 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Channel Estimation and Reflection Optimization for Reconfigurable Intelligent Surface-Enhanced OFDM Systems
Oct 25, 2021
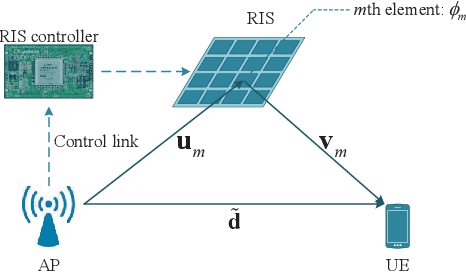
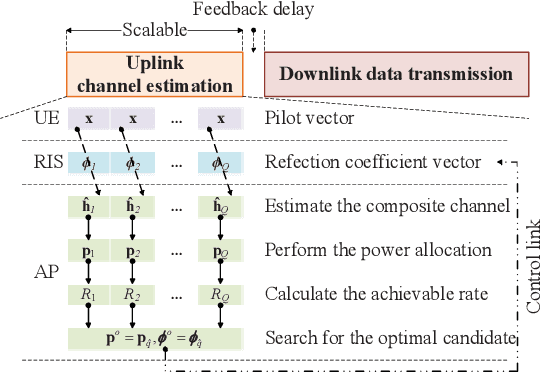
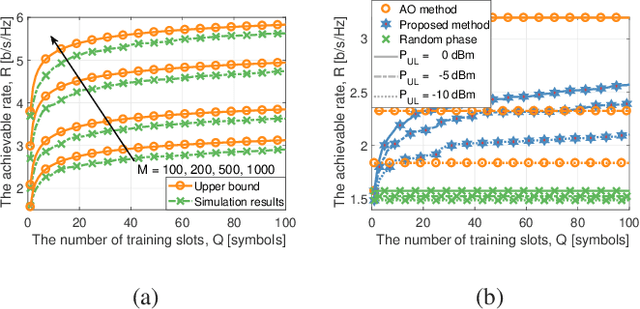
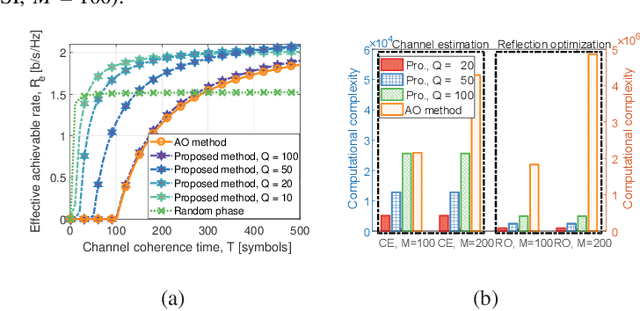
This paper proposes a scalable channel estimation and reflection optimization framework for reconfigurable intelligent surface (RIS)-enhanced orthogonal frequency division multiplexing (OFDM) systems. Specifically, the proposed scheme firstly generates a training set of RIS reflection coefficient vectors offline. For each RIS reflection coefficient vector in the training set, the proposed scheme estimates only the end-to-end composite channel and then performs the transmit power allocation. As a result, the RIS reflection optimization is simplified by searching for the optimal reflection coefficient vector maximizing the achievable rate from the pre-designed training set. The proposed scheme is capable of flexibly adjusting the training overhead according to the given channel coherence time, which is in sharp contrast to the conventional counterparts. Moreover, we discuss the computational complexity of the proposed scheme and analyze the theoretical scaling law of the achievable rate versus the number of training slots. Finally, simulation results demonstrate that the proposed scheme is superior to existing approaches in terms of decreasing training overhead, reducing complexity as well as improving rate performance in the presence of channel estimation errors.
