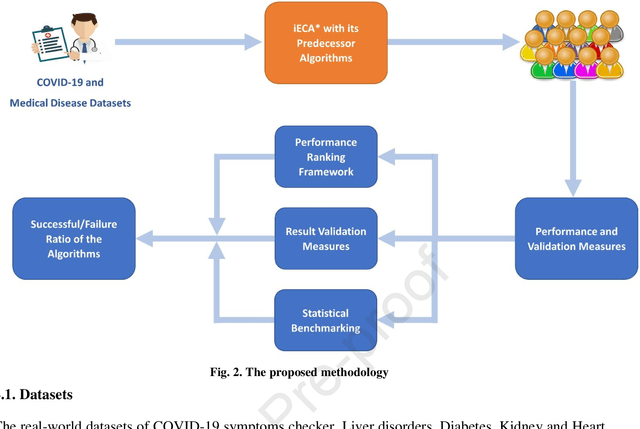
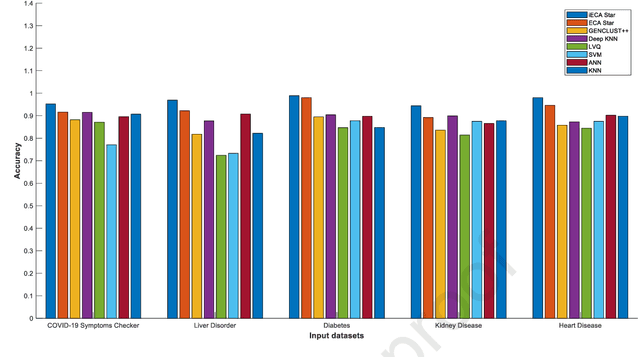
With the increasing number of samples, the manual clustering of COVID-19 and medical disease data samples becomes time-consuming and requires highly skilled labour. Recently, several algorithms have been used for clustering medical datasets deterministically; however, these definitions have not been effective in grouping and analysing medical diseases. The use of evolutionary clustering algorithms may help to effectively cluster these diseases. On this presumption, we improved the current evolutionary clustering algorithm star (ECA*), called iECA*, in three manners: (i) utilising the elbow method to find the correct number of clusters; (ii) cleaning and processing data as part of iECA* to apply it to multivariate and domain-theory datasets; (iii) using iECA* for real-world applications in clustering COVID-19 and medical disease datasets. Experiments were conducted to examine the performance of iECA* against state-of-the-art algorithms using performance and validation measures (validation measures, statistical benchmarking, and performance ranking framework). The results demonstrate three primary findings. First, iECA* was more effective than other algorithms in grouping the chosen medical disease datasets according to the cluster validation criteria. Second, iECA* exhibited the lower execution time and memory consumption for clustering all the datasets, compared to the current clustering methods analysed. Third, an operational framework was proposed to rate the effectiveness of iECA* against other algorithms in the datasets analysed, and the results indicated that iECA* exhibited the best performance in clustering all medical datasets. Further research is required on real-world multi-dimensional data containing complex knowledge fields for experimental verification of iECA* compared to evolutionary algorithms.