Quantum Boosting using Domain-Partitioning Hypotheses
Oct 25, 2021
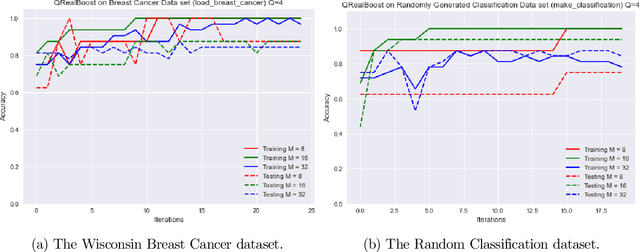
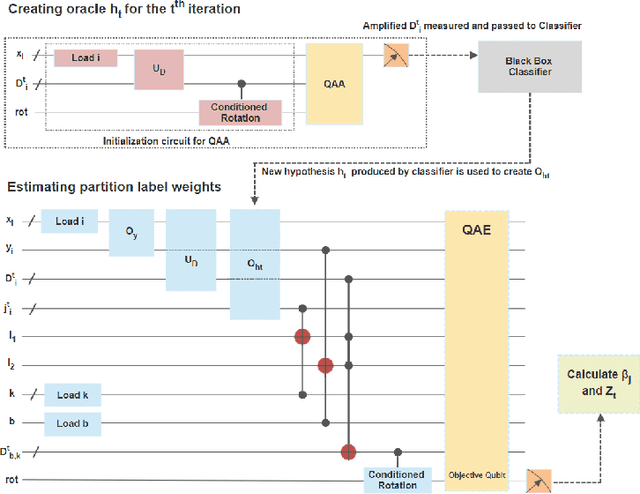
Boosting is an ensemble learning method that converts a weak learner into a strong learner in the PAC learning framework. Freund and Schapire gave the first classical boosting algorithm for binary hypothesis known as AdaBoost, and this was recently adapted into a quantum boosting algorithm by Arunachalam et al. Their quantum boosting algorithm (which we refer to as Q-AdaBoost) is quadratically faster than the classical version in terms of the VC-dimension of the hypothesis class of the weak learner but polynomially worse in the bias of the weak learner. In this work we design a different quantum boosting algorithm that uses domain partitioning hypotheses that are significantly more flexible than those used in prior quantum boosting algorithms in terms of margin calculations. Our algorithm Q-RealBoost is inspired by the "Real AdaBoost" (aka. RealBoost) extension to the original AdaBoost algorithm. Further, we show that Q-RealBoost provides a polynomial speedup over Q-AdaBoost in terms of both the bias of the weak learner and the time taken by the weak learner to learn the target concept class.
Dictionary Learning with Convex Update (ROMD)
Oct 25, 2021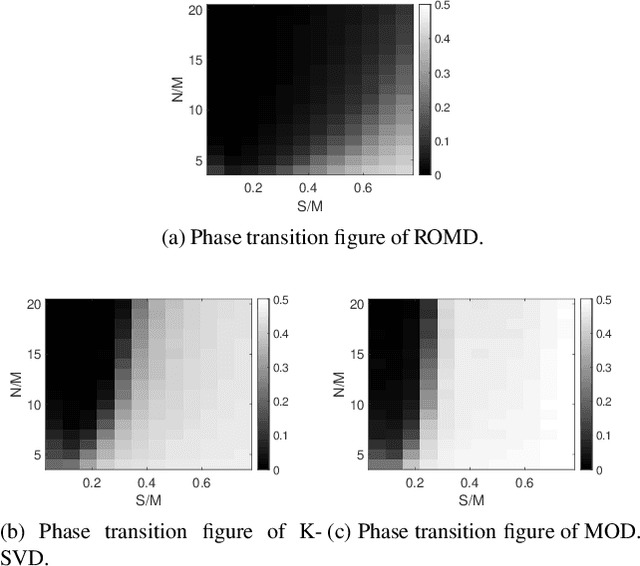
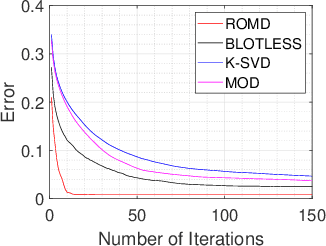
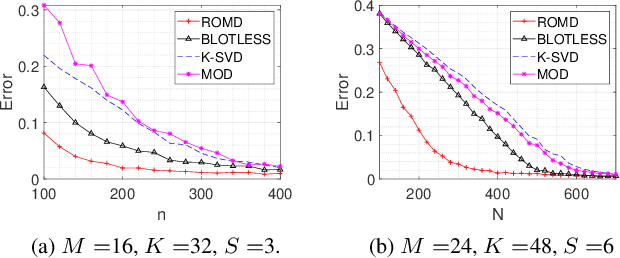
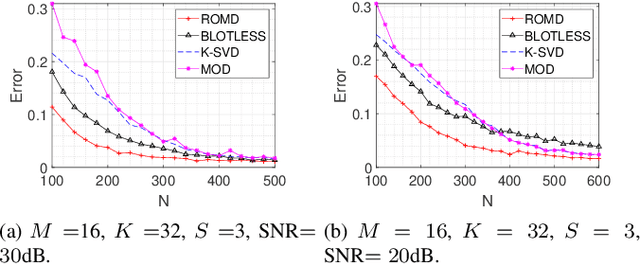