Causal Mechanism Transfer Network for Time Series Domain Adaptation in Mechanical Systems
Oct 13, 2019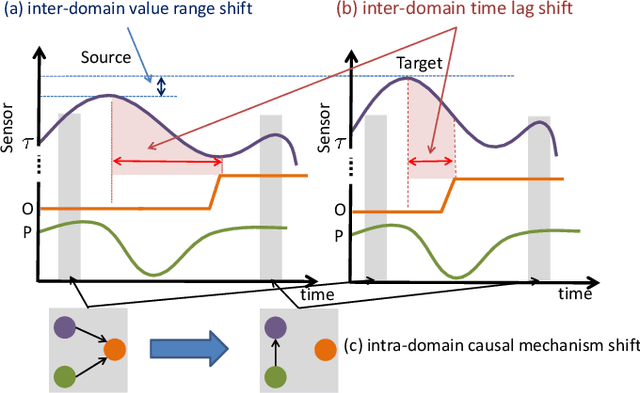
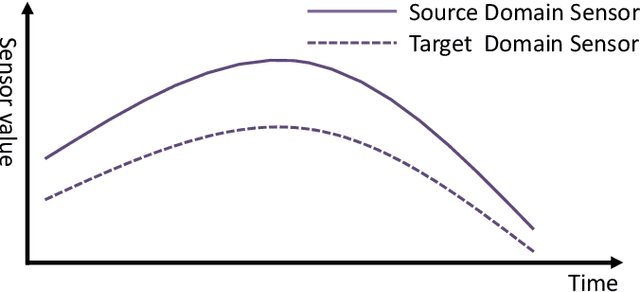
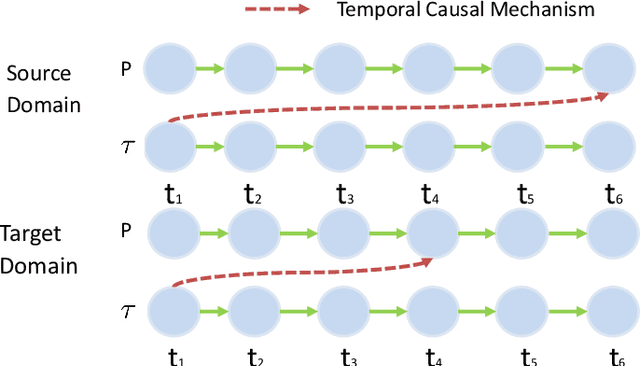
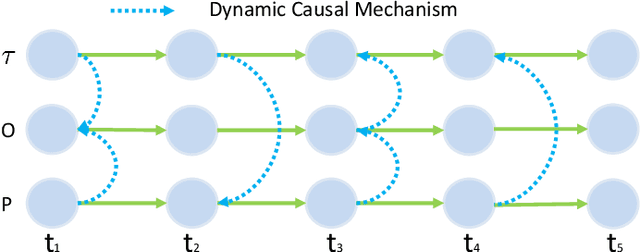
Data-driven models are becoming essential parts in modern mechanical systems, commonly used to capture the behavior of various equipment and varying environmental characteristics. Despite the advantages of these data-driven models on excellent adaptivity to high dynamics and aging equipment, they are usually hungry to massive labels over historical data, mostly contributed by human engineers at an extremely high cost. The label demand is now the major limiting factor to modeling accuracy, hindering the fulfillment of visions for applications. Fortunately, domain adaptation enhances the model generalization by utilizing the labelled source data as well as the unlabelled target data and then we can reuse the model on different domains. However, the mainstream domain adaptation methods cannot achieve ideal performance on time series data, because most of them focus on static samples and even the existing time series domain adaptation methods ignore the properties of time series data, such as temporal causal mechanism. In this paper, we assume that causal mechanism is invariant and present our Causal Mechanism Transfer Network(CMTN) for time series domain adaptation. By capturing and transferring the dynamic and temporal causal mechanism of multivariate time series data and alleviating the time lags and different value ranges among different machines, CMTN allows the data-driven models to exploit existing data and labels from similar systems, such that the resulting model on a new system is highly reliable even with very limited data. We report our empirical results and lessons learned from two real-world case studies, on chiller plant energy optimization and boiler fault detection, which outperforms the existing state-of-the-art method.