Dictionary learning aims to find a dictionary under which the training data can be sparsely represented, and it is usually achieved by iteratively applying two stages: sparse coding and dictionary update. Typical methods for dictionary update focuses on refining both dictionary atoms and their corresponding sparse coefficients by using the sparsity patterns obtained from sparse coding stage, and hence it is a non-convex bilinear inverse problem. In this paper, we propose a Rank-One Matrix Decomposition (ROMD) algorithm to recast this challenge into a convex problem by resolving these two variables into a set of rank-one matrices. Different from methods in the literature, ROMD updates the whole dictionary at a time using convex programming. The advantages hence include both convergence guarantees for dictionary update and faster convergence of the whole dictionary learning. The performance of ROMD is compared with other benchmark dictionary learning algorithms. The results show the improvement of ROMD in recovery accuracy, especially in the cases of high sparsity level and fewer observation data.
Model reduction for the material point method via learning the deformation map and its spatial-temporal gradients
Sep 25, 2021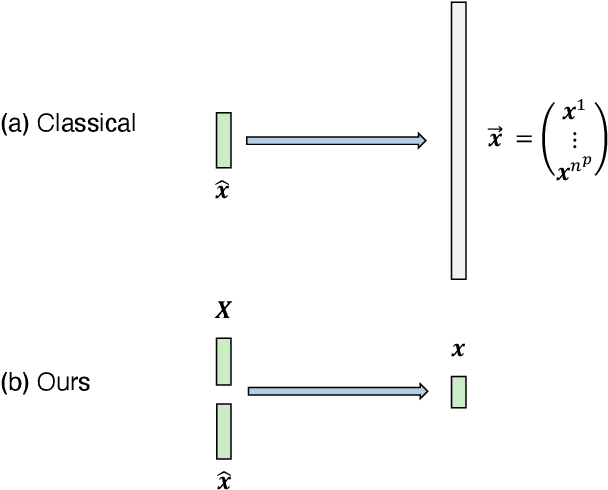
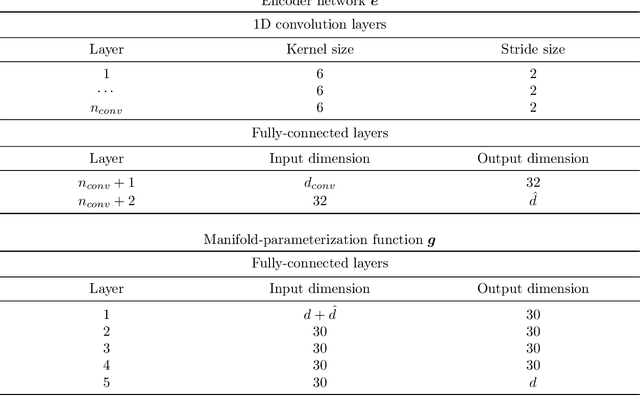
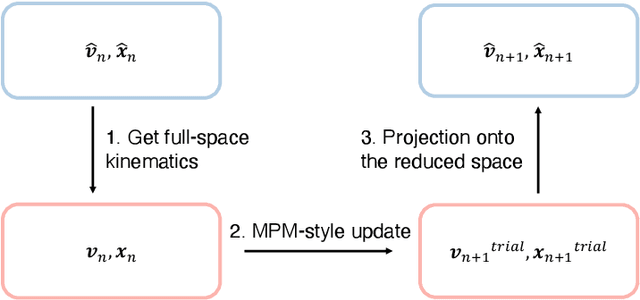

This work proposes a model-reduction approach for the material point method on nonlinear manifolds. The technique approximates the $\textit{kinematics}$ by approximating the deformation map in a manner that restricts deformation trajectories to reside on a low-dimensional manifold expressed from the extrinsic view via a parameterization function. By explicitly approximating the deformation map and its spatial-temporal gradients, the deformation gradient and the velocity can be computed simply by differentiating the associated parameterization function. Unlike classical model reduction techniques that build a subspace for a finite number of degrees of freedom, the proposed method approximates the entire deformation map with infinite degrees of freedom. Therefore, the technique supports resolution changes in the reduced simulation, attaining the challenging task of zero-shot super-resolution by generating material points unseen in the training data. The ability to generate material points also allows for adaptive quadrature rules for stress update. A family of projection methods is devised to generate $\textit{dynamics}$, i.e., at every time step, the methods perform three steps: (1) generate quadratures in the full space from the reduced space, (2) compute position and velocity updates in the full space, and (3) perform a least-squares projection of the updated position and velocity onto the low-dimensional manifold and its tangent space. Computational speedup is achieved via hyper-reduction, i.e., only a subset of the original material points are needed for dynamics update. Large-scale numerical examples with millions of material points illustrate the method's ability to gain an order-of-magnitude computational-cost saving -- indeed $\textit{real-time simulations}$ in some cases -- with negligible errors.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019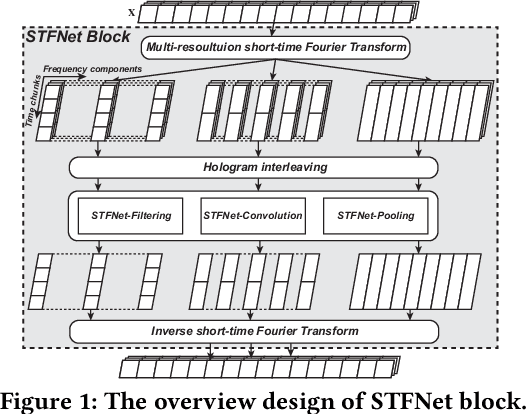
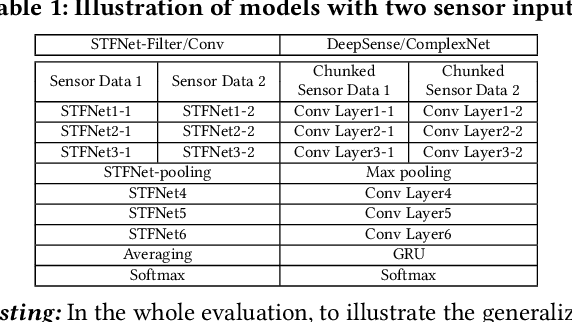
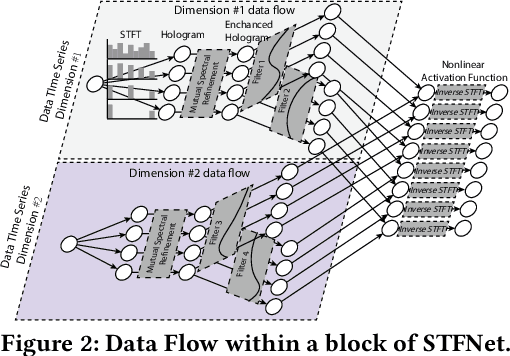
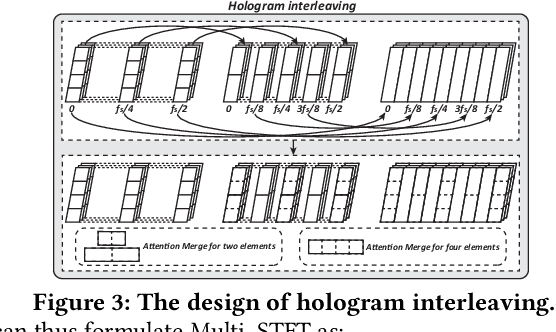
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.