DCUR: Data Curriculum for Teaching via Samples with Reinforcement Learning
Sep 15, 2021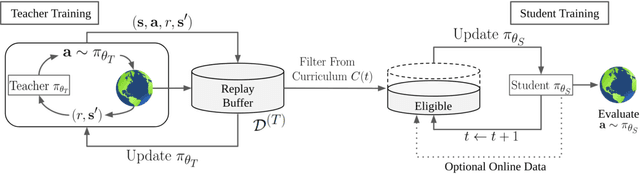
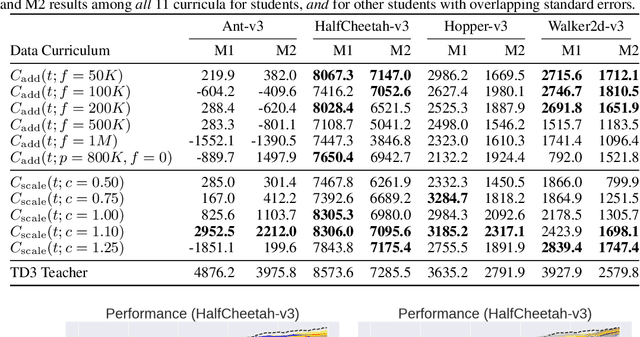
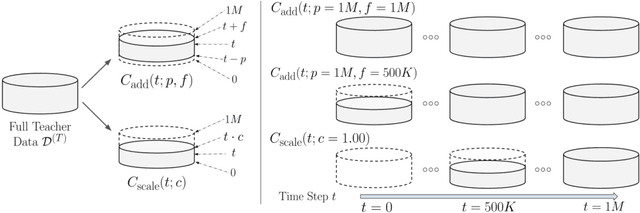
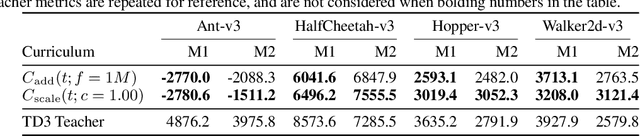
Deep reinforcement learning (RL) has shown great empirical successes, but suffers from brittleness and sample inefficiency. A potential remedy is to use a previously-trained policy as a source of supervision. In this work, we refer to these policies as teachers and study how to transfer their expertise to new student policies by focusing on data usage. We propose a framework, Data CUrriculum for Reinforcement learning (DCUR), which first trains teachers using online deep RL, and stores the logged environment interaction history. Then, students learn by running either offline RL or by using teacher data in combination with a small amount of self-generated data. DCUR's central idea involves defining a class of data curricula which, as a function of training time, limits the student to sampling from a fixed subset of the full teacher data. We test teachers and students using state-of-the-art deep RL algorithms across a variety of data curricula. Results suggest that the choice of data curricula significantly impacts student learning, and that it is beneficial to limit the data during early training stages while gradually letting the data availability grow over time. We identify when the student can learn offline and match teacher performance without relying on specialized offline RL algorithms. Furthermore, we show that collecting a small fraction of online data provides complementary benefits with the data curriculum. Supplementary material is available at https://tinyurl.com/teach-dcur.
DirectQuote: A Dataset for Direct Quotation Extraction and Attribution in News Articles
Oct 15, 2021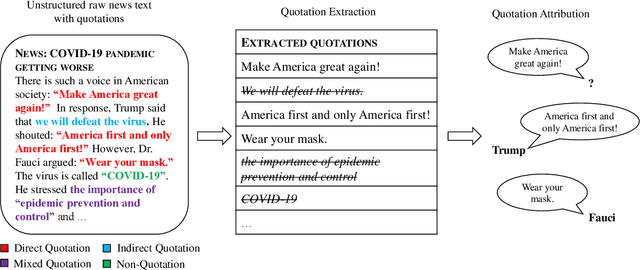


Quotation extraction and attribution are challenging tasks, aiming at determining the spans containing quotations and attributing each quotation to the original speaker. Applying this task to news data is highly related to fact-checking, media monitoring and news tracking. Direct quotations are more traceable and informative, and therefore of great significance among different types of quotations. Therefore, this paper introduces DirectQuote, a corpus containing 19,760 paragraphs and 10,279 direct quotations manually annotated from online news media. To the best of our knowledge, this is the largest and most complete corpus that focuses on direct quotations in news texts. We ensure that each speaker in the annotation can be linked to a specific named entity on Wikidata, benefiting various downstream tasks. In addition, for the first time, we propose several sequence labeling models as baseline methods to extract and attribute quotations simultaneously in an end-to-end manner.