Multi-agent Reinforcement Learning Improvement in a Dynamic Environment Using Knowledge Transfer
Jul 20, 2021
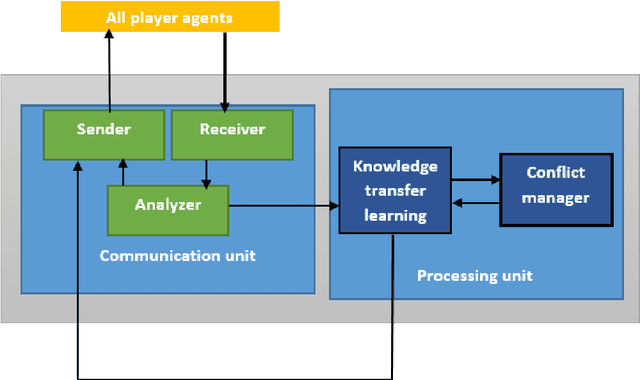
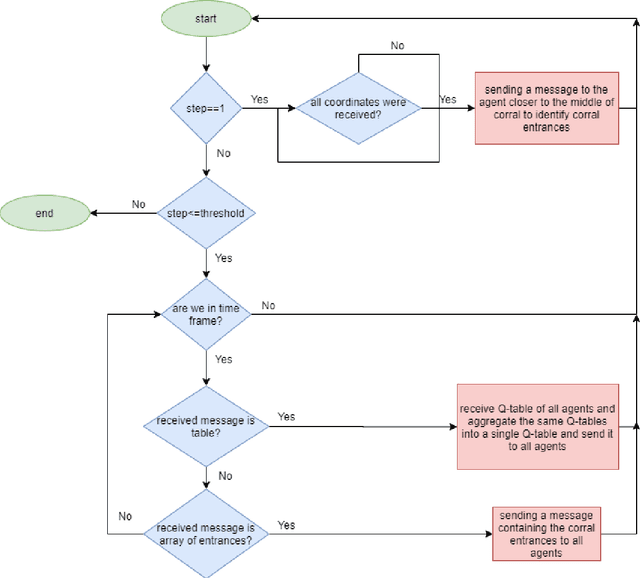
Cooperative multi-agent systems are being widely used in different domains. Interaction among agents would bring benefits, including reducing operating costs, high scalability, and facilitating parallel processing. These systems are also a good option for handling large-scale, unknown, and dynamic environments. However, learning in these environments has become a very important challenge in various applications. These challenges include the effect of search space size on learning time, inefficient cooperation among agents, and the lack of proper coordination among agents' decisions. Moreover, reinforcement learning algorithms may suffer from long convergence time in these problems. In this paper, a communication framework using knowledge transfer concepts is introduced to address such challenges in the herding problem with large state space. To handle the problems of convergence, knowledge transfer has been utilized that can significantly increase the efficiency of reinforcement learning algorithms. Coordination between the agents is carried out through a head agent in each group of agents and a coordinator agent respectively. The results demonstrate that this framework could indeed enhance the speed of learning and reduce convergence time.
TomoSLAM: factor graph optimization for rotation angle refinement in microtomography
Nov 10, 2021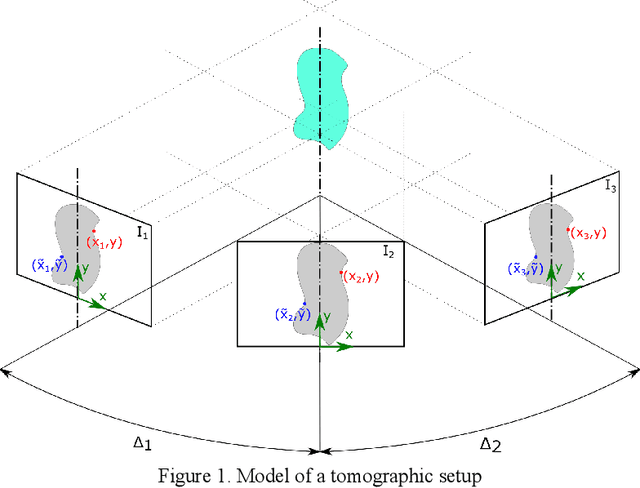

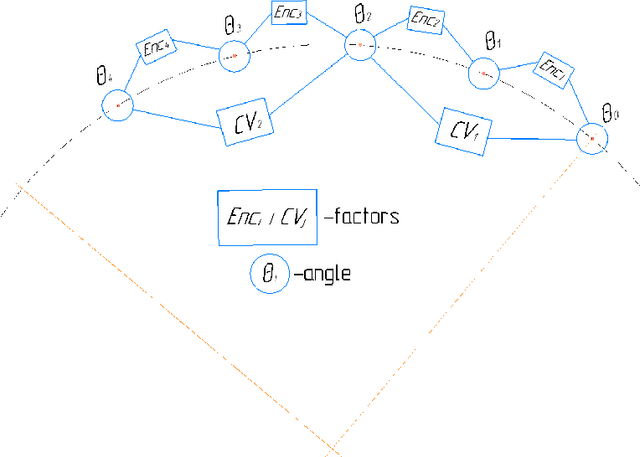
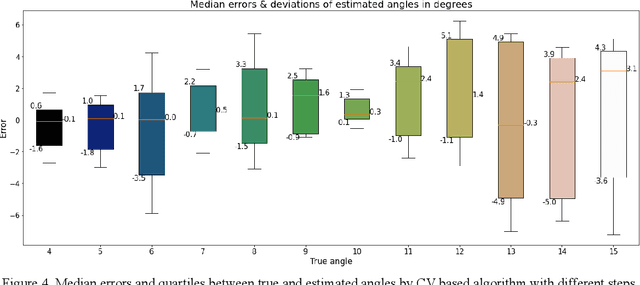
In computed tomography (CT), the relative trajectories of a sample, a detector, and a signal source are traditionally considered to be known, since they are caused by the intentional preprogrammed movement of the instrument parts. However, due to the mechanical backlashes, rotation sensor measurement errors, thermal deformations real trajectory differs from desired ones. This negatively affects the resulting quality of tomographic reconstruction. Neither the calibration nor preliminary adjustments of the device completely eliminates the inaccuracy of the trajectory but significantly increase the cost of instrument maintenance. A number of approaches to this problem are based on an automatic refinement of the source and sensor position estimate relative to the sample for each projection (at each time step) during the reconstruction process. A similar problem of position refinement while observing different images of an object from different angles is well known in robotics (particularly, in mobile robots and self-driving vehicles) and is called Simultaneous Localization And Mapping (SLAM). The scientific novelty of this work is to consider the problem of trajectory refinement in microtomography as a SLAM problem. This is achieved by extracting Speeded Up Robust Features (SURF) features from X-ray projections, filtering matches with Random Sample Consensus (RANSAC), calculating angles between projections, and using them in factor graph in combination with stepper motor control signals in order to refine rotation angles.
Hierarchical Modeling for Task Recognition and Action Segmentation in Weakly-Labeled Instructional Videos
Oct 12, 2021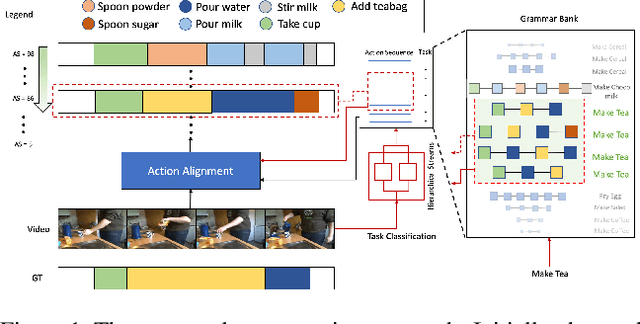
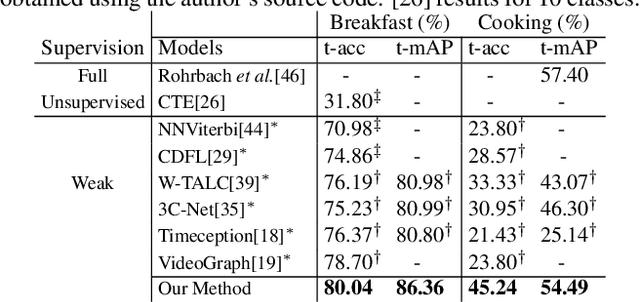
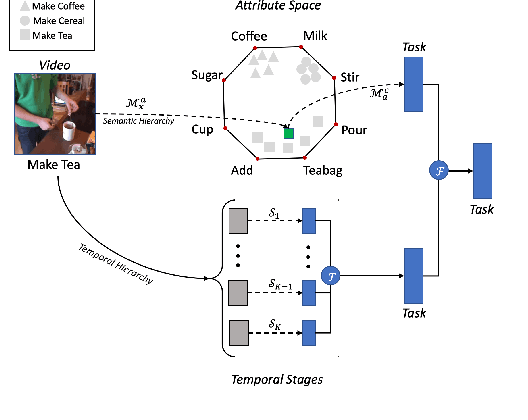
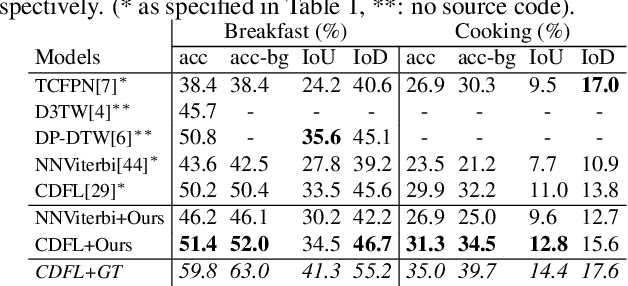
This paper focuses on task recognition and action segmentation in weakly-labeled instructional videos, where only the ordered sequence of video-level actions is available during training. We propose a two-stream framework, which exploits semantic and temporal hierarchies to recognize top-level tasks in instructional videos. Further, we present a novel top-down weakly-supervised action segmentation approach, where the predicted task is used to constrain the inference of fine-grained action sequences. Experimental results on the popular Breakfast and Cooking 2 datasets show that our two-stream hierarchical task modeling significantly outperforms existing methods in top-level task recognition for all datasets and metrics. Additionally, using our task recognition framework in the proposed top-down action segmentation approach consistently improves the state of the art, while also reducing segmentation inference time by 80-90 percent.
Reducing the Deployment-Time Inference Control Costs of Deep Reinforcement Learning Agents via an Asymmetric Architecture
May 30, 2021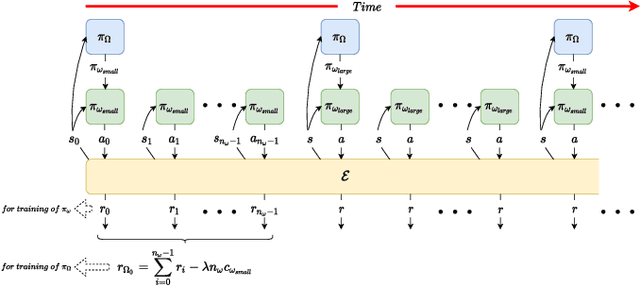
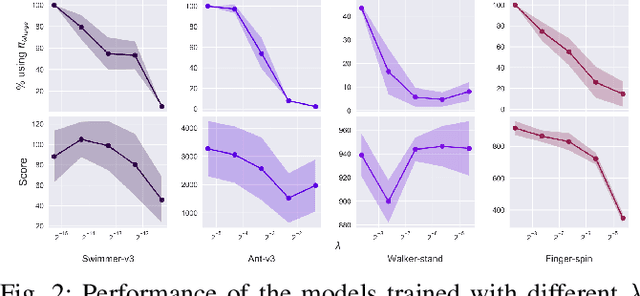
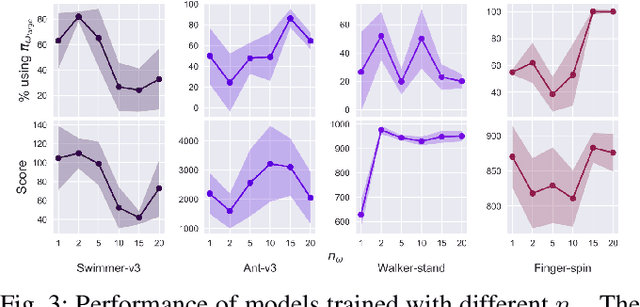
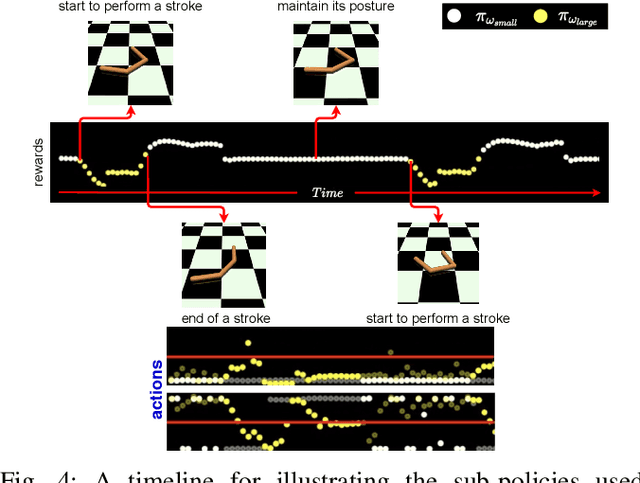
Deep reinforcement learning (DRL) has been demonstrated to provide promising results in several challenging decision making and control tasks. However, the required inference costs of deep neural networks (DNNs) could prevent DRL from being applied to mobile robots which cannot afford high energy-consuming computations. To enable DRL methods to be affordable in such energy-limited platforms, we propose an asymmetric architecture that reduces the overall inference costs via switching between a computationally expensive policy and an economic one. The experimental results evaluated on a number of representative benchmark suites for robotic control tasks demonstrate that our method is able to reduce the inference costs while retaining the agent's overall performance.
Unsupervised Action Localization Crop in Video Retargeting for 3D ConvNets
Nov 14, 2021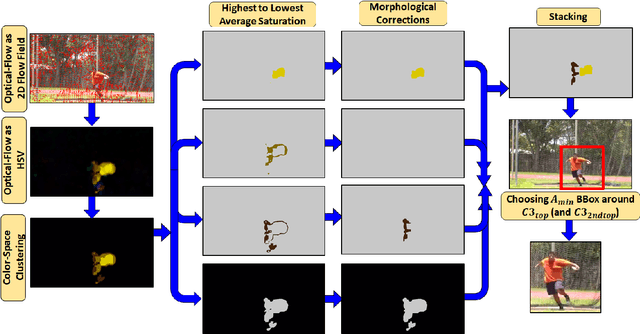
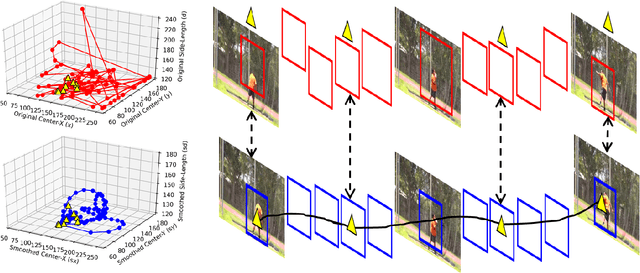

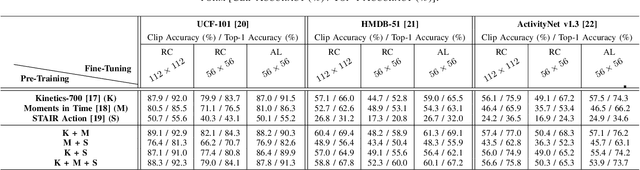
Untrimmed videos on social media or those captured by robots and surveillance cameras are of varied aspect ratios. However, 3D CNNs require a square-shaped video whose spatial dimension is smaller than the original one. Random or center-cropping techniques in use may leave out the video's subject altogether. To address this, we propose an unsupervised video cropping approach by shaping this as a retargeting and video-to-video synthesis problem. The synthesized video maintains 1:1 aspect ratio, smaller in size and is targeted at the video-subject throughout the whole duration. First, action localization on the individual frames is performed by identifying patches with homogeneous motion patterns and a single salient patch is pin-pointed. To avoid viewpoint jitters and flickering artifacts, any inter-frame scale or position changes among the patches is performed gradually over time. This issue is addressed with a poly-Bezier fitting in 3D space that passes through some chosen pivot timestamps and its shape is influenced by in-between control timestamps. To corroborate the effectiveness of the proposed method, we evaluate the video classification task by comparing our dynamic cropping with static random on three benchmark datasets: UCF-101, HMDB-51 and ActivityNet v1.3. The clip accuracy and top-1 accuracy for video classification after our cropping, outperform 3D CNN performances for same-sized inputs with random crop; sometimes even surpassing larger random crop sizes